Abstract
scene representation은 로봇 조작에서 중요하며 다음 3가지 특성 3D, dynamic, semantic을 모두 만족하기를 바랍니다. 그러나 지금까지는 이러한 3가지 특성을 모두 가지는 representation이 없었으며 따라서 저자들은 D3Field-dynamic 3D descriptor fileds-라는 representation을 제안합니다. 이는 3D point를 입력으로 받아 의미론적 특징과 instance mask를 출력하는 implicit 3D representation으로, 3차원 공간의 동적인 특성도 포착할 수 있다고합니다. 작업 공간 내 임의의 3D 점을 다중 뷰 2D 시각 관측에 투영하고 VFMs에서 추출된 feature를 보간하는 방식으로 구해집니다. 이렇게 융합된 descriptor field는 다양한 의미론적 정보와 스타일, 객체 등을 포함하는 2D 이미지를 사용하므로써 유연하게 목표를 설정할 수 있다고 합니다. (유연한 목표 설정이라는 게 어떤 표현일지 생각해보았는데, 정확한 좌표 정보를 주며 ‘x,y,z 위치로 가서 잡아라’와 같은 명령 뿐만 아니라 참조 영상을 제공하며, ‘이미지의 이런 컵 같은 부분을 잡아라’ 와 같 방식이 조금 더 유연한 방식의 목표 설정도 가능해진다고 이해하시면 될 것 같습니다.) 저자들은 이러한 D3Fields를 rearrangement task(물건을 goal 이미지처럼 정렬하는 로봇 작업입니다)에 적용하여 실제 및 가상 환경에 대한 평가를 진행하였으며, 효과적으로 zero-shot 방식으로 일반화가 가능함을 실험적으로 보였습니다. 또한 SOTA 3D representation 방식들과도 비교하여 성능 및 효율성이 개선되었음을 보였습니다.
Introduction
로봇 시스템에서 장면을 이해하는 것은 중요한 역할을 하며, 장면에 대한 representation은 3차원 정보(3D)와 동적 장면(dynamic), 의미론적 정보(semantic)를 모두 포함하는 것이 이상적입니다. 그러나 기존 연구들은 3차원 공간에 대한 표현의 의미론적 정보를 간과하거나, 동적 장면을 모델링하는 방식은 3D 공간을 고려하지 못하거나, 2차원 공간에서의 semantic 정보만을 고려하는 등, 3가지 특성(3D, dynamic, semantic)을 동시에 표현하는 연구가 없다고 저자들은 어필합니다.

따라서, 저자들은 D3Fields라는 3D, dynamic, semantic 정보를 모두 포함하는 새로운 implict 3D representation 방식을 제안합니다. 이는 3D 좌표를 받아 의미론적 정보와 기하학적 정보를 함께 제공하며, instance mask와 semantic feature 등을 포함합니다. 또한, 별도의 학습과정 없이 Grounding-Dino와 SAM등의 VFMs를 활용하여 zero-shot 방식으로 동작합니다. 다중 시점의 2D 이미지로 3D point를 투영한 뒤 보간 및 융합을 통해 해당 3D 위치의 descriptor를 생성하며, 이렇게 구한 representation은 대상 물체의 3D point를 안정적으로 추적할 수 있도록 하며, 이를 통해 동적 모델을 학습할 수 있도록 합니다. 또한 MPC(motion predictive controll)와 결합하여 zero-shot으로 다양한 rearrangement task가 가능하도록 합니다. 이러한 연구를 통해 저자들은 2D 이미지를 활용하여 로봇 작업의 목표를 제시할 수 있어지는 등 유연한 목표 설정이 가능해짐을 어필합니다.
저자들은 D3Fields를 로봇의 rearrangement tasks에 적용하여 zero-shot 방식으로 평가를 수행하였고, 이를 통해 기존의 명시적인 3D representation 방식보다 효율 및 성능 측면에서 개선됨을 보였으며, 분석을 통해 category-level로의 확장 가능성을 제시합니다.
