이번에 소개드릴 논문은 Video Depth Estimation 논문입니다. 근데 이제 고해상도에 빠른 추론 속도를 곁드린. 보통 Depth estimation은 단일 프레임에 대해서 입력으로 하는 경우가 대부분이고 종종 2~3프레임을 입력으로 현재 프레임의 Depth를 예측하는 방법론들도 있지만 이런 방법론들은 결국 한 프레임에 대한 깊이 추론을 잘하려고 하는 것 뿐이지 3개의 연속 프레임이 일관성 있고 연속적인 깊이를 추론하려고 하는 것은 아닙니다.
반대로 Video Depth Estimation은 말 그대로 정확한 깊이를 추정하는 것 뿐만 아니라 연속되는 프레임 별 깊이 맵이 서로 일관성있는 scale을 가져야한다는 점에서 기존의 단안 깊이 추정 방식들과는 더 어려운 task가 된다고 볼 수 있겠습니다.
Intro
위에서 소개드린 내용을 한번 더 정리하자면, video depth estimation의 핵심은 1) 비디오 시퀀스간에 연속적이면서 정확한 깊이 추정을 해야 한다는 것이며, 2) 고해상도와 선명한 특징들을 잘 보존해야하고 3) 마지막으로 실시간 추론성을 가질 수 있어야한다는 점입니다.
하지만 기존 연구들은 후처리 최적화 방식 또는 diffusion 모델 등을 활용하느라 실시간 추론성을 보장하기 어렵다는 문제점이 있습니다. 그렇다고 실시간성만 고려하면 또 너무 가벼운 모델을 활용해야 하느라 모델의 캐파 한계로 인해 부정확하거나 프레임 간의 관계성을 제대로 파악 못해 일관성 있는 깊이를 추론하지 못하는 문제가 발생하기도 합니다.
그래서 저자들은 기존의 Video Depth estimation SOTA 방법론 중 하나인 비디오 디퓨전 모델을 학습하기보다는 single-image 모델인 Depth Anythingv2를 활용하기로 결정하였습니다. 우선 DAv2는 단일 영상 깊이 추정 모델이니 저자들은 recurrent network를 추가해 개별 프레임 간의 스케일을 정합합니다. 이때 DAv2의 상대적인 깊이 맵은 스케일과 시프트 요소가 GT와 다르기 때문에, 각각의 개별 뎁스 맵에 대하여 올바른 스케일 팩터만 잘 결정해주면 이들간의 스케일을 정합할 수 있다는 것이 저자들의 주장이구요.
각 프레임별마다 서로 다른 scale을 정렬해주기 위해 recurrent model을 적용할 때 최종 output level에서 align맞추는 것보다는 중간 특징 단에서 이를 맞추는 것이 더 적은 연산량을 가질 수 있었다고 합니다.
또한 저자들은 저해상도와 고해상도를 따로 나누어 연산 후 이들 특징들을 융합하는 방식을 채택하는데, 각 픽셀별로 depth의 올바른 순서를 예측하는 것에 대하여 해상도가 높다고 크게 성능이 좋고 그런 것은 아니였다고 하네요. 오히려 해상도는 전경의 경계면을 명확하게 해줄때에만 필요한 것이기에 이둘을 나누어서 고려해야한다고 하며, 결과적으로 Depth의 성능 향상을 위해 저해상도 영상을 입력으로 하는 Large model과 선명한 깊이 영상을 위해 고해상도 이미지를 처리하는 가벼운 모델을 혼용하는 방식을 채택합니다.
이러한 노력?끝에 자신들의 방법론이 2K 해상도 비디오에 대해서 A100 기준 24FPS가 나올 수 있다고 하네요.
Method
그럼 본격적인 방법론에 대해서 소개드리겠습니다. 우선 저자들의 전반적인 framework은 다음과 같습니다.
