안녕하세요. 박성준 연구원입니다. 오늘도 Video Question Grounding 논문입니다.
Introduction
비디오 정보와 자연어 정보를 같이 이해할 수 있는 Video-LM은 이미지-언어 모델인 Image-LM에 비해 더 높은 계산 비용과 높은 주석 비용으로 인해 모델 및 데이터의 규모를 확장하는 데에 어려움이 있었습니다. 이 한계를 극복하기 위해 최근 연구들은 사전 학습된 Image-LM을 활용하여 Video-LM을 효율적으로 학습하는 방법을 연구하기 시작했습니다. 그 방법인 Warm-Start 전략은 Video-LM의 학습에 도움이 되지만, 대부분 균일하게 혹은 무작위로 샘플링된 비디오 프레임들을 시각 입력으로 연결할 뿐이며 명시적으로 언어를 이해한 채로 시간적 모델링을 하지 않습니다. 이러한 방식은 중요한 시각적 단서의 손실로 이어질 수 있기에 Video-LM이 자연어와 무관하거나 중요하지 않은 프레임에 집중할 수도 있게 만듭니다. 어렵게 서술되어 있지만, 간단하게 설명하면 Video-LM을 학습할 때 어떤 비디오 프레임이 자연어와 연관이 있는 지를 학습하지 않기에 기존의 모델은 자연어와 유사도가 높은 중요한 프레임의 위치를 잘 알지 못한다는 것을 말합니다.
저자는 이러한 한계를 극복하기 위해서 Self-Chained Video Localization-Answering(SeViLA) 프레임워크를 제안합니다. 저자는 BLIP-2 모델을 베이스라인으로 사용하여 Video에 대한 QA와 Grounding을 모두 처리할 수 있으면서 동시에 주석으로 인한 비용을 최소화할 수 있도록 프레임워크를 설계했습니다. SeViLA 모델은 Localizer와 Answerer의 두 모듈로 구성되며 효율적인 미세조정 방법인 PEFT기법으로 초기화합니다. 저자는 Forward 단계에서 Localizer의 출력을 Answerer의 입력으로 연계하고 Backward에서 Answerer의 피드백을 통해 Localizer를 계선하는 프레임워크를 제안합니다. 구체적으로는 Forward 단계에서 각 프레임워크마다 “해당 프레임의 정보가 주어진 질문을 정확히 답변하는 데 필요한 세부 정보를 제공하는가(“Does the information within the frame provide the necessary details to accurately answer the given question?)”라는 프롬프트를 사용하여 질문으로부터 중요한 비디오의 키프레임을 선택하고 Answerer는 Localizer가 선택한 키프레임을 입력으로 연결하는 것으로 최종 답변을 생성합니다. Backward 단계에서는 Answerer를 활용하여 키프레임에 대한 pseudo-label을 생성하고 이 pseudo-label을 통해 Localizer를 스스로 조정(self-refinement)합니다. 이러한 Forward, Backward 과정에서 QA와 Grounding의 성능이 모두 향상되며 스스로 조정하기에 주석도 필요없게 됩니다. 즉, weakly supervised 방법임을 알 수 있습니다.
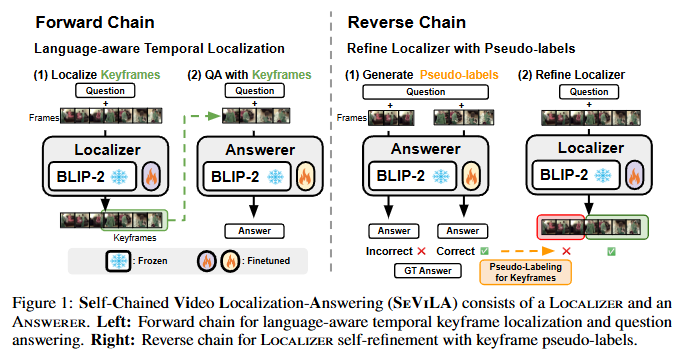
Figure 1은 방금 제가 설명드린 Forward와 Backward 과정을 그림으로 설명하고 있습니다. 자세한 방법은 Method에서 한번 다시 다루겠습니다. 저자는 이러한 방법을 통해서 Video QA와 Grounding을 모두 수행할 수 있는 프레임워크를 제안합니다. Grounding 주석 없이 학습할 수 있는 Weakly supervised 방법론이며, 여러 Video-Language 벤치마크에서 SOTA를 달성하였습니다.
