안녕하세요 이번 주도 지난 번에 이어서 토큰 푸르닝 관련 논문을 소개해드리려고 합니다. 생각보다 토큰 프루닝이라는 친구가 단순한듯 어렵게 느껴지는 친구 같습니다. 지 지난 주에 리뷰했던 SViT라는 논문이 어떤 dense 한 태스크를 위한 전체적인 토큰 프루닝의 프레임 워크를 제안하는 느낌이었다면 이번에 리뷰할 논문은 조금 더 구체적으로 dense한 태스크에서 연산량을 효과적으로 줄이기 위해서 중요한 토큰들을 어떻게 선별해야할지 즉 토큰 선택에 좀 더 집중한 논문이라고 보시면 될 것 같습니다. 해당 논문은 CVPR workshop에 2024년에 게재된 퀄컴에서 연구한 논문이고 SViT 와는 달리 attention map을 기반으로 토큰을 drop할지 keep 할지를 결정 한다는 점에서 조금 차별점이 있습니다. 그래서 저는 이 부분이 현재 진행하는 연구와 어떻게 연결짓고 또 어떻게 아이디어를 확장해 나아갈 수 있을까를 고민하면서 읽게 되었습니다.
바로 리뷰 들어가도록 하겠습니다.
introduction
이번 논문에서는 ToSA(Token Selective Attention) 라는 새로운 토큰 선택 기법을 제안합니다. 어떤 토큰은 어텐션 연산에 참여해야 하고, 어떤 토큰은 굳이 참여하지 않아도 되니 그냥 다음 레이어로 건너뛰어도 된다라는 방식으로 SViT의 selective module의 컨셉과 비슷하지만 방식에 차이가 있다고 보시면 될 것 같습니다. 핵심은 현재 레이어의 어텐션 맵을 보고 다음 레이어의 어텐션 맵을 예측한 뒤, 그 정보를 토대로 중요한 토큰만 남기는 방식입니다. 나머지 토큰은 bypass 시켰다가, 어텐션을 거친 토큰과 다시 합쳐 전체 집합을 유지하는 구조라고 이해하시면 좋을 것 같습니다.즉, 중요한 토큰만 뽑아서 어텐션에 참여시키고, 나머지는 그대로 통과시킨 뒤 다시 합치는 방식이라고 보시면 좋을 것 같습니다.
모두가 아시다시피 self-attention의 가장 큰 문제 중 하나가 토큰 수에 따라 계산량과 메모리 사용량이 토큰 수 제곱으로 증가한다는 점인데 이렇게 토큰 수를 줄이는 것만으로도 백본에서의 연산량을 크게 줄일 수 있고, 동시에 dense한 태스크에 대해서는 bypass를 통해 모든 이미지 패치의 정보 자체는 보존되기 때문에 dense prediction 태스크에도 적용할 수 있다는 장점이 있습니다.
그리고 이전 연구들을 보면 직접적인 프루닝은 아니지만 연산량을 효율적으로 줄이고자 했던 연구자들이 기존에 시도했던 방법들을 잠깐 보면, 예를 들어 Swin Transformer 같은 경우는 로컬 윈도우 단위로 어텐션을 제한해서 헤당 윈도우 내에서만 셀프 어텐션을 적용하여 계산량을 줄이거나 또 어떤 연구들은 먼저 몇 개의 convolution)레이어를 적용한 후 입력 이미지를 상당히 다운샘플링한 버전에만 셀프 어텐션을 수행하여 계산 비용을 줄이는 방법도 있고 이외에도 많은 변형들이 제안이 되었습니다.
위와 같이 효과적인 ViT 변형들이 많이 제안되었음에도 불구하고 SViT나 이번에 리뷰하는 ToSA와 같은 방법론은 바닐라 ViT에서 연산량을 줄이고자 고집합니다.
