안녕하세요. 이번 논문은 CLIPSELF 라는 논문입니다. CLIP 의 모델 설계구조상 가지지 못하는 locality를 self distill 방식으로 보완하였고, Object detection 뿐만 아니라 segmentation 까지 쓰일 수 있는 방법론입니다. 자기지도학습이라는 타이틀을 유지하면서 CLIP 의 ViT 를 재학습시킬 수 있는 방법론입니다. 그럼 리뷰 시작하겠습니다.
ABSTRACT
Open-vocabulary dense prediction 이라는 task 는 CLIP 의 등장으로 많이 발전되어왔다고 합니다. 여기서 OVDP 라는 이 task는 이름에서 유추할 수 있듯이 Open vocabulary object detection과 image segmentation, panoptic segmentation 까지 pixel 이나 patch 단위까지의 정보를 예측하는 task라고 생각하면 됩니다.
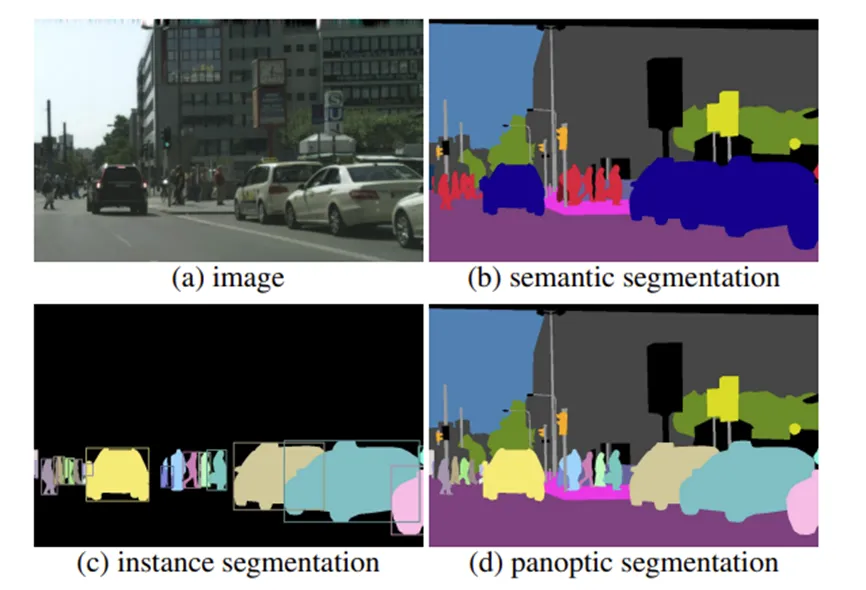
그 주역으로 CLIP 의 image encoder 인 ViT 가 주목할만한 일반화 성능을 가지고 있기 때문이라고 언급하는데, CLIP의 ViT는 이미지의 전역적인 부분과 텍스트가 align 되어 학습되었지만 이 부분을 patch 나 ROI 수준으로 가져오면 분포가 달려저서 ( domain shift 때문에 ) OVDP task에 어려움을 겪는다고 합니다. 뭐 사실 간단하게 얘기하면 pixel 이나 patch 단위의 이미지-text 쌍을 CLIP image encoder인 ViT가 학습한적이 없으니 local 적 정보에 취약하다는 점을 언급한 것입니다.
저자는 dense-vocabulary alignment 는 clip 의 downstream task인 OVDP 에 필수적인데, 이를 향상시킬 방법으로 CLIPSELF 라는 방법론을 제안하게 됩니다. 간단히 얘기하면 해당 방법론은 region-text 쌍이 존재하지 않더라도 CLIP ViT의 이미지 수준 인식 능력을 지역적 이미지 영역으로 적응시키는 방법입니다. ( 여기서 region은 전체 이미지의 patch 혹은 ROI 입니다.) 방법은 image 의 dense feature map 에서 추출한 지역 표현이 해당 이미지 crop의 이미지 수준 표현과 정렬시켜 ViT가 self-distill 할 수 있게 한 방법론입니다.
물론 이렇게 얘기하면 무슨 얘기인지 이해가 잘 안될 것이므로 차차 설명하겠습니다.
Introduction
저자는 OD task segmentation task 등의 발전과 CLIP 의 발전을 언급하고 CLIP 이 classification 뿐만 아니라 OD task를 수행하려면 vision-language alignment 를 full images 에서 local images region 으로 옮겨가는 것이 필수적이고 특히 CLIP 의 ViT-based variants가 더 그럴 필요가 있다고 주장합니다. ( 이미지의 지역적 특징을 아무래도 언어보단 이미지단에서 찾는것이 자연스럽습니다.)