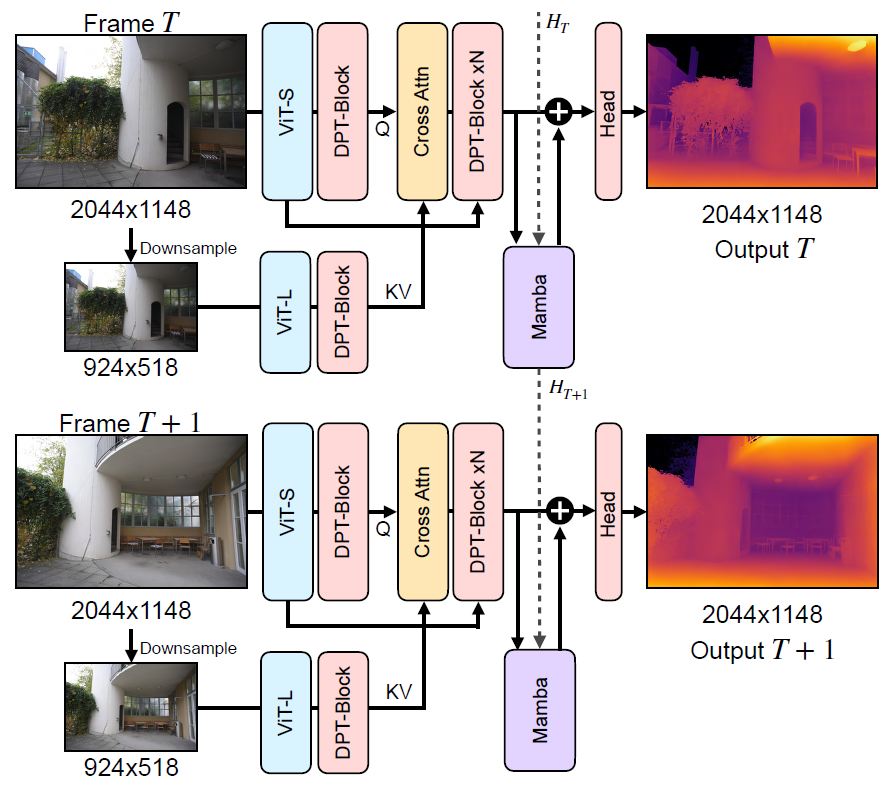
우선 고해상도 영상을 입력으로 하는 ViT-S 모델과 저해상도 이미지를 입력으로 하는 ViT-L모델 그리고 DPT block, Cross-Attention, Mamba 등 모듈이 따로 존재합니다. ViT와 DPT는 기존 DepthAnything model의 Encoder와 Decoder를 각각 의미하며, 저자들이 새롭게 추가한 모듈들은 Cross-Attention과 Mamba에 해당한다는 점 이해하고 넘어가면 좋을 듯 싶네요.
기존적으로 DAv2는 단안 영상 깊이 추정 방법론이기 때문에 연속적인 프레임에 대해서 개별적으로 Depth map을 추론하게 되면 앞뒤 프레임의 depth scale이 불일치하는 바람에 동일한 거리임에도 불구하고 depth 값이 미묘하게 다른 일명 Flicker 현상이 발생합니다. 그래서 저자들은 temporal 축에 대한 일관성을 맞추기 위해 집중하는 모습입니다.
우선 모델은 이전 프레임들의 정보와 현재 프레임만을 입력으로 받을 수 있으며, 저자들은 recurrent network를 통해 과거 프레임들의 정보가 담겨있는 hidden state를 현재 hidden state 계산 시 활용하는데 이때 Mamba 구조를 활용했다고 합니다. Mamba는 긴 sequence에 대하여 연관성 있는 정보를 선택적으로 잘 보존할 수 있는 구조라서 딱히 해당 구조를 따로 변경하는 것 없이 그대로 활용했다고 하네요.
이제 특징들별로 scale을 alignment해주어야 하는데 이때는 아까 intro에서 얘기했듯이 딱히 고해상도의 정보가 필요하지는 않습니다. 해상도가 높든 작든 대략적으로 누가 더 가깝고 먼지에 대해서는 모델이 잘 이해하기 때문에 저자들은 DPT Decoder에서 타고 나온 feature map의 해상도를 downsampling한다음에 mamba를 통해 scale alignment를 진행하였다고 합니다.
