안녕하세요 이번에 소개할 논문도 Text-Video Retrieval 태스크의 논문입니다. 이번 논문은 VLM을 활용해 비디오의 프레임 캡션을 생성하고 이를 다양한 방식으로 활용해 Retrieval 성능을 높인 논문입니다. 그럼 바로 리뷰 시작하겠습니다.
1. Introduction

Text-Video Retrieval(TVR) 태스크는 주어진 쿼리에 대응하는 비디오나 텍스트를 검색하는 태스크입니다. 예를 들어, 텍스트 쿼리가 입력되면 해당하는 비디오를 찾고, 반대로 비디오 쿼리가 입력되면 이에 대응하는 텍스트를 검색하는 방식입니다.
정확한 검색을 위해서는 서로 다른 모달리티(언어·시각) 사이의 정렬(alignment)을 맞춰주는 것이 핵심입니다. 이를 위해 CLIP, BLIP 같은 비전-언어 모델(VLM) 을 활용하는 접근이 널리 쓰이는데, 이들 모델은 대규모 이미지–텍스트 데이터셋으로 사전학습되었기 때문에, 비디오에 적용할 때는 프레임 샘플링이나 비디오에 맞게 모델을 파인튜닝해서 temporal information을 반영하는 방법이 주로 사용됩니다.
비디오의 본질적 특성인 시간적 맥락을 모델링하기 위해서는 temporal module이 필요합니다. 과거에는 3D Convolution(I3D 등) 이 대표적이었고, 최근에는 TimeSformer 종류, temporal pooling/attention 처럼 시간 정보를 고려할 수 있는 모듈을 추가하는 구성이 많이 쓰입니다.
하지만 최근에는 비디오는 프레임이 많아 정보가 풍부한 반면, 쿼리 텍스트는 짧고 단순해 정보가 부족하거나 모호할 수 있습니다. 이러한 모달리티 불균형을 줄이기 위해 LLM/VLM을 활용해 비디오 캡션 등의 보조 텍스트를 추가하는 연구가 많이 진행되고 있습니다. 이번에 소개할 논문도 VLM을 활용해 비디오 캡션을 늘리고 이를 alignment에 다양한 방식으로 활용한 연구입니다.

최근 몇몇 연구 에서는 비디오로부터 캡션을 생성해, 비디오와 언어 사이의 modality gap 을 줄이는 방법을 제안했습니다. Cap4Video는 비디오 전체를 요약하는 video-level caption 을 생성하고, 이를 활용해 모달리티 간 차이를 줄이려고 했습니다. 하지만 그림 1(a)에서 보듯, 비디오 전체를 하나의 문장으로 요약하면 시간에 따라 달라지는 맥락(contextual variation)을 충분히 반영하지 못하는 한계가 있습니다. 게다가, 캡션이 잘못 생성되면 오히려 성능이 떨어질 수도 있습니다.
EA-VTR 은 이 문제를 보완하기 위해 frame-level caption 을 도입해, 비디오에서 시간에 따라 변하는 사건(event)을 인식하는 event-aware 방식을 제안했습니다. 하지만 이들은 주로 event detection 성능을 높이는 것에 초점을 맞췄고, retrieval 태스크에서 중요한 쿼리에 따라 필요한 캡션만 활용하는 방법은 고려하지 않았습니다.
이러한 기존 방식들의 한계를 극복하기 위해, 저자는 NarVid(Narrating the Video) 이라는 새로운 프레임워크를 제안합니다. NarVid도 EA-VTR과 마찬가지로 비디오 전체에서 frame-level captions 을 생성합니다. 하지만 이렇게 생성한 모든 캡션이 쿼리와 직접적으로 관련 있는 것은 아니기 때문에, 불필요한 캡션을 적절히 걸러내고 필요한 정보만 활용하는 처리 과정을 추가해줬습니다. 뿐만 아니라 생성된 캡션을 다양한 방식으로 활용을 해줬는데 자세한 방법론은 이후 Method 부분에서 알아보도록 하겠습니다.
2. Method
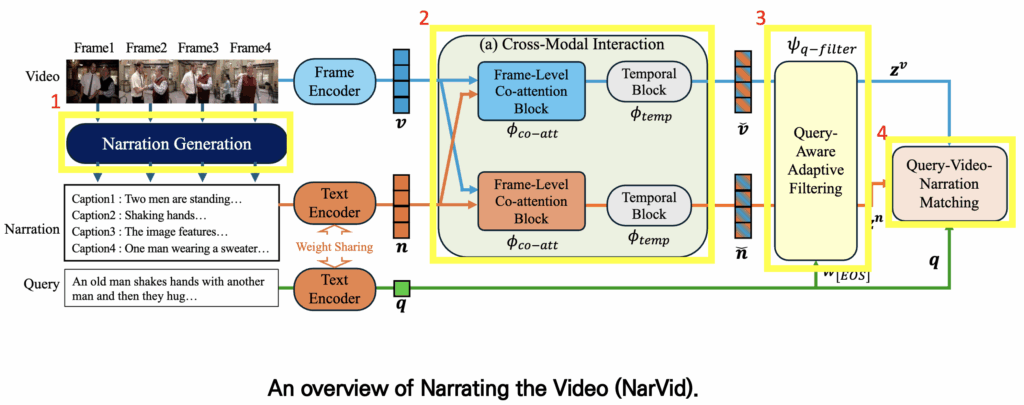
먼저 저자가 제안하는 모델의 architecture는 다음과 같습니다. 이 모델은 CLIP을 backbone으로 사용하기 때문에 visual encoder와 text encoder가 기본적으로 포함되어 있습니다. 또한 모델은 크게 네 가지 주요 모듈로 구성됩니다.
