안녕하세요, 허재연입니다. 오늘 리뷰할 논문은 Video Object Detection을 다룬 논문입니다. 지금 DETR 구조를 기반으로 하는 video scene graph generatino(VidSGG) 모델을 고도화 하고자 하는데, Scene Graph의 relation을 예측하기 이전 object detection의 품질이 상당히 낮아서 이 부분을 어떻게 개선할지 고민하며 읽어본 논문입니다. VOD 쪽 task는 이번 기회에 처음 살펴봤는데, 기본적으로 image 기반 OD의 기법들을 기반으로 하되 temporal 정보를 어떻게 함께 잘 고려해볼지에 집중하는 느낌입니다. 이 논문에서 제안하는 모델도 기본적으로 DETR 구조를 기반으로 하고 있기에, DETR 생각하시면서 리뷰 읽으시면 좋을 것 같네요. 리뷰 시작하겠습니다.

Introduction
컴퓨터 비전을 공부하신 분이라면 object detection(OD)에 대해 잘 알고 계실 겁니다. object detection은 주어진 이미지 내부에 있는 다양한 물체들의 위치를 찾아내고, 이들의 속성(class 등)을 예측해내는 task로, 특히 CNN이 본격적으로 도입된 이후에 굉장히 많은 발전이 이뤄졌습니다. 하지만 CNN 기반의 detector들은 동작 과정이 복잡하고 NMS같은 휴리스틱하게 사람이 설정해줘야 하는 부분이 많다는 한계가 있었죠. 이런 한계점을 해결하기 위해 제안된 모델이 DETR입니다. DETR은 object detection을 set-prediction 문제로 다시 정의해서 transforemer 구조를 기반으로 end-to-end 학습 및 추론이 가능했습니다. 초기 DETR은 잘 튜닝된 SOTA CNN보다 detection 성능이 높지 않았고, 학습에 굉장히 오랜 시간과 많은 데이터가 필요한 단점이 있었지만 후속 연구들(Deformable DETR, DAB-DETR, DN-DETR, DINO, RT-DETR .. )을 통해 이런 문제점들이 점점 개선되었습니다. 특히 초기 DETR은 decoder의 object query를 랜덤 초기화했지만, DAB-DETR 이후부터는 object query를 일종의 prior로 기능할 수 있도록 개선해서 효율성을 많이 높일 수 있었습니다.
이런 흐름은 자연스럽게 Video Object Detection(VOD)에도 영향을 주었습니다. VOD는 각 frame마다 물체를 잘 검출하는것을 목표로 하는데, 기존의 이미지 기반 object detector를 각 프레임에 단순히 적용시키면 물체의 모션 블러, 형태 변형 등의 이유로 잘 검출되지 않는 사례가 많았다고 합니다. 이에 비디오 데이터에서 활용할 수 있는 시간적(temporal) 정보를 활용해 이런 문제를 해결해보려는 시도가 있었다고 합니다. 대표적으로는 (1)후처리(post-processing) 기반 방법과 (2) 특징 집계(feature aggregation) 기반 방법이 있었습니다.
후처리 기반 방법은 비디오의 모든 프레임을 object detector로 처리한 뒤, IoU나 optical flow등과 같은 temporal cue를 이용해 프레임 간 box/track을 연결하는 방법입니다. 하지만 이런 방법은 검출기와 후처리 과정이 end-to-end로 joint training이 불가능하기 때문에 성능 향상에 제약이 있었다고 합니다.
특징 집계 기반 방법은 현재 프레임의 feature를 이웃 프레임의 feature와 정렬 및 가중합하여 보정하고, 이렇게 집계된 feature들을 task head에 입력하여 최종 예측을 수행하게 됩니다. 이 때 feature aggregation 하는 방법이 다양하게 제안되어왔다고 합니다(아래 Figure 1의 b).
