안녕하세요, 지금까지 real to sim을 통한 현실을 시뮬레이터로 옮기는 과정에 대한 연구를 진행해왔는데요, 앞으로의 연구방향은 당연하게도 이렇게 구성된 환경을 바탕으로 vision based robotic manipulation policy의 성능 향상을 하는 것입니다. 그런 의미에서 이번주에는 NVIDIA에서 발표한 vision-based robotic manipulation에서 real 데이터와 sim데이터를 활용한 manipulation 학습에 대한 인사이트를 제시한 논문을 리뷰해보려고 합니다. 시뮬레이션과 real 데이터를 동시에 학습했을 때 순수하게 real 데이터로만 학습한 정책보다 일관된 성능을 올릴 수 있다는 것을 증명하고, 이를 실용적으로 적용하기 위한 간단한 레시피를 제시한 연구입니다. 리뷰 시작하도록 하겠습니다.
Introduction
다양한 환경에서 로봇의 일반화를 이끌어내는것은 general한 로보틱스를 꿈꾸는 방향에서 굉장히 중요한 단계입니다. ㅁ많이들 아시는 pi-zero나 GR00T와 같은 모델들은 웹스케일의 vision-language 데이터셋과 로봇에 특화된 데이터셋을 추가로 활용해 foundation model스러운 (다양한 domain에서 adaptive 한) 모습을 보여주기도 했습니다. 다만 이를 위해서는 Droid, OpenEmbodiment-X와 같은 대용량의 real robot data가 필요합니다. 저자들은 이러한 대용량 데이터셋을 취득했음에도 불구하고, 로봇의 진정한 real world 에서의 일반화를 기대하기에는 여러 challenge들이 남아있다고 주장합니다. 사실 pi-zero와 같은 모델들도 데이터를 더 large scale로 취득해 학습했고, 정말 놀라운 모습들을 보여주면서 scaling된 real data가 다양한 스킬을 학습하는데 도움을 준다는 실험적인 결과를 제시했지만 현실에서 large data를 모으는 일은 그 자체로 시간적으로나 비용적으로나 cost가 정말 많이 필요합니다. 저자들은 여기서 “과연 real data를 scaling하는것 만으로 현실에서 generalist로 활동하는 로봇을 학습시킬 수 있을까?” 라는 좀 더 근본적인 의문을 제시합니다. 그러면서 physics적으로 완벽하고 high fidelity를 가지는 시뮬레이터와 고성능의 생성형 AI로 다양한 고퀄리티 robot trajectory를 minimal human effort로 얻어야 함을 주장합니다. (근데 가만 생각해보니 NVIDIA에서 쓴 논문이라 시뮬레이터를 강조하는건가 싶기도 하고, 결국 현실과 최대한으로 비슷한 데이터를 생성하려고 하면서 ‘real data를 scaling하는게 답인가?’ 라는 질문을 던지는게 뭔가 모순적이라는 느낌도 들었습니다. 앞으로 계속 해당 분야를 연구하려면 제 안에서도 Cost 문제를 더 큰 문제로 삼아야 할 것 같습니다..)
하지만 sim data를 활용한다면 넘어야하는 큰 벽이 있습니다. Visual적으로나 physics적으로나 시뮬레이터가 현실과 완전히 같을수는 없기 때문에, 근본적으로 존재하는 domain gap을 극복해야 합니다. RialTo나 Real2render2real, Asid와 같이 최대한 주어진 시뮬레이션 환경에서 현실성을 추구하는 연구들도 존재했고 domain randomization을 주로 수행하며 simulation parameter들을 통한 해결을 제시하는 연구들이 존재했지만, 이들은 전부 인간이 개입해야하는 (저자는 significant human effort라고 표현합니다) 문제가 있습니다. 저자들은 이러한 sim-to-real gap을 줄이는 방법으로 시뮬레이션 데이터와 현실 데이터의 mixture를 제시합니다. Robocasa등과 같은 연구에서 시뮬레이션과 real world 데이터를 함께 학습시키는 것이 real world에서의 general한 성능 향상을 이끌어낸다는 것을 보여줬고, reality와의 high allignment조차 필요하지 않다는것 또한 어필하며 large scale synthetic dataset을 구성하는 것에 대한 비전을 제시합니다. 또 고퀄리티의 digital twin을 구축하는것 또한 대안이 될 수 있지만 high fidelity의 환경을 만든느 것에는 많은 human effort가 들어가기 때문에 무리고, 심지어 퀄리티가 낮아도 성능 향상을 낼 수 있다고 어필하면서 minimal human effort에 힘을 실어 얘기했습니다. 그러면서 현실과 low allignment를 갖는 데이터를 만들어내는 데에는 무리가 없을 정도의 asset creation이나 rendering 기술들이 발전했다고 주장합니다. 인용으로 mimicgen 시리즈들을 달아두었는데, real to sim까지의 내용은 아닌 것 같습니다. 이러한 맥락들에서 고도화된 Real to sim의 자동화 연구가 의미를 갖는 것 아닌가 라는 생각을 해봤습니다.