그 이유는 아무래도 pure한 ViT 자체가 구조가 직관적이고 구현이 쉽고, 무엇보다 CLIP, DINO v2-3와 같은 강력한 사전학습 체크포인트들이 많이 존재하기 때문입니다. 그래서 다양한 태스크로의 확장도 가능할 수 있다는 장점이 있습니다. 그리고 대규모 데이터에서 잘 확장된다라는 이유도 저자가 언급해주었는데, 개인적으로 생각했을 때에는 이 이유가 데이터가 적을 때는 inductive bias가 많은 모델이 유리하지만, 데이터가 커질수록오히려 bias가 적고 유연한 vanilla ViT가 더 잘 학습되고 더 높은 성능을 내기 때문이지 않나 싶습니다. 개인적으로는 이게 장점이자 단점일 수 도 있겠다 라는 생각이 들었습니다. 반대로 데이터가 적은 경우엔는 inductive bias를 갖는 ViT 변형들을 사용하는 것이 더 좋다는 의미를 갖게 되는 것이 아닐까 싶습니다.
위와 같은 이유 때문에 연구자들의 초점은 결국 바닐라 ViT의 구조는 유지하면서도 어떻게 효율성을 높일 것인가로 푸루닝을 연구를 하게되는데, 지금까지의 일반적인 접근은 토큰 수 자체를 줄이는 것이었습니다. 문제는 이런 방식이 대부분 classification태스크에만 적합하다는 점입니다. 토큰을 완전히 버리거나 합쳐버리면 픽셀/패치 단위의 fine한 정보가 사라지기 때문에, dense prediction 태스크에는 이를 그대로 적용하기 어렵다는 문제가 있습니다.
그래서 이 지점에서 위와 같은 문제를 해결하기 위해 ToSA라는 방법론을 저자는 제안을 하게 되고 토큰을 버리는 게 아니라, 필요한 순간에만 어텐션을 거치게 하고 다시 전체 집합으로 복원한다는 아이디어 덕분에 SViT나ToSA라는 방법론은 분류뿐만 아니라 dense task까지 확장할 수 있다는 점이 어떻게 보면 기존 프루닝 연구와의 차이점이라고 보실 수 있습니다.
바로 메서드 설명하도록 하겠습니다.
Method
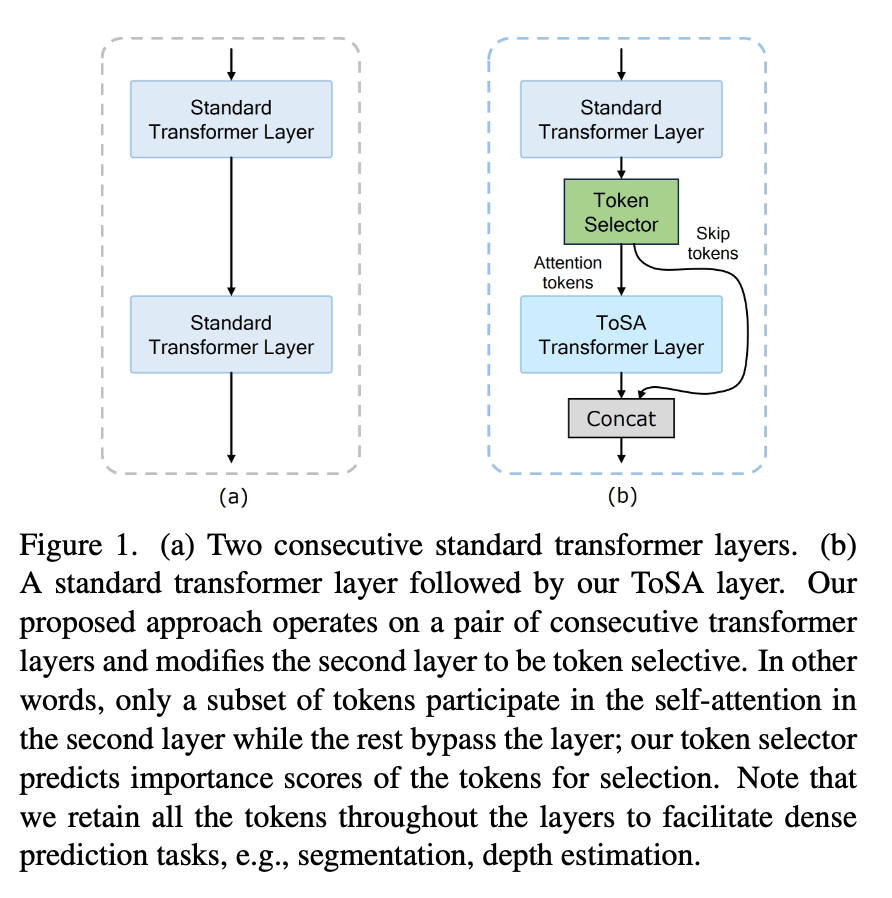
위 그림은 ViT의 2개의 레이어만 간단하게 도식화해서 들고온 그림입니다.