저자는 이러한 상황을 고려하여 사전실험을 진행하는데, 이는 CLIP의 dense features가 local object 인식 수준이 어느정도인지 먼저 확인해봅니다.
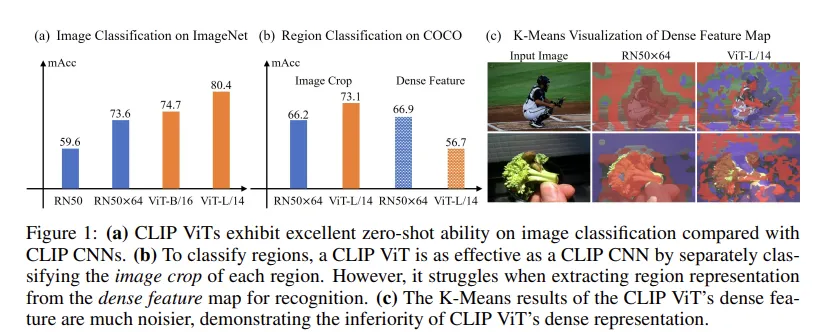
우선 (a) 실험은 기존의 classification 성능으로 ViT계열이 ResNet 계열을 압도한다고 적혀있습니다. 저자가 선행실험을 해본 부분은 (b) 부분으로 Image crop 과 Dense feature 성능을 비교하고 있습니다.
Image crop 실험은 이미지를 Crop 하고 ViT 인코더에 넣어 image-level classification 능력을 이용한 것입니다. 여기서는 crop 된 이미지를 ViT에 태우고 나온 CLS 토큰을 사용합니다. ( 왜 CLS 토큰이냐고 생각할 수 있는데, crop 이미지의 전역적 토큰인 CLS가 원본 이미지의 지역적 representation을 가지고 있다고 생각하면 됩니다. ) 여기서 생각해볼 수 있는 점은 기존 (a) 의 Image classification 에 있는 ViT-L/14 에서 80.4 성능이던 것이 Image crop 을 이용하여 classification 하면 73.1로 성능이 하락한다는 것인데, GT box부분만 crop 해서 ViT를 태워 성능을 체크했더니 성능이 낮아진 이유는 이미지의 객체 주변부 정보가 사라져 성능이 하락했기 때문이라고 생각합니다.
Dense Feature 실험은 우선 dense feature map 을 input image로 부터 얻고, 지역적 representation을 추출하여 인식 능력을 평가한 것입니다. 여기서 dense feature map은 단순히 이미지 전체를 ViT로 태워 CLS 토큰을 제외하고 남은 feature map입니다.
표의 순서상 image classification 성능이 RN 보다 ViT가 더 좋은데 Region classification 으로 넘어가면 Dense Feature의 성능이 RN 이 더 높고, Image crop 으로 던져줬을때의 ViT 성능은 여전히 ViT가 더 높으므로, 이 성능을 이용하면 어떨까 하는 내용을 보여주고 있습니다. Figure 1 의 (c) 를 보면 Dense Feature map을 각각 K-mean 으로 묶어서 시각화 하였을때 ResNet이 ViT보다 확실히 배경이나 객체에 대한 segmentation 구분력이 존재하는 것을 확인할 수 있습니다.
여기서 Feature map은 패치단위에서의 각각의 vector 이고, K-Mean 으로 묶었을때는 cosine sim 을 이용하여 K 개의 cluster를 만들었다고 생각하면 됩니다.
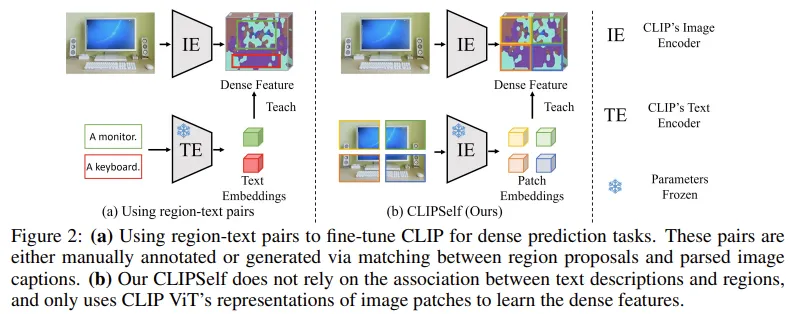
저자는 Dense feature map 의 성능을 가장 직관적으로 올려줄 수 있는 방법으로 region – text 를 pair로 하여 학습시키는 방법이라고 합니다. Figure 2 의 (a) 그림으로 확인할 수 있는데, 해당 방법을 적용하기 위해서는 region 과 text의 pair 쌍을 annotating 해야하는데, 이는 자원이 많이 필요합니다. 이걸 해결하기 위해 RegionCLIP 은 text caption 에서의 object nouns 들을 추출하여 pseudo label처럼 사용하고 이를 각 region 과 짝지어 region-text pair 쌍을 만들고 학습시킨 방법입니다. 한계점도 간단하게 언급하는데, region proposal과 object noun을 단순 매칭하는 방식은 노이즈가 많고, 텍스트 설명은 지역을 충분히 표현하지 못한다고 합니다. 해당 지역에 해당 object noun에 해당하는 이미지가 없을 수도 있고, 단순 dog라는 텍스트가 해당 이미지의 지역을 충분히 표현하지 못할 수 있다고 주장하는 것입니다.
