오늘은 기존에 연구하던 논문과는 집중하는 문제가 약간 다른 논문을 리뷰해보려고 합니다. 바로 Video-Text Model 인데, Mobile에 특화된 모델이라고 합니다. 바로 시작하겠습니다.
- Conference: ICCV 2025
- Authors: Min Yang, Zihan Jia, Zhilin Dai, Sheng Guo, Limin Wang
- Affiliation: Nanjing University, Ant Group, Shanghai AI Lab
- Title: MobileViCLIP: An Efficient Video-Text Model for Mobile Devices
1. Introduction
최근 비디오-텍스트 모델들은 다양한 video 관련 task에서 훌륭한 성능을 보였지만, 대부분 ViT-L 이상의 초대형 백본을 사용해 모델 크기와 계산량이 너무 커서 모바일 환경에서 활용되기는 어려웠다고 합니다. 게다가 대형 모델을 학습하려면 수십 개의 A100 GPU와 수천 시간 이상의 학습 시간이 필요하고, 1억 개 이상의 대규모 데이터셋이 요구됩니다.
이러한 이유로 Parameter-Efficient Transfer Learning (PETL) 기법이 인기를 얻었다고 합니다. PETL은 대규모 이미지-텍스트 모델을 그대로 활용해 비디오 태스크에 transfer 시키는 방식으로, 파라미터 수를 최소화하면서도 효과적으로 모델을 학습할 수 있는 방법이죠. 