(a)가 기본적인 트랜스포머 레이러라면 (b)는 ToSA를 적용한 레이어라고 보시면 좋을 것 같습니다. 조금 간단하게 핵심을 요약하자면 ToSA transformation later는 연속된 두 개의 트랜스포머 레이어에 적용되고, 이 중 두 번째 기존 스탠다드 레이어가 토큰 선택적 레이어로 변환된다고 보시면 됩니다. 첫 번째 레이어에서 얻은 멀티헤드 어텐션 맵을 입력으로 토큰 셀렉터에게 넘겨주면 토큰 셀렉터는 다음 레이어가 생성할 어텐션 맵을 예측을 하도록하고, 이에 따라 각 토큰의 중요도 점수를 생성하는 방식입니다. 그리고 이 중요도 점수를 기반으로 상위 토큰(top-k)들만 다음 레이어의 셀프 어텐션 연산에 참여하게 됩니다. 이때 상위 토큰들만 셀프어텐션 연산에 참여하는 이 레이어를 ToSA 트랜스포머 레이어라고 보시면 됩니다. 즉, ToSA 트랜스포머 레이어는 기존의 두 번째 스탠다드 트랜스포머 레이어를 대체하게 되는 것입니다. 나머지 토큰들은 단순히 ToSA 레이어를 건너뛰고, 어텐션에 참여한 토큰들과 다시 결합되어 전체 토큰 집합을 복원하게 됩니다.
앞서 주저리 주저리 말쓴드린 과정은 항상 연속된 두 개의 레이어 쌍에서 일어나게됩니다. 첫 번째 레이어는 스탠다드 트랜스포머 레이어, 두 번째 레이어는 ToSA 레이어로 대체되는 구조입니다.
여기서 중요한 점은 이 셀렉터는 미리 학습을 시켜놓는 친구라는 것입니다. end to end가 아니라 미리 pretrained 된 가중치를 가지고 이 토큰 셀렉터가 다음레이어가 생성해 낼 것 같은 어텐션 맵을 잘 예측해내도록 미리 학습을 시켜놓게 됩니다. 즉 pretrained된 다음 레이어의 어텐션 맵이 supervision이 되서 학습이 이루어지게 됩니다. 즉, 사전 학습된 ViT 모델이 실제로 생성한 어텐션 맵을 GT로 삼고, KL Divergence 손실을 통해 예측된 어텐션 맵과 정답 어텐션 맵의 차이를 줄이도록 학습됩니다. 이때 백본 ViT는 freeze 시키고 오직 셀렉터만 학습합니다. 덕분에 추가적인 데이터가 필요 없고 기존의 pretrained 모델을 그대로 재활용할 수 있습니다.