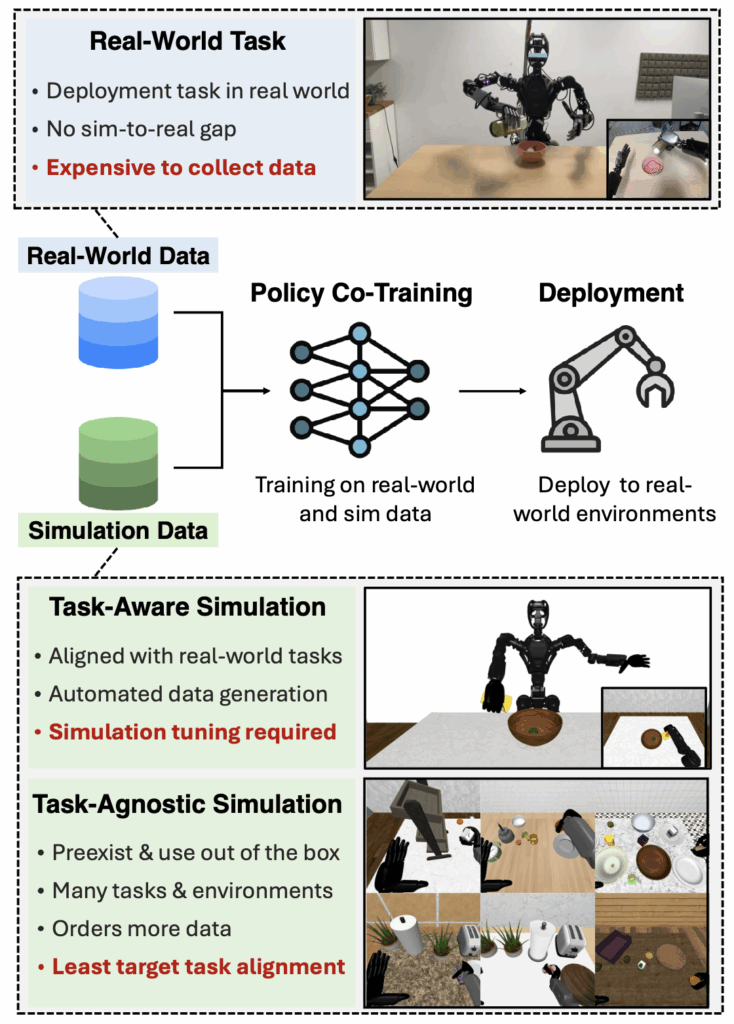
저자들은 그럼에도 불구하고 robot learning을 하는 커뮤니티 자체가 real-robot learning에서의 시뮬레이션 데이터가 가지는 이점을 간과한다는 것을 주장합니다. 그렇기 때문에 시뮬레이션 데이터의 이점을 챙기기 위해 정확히 무엇이 필요한지, 얼마나 현실과 달라도 되는지, 데이터의 구성 비율은 어떻게 되는지에 대한 연구가 부족하고, 정의되지 않았다고 어필하며 vision based 방법론들에서 synthetic simulation dataset을 통해 real robot dataset을 강화하는 간단한 방법을 제시했습니다. 재료로는 현실과 조금 덜 align 됐지만 task관점에서 semantic하게 같은 환경인 digital cousin류의 task-aware 시뮬레이션과 사전에 구성된 다른 환경이지만 해당 task를 진행할 수 있는 환경인 task-agnostic 시뮬레이션 환경으로 나누어서 진행했습니다. 해당 시뮬레이션 재료들을 어떻게 섞을것인가?에 대한 레시피를 제공하는 연구라고 생각하면 읽기 편할 것 같습니다. 저자들의 main contribution은 아래와 같이 정리할 수 있을 것 같습니다.
- Real, sim co-trainig에 대한 체계적인 연구를 수립하고 실세계에서의 manipulation 향상을 위한 레시피 제시
- Co-training이 현실의 downstream task들에서 평균적으로 38%의 성능 향상을 보인다는 것을 실증한 것
- Synthetic 데이터가 실제와 완전히 같지 않아도 유의미한 이점을 지닌다는 un-seen환경에서의 성능 향상 관점에서의 효과에 대한 통찰을 제시한 것
Problem Statement and Preliminaries
Co-Traininig on Real-World and Simulation Data
간단하게는 앞서 말했듯 실세계 환경에서 수집한 데이터와 시뮬레이션 데이터를 섞어서 학습에 활용하는 것입니다. 저자들은 Robocasa에서 제시한 co-training 정의를 채택해 학습 목표를 아래와 같은 Behavior Cloning loss의 가중합을 최소화하는 방향으로 각 미니배치에서 시뮬레이션 데이터가 샘플링 될 확률인 α값을 조정해야 하고, 사실상 α값을 적절하게 선택하는것이 policy 성능에 결정적이었다고 합니다. Appendix에 있는 정보에 따르면 DiffusionPolicy를 사용했을 때 panda(7DoF manipulation)의 경우 0.9, 휴머노이드의 경우 0.99를 사용했을 때 optimal 했다고 합니다. 0.9는 그렇다 치고 0.99는 거의 시뮬레이션 데이터로 학습하는 것 아닌가 싶습니다.
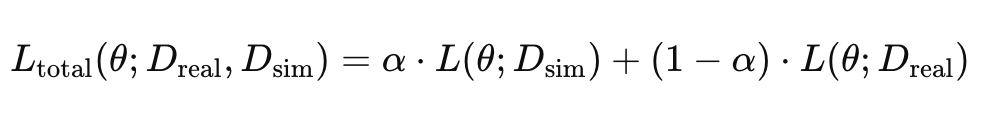
Data Composition Factors
현실 데이터와 시뮬레이션 데이터 모두 다양한 emobodiment, 환경, task로 구성되기 때문에 데이터셋 구성요소를 명확히 정의했다고 합니다. 이들을 통제해 실질적으로 성능 향상에 영향을 미치는 시뮬레이션 기반 데이터셋이 현실에서 취득한 데이터셋과 어떤 요소들의 차이를 가지고 있는지를 명확히 했다고 합니다. Scene을 구성하거나 데이터셋 활용 등 여러 측면에서 해당 요소들을 기준으로 고민해보는 것도 좋은 방법인 것 같습니다. Mimicgen의 randomization 요소들과 유사하게 구성이 된 느낌도 있네요. 아래와 같이 정의됐습니다.
- Task Composition : 데이터셋에 어떤 task들이 포함돼있는가? Subtask와 조작 skill은 어떻게 구성돼있는가?