Method
Self-Chained Video Localization-Answering(SeViLA)는 BLIP-2 모델의 사전지식을 활용하여 학습합니다. BLIP-2 모델은 당시 SOTA 사전학습 이미지-언어 모델로 Frozen 이미지 인코더와 Frozen LLM 그리고 이미지 인코더와 LLM을 이어주는 Q-Former로 구성됩니다. Q-Former는 이미지 인코더로부터 추출된 시각 특징 h과 학습 가능한 쿼리 임베딩 q를 입력 받아 고정된 길이의 시각 특징 v를 얻습니다. BLIP-2의 Q-Former는 두 단계를 통해 학습되는데 첫 단계에서는 이미지 인코더에 연결하여 이미지-텍스트 사전학습을 진행하는 것으로 텍스트에 가장 유용한 시각 정보를 추출하고 h 내의 관련 없는 세부정보를 제거하도록 학습합니다. 두번째 단계에서는 Q-Former를 LLM에 연결하여 생성적 언어 능력을 학습합니다. FC-layer를 통해 자연어 쿼리의 임베딩을 LLM 차원으로 사영시켜 이미지-텍스트 사전학습을 진행합니다. 이 두과정을 거쳐 사전학습된 BLIP-2는 다양한 이미지-언어 과제에서 뛰어난 성능을 보일 수 있습니다. SeViLA는 기본적으로 BLIP-2를 Localizer와 Answerer에서 모두 활용합니다. 이미지 인코더와 LLM을 Freeze해둔 상태로 두개의 Q-Former를 학습하는 방법으로 Localizer와 Answerer를 업데이트합니다.
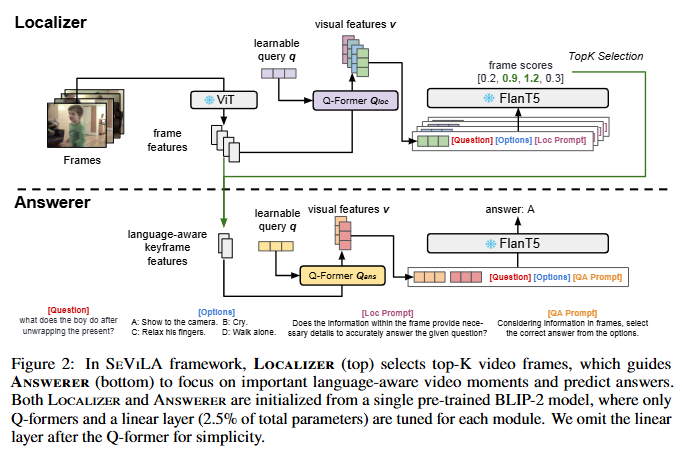
Figure 2는 SeViLA가 Localizer와 Answerer가 BLIP-2를 활용하는 방법을 보여줍니다. Localizer는 상위 K개의 프레임을 선택하며 Answerer는 이 프레임들(키프레임)에 집중하여 답변을 예측합니다. Localizer와 Answerer는 서로 다른 Q-Former를 사용합니다.
Localizer는 Frozen 이미지 인코더 ViT를 통해 feature h를 추출합니다. 비디오 특징 V = {h_1, h_2, \dots, h_n}는 Answerer와 Localizer에서 모두 동일하게 사용됩니다. Localizer의 목적은 V로부터 가장 자연어 쿼리에 연관 높은 키프레임을 선정하는 것입니다. Figure 2의 상단에서와 같이 원본 비이도 특징으로부터 프레임 특징을 각각 독립적으로 추출하고 이를 LLM인 Flan T5에 입력합니다. 여기서 LLM에는 “해당 프레임의 정보가 주어진 질문을 정확히 답변하는 데 필요한 세부 정보를 제공하는가(“Does the information within the frame provide the necessary details to accurately answer the given question?)”의 프롬프트와 자연어 쿼리를 함께 입력하여 자연어 context를 파악할 수 있게 구성합니다. LLM은 각 프레임의 점수를 산출하고 이 점수는 LLM이 키프레임을 선정할 때 기준이 되는 점수입니다. 이를 top-K개 선정하여 사용하게 됩니다. k개는 하이퍼파라미터로 선정합니다.