이후에 두번째 standard layer들을 ToSA 레이어에서는 선택된 토큰만 self-attention을 수행하고 어텐션을 수행한 토큰과 skip된 토큰을 합쳐서 다시 standard 레이어에 전달하는 방식으로 위 그림같은 흐름으로 두번 째 학습이 이루어지고 이때 에는 셀렉터만 freeze해서 전체 네트워크를 학습시키게 됩니다.
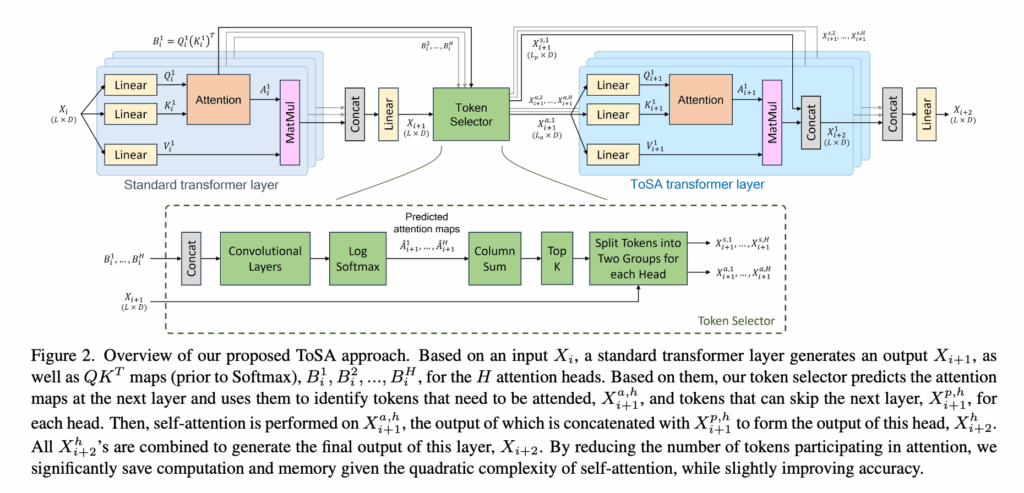
좀더 세부적으로 설명을드리면 일단 이전 레이어의 어텐션 맵이 토큰 셀렉터의 input으로 들어간다고 했습니다. 해당 어텐션 맵은 바로 앞의 standard 레이어에서 나온 softmax를 타고 나오지 않은 QK^T를 의미하고 헤드의 개수만큼 나오게 됩니다 이때 토큰 셀렉터는 다음 레이어의 헤드별 어텐션 맵(LxL)을 예측하고 각 헤드의 예측 어텐션 맵에 대해서 key축(열 방향)으로 합을 계산합니다.(다른 해당 토큰이 다른 토큰들에게 얼마나 주목받는지)해당 토큰이 다른 모든 query 토큰에게 받은 attention 총합이 결국에 attention score라고 보시면 됩니다. 그 다음 정해진 비율 만큼의 상위 K개의 토큰을 헤드별로 score기준으로 선택한후 토큰들을 입력 받아 어텐션에 참여해야 할 토큰(X^{a,h}_{i+1}) 과 다음 레이어를 건너뛸 수 있는 토큰(X^{p,h}_{i+1}) 을 각 헤드별로 마스킹을 적용한 후 ToSA transformer layer로 넘기게 되는 방식으로 동작합니다.
사실 ToSA 레이어와 standard Transformer layer는 크게 다를 것 이 없이 단지 모든 토큰을 받아서 처리하는지, 선별된 중요한 토큰만 받아서 그에 맞게 처리하는지의 차이라고 보시면 됩니다.
Experiments
해당 논문이 단축 논문이기 때문에 저자가 제안한 방법의 효율성을 보여주기 위한 대표적인 결과들만을 제시 했기 때문에 리뷰로 다룰 실험이 몇개 없습니다.. 자세한 결과는 full 버전의 논문에 포함될 예정이라고는하나 아직 full 버전을 찾지 못하였습니다..
위 점을 감안하고 읽어주셨으면 감사하겠습니다.