해당 논문의 contribution을 정리하면
- 3D, dynamic, semantic을 동시에 고려하는 implict 3D representation 방식인 D3Fields제안
- 2D 이미지 다양한 정보를 활용하는 새로운 목표 설정 방식을 제안
- zero-shot 방식으로 다양한 zero-shot rearrangement tasks가 가능한 프레임워크 제안
Method
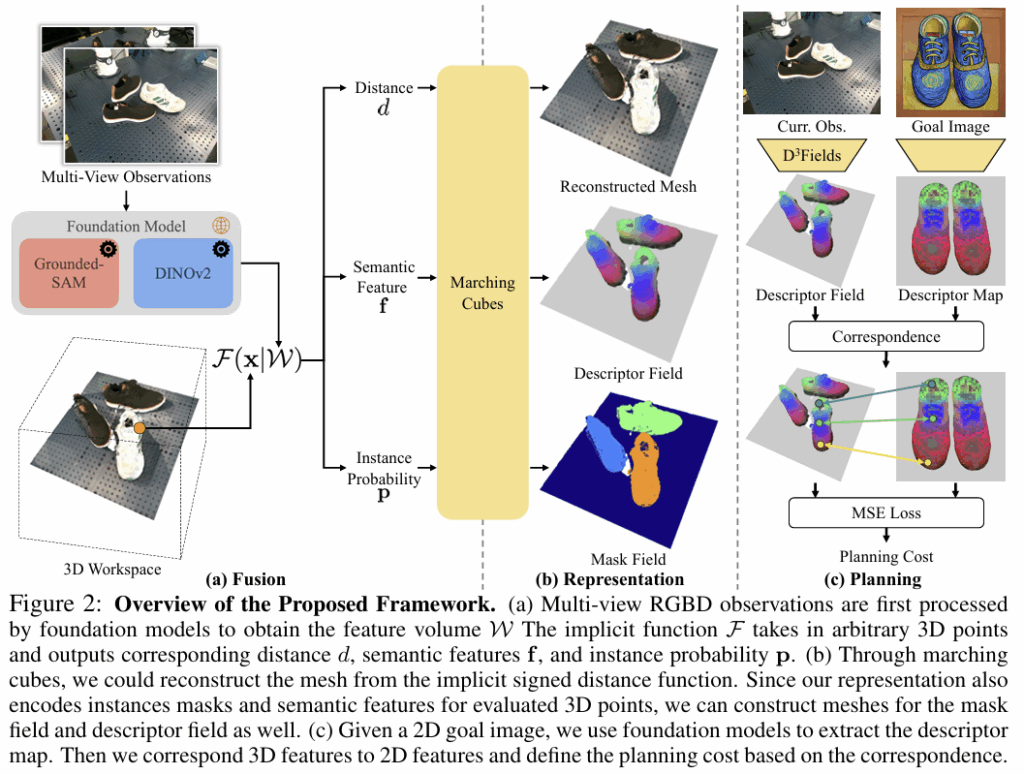
0. Problem Formulation
아래의 식(1)은 zero-shot rearrangement에 대한 문제 정의로, 2D goal 이미지 \mathcal{I}와 현재 시점에 대해 정해진 시점의 멀티뷰 RGBD observation \mathbf{o}^{t}이 주어졌을 때, 작업을 수행하기 위한 최적의 action squence \{a_t\}를 찾는 것 입니다. 즉, 현재의 view 들에 대하여 representation extractor g(.)를 적용하여 3D representation \mathbf{s}^t를 만들어내고, goal representation \mathbf{s}_{goal}과의 distance로 정의되는 cost function c(.)가 최소가 되도록 하는 action sequence \{a_t\}를 찾는 것 입니다. 또한, 여기서 현재 시점 이후의 representation \mathbf{s}^{t+1}은 현재의 representation과 action a^t을 dynamic fuction f(.)에 조건으로 활용하여 구해집니다.
1. D3Fields Representation
해당 논문에서 핵심으로 제안하는 3D, dynamic, semantic을 모두 고려하는 D3Fields는 문제 정의된 수식에서 g(.)에 해당합니다. 정해진 다중 시점의 RGBD 영상을 VFMs에 입력하여 2D featues \mathcal{W}를 구하고, 아래의 식으로 정의된 D3Fields를 만드는 implict function \mathcal{F}(.|\mathcal{W})에 입력합니다.

- \mathbf{x}: 임의의 3D 좌표
- d: signed distance
- \mathbf{f}: semantic descriptor
- \mathbf{p}: 전체 M개의 instance에 대한 확률 분포
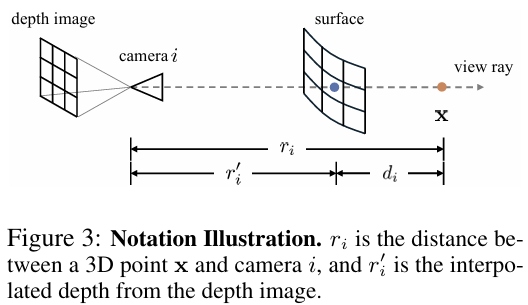
이제 \mathcal{F}(.|\mathcal{W})가 어떻게 동작하는 지 살펴보겠습니다. 임의의 점\mathbf{x}과 i번째 view의 카메라 사이의 거리를 r_i라 하고, depth 이미지 \mathcal{R}_i에 투영된 픽셀 \mathbf{u}_i의 depth값을 r’_i라 하면, truncated depth difference를 아래의 식으로 정의합니다.