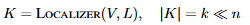
Answerer는 Localizer로부터 키프레임 집합인 K를 이어 받아 답변을 생성합니다. Localizer에서와 마찬가지로 Q-Former를 거쳐 키프레임들과 자연어 쿼리 특징을 연결하고 LLM에 입력하는 것으로 최종 답변을 생성합니다. LLM에 입력할 때에는 각 프레임의 ID 토큰을 추가로 입력하는 것으로 프레임을 구분하여 입력했다고 합니다.
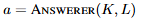
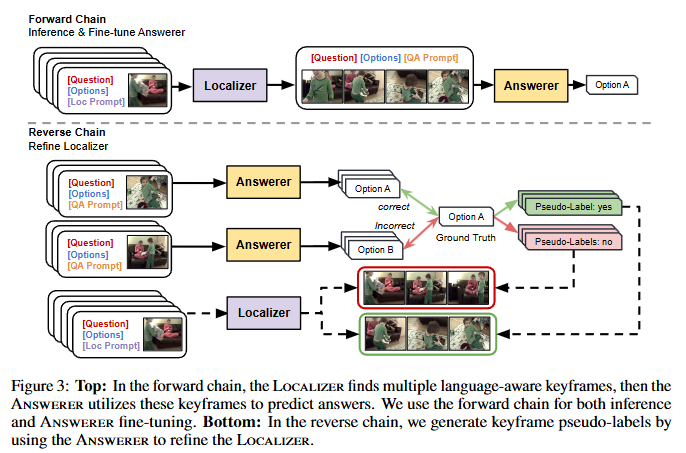
Figure 3은 Forward와 Backward를 설명하는 그림입니다. Forward에서는 Answerer를 미세조정합니다. 일반적인 미세조정 과정과 동일하므로 자세한 설명은 생략하겠습니다. Backward가 저자가 제안하는 파이프라인의 핵심 내용입니다. 앞선 Forward 과정에서 답변을 Answerer가 생성했습니다. Answerer가 생성한 답변을 pseudo-label로 사용하는 것으로 저자는 주석을 필요로하지 않는 weakly-supervised 방법론임을 Introduction에서 강조했었습니다. 여기서 생성하는 pseudo-label은 이진 분류 라벨로 키프레임인지 아닌지를 구분하는 라벨입니다. 만약에 Answerer가 하나의 프레임을 참고하여 답변을 맞출 수 있다면, 키프레임이고, 그렇지 않다면 키프레임이 아닐거라는 가설로 Freeze된 Answerer로 프레임별로 답변을 생성하고 정답과 비교를 통해 키프레임이 될 수 있는지 없는지를 판단하게 됩니다. 이 과정을 통해 Localizer는 키프레임에 해당하는 프레임이 어떤 프레임인지를 스스로 미세조정(self-refinement)할 수 있습니다. Lozalizer의 성능을 확실히 하기 위해 저자는 영상 내 구간 검색(Moment Retrieval) 데이터셋인 QVHighlights 데이터셋을 통해 사전학습 한 후에 self-refine합니다. 이를 통해 저자는 BLIP-2 기반의 Video QA, Grounding 모델인 SeViLA를 학습했습니다.
Experiments
저자는 먼저 여러 VideoQA 데이터셋에서의 객관식 QA 성능을 실험합니다. 그리고 Video Language Event Prediction (VLEP)와 Moment Retrieval 성능을 측정하는 것으로 저자가 제안하는 SeViLA 모델이 VideoQA, Grounding 모두 가능하고 성능이 좋다는 것을 검증합니다. Baseline은 InternVideo와 BLIP-2로 설정하여 성능을 비교합니다.