일단 논문에서는 두 가지 주요 태스크를 대상으로 ToSA의 성능을 평가했습니다.
- imageNet-1K 분류: 가장 표준적인 벤치마크에서 정확도와 효율성을 동시에 검증.
- Monocular Depth Estimation: NYU Depth V2, KITTI 데이터셋에서 NeWCRFs를 기반으로, ToSA를 백본으로 넣었을 때 성능 비교.
일단 논문에서 다룬 것은 백본으로 제일 작은 DeiT-Tiny (12층 ViT)만을 사용해서 평가하였습니다. ToSA는 2, 4, 6, 8, 10번째 레이어에 적용했고, 각 ToSA 레이어에서는 토큰의 상위 80%만 self-attention에 참여하도록 설정했다고 보시면 될 것 같습니다.
ImageNet 평가
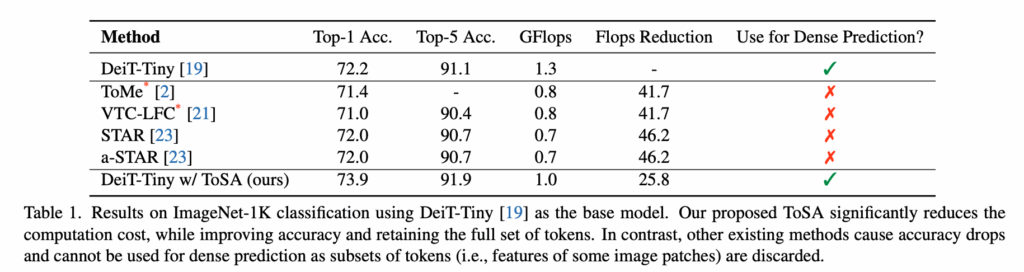
표 1을 보면 T 기존 DeiT-Tiny 같은 경우에는 Top-1 정확도 72.2 GFLOPs 1.3인 것에 반해 ToSA 적용하면 Top-1 정확도 73.9, GFLOPs 1.0로 약 25% 연산량을 줄이면서도 정확도는 오히려 1.7% 향상되는 것을 확인할 수 있습니다. 반면 기존의 ToMe, VTC-LFC, STAR 같은 다른 경량화 기법들은 FLOPs는 더 많이 줄였지만 정확도가 하락했고 무엇보다 토큰을 실제로 버려버리거나 병합하기 때문에 픽셀 단위 정보가 사라지기 때문에 특히나 dense prediction에는 쓸 수 없는 구조적 한계가 있습니다.
그리고 신기했던 부분은 정확도가 소폭 올라갔다는 부분인데, 이건 아마도 불필요한 토큰들이 노이즈로 작용하는 걸 걸러낸 효과가 아닐까 싶습니다. 약간 regularization처럼 모델이 더 중요한 정보에 집중할 수 있게 해주는 셈이지 않나 싶습니다.

개인적으로 재미있던 봤던 부분은 토큰 시각화 결과Fig 4인데 ToSA는 주로 주요 객체(고양이)의 패치를 꾸준히 선택하는 반면, 배경 패치는 레이어마다 다르게 선택합니다. 예를 들어 2번째 레이어에서는 오른쪽 배경 위주로, 6번째 레이어에서는 약간 왼쪽 배경 위주로, 10번째 레이어에서는 상단 배경을 선택하는 식으로 일관성이 없는 모습을 보입니다. 객체에 대한 토큰은 일관되게 보존하면서도 다양한 위치의 배경 정보를 교차적으로 활용한다는 걸 보여주는데 이말은 결국에 기존에 토큰을 무작정 줄이는 프루닝 방식과는 약간 차별화 된다는 것을 보이는 것 같습니다.
일반적인 pruning 기법은 전체 토큰 수를 무작정 줄인다는 느낌인데, ToSA는 객체 중심 토큰은 계속 유지 하면서도 배경 토큰은 레이어마다 다른 부분을 선택함으로써 부가적인 정보는 필요에 따라 상황에 따라 선택적으로 활용하는 느낌입니다.