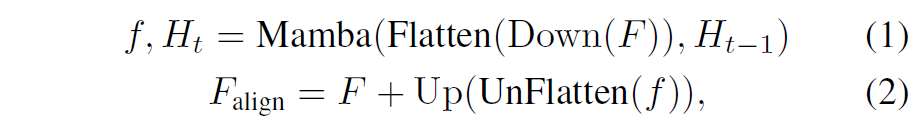
다운샘플링 비율은 논문에서 따로 언급이 안되는 것으로 보이는데 깃허브에서 확인해보니 1/10정도로 다운샘플링한 것으로 보입니다. Flatten연산은 H와 W축을 하나로 묶어버리는 연산이고 반대로 Unflatten은 HW를 H와 W로 구분짓는 축을 의미합니다.
이렇게 맘바를 통해 align을 맞춘 Feature map F_{align} 은 Depth head를 통과하여 최종 Depth map을 생성하게 됩니다. 저자들은 또한 temporal module을 처음 초기화할 때, single-image depth model의 성능을 최대한 유지할 수 있도록 초기화를 하고 싶었다고 합니다.
그래서 mamba를 DPT의 디코더 제일 마지막 convolution 이전에 위치하도록 하였는데, 이는 DAv2의 pretrained weight을 최대한 온전히 다 활용한 채 진짜 마지막으로 depth output을 예측하는 convolution head 하나 이전에 맘바를 설치하도록 한 것을 의도했다고 하네요. 그리고 Mamba module에 대해서는 zero-initialize를 함으로써 모델 학습시에 최대한 모델의 기존 결과값을 최대한 활용할 수 있도록 설정하였다고 합니다.
Hybrid Model for Efficiency at High-Resolution
일단 mamba 기반의 temporal module은 무시할만한 latency를 가지고 있을정도로 효율적이지만, 그냥 DAv2 모델 자체가 2K image를 처리하는데 있어 6FPS가 걸릴정도로 연산량을 많이 잡아먹고 있습니다. 저자들이 하고자 하는 것은 결국 고해상도 이미지에서 깊이를 추정함으로써 보다 정확하고, 선명하며, 또 추론 속도는 빠른 모델을 만들고 싶어하는 것인데, 현실적으로 모델의 크기와 해상도를 키우면서 동시에 실시간 추론성을 가지는 것은 매우 어려운 문제긴 합니다.
그래도 저자들은 이를 최대한 달성하기 위해서 속도와 정확도 관계를 제대로 파악하기 위해 DAv2의 Small, Base, Large 모델 각각에 대해서 실험하였다고 합니다. 뭐 뻔한 이야기지만, Large model이 가장 정확한 대신에 가장 느렸다는 것이고, 반대로 small 모델이 가장 작은 만큼 가장 빨랐지만 성능이 제일 아쉬웠다는 내용이 나옵니다.
그렇다면 어떻게 성능은 보장하면서 속도를 빠르게 할 수 있을까요? 저자들은 가벼운 모델과 무거운 모델을 동시에 활용하는 하이브리드 기반의 구조를 제안합니다. 우선 실시간성을 충분히 보장하기 위해 DAv2-Small model을 2K frame을 처리하는 main stream으로 설정하고, 저자들은 이를 FlashDepth-S라고 호칭합니다.
그리고 성능을 보장하기 위해 DAv2-L를 fine-tuning한 FlashDepth-L을 도입하였는데, 이는 518의 상대적으로 저해상도 이미지를 처리하여 정확한 특징들을 제공하는 역할을 하며, 해당 특징맵은 FlashDepth-S의 중간 특징들을 지도하는 역할을 수행하게 됩니다.
이러한 방식을 도입하게 된 계기는 저자들이 확인해보니 고해상도가 경계면을 명확하게 해주는 것은 맞는데, 이게 실제 수치적 성능 향상 관점에서는 크게 기여한다고 보기 어렵다고 합니다(경계면이 영상 전체 중에 차지하는 비율이 1%미만이기 때문). 실제로 2K 이미지랑 짧은 면이 518인 이미지에 대해 정확도를 평가해보니 그 성능 차이가 미미하였다고 하구요.