(b) 설명을 읽으면 알 수 있듯이 저자의 방법론은 regions와 text descriptions 와의 관계에 의존하지 않는다고 적혀있습니다. 각 region 패치에 맞는 text가 존재하지 않더라도 ViT의 representations 만으로도 dense feature로 하여금 배우게 할 수 있다고 합니다.
Methodology
저자는 ViT 에서 마지막 attention block 에 대해 Teacher 와 student 에 각각 다르게 적용하는 방법을 사용하였습니다.
CLIP’s Image Representation.
우선 기본적인 CLIP의 ViT 에서의 과정입니다.
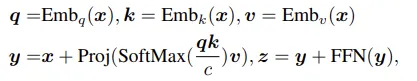
x는 cls 토큰에서부터 각 이미지 패치들을 임베딩 벡터화 시켜서 표현됩니다. 이 벡터를 이용하여 각 패치 사이의 attention score를 뽑고 v라는 벡터에 곱해주어 다른 패치들과의 관계가 가중합된 임베딩 벡터가 생겨나고 여기서 최종 output인 z의 cls토큰을 전역적인 토큰으로 사용합니다.
CLIP’s Dense Representation.
CLIP ViT에서 dense feature map을 뽑아내기 위해서 간단하게 마지막 residual attention block을 수정했다고 합니다.
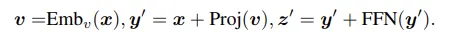
projection layer나 layer norm, FFN 등은 그대로 유지가 되지만 self attention 부분이 없어졌습니다. 또한 z’[0] 에 해당하는 cls 토큰을 사용하지 않고 해당 부분을 제외한 z’[ 1 : h X w ] 부분을 사용하여 dense feature map을 뽑아냈다고 합니다. 해당 feature map을 가지고 boxes 나 masks 등을 RoIAlign 혹은 mask pooling으로 뽑아낼 수 있다고 합니다.
우선 왜 기존에 존재하는 self attention 을 마지막 ResAttn block 에서 제외했는지와 cls토큰을 왜 dense representation에서는 안썻는지가 궁금할 수 있습니다.
이 부분은 논문에 구체적인 설명이 나와있지 않고, attention에 관련된 ablation이 존재하지 않아서 조금 아쉬움이 남지만, 논문의 다른 부분들을 읽고 드는 저자의 생각을 유추해 보자면,
우선 cls 토큰은 해당 input 의 대표특성입니다. 다른 patch들과의 연관성을 배우고 나온 대표 토큰인데, 이미지를 패치단위로 잘라서 input으로 넣어주게 되면 cls 토큰을 사용함으로써 원본 이미지의 지역적인 대표특성을 얻게되고 이를 teacher로서 사용하기에 적합합니다. 이미지의 전체사이즈를 넣어주는 dense representation 부분은 결국 OD나 segmentation task를 수행하려면 전역적인 정보를 담고있는 cls 토큰이 필요하지 않습니다. ViT의 마지막 12번째 layer에서 cls 토큰과 다른 patch들과의 self attention을 진행하게 된다면 원하던 지역적인 정보가 대표토큰과 섞여 지역적 정보의 소실이 일어난다고 저자는 생각하는 것 같습니다. CLIPSELF는 사전학습된 CLIP ViT의 가중치를 그대로 활용해야 하는 제약이 있습니다. 모든 layer에서 cls 토큰을 제거하거나 self attention을 빼는 행위는 사전학습된 가중치를 사용할 수 없게 되므로 마지막 layer만 수정하여 dense feature를 뽑는 전략을 선택했다고 볼 수 있습니다. 이러한 이유로 ablation을 하기에 좀 짜친다고 생각했을 것 같기도 합니다..