- Narration Generation
- 각 비디오 프레임마다 캡션을 생성하여 frame-level captions을 얻는 모듈입니다.
- Cross-Modal Interaction
- visual features와 text features 간의 상호작용을 통해 서로 보완적인 정보를 추출합니다. 이 과정은 co-attention 을 활용하여 두 모달리티의 alignment를 강화합니다.
- Filtering Module
- 주어진 query와의 유사도를 기준으로, 관련성이 낮은 프레임이나 잘못 생성된 캡션을 필터링 해주는 모듈입니다.
- Matching Module
- 최종적으로 frame features, narration features, query features를 종합하여 매칭을 수행합니다. 이때 단순한 query-video 매칭뿐만 아니라 query-narration 매칭까지 함께 고려하여 성능을 향상시키며, 학습 과정에서는 hard negative loss도 추가해줘 모델이 구별하기 어려운 negative samples에 대해 구별력을 키워 주었습니다.
2.1 Narration Generation
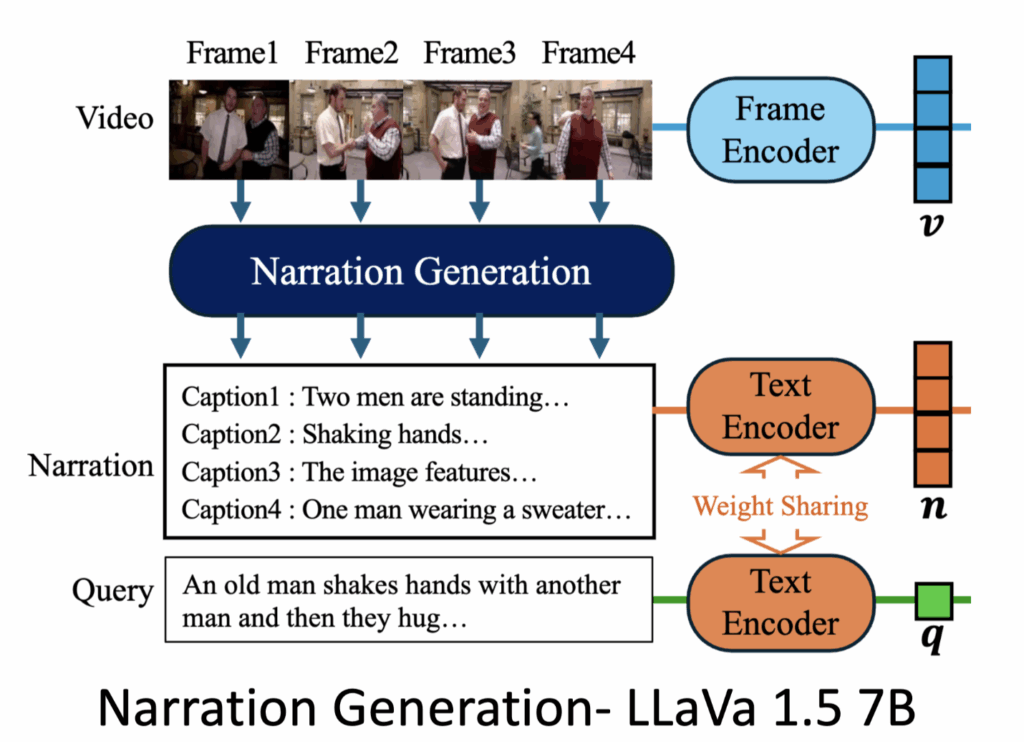
먼저 Narration Generation 모듈에 대해 살펴보겠습니다. 캡션을 생성하기 위해 저자는 LLAVA 1.5 7B 모델을 사용했습니다.

캡션은 Prompt에 따라 다양하게 생성될 수 있기 때문에, 저자는 3가지 타입의 Prompt를 구분했습니다.
- Type A
- 각 프레임 내의 object만을 단일 문장으로 생성하도록 하는 Prompt
- Type B
- 단일 문장 생성은 동일하지만, object, action, 그리고 기타 관련 정보까지 포함하여 문장을 생성하도록 설계된 Prompt
- Type C
- 이미지에 대해 간단히 설명하는 방식이지만, 단일 문장 생성 제한이 없는 Prompt
실험 결과, Type C가 가장 좋은 성능을 보여 최종적으로 Type C를 사용하여 Prompt를 설정했습니다.
따라서 최종적으로 각 프레임에 대해 캡션을 생성하는 과정을 수식으로 표현하면 다음과 같습니다.
2.2 Cross-Modal Interaction
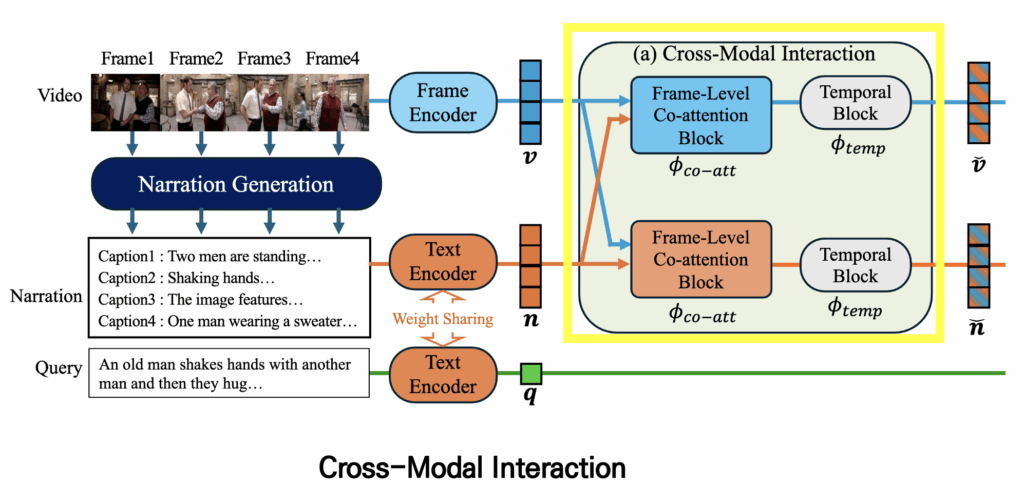
이제 encoder를 통해 얻은 frame features와 caption features를 이용해 바로 alignment를 맞출 수도 있지만, 단순히 그대로 사용하는 것보다는 두 모달리티의 특징을 상호작용시키는 모듈을 추가하여 feature를 향상시키는 것이 alignment를 맞춰주는 것에 도움을 줄 수 있습니다. 이를 위해 저자는 Cross-Modal Interaction 모듈을 사용합니다.