그래서 고해상도를 처리하는 부분은 상대적으로 가벼운 모델 S가 하고, 저해상도에서 좋은 특징을 추출할 모델은 무거운 모델 L이 처리하는 방식을 채택하는 것이죠.
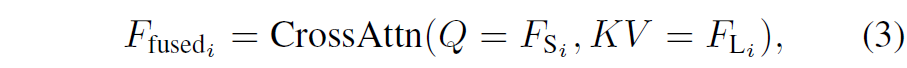
하이브리드 모델에서 추출한 특징들을 합치는 방식은 위의 수식3과 같이 CrossAttention으로 간단하게 구현이 되어있습니다.
다음은 이제 학습 과정에 대해서 간략하게 소게드리겠습니다. 저자들은 High resolution depth video data가 많지 않아 우선 FlashDepth-L과 FlashDepth-S를 각각 low resolution data로 학습을 먼저 진행하였다고 합니다. 그리고 나서 두번째 학습 단계에서 cross-attention을 통한 hybrid model을 학습시킬 때 작은 양의 고해상도 데이터셋을 활용하였다고 하네요.
첫번째 학습 단계에서는 DAv2가 학습하는 과정과 동일하게 518×518 random cropping을 통해서 학습을 진행하였고, 학습 때는 scale-shift invariant loss 대신 L1 loss를 사용했다고 합니다.
또한 메모리 이슈로 인해서 저자들은 입력 시퀀스를 고작 5프레임 정도만 가지고 학습을 진행하였는데, 이때 프레임의 간격을 augmentation을 통해 더 긴 프레임 간격을 주는 등 변화를 줌으로써 test 시 1000프레임 가량의 데이터가 입력으로 들어온다하더라도 좋은 성능을 보여줄 수 있었다하는데 이 부분은 상당히 흥미롭긴 하네요.
2번째 스테이지에서는 고해상도 이미지 1만6천장으로 학습을 했으며, 이때 FlashDepth-L은 freeze하고 FlashDepth-S만 fine-tuning을 진행하였다고 합니다. 당연히 FlashDepth-S는 2K 해상도를 입력으로 받으며, FlashDepth-L은 짧은 쪽 길이가 518의 low resolution 이미지를 입력으로 받게 됩니다.
Experiments
그럼 실험 결과 살펴보고 리뷰 마치겠습니다.
우선 비교 방법론들에 대해서 간략하게 소개드리면 크게 DepthCrafter, Video Depth Anything, CUT3R, 그리고 그냥 기존 DAv2 모델 이렇게를 비교 방법론으로 선정했다고 합니다.
DepthCrafter는 video diffusion model을 파인튜닝한 방법론으로 좋은 일반화 성능을 보여준다고 하고, Video Depth Anything 모델은 DAv2에 temporal module을 추가해서 학습시킨 방법론으로 저자들의 방법론과 결이 비슷한 방법론으로 보이네요. CUT3R은 스트리밍 비디오로부터 pointmap을 추정하는 방법론으로 모델 구조는 transformer 기반의 recurrent model 구조를 택하고 있습니다.
저자의 평가 방식은 기존의 depth estimation 방법론들이 자주 활용하는 Abs_rel과 Delta 값을 리포팅하며, 재밌는 점은 F1 score를 함께 리포팅을하게 됩니다. 이 F1 score는 GT depth의 바운더리 부분들에 일정 임계치를 설정해서 이를 넘긴 경우 1 아니면 0의 이진 마스크를 계산하게 되고, 마찬가지로 예측된 depth map 역시 이진 마스크를 계산하여 GT와 동일하게 1 또는 0 값을 뱉었는지를 평가한다고 합니다.
이 평가 방식을 도입하는 이유는 저자들의 방법론이 전경과 배경을 선명하게 구분하는 depth 추정을 하였는지를 판단하기 위함이라고 하며, 기존의 abs_rel과 delta와 같은 평가 방식은 경계면이 전체 영역의 1%수준만 유지하고 있어 해당 평가 방식들로는 유의미한지 평가하기가 어려워 F1 score 방식을 도입했다고 합니다.