하지만 기존 PETL 연구는 대부분 단순한 비디오 분류에 초점을 맞추고 있어, Text-Video Retrieval 처럼 복잡한 비디오-텍스트 표현 학습에는 한계가 있었다고 합니다.
이 논문은 이런 한계를 해결하기 위해 MobileViCLIP이라는 경량화된 비디오-텍스트 모델을 제안했습니다. MobileViCLIP은 기존 이미지-텍스트 모델을 기반으로 PETL 방식을 적용해 복잡한 구조 변경 없이 빠르고 효율적으로 학습할 수 있도록 했습니다. 또, Spatiotemporal RepMixer와 Attention 모듈을 도입해 비디오의 시간적 맥락까지 표현할 수 있도록 설계했다고 하는데 자세한 내용은 본문에서 설명드리겠습니다.
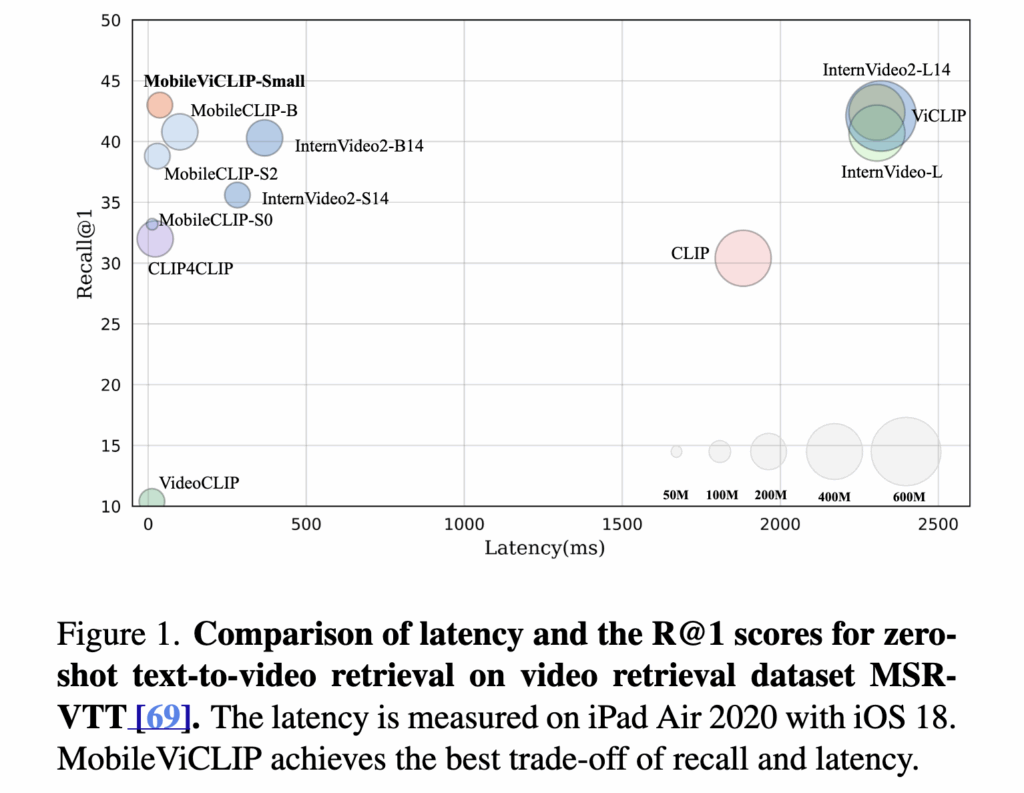
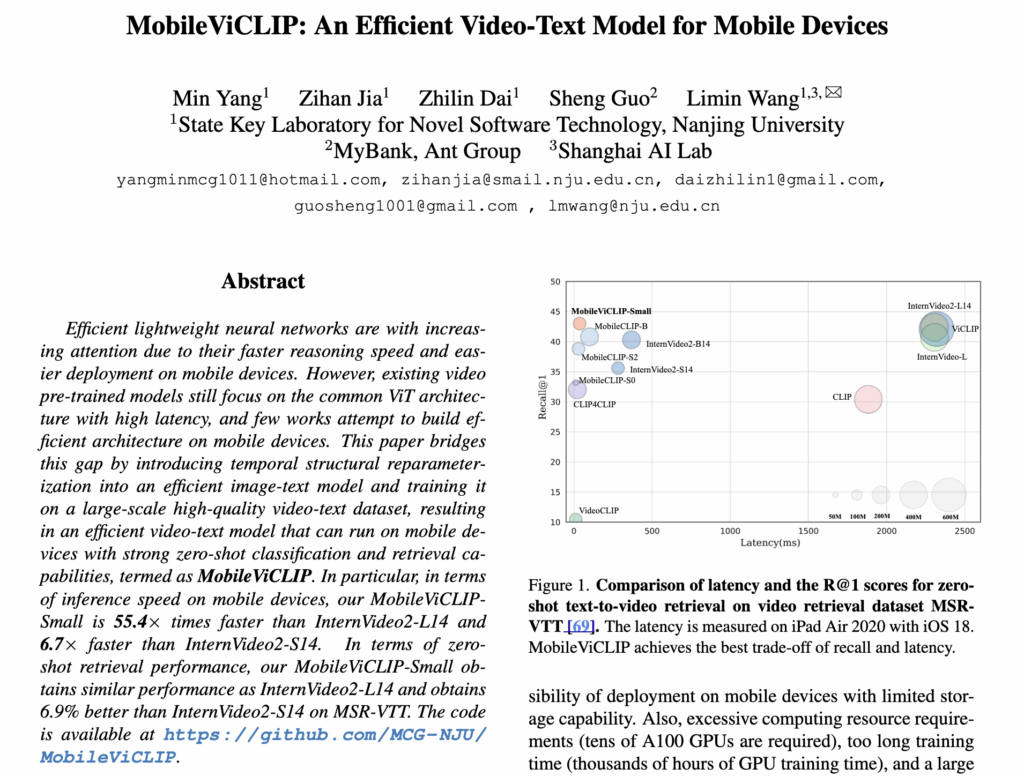
특히 이 모델은 8개의 RTX 3090 GPU로 단 2일 만에 학습되었다고 합니다. 상단 그림 1을 보면, 해당 MobileViCLIP은 기존 InternVideo2-L 수준의 zero-shot retrieval 성능을 유지하면서도 훨씬 낮은 latency와 적은 파라미터 수를 달성하였습니다. 저자가 말하길, MobileViCLIP은 고성능을 유지하면서도 실제 모바일 환경에 배포할 수 있는 첫 비디오-텍스트 모델이라고 할 수 있었다고 합니다.