Monocular Depth Estimation
논문에서 Intro에서 계속해서 언급한 ToSA의 진짜 장점인 dense task 적용 가능성인데, 이를 depth estimation으로 보여줍니다.
full 버전에는 object detection 이나 segmentation 같은 태스크에도 적용해서 평가했을 것 같은데 여기서는 다루지 않아서 아쉽긴합니다.
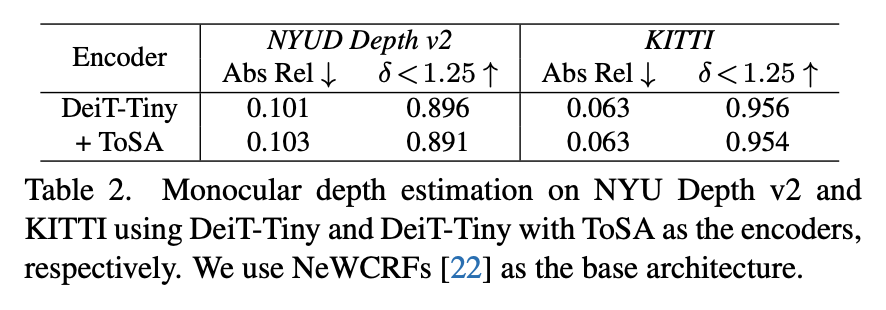
위 표를 보시면 토큰 수를 줄였는데도 깊이 추정 정확도는 그대로 비슷하게 유지된다는 게 포인트인데. NYU Depth V2에서 DeiT-Tiny와 ToSA 적용 모델의 성능 차이는 엄청 하락하지 않았고거의 비슷한 수준을 보이면서도, KITTI에서도 거의 비슷한 수치를 보이는 것을 확인할 수 있습니다.
Conclusion
저는 pretrained된 ViT의 attention map 자체를 supervision으로써 활용했다는 점은 기존의 pruning 방식들이 단순히 토큰 자체의 값이나 CLS 토큰의 활용과는 달리 실제 모델 내부의 동작(어텐션 맵)을 학습 신호로 먼저 학습을 시키고 이를 활용한다는 점에서 직관적이고 나름 좋게 다가온 것 같습니다.
물론 셀렉터 학습 과정이 pretrained 모델의 어텐션 맵에 의존한다는 점에서 학습 효율이나 일반화 성능에 대한 의문은 남습니다. 해당 논문을 읽고 이 아이디어를 어떻게 바꿔서 적용할 수 있을지에 대한 고민은 하는 중인데 아이디어 확장이 잘 되질 않는 것 같습니다. 이만 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요 우현님 리뷰 감사합니다.
궁금한점이 있는데 ImageNet에서의 연산량 감소하는 부분에서 사전에 토큰 셀렉터가 학습되는 과정까지 포함된 수치인지 궁금합니다. 그리고 figure4는 흠 뭔가 신기하기는 한데 해당 모델구조의 어떤 부분이 저런 결과를 만들었을지 신기하네요.. 배경 부분을 각 레이어가 다르게 선택하는 것이 우연인지 모델의 설계에 부가적으로 일어난 효과인지에 대한 생각이 궁금합니다.
감사합니다.
안녕하세요 인택님 댓글 감사합니다.
Q1. ImageNet에서의 연산량 감소하는 부분에서 사전에 토큰 셀렉터가 학습되는 과정까지 포함된 수치인지 궁금합니다.
일단 기본적으로 연산량 측정이나 FPS측정 은 추론시에 합니다. 토큰 셀렉터가 학습되는 과정까지는 포함해서 연산량을 측정하지는 않았을 것 같습니다.