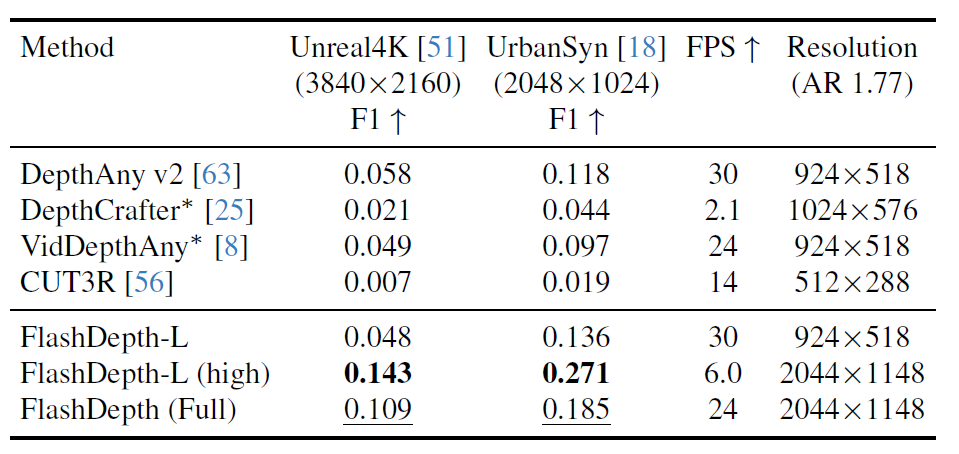
그래서 위에 표가 경계면을 얼만큼 잘 구분해서 예측했는지를 나타내는 F1 score 평가 방식이며, 결론부터 말씀드리면 저자들의 방법론이 다른 방법론들과 비교해서 훨씬 경계면을 잘 예측하는 모습입니다. 보다 정확하게는 FlashDepth-L 모델의 경우 저해상도를 사용하게 될 경우 기존 방법론들과 비슷한 F1 score를 보여주게 되지만, 고해상도로 넘어가게 되면 훨씬 높은 F1 score를 계산한다는 점입니다.
이전 연구들은 다 저해상도로 평가하고 자기들만 고해상도로 평가하는 것은 비겁하지않나?라고 생각이 드실 수 있지만 저자들이 제안하는 흐름은 이전 연구들은 Diffusion model과 같이 연산량을 너무 많이 차지하여 고해상도 이미지를 도저히 사용할 수 없는 방법론이지만 자신들의 방법론은 고해상도 이미지를 입력으로 상대적으로 빠르고 효율적인 추론이 가능하기 때문에 고해상도 이미지를 입력으로 하게 됩니다.
물론 FlashDepth-L는 ViT Large 모델을 통짜로 활용하는 것이라 해당 모델에 고해상도 이미지를 넣게 되면 A100 기준 6FPS가 걸리는 등 실시간 추론 시간이 상당히 떨어지게 됩니다. 하지만 저자들이 최종적으로 제안하는 하이브리드 모델 FlashDepth의 경우에는 24FPS를 유지하면서도 고해상도 이미지를 입력으로 할 수 있어 (FlashDepth-L의 고해상도 입력 결과보다는 아쉽지만) 다른 방법론들과 비교해서 더 높은 F1 score를 계산할 수 있게 됩니다.