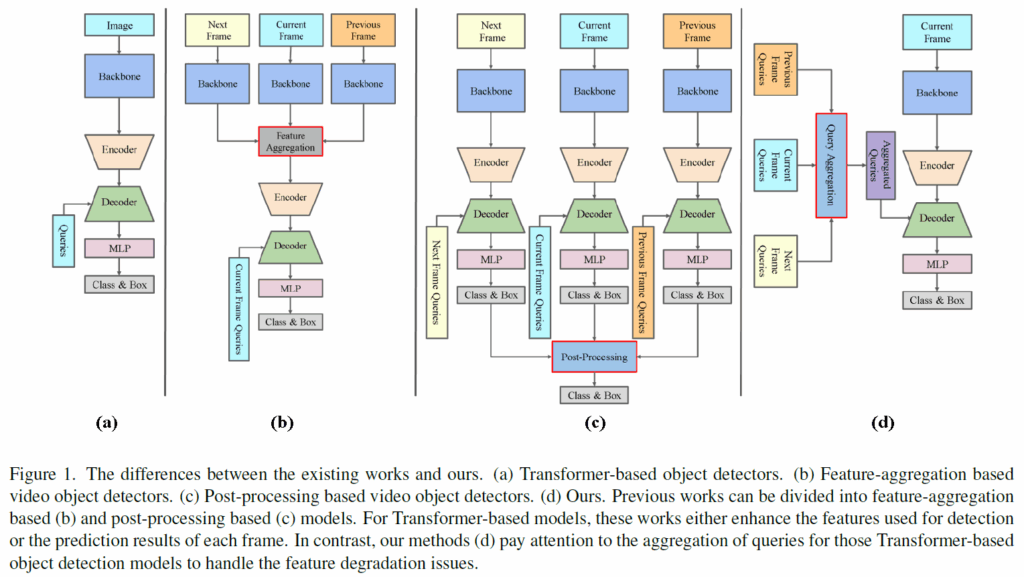
본 논문에서는 기존의 VOD 방법론들과 달리, object query에 집중합니다. feature나 검출 결과를 집계하는 기존 방법이 아니라 위 Figure 1(d)처럼 object query를 집계하는 방식으로 입력 쿼리 품질을 개선하여 성능 향상을 시도한 것이죠. image 기반 object detection에서 DETR의 query를 개선한 흐름을 video에 끌고 온 연구라고 보시면 될 것 같습니다.
Method
Preliminary
우선 간단하게 VOD용 DETR에 대해 살펴보겠습니다. 먼저 입력 프레임 I가 주어지고, ResNet등의 백본에서 multi-scale feature를 추출한 다음 이를 트랜스포머 인코더 {N}_{enc}에 입력해 image feature를 추출합니다. 이후 트랜스포머 디코더 {N}_{dec}에 {N}_{enc} 출력 피쳐 및 랜덤 초기화된 n개의 쿼리를 입력합니다. 디코더 출력값들은 이후 task head {N}_{t}에 입력되어 최종 예측값(class 점수 및 bbox 좌표)을 출력하게 됩니다. 이 과정을 요약하면 다음 수식(1)과 같습니다.
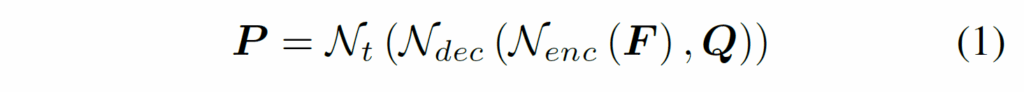
이후 예측값 P는 헝가리안 알고리즘을 활용해 bipartite matching으로 정답 GT값 Y와 매칭되고, 모든 프레임에 대한 총합으로 최종 loss가 계산됩니다.

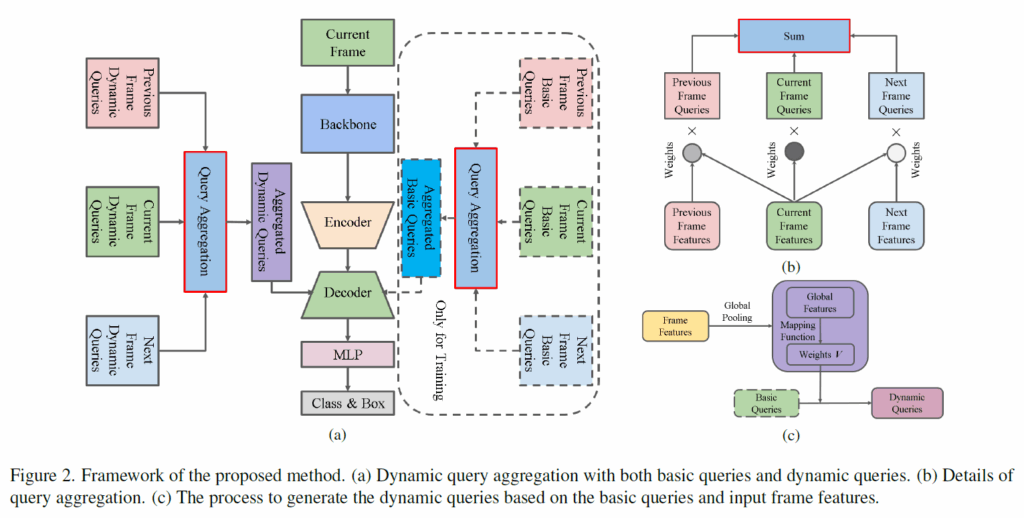
기존 VOD 방법론들은 비디오 프레임에서 degradation 문제를 해결하기 위해 위 수식 (1)에 있는 구성요소들을 개선하여 representation을 강화하는 방향으로 발전하였다고 합니다. 저자들은 이와 달리 Fig.1(c)처럼 frame aggregation을 위해 쿼리 Q의 품질을 향상시켰다고 합니다. 이 때 query aggregation 연산은 decoder 첫번째 계층에만 적용했다고 합니다.
