manipulation task의 high-level planning 시 spatial 정보, 특히 semantic orientation 정보를 고려한 방법론을 들고 왔습니다. 복잡한 로봇 조작 액션을 위해선 ‘객체 중심의 의미론적 방향 이해’ & 이와 연관된 ‘공간 추론’이 선행되어야 합니다. 물론 high-level planning 관점, low-level policy 관점 모두에서 이런 spatial한 reasoning 정보는 중요할 것 같으나, 본 논문에선 전반적으로 ‘객체의 방향 정보를 필요로 하는 manipulation을 위해 구축한 통합 VLM 파이프라인’ 을 목표로 두고 있었습니다. 즉 정리하면 low-level action 같은 경우는 motion planning에 의존하고, high-level planning에서 VLM 기반으로 객체 중심의 의미론적 방향 이해 & 공간 추론 에 대한 constraints 에 초점을 맞춘 방법론이라고 정의할 수 있을 것 같습니다.

분량이 좀 돼서 먼저, 본 논문의 큰 그림 정말 핵심만 딱딱 짚어서 설명하고 넘어가겠습니다. 객체 중심의 ‘semantic orientation’ 정보를 orientation-text pair annotation으로 표현한 학습 데이터셋 OrienText300K 구축합니다. 그리고 그 데이터셋으로 학습하여 orientation을 output으로 내뱉게 하는 Cross-modal 3D transformer 모델인 PointSO를 제안합니다. 그 PointSO와 함께 Florence2 + SAM + VLM(gpt4o) 를 짬뽕해서 사용하면서 high-level planning을 수행하고, high-level planning과 low-level planning 사이에서 핵심 bridge 역할을 담당하는 6DoF Scene Graph Map을 생성하게끔 하고, 이를 활용해서 low-level action 단에선 어떤 학습된 IL/RL Policy가 아닌 Motion Planning을 수행하는 방식의 큰 그림을 갖고 있습니다.
마지막으론 저자들이 학습 데이터셋도 제안하고, 모델 아키텍쳐도 제안하고, 6DoF scene graph map도 제안하고, 등등등 파이프라인의 내의 핵심 요소를 상당 부분 새로 제안한 터라, 마지막으로 평가 벤치마크 또한 저자들의 semantic orientation 기반 파이프라인에 맞추어 Open6DOR V2라고 Open6DOR라는 기존 벤치마크 기반으로 재구성한 벤치마크도 제안합니다. 당장 읽어봤을 땐 contribution을 아주 고봉밥으로 꽊꽉 눌러담은 논문인데, 공개된지 꽤 된 논문임에도 불구하고(25년 2월 arxiv) 아직 게재소식이 없는 걸 보니 어디에 붙을지 궁금해지는 논문입니다. 이제 각설하고 본 리뷰로 넘어가겠습니다.
1. Introduction
개방형 공간 지능은 로봇이 효과적인 상호 작용을 위해 객체가 “무엇”인지 뿐만 아니라 정확히 “어디”에 있는지를 이해해야 하므로, Embodied AI에 매우 중요합니다. 이를 위해 공간적 개념과 관계를 이해하는 공간 이해 능력을 갖춘 VLM쪽도 연구가 되어왔습니다(SpatialBot, SpatialVLM, SpatialRGPT). 해당 연구들은 spatial한 지식을 모델이 학습하게끔하기 위해 학습 데이터를 annotation하거나 아키텍처를 설계하면서 왼쪽과 오른쪽을 구별하고, 객체 수를 세고, 로봇 조작을 위한 end-effector의 position 위치를 추론하여 output으로 내뱉게(RoboPoint) 하는 등의 작업을 수행할 수 있도록 합니다. 근데 저자들은 이런 spatial VLM 선행연구들에 만족 않고 그런 뛰어난 spatial understanding 연구들에서조차 놓친 주춧돌은 무엇일지? 즉 더 깊게 고민해보며 아주 핵심으로 더 들어가고 싶었다고 합니다. “seeing is for doing”(Fei-Fei Li 교수님의 The Worlds I See[24’] 라는 저서에서 인용한 문구라고 합니다.)라는 spatial reasoning task 자체의 본질적인 의도를 고려할 때, 이걸 어떻게 더 발전시킬 수 있을까?를 파고 들고 싶었나 봅니다.
그런 의미에서 현재 VLM의 spatial reasoning의 허점 중 하나로, 객체의 방향 이해에 있어서의 어려움으로 스토리를 끌고 갑니다. 현재의 VLM은 객체의 방향을 이해하는 데 어려움을 겪고 있으며, 이게 일반적인 로봇 조작 계획에 충분하지 않는다는 것인데, 이전 연구들의 접근 방식은 주로 “펜이 ‘어디’에 있는지” 또는 “와인 잔이 ‘어디’에 있는지” 이런 grounding 이해까지만 초점을 맞추고 객체의 방향을 고려하는 연구는 그렇게 많지 않았습니다. (제 기억엔 OmniManip[CVPR 25’ HL]가 있긴 합니다. ReKep[CoRL 24’]의 경우는 공간과 객체에 대한 keypoint 추정 기반이기에 orientation의 관점에서는 명시적인 reasoning이 있진 않습니다.) 저자들은 객체를 바라보는 각 특정 방향마다 semantic significance, 즉 그 의미적 특징이 바뀐다고 언급합니다. 예를 들면 펜을 펜 홀더에 꽂거나, 기울어진 와인 잔을 똑바로 세우거나, 코드를 전원 스트립에 꽂는 것과 같은 일상의 조작 시나리오들이 사실 모두 일반적인 픽앤플레이스 동작은 아닐 수 있기에 무작정 객체만 있다고 액션을 수행해야되는 것은 아니고, 저런 복잡한 액션을 수행하려면 물체를 어느 방향으로 어떻게 조작해야되냐?의 관점으로 접근해야되는 것입니다. 예를 들어, 펜을 펜 홀더에 꽂으려면 펜촉을 펜 홀더 입구 방향과 정렬해야 하고, 와인 잔을 똑바로 세우려면 잔의 윗부분을 세계 좌표계의 z축과 정렬해야 합니다. 전원 스트립에 플러그를 꽂으려면 전원 스트립 표면에 수직인 “삽입” 방향을 이해해야 합니다. 그러나 특정 언어 설명을 원하는 객체 방향으로 변환하는 것은 기존 VLM에게는 어려운 일입니다.
그래서 저자들은 이러한 문제점에서 출발하여, “language-grounded orientation that bridges spatial reasoning and object manipulation” 를 핵심 주제로 들고가게 됩니다. 아래는 이 핵심 주제를 뒷받침할 근거와 세부적인 주장입니다.
- From Position Awareness to Orientation Awareness.
기존 VLM 기반 연구들이 Position Awareness에만 중점을 둔 반면, Orientation awareness가 중요하다. 6d pose estimation 연구들에서 다루는 것처럼 객체 또는 ee pose의 6-DoF에 대한 정의가 spatial reasoning에 있어서는 똑같이 중요해진다고 말을 합니다. 객체 방향과 open-world에서의 관계를 이해하여 로봇이 위치 인식과 함께 정확한 정렬 및 재배열까지 필요한 작업을 완료할 수 있도록 하는 것을 중점으로 두고 싶은 것입니다.
- From Orientation to Semantic Orientation.
그냥 orientation에서 의미론적 orientation으로. 기존의 그냥 쌩짜 orientation을 생각해보면 기준 프레임 또는 템플릿 모델, 즉 3D CAD모델을 기준으로 정의되는데, 이건 사실 객체의 회전을 월드 프레임이나 모델의 고정된 어떤 축을 기준으로 정의하기에, 실제 환경의 객체들은 canonical orientation이 불명확하거나(웹 3D 모델의 axis flip 차이, 비정형 물체 등) 카메라 관측에 따라 기준이 달라지기에 고정 프레임에 의존하면 실제 환경 객체에 대한 일반화된 해석이 어렵게 된다는 문제점이 있습니다. 또 language instruction에 의한 open world 조작 태스크 관점에서 보면 (언어+방향)→동작으로의 의미적 연결고리가 기존 쌩짜 orientation엔 없습니다. 저자들은 객체의 방향 벡터를 open vocabulary prompt(칼 손잡이 방향 또는 USB 꽂는 방향 등)에 연결하는 의미론적 orientation을 도입하여 기하학적 추론과 기능적 의미론을 연결하여 로봇이 작업별 방향 변화를 해석할 수 있도록 하고자 했습니다.