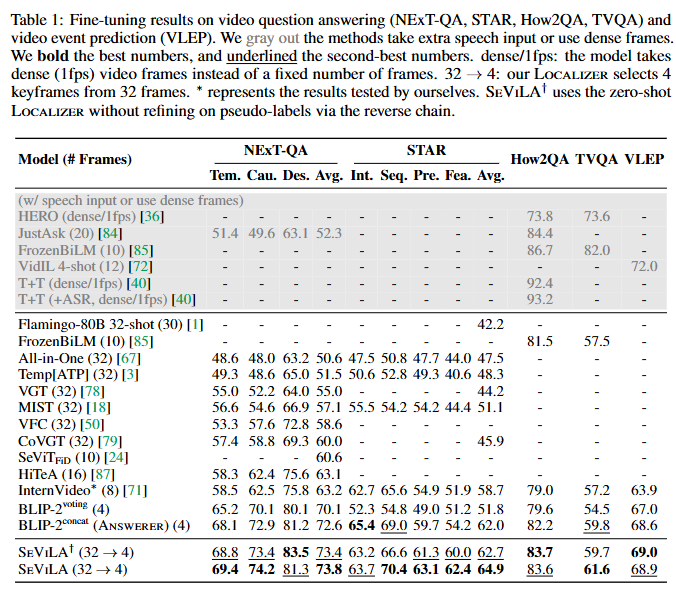
Table 1은 VideoQA와 VLEP의 성능입니다. NExT-QA, STAR, How2QA, TVQA 데이터셋은 VideoQA 데이터셋이고 VLEP는 비디오 내 사전을 예측하는 task입니다. 32->4는 Localizer가 32장 중에 4장의 키프레임을 선정하는 것을 의미하고 십자가 모양은 Backward를 통한 Localizer 학습을 하지 않은 모델입니다. 저자는 위 실험결과를 통해 세가지 결론을 내렸습니다. 하나는 temporal modeling의 중요성입니다. 시간적이해능력을 키우는 것이 저자는 QA 성능을 향상시키는데 큰 도움이 됐다고 말합니다. STAR 데이터셋에서 특히 BLIP-2에 비해 13퍼센트 가량 성능이 향상하며 좋은 성능을 보였다고 합니다. 두번째는 키프레임 선택의 효과입니다. 십자가 달린 성능이 Backward 학습을 하지 않고 키프레임 선정만 한 성능임에도 불구하고 기존의 BLIP-2 혹은 InternVideo보다 높은 성능을 보이며 효과적이었음을 강조하고 있습니다. 이를 통해 자연어 쿼리와 연관있는 비디오에 집중하는 것이 더 효율적인 동시에 성능 향상에도 도움을 주고 있음을 보이고 있습니다. 세번째는 self-refinemet의 성능입니다. pseudo-label을 생성하고 학습한 모델의 성능이 사용하지 않았을 때 대비 NExT-QA에서 0.4, STAR에서 2.2, TVQA에서 1.9의 성능 향상을 보이며 self-refinement의 효과를 검증했습니다.
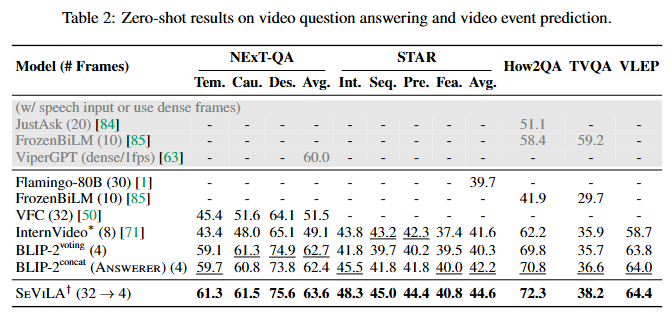
Table 2는 zero-shot 성능 비교입니다. 비디오 사전 학습 없이도 SeViLA는 기존 모델들보다 높은 성능을 보였습니다. 추가로 저자는 음성 및 추가적인 비디오 사전학습까지 수행한 FrozenBiLM 보다도 높은 성능을 보였음을 강조하며 SeViLA의 성능을 강조합니다. 저자는 추가로 균일하게 비디오를 샘플링하는 것보다 키프레임에 집중하는 것이 효율적이라는 것을 확인할 수 있다고 강조하고 있습니다.
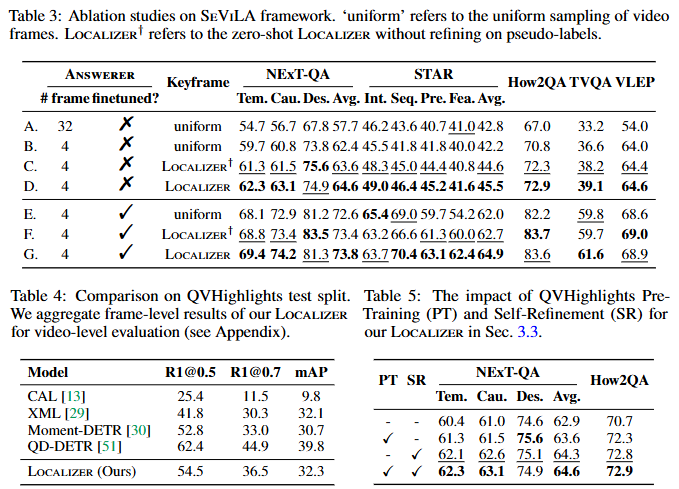
다음은 Ablation Study입니다. 균등하게 프레임을 사용하는 것보다 키프레임에 집중하는 것이 더 성능이 좋은 것을 확인할 수 있고, Backward를 통하 Localizer의 학습을 거치는 것이 더 성능인 높은 것을 Table3를 통해 확인할 수 있습니다. 저자는 특히 너무 dense한 프레임 선정보다도 오히려 sparse하게 특정 프레임을 선정하는 것이 더 효율적임을 강조합니다.