Query Aggregation
Vanilla Query Aggregation
프레임 I의 쿼리 Q를 집계하는 가장 간단한 방법은 Figure 2(b)처럼 인접 프레임 {I}_{i}의 쿼리 {Q}_{i}들을 weighted average하는 것이라고 합니다. 이 때 프레임 수 l에 대해, 하나의 배치 내에서 학습되는동안 I×n개의 쿼리가 랜덤 초기화되어 전체 학습 데이터에 걸쳐 공유됩니다. 현재 프레임 I에 대한 aggregated query는 다음과 같이 나타낼 수 있습니다.
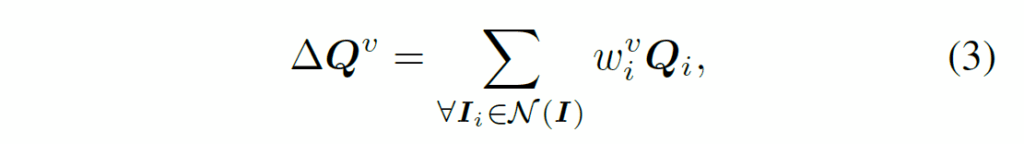
여기서, {Q}^{v}는 learnable weight입니다. 이 learnable weight는 입력 프레임 feature의 코사인 유사도 기반으로 생성하게 됩니다. 기존의 feature aggregation 기반 VOD 방법론들처럼 아래 수식(4)처럼 {w}^{v}_{i}를 생성한다고 합니다.
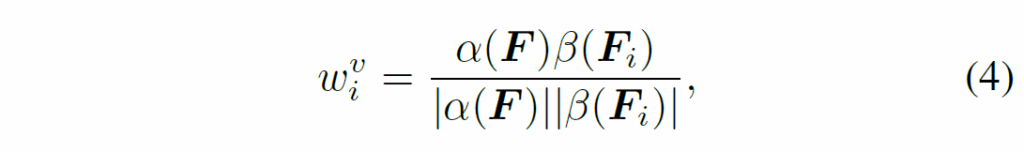
여기서 α, β는 매핑 함수입니다. F, {F}_{i}는 각각 현재 프레임과 이웃 프레임을 의미합니다. 따라서, 위 수식 (1), (2)의 과정이 다음과 같이 수행됩니다.
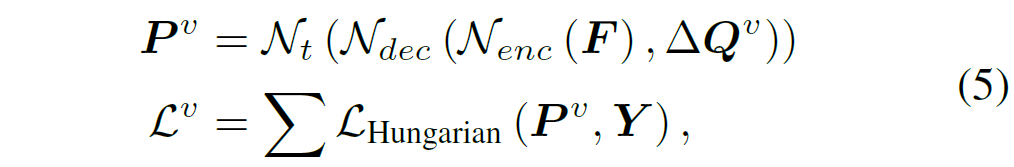
Dynamic Query Aggregation
위 Vanilla Query Aggregation에서는 쿼리 Q가 랜덤 초기화된다는 문제가 있습니다. 저자들은 각 frame의 정보를 쿼리에 반영하기 위해 입력 프레임의 feature {F}_{i}에서 쿼리 {Q}_{i}를 생성하는 방법으로 구현하였습니다. basic query {Q}^{b}_{i}와 dynamic query {Q}^{d}_{i}를 정의하고, 학습 및 추론 과정에서 입력 프레임 feature를 활용해 basic query에서 dynamic query를 생성합니다.