사실 위에서 저자들이 주장하는 그런 contribution을 위해서는 open-world에 대한 semantic orientation 지식을 먼저 획득하고나서, 이를 기존 VLM 기반 파이프라인과 통합하는, 두 가지 큰 문제를 해결해야만 합니다. 첫 번째 문제를 해결하기 위해 generalizable cross-modal 3D TF 구조인 PointSO를 제안한 것이었는데, open-world spatial orientation 이해를 위한 robustness와 범용성을 목적으로 둡니다.그리고 이 PointSO를 효과적으로 학습하기 위해 인터넷 scale의 대규모 orientation-text pair 데이터셋인 OrienText300K를 구축한 것입니다. 흔히 human-fuel이라 하는 비싼 로봇 teleop 데이터는 아니고, GPT-4o에 프롬프팅하여 자동으로 레이블이 지정하고 검수하는 방식으로 구성했습니다. OrienText300K는 다양한 일상 객체의 350K 개 이상의 3D 모델로 구성됩니다. 대규모인 덕분에 open-set이나 unseen에 대응가능할 정도의 PonitSO를 학습시킬 수 있었던 것으로 보이네요.
이제 두번째 문제입니다. 앞선 PointSO로 뽑게 될 semantic orientation을 로봇이 위치 및 방향 제약 조건 모두에서 조작 작업까지 이끌어가기 위해선 두번째 문제인 VLM 시스템에 어떻게 통합할거냐인데, 이는 방법론 파트에서 자세히 다루겠습니다.
자 사실 intro가 요약하면 결국, 본 주제의 문제정의, 주장과 근거, 본 논문의 큰 그림에 대한 설명이었기 때문에 리뷰 소개글에 먼저 큰 그림을 요약해서 말씀드린 거와 연결지어서 contribution 정리하고 넘어가겠습니다.
첫째, PointSO를 도입. PointSO는 오픈월드 환경에서 새로운 객체의 semantic direction을 추론하는 orientation base model로써 작용. 둘째, OrienText300K을 학습 데이터셋 구축. semantic directions로 annotation된 대규모 3D 모델 데이터셋으로, orientation 모델인 PointSO 학습에 기여. 셋째, 강력한 VLM에 향상된 공간 이해를 결합한 통합 시스템인 SoFAR를 개발하여 위치 정보와 orientation이 모두 필요한 복잡한 로봇 조작도 가능하게 함. 넷째, 6-DoF SpatialBench 및 Open6DOR V2 제안. orientation-aware한 spatial VQA 벤치마크와, open-loop 및 closed-loop 방식의 open-world 6D rearrangement 전략을 평가하기 위한 포괄적인 로봇 조작 벤치마크.
2. Semantic Orientation: Connecting Language and Object Orientation
A. Definition of Semantic Orientation
기존에 객체의 방향은 주로 쿼터니언이나 오일러 각도 같은 수학적 표현으로, 특정 기준 프레임 안에서 상대 회전을 정의하는 식으로 다루어졌습니다. 하지만 실제 상호작용의 관점에서 보면, 객체 방향은 단순한 좌표계 속의 회전값 이상입니다. 대부분의 경우 어떤 특정 의미와 맞닿아 있으며, 인간도 객체의 방향을 훨씬 더 의미적이고 비기준적인 방식으로 이해합니다.
예를 들어 플러그를 충전기에 꽂을 때를 생각해보면, 결국 금속 단자의 방향이 충전기 소켓의 바깥쪽과 일치해야 “꽂기”라는 동작이 가능합니다. 즉 단순한 회전값이 아니라 “꽂을 수 있는 방향”이라는 의미론적 속성을 전제로 이해하게 되는 것이죠.
이런 맥락에서 저자들은 객체의 의미론적 방향(Semantic Orientation)을 다음과 같이 정의합니다. 객체 X와 언어 설명 ℓ이 주어졌을 때, 해당 의미론적 방향 s_X^{\ell} 은 설명 ℓ과 의미적으로 일치하는 객체 중심의 단위 벡터로 표현됩니다.
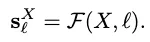
여기서 ℓ은 일반적인 공간 방향(예: 앞, 위)일 수도 있고, 객체의 특정 부품(예: 손잡이, 뚜껑)일 수도 있으며, 더 나아가 조작 목표(예: 쏟기, 꽂기)일 수도 있습니다. 중요한 점은 이 설명이 반드시 객체의 실제 사용 맥락과 의미적으로 대응되어야 한다는 것입니다. 결과적으로 객체 X는 다양한 언어 설명 ℓ에 따라 다양한 기능 또는 속성에 해당하는 여러 의미론적 방향을 가질 수 있으며, 이는 의미론적 방향 집합 \(S_X = \{s_{X}^{\ell_1}, s_{X}^{\ell_2}, …, s_{X}^{\ell_n}\}\)을 형성합니다. 이렇게 정의된 의미론적 방향 집합을 통해, 객체의 회전 자체를 단순한 좌표계 기준이 아니라 의미론적 방향 변환으로 특징지을 수 있게 됩니다.
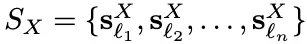
B. Robotic Manipulation via Semantic Orientation
결국 Semantic orientation(의미적 방향성)은 단순히 “방향을 나타내는 또 하나의 표현”을 넘어, 다양한 방향 관련 지식을 추상화할 수 있는 강력한 표현 방식이라고 볼 수 있습니다. 특히 로봇 조작이랑 연결 짓자면 가장 밀접하게 관련된 것은 물체의 재배치(reorientation) 문제로 이어지게 됩니다.
구체적으로는, 특정 물체 X의 초기 관찰값과 원하는 재배치를 명시한 작업 명령 c가 주어졌을 때, semantic orientation을 활용하여 물체 회전이 어떻게 이루어져야 하는지를 결정할 수 있습니다. 절차는 이렇습니다. 먼저, 작업 명령 c에서 원하는 방향이 명확하게 드러난 semantic orientation 설명 집합 {lc}를 식별합니다. 예를 들어, “병을 뒤집어 땅에 놓아라”라는 명령은 “병의 위쪽 방향”이라는 semantic orientation을 식별해야 하며, 이때 원하는 방향은 지면에 수직인 z축 좌표계에서 (0, 0, −1)입니다. 이후, 초기 관찰 X로부터 semantic orientation을 추출하고, 이것을 목표 방향과 정렬하기 위해 필요한 회전을 계산함으로써, 물체가 어떻게 재배치되어야 하는지를 효과적으로 결정할 수 있습니다. 물체 재배치뿐만 아니라, semantic orientation은 전통적인 instance-level 및 category-level 방향성, 나아가 cross-category 방향성까지 연결될 수 있습니다. 구체적으로, 우선 하나의 semantic orientation 집합을 직교화하면 개별 물체의 인스턴스 수준 기준 좌표계를 정의할 수 있습니다. 동일한 category의 물체들에 대해 일관된 언어적 설명을 부여하면, semantic orientation 집합들이 일치하게 되고, 이를 통해 category-level의 일관된 기준이 마련되어 category-level orientation을 도출할 수 있습니다. 더 나아가, 동일한 언어적 설명을 서로 다른 category에 적용하면, cross-category level의 일관된 semantic orientation 집합이 형성되고, 이를 기반으로 cross-category 기준 좌표계가 도출될 수 있습니다. 따라서, 이 접근법은 semantic orientation을 기반으로 orientation 이해를 구축하며, 특히 open-world 환경에서의 객체에 대해 open-ended 설명을 바탕으로 이러한 방향을 추정하는 학습에 초점을 둡니다.