마지막으로 정성적 결과와 함께 리뷰 마치겠습니다. 저자의 키프레임 선정방식이 기존의 균등하게 비디오 프레임을 샘플링해서 QA를 진행하는 것보다 더 정답에 가까운 결과를 내는 것을 확인할 수 있습니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다.
제가 방법론을 이해하기로는 Flan-T5를 통해 먼저 Top-K 프레임(키프레임)을 선택하고, Backward 학습 단계에서 Answerer가 생성한 답변과 정답을 비교해 다시 한 번 키프레임을 추출하는 방식으로 이해를 했습니다. 그렇다면 처음 Flan-T5를 통해 선택된 프레임들도 중요한 프레임일 텐데, Answerer의 답변을 통해 최종적으로 키프레임으로 확정되지 못한 프레임들은 학습 과정에서 어떻게 활용되는지 궁금합니다.
감사합니다.
안녕하세요. 정의철 연구원님 좋은 댓글 감사합니다.
기본적으로 Localizer는 사전학습을 거친 모델을 활용하기에 어느정도의 localizing 능력을 보유하고 있다는 것이 저자의 주장이긴합니다. Answerer의 최종 답변에 영향을 주는 키프레임은 Localizer를 통해 이진분류되기 때문에 최종적으로 키프레임이 아니라고 분류된 프레임들은 최종답변을 통한 학습은 되지 않습니다. 하지만, self-refinement 과정에서 어느정도 학습되기에 전체적으로 localizing 능력이 향상된다고 볼 수 있을 것 같습니다.
감사합니다.
리뷰 잘 읽었습니다. 한 가지 궁금한 점이 있어 댓글 달아두겠습니다.
pseudo-label로 프레임별 키프레임 여부를 예측할 때, Answerer가 틀린 답을 내면 학습 노이즈가 커질 가능성이 있을 것 같다는 생각이 드는데.. 잘못된 pseudo-label이 Localizer를 학습할 때 성능 저하를 일으키지 않는지, 이를 완화하는 무언가는 없는지 궁금합니다
안녕하세요. 홍주영 연구원님 좋은 댓글 감사합니다.
저자도 localizer의 초기 성능의 중요성의 중요성을 언급하고 있긴합니다. 저자는 BLIP-2의 성능을 믿고 있기도하고(?) 추가적으로 localizer를 moment retrieval 데이터셋으로 사전학습하는 것으로 어느정도 신뢰성이 있는 localizer를 사용하는 것으로 그 문제를 완화하고 있습니다.
감사합니다.
안녕하세요 박성준 연구원님 질문을 달러 왔습니다.
소개해주신 논문에서 keyframe의 성격에 대해 궁금한데요, 혹시 어떤 영상을 keyframes으로 했는지 추가 설명이 논문이나 부가자료에 있었는지 궁금합니다.
그 외에 Table1에서 Temporal modeling이 중요성을 보이는 실험에서 키프레임 선택만 하여도 성능이 개선됨을 확인할 수 있었는데, 해당 결과는 키프레임 선별장치인 localizer를 학습하지 않은것으로 이해했습니다. 학습하지 않고 어떠한 기준으로 키프레임을 선택하게 되는지 알 수 있을까요?
아무쪼록 좋은 리뷰해주셔서 감사합니다
안녕하세요. 황유진 연구원님 좋은 댓글 감사합니다.
키프레임의 경우 저자는 단순하게 자연어 쿼리와의 유사도를 기반으로 추출하고 있습니다. 다만, BLIP-2 자체에도 이미지-텍스트 정합이 맞춰져 있다는 점, 그리고 Grounding 사전학습을 통해 Grounding의 성능을 개선시켰기 때문에 저자는 어느정도의 Grounding 능력을 갖고 있다는 것을 가정하고 있습니다.