2. Method: MobileViCLIP
2.1 MobileCLIP Revisited
본격적인 설명에 앞서, 해당 논문이 베이스라인으로 삼은 *MobileCLIP에 대해 아주 간단하게 알아보겠습니다.
*MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training, CVPR, 2024.
MobileCLIP은 Apple에서 공개한 모바일 기기에서도 빠르고 정확하게 CLIP을 활용할 수 있도록 설계된 경량 이미지-텍스트 모델입니다. 기존 CLIP 모델이 강력한 성능을 제공하더라도 모델 크기와 추론 속도가 지나치게 커 모바일 환경에서는 적용하기 어려웠던 문제를 해결하고자 만들어졌습니다
Multi-Modal Reinforced Training
MobileCLIP은 기존 CLIP 모델과 이미지 캡셔닝 모델로부터 knowledge distillation을 통해 데이터셋 자체에 저장하는 방식으로 학습 효율을 극대화하였다고 합니다. 원본 데이터셋(DataComp)에 대해 Teacher CLIP 모델의 임베딩과 생성된 캡션을 함께 저장(DataCompDR)하여, 학습 시 추가적인 계산 비용 없이도 teacher의 지식을 활용할 수 있도록 했습니다. 이를 통해 MobileCLIP은 최대 1000배 더 높은 데이터 효율을 달성했으며, 짧은 시간 안에 높은 성능의 모델을 학습할 수 있게 되었다고 하네요.
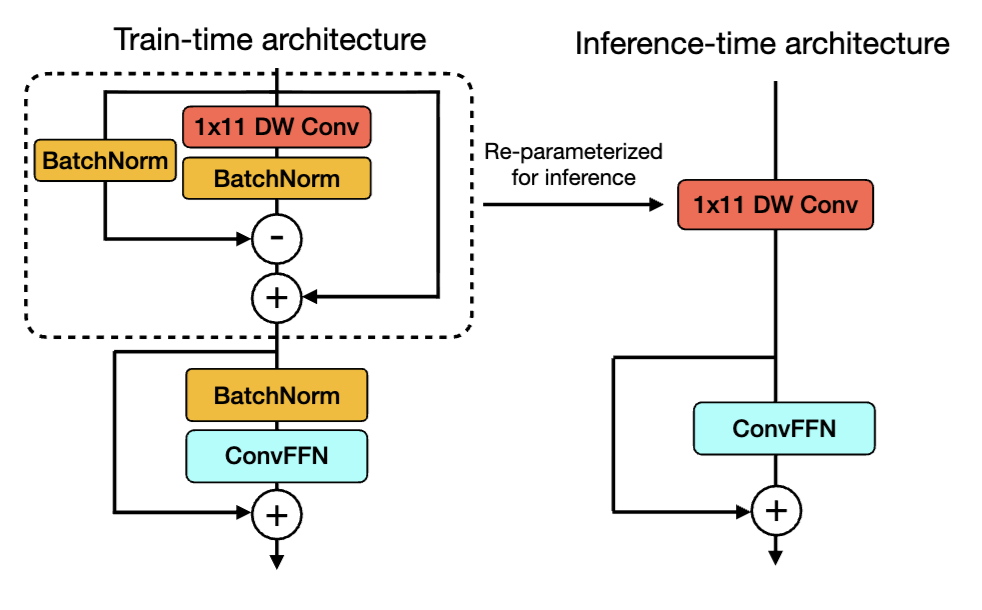
Hybrid CNN-Transformer 아키텍처
또 재밌는건, MobileCLIP은 이미지 인코더와 텍스트 인코더 모두에서 CNN과 Transformer를 결합한 하이브리드 구조를 사용했다는 점인데요. 특히, 텍스트 인코더에는 Text-RepMixer라는 구조적 재파라미터화 (Structural Reparameterizable) 기법을 적용하였다고 합니다. 이는 학습 시에는 skip connection과 Batch Normalization이 포함된 복잡한 연산 구조를 사용하지만, 추론 단계에서는 단순한 depthwise convolution으로 변환해 메모리 접근 비용을 줄이는 방식입니다. 이렇게 하면 학습 효율과 추론 속도를 모두 확보할 수 있다고 합니다.
