현재 LLM은 Long-context 입력을 소화할 수 있는 수준으로 빠르게 발전하고 있습니다. 그러나 아직 완벽하지 않은데요, 비교적 짧은 입력만을 소화할 수 있던 기존의 LLM이 데이터베이스 외부의 정보를 활용하기 위해서는 RAG 기법을 사용했었습니다. 외부의 입력에서 쿼리와 직접적으로 연관된 정보만을 선택해 LLM의 입력으로 활용하는 기술이죠. 즉, 데이터베이스나 학습데이터 외의 정보를 LLM이 활용하기 위해 RAG를 활용해 context를 작게 가공하는것에서 부터 LLM이 Long context를 활용하는 방향으로 발전하고 있습니다. 본 논문은 그 중간 과도기로서 RAG를 활용하되 기존 방법보다 더 많은 정보를 LLM에 입력으로 활용하는 방법을 분석을 통해 제시합니다. 리뷰를 통해 자세한 내용을 알아보겠습니다.
개요
최신 LLM은 사용자의 질의인 쿼리와 함께 참고할 수 있는 자료를 제공받습니다. 자료들은 논문 한편에서부터 수권의 책까지 LLM이 입력으로 사용하기에는 상당히 깁니다. 이러한 자료를 답변 생성에 활용하기 위해 RAG 기법이 활용됩니다. RAG란 현실적으로 이러한 보조자료를 모두 LLM의 입력으로 할 수 없으니, 입력을 청크(일종의 Receptive field)로 분할해 놓고, 사용자의 요청인 쿼리와 유사한 청크 집합을 쿼리와 함께 입력으로 제공하는 것입니다. 보통 유사한 보조 자료의 개수를 Top-k개를 설정하여 쿼리와 함께 LLM에 입력하게 되는데요, 그렇다면 보조자료의 개수는 몇가개 좋을까요? 직관적으로는 LLM이 수용할 수 있는 한, 많을수록 좋을것 같습니다.
본 논문은 RAG가 가능한 많은 즉, Long-context를 LLM에 제공할수록 좋다는 직관에 대해 분석합니다. 분석 결과 실제로는 제공되는 정보량이 많을수록 무조건 답변의 생성 결과가 좋지는 않으며, 이러한 정보는 종종 잡음으로 처리되어 오히려 답변의 생성 성능을 하락시키기도 함을 밝힙니다. 정리하면 본 논문은 long-context RAG에 대해 체계적으로 분석합니다. 또한 long-context RAG에서 발생하는 문제에 대한 3가지 해결책을 제시하고 있습니다. 리뷰를 통해 먼저 분석 결과를 살펴보고 이어서 제안한 해결책을 살펴보겠습니다.
Long context RAG의 문제점
# 검색된 context 개수와 RAG 성능간의 관계
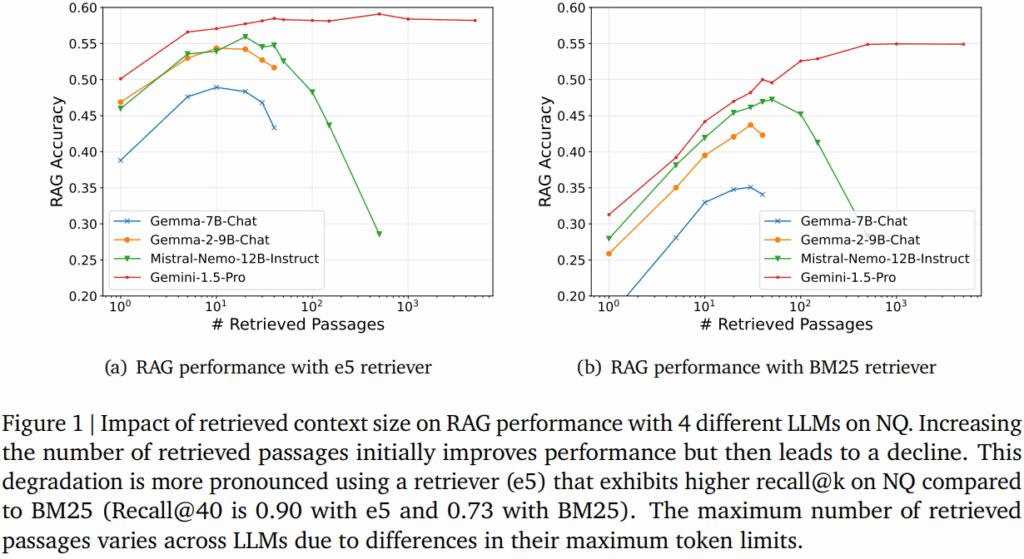
가장 먼저 논문은 RAG를 통해 쿼리와 유사하다고 판별되는 문맥(passages)의 수가 RAG가 생성한 정확도에 어떠한 영향을 미치는시 확인했습니다. 두개의 검색기인 e5와 BM25(performance: e5 > BM25)와 4개의 LLM 모델을 통해 구축한 RAG 프로세스에 대한 실험 결과는 Figure1과 같습니다. 실험에서 확인할 수 있듯이 그래프는 역-U 패턴을 보이고 있으며, 일반적으로 최적의 passage 갯수가 있고 정보량이 많을수록 무조건 성능에 긍정적인 영향을 미치지는 않음을 확인할 수 있었습니다. 그 외에 성능이 좋은 검색기인 e5의 경우 이러한 역-U 패턴이 더욱 도드라졌으며 비교적 비정확한 검색기인 BM25는 passages 증가에 따른 성능 하락이 비교적 약했다는 특징적인 결과도 확인할 수 있습니다.