- Scene Composition : Scene 수, 고정된 물체와 상호작용 가능한 물체의 수, 상호작용 객체의 articulation 유무, 조명과 배경 텍스쳐의 범위
- Object Composition : 어떤 카테고리의 객체들이 분포하는지, 카테고리별 고유 인스턴스의 수는 얼마인지
- Initialization Distribution : Scene에 존재하는 로봇 베이스와 객체들의 state는 어떤지, trajectory는 어떤지
- Camera Parameter : 몇대의 카메라가 존재하는지, 각 카메라들의 카메라 파라미터는 어떤지
Automated Synthetic Data Generation
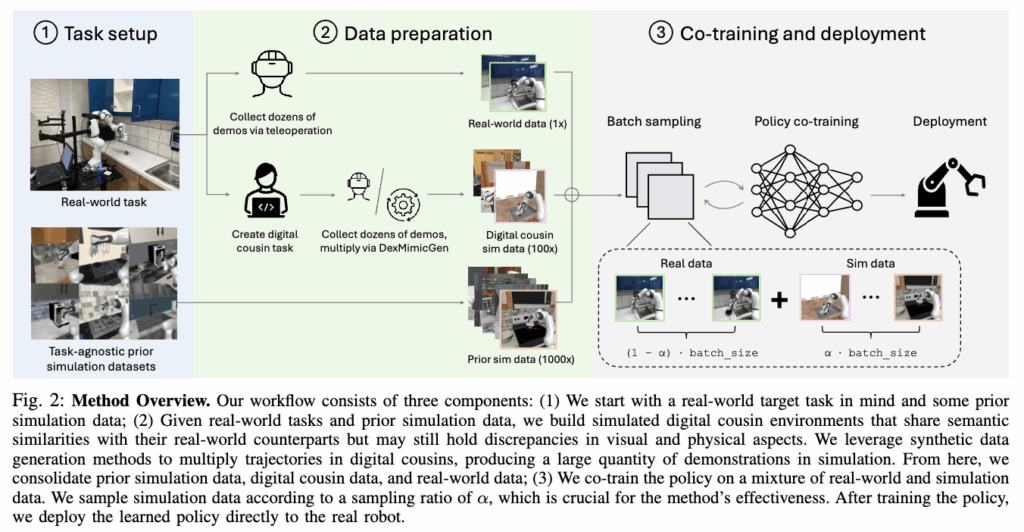
Synthetic Data는 예상 가능하지만 mimicgen을 활용해 자동화된 생성을 했다고 합니다. 시뮬레이션 내에서 각 task별로 수십개의 teleop demo를 획득한 후 단일팔/양팔인 경우 각각 mimicgen / Dexmimicgen을 활용해 대규모로 augmentation을 진행했다고 합니다. Object centric한 trajectory를 구하고 ee와 object에 동일한 linear transform을 가하며 interpolation을 통해 trajectory를 보완해 그대로 rollout하며 새로운 데이터를 만들고 이 과정을 다양한 transform을 적용해가며 scaling을 진행합니다.
Study Setup
Scenarios
Study는 크게 prior large-scale simulation data 활용과 task-aware simulation data활용 두 시나리오로 나뉘어 진행됐습니다. Prior large-scale 데이터의 경우 사전에 존재하는 synthetic dataset을 co-training에 직접 사용하는 경우입니다. 이 시나리오에서는 기존에 만들어진 대규모 시뮬레이션 데이터셋이 그대로 co-training에 사용한가? 에 대한 탐구를 진행했다고 합니다. 핵심은 기존의 시각적으로나 scene구성 적으로나 domain gap이 큰 시뮬레이션 데이터를 그대로 co-training에 사용했을 때 domain gap에도 불구하고 도움이 됐는가? 에 대한 정량적인 분석입니다.
Task-aware simulation data의 경우는 현실에서의 task 환경에 대한 정보들을 바탕으로 simulation environment를 구성해 better aligned된 데이터를 사용했을 때의 co-training 효과입니다. 저자들은 DigitalCousin 연구를 직접 언급하며 해당 방식으로 loosely aligned scene을 구성했을 때를 가정했습니다. 이 때도 더 정밀한 scene을 구성하는 노력은 비용상으로 어렵다는 판단을 진행했다고 주장했습니다. 핵심은 앞서 구성된 component들을 기준으로 어떤 데이터 구성 요소들을 정렬시키는게 중요한가?와 현실적으로 완벽한 scene을 구성하는 연구의 필요성 검토입니다.

Real world domain setting
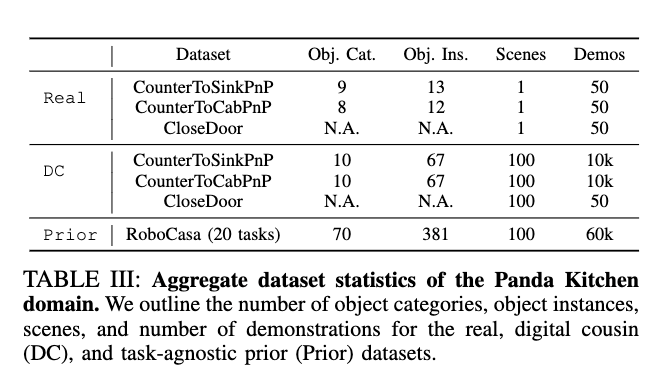
Manipulator는 실제 주방환경에서 Franka Emika Panda 로봇과 DROID 세팅 기반으로 side view 카메라들의 위치에 약간의 변화만 준 채로 Counter to Sink, Counter to Cabinet, Close door 세가지 태스크에 대해 50개씩 human demo를 준비했다고 합니다. 특이한 점은 real world에서 진행할 때 spacemouse를 사용해 데모를 취득했다고 합니다. 휴머노이드 데모를 취득할 때는 GR-1과 6DoF dexhand를 가지고 MANUS glove를 활용한 모션 캡쳐를 진행했다고 합니다. 휴머노이드 작업의 경우 side view 카메라들은 활용하지 않고 OAK-D 카메라 한대만을 머리에 두고 사용했다고 합니다. Task는 접시 위의 컵을 테이블로 옮기기, 우유박스 아래층으로 내리기, 컵에 담긴 탁구공 bowl에 담기 입니다. 초록색 부분은 물체들의 initial pose들이 존재하는 구역입니다. 모든 co-training method들을 평가할 때 해당 환경에서 진행했다고 합니다. Task는 대체적으로 쉽게 구성된 느낌입니다. 개인적으로 약간 아쉬운 부분입니다. 시뮬레이터의 현실성은 좀더 contact rich하고 정교한 환경에서 빛을 발하지 않을까 하는 개인적인 의견입니다,, 어떻게 보면 결국 deformable이나 articulated object를 reconstruction 하는것도 결국엔 필요하겠구나 싶기도 합니다.