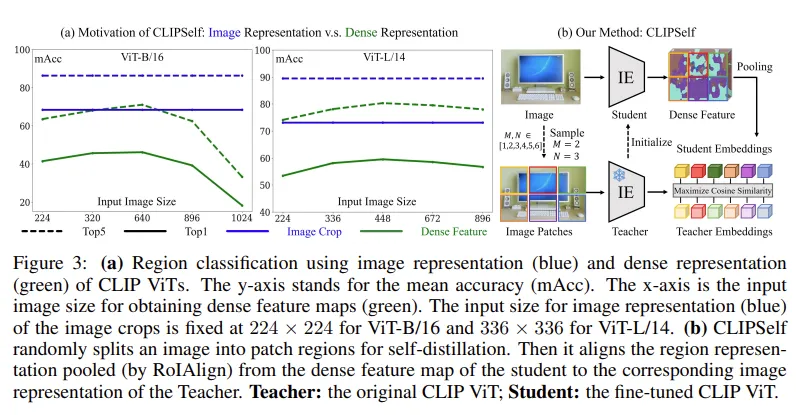
(a) x축 : dense feature map을 얻기위한 이미지 사이즈 y축 : mean accuracy blue : 정답 crop 후 ViT-B/16 은 224X224 , ViT-L/14 는 336 X 336으로 resize green : 전체 이미지 넣기 우선 crop 하여 넣은 성능이 dense feature의 성능보다 압도적으로 높은 것을 확인할 수 있으며, 기존의 ViT나 CLIP classification등에서는 이미지의 사이즈를 높여주면 올라가던 성능이 해당 task에서는 통하지 않는 모습을 보여줍니다.
(b) 전체 이미지를 랜덤 1~6 개수로 crop하여 ( N,M 모두) N*M 개의 crop들을 teacher 로서 사용하고, 전체 이미지를 넣은 dense feature map이 각 crop된 패치들의 정보를 학습하는 형태임을 알 수 있습니다.
Image Patches as Regions.
저자는 2가지 방식으로 실험을 해봤는데, 우선 랜덤으로 잘린 모든 patch들을 학습에 이용해봤고, ROI 로 객체위주로 뽑아서 해당 부분만 학습시켜보기도 했습니다. 랜덤으로 잘린 patch들은 {1,2,3,…M} 개의 랜덤 개수로 뽑힌 M X N 개의 패치로 학습되었습니다.
Self-Distillation.
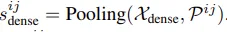
i,j 번째 patch (P^ij) 에 대해 dense feature map에서 pooling된 지역을 s^ij_dense 라고 한다면 self-distillation loss는
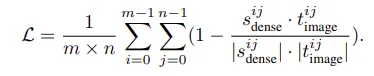
이런식으로 표현될 수 있습니다. 모든 패치들에 대해서 teacher의 vector 방향과 student의 vector 방향이 비슷해지는 방향으로 학습된다고 생각하면 됩니다. 분모는 정규화 term 이고 분자는 cosine simmilarity라 vector 방향이 가까우면 1이 되어 teacher를 따라가게 합니다.
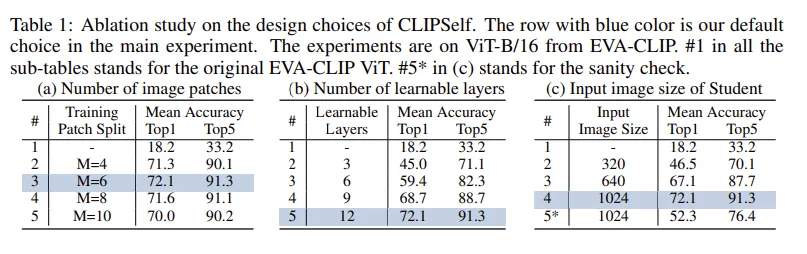
CLIPself 방법론을 EVA-CLIP 에서 적용했을때의 ablation이며 이미지 패치수와 learnable layer수 이미지 해상도를 ablation을 통해 결정했다고 합니다.