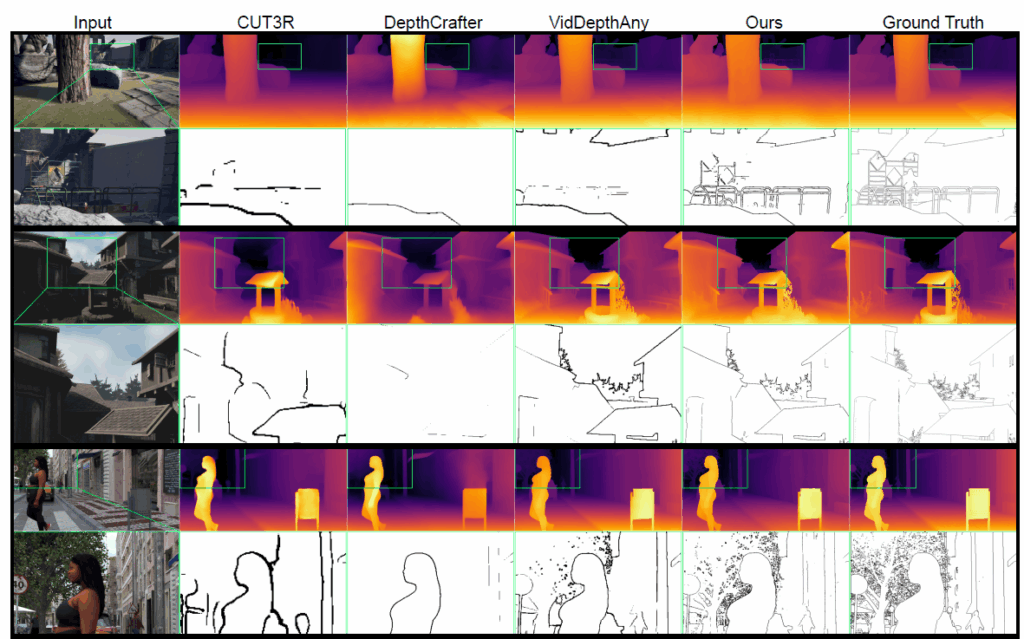
실제 정성적 결과를 살펴보더라도, 저자들의 방법론이 훨씬 더 멀리 있는 배경, 또는 객체의 세세한 부분들까지 모두 포착해서 depth를 예측하는 모습입니다.
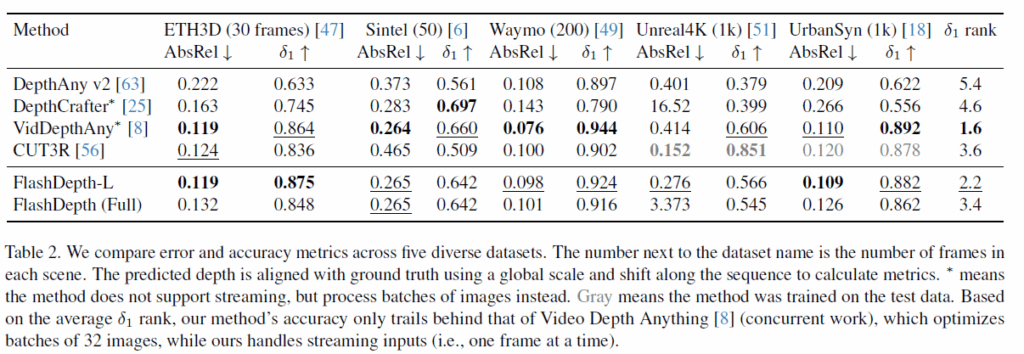
다음은 깊이 정확도에 관련된 실험인데, 솔직히 말해서 이 부분에서 아쉬운 점은 저자들이 제안하는 방법론보다 다른 방법론들(DepthCrafter, VidDepthAny)가 특정 데이터셋에서 더 좋은 경우가 종종 발생합니다. 그런 관점에서 아쉽게 느껴지긴 하는데, 저자들이 주장하는 바로는 VideoDepthAnything model의 경우에는 32장의 프레임 이미지를 한번에 입력으로 받아서 동작하는 방법론이라고 합니다. 즉 실시간으로 이미지가 들어온다는 real-time application 관점에서는 무언가 적용하게 현실적으로 어려운 방법론이라는 것을 전달하고 싶은 듯 합니다.
그리고 CUT3R의 경우에는 33개의 데이터셋으로 학습을 했기 때문에 학습 데이터 총량에서 자신들보다 많음에도 불구하고 자신들의 FlashDepth(Full)이 전체 데이터셋 평균 기준 델타값이 더 높다라는 것을 어필합니다.