Cross-Modal Interaction은 크게 두 가지 구성 요소로 이루어져 있습니다.
- Co-Attention (co-att)
- frame features와 caption features의 Co-Attention을 통해 서로의 정보를 바탕으로 피처를 강화
- Temporal Block (temblock)
- 프레임 간 temporal information을 반영, 각 프레임이 시퀀스 내 다른 프레임과 어떻게 연관되는지 학습
Co-Attention
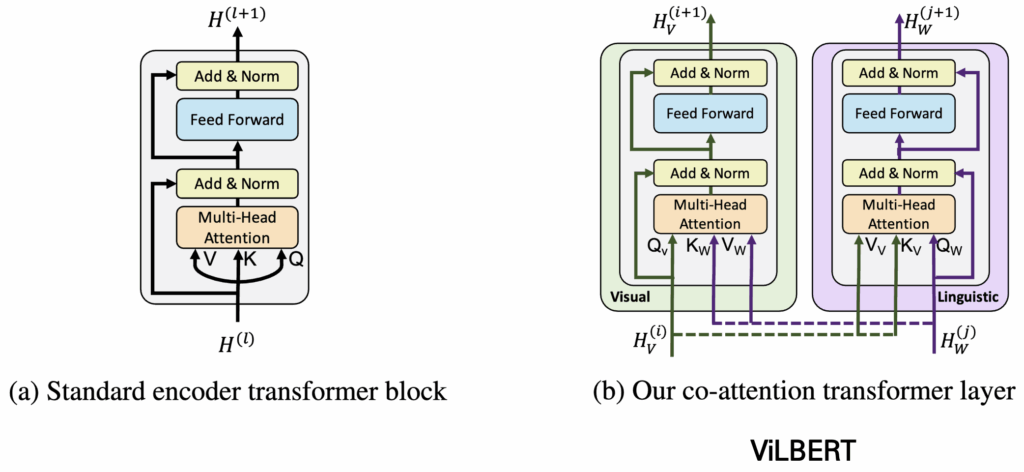
일반적인 Attention 연산에서는 Query, Key, Value 모두 같은 입력에서 가져와 연산을 수행합니다. 하지만 ViLBERT에서 제안한 Co-Attention(co-att)은 한 모달리티에서 처리하는게 아닌 다른 모달리티의 피처를 참고하여 Attention 연산을 수행합니다. 예를 들어, visual feature를 처리한다고 가정하면 Query는 visual feature 자체를 사용하고, Key와 Value는 text feature에서 가져옵니다. 이 과정을 통해 visual feature는 텍스트 정보를 반영하게 되며, 반대로 text feature도 visual 정보를 반영할 수 있습니다. 결과적으로 서로 다른 모달 간의 정보를 결합하여 상호 보완적이고 향상된(feature-enhanced) representation을 얻을 수 있습니다.
그래서 co-attention 연산과, Temporal Block을 수식으로 살펴보면 다음과 같이 표현할 수 있습니다.

2.3 Query-Aware Adaptive Filtering
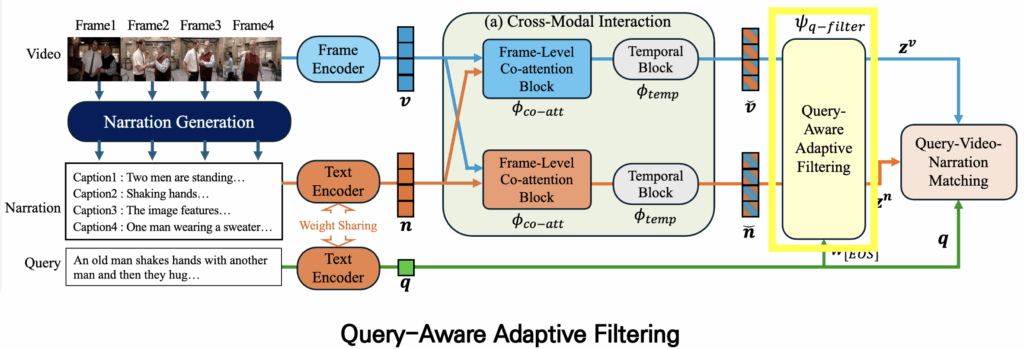
그리고 이렇게 생성된 강화된 feature를 가지고 바로 쿼리와 매칭을 수행할 수도 있지만, 실제로 프레임과 캡션에는 쿼리와 관련 없는 불필요한 정보가 포함될 수 있습니다. 이를 해결하기 위해 저자는 쿼리를 기반으로 한 filtering module을 추가하여 중요하지 않은 정보를 제거합니다.