(a) 를 보면 1024 해상도를 6등분까지 선택하는것이 제일 효과가 좋았고 (b) 를 보면 당연하지만 ViT의 학습 layers 를 늘리는게 성능이 좋아지는 경향이 보입니다. (c) 에서 주목할 점은 region-level self distill 방식으로 학습을 시키니 위의 figure 3 에서 이미지 해상도에 따른 성능이 감소 되던 경향성이 성능이 증가하는 경향성으로 바뀐 모습을 확인할 수 있습니다. 5* 실험은 4번실험의 추가실험으로 region-level distill 없이 단순히 image-level 로 학습했을때의 성능입니다. 저자는 이 실험을 통해 image resolution 뿐만 아니라 저자의 region-level distill 방식을 적용했을 때 성능이 더 높은 것을 확인할 수 있습니다. (52.3 → 72.1)

해당 Table2를 보고 여러정보를 얻을 수 있습니다.
Quantitative Evaluation.
region box classification 뿐만 아니라 COCO Panoptic dataset의 thing/stuff mask의 분류 정확도를 측정해본 결과 저자의 CLIPSELF 방법론은 bbox ,panoptic mask등에서도 성능 향상을 보입니다. 여기서 mask representation은 dense feature map에서 mask pooling으로 추출했다고 합니다.
Using Region Proposals.
RPN을 이용하여 COCO2017 의 48개 base category 들로 proposals들 생성하여 CLIPSELF 적용했습니다. 결과로는 Foreground 인식 성능이 올라가고 Background 인식 성능은 떨어집니다. 이는 proposals 들이 foreground 중심이라 stuff의 학습이 부족하기 때문이고 Region proposals 들은 detection 에는 유용하지만 segmentation같이 background까지 커버해야 하는 경우에는 random 하게 정보를 주는것이 더 좋은 것을 확인할 수 있습니다.
Qualitative Results.
Figure4는 Dense feature map 에 K-means clustering을 통해 pixel embedding을 시각화한 것입니다. CLIPSELF 로 파인튜닝 된 모델은 동일 객체 pixel 의 정보들을 더 잘 묶는 모습을 확인할 수 있습니다. 시각적으로 CLIP ViT dense representation이 개선됐음을 확인할 수 있습니다.
Experiments
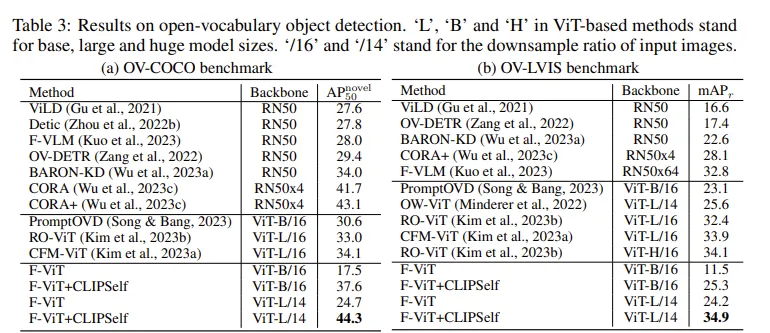
저자는 우선 OVOD 실험에서 EVA-CLIP 의 ViT 를 떼어와서 F-VLM 이라는 논문에서 제시한 방법대로 detect 하되 여기서 저자의 방법론인 CLIPSELF 를 적용했다고 합니다. 우선 EVA-CLIP 을 사용한 이유는 Open AI CLIP 은 4억쌍의 데이터로 사전학습되었지만 EVA-CLIP은 수십~수백억 단위로 학습되었고 추가적인 사전학습 전략들이 존재합니다. F-VLM 이라는 논문에서 제시한 방법은 CLIP ViT의 중간 layer feature 들을 꺼내서 interpolate 시킨 후 FPN 을 만들어 detecting한 방식입니다.
저자의 방법을 F-ViT에 붙였을때가 COCO novel class 와 LVIS 에서 좋은 모습을 보여줍니다.
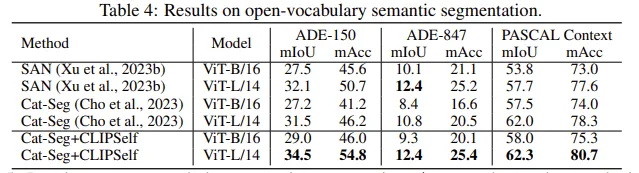
semantic segmentation 에서는 cat-seg 라는 방법론에 저자의 CLIPSELF 를 붙였습니다. 전체적으로 데이터셋에 상관없이 모두 성능이 향상되는 모습을 보입니다. 여기서 mIoU 와 mAcc는 얼핏보면 비슷해보일 수 있지만 iou 는 FP 를 고려하지만 acc는 fp 를 고려하지 않는 값입니다.