C. OrienText300K: Orientation-Text Paired Data at Scale
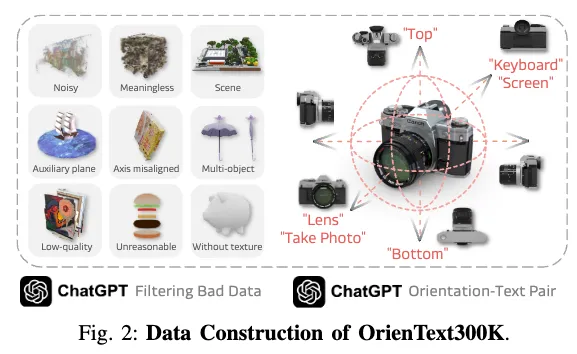
앞선 문제 정의에서 중요한 포인트는 결국 open-world 환경에서 semantic orientation을 추론할 수 있는 범용 모델을 학습해야 한다는 것이었습니다. 이를 위해 저자들은 OrienText300K라는 새로운 대규모 데이터셋을 구축합니다. 핵심은 단순히 3D 객체 모델을 모으는 것이 아니라, 거기에 의미론적 방향(semantic orientation) annotation을 붙여 언어와 방향을 연결한 학습 데이터를 만드는 데 있습니다.
- Scalability 관점 semantic orientation은 기본적으로 객체의 정규화된(canonical) 좌표계에서 여섯 개의 직교 방향(앞, 뒤, 위, 아래, 왼쪽, 오른쪽)에 의해 정의될 수 있습니다. 다행히도 대부분의 웹 기반 3D 모델들은 이미 canonical setup이 되어 있기에(물론 축 반전 axis flip 문제는 존재), 이를 활용할 수 있습니다. 따라서 저자들은 multi-view rendering을 수행한 뒤, GPT를 통해 자동으로 언어 설명을 붙이고, 특정 방향과 연결시켜 annotation을 대규모로 확장합니다.
- Data Source 확장을 위해, Objaverse(약 80만 개 인터넷 3D 모델)에서 OrienText300K를 구축합니다. 그러나 인터넷 데이터 특성상 노이즈가 많고 품질이 고르지 않기 때문에, 조명 환경을 세밀하게 세팅해서 Blender 기반 렌더링을 새로 진행하여 800만 장 이상의 high-fidelity multi-view 이미지를 생성했다고 합니다.
- Data Filtering 데이터를 무작정 다 쓰면 노이즈가 심하기 때문에 filtering 전략을 도입합니다. 조건은 6가지였습니다: 1) 정규 직교 뷰만 허용 (랜덤 뷰는 제거). 2) 바닥이 없는 깨끗한 객체. 3) 공간적 추론이 가능한 합리적 객체 4) 고품질 객체 (흐릿하거나 잘못된 샘플 제거). 5) 식별 가능한 객체 (무의미한 고체 같은 추상 객체 제거). 6) scene 객체 제외 (3D 장면을 묘사한 샘플 제거).
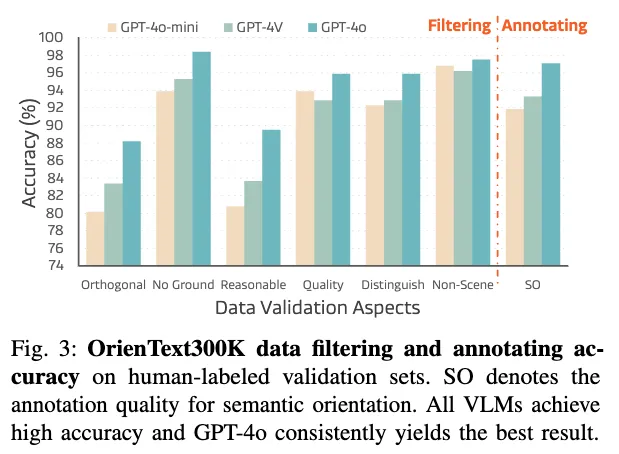
이 과정은 수작업이 비현실적이기에, GPT-4o를 데이터 필터로 활용(최근 연구에서 대규모 VLM(Vision-Language Model)이 2D 또는 3D 이미지 기반 판별기(human-aligned judger) 역할을 할 수 있음이 확인된 바)하여 multi-view 이미지를 prompt와 함께 주고 필터링을 자동화했다고 합니다. 결과적으로 35만 개 이상의 깨끗한 샘플을 확보하여 노이지함을 대폭 줄였다고 합니다.
- Data Annotation Annotation 또한 GPT-4o를 활용합니다. Blender로 생성한 6개 직교 뷰와 추가적으로 4가지 45도 대각선 뷰까지 함께 GPT에 제공하면, GPT가 언어 설명과 가장 잘 대응되는 방향을 자동으로 골라내 semantic orientation label을 붙입니다.
- Quality Validation 마지막으로 검증을 위해 208개 샘플에 대해 사람이 직접 라벨링한 validation set을 만들고, GPT-4o가 필터링과 어노테이션을 얼마나 잘 수행했는지 확인했습니다. 그 결과, Filtering 정확도 88.3%, Annotation 정확도 97.1%로, 신뢰할 만한 수준임을 피력했습니다.
D. PointSO: A Cross-Modal 3D Transformer for Semantic Orientation Prediction
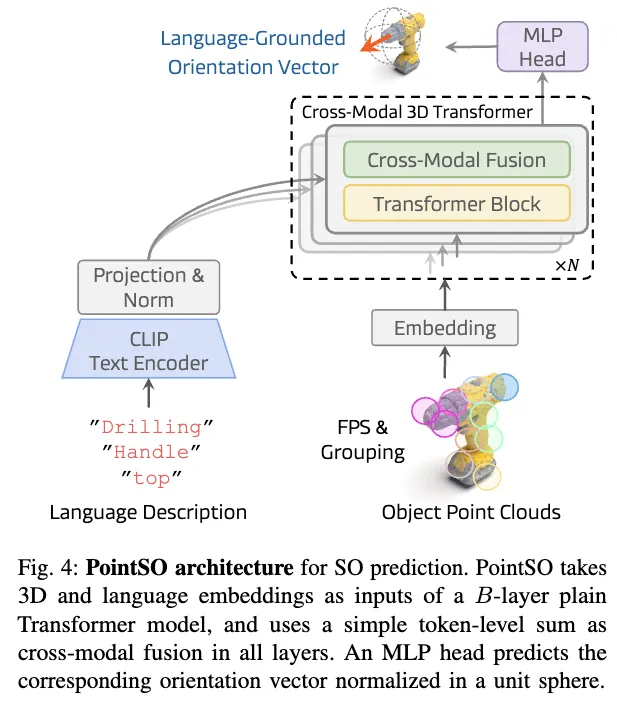
저자들이 제안하는 핵심 모델은 PointSO라는 cross-modal 3D Transformer 기반 아키텍처입니다. 큰 그림은 간단합니다. 객체의 3D 포인트 클라우드와 언어 설명을 동시에 입력받아, 그에 대응되는 semantic orientation을 출력하는 구조입니다.
1) 3D 및 언어 임베딩 (3D and Language Embeddings)
먼저 객체의 3D 포인트 클라우드 X = {x_i \in \mathbb{R}^3 | i=1,2,\dots,N} (즉, N개의 (x,y,z) 좌표)와 임의의 언어 설명 ℓ을 각각 임베딩 공간으로 매핑합니다. 3D 입력은 PointNet 기반 네트워크를 활용해 임베딩합니다. Farthest Point Sampling(FPS)으로 seed point center를 뽑고, KNN을 이용해 포인트들을 그룹화하여, 포인트 클라우드를 여러 cluster로 그룹핑으로 나누고, 이걸 PatchEmbedding을 통해 로컬한 기하학적 특징에 대한 token 임베딩하는 방식입니다. 추가로 [CLS] 토큰을 붙입니다.
언어 입력은 freezed CLIP의 글로벌 텍스트 피처를 활용합니다. CLIP이 생성한 텍스트 임베딩을 cross-modal fusion 입력으로 쓰는 구조입니다.