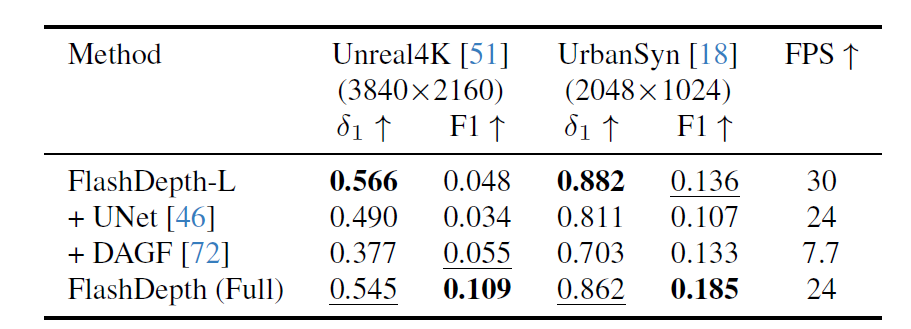
다음은 ablation study에 대한 것인데, 저자들이 FlashDepth-L을 학습시킨다음에 이를 freeze한 다음 Unet 구조의 네트워크를 추가로 붙여서 해당 네트워크를 fine-tuning시켜 고해상도 이미지를 처리하는 방식을 적용해보았다고 합니다. 결과적으로 FlashDepth (Full)보다 delta 값이나 F1 score 모두 좋지 않은 모습을 보여주는데 그 이유로 depth head를 pretrained weight을 온전히 사용하지 못하고 retrain을 해야만 하는 구조로 설계되다보니 retrain하기에는 데이터가 충분하지 않아 선명하지도 못하고 정확도도 떨어지는 결과가 도출될 수 밖에 없었다고 합니다.
그리고 DAGF는 off-the-shelf super resolution network로 어텐션 기반으로 영상을 필터링하는 기법이라고 합니다. 이를 통해 depth를 고해상도로 업샘플링해보았지만 이 역시도 추론 속도만 크게 잡아 먹을 뿐 성능이 좋지 못했다고 하네요. 이는 해당 모델이 Out of data distribution에서 강인한 모습을 못 보여주었기 때문이라고 저자는 주장합니다.
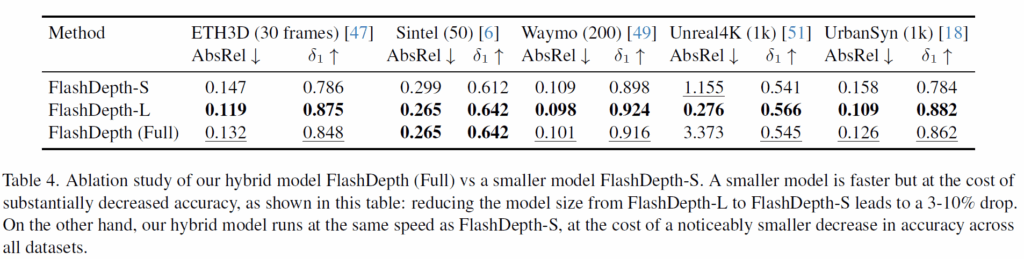
다음은 저자들의 FlashDepth-S, FlashDepth-L 그리고 이 둘의 하이브리드 버전인 FlashDepth (Full)에 대한 각 데이터셋 성능 평가 입니다. 결과론적으로 말씀드리면 당연히 FlashDepth-L이 가장 좋은 성능을 보여줄 것입니다. 하지만 추론 속도가 그만큼 상당히 크게 감소하는 것이며, 결과론적으로는 하이브리드 구조를 채택함으로써 정확도와 효율성의 tradeoff를 잘 이겨낼 수 있었다고 저자들은 주장합니다(즉 small보다는 성능이 좋으면서 Large보다는 빠르게 동작할 수 있는?).