Prior Task-Agnostic Simulation Data setting
기존에 존재하는 synthetic data의 경우는 그대로 co-training에 활용하기 위해서 같은 로봇과 action space를 지닌 데이터들을 활용했다고 합니다. 여기서 저자들이 집중한 부분은 정말 아무런 조작 없이 그대로 시뮬레이션 데이터를 활용할 수 있는가 였다고 합니다. Robocasa 데이터셋으로 부터 가져왔고 현실과 다양한 차이점들이 있는 데이터셋이지만 해당 task를 진행할 때 그대로 가져다 쓸 수 있는 데이터/환경이라고 판단되는 애들을 가져다 썼다고 합니다. 가져다 쓴 데이터가 Real환경 구성과 Task선정에 지대한 영향을 미치지 않았나 싶습니다.(이건 좀 가상 데이터에 역으로 현실 환경을 맞추는 느낌이라 좀 사기가 아닌가 하는 느낌을 받았습니다;; 근데 또 어떻게 생각하면 합성 데이터의 종류가 매우 다채롭기도 하고 워낙 task가 많은데 로봇이 현재 목표로 하는 task들이 어느정도 공통이기 때문에 지금으로서는 사용할 만한 데이터가 존재할 수 있겠다는 생각도 들었습니다. 일단 RSS니까,, 받아들이는거로) Robocasa 데이터셋은 robosuite 기반이라 환경이 isaac sim과 통합되었다고 하니 만약 추후 연구에 필요하다면 사용해볼수도 있을 것 같습니다.
Robocasa 환경에서 human demonstration을 50개 만들어 mimicgen을 통해 3000개로 불려서 사용했다고 합니다. 저자들은 해당 방법으로 수집된 데이터가 initial robot joint positions, controller parameters, physical
parameters, object categories, and the robot base position이 모두 다른 (상당히 allign이 안 맞는) 데이터라는 점에 주목하라고 합니다. 다만 camera pose의 경우는 다를경우 대상 객체가 가려지는 현상도 생기고 굉장히 중요한 셋업이라 real 환경과 맞췄다고 합니다. 저자들은 이런 간단한 post-processing만 거쳤음을 강조했습니다.
Building Task-Aware Simulation Dataset
Custom scene을 만들때는 더 노력을 하면 더욱 현실과 같은 scene을 만들수는 있지만, 완벽한 digital twin을 만드는것은 현실과 동일한 3D asset을 취득하는것 부터 시뮬레이션 환경의 manual tuning이 너무 많이 필요하기 때문에 Digital Cousin 환경 (task semantics만 공유하는 환경)을 기준으로 진행했다고 합니다. 저자들은 해당 환경에 대해 더 명확히 정의할 필요를 느껴서 Digital Cousin 환경을 다음과 같이 정의했다고 합니다.
- 같은 로봇과 action space를 가지는 데이터
- Task goal (task와 success check 기준, language instruction)이 같은 데이터
- Geometry와 texture는 다를지언정 same object category를 지닌 데이터 (컵이면 모양 색깔은 다를지언정 컵)
- 환경을 구성하는 요소들의 카테고리가 같은 데이터 (캐비넷, 싱크대, 테이블 등등)
해당 환경에서도 동일하게 50개의 human demonstration을 취득해 mimicgen을 통해 3000개의 데이터를 만들어 co-training에 활용했다고 합니다. 아래 Table들로 요약할 수 있을 것 같습니다.

Training and Evaluation Protocol
실험은 co-training 진행시 기존의 존재하는 데이터와 digital cousin 데이터셋의 효과를 비교하는 실험으로 진행했다고 합니다. 평가는 real data를 취득한 환경에서 그대로 진행했고, visumotor policy는 Diffusion Policy를 활용했습니다. Panda 기준으로 ResNet 기반의 시각 인코더를 활용했고 세장의 128 * 170 이미지 뷰와 propreoception 정보를 input으로 받았다고 합니다. 또 task에 해당하는 텍스트를 CLIP sentence encoder로 임베딩해서 FiLM을 통해 DP에 얹어서 사용했다고 합니다. 이해하기로는 일단 DP니까 VLA는 아닌거같은데,, 텍스트 요소를 신호로 주는 것 같습니다. Real data와 simulation data는 1:9 비중으로 사용했다고 합니다. 휴머노이드의 경우는 UMI기반의 DP를 사용해 ViT를 인코더로 써서 학습하고 평가했다고 합니다. Training 중에 동일한 지점에서 3개의 checkpoint를 가져와 평가를 진행하고 셋 중 가장 높은 SR을 final result로 활용했다고 합니다.
Experiments
Effectiveness of Sim and Real Co-Training
앞선 세팅대로 실험을 진행한 결과로, 각 시나리오별로, 둘을 섞어서 구성했을 때의 실험결과입니다.
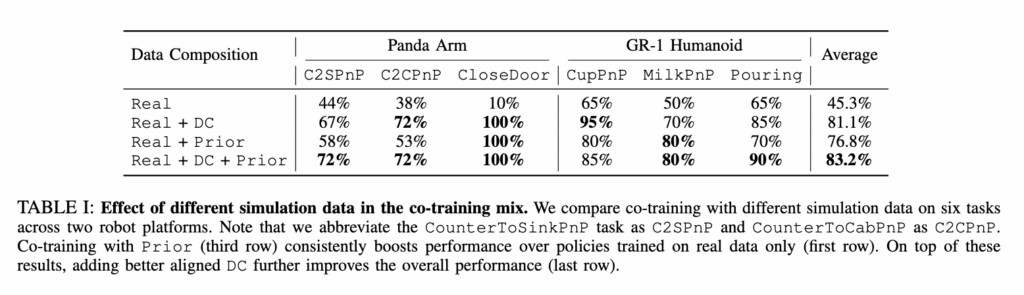
우선 Digital Cousin 환경에서 취득한 데이터를 취득했을 경우가 성능 향상에 많은 영향을 미친다는 점을 보면 확실히 ‘현실스러운’ 환경에서 취득한 데이터가 성능 향상에 효과적임을 시사하는 것 같습니다. 또한 기존 데이터셋 환경(robocasa)으로 취득한 데이터만 가지고 co-training할때와 DC환경과 혼합하는 경우 둘 다 성능 향상이 되는것으로부터 allign이 맞지 않는 어느정도 비슷한 기존 시뮬레이션 환경을 통해 제작된 데이터로 학습하는 것도 성능 향상에 긍정적인 영향을 미친다는 점도 중요한 포인트인 것 같습니다. 또 Panda 기준의 CloseDoor의 경우 co-training을 진행하는것 만으로 성능이 100%로 향상되는 것을 알 수 있는데, 단순 데이터 수가 늘어서 그런것인지를 확인하기 위해 저자들이 closedoor의 real demo 50개를 추가로 취득해 100개의 데이터로 진행했을 때 80%를 달성했다고 합니다.