2) 크로스모달 융합 (Cross-Modal Fusion)
포인트 클라우드 token과 텍스트 임베딩을 Transformer 내부에서 layer-wise로 결합합니다. 여러 방식(예: cross-attention, adapter, 채널 차원 concat 등)이 가능하지만, 저자들은 텍스트 token 전체 합을 포인트 token마다 주입하는 방식이 가장 단순하면서도 효과적임을 보였다고 합니다. 이는 언어 길이가 상대적으로 짧아 per-token attention보다 global sum이 오히려 효과적이었기 때문입니다. 마지막으론 MLP head로 orientation을 예측합니다.
3) 최적화 (Optimization)
- F_{SO}는 PointSO 모델(파라미터 \theta_{SO}로 정의)을 나타냅니다.
- OrienText300K 데이터셋의 각 객체 포인트 클라우드 X_i는 언어 라벨 집합 L_i = {\ell_j^i, j=1,2,\dots,Q} 와 대응되는 의미적 방향 집합 S_i = {s_j^i, j=1,2,\dots,Q} 으로 주어집니다. 최적화 목표는 예측된 방향과 정답 의미적 방향 간의 음의 코사인 유사도(negative cosine similarity) 를 최소화하는 것입니다
- 학습은 OrienText300K 데이터셋을 기반으로 진행됩니다. 각 객체 X_i에는 언어 설명 집합 L_i와 그에 대응되는 semantic orientation ground truth S_i 가 주어집니다.
PointSO의 출력 \mathcal{F}_{SO}(X_i,\ell_j) 과 실제 정답 s_j^i간의 코사인 유사도를 최소화하는 방식으로 학습합니다. 즉, negative cosine similarity loss:
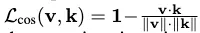
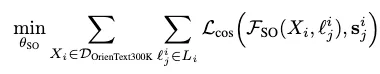
를 최소화하는 방향입니다.
3. Methods (SoFAR: Semantic Orientation Bridges Spatial Reasoning and Object Manipulation)

앞서 저자들의 제안 모델인 PointSO는 object-centric한 공간적 방향성 이해를 위한 off-the-shelf 솔루션을 마련했지만 이러한 객체 중심 공간 이해를 scene-level의 공간 추론으로 확장하는 방법은 여전히 불분명했고, 이를 high-level에서의 VQA 이해와 물리적인 조작 관점 모두 고려하며 끌고 가기 위해서 Florence2 + SAM과 VLM을 결합한 파이프라인 형식을 취하게 됐습니다.
3-A에선 orientation-aware 3D scene graph의 구성 방법을, 3-B에선 spatial-aware 작업 추론 및 로봇 조작을 위한 계획 방법론에 대한 설명으로 들어갑니다.
A. Orientation-Aware Scene Graph from RGB-D
SoFAR의 첫 단계는 RGB-D 입력을 orientation-aware 3D scene graph로 변환하는 과정입니다.
[Task-Oriented Object Segmentation]
- 주어진 언어 질의 Q로부터 VLM을 활용하여 task와 관련된 object phrase set \mathcal{P} = \{p_i\}_{i=1}^M을 먼저 추출합니다.
- 그런 다음 SAM을 활용해 영상에서 객체별 3D point cloud X_i를 분리합니다.
- 객체마다 ID를 부여(Set-of-Mark prompting 활용), 이후 VLM이 각 객체의 task-oriented 언어 설명 집합 L_i를 생성합니다.
- 마지막으로 PointSO를 통해 각 언어 설명에 맞는 semantic orientation S_i를 추출합니다.
[Orientation-Aware 3D Scene Graph]
분할된 객체 집합 X을 기반으로 scene graph G=(V,E)를 만듭니다. 여기서 각 노드 o_i \in \mathcal{V}는 아래 네 가지 semantic + spatial 속성을 포함합니다.
- (1) 객체 이름 p_i와 고유 ID
- (2) 객체 중심 좌표 c_i = (x,y,z)
- (3) 객체의 3D bounding box 크기 b_i = (h,w,l)
- (4) semantic orientation 집합 S_i와 task-oriented 언어 설명 L_i
또한 edge e_{ij}는 두 객체 간 상대적 위치와 bounding box 비율 관계를 담습니다.
즉, SoFAR의 scene graph는 단순히 “무엇이 어디 있다”라는 수준을 넘어서, “무엇이 어디 있고, 어떤 방향을 의미적으로 가져야 한다”까지 반영된 orientation-aware scene graph를 제공합니다.
B. Spatial-Aware Task Reasoning
앞서 SoFAR가 orientation-aware scene graph를 구축하는 단계까지 설명했다면, 이제는 이 graph를 실제로 reasoning과 manipulation planning에 어떻게 활용하는지가 핵심입니다. 저자들은 이를 두 가지 레벨에서 풀어냅니다. 이를 위해 저자들은 Chain-of-Thought(CoT) reasoning을 활용합니다.
1) Chain-of-Thought Spatial Reasoning
로봇 조작 문제는 본질적으로 강체의 위치와 방향을 바꾸는 것으로 볼 수 있습니다. 따라서 VLM이 단순히 결과를 내뱉는 것이 아니라, “어떤 transformation을 수행해야 하는가”를 단계적으로 사고할 수 있도록 유도하는 것이 중요합니다.
- 언어 질의 Q와 scene graph 내 객체 노드들을 분석합니다.
- 각 객체에 대해 원하는 위치·방향을 산출하기 위해 분석적 계산 과정을 수행합니다.
- 최종적으로 task에서 요구하는 목표 위치 \tilde{c}_i와 semantic orientation \tilde{S}_i를 출력합니다.
이후 객체의 초기 상태 (c_i, S_i)와 목표 상태 (\tilde{c}_i, \tilde{S}_i)가 주어지면, 6-DoF 변환 행렬 P_i를 도출할 수 있습니다. 구체적으로는 이동 벡터 t_i = \tilde{c}_i - c_i를 계산하고, 회전 변환 R_i는 S_i와 \tilde{S}_i를 정렬시키는 문제로 풀어 Kabsch-Umeyama 이라는 알고리즘으로 해결합니다. 두 점군(또는 벡터 집합)의 대응점들이 주어졌을 때 이들을 최적의 rigid(또는 similarity) 변환으로 정합하는 방법이라고 하는 데 깊게 들어가니 제가 와닿질 않아서 해당부분은 질문 주시면 추가로 더 찾아서 답변드리도록 하겠습니다.
어찌됐든, 단순히 “이 물체를 이 위치에 둬라”가 아니라, 그 과정에서 언어 → reasoning → 6D 변환 행렬까지 이어지는 CoT 기반의 공간 추론 과정을 formalize했다는 점이 의미가 있다고 볼 수 있겠습니다.
2) Low-Level Motion Execution
이제 남은 건 이 변환을 실제 로봇 동작으로 옮기는 건데, 저자들은 CoPa 프레임워크와 유사하게 task-oriented grasping + motion planning을 결합하는 방식으로 마무리합니다.
Florence-2와 SAM으로 조작 대상 객체 point cloud를 얻고, GSNet을 통해 grasp pose 후보를 생성합니다. grasp 후보들 중에서는 grasp score와 로봇 접근 방향과 z축 정렬 정도를 균형 있게 고려하여 최적 pose를 선택합니다. 이후 SoFAR는 텍스트 지시에 맞춰 목표 translation/rotation을 정의하고, grasp pose에서 placement pose까지의 변환을 예측합니다. 마지막으로 OMPL을 사용해 motion planning을 위한 collision-free trajectory를 생성합니다. 이때 조인트 초기 위치를 중간 지점으로 설정해, 물체와 환경 사이 충돌을 줄이고 부드러운 모션을 유도하게했다고 합니다.
4. Experiments
A. Benchmarks
저자들은 SoFAR의 공간 추론 및 로봇 조작 효과를 검증하기 위해 두 가지 새로운 벤치마크를 제안합니다.
1) Open6DOR V2
시뮬레이션 기반 평가를 위해 기존 Open6DOR 벤치마크를 확장하여 Open6DOR V2를 제안합니다. 기존에는 주로 perception 관점에 머물렀던 것을 넘어, execution까지 포함시켜 closed-loop policy와 비교할 수 있도록 설계했습니다. execution task 추가로 와 비교할 수 있도록 저자들이 확장했다고 합니다. 해당 확장 벤치마크 버전을 Open6DOR V2라고 제안했습니다.