# 검색기 성능과 LLM의 상관관계
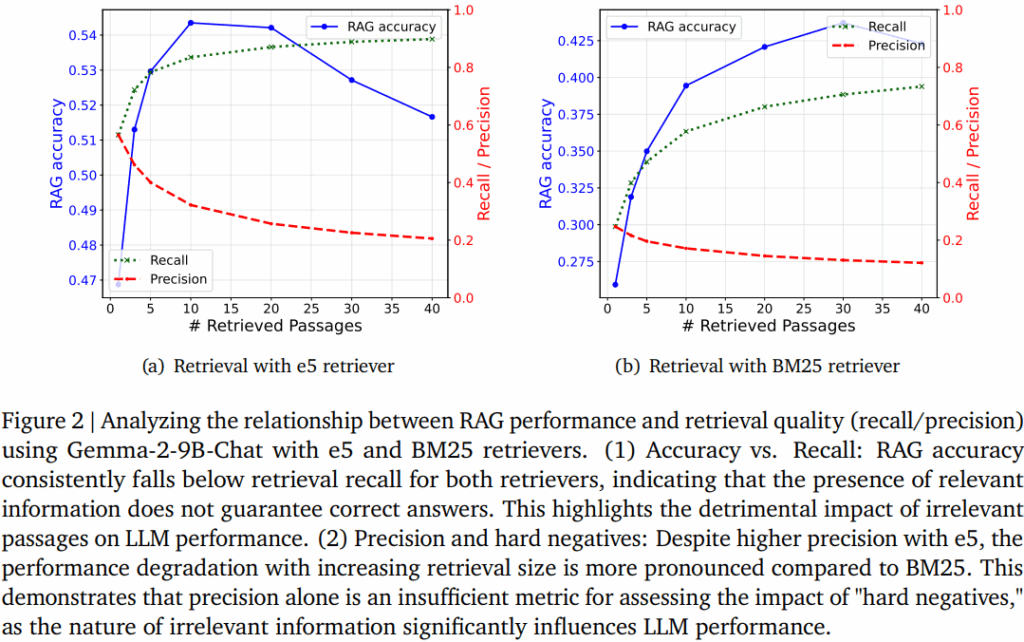
일반적으로 좋은 검색기를 활용해야 RAG 프로세스가 잘 동작할 것으로 예측할 수 있는데요, 첫번째 실험에서 이러한 직관에 반하는 결과를 확인할 수 있었습니다. 그렇다면 너무 많은 검색 결과를 제공하여 관련 없는 정보까지 LLM에 제공된것 아닐까? 하는 의문이 발생할 수 있습니다. 즉, 실험 세팅이 타당한가에 대한 고민까지 이어질 수 있는데요, 해당 실험에서는 검색기의 성능과 RAG 답변 생성의 결과를 분석했습니다. 이번에도 e5와 BM25에 대해 실험을 진행했으며 Gemma-2-9B-chat 모델을 통해 실험을 진행했다고 합니다. 실험 결과 Recall(녹색라인)은 계속 개선을 보였지만 RAG의 성능(파란 라인)은 하락했습니다. 즉, 쿼리와 유사한 결과를 제공했음에도 passage 개수가 너무 많아지면 RAG 성능이 하락하는 역-U 패턴을 보였다는 것을 확인할 수 있습니다.