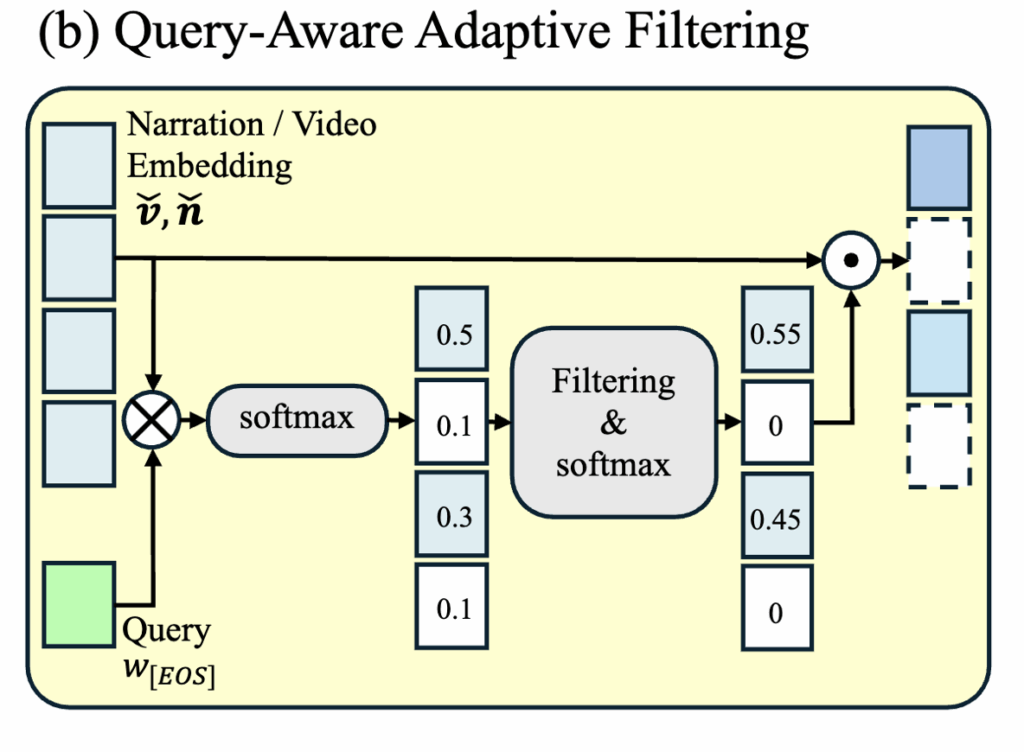

구체적으로, 쿼리 feature q, 비디오 feature v, 캡션 feature n 이 있다고 가정하면, 필터링 과정은 다음과 같이 진행됩니다.
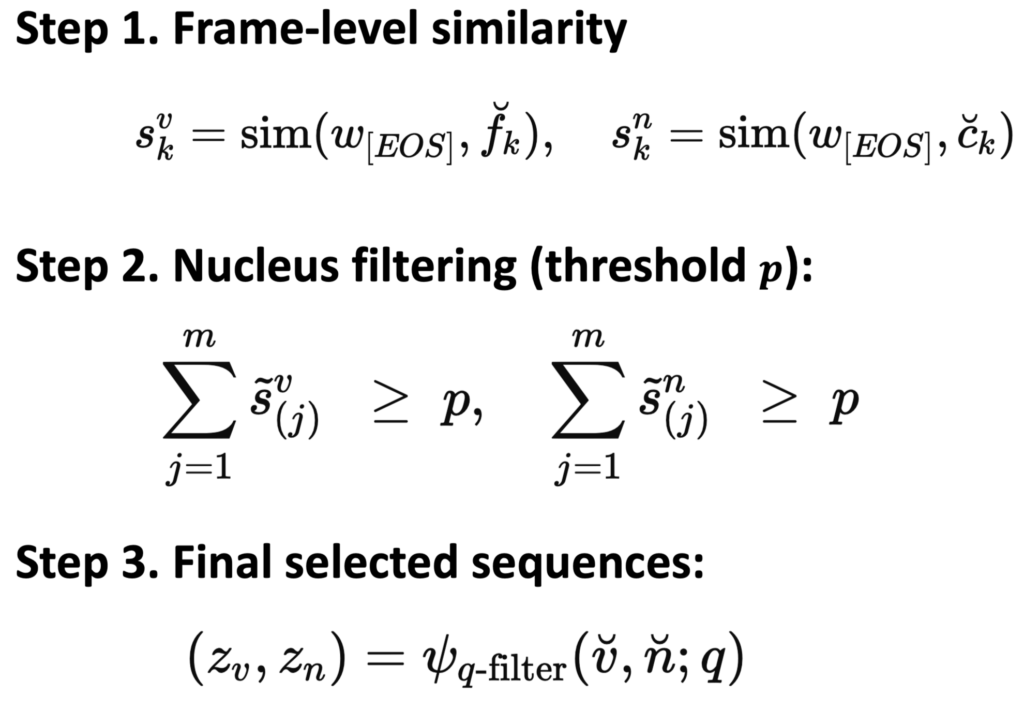
- 먼저 쿼리의 [EOS] 토큰과 모든 프레임(feature) 간의 similarity를 계산합니다.
- 마찬가지로 쿼리와 각 캡션 feature 간의 유사도도 계산합니다.
- 계산된 유사도를 내림차순으로 정렬한 뒤, 가장 유사도가 높은 값부터 순차적으로 누적합니다.
- 예를 들어, 그림2.b에서 처럼 유사도가 0.5, 0.3, 0.1 순으로 나온 경우, 유사도가 높은 순으로 값을 더해 누적 합을 구합니다. 그리고 이 값이 thershold P를 넘기 전까지 더하고 나머지는 0으로 처리하여 불필요한 정보를 제거합니다.