다양한 크기의 모델
MobileCLIP은 모델 크기에 따라 S0, S1, S2 등 다양한 버전을 제공하여, 모바일 환경에서 매우 빠른 S0부터 성능 중심의 S2까지 폭넓게 활용할 수 있다는 점이 또 특징이라고 합니다. 예를 들어 MobileCLIP-S0는 ViT-B/16 기반 CLIP 대비 5배 빠르고 3배 가벼우면서도 동일한 정확도를 달성했습니다
다시 제안하는 논문 설명으로 돌아와서, MobileViCLIP은 MobileCLIP의 S0, S2 백본을 기반으로 Tiny 모델과 Small 모델을 구축했다고 합니다: (1) MobileCLIP-S0 → MobileViCLIP-Tiny (2) MobileCLIP-S2 → MobileViCLIP-Small.
더 나아가 Spatiotemporal RepMixer와 Attention 모듈을 추가하여 시간 정보를 처리할 수 있도록 확장했는데, 이건 MobileCLIP의 경량성과 효율성은 그대로 가져가면서 비디오 이해 능력을 강화한 구조라고 할 수 있겠네요!
2.2 Overview of MobileViCLIP
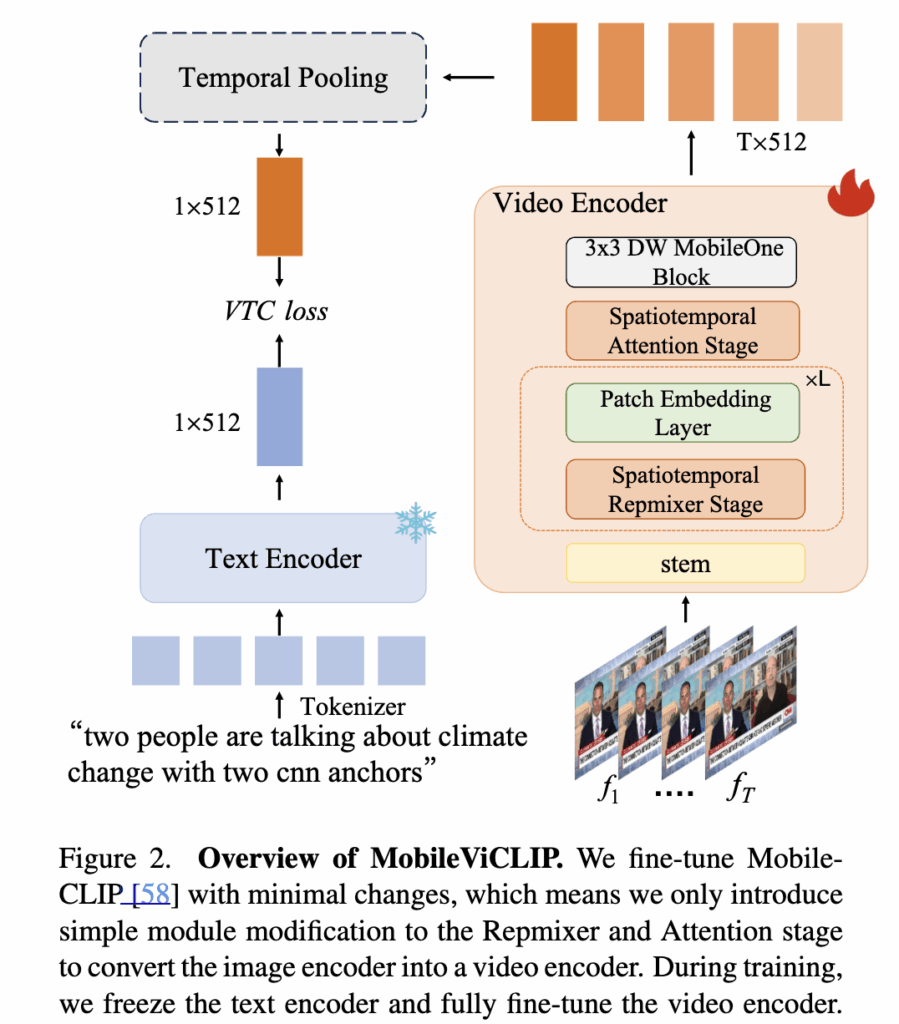
MobileViCLIP은 MobileCLIP의 경량성과 학습 효율성을 그대로 유지하면서 시간 축 정보가 있는 비디오에 대한 이해를 높이도록 설계되었습니다. 상단 그림 2를 보면, 입력 비디오 V는 T개의 프레임 단위로 인코딩되어 각 프레임의 임베딩 f_1, f_2, ..., f_T을 얻고, 이들을 mean pooling해 비디오 전체를 표현하는 벡터로 변환합니다. 텍스트는 CLIP 기반 텍스트 인코더를 통해 임베딩으로 변환되며, 이렇게 얻은 비디오-텍스트 임베딩 쌍을 이용해 Video-Text Contrastive Learning(VTC)으로 학습하는 방식입니다.