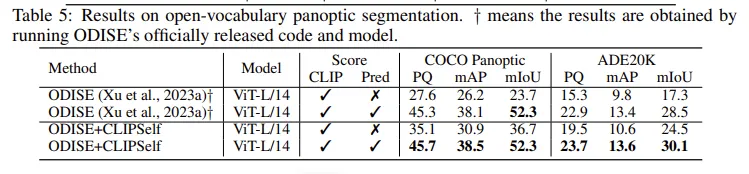
panoptic segmentatoin 에서는 ODISE 에 저자의 방법론을 붙였으며
score 에서 clip 과 pred 를 각각 선택하거나 안한걸 볼 수 있는데 이는 CLIP 의 confidence score 만 사용한 경우와 mask generator가 예측한 class score를 fusion 해서 사용했을때의 성능이며 fusion 했을 때 성능이 대폭 향상하고 저자의 CLIPSELF 를 적용하면 조금 더 오르는 것을 알 수 있습니다. 여기서 CLIP score 만을 사용할때에는 저자의 방법론이 성능향상을 큰 폭으로 하는 것도 알 수 있습니다.

Table 6 으로는 RegionCLIP 방식과 저자의 방식에서의 각각 성능 차이입니다. 저자의 방법론이 모든 task 에서 더 나은 성능을 보여주고 있습니다.
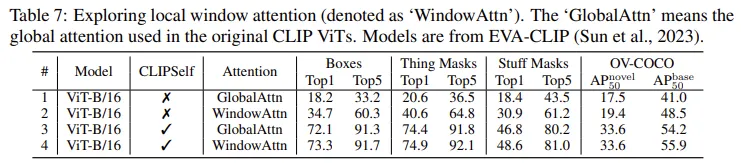
Table 7 은 teacher의 마지막 Attention 방식을 global로 할지 window 방식으로 지역적 패치위주의 attention을 할지를 ablation 한 결과입니다. 저자의 CLIPSELF 방법론을 사용하는 것이 훨씬 큰 성능향상을 보여주고 있습니다.

Table 8 은 COCO 데이터에 과적합된게 아니냐는 질문을 피하기 위해 다른 데이터셋에서의 CLIPSELF 방법론 성능 향상폭을 보여주고 있습니다.
Conclusion
저자는 ViT 기반 CLIP 모델의 dense feature map을 체계적으로 분석하고 dense representation은 지역적 표현력이 낮다는 것을 지적하며 CLIPSELF 방법론을 통해 self-distillation 방식으로 feature representation을 향상시킬 방법론을 제안했습니다. 해당 방법론은 OVOD & OVIS 등 여러 task 에 확장될 수 있고 Local window attention에서의 가능성을 보여 swin transformer 계열에서도 적용 가능할 것으로 보입니다. 단순하지만 효과적인 방법으로 CLIP ViT의 dense map representation을 강화한 방법론이라고 할 수 있습니다.
안녕하세요 인택님 좋은 리뷰 감사드립니다. 저도 이거랑 결이 살짝 비슷한 실험을 진행중에 있었는데 재밌게 읽었습니다.
먼저Teacher가 crop 이미지 전역 표현을 잘 잡지 못한다면 Student도 한계가 있을 수 있을 것 같다는 생각을 했습니다. 특히 object 주변 context가 잘려나가는 문제 때문에 teacher signal이 약하거나 노이즈가 될 가능성은 없을까 하는 질문이 생깁니다다.
그리고 두번 째 질문인데 RegionCLIP은 region-text pair를 만들어 학습하지만 noise가 많다는 단점이 있다고 하셨고
CLIPSELF는 text 없이 self-distill만으로 dense alignment를 강화하는 것으로 이해했습니다.
여기서 드는 의문은 정말 text supervision이 필요없었던 것인지 혹은 self-distill만으로는 특정 semantic alignment가 약해질 가능성도 있지 않을까 이런생각이 듭니다. 즉, text-free 학습으로 local 표현이 강화되더라도, semantic alignment는 오히려 약화될 수도 있지 않나 이런생각이 드는데 이런 내용이 논문에서 다뤄졌었는지 궁금합니다.
감사합니다.
안녕하세요 우현님 답글 감사합니다.
knowledge distill을 teacher 모델로부터 하는만큼 저자는 classification 과 image corp 부분에서 teacher의 성능이 높은것을 figure를 통해 먼저 언급하는 것 같습니다. 기존 SOTA 성능에 비해 image crop ViT 성능이 높아서 충분히 뽑아낼만하다 생각한 것 같습니다. 그리고 저자는 OD 뿐만 아니라 segmentation까지 해야하는만큼 사실 object 주변 context가 잘려나가는 것까지 고려할 필요가 없었을 거라고 생각합니다. K-means로 픽셀단위의 표현력이 좋아지는 것까지 보여주었기에 ViT의 지역적 표현력이 증가하면 OD 뿐만 아니라 segmentation 까지 좋아지는 것을 실험적으로 보여준 거라고 생각합니다.