- 이 과정을 통해 중요한 프레임과 캡션만 남긴 필터링 피처 Z를 얻습니다.
2.4 Matching Module
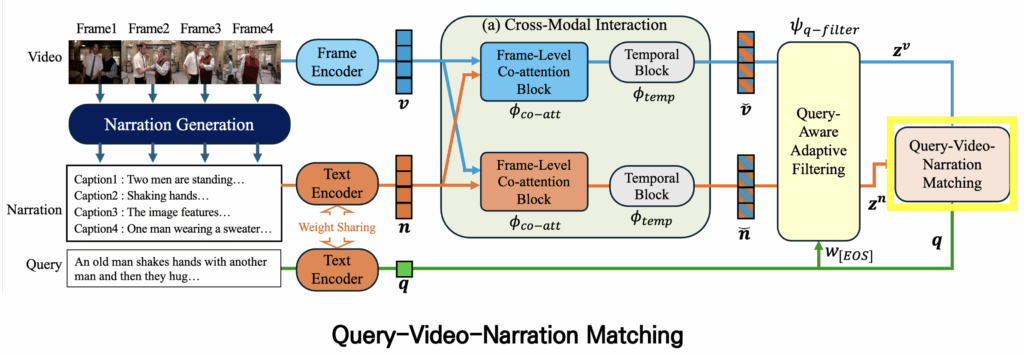
이렇게 필터링을 마친 feature에 대해 쿼리와의 matching을 수행합니다. 저자는 매칭 방식을 두 가지 단계로 구성했습니다.

- Coarse Matching
- 먼저 쿼리의 [EOS] 토큰과 비디오 프레임의 [CLS] 토큰 간의 유사도를 계산합니다.
- 이를 통해 비디오 전체와 쿼리 간의 전반적인 상관관계를 매칭합니다.
- Fine-Grained Matching
- 다음으로 쿼리의 각 단어(word embedding)와 프레임의 [CLS] 토큰 간 유사도를 계산하여, fine-grained 매칭을 수행합니다.
최종 매칭 스코어는 Coarse Matching과 Fine-Grained Matching 결과를 평균 내어 값을 결정합니다.

hard negative loss
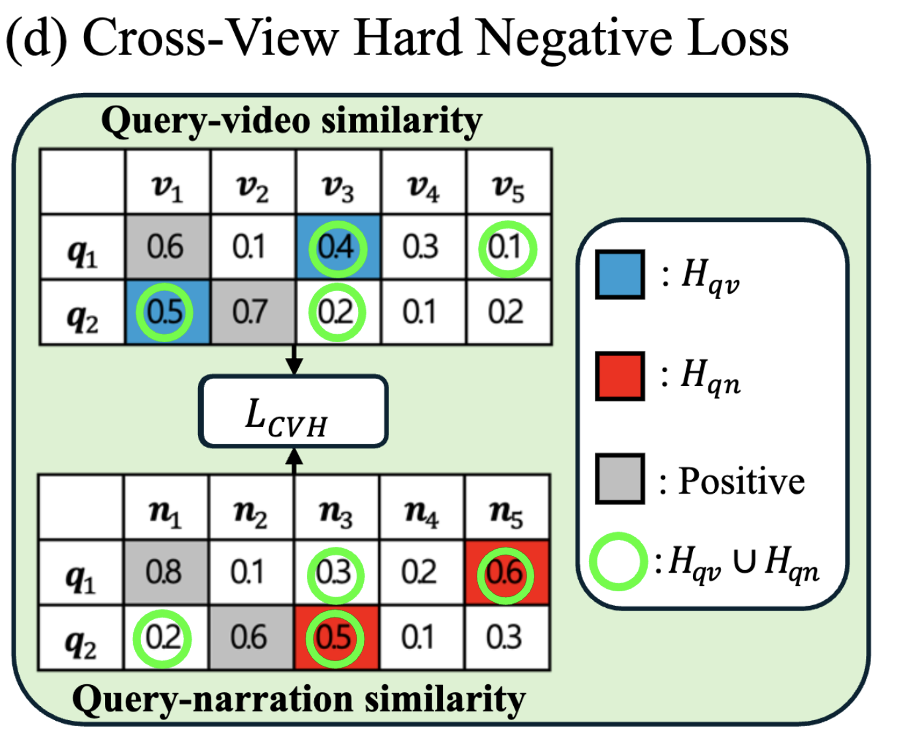
저자는 Contrastive Loss뿐만 아니라 Hard Negative Loss도 함께 사용합니다. Hard Negative 샘플이란, 모델이 구분하기 어려운 Negative 샘플을 의미합니다. Hard Negative 샘플을 구하는 과정은 다음과 같습니다.
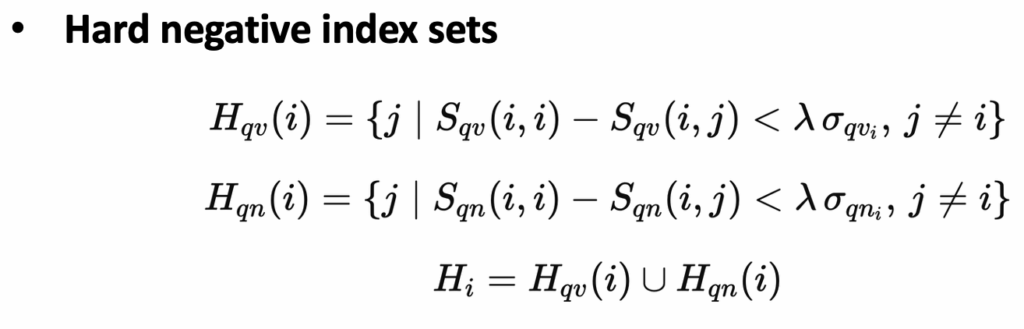
- 앞서 계산한 유사도(similarity) 점수를 기준으로, positive 샘플과 negative 샘플 간 유사도가 특정 임계값(threshold) 이하이면, 모델이 이 negative 샘플을 제대로 구분하기 어렵다는 의미로 판단합니다. 이렇게 판단된 샘플을 Hard Negative 샘플로 설정합니다.