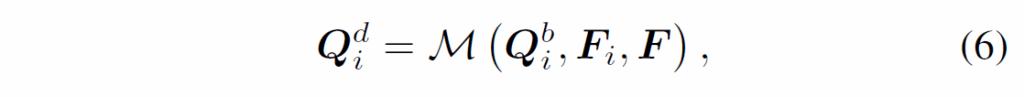
수식(6)에서 M은 F, {F}_{i}에서 basic query와 dynamic query를 만드는 mapping funciton입니다. M(⋅)은 다양하게 구성할 수 있다고 하는데, 해당 본문에서는 간단한 예시로 설명하였습니다. 먼저 basic query {Q}^{b}_{i}를 m개 그룹으로 나눕니다. 이때 각 그룹에는 쿼리가 r개 있습니다. 이후 각 그룹에 대해 동일 가중치 V = {{v}_{j} , j = 1, 2, . . . , r}를 사용해 해당 그룹내 쿼리들을 다음과 같이 weighted average 합니다.
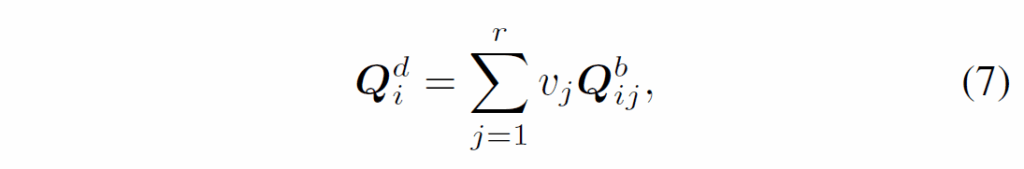
여기서 {Q}^{b}_{ij}는 {Q}^{b}_{i}의 현재 그룹에서 j번째 basic query입니다. 가중치 V는 global feature {I}_{i}를 사용해 다음과 같이 생성합니다.
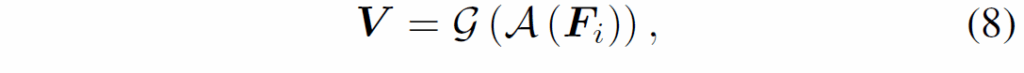
여기서 A는 global pooling이고, g는 풀링된 feature를 r×m차원으로 projection하는 mapping function입니다.
최종적으로, 입력 프레임 feature를 기반으로 쿼리를 aggregation 하는 과정은 다음과 같습니다.
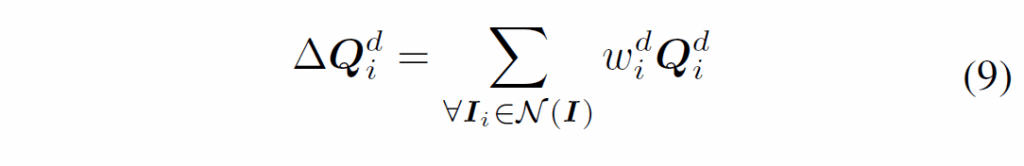
학습 과정에서는 Figure 2(a)처럼 dynamic query {Q}^{d}_{i} 및 basic query {Q}^{b}_{i}를 동일 가중치 {w}^{d}_{i}로 각각 집계하여 식 (10)과 같이 {P}^{b} 및 {P}^{d}를 출력합니다.
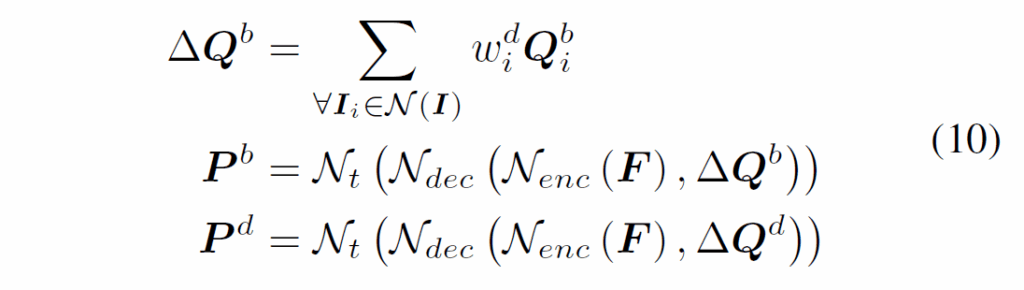
Figure 2의 학습 단계에서, 점선으로 표시된 동일한 basic query group을 활용해 dynamic query를 만들어냅니다. 이후 {P}^{d}와 {P}^{b}모두를 사용해 loss를 계산하게 됩니다.