# Long-context LLM에서 hard negatives의 영향과 중요성
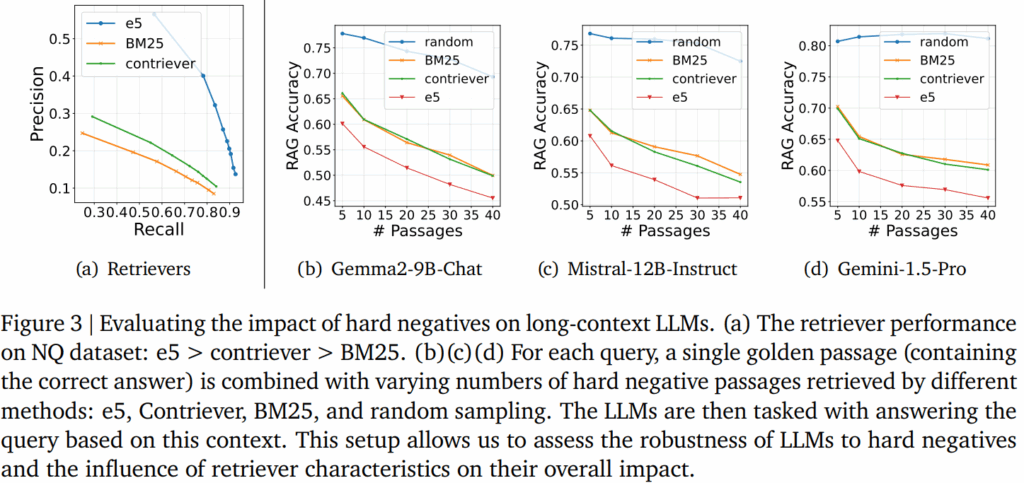
위의 두 실험 결과 long-context RAG는 passage 개수가 특정 역치를 넘어가면 오히려 성능이 하락한다는 문제점과, 해당 문제의 원인이 검색기의 성능(정확도)은 아님을 확인했습니다. 쿼리와 의미적으로 유사한 context를 추가함에도 답변 생성의 성능이 하락하는 원인은 무엇일까요? 하나의 원인으로 우리는 Hard negative를 예측할 수 있습니다. 쿼리와 유사하지만 실제로는 할루시네이션을 이끌 수 있는 검색결과가 허용가능한 passage 개수를 늘릴수록 많이 포함되는 것일수 있다는 것입니다. 이를 실험하기 위해 하나의 정답 문서와 여러 hard negative를 LLM의 입력으로 했을때의 성능을 Figure3으로 제공합니다. 해당 hard negative를 고르기 위해 3가지 검색기(e5, contriever, BM25, random)를 활용해 성능을 보였습니다. 검색기의 성능은 Figure3-(a)에서 확인할 수 있으며 e5 > contriever > BM25 순으로 성능이 좋습니다.
실험 결과 랜덤으로 선출된 hard negative에 비해 검색기를 통해 제공된 hard-hard negative가 RAG 의 성능을 크게 와해시킴에 따라 RAG 성능이 hard negatives에 예민함을 알 수 있었습니다. 또한, 검색기의 성능이 좋을수록, 즉 더욱 어려운 hard negative가 제공될수록(빨간선 e5) RAG의 성능이 낮아짐을 확인할 수 있습니다.