Generalization Beyond Real Demonstrations
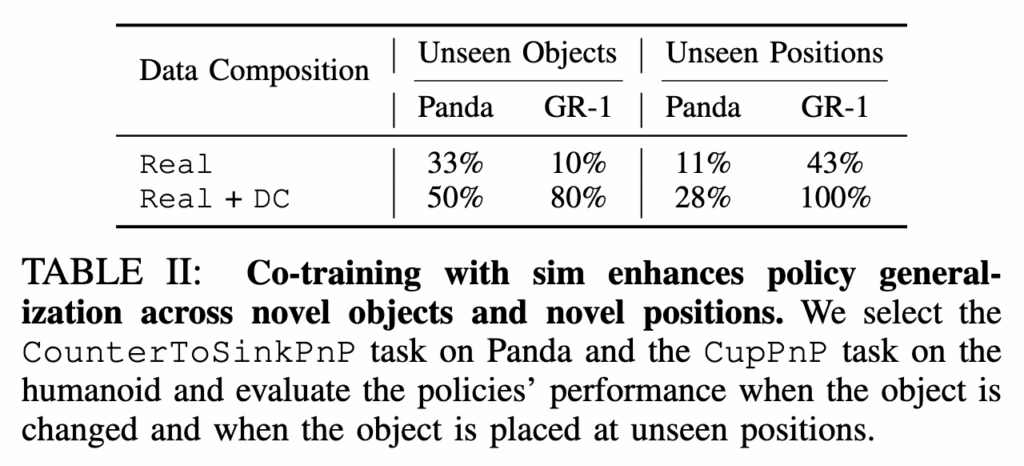
시뮬레이션 데이터가 real world에서의 unseen 작업 성공률에 대한 영향에 대한 실험입니다. 해당 실험은 시뮬레이터의 강점중 하나인 “로봇이 같은 태스크를 다른 환경에서 학습했을 때” unseen 환경에서 generalization 성능이 향상되는가?에 대한 답변을 주는 실험입니다. Panda 기준으로 해당 실험은 학습 때 보지 못 한 위치에 보지 못 한 object를 두고 counter to sink 작업을 평가했습니다.

결과는 아래 TABLE II와 같습니다. Unseen objects와 positions인 경우 둘 다 DC 환경에서 취득한 데이터를 추가했을 때 성능 향상을 볼 수 있었습니다. 이를 통해 시뮬레이션의 데이터 다양성이 real world에서의 성능 향상에 기여함을 알 수 있습니다. prior의 경우는
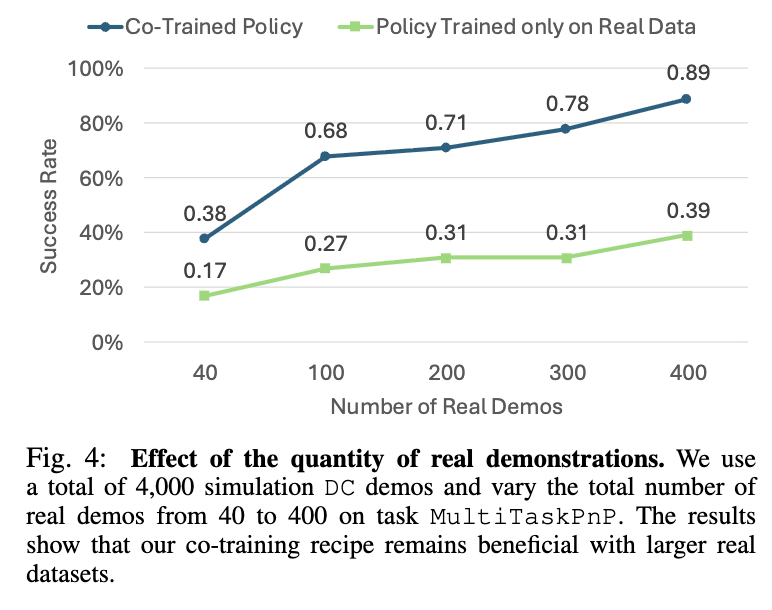
Effectiveness of Co-Training in Data-Rich settings
이번 실험은 과연 Real Data가 많을 때도 co-training이 효과적인가? 입니다. 사실 pi zero와 같은 모델들은 이미 대규모의 real data로 학습을 진행하고 있고, 현실 데이터도 시간이 따라 점점 불어나기 때문에 해당 실험도 의미가 있지 않나 싶습니다. 다만 한 task에 400개까지 실험을 했는데 이 숫자가 적당한 숫자인지에 대한 기준이 없어서 아쉽습니다. 왼쪽의 figure 4는 휴머노이드로 4개의 multitask를 진행했을 때 novel object로 평가를 진행했을 때의 결과입니다. Real demo의 숫자가 늘어남에 따라 co-training 했을때의 SR이 같이 향상되는 모습을 볼 수 있습니다.