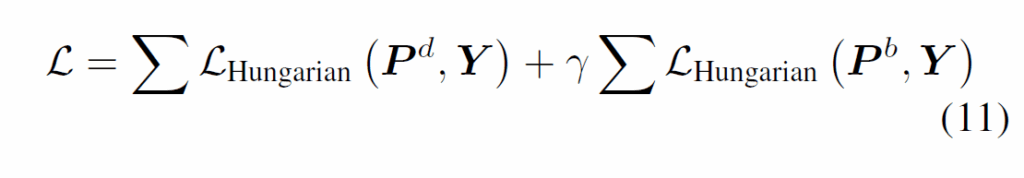
추론 시에 복잡도를 고려하여 dynamic query {Q}^{d}_{i}만을 사용하여 이의 예측값{P}^{d}만 최종 출력한다고 합니다.
Experiments
벤치마크 평가는 ImageNet VID라는 Video Object Detection 데이터셋에서 이루어졌다고 합니다. 기존의 SOTA 모델인 TransVOD처럼 먼저 MS COCO에서 사전학습하고 ImageNet VID와 DET 데이터셋을 합쳐서 finetuning했다고 합니다. 학습 및 추론 과정에서 aggregation을 위한 이웃 프레임 개수는 14개를 사용했다고 합니다. 학습은 A100 8장으로 수행했다고 하네요.
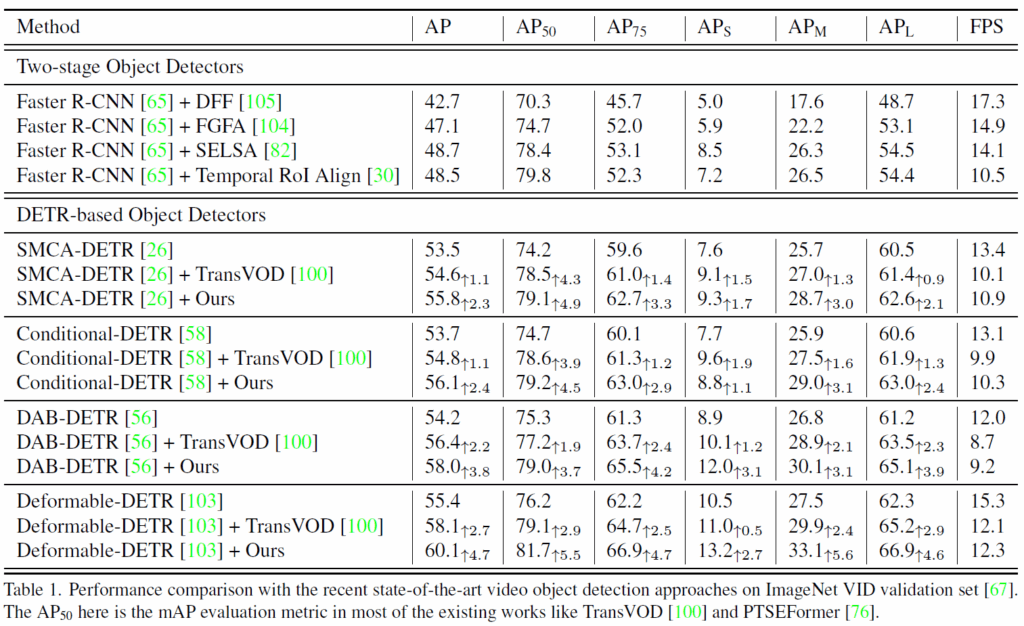
main result를 보면, 저자가 제안한 모듈을 추가했을 때 일관적으로 성능이 향상되는 것을 확인할 수 있습니다. 기존 SOTA인 TransVOD모델에 해당 방법론을 추가해도 성능이 잘 오르네요. object size 관점에서 보면 중형/대형 물체의 검출 성능이 소형 객체보다 훨씬 큰데, 이는 dynamic query를 생성하는 과정에서 global feature를 기반으로 했기에 small object에 대한 정보가 충분하지 않기 때문으로 분석된다고 합니다.