문제점에 대한 해결책
# training-free 해결책
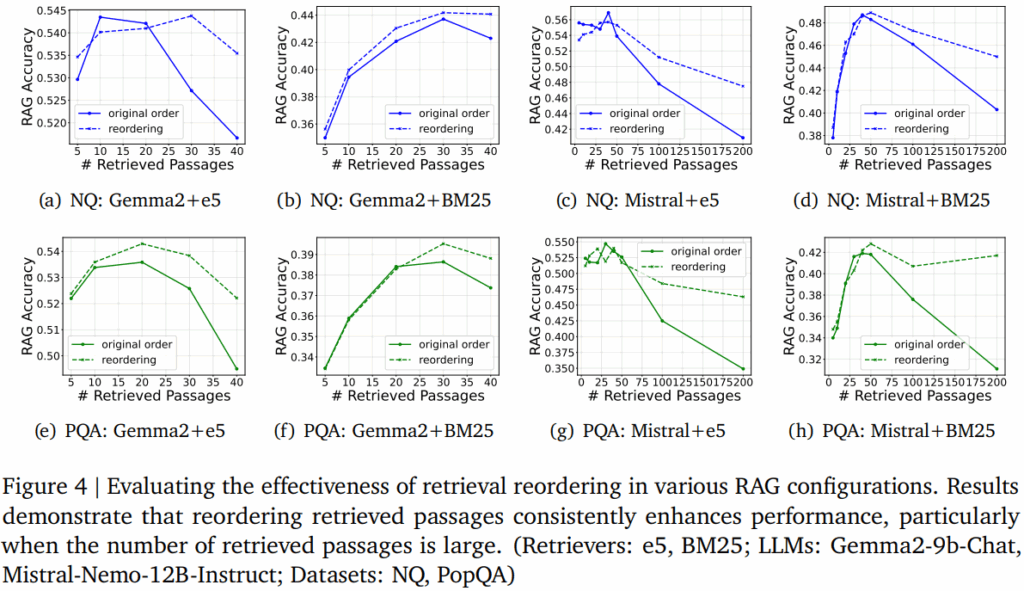
앞서서 검색의 결과에서 허용 폭이 넓어질수록 hard negative가 포함될 확률이 높아짐을 확인할 수 있었습니다. 그러나 추가된 정보에서 모든 검색 결과가 hard negative는 아닐 것입니다. 본 논문에서는 LLM의 입력에서 중간으로 갈수록 집중을 덜한다는 기존 연구 결과를 활용하여 입력의 형식을 아래와 같이 수정했습니다. 즉 검색을 통해 쿼리와 유사한 순으로 양쪽 끝에 우선적으로 배치되도록 수정한 것입니다.

실험 결과은 두가지 데이터셋(NQ, PQA)에 진행되었으며, 제안한 방법을 적용(점선, reordering)했을 때 RAG의 응답 생성 성능이 개선됨을 Figure4에서 확인할 수 있습니다.
# training-based 해결책 (Fine-tuning)
앞선 Retrieval reordering 결과는 LLM의 noise에 대한 대응 성능을 개선하는것은 아니였습니다. 논문에서는 LLM을 RAG에 활용하기에 최적화되도록 튜닝하는 방법을 제시했는데요, 암시적인 개선과 명시적인 개선으로 나누었습니다.
1) 암시적 개선
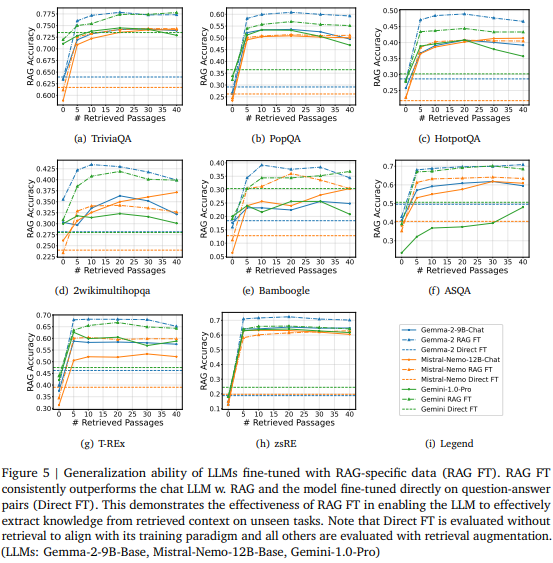
암시적 개선이란 retrieval 결과에 잡음이 섞여있음을 가정하여 LLM이 잡음에 대한 대응력을 개선하는 학습입니다. 기존에 쿼리와 정답값을 학습하는 LLM 학습 패러다임을 수정하여, RAG 프로세스에 맞게 retrieved passages를 함께 학습에 사용한 것입니다. 실험 결과는 Figure5와 같습니다 8개(a~h)의 데이터셋에 대하여 해당 암시적 개선을 적용했을때 passage 개수가 증가하여도 역-U 패턴이 발생하지 않았으며, 해당 방법으로 long-context RAG의 문제점을 개선할 수 있음을 확인할 수 있습니다.