Key Elements of Effective Co-Training
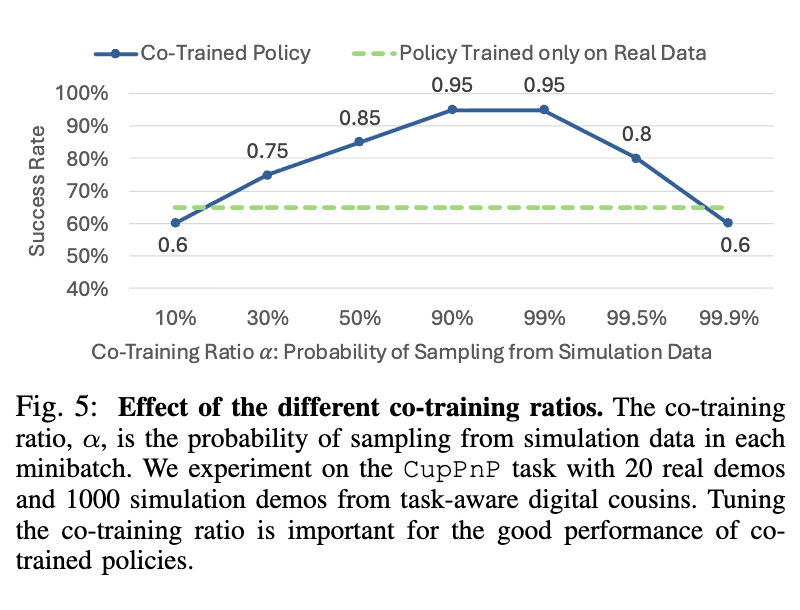
이번 실험은 성공적으로 co-training을 진행하기 위해 중요한 요소들에 대한 실험입니다. Real과 Sim 데이터의 비중과 DC 환경에서의 camera pose allignment의 중요성에 대해 다루었습니다. 우선 당연하게도 시뮬레이션 demonstration 수를 충분히 구하는 것이 중요하다고 합니다. 배치를 구성할 때 simulation 데이터 샘플링을 1만개 대신 500개에서 진행했을 때, Panda의 counter to sink 기준으로 67%에서 53%로 성능 저하가 일어났다고 합니다. 휴머노이드에서도 마찬가지로 sampling하는 data의 풀을 줄였을 때 성능 하락이 발생했습니다. 다만 500개의 비교적 적은 숫자로도 성능 향상이 일어난다는 점을 알 수 있었습니다.
다음은 co-training시의 simulation data의 비중 tuning에 대한 결과입니다. 결과는 GR-1에서 평가된 Cup pick and place 기준으로 리포팅 되었습니다. Real data와 sim data를 1대1로 가져갔을 때 suboptimal 하고, 90% – 99%까지도 95%의 성공률로 optimal 하지만 real data 가 부족해지면 오히려 성능 drop이 일어나기 시작합니다. 학습시 Real Data의 존재감도 역시 강한 것 같습니다. 어쩌면 좀 더 contact-rich 하거나 물리법칙이 중요한 task로 평가할때는 이 비율이 달라지지 않을까 하는 생각도 들었습니다. Task가 너무 단순한 pick and place라 아쉬웠습니다. 또 optimal 한 데이터 비율 부근에서는 0.1퍼 단위로 성능이 왔다갔다 하는것을 봤을 때 특정 구간에서는 정말 미세하게 비율을 조정하는 것도 중요할 수 있겠다 싶었습니다.
마지막은 Camera alignment에 대한 실험입니다. 우선 저자는 성공적인 co-training을 위해서는 카메라 시점을 정렬하는것이 정말 중요하다고 강조합니다. 핀트를 잘못 잡은것인지는 모르겠지만 Robosplat도 동일하게 panda arm을 ResNet인코더 사용하는 DP로 학습시켰던걸 생각했을 때 camera pose augmentation을 진행하고 오히려 일반화에 도움이 된다고 했는데, 둘을 섞으면 결과가 어떻게 되는지 궁금해지긴 합니다. (써놓고 보니까 해당 논문은 augmentation 얘기를 하는 논문이 아니라 핀트를 잘못 잡은 것 같습니다..)
어쨌든 저자는 아래 figure 6와 같이 DC환경에서 데이터를 취득하고 co-training하는 과정에서 camera pose를 align하고 취득한 데이터가 default view(misalign) 환경에서 취득한 데이터보다 10% 이상 높은 작업 성공률을 보여주었다고 합니다. 다만 현실에서는 fisheye cam을 사용하고 시뮬레이션에서는 사용하지 않았는데, 성능 향상이 된 것으로 보아 Lens distortion은 엄청나게 큰 차이를 만들어내지 않는 것 같다는 흥미로운 결론을 내렸다고 합니다.

Would improving visual realism enhance co-training?
Appendix에 추가로 들어있던 항목인데, 제일 눈에 들어오는 소제목이었습니다. Digital cousin 환경에서 camera alignment를 맞추는 것과 같이 시각적인 요소가 성능 향상에 도움을 주었는데, 시각적으로 현실적인 simulation 데이터(배경의 유무 포함 영상의 현실성)가 의미가 있는가? 에 대한 내용이었습니다. Vid2Vid라는 디퓨전 모델을 활용해 시뮬레이션 영상을 더 현실스럽게 바꾸어 활용했을 때 noise strength가 강해지면 객체의 위치가 바뀌면서 action에 대한 label을 활용할 수 없어 아래 figure 기준 0.6으로 두었는데, 그 기준으로 5-10% 정도의 성능 향상이 있었다고 합니다. Cosmos를 활용하면 어떨지 한 번 실험을 해봐야 할 것 같습니다. 저자들도 파이프라인에 생성형 모델을 결합하는 접근이 잠재력이 있다고 말하고 그래픽 렌더러에 의존하지 않는 방법으로 확장하는것이 유의미한 TODO라고 합니다.

A simple Recipe for Co-Training
그래서 결론적으로 저자들이 이러한 empirical한 실험들을 진행하고 얻은 co-training의 레시피가 뭐냐?에 대한 답변은 다음과 같습니다.
- Task, Scene 구성 : 실제와 유사한 장면을 구성해야 co-training의 결과가 좋아진다. Digital Cousin을 활용했지만 더 현실같은 환경에서는 더 좋은 결과를 얻을 수 있지 않을까 싶습니다.