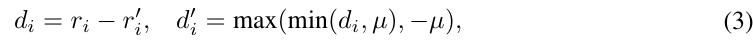
- \mu: tranctation 임계치
이렇게 정의된 turncated depth를 기준으로 각 view의 가중치 v_i, w_i를 구합니다. 가중치에 대한 식은 아래와 같이 정의되며, v_i는d_i < \mu일 경우 1 아니면 0이 되도록 하여 표면 앞에서 보이는 지를 나타내는 가중치이며, w_i는 해당 포인트가 가까울수록 신뢰도가 높아지므로 표면에 가까울수록 커지고 멀수록 0이 되도록 합니다.
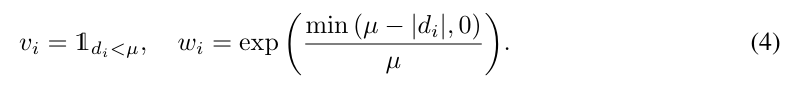
그다음, 저자들은 DINOv2로 semantic feature \mathbf{f}_i를 추출하였으며, Grounded-SAM을 이용하여 instance mask \mathbf{p}_i를 구하였습니다. 이렇게 구해지는 감ㅅ들에 대하여 아래의 식을 계산하여 K개의 시점에 대하여 signed distance, semantic feature, instance mask를 만들어냅니다.
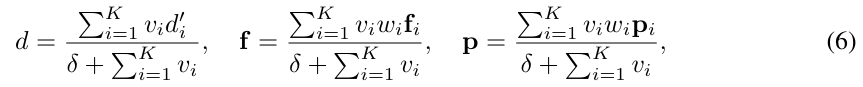
- \delta: 분모가 0이 되는 걸 막기 위한 파라미터
2. Keypoints Tracking and Dynamics Learning
앞의 과정은 implict 3D representation을 구하는 과정이며, 해당 과정은 이렇게 구해진 representation을 어떻게 keypoint tracking과 dynamics 학습에 사용하는지 설명합니다. 단일 객체를 추적하는 것을 \mathbf{s}^t \in \mathbb{R}^{3⨉n_s}(시점 t에서 n_s개의 keypoint)로 가정합니다. 초기 keypoint \mathbf{s}^0은 인스턴스 표면에서 샘플링되며, 이후의 \mathbf{s}^0 tracking은 최적화 문제로 공식화하며 아래의 식으로 정의합니다.
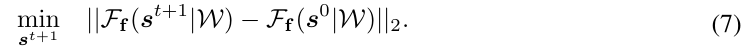
gradient-based optimizer를 사용하여 다음 시점 t+1에서의 feature의 distance가 가장 작아지는 point들을 찾아 tracking을 수행합니다. 이렇한 방식은 다중 객체로도 확장이 가능하며, 저자들은 안정성을 높이기 위해 물체가 강체라는 점을 이용하여 point 사이의 제약을 추가하였다고 합니다. 해당 제약에 대해서 논문에 자세한 설명은 없지만 코드를 살펴보았을 때, 인스턴스에 대한 하나의 rigid transform SE(3)을 초기에는 0으로 설정하고 이전 시점의 3D point에 적용한 뒤, 변환된 위치의 descriptor와 이전 descriptor 사이의 L2 loss와 distance 오차를 구하여며 점차 SE(3)가 최적의 값이 되도록 adam optimizer를 이용하여 업데이트 합니다.
이렇게 keypoint에 대한 tracking을 통해 dynamics model을 학습하며, 저자들은 기존 연구를 따라서 물체의 dynamics를 예측하는 dynamics model을 GNN 기반으로 구현하였다고 합니다. 이렇게 학습된 모델은 이후 trajectory 최적화에 활용됩니다.