BlockDesign
MobileViCLIP의 비디오 백본은 MCi라는 하이브리드 구조로, CNN과 Transformer를 결합해 local 정보와 global 문맥을 모두 파악합니다. 하지만 MobileCLIP은 이미지-텍스트 태스크에 맞춰 설계되었기 때문에 시간적 관계를 학습하는 데 한계가 있었습니다. MobileViCLIP은 이를 해결하기 위해 블록 단위로 시간 정보를 처리하는 모듈을 새로 추가했습니다.
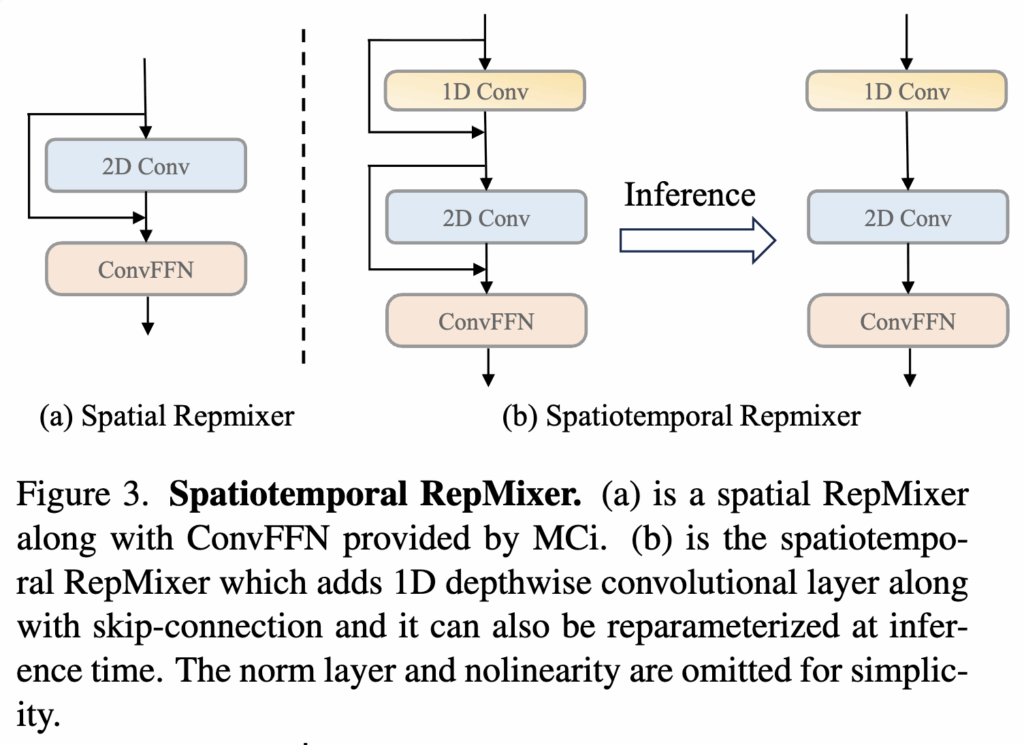
(1) Spatiotemporal Repmixer
저자는 MobileCLIP의 RepMixer 구조를 확장해 시간 정보(temporal dynamics)를 처리할 수 있도록 1D Depthwise Convolution 레이어를 추가했습니다. 구조는 상단 그림3에서 확인할 수 있습니다. 이 레이어는 프레임 간 관계를 먼저 학습한 뒤, 2D Convolution으로 공간 정보를 결합한다고 합니다. RepMixer와 동일하게, 학습 시에는 Batch Normalization과 Skip Connection이 적용된 복잡한 형태로 학습되지만, 추론 시에는 단순한 Convolution 연산으로 재파라미터화(Structural Reparameterization)되어 연산 비용을 크게 줄일 수 있습니다.