- Perception Task: Open6DOR 정의에 따라, 모델은 RGB-D & language instruction을 입력으로 받아 대상 객체의 translation & rotation을 직접 출력하게끔 해야합니다.
- Execution Task: Open6DOR scene을 재현해서, robosuite 시뮬레이션 환경에서 실행이 가능하도록 구축했다고 합니다. 단일 객체 장면은 제외하여 공간적 관계 이해를 더 잘 평가할 수 있도록 했고 인풋은 위 Perception task와 동일하게 받는다고 합니다. robosuite 시뮬레이션 환경 기반이면서, LIBERO 가 확립한 형식을 채택했는데, 조작 과정을 끝까지 실행하고, 최종 위치와 orientation이 평가 지표가 됩니다.
2) 6-DoF SpatialBench
두 번째로 저자들은 6-DoF SpatialBench라는 새로운 VQA 기반 평가를 제안합니다. 이전의 벤치마크들 [SpatialBot, SpatialRGPT, EmbSpatial-Bench, Space3D-Bench] 등은 주로 VLM의 spatial position understanding에만 집중했으며, orientation 정보는 거의 고려하지 않았습니다. 또 대부분의 평가 요소가 “to the left,” “nearest” 와 같은 상대적이고 정량화되지 않은 관계에 초점을 맞추었으며, 정량적 지표는 부족했습니다. 6-DoF SpatialBench는 position, orientation을 동시에 평가하고자 했습니다.
- 총 223개의 human annotated 샘플로 구성되어 있으며, 질문 유형에 따라 position task과 orientation task로 나뉘고, 각 task는 RGB image와 4지선다형 질문으로 구성됩니다.
- 숫자 기반 질의(예: 개수 세기), 위치 관계(예: 왼쪽/오른쪽), 방향(객체의 정면 방향) 등의 task질의가 있고, 모델은 이미지를 분석하여 네 개 선택지 중 정답을 선택하는 방식입니다.
B. 6-DoF object rearrangement evaluation in Simulation
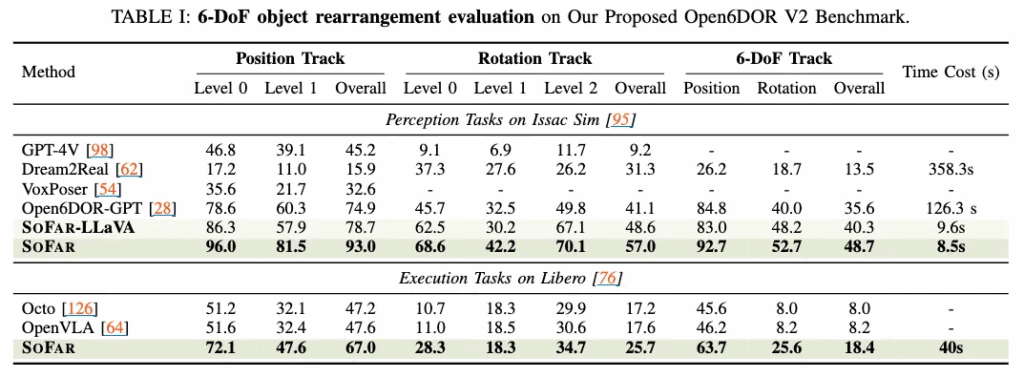
Open6DOR V2 벤치마크 실험 결과입니다.
Perception track에서는, 원래 Open6DOR 실험에서 사용된 동일한 베이스라인과 결과를 비교했다하는데, SOFAR는 모든 베이스라인을 능가하며, 효과적인 공간 이해 능력과 zero-shot generalizability를 보입니다. 다만 저희 팀이 voxposer의 속도를 짧게 경험해본 입장으로서는, 다른 벤치마크 환경에서의 gpt-4v와 voxposer에 대한 time cost를 리포팅하는 게 어려운 건 아닌 것 같은데, 안한 점이 조금 아쉽네요.
Execution track에서는, 실행 성공 여부를 평가하기 위해 객체의 초기 pose와 최종 pose를 기록했습니다. 사전학습된 Octo 와 LIBERO로 finetuned된 OpenVLA 를 베이스라인으로 사용했으며, 모든 실험은 동일한 LIBERO 환경에서 수행되었다고 합니다. 이때 OpenVLA는 도메인 간 격차를 최소화하기 위해 finetuning되었다고 하는데, 그럼에도 불구하고, Octo와 OpenVLA는 낮은 성공률을 보였고, SOFAR는 약 40%의 성공률 상승을 보였습니다. 여기도 time cost 리포팅 안한 게 아쉽습니다. 이쯤되니 일부러 안한 것 같기도 하네요.
추가적으로 저자들은 일부 객체가 본질적으로 파지가 어려운 특성을 가지고 있고, 이는 실행 성공을 크게 방해할 수 있기에 Open6DOR V2에서 더 나은 성능을 보여주기 위해서는 prehensile grasping(손가락 등으로 잡는 파지)이나 적응형 기술(adaptive techniques)과 같은 보다 강력한 조작 전략이 필요함을 제안합니다.
C. Zero-shot Object Manipulation Evaluation in Simulation
구글에서 만든 SimplerEnv는 실제 로봇 조작 환경을 모사하기 위해 설계된 오픈소스 시뮬레이션 평가 환경 모음인데, 재현성과 실세계 시나리오와의 정합성을 강조한 벤치마크입니다. 저자들은 SIMPLER 환경에서도 Google Robot 과 WidowX+Bridge 태스크를 제로샷으로 평가합니다. 평가 셋업으로 플래닝 모듈이 산출한 경로를 로봇이 그대로 수행하며, 단일 시도 실패 시 소수의 재시도를 허용해 “유사 폐루프” 효과를 부여합니다.
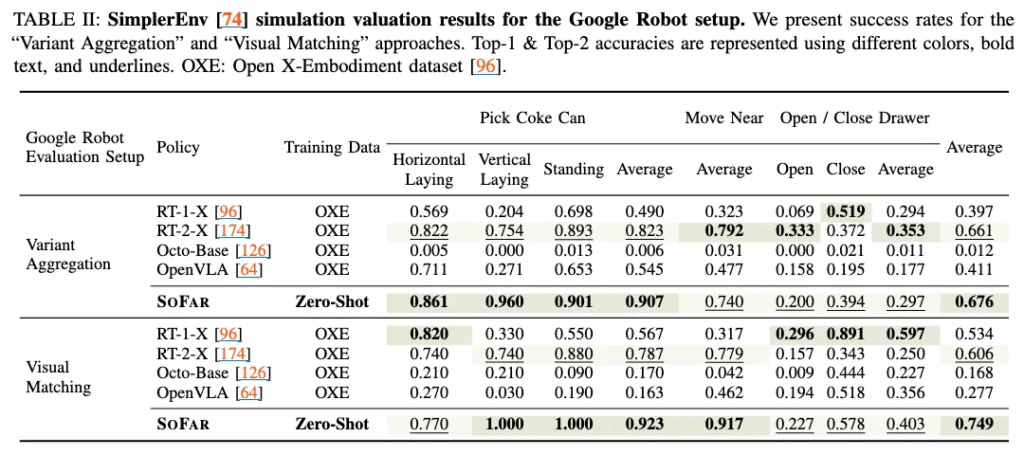
Table 2,3 전반에서 SoFAR가 대부분의 베이스라인(Octo, OpenVLA 등)을 앞서는데, Google Robot 세트에서 평균 성능은 가장 높고, Pick Coke Can / Move Near 류의 단순 변환 태스크에서 강세를 보이는데, 오히려 저자들이 물체의 semantic한 방향을 고려한 액션 태스크에 해당하는 open/close drawer같은 경우는 생각보다 낮은 성능을 보였습니다. 이건 약간 저자들의 설계한 방향과 반대되는 결과이기에 좀 의아하긴 한데, 생각해보면 결국 아무리 high-level에서 물체중심의 semantic orientation을 잘 추정했다고 해도, low-level action이 OMPL 기반의 motion planning 이라는 게 Failure 요소로 작용하지 않았을까 싶습니다.