- Object의 구성과 초기위치의 분포 : 다양할수록 unseen task에 대한 일반화 성능이 좋아진다고 합니다.
- 시뮬레이션 환경 data와 Real data의 정렬 : task의 성공, 실패를 판단하는 기준이 동일해야 하고 카메라 시점도 유사하게 맞추는것이 중요하다고 합니다.
- 우선 현실 데이터와 비교했을 때 굉장히 많은 수의 시뮬레이션 데이터를 만들어야 하고, 학습시에 시뮬레이션 데이터와 real data의 비율을 미세하게 tuning해야 최적의 성능을 얻을 수 있을 것이라고 합니다.
ETC
해당 내용은 Appendix의 FAQ에 해당하는 내용들입니다. 시뮬레이션 환경의 physics를 tuning하는 것이 학습에 영향을 미치지 않았느냐? 라는 질문에 GR-1으로 cup pick and place를 수행할 때 SR에 변화가 없이 그대로 95%였다고 대답했습니다. 이것또한 task가 너무 단조로워서 그런거 아닌가 싶습니다. 일단 pick and place 수준에서는 물량 tuning에 대해 문제는 없는 것 같습니다.
추가로 domain randomization이랑은 뭐가 다르냐? 라는 질문에는 domain randomization을 진행하면 추가적인 성능 향상을 경험할 수 있지만, domain randomization 없이도 co-training만 진행해서 현실에서의 성능이 향상되는게 주목해야할 포인트라고 합니다.
Limitations & Conclusion
‘시뮬레이션 환경에서의 데이터 취득이 cost가 낮은 이점이 있다’ 정도로만 막연하게 생각하고 있었고 real data와 같이 training을 하는 것에 대해서는 깊게 생각해보지 않았는데, 그 점에 대해 다양하게 분석을 해준 논문이라 읽는게 의미가 있었던 것 같습니다. 다만 실험이 좀 제한되고 단순한 환경에서 진행된 것 같고 co-training에 대한 특별한 방법론은 다루지 않아서 다른 논문들도 몇개 보였는데 읽어봐야 할 것 같습니다.
저자들도 대부분의 실험이 pick and place 수준으로 진행된 점이 아쉽다고 합니다. High precision이 필요하거나 longer horizon인 task들로 실험이 future work로 남아있다고 합니다. 또한 policy 자체의 성능에 따라서도 다른 결과가 나올 수 있다고 합니다. 마지막으로 deformable, liquid에 대한 co-training도 future work로 남아있다고 합니다. World model로 나아가야 하는 방향이 여기서도 좀 보이지 않나? 싶습니다.
안녕하세요, 영규님. 좋은 논문 리뷰를 남겨주셔서 감사합니다.
리뷰를 읽고 제가 이해한 바로는, Real 데이터는 대량으로 수집하기 어렵기 때문에 sim 데이터를 적절히 활용하여 Real과 sim을 혼합해 사용하는 방식이라고 생각되었습니다.
또한 논문에서 시각적 사실성을 높이기 위해 Vid2Vid와 같은 모델을 활용할 때 ‘noise’를 추가하는 것이 성능 향상에 기여한다고 언급하셨는데, 여기서 말씀하신 noise가 단순히 배경, 그림자, 광원 효과 등 시각적 디테일을 의미하는 것인지 궁금합니다. 또한 이러한 부분이 시뮬레이터에서 광원을 직접 모델링하여 처리하는 것과는 어떤 차이가 있는지도 궁금합니다.
좋은 논문 리뷰를 공유 감사합니다. 👏
안녕하세요 기현님 읽어주셔서 감사합니다.
Real-sim co-training은 이해하신게 맞습니다. 다만 시뮬레이션 데이터는 시뮬레이터 내의 환경에서 로봇이 상호작용 하는 장면을 시뮬레이션 내의 카메라에서 직접 캡쳐하는 식으로 진행되기 때문에 시뮬레이션 렌더링의 결과물보다 현실적일 수는 없다는 한계가 존재합니다. 이를 위해 시뮬레이션으로부터 취득한 덜 현실스러운 프레임들을 더 현실스럽게 만들기 위해 Vid2Vid라는 디퓨전 모델을 통해 비디오를 더 현실적으로 보이게 만들어줍니다.
이 때 디퓨전 모델은 입력 영상에 잡음을 넣고 점점 제거하면서 영상을 생성하는데 글의 figure12를 보면 noise strength가 높아질수록 원본을 덜 보존하지만 현실적인 영상이 만들어집니다. 다만 noise strength가 높아지면 로봇팔이나 물체의 위치가 미묘하게 변하는 것을 볼 수 있는데요, 이렇기 때문에 라벨링된 데이터가 망가지지 않는 선에서 적당한 noise strength를 사용합니다.
광원을 시뮬레이터에서 모델링 하는것도 여러 환경을 모델링 할 수 있다는 장점이 있기때문에 augmentation을 진행할 때 활용되지만, vid2vid를 사용하는것은 현실성을 향상한다고 보시면 될 것 같습니다.
안녕하세요 영규님 좋은 리뷰 감사합니다.
Real vs Sim 데이터 비율에 대한 의문이 들어서 답글 드립니다.
α=0.99면 거의 시뮬레이션 데이터만 학습하는 셈인데, 그래도 Real Data가 완전히 빠지지 않고 아주 작은 비중으로라도 들어가는 것만으로도 효과적이다라는 것을 보여주는 건지 궁금합니다. 아니면 왜 적절한 α값이 0.99였는지가 궁금합니다.
감사합니다.
안녕하세요 우현님 리뷰 읽어주셔서 감사합니다.
우선 저자들이 실험한 환경과 task 기준으로는 맞습니다. 시뮬레이션 데이터 비중이 10퍼센트일 때 부터 99퍼센트일 때 까지 지속적으로 성능이 향상되는 모습을 보여주었고, 99퍼센트 보다 커지면 오히려 성능이 하락하는 모습을 보여주었는데요, real data가 많아도 문제지만 너무 없어도 문제고, 99대1 비율일 때 성능이 좋았다고 합니다. 이유는 경험적인거라 저자가 의견을 내지는 않았습니다.