2) 명시적 개선
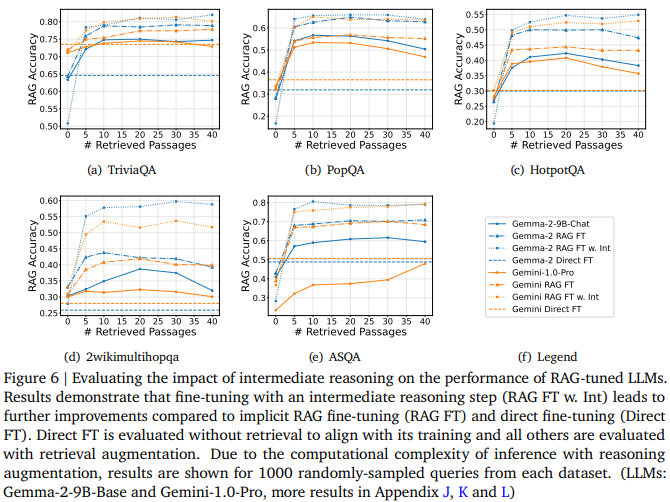
앞서서 long-context RAG의 문제 발생 원인을 hard negative로 확인했습니다. 이에대한 명시적 해결책으로 LLM이 답변을 생성할 때, 답변의 생성 원인을 같이 생성하도록 학습하는것이 명시적 해결입니다. 모델이 유사한 context와 답변의 연관성을 학습하도록 명시적으로 지시함으로서 long-context의 문제점을 해결한 것입니다. 이에 대한 실험 결과는 Figure6과 같으며 Direct FT보다 제안한 RAG FT이 효과적이며 RAG FT에 명시적 해결책인 Intermediate reasoning까지 수행하도록 학습했을때 가장 개선효과가 컸음을 확인할 수 있습니다
# data-centric perspectives
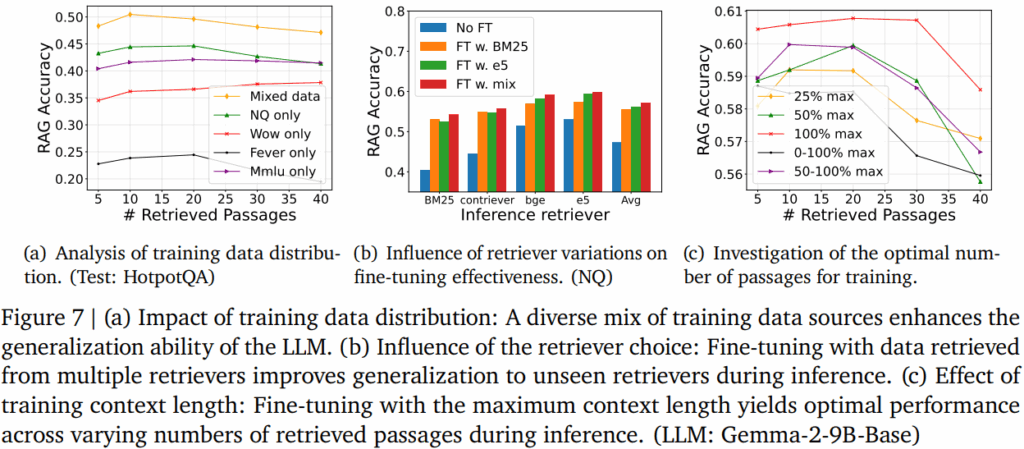
저자들은 마지막으로 LLM을 fine-tuning 할때, 데이터의 구성 방식이 중요함을 해당 파트를 통해 밝힙니다. 가장 먼저 Unseen datasets에 대한 대응 능력으로 어떠한 데이터 분포가 학습에 가장 도움이 되는지를 Figure7-(a)를 통해 분석했습니다. 실험 결과 NQ, WoW, Fever, MMLU 데이터를 각각 따로 사용하는것 보다 모든 데이터를 학습하는 것이 Unseen datasets인 HotpotAQ에 대한 답변 생성 성능을 개선함이 중요함을 보이며, HotpotQA와 최대한 유사한 분포를 갖는 특정 데이터에 fine-tuning 하는것 보다 다양한 분포를 학습함이 좋음을 확인했습니다. 둘째로 검색기의 영향력에 대해 Figure7-(b)를 통해 확인했습니다. 실험 결과 혼합(e5+BM25, 빨간막대)검색기의 결과를 학습하는 것이 가장 안정적인 성능을 보임을 확인할 수 있으며, e5 검색기를 활용할 경우(녹색막대), 해당 검색기로 인퍼런스할때 다른 검색기를 활용한것보다 높은 성능(4번째 x 축: e5, mix 결과제외 가장 높은 성능)을 보임을 통해 검색기마다 hard negative의 성격이 다르며, 학습한 검색기와 동일한 검색기를 추론에 사용하는것이 가장 좋음을 보였습니다. 마지막으로 학습시 사용하는 retrieval passage의 개수에 대해 Figure7-(c)로 분석했습니다. 학습 결과, fine-tuning 시에는 LLM이 수용가능한 context capacity를 최대치까지 활용하여 많은 passage를 학습하는게 좋음(빨간선)을 확인할 수 있습니다.