두번째 질문은 저도 들었던 생각이긴 한데, 논문에서 다뤄지진 않았고 사실 성능이 그렇지 않았다는 것을 보장하고 있기 때문에 왜 저런 악영향이 없었는지 굳이 생각해보자면 이미 text 와 align 되어있는 ViT에서 knowledge 를 뽑아냈기 때문이 아닌가 라고 생각하고 있습니다.
감사합니다.
안녕하세요. 리뷰 읽고 궁금한게 생겨 질문 남깁니다.
구체적인 학습 과정이 제가 머릿속에서 잘 그려지지 않는데, CLIP ViT encoder의 제일 마지막 단에 dense feature를 추출하는 (self-attention이 존재하지 않는) block과 image crop에서 특징을 추출하는 (self-attention이 포함된) block이 있는 것으로 이해를 했습니다.
이 image crop을 처리하는 block에서의 output이 teacher가 되는 것이고, dense feature를 추출하는 block에서의 output이 student가 되는 것으로 이해를 했는데, 여기서 궁금한게 Self-distillation 학습 중에 제일 마지막단 block을 제외하고는 모든 CLIP ViT Encoder의 layer들이 pretrained CLIP weight으로 초기화된 다음 freeze 상태로 존재하는건가요?
그리고 image crop을 처리하는 block의 경우에도 마찬가지로 기존 CLIP의 pretrained weight으로 온전히 활용되고 freeze되며, 오로지 학습이 되는 weight는 dense feature를 추출하는 block만 해당되는건가요?
그림 3 우측에 무언가 학습 framework이 설명되어있는데 여기서는 단순히 teacher는 freeze, student는 learnable하게 학습한다고만 표기되어있어서요. 저 그림만봐서는 Student의 ViT Encoder 전체가 다 학습이 되는 것처럼 보이는데 만약 모델 weight 전체가 다 학습이 되는 것이라면 기껏 수십억개의 데이터로 학습한 가중치를 COCO와 같은 상대적으로 매우 적은 양의 데이터로 학습해서 모델의 일반화 성능을 망치는 것이 아닌가 하는 걱정이 들어서요.
마지막으로 self-distillation loss를 계산할 때 dense feature에다가 pooling을 적용하는 이유도 추가적으로 설명해주시면 감사하겠습니다.
안녕하세요 정민님 답글 감사합니다.
우선 dense feature 는 CLIP ViT의 마지막 layer에서 self attention 을 제거한 부분의 최종 출력이며
crop feature 는 CLIP ViT 의 마지막 layer 출력의 cls 토큰입니다. 원본 ViT encoder 를 그대로 사용한다고 생각하면 됩니다.
teacher 모델은 pretrained 된 상태에서 freeze 시키고 정보들만 뽑아서 사용합니다.
student 모델은 코드 확인결과 마지막 layer 기준 몇개를 unlock 해서 학습시킬지를 args 인자로 받게 되어있고 default가 3입니다. ViT layer 12개중에 3개를 학습시키는게 기본 코드로 보이네요. 해당 부분은 parse args 로 선택해서 실험이 가능할 것 같습니다.
마지막 질문 답변으로 pooling 적용하는 이유는 dense feature 는 이미지 전체에 대한 feature 를 가지고 있고 grid 형태의 2차원 최종 출력을 가지고 있습니다. teacher는 crop 시켜 ViT에 태우게 되고, 이는 cls 토큰인 1차원 벡터로 나오게 되는데, 해당 차원을 맞춰주기 위해 평균 pooling 을 사용해서 정보를 distill 해줄 수 있게 됩니다.
감사합니다.
좋은 리뷰 감사합니다. 읽다 궁금한 점이 있어 질문 남기겠습니다.
1. ResNet과 ViT의 dense feature map을 K-Means하였다고 하는데, 이게 구체적으로 무엇을 클러스터링한건가요? featuremap을 패치로 나눠서 벡터로 만든건가요?
2. vit의 경우 입출력이 1d 벡터 형태로 나오기 때문에 dense feature map 형태로 사용하기 위해서는 다시 2d형태로 변환해줘야 할 것으로 생각되는데, 이 과정을 구체적으로 어떻게 수행하나요? CLIP’s Dense Representation 부분에서 [CLS]토큰 이외에 z’[ 1 : h X w ]부분을 사용한다고 했는데, 그럼 1d 벡터 형태를 단순해 HxW으로 reshape한것인가요?