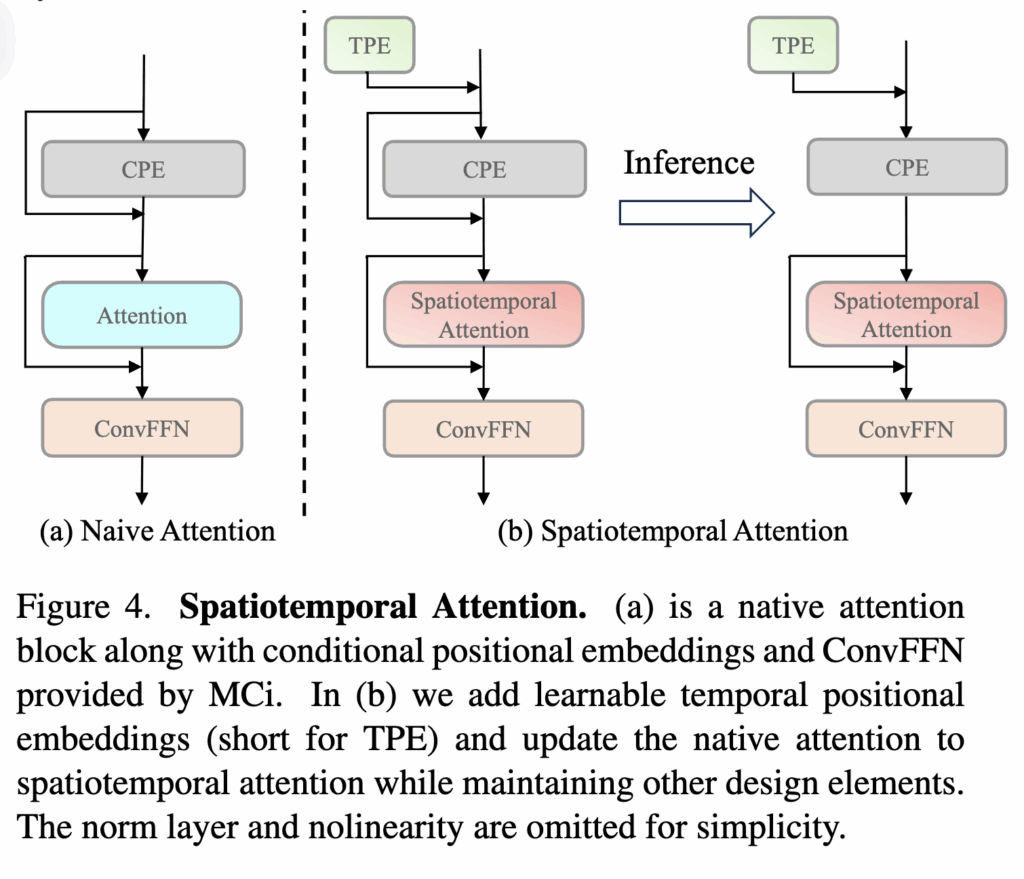
(2) Spatiotemporal Attention
뿐만아니라, 기존 MobileCLIP의 Attention 블록을 확장해 공간-시간적 관계를 함께 모델링할 수 있도록 설계하였다고 합니다. 상단 그림4(b)에서 확인할 수 있듯, Conditional Positional Encoding(CPE) 구조에 Temporal Positional Encoding(TPE)을 추가하여 프레임 간 순서와 위치 정보를 학습할 수 있게 한 것이 핵심입니다.