- 이 과정을 비디오 프레임(feature)뿐만 아니라 프레임 캡션(feature)에도 동일하게 적용하여 Hard Negative 샘플로 설정합니다.
최종적으로는 프레임 Hard Negative 샘플과 캡션 Hard Negative 샘플의 합집합으로 Hard Negative 샘플을 정의합니다. Hard Negative Loss는 Margin Loss 형태로 구현되며, 수식으로 살펴보면 다음과 같습니다.
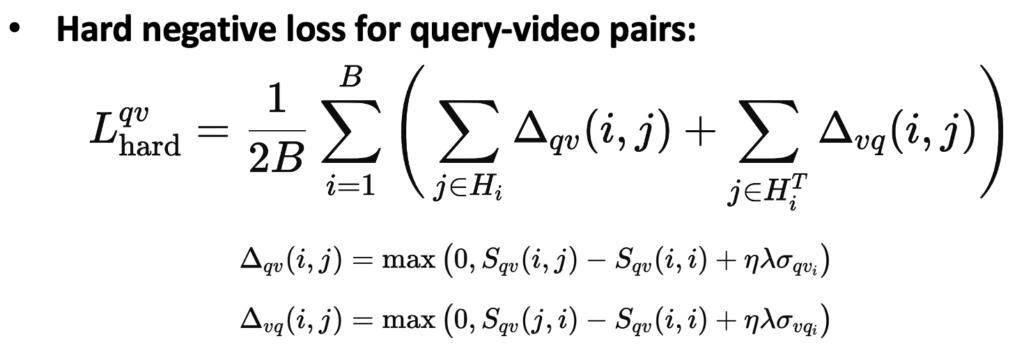
최종 Loss는 다음과 같이 Contrastive Loss와 Hard Negative Loss로 구성하였습니다.
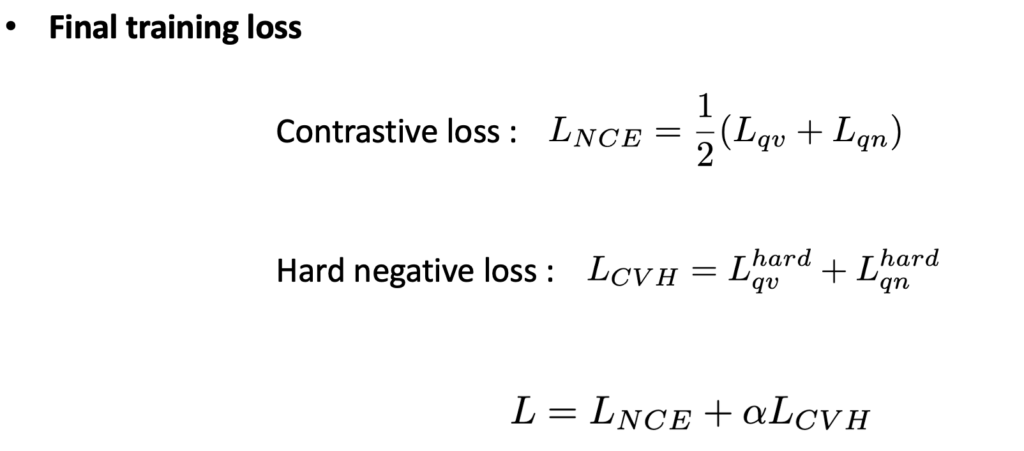
3. Experiments
다음으로 실험 결과를 살펴보겠습니다. 저자는 총 4가지 벤치마크 데이터셋에서 모델 성능을 평가하고 결과를 리포팅했습니다.
MSR-VTT, MSVD, VATEX, DiDeMo 데이터셋에서의 성능은 다음과 같습니다.