Model Analysis
여기서는 제안 모듈(특히 dynamic query aggregation module)설계에 대해 분석합니다. ImageNet VID 데이터셋과 Deformable DETR을 기반으로 실험을 수행했다고 합니다.
Analysis of M
아래 표 3에는 M의 설계에 대한 분석을 나타내었습니다. 모델 A는 기본 설정으로, 하나의 V을 생성하고 r=4로 설정했다고 합니다. B,C 모델은 weight matrix V 수를 각각 2,4개로 늘린 것이라고 합니다. D 모델은 식(8)의 g와 A연산을 MLP로 교체한 것이고, E모델은 basic query와 feature map에 multi-head cross attention 연산을 사용해 dynamic query를 생성한 것이라고 합니다. F와 G모델은 A모델에서 basic query의 그룹핑 방법을 다르게 한 것이라고 합니다. F는 grouping 이전에 쿼리를 셔플한 것이고, G는 인접하지 않은 쿼리들을 클러스터링하였다고 하네요.
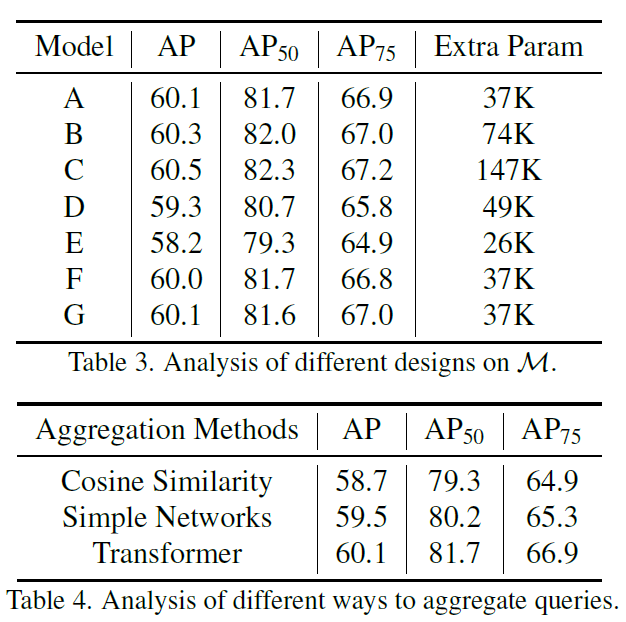
결과적으로, V의 수를 늘리면 성능이 소폭 상향됨을 확인할 수 있었습니다(대신 파라미터 수가 좀 증가합니다)
Analysis of aggregation process
앞에 method에서는 cosine similarity기반으로 aggregation하는 방법을 설명했습니다. 이는 기존 연구에서 사용하던 방법이라고 합니다. 하지만 aggragation 방법으로 다른 방법도 사용할 수 있기에, 이에 대한 실험 결과를 Table 4.에 나타내었습니다. TF-Blender라는 방법에서는 간단한 learnable network를, TransVOD 논문에서는 Transformer를 사용했기에 해당 방법들을 적용한 결과를 나타내었습니다. 위 Table 4에서 확인할 수 있듯 코사인 유사도 기반 aggregation이 가장 낮은 성능을 보였고, learnable simple network와 transformer를 사용했을 때 더 좋은 결과를 보였습니다. 따라서 저자들은 기본적으로 transformer 기반 aggregation을 사용했다고 합니다.
Analysis of each component.
아래 Table 2에서는 각 구성요소에 대한 ablation을 수행하였습니다. A는 Deformable-DETR, B는 vanila query aggregation module, C는 dynamic query aggration module, D는 랜덤 초기화한 {Q}^{b}_{i}와 {Q}^{d}_{i}, E는 dynamic query aggregation 및 추가적인 loss를 사용한 것입니다.
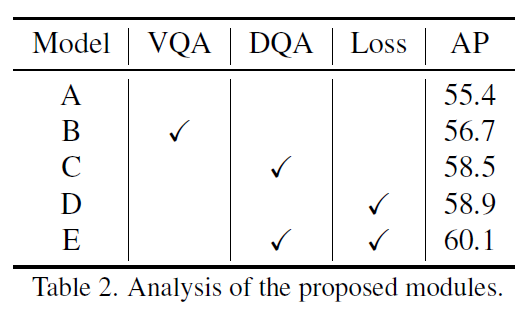
vanilla query aggregation module만 사용하고, 이를 dynamic query aggregation을 변경하면 성능이 향상됨을 확인할 수 있었습니다. 결과적으로는 DQA와 extra loss를 사용한 E에서 가장 좋은 결과를 보였습니다.