3. Zero-Shot Generalizable Robotic Rearrangement
해당 파트는 zero-shot rearrangement를 위해 planning cost를 정의하는 방법에 대하여 설명합니다. 해당 과정은 goal 이미지와 로봇 시스템에서 관측된 환경에 대한 대응 관계를 설정한 뒤, 저자들이 정의한 cost function c(.,.)를 통해 현재 상태와 목표 상태 사이의 거리를 측정하여 최적의 행동 sequence \{a_t\}를 구합니다. 앞서 초기에 샘플링된 포인트 \mathbf{s}^0와 이에 연관된 feature \mathbf{f}^0를 구하였으며, 이를 goal image \mathcal{I}_{goal}과 대응시켜 2D goal points \mathbf{s}_{goal} \in \mathbb{R}^{2⨉n_s}를 정의합니다.
먼저, goal image \mathcal{I}_{goal}의 i번째 픽셀 \mathbf{u}_i와 \mathbf{s}^0의 j번째 point 사이의 feature distance \alpha_{ij}를 구합니다. 이후 전체 이미지에 대한 softmax를 적용하여 정규화하고 가중치 \beta_{ij}를 구하고, 마지막으로 가중합을 통해 j번째 3D 점에 대응되는 2D 포인트 \mathbf{s}_{goal,j}를 구합니다.
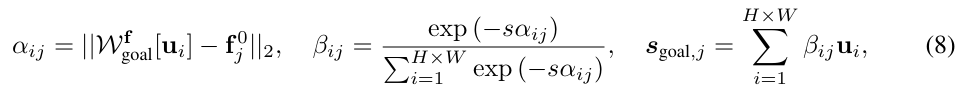
- \mathcal{W}^f_{goal}: \mathcal{I}_{goal}에 DINOv2를 적용하여 구한 feature
- s: smoothing 파라미터
이렇게 구해진 \mathbf{s}_{goal}은 2D space에 위치하므로, 이를 가상의 레퍼런스 카메라를 도입한 뒤 \mathbf{s}^t도 해당 레퍼런스 이미지 영상으로 투영시켜 \mathbf{s}^t_{2D}를 구한 뒤 아래의 식(9)로 정의된 cost function을 구합니다. (여기서 가상의 카메라를 어떻게 정의하는 지 설명이 자세히 나와있지 않고, 깃허브에 수동으로 설정되었다고 언급되어 있습니다.)
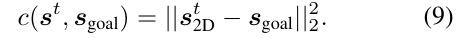
저자들은 MPPI를 통해 action sequence를 최적화하고, 각 시점마다 action sequence 샘플링 후 planning cost를 계산하는 과정을 반복하여 goal 이미지처럼 물체를 배치하도록 하는 rearrangement task를 수행합니다.
Experimetns
실험을 통해 저자들은 D3Fields가 기존 representation에 비해 얼마나 효율적이고 효과가 있는 지 확인하고, 저자들이 제안하는 프레임워크로 어떤 작업이 가능하며 일반화 달성이 가능한지, D3Fields가 일반화에 어떤 영향을 미치는 지 확인하고자 하였습니다.
0. Setting
저자들은 real world에서 워크스페이스 안에 4개의 RGBD 카메라를 배치하고, Kinova Gen3 로봇 팔을 이용하여 실험을 수행하였습니다. 시뮬레이션 환경에서는 OmniGibson과 Fetch 로봇을 사용하여 모바일 manipulation 작업을 수행하였으며, task는 신발 정리, 테이블 정리 등의 작업을 수행하였다고합니다.
1. D3Fields Efficientcy and Effectiveness
저자들은 D3Fields의 효과와 효율을 평가하기 위해 2가지의 feature representation 방식인 F3RM과 FeatureNeRF를 비교에 사용하였습니다.
- F3RM: 4개의 카메라 시점을 입력으로 사용하고 DINOv2로 구한 feature를 supervision으로 사용하여 2000 step동안 distillation을 수행
- FeatureNeRF: 작은 데이터 셋으로 사전학습

위의 Figure 5는 이에 대한 정성적 결과로, D3Fields가 고품질의 mesh를 생성할 수 있음을 보였으며(Corr. Mesh 결과 비교) source 이미지와 다른 인스턴스인 경우에도 의미론적으로 유사한 영역을 찾을 수 있는 것을 보였습니다. 한편 F3RM는 구한 mesh의 품질이 떨어질 뿐만 아니라, 신발이 아닌 망치와 컵에 대해서는 유의미한 영역이 활성화되지 않았으며, FeatureNeRF의 경우 소량의 데이터로 사전학습 되어있다보니 일반화 성능이 떨어져 의미론적으로 대응되는 영역에 대한 활성화 뿐만 아니라 mesh reconstruction도 거의 불가능한 결과를 보였습니다.