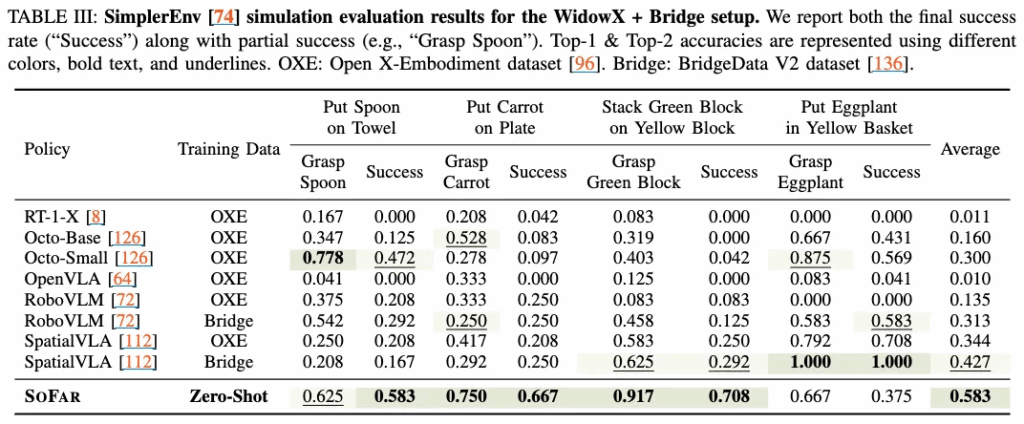
WidowX+Bridge 세트에서도 평균 성능은 우위긴 한데, 그립·이동·배치로 이어지는 단계적 변환을 제로샷으로 처리함에 있어서, eggplant를 노란 바스켓에 넣어라를 못한다는 것 역시 아까처럼 의아했습니다. Spoon, Carrot, Block과 다르게 eggplant는 형태가 곡선형이라 orientation 추정이 쉽지 않았나? 아니면 애초에 Grasp성능이 낮으니 GSNet 쪽에 문제가 있었나? 싶긴 합니다.
D. Zero-shot Real-world Manipulation
1) 하드웨어 설정 (Hardware Setup)
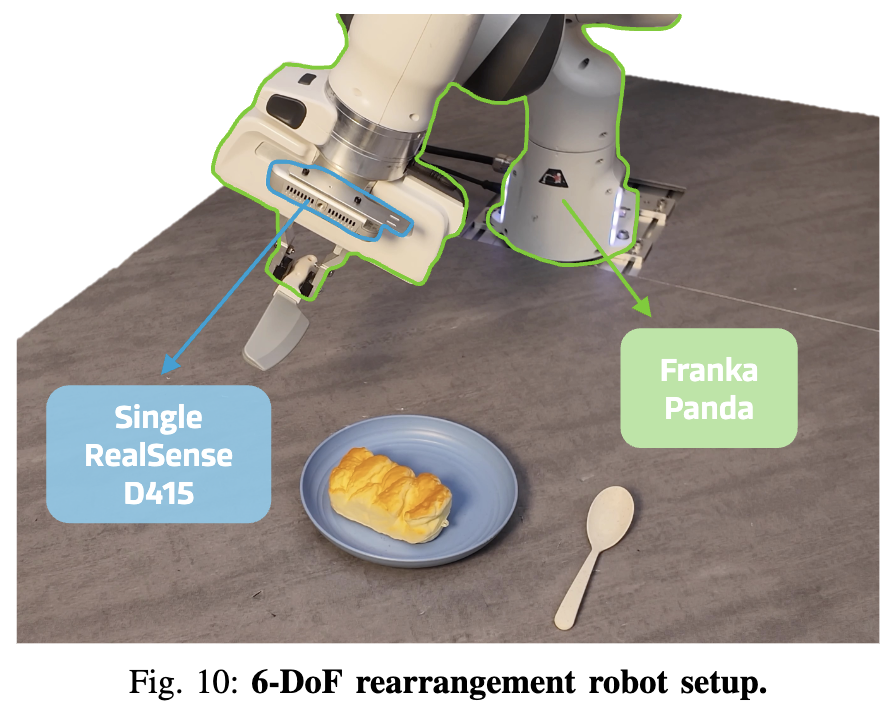
- 하드웨어: Franka Panda + 병렬 그리퍼, wrist에 Intel RealSense D415.
- 태스크/프로토콜: 60개 실세계 rearrangement 태스크, 100종 이상 객체. Position-Simple/Hard, Orientation-Simple/Hard, Comprehensive, 6-DoF의 6개 트랙으로 묶고 각 태스크 3회 반복으로 통계적 신뢰성을 챙기고자 했답니다.
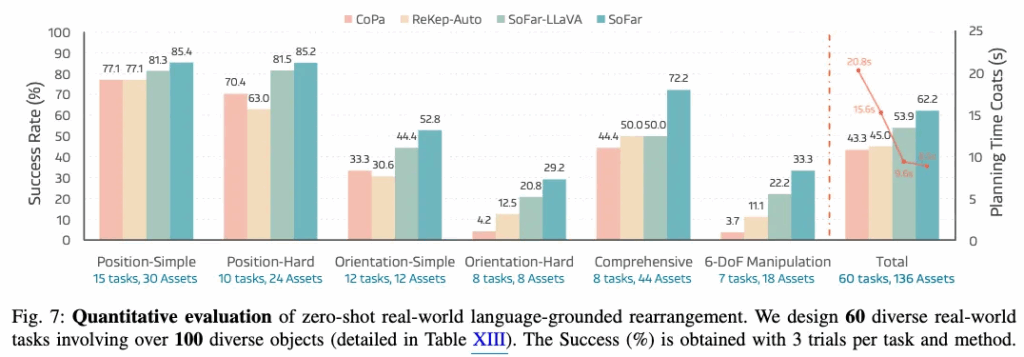
Fig. 7 기준, SoFAR는 대부분 트랙에서 CoPa, ReKep-Auto를 상회하는데, 특히 Orientation-Hard, Comprehensive, 6-DoF 트랙에서 격차가 컸습니다. 총합 성공률에서도 우위이며, 플래닝 시간 오버헤드는 제일 낮았습니다.
추가적으로, SOFAR는 하나의 로봇 형태(embodiment) 에 제한되지 않았습니다.

정성적 실험에서, 그림 6에 나타난 바와 같이 dex hand와 suction cup 과 같은 다른 형태의 로봇으로도 실험을 진행한 모습입니다.
E. Visual Question Answer on 6-DoF SpatialBench
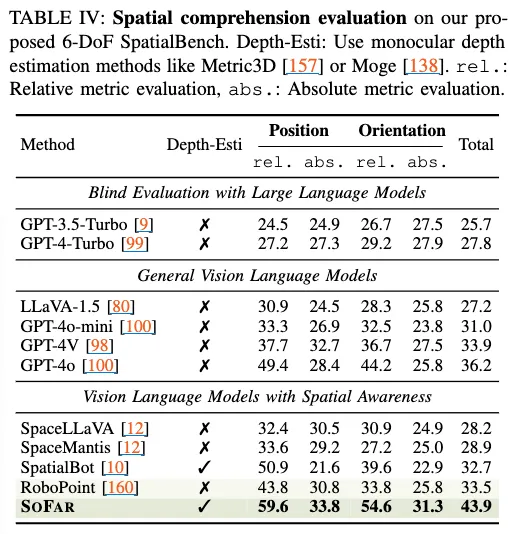
Table 4에서 223개 수작업 라벨 VQA, 위치·방향을 모두 정량 평가(4지선다) 한 모습인데, SoFAR가 position-track과 orientation-track 모두에서 기존 VLM·spatial VLM 대비 우수하며, 평균 기준 18% 이상 높았습니다. scene level의 vqa에서도 방향을 명시적으로 다루고자 할 때 기존 spatial 목적으로 고안된 VLM들 보다 spatial reasoning 능력이 더 있더라~가 되겠습니다.