Analysis of the number of queries
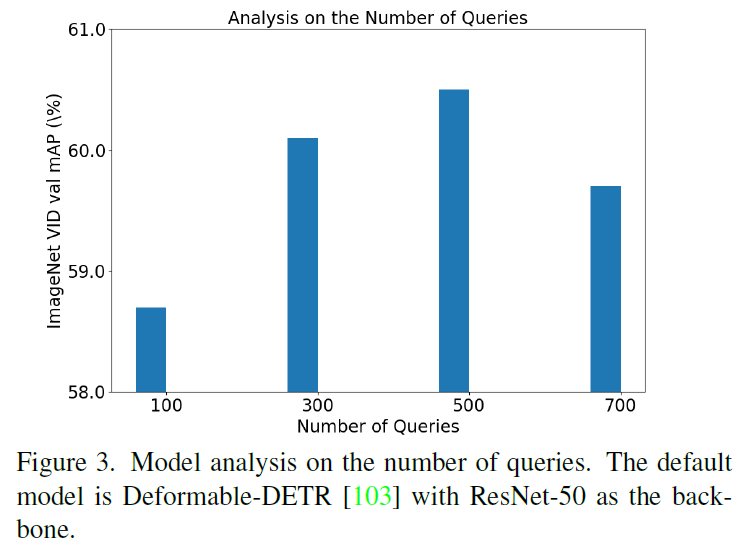
Dynamic Query Aggregation에서 쿼리 개수에 대한 실험 결과를 나타내었습니다(일반적으로 DETR에선 100개를 사용하죠). Figure 3에서 확인할 수 있듯 쿼리 수를 늘리면 성능이 좋아지다, 500개를 넘어가면 포화되기 시작합니ㅏㄷ.
Analysis of {Q}^{d}_{i} and {Q}^{b}_{i}
아래 Figure 4는 원래 모델의 쿼리들과 제안 모델의 dynamic query를 시각화한 것입니다. ImageNet VID에서 비디오 클립 100개를 선정해서 14개 프레임을 샘플링 한 것입니다. 입력 프레임을 기반으로 해당 쿼리를 생성하고, t-SNE로 시각화하였습니다. 기존 모델의 경우 입력 프레임과 무관하게 쿼리가 항상 동일했지만, 제안하는 동적 쿼리는 아래 그림처럼 동일한 비디오 클랩 내 쿼리들이 유사한 representation을 가지고 있고, 이런 representation 덕분에 video object detection 성능 개선에 더 유리하다고 주장합니다.

VOD 계열 논문을 살펴보았습니다. 저도 처음 보는 task기에 많이 낯설었는데, 기본적으로 이미지 기반 OD 모델들을 확장하며 temporal 정보를 잘 모델링하는데 집중하는 흐름이네요. 기존 연구들의 경우 feature aggregation에 집중했지만, 오늘 리뷰한 논문은 query에 집중한 점이 꽤 신선했습니다.
이만 리뷰 마무리하도록 하겠습니다.
감사합니다.
안녕하세요 재연님 좋은 리뷰 감사합니다.
Loss가 좀 복잡해서 제가 이해를 잘 못했을 수 도 있는데, 학습 단계에서는 Pb, Pd 둘 다 사용, 추론에서는 Pd만 사용한다고 이해 했는데 왜 학습 시에는 둘 다 쓰는지가 궁금합니다! 뭔가 단순히 regularization 차원인지 아니면 basic query 자체도 detection 성능에 긍정적인 신호를 주는지가 궁금합니다.
감사합니다!
basic query는 기본적으로 random init되므로 해당 frame의 시각적 정보를 담고 있지 않습니다. 이를 함께 사용하면 학습 과정에서 도움을 줄 수는 있지만, ‘각 인접 프레임의 정보를 활용해서 쿼리를 초기화하겠다’라는 본래 의도와는 맞지 않습니다. 또한, basic query를 함께 사용하면 추론 시간이 더 늘어날 수 있기에 속도 측면에서도 제거하는게 좋다고 합니다.