다만 단순 pick and place 정도의 task여서 이런 결과가 나온건 아닌가 생각합니다.
안녕하세요 영규님 좋은 리뷰 써주셔서 감사합니다.
아직은 읽으면서 용어가 이해가 안되는 부분이 많아서 제가 정확히 이해한지 의문이네요.
제가 궁금한 점은, Domain gap이 큰 시뮬레이션 데이터를 저자는 Robocasa 데이터 셋을 사용한 것으로 보았습니다.
하지만 언급된 데이터 셋을 task를 진행 할 때 그대로 가져다 쓸 수 있다는 점을 보아 Domain gap이 크다? 에 의문이 생겼습니다.
Domain gap이 크다의 기준이 혹시 따로 있는 건가요?
안녕하세요 인하님 읽어주셔서 감사합니다.
저자가 말하는 Domain Gap은 두가지가 존재하는데요, 첫 번째는 물리적으로, 광학적으로 시뮬레이터가 현실과 완전하게 동일할 수 없기 때문에 ‘현실성’의 gap이 존재합니다. 두번째는 물체를 집어서 싱크대에 넣는 task를 진행한다는 가정 하에 싱크대의 위치, 크기 등이 미리 만들어진 시뮬레이션 환경과 현실 작업공간이 같지 않다는 점에서 domain gap이 있다고 할 수 있습니다.
정리하자면 시뮬레이션 자체의 현실성 부족, 해결하려는 task를 위해서 정교하게 설계되지 않은 환경 내 요소들의 구조차이 라고 볼 수 있습니다.
안녕하세요 영규님, 좋은 리뷰 감사합니다.
Robocasa에서 제시한 co-training 정의에서의 가중합 alpha 값 비율에 좀 충격을 먹었네요. 진짜 말씀하신대로 그냥 거의 시뮬레이션 데이터로 학습하는데, real data 한방울씩 톡 떨어뜨리니까 마치 real의 그 고농도,고퀄리티 knowledge가 사악~ 퍼져서 영향을 주는 것처럼 느껴집니다. 즉 alpha값의 미세조정이 말 그대로 핵심인 것 같은데, 근데 오히려 극단적인 alpha값 비율로 인해 운 나쁘면 real world domain 정보에 대한 catastrophic forgetting 문제가 일어날 수 있는 건 아닌지 우려되기도 합니다. 다른 방식의 real-sim co-trianing 방법론들도 있나요? 일반적인 domain adaptation의 teacher-student 구조 knowledge distill 방법론처럼?
또한 이제 궁금해지는 게 0.9~0.99정도의 비율로 시뮬레이션 데이터를 섞어주는 게 효과가 있는 건, 어느정도 대규모의 데이터일때까지 유효할 지(즉 시뮬레이션 데이터를 아주아주아주 많이 섞었을 때 성능 drop이 생길 수 있는 경우를 고려해서, 어느정도 upper 양까지 섞어도 되는지), 혹은 무조건 real data가 시뮬 데이터에 비례해서 꼭 0.01~0.1의 비율은 있어야 한다라는 최소한의 lower 역치를 알아내는 것도 영규님이 하시는 연구주제에서 어찌보면 핵심이 될 수 있을 것 같습니다. 0.9~0.99 : 0.01~0.1은 현재로써는 거의 불문율인가요? 아님 또 simulator 환경이나 task-specific 요소들, 환경들에 따라 결국 hyperparameter처럼 바뀌는 요소로 남게되는 건가요?
co-training 과정이 figure를 보면 마치 policy net의 인풋단에서 real-sim 간의 데이터 early fusion을 하는 것처럼 느껴지는데, policy net의 embedding 차원에서 real-sim 정보에 대한 fusion 방식을 적용하는 방식도 있나요?
마지막으로, 현실적으로 완벽한 scene을 구성하는 연구의 필요성도 고민해봐야한다고 언급해주시긴 했지만, 오히려 현재 존재하는, 현재 만들어진 여러가지 시뮬레이션 환경 데이터셋들을 noisy한 요소를 덜어내고 데이터 큐레이팅하는 것도 좋은 방법이 될 수도 있을까요?
감사합니다.
안녕하세요 재찬님 리뷰 읽어주셔서 감사합니다.
저도 실제로 알파값을 보고 좀 충격을 먹었습니다.. 진짜 그 고농도의 고퀄리티 knowledge가 사악-퍼지는건지… 다른 이유가 있는건지 다양한 task에 대해서 좀 더 원인이 분석되지 않은 점이 매우 아쉬웠습니다..
알파값의 미세조정은 저자들도 co-training에 있어서 제일 중요한 요소중 하나고, 그렇기 때문에 0.1 단위로 리포팅을 했다고 합니다. 저자들도 어떤 task를 진행할 때 이런 저런 값을 많이 넣어보라고 하더라고요,, 하하
다른 co-training에 대한 논문이 있긴 한데, 그 논문 또한 Diffusion Policy로 Push T task를 학습시킬때 다양한 empirical study만을 진행한 논문입니다. 아직 구체적인 방법론들이 많이 등장하진 않은 것 같습니다. 거기선 알파값 외에 시뮬레이션 데이터를 어떻게 augmentation 하는지에 대한 요소들도 등장했던 거로 기억하고 있는데,, 우선 알파값은 hyperparameter 처럼 인식되고 있는 것 같습니다.
마지막으로 질문주신 부분은 Digital Cousin (ACDC 연구)가 어느정도 해결했다고 생각합니다. 다만 기존의 asset들이 많다고 해도 제한적이고, 구성하는데 시간이 매우 오래 걸리고, 완성도 면에서 digital twin과는 차이가 날 수밖에 없기 때문에 co-training 측면에서는 큐레이팅 하는 것도 좋은 방법으로 결론이 난 것 같습니다만, 다른 real to sim to real 같은 측면에서는 여전히 중요한 문제인 것 같습니다.