F. Semantic Orientation Prediction
자유 텍스트 설명을 사용해 객체 포인트 클라우드에서 semantic orientation을 추출하는 것은 도전적인 과제이기에, Objaverse에서 저자들은 128개의 다양한 객체를 수작업으로 어노테이션하고, OrienText300K의 테스트 분할을 구성하여 PointSO의 ‘방향 정확도’도 평가했습니다.
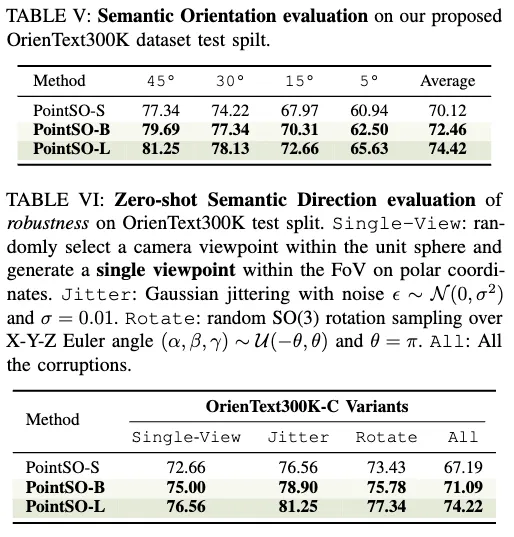
Table 5는 확실히 각도가 작아질수록 더 맞추기 힘들긴 하나, 전반적으로 모델 크기가 커질수록 PointSO-L이 당연히 성능이 좋았고, Table 6은 단일 뷰, 지터, 임의 회전, 다 섞은 혼합 교란 등 강건성 실험에서도 Large모델이 전반적 우위였습니다. 이는 자동 어노테이션 데이터로 학습한 cross-modal 3D 변환기가 각종 뷰/노이즈 교란에 견딜 만큼 충분히 일반화됐다는 걸 시사한다고 저자들은 주장했습니다.
Quantative Results & Failure Case

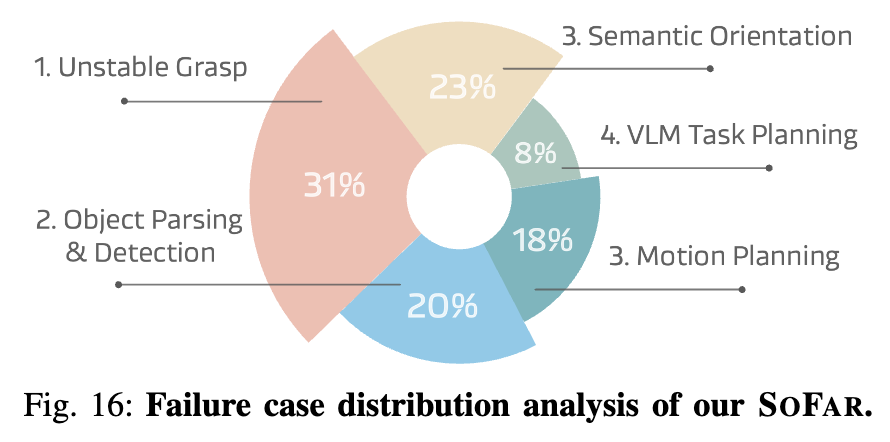
마지막으로 real world에서의 PointSO의 정성적인 시각화 결과와, failure case의 분석 결과입니다.
특히 failure case의 경우 사실상 unstable grasping과 object parsing, motion planning의 실패 결과가 절반 이상의 비율을 차지하는 것으로 보았을 때, 결국 GSNet과 OMPL, Florence2+SAM 등의 off-the-shelf 모듈들을 사용하는 것으로 인해 일정부분 감수해야되는 결과가 아니었나 싶습니다. 그래도 저자들이 주로 손댄 semantic orientation도 23%의 비율로 실패율을 차지하는 것을 보면 해당 부분에서도 여전히 개선할 여지가 다분하다로 유추해볼 수 있겠습니다.
Articulated Object Evaluation
안녕하세요 재찬님 리뷰 감사합니다.
지금 생각해보면 어디에 있는지도 중요하지만 어떤 방향으로 존재하는지, 어떤 방향으로 상호작용 해야 task를 성공할 수 있을지를 아는것도 꽤나 중요한 문제인데, 저는 이런 방향으로는 고민을 많이 안 해본것 같습니다 허허..
cross modal fusion을 진행할 때 cross attention같은거 말고 global sum으로 fusion해준것은 input 텍스트가 단어 단위로만 들어와서 그렇다라고 이해해도 될까요?
아래부터는 좀 개인적인 질문인데 semantic한 orientation을 아는것은 굉장히 중요하고 발전 시켜야하는 방향이라는 생각이 드는데, 지금처럼 high level에서 output을 주는것을 지나서 IL/RL을 진행할 때 좀 더 low level에서 영향을 미치는 쪽으로 representation을 통합시키면서 발전시킬 수 있을까요? 결국 작업 성공률로 이어질 때 OMPL이 약간 발목을 잡지는 않을까 싶습니다..
또 저희가 자주 본 옷 접기, 서랍 여닫기 등 rigid한 단일 물체외에 deformable하거나 articulation이 있는 물체에 대한 orientation에 대한 발전 가능성이 언급됐나요? 재찬님이 추후에 orientation 연구를 하실 생각이 있으신지, 그렇다면 어떤 방향을 생각하고 계신지 궁금합니다.
안녕하세요 영규님, 댓글 감사합니다.
1. 네, 저자들의 언급처럼 input 텍스트 길이가 짧아서 그런 거라고 이해해주시면 됩니다.
2. 저도 그런 쪽으로 발전하고 싶은 생각이 추후에 있습니다. 본 논문은 일단 사전에 형식과 구조를 지정해야되는 scene graph 구조를 semantic orientation 정보까지 담아 high-level output으로 low-level(OMPL)에 던져준 식이었는데 이러면 역시 OMPL에게 motion planning을 의존하기에 발목을 잡을 수 있죠. 저는 결국엔 이런 것들이 latent feature space 상에서 표현되어야 한다고 생각합니다. 모든 scene graph 형식과 구조를 매번 지정해줄 수는 없기 때문이죠. 즉 앞인 System2(VLM)에서 semantic한 latent feature를 System1(IL기반 action 모듈)에 영향을 주는 ‘Dual-System’ 방식을 기반으로 해서 해당 latent feature 내에 어떤 semantic 한 feature를 담을까를 고민하는 기술들이 발전할 것이라고 기대하고 있고, 저 또한 그러한 방향으로 연구하고 싶은 생각이 있습니다. RL에 VLM이 뱉은 high-level semantic output(6d 혹은 orientation)을 활용해서 reward로써 줄 수도 있을 것 같지만, 사실 제가 RL쪽 연구들의 경향을 잘 몰라서 발전가능성은 잘 모르겠네요.
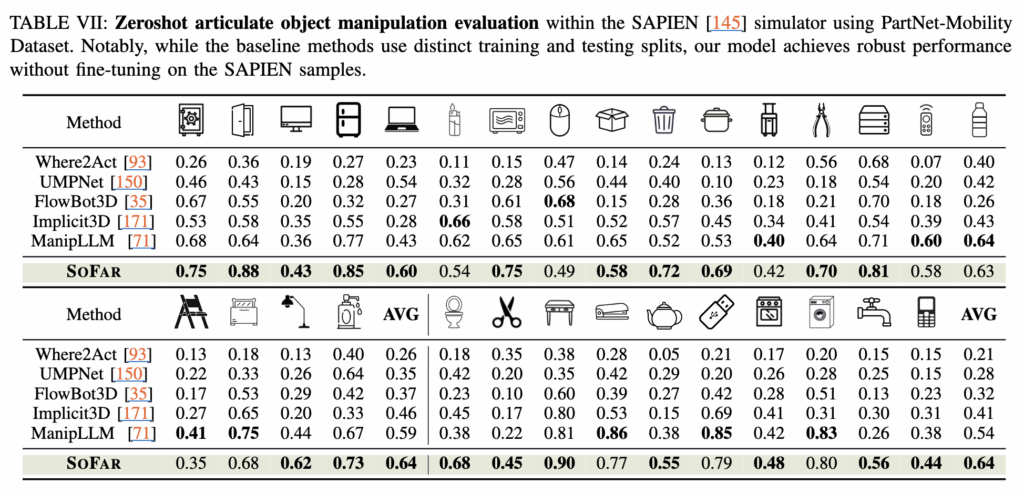
3. appendix에서 찾아보니 zeroshot articulate object manipulation evaluation 에 대한 실험 테이블이 있었습니다. 본 리뷰글 마지막에 업데이트하여 올려놨습니다. deformable에 대한 semantic orientation 접근에 대한 발전 가능성 언급은 없는 것으로 확인됩니다만, 개인적으로는 그것 또한 해결해야될 과제일 것이라고 생각합니다. 저 또한 추후 semantic orientation 정보를 Dual-system에서의 latent feature로써 적용할 수 있지 않을까? 라는 막연한 생각이 있긴 합니다.