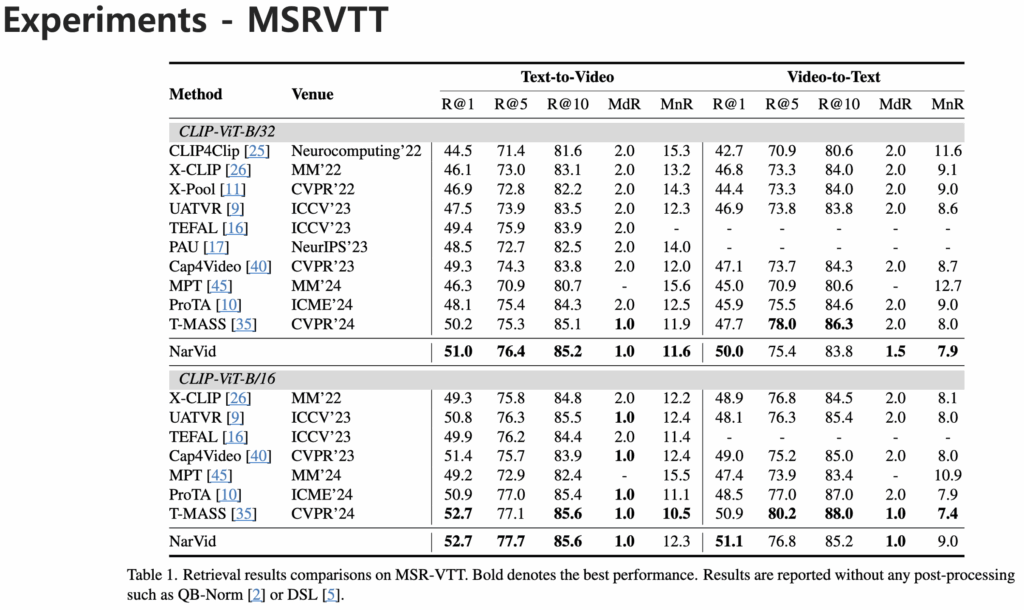
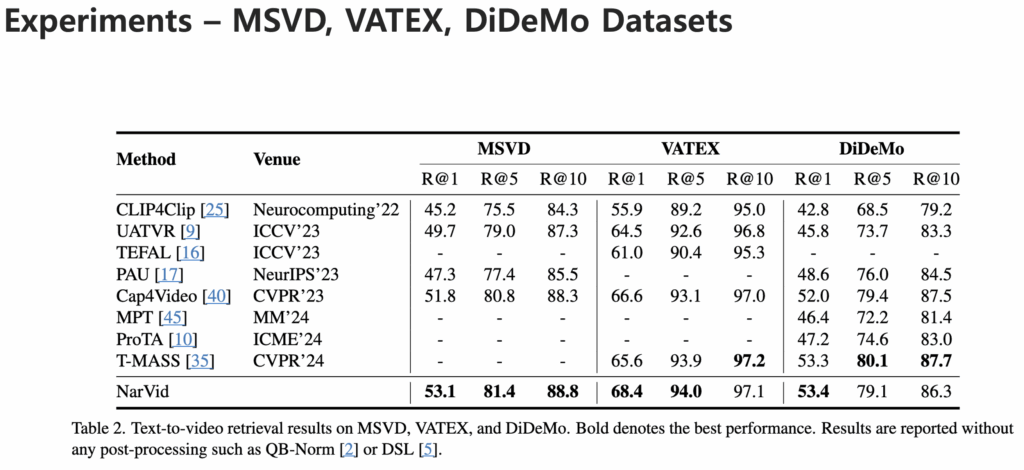
기존 방법론보다 높은 성능을 달성하며 제안한 모델이 다양한 데이터셋에서 일관되게 높은 성능을 달성했음을 확인할 수 있습니다.
Ablation Study
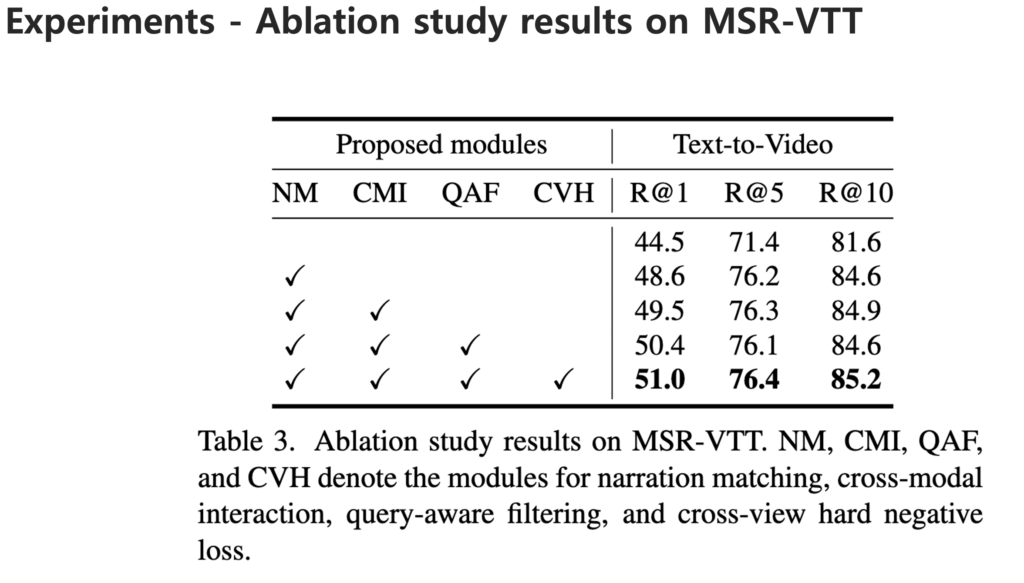
저자는 제안하는 네 가지 모듈을 검증하기 위해 MSR-VTT 데이터셋에서 Ablation Study를 수행했습니다. 먼저, Narration Matching(NM)모듈을 추가했을 때 R@1 성능이 4.1% 향상되며 내레이션이 매칭 과정에서 보조적인 역할을 한다는 점을 확인했습니다.
두 번째로, Cross-Modal Interaction(CMI)을 통해 영상 프레임과 내레이션을 Co-Attention과 Temporal Block으로 상호작용시켜 feature를 강화했을 때 모든 Recall 지표에서 성능이 개선되었습니다.
세 번째로는 Query-aware Adaptive Filtering (QAF)모듈입니다. 프레임과 캡션의 feature에는 불필요하거나 잘못된 정보가 포함될 수 있기 때문에 필터링 과정을 거쳐 쿼리와 관련 있는 정보만 남겼습니다. 이 과정을 통해 R@1 성능을 높일 수 있음을 알 수 있고, 고정된 Top-k Adaptive Nucleus Filtering이 더 효율적인 것을 알 수 있습니다.
네 번째는 Cross-view Hard Negative Loss(CVH)입니다. 내레이션을 활용해 Hard Negative 샘플을 정의하고 intra-modal similarity까지 고려했을 때 모든 Recall 지표에서 추가적인 성능 향상을 얻었습니다.