Q2. 배경 부분을 각 레이어가 다르게 선택하는 것이 우연인지 모델의 설계에 부가적으로 일어난 효과인지에 대한 생각
일단 우연은 아니라고 생각합니다. attention 기반 선택이라는 구조적 특징에서 비롯된 결과라고 보는 게 더 맞다고 생각이 듭니다. 왜냐하면 대부분 실험에서 일관되게 객체 중심 토큰은 유지, 배경은 교차적으로 선택이라는 패턴이 반복적으로 관찰되었는데 이걸 우연이라고 보기는 어려울 것 같습니다.
감사합니다.
즉, 모델 설계에 내재된 토큰 중요도 산정 로직의 부산물이자, 결과적으로는 객체/배경 균형을 맞추는 유용한 효과로 작동했다고 볼 수 있습니다.
안녕하세요 우현님 좋은 리뷰 감사합니다.
Method부분중에 사전 학습된 ViT 모델이 실제로 생성한 어텐션 맵을 GT로 삼고, KL Divergence 손실을 통해 줄인다고 제가 이해를 했는데 KL을 쓴다는거는 attention 맵이 가지고있는 분포를 학습해야할건데
잘 와닿지가 않아서 추가적인 설명 부탁드립니다.
감사합니다
안녕하세요 우진님 댓글 감사합니다.
일단 attention map은 사실상 확률 분포입니다. self-attention에서 softmax(쿼리 키 내적) 연산을 거치기 때문에, 각 query 토큰이 key 토큰들에 얼마나 집중하는지를 나타내는 값들의 합은 1이 됩니다.
그래서 다음 레이어가 만들어낼 실제 attention map을 GT 분포로 놓고, 토큰 셀렉터가 예측한 attention map을 예측 분포로 놓으면 이 둘의 분포 간 차이를 측정하는 KL Divergence로 Loss를 계산하고 이 둘의 차이를 줄이는 방식으로 학습이 된다고 보시면 됩니다.
감사합니다.
안녕하세요 우현님 리뷰 감사합니다.
Dense task 적용이 가능하다는 것은 segmentation, detection 같은 태스크에도 적용이 가능하다는 뜻인가요? Bypass하는거랑은 연관이 없나.. 싶은데 지식이 없어서 좀 붕뜬 질문이어도 양해 부탁드립니다,,
또 각 ToSA 레이어에서는 토큰의 상위 80%만 self-attention에 참여하도록 설정했다고 하는데 이 수치에 대한 ablation이나 80%로 설정된 이유가 있을까요?
안녕하세요 영규님 댓글 감사합니다.
Dense task 적용이 가능하다는 것은 segmentation, detection 같은 태스크에도 적용이 가능하다는 뜻으로 이해하면 좋을 것 같습니다. 정확히는 object detection이 Dense task인지는 논문마다 정의하는게 달라서 확답은 못드리겠으나 토큰 프루닝에서는 object detection도 Dense task로 취급하는 것 같습니다. 이제 classification과 다른게 dense task에서는 ByPass하는 것이랑 연관이 좀 깊어질 수 있다라고 볼 수 있는게 최종 예측 헤드를 보시면 classification 같은 경우에는 cls토큰 하나만을 가지고 예측을 하게되는데 segmentation 같은 경우에는 픽셀단위로 뭔가를 예측하거나 ,object detection 같은 경우도 Local 단위로 뭔가를 예측하기 때문에 각 국소적이 정보를 가진 토큰들 또한 중요하므로 이를 bypass하여 보존해서 최종 예측단 까지 끌고가야 토큰 프루닝을 하는데에 있어서 성능 하락이 적다고 보시면 좋을 것 같습니다. 각 ToSA 레이어에서는 토큰의 상위 80%만 self-attention에 참여하도록 설정했다고 하는데 이 수치에 대한 ablation이나 80%로 설정된 이유가 있을까요?에 대해서는 사실 80으로 설정한 이유와 이에 대한 ablation study는 따로 없었습니다.
감사합니다.