재찬님 좋은 리뷰 감사합니다.
해당 연구는 정밀한 작업을 위한 초기 연구로 볼 수 있을 것 같습니다.
‘의미론적 방향’이라는 표현은 해당 논문에서 처음으로 제안하는 것 같습니다. Fig. 2의 “Top”, “Kyeboard” “screen”과 같이 caterory별로 물체에 대한 설명 및 방향 정보가 포함되도록 구축한 것으로 이해하였습니다. 예시를 보면 행동에 해당하는 설명으로 보기는 어려운 상태로 보여, 앞서 인트로에서 이야기한 플러그 꽂기와 같은 작업으로 확장하기에는 어려움이 있을 것 같습니다. 해당 논문에서 수행한 실험 중 ‘의미론적 방향’이 유의미함을 보여주는 실험 및 시나리오가 없었는지 궁금합니다.
안녕하세요 승현님, 댓글 감사합니다.
1. 사실 Fig.1을 보면 ‘cut’도 있고, Fig.2 의 경우는 ‘Take photo’도 있고, Fig.4를 보면 ‘drilling’도 있고 사실 물체에 대한 설명, 방향 정보 외에도 affordance 같은 행동에 대한 설명도 있습니다. 물론 저자들이 인트로에서 언급한 플러그 꽂기에 대한 데모를 보인 흔적은 없어보이고(프로젝트 페이지에서도 찾기 힘드네요), 플러그 구멍에 대한 정밀한 방향 정합이 맞아야한다는 점에서 어려운 작업임에는 확실하나, OMPL로 진행되는 low-level policy를 추후 Dual-system에서의 IL기반 action model로 대체한다면 충분히 확장가능하지 않을까 생각합니다.
2. 마지막으로 ‘semantic orientation’이 저자들이 처음 제안한 개념임은 맞아보이나, 이것에 대한 ablation study가 딱히 없는 점을 꼬집어주신 것 같은데요. 맞습니다. 실험결과를 살펴봐도 이 semantic orientation에 대한 ablation을 보인 실험은 딱히 없더라구요. 뭐 각도 변화를 주면서 평가를 한 건 있지만. 애초에 해당 논문이 아직 arxiv로 남아있는 이유가 이런 부분에서 허점이 있어서 보완하느라 그런 것 같기도 한 것 같습니다.
안녕하세요 재찬님 좋은 논문 리뷰 감사합니다.
리뷰를 읽으면서 로봇 조작에 있어서 객체 중심의 위치뿐만 아니라 semantic orientation의 정보도 매우 중요하다는 것을 이해해서 매우 흥미로웠습니다.
궁금한 점이 몇 가지 있었습니다.
첫 번째는 Dex hand로 실험을 진행할 때 사진을 보면 음료수를 세우는 동작이 있는데, 제가 이해한 바로는 semantic orientation에 대한 정보 덕분에 올바르게 Top 방향으로 세운 것 같아 보였습니다. 기존의 방향에 대한 정보가 부족한 VLM 방식은 이러한 Task를 수행하지 못했나요? 수행했다면 어떤 방식으로 수행했는지 궁금합니다.
두 번째는 일부 객체가 파지가 어려운 특성을 가지고 있어서 성공률을 낮출 수 있다는 글을 보고 궁금증을 가지게 되었는데, 방향 정보를 통해 객체의 파지가 쉬운 곳을 알 수는 없는지 궁금합니다!
안녕하세요 인하님, 첫 댓글 환영합니다.
1. 기존에도 VLM의 reasoning 능력을 활용해서 high-level planning을 수행하고, 여기서의 어떤 bridge가 되는 정보를 low-level policy에 넘겨주는 방식의 연구들이 꽤나 있어왔습니다. 인하님 말씀대로 방향이나 공간정보에 대한 추론 능력이 부족하니, 23년 말~24년 이쯤부터 그걸 보완하기 위한 연구들이 쏙쏙 나오고 있던 찰나였죠.
대표적으로 VLM visual prompting 방식으로 scene내의 물체 grounding 정보를 보완하거나([RSS 24’] MOKA), 더 나아가 grasping part에 대해서 fine-grained part grounding을 수행하고, 해당 SoFAR 논문에서의 학습된 orientation 정보만큼은 아니지만, 그와 유사한 물체 내의 작업 관련 부분에 대한 벡터 정보 제약을 추가하는 식의 연구([IROS 24’] CoPa), 시공간적 추론의 spatial hint 정보가 되는 keypoint 추정 방식을 활용한 연구([CoRL 24’] ReKep) 등등이 있습니다. 저는 이런 식으로 로봇 매니퓰레이션 작업을 위해 high-level planning (with VLM) -> low-level action policy (IK나, IL기반의 VA,VLA, 더 나아가서는 RL) 의 과정으로 hierarchical한 프레임워크 위주로 연구를 follow up하고 있었는데, 해당 연구들 모두 제 과거 x-review를 통해서도 리뷰를 해놓았으니 관심있으시면 찾아보시면 비교 및 도움될 것 같습니다.
2. 파지가 어려운 특성을 가지고 있는 객체라고 하면, articulated object나, deformable object 등이 있을 수 있겠는데요. articulated object 예시로 서랍을 들어볼게요. 본 논문의 방법론을 통해 “open drawer”를 진행하려면 이런 language description에 대해 orientation vecotor를 내뱉도록 대규모로 사전학습된 PointSO 모듈을 통해, 서랍의 손잡이 부분에 대해서 축 방향정보를 뽑아낼 수 있을 것입니다. 그리고 그걸 본 논문의 파이프라인처럼 VLM에서 low-level policy로 넘어가는 bridge가 되는 scene graph 정보에 해당 orientation 정보를 담을 수 있을 것 이고, 그 정보를 토대로 low-level policy에서 manipulation을 수행할 수 있게 되겠습니다. 이런 식으로 articulated object까지는 어느정도 객체의 파지가 쉬운 곳을 알 수 있게 될 것 같습니다. 뭐 물론 orientation 예측이 잘못되거나 손잡이 재질이나 형태가 특이하면 잡기어렵긴 하겠죠. 두번째로 deformable object, 예를 들어 옷 같은 경우는, 재질 자체가 흐물흐물하기도 하고 어느부분을 어떻게 잡아야할지가 명시적으로 추론하기가 참 쉽지 않습니다. 옷이 놓여있는 상태에 따라 다 다르니까요(완전 접혀있어서 형체가 꾸깃꾸깃할수도 있고, 완전 예쁘게 펼쳐져있을 수도 있고). 앞서 언급한 방법론 중에 ([CoRL 24’] ReKep) <- 이 논문이 VLM을 활용한 keypoint 추정 기반으로 deformable object 즉 옷에 대한 접기 작업을 해내긴 했지만, 여전히 deformable object 에 대한 manipulation 작업은 매우 어려운 연구에 속한다고 생각합니다. 나중엔 저도 꼭 해당 문제에 도전해보고 싶네요. 결론은 방향 정보나 다른 공간정보를 통해 객체의 파지가 쉬운 곳을 알 수도 있다! 하지만 방향 정보를 '어떻게' 더 잘 활용할 지가 앞으로의 관건이다!