Table 1에서의 Temporal Modeling을 하지 않았을 때와 했을 때의 차이를 비교하는 것은 Backward를 통해 학습을 했을 때와 학습하지 않았을 떄를 비교하는 것으로 이미 어느정도의 Grounding 능력을 갖추고 있는 localizer를 사용했다고 볼 수 있습니다. 기존 BLIP-2와의 차이점은 프레임들을 균등하게 샘플링하는 것과 sparse하게 키프레임을 샘플링하는 것의 차이를 의미합니다.
감사합니다.
성준님 안녕하세요. 좋은 리뷰 감사합니다.
Sevila라는 방법론의 이름만 들어봤었는데, 덕분에 자세한 내용을 잘 이해하게되었습니다.
마지막 실험 부분에서 표 3에 대한 설명으로 “너무 dense한 프레임 선정보다도 오히려 sparse하게 특정 프레임을 선정하는 것이 더 효율적”이라는 멘트를 남겨주셨는데, 표 3에서 A와 B를 비교했을때 얻을 수 있는 결과가 맞는것인가요?
보통은 QA를 비롯하여 어떤 task이든 프레임을 많이 쓸수록 연산량이 많아진다는 단점은 있지만 당연히 정보량이 늘어나니 벤치마크 성능 측면에선 장점을 불러오게 되는데, 이 프레임 수와 관련해 저자의 좀 더 깊은 분석이 있었는지 궁금합니다.
안녕하세요. 현우님 좋은 댓글 감사합니다.
네, 현우님이 댓글에 남겨주신 것처럼 Table 3에서 A와 B는 샘플링하는 프레임수가 32개와 4개로 sparse하게 샘플링했을 때의 성능이 더 좋은 것을 확인할 수 있습니다. 이를 통해 저자는 sparse하게 샘플링하는 것의 효율성을 강조하고 있습니다.
저자가 실험결과 말고는 깊은 분석은 없었습니다. dense한 샘플링이 오히려 모델을 방해(distract)했을 수 있다고만 설명하고 있네요. 제 개인적인 생각으로는 중요한 프레임에 집중하는 저자의 의도가 어느정도 반영된 결과라고 보이긴 합니다.
감사합니다.
안녕하세요 성준님, 좋은 리뷰 감사합니다.
비디오를 인코딩하는 것과 관련해서 제가 이해하기로는 비디오의 key frame을 몇 개 골라서, 즉 “중요한 이미지”들만 가지고 학습을 시키는 것 같습니다. 결국 이런 방식은 이미지 데이터와 구별되는 비디오의 시계열적인(?) 특성을 고려하지 못하는 방법이라고 생각이 듭니다. 그런데 experiments table 1에는 “시간적 이해능력이 QA 성능을 향상시키는 데 도움이 되었다”고 하는데, 이 부분을 봤을 땐 시간적 정보를 어떻게 활용했길래 위 같은 결론이 내려졌는지 궁금합니다.
안녕하세요 이재윤 연구원님 좋은 댓글 감사합니다.
좋은 지적 감사합니다. 재윤님이 언급하긴 것처럼 본 논문이 temporal transformer와 같은 명시적인 temporal 모델링을 하지 않는 것은 사실입니다. 이는 저자도 언급한 limitation 중에 하나입니다. 하지만, 그렇다고 시간적 이해능력이 없는 것은 아닙니다. 저자가 table 1에서 시간적 이해능력이 QA 성능을 향상시켰다는 것은 localizer의 grounding 및 reasoning 능력이 temporal 정보를 이해하고 있어야함을 전제하고 있기 때문에 나오는 해석입니다. 기존 QA 모델은 uniform sampling을 통해 비디오의 모든 프레임을 균등하게 샘플링하지만, SeViLA 모델은 그렇지 않습니다. 자연어 질문과 temporal 정보의 이해를 바탕으로 중요한 프레임을 선정하고 그 키프레임을 기반으로 QA를 진행합니다. 이때 keyframe은 시간적 정보를 고려하여 중요하다고 선정된 프레임이라는 것은 전제하고 있기에 저자는 시간적 이해능력이 QA 성능을 향상시켰다고 분석하고 있습니다.
감사합니다.