또한, 저자들은 효율적인지를 판단하기 위해 4장의 이미지에 대해 A6000에서 F3RM 방식과 소요 시간을 비교하였습니다. D3Fields는 0.166 ± 0.002초, F3RM은 88.379 ± 5.306초로 속도가 크게 개선되었음을 어필합니다.
Zero-Shot Generalizable Rearrangement

다음은 zero-shot 방식으로 로봇 rearrangement 작업을 비교하는 실험을 수행하였습니다. 이에 대한 결과는 위의 Figure 1과 Figure 6에서 확인할 수 있으며, 특히 Figure 1에서 신발 영상의 경우 원본 영상을 반 고흐 스타일의 이미지로 생성한 뒤 goal 이미지로 활용한 결과로 이를 통해 외관이 크게 다른 경우에도 의미론적으로 유사한 영역을 찾을 수 있다는 것을 어필합니다.
또한, Figure 1의 Organize Office Table 작업에서, 로봇은 먼저 마우스와 펜을 목표 이미지와 맞추도록 정렬한 뒤, 머그잔을 상자 위에서 머그받침대 쪽으로 재배치합니다. 이는 머그잔에 대해서는 별도의 goal 이미지를 활용한 결과로, 이처럼 저자들이 제안하는 시스템이 여러 목표 이미지를 기반으로 작업을 수행할 수 있음을 보였습니다.
또한, 워크스페이스 내의 여러 물체에 대해서도 작동 가능함을 보여주며 일반화 가능성을 어필합니다. Figure 6의 오른쪽 3개 열인 sim 결과를 통해 goal 이미지가 real-world 이미지인 경우에도 조리도구 정리 및 머그잔 정리가 가능함을 보였으며, 이러한 전반적인 실험 결과를 통해 저자들은 일반화 능력을 보였습니다.
D3Fields Analysis
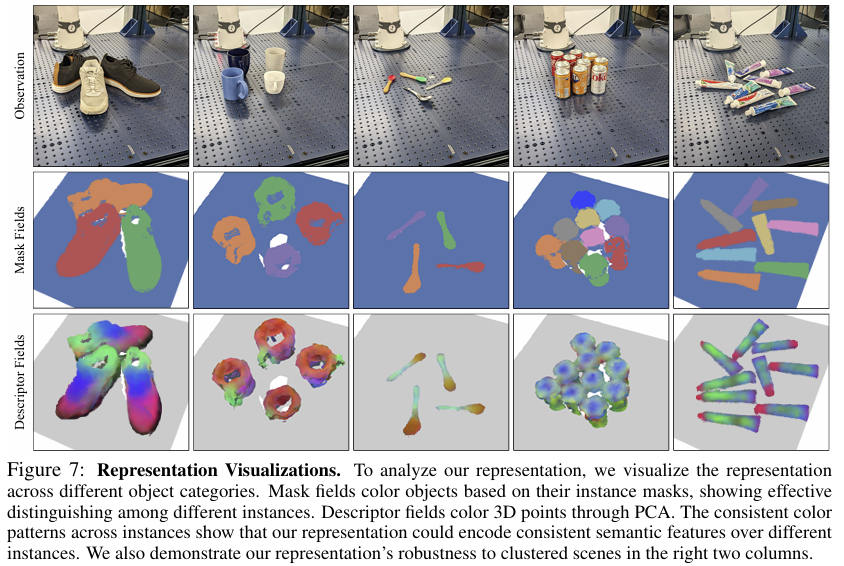
Figure 7의 Mask Field는 서로 다른 시나리오에서 3D 인스턴스 분할 결과를 보여주며, 캔(4열)이나 치약(5열)처럼 유사한 물체들에 대해서도 instance segmentation이 잘 이루어짐을 확인할 수 있습니다. 이를 통해 다수의 객체를 구별하고 조작할 수 있다는 점을 어필합니다. 또한, Descriptor Fields 결과는 D3Fields에 PCA를 적용한 결과로, 신발이나 컵과 같이 외관이 달라지는 경우에도 의미론적으로 유사한 영역이 비슷한 색을 나타내는 것을 통해 category-level의 일반화가 가능하다는 것을 어필하였습니다.
안녕하세요 승현님 리뷰 감사합니다.