해당 논문에서는 많은 실험을 통해 RAG의 성격을 분석하고 RAG 프레임워크가 소화할 수 있는 context의 크기를 늘릴 수 있는 실용적인 방법을 제안했습니다. 또한 해당 방법론이 Hard negative에 예민함을 직접적으로 확인할 수 있었습니다. RAG 프레임워크를 설계할때 주의해야할 점을 잘 짚어준 논문 같습니다.
재밌는 논문이네요 좋은 리뷰 잘 읽었습니다.
리뷰 읽다가 제가 잘 이해한것이 맞는지 궁금해서 댓글 남깁니다!
Figure2에서 검색기의 Recall은 꾸준히 상승하는데도 RAG 성능은 역-U 패턴을 보였다고 하셨습니다. 그렇다면 이 실험은 검색기 품질(?)이 충분히 높다는 것을 전제로 모델의 long-context 한계를 드러내기 위한 것인가요?? 검색기의 Recall 외 다른 요인(문서 길이 분포, 중복 비율 등)이 영향을 줄 가능성은 없을까요?
안녕하세요 홍주영 연구원님 리뷰 읽어주셔서 감사합니다.
말씀하신대로 검색기의 품질이 충분하다는것을 전재로, 검색기의 이상이 없는데도 long-context를 이용할시 성능이 하락함을 보인것 입니다. hard negative 외에도 말씀해주신 정보 중복과 같은 다른 요인이 성능에 미치는 영향이 저도 궁금하긴 합니다만, 이에 대한 분석은 확인하지는 못했습니다. 다만 완전 동일한 passages는 없다는 가정하에 hard negative가 아닌 유사한 정보를 LLM에 더 제공하면 RAG 결과 생성 성능이 개선된다는 Figure7-c의 결과로 미루어 보았을때, 유사한 정보더라도 많이 제공되는것이 제공되지 않는것보다 나을 것이라고 생각됩니다.
감사합니다.
안녕하세요. 황유진 연구원님 좋은 리뷰 감사합니다.
암시적 개선에서 retrieved passages를 함께 학습에 사용했다고 했는데 passages의 수를 제한하는 방향으로 학습한 건지 어떻게 학습한건지 궁금합니다. 또, 명시적 개선에서 답변 생성할 때 생성 원인도 같이 생성하도록 함께하는건 프롬프트를 추가해준건가요?
감사합니다.
안녕하세요 박성준 연구원님 리뷰 읽어주셔서 감사합니다.
기존 LLM 학습의 경우 쿼리(q)와 이에 해당하는 정답값(a)을 학습하게 됩니다. 이때 학습에 사용되는 입력은 [I, q] 출력은 [a] 입니다. (I는 instruction) 반면 제안된 암시적 개선(RAG FT)의 경우는 입력은 [I, {passages}, q] 출력은 [a] 가 됩니다. 이때 {passages}의 경우 검색기가 쿼리와 유사하다고 판별한 순으로 top-40개를 이용했다고 합니다. 다음으로 명시적 개선(RAG FT w “int”)의 경우는 입력이 [I, {passages}, q] 출력이 [r, a] 이 되도록 학습한 것으로 학습에 사용되는 reasoning labels은 Gemini-1.5-Pro를 통해 생성했다고 합니다.
감사합니다.
안녕하세요. 리뷰 잘 읽었습니다.
그림1번에서 저자들이 설명하고 싶었던 부분은 문맥이 무작정 많아봤자 오히려 RAG의 정확도는 떨어진다 라는 것을 말하고 싶었던 것 같은데, 다른 방법론들은 실제로 그랬지만 gemini-pro는 생각보다 더 많은 맥락 수를 가지더라도 성능이 유지되거나 더 오르는 경향을 보이는 것 같습니다.
즉 Gemini는 저자들의 주장들과 좀 반하는 결과를 보여주는 듯 싶은데도 불구하고 저자들이 굳이 넣은 이유는 뭘까요? 그리고 Gemini는 왜 다른 방법론들과 다르게 문맥이 길어도 성능이 크게 감소하는 것이 아닌 향상되거나 보장이 되는 걸까요? 논문이랑 크게 관련없는 질문이라 답하기 곤란할 수도 있겠지만 혹시 아는 내용이 있으시나 싶어 여쭤봅니다.
캄사합니다.