결론
뭔가 방법론 자체가 그렇게 복잡하지도 않고, 맘바도 그냥 가져다가 사용하는 것 같고, fusion하는 방식도 단순히 cross-attention을 활용하는 것이고해서 novelty가 막 그렇게 대단하다고 느껴지지는 않았습니다. 다만 depth estimation 방법론들이 워낙 단일 이미지에서 좋은 성능을 보여준다 하더라도 비디오 레벨로 확장돼서 일관성 있는 깊이를 추론하기에는 어렵다라는 사람들의 인식이 모여져서 그런지 해당 연구의 시도 자체를 가치있게 봐준 것이 아닐까라는 생각이 드네요.
안녕하세요, 정민님. 좋은 논문 리뷰 공유 감사드립니다.
영상이라는 이점을 활용해 depth에 대한 유익한 정보를 얻는 과정이 인상 깊었습니다.
논문 리뷰를 보면서 프레임 간 이미지를 활용하는 것으로 보였는데, 만약 카메라가 불규칙적으로 움직이거나 속도가 가변할 경우 성능이 떨어지는지 궁금증이 생겼습니다. 만약 그렇다면 이러한 상황에서 해당 논문을 어떻게 활용할 수 있을지, 또 가변 문제를 해결하기 위해 객체 감지나 특징점 기반 정합을 추가하면 보완할 수 있을지도 궁금합니다.
다시 한번 좋은 논문 리뷰 감사드립니다. 😎
안녕하세요. 질문에 대해 답을 드리자면,
저자들이 논문에서 카메라가 불규칙적으로 움직이거나 속도가 갑자기 바뀌는 경우에 depth의 성능이 어떻게 되는지에 대해 실험하는 부분은 없어서 정확하게 말씀드릴 수는 없습니다만 제 생각을 말씀드리면 그러한 상황에서 깊이 추정 성능이 떨어질 것 같긴 합니다. 하지만 결국 중요한 것은 그 카메라의 움직임을 학습 때 보았느냐가 가장 중요할 것 같아요.
즉, 갑자기 카메라가 빠르게 움직이거나 불규칙하게 움직이더라도 그러한 움직임을 학습 때 보았다면 충분히 좋은 성능을 유지할 수 있을 것이라고 생각하고, 학습 때 전혀 보지 못한 움직임이면 당연히 성능이 떨어지겠죠.
그리고 그런 불규칙한 상황에 대해서 최대한 성능 하락을 막기 위한 방법으로 말씀해주신 객체 감지 부분은 제가 댓글만으로는 객체 감지 결과물을 어떻게 활용한다는 것인지 기현님의 의도가 감이 안잡혀서 뭐라 말씀은 못드리겠고 정합 부분도 마찬가지로 정합 자체에는 큰 의미는 없을 것 같아요.
다만 정합을 하기 위해서는 두 연속된 프레임 사이의 기하학적 관계를 잘 알아야만 하는데, 이 기하학적 관계를 안다라는 것은 어찌보면 두 프레임 사이의 카메라 좌표계간 변환 행렬을 구할 수 있다는 것이라서 이를 추론 단계에서 같이 활용한다면 이러한 갑작스러운 움직임 속에서도 깊이 추정의 성능 하락을 막을 수 있을 것이라고 저는 생각합니다.
물론 전반적인 scene level에서의 뎁스 성능이 개선될 것이라고 보고 실제 카메라의 움직임과 별개로 피사체의 움직임도 급격하게 변할 수가 있는데 그럴 때 해당 객체에 대한 깊이 추정 성능은 앞서 언급한 카메라 포즈 정보 등으로는 개선이 안될 수 있을 것 같아요. 피사체가 급격하게 빨라지는 등의 문제는 카메라의 움직임과 달리 두 프레임 사이의 피사체에 해당하는 대응점들을 통해 얼만큼 움직였는지에 대한 정보를 계산해서 모델에게 추가정보로 주면 또 해결해볼 수도 있을 것 같은데 이렇게 여러 정보들을 추론하고 이를 깊이 추정 할 때 활용하게 되면 깊이 추론 하는데에만 많은 연산량이 들어가고 모델의 구조도 더 복잡해질 것 같아요. 즉 말씀해주시는 문제점은 해결해야될 문제점이지만 쉽지 않은 문제다 라고 정리해볼 수 있겠네요.
감사합니다.