안녕하세요 재연님 답글 감사합니다.
1. 해당 부분은 논문에 구체적으로 설명이 없고 코드도 제공되지 않았었는데, github issue 에서 저자가 공개한 코드기반으로 설명드리면 dense feature map 의 모든 위치를 c 차원 벡터로 만들어 k-means 의 입력으로 사용합니다.
k 개수는 해당 이미지의 GT 마스크 개수로 결정되고, 클러스터 시킵니다. 이후 클러스터된 형태와 GT mask 의 겹침점도로 점수까지 반환해주는 형태입니다.
2. ViT의 최종출력이 1d 벡터라는 것이 teacher 는 cls토큰을 뽑으니까 1d 최종출력을 가질텐데 이를 어떻게 2d grid 형태의 student 에게 지식증류를 하냐는 질문으로 이해하자면 마지막에 평균 풀링을 사용하여 student 의 차원을 [D_model,H,W] 에서 [D_model] 로 바꿔주게됩니다. (ViT-B/16 기준 d = 512) 감사합니다.
좋은리뷰 감사합니다 인택님
self-distillation 과정에서 궁금증이 생겼는데요 CLIPSelf에서 Teacher와 Student 모델의 역할과 관계는 어떻게 설정되나요? 그리고 이 둘이 어떤 방식으로 지식을 전달하며 미세 조정(fine-tuning)되는지 구체적인 학습 과정이 궁금합니다.
감사합니다
안녕하세요 우진님 답변 감사합니다.
self-distillation 과정을 다른 논문들을 읽어본 것은 아니라 일반적인 설정 기준은 모르겠으나, 해당 논문 기준에서는 같은 구조에서 upper 성능으로써 지식을 전달해줄 수 있는 부분을 찾아서 설정한 것 같습니다.
지식을 전달하는 방식은 loss 함수를 보면 알 수 있는데, 좋은 성능을 내는 애의 임베딩 벡터 방향대로 안좋은 성능을 내는 애의 임베딩 벡터 방향을 옮겨준다고 할 수 있습니다.
감사합니다.
인택님 안녕하세요. 좋은 리뷰 감사합니다.
1. Dense feature를 추출할때 마지막 self-attention이 제외된 이유에 대한 고민을 적어주셨는데요, 논문상 기존 연구([1])를 따랐다고 언급되어있지 않나요? 참조한 논문이 있는만큼, 그 논문을 먼저 찾아보는 것이 가장 안전한 방식일 것 같습니다. 만약 참조 논문에 왜 위와 같은 방식으로 dense feature를 뽑았는지 밝히고있다면 답글로 남겨주시면 좋을 것 같습니다.
2. 리뷰 글 “Using Region Proposals.” 부분에, RPN에서 뽑은 영역을 CLIPSelf 학습에 활용하는것이 detection에서는 더 유용하다고 언급해주셨습니다. 혹시 국방 도메인 이미지에서 detection을 해야한다면, 그 상황에서도 RPN을 주는 것이 좋을지, 아니면 랜덤으로 grid를 주어 학습하는 것이 좋을지 인택님의 의견이 궁금합니다.
[1] Chong Zhou, Chen Change Loy, and Bo Dai. Extract free dense labels from CLIP. In Eur. Conf.
Comput. Vis., 2022a.
안녕하세요 현우님 답글 감사합니다.
질문에 대한 답변을 드리자면
1. 아래 [1] 논문기반으로 답변드리면 마지막 블록의 self-attention 을 제거하는 이유는 CLS 토큰 기반의 global feature 와 달리 patch-level dense representation을 얻기 위해서는 self-attention이 섞이기 전의 feature 가 더 직관적인 local 표현을 제공하기 때문이라고 합니다.
2. 음 국방 도메인 뿐만 아니라 어떤 데이터셋인지에 따라도 다르겠지만.. 국방 도메인의경우 보통 주변 배경과의 비슷한 색상으로 물체들을 색칠해놓는 경우가 많으니 명시적인 bbox로 어디까지가 국방객체인지를 주는 것이 중요할 수도 있고, 명시적으로 주지 않고 모델로 하여금 학습하도록 하는게 좋을 수도 있어서 CLIPSELF 논문의 성능과 상관없이 데이터셋마다 직접 해봐야한다고 생각합니다.