3D field를 정밀하게 구현하도록 설계하고 2D->3D에 semantic한 정보와 instance 정보를 주입해서 representation을 만들고, 그 기반으로 dynamics를 학습해 MPC를 결합한 프레임워크라고 이해했습니다. Zero shot에 완전 강한 느낌인거 같습니다. 몇가지 질문이 있는데요,
1. GNN방식으로 dynamics를 학습한 다음에 MPC가 goal image 기반의 planning을 할 때 사용하는 function으로 사용될 때 function은 다음 state를 출력하는거고 그 state에 해당하는 액션을 MPC가 진행하는 것일까요? 현재 상태를 goal image와 맞출 때 등장하는 cost function과 어떻게 연결돼있는지 이해가 명확히 되지 않는 것 같습니다.
2. 0.16초의 시간이 매우 인상적이었는데 DINOv2, GroundedSAM의 2D feature를 뽑아서 D3field를 구성하는데 까지 걸리는 시간이라고 이해해도 될까요?
안녕하세요 승현님, 좋은 리뷰 감사합니다.
CoRL 25′ oral 페이퍼이다보니 시간을 들여 좀 집중해서 리뷰를 읽게 되었는데요. 궁금한 부분이 많이 생겨 질문드립니다.
1. Method 1에서 implict function F를 통해 D3Fields Representation 가 만들어지는 과정들에서 truncated depth difference 기준으로 가중치 구하고 그걸 representation에 곱해주는 과정이 왜 필요한지 고민해봤는데, 제가 이해한 게 맞는 지 잘 모르겠습니다. truncated depth difference를 기준으로 각 view의 가중치 v_i, w_i를 구하는 이유가 대략적으로 실제 view-ray 상의 포인트가 depth image의 예상surface보다 더 멀리있을 경우(실제 depth값이 측정된 depth값보다 더 멀 경우)에서 결론적으로 생기게 될 D3Fields Representation 값들이 noisy해지는 것을 완화하기 위한 단순 전처리인건가로 이해했는데,,, 이게 맞나요? 아니면 다른 이유가 있나요?
2. Method 2에서의 keypoint tracking은 물체들이 강체라는 것을 가정으로 깔고 제약을 걸어서 가능했던 것으로 이해했습니다. 그 다음 tracking된 keypoint들을 가지고 물체의 dynamics를 예측하는 model을 GNN기반으로 학습한다고 하셨는데, GNN기반인 이유가 무엇이고, 물체의 dynamics는 강체라는 가정 하에 R,t만 예측하게 되는 모델인건지, 그리고 학습된 모델이 이후 trajectory 최적화에 활용된다고 말씀해주셨는데 그게 3에서 어떤 부분에 연결되는 내용인건지 궁금합니다.
3. Method 3에서 generated goal image 에 DINOv2 태운 feature값이랑, 초기 샘플링된 3D포인트 의 implicit function을 타고 나온 D3Fields representation 중 semantic descriptor인 f간의 L2 distance 인 것으로 이해했는데, 모든 2D pixel과 3D point 간의 이런 대응쌍을 고려한 연산으로 α값을 구하고 이걸 가지고 β 가중치를 또 구하고, 그걸 가지고 최종 s_goal이라는 대응포인트를 구하는 과정이 꽤 오래걸리고 noisy할 수 있지 않을까 싶었는데, F3RM이라는 베이스라인 대비 속도 개선에 강조를 두니 좀 의아한 부분이 있습니다. 정확히 어떤 부분에서 이런 속도 개선이 이루어졌는지 저자들의 설명이 따로 있을까요?
4. 이어서 s_goal과 s^t_2D 랑의 MSE loss 계산 후 planning cost에서도 goal image의 생성 양상에 따라 이런 noisy함이 성능에 영향이 있을 것 같다고 생각이 들었는데요.(overview에서도 goal image 내의 운동화가 배경과 색깔 및 기타 특징 모두 obs에서 보이는 운동화랑은 사람이 봤을 땐 꽤나 다른 특징을 띄고 있습니다.) 그런 관점에서 experiments에서의 베이스라인들과 비교하는 정량적인 성능지표나, goal image를 obs와 비슷하게 생성하는 데 사용되는 prompt가 궁금해지는데, 이런 부분에 대한 언급을 제가 발견하지 못해서, 혹시 논문에는 이런 부분에 대한 저자들의 언급이 있을까요?
5. 또한 action sequence 샘플링 후 planning cost를 계산하는 과정을 반복하며 goal 이미지처럼 물체를 배치하도록 한다고 했는데, 이 과정이 정확히 어떻게 진행되는지 이해가 되지 않아 추가설명 부탁드립니다. (영규형 1번 질문과 동일합니다.)