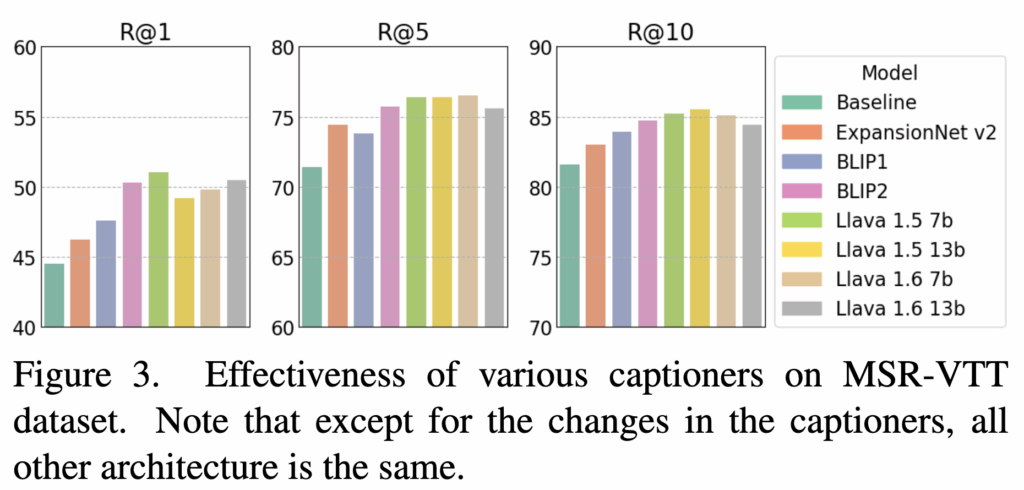
마지막으로, 내레이션 생성 모델의 차이가 성능에 어떤 영향을 미치는지도 분석했습니다. 생성 모델로는 Image-Captioning 모델, VLP(vision-language pre-trained) 모델, 그리고 LMM(Large Multimodal Models)을 활용했을 때 모두 성능 향상이 나타났습니다. 다만, 성능이 더 좋은 모델일수록 더 디테일하고 긴 캡션을 생성했는데, 이 과정에서 쿼리와 무관한 단어들이 포함되면 오히려 검색 성능에 부정적인 영향을 줄 수 있다고 저자는 설명하고 있습니다.
종합적으로 볼 때, 내레이션 매칭만으로도 성능 향상이 가능하지만, Cross-Modal Interaction, Adaptive Filtering, 그리고 Hard Negative Loss를 함께 적용해야 성능을 가장 높일 수 있음을 확인할 수 있습니다.
안녕하세요 정의철 연구원님 질문을 달러 왔습니다.
기존에는 비디오 단위의 캡션을 중심으로 modality gap을 줄였으나 소개해주신 논문은 frame-level caption을 이용하여 modality gap을 더욱 효과적으로 줄인것으로 이해했습니다.
우려되는 부분은 video level caption에 비해 frame level caption은 각 영상을 프레임단위로 보기 때문에 시간적 이해가 떨어질 것으로 예상되는데요, 논문에서 이러한 두 캡션의 성격적 차이를 다루거나 이에대한 의견을 제시한 바가 있나요? 없다면 어떻게 생각하시는지 궁금합니다.
아무쪼록 좋은 리뷰해주셔서 감사합니다
안녕하세요 유진님 질문 감사합니다.
video level caption의 캡션은 비디오의 전역적인 정보를 담고 있어, 비디오의 전반적인 내용을 갖는다고 할 수 있습니다. 하지만 video level의 단일 caption만 사용하면 정보량이 부족할 수 밖에 없습니다. 그래서 LLM을 사용해서 frame-level caption을 생성하는 연구가 최근 많이 진행되고 있습니다.
Text-Video에서 말하는 시간적 정보는 보통 Visual 측면에서 많이 다뤄지고 있습니다. 왜냐하면 비디오는 프레임의 집합으로 이루어져 있어 이들의 프레임 관계를 모델링 해야하기 때문입니다.
반면 비디오 캡션은 비디오의 전체적인 내용을 설명하거나 프레임 캡션은 프레임의 내용을 설명하기 때문에 시간적 요소의 차이보다는 요약과 상세한 설명의 차이로 이해하시는게 좋을 것 같습니다.
감사합니다.
안녕하세요. 정의철 연구원님 좋은 리뷰 감사합니다.
co-attention이 결국 cross-attention을 두번 하는것과 비슷하다고 생각했는데 궁금한 점이 text를 Q로 줬을 때랑 video를 Q로 줬을 때랑 feature의 shape이 달라지게 될텐데, query-aware adaptive filtering에서 일치시켜주는건가요? 필터링 과정에서는 [EOS] 토큰만 사용하는 것으로 보이는데 [EOS] 토큰만 사용하는 이유가 무엇인가요?
감사합니다.
안녕하세요 성준님 질문 감사합니다.
먼저 co-attention에서 서로 다른 모달리티가 들어와도 projection을 통해서 차원은 맞춰줄 수 있습니다.
query-aware adaptive filtering은 단지 query를 기반으로 관련 없는 피처를 걸러주는 모듈입니다.
일반적으로 텍스트와 이미지의 유사도를 계산할때 Eos 토큰과 CLS 토큰의 유사도를 계산합니다. 이렇게 하는 이유는 계산이 간단하면서도 쉽게 유사도를 계산할 수 있기 때문입니다. 물론 EOS,CLS가 아닌 word-patch 단위로 내려가서 유사도를 계산할 수 있지만 그렇게 되면 더 fine-grained 하게 유사도를 계산할 수는 있지만 계산 cost는 올라갑니다. 필터링 과정에서 EOS 토큰만 사용한 이유는 효율성 때문이지 않을까 생각합니다.
감사합니다.