입력 텐서 X \in \mathbb{R}^{T \times H \times W \times C}가 있을 때, TPE와 CPE를 순차적으로 적용해 시공간 위치 정보를 반영합니다.
X' = X + TPE, \quad Y = X' + CPE(X').
- TPE \in \mathbb{R}^{T \times 1 \times 1 \times C}: 프레임 순서를 인코딩한 학습 가능한 파라미터. 각 프레임마다 독립적인 위치 벡터를 학습해 시간축의 상대적 위치 정보를 명시적으로 추가.
- CPE(\cdot): 깊이 방향 Depth-wise Conv를 사용한 공간 위치 인코딩 함수
이 과정을 통해 모델은 입력 비디오의 각 프레임 위치에 대해 시간 순서 정보(TPE)와 공간적 위치 정보(CPE)를 동시에 활용하게 됩니다.
다시 정리하면, MobileViCLIP은 학습 시 복잡한 Skip Connection과 Batch Normalization이 포함되지만, 추론 단계에서는 다음과 같이 단순화됩니다. X' = X + TPE, \quad Y = CPE(X'). 즉, 추론 시에는 입력 텐서에 시간 정보(TPE)를 더한 뒤 CPE만 통과시키는 구조가 되어 연산량을 최소화합니다.
간단하게 정리하면.. 1D Depthwise Convolution 레이어를 추가해서, 프레임 간의 관계를 파악하고 + Frame 단위로 PE를 추가함으로써 시간축을 고려하였다고 할 수 있겠네요.
2.3 Training
Settings
MobileViCLIP은 256×256 해상도의 비디오 프레임 8장을 샘플링해 학습에 사용했습니다. 학습에는 8개의 RTX 3090 GPU가 사용되었고, GPU당 batch size는 64였다고 하네요. 추가로 다운스트림 비디오-텍스트 Retrieval 데이터셋에 fine-tuning할 때는 동일한 batch size로 10 epoch 학습을 수행했다고 합니다. 저자들은 MobileViCLIP이 경량 구조 덕분에 다른 대형 모델 대비 훨씬 적은 데이터와 연산 자원으로 충분히 학습할 수 있다고 강조하기도 하였습니다.
Pre-trained Dataset
MobileViCLIP의 백본인 MobileCLIP은 DataCompDR-1B라는 강화 데이터셋으로 사전학습되었습니다. 여기에 더 나아가 MobileViCLIP의 학습에는 InternVid-10M-FLT를 사용하였습니다. 비디오에 대한 이해를 위해 비디오 텍스트 데이터셋으로 학습을 수행한 것이죠.

- DataCompDR-1B: MobileCLIP 백본을 학습하기 위해 사용한 이미지-텍스트 데이터셋. Teacher CLIP과 LLM으로 캡션을 강화한 초대형 데이터셋이라 MobileCLIP이 이미지-텍스트 표현력을 충분히 갖추게 해줌.
- InternVid-10M-FLT: MobileViCLIP 단계에서 비디오-텍스트 학습에 사용한 데이터셋으로, 1천만 개 이상의 고화질 유튜브 영상과 6천 개 이상의 액션 레이블, LLM이 생성한 고품질의 캡션이 포함돼 있어, 비디오 이해 성능을 크게 높임.
Augmentation으로는 학습 시 8장의 프레임을 랜덤으로 추출한 후, 크기 조정과 랜덤 크롭, 0.5확률의 Horizontal Flip을 적용했고, 추론 단계에서는 크기 조정만 적용해 간단한 전처리로 속도를 높였다고 합니다.
Evaluation Datasets and Metrics
MobileViCLIP의 성능을 검증하기 위해 세 가지 대표적인 Text-to-Video Retrieval 데이터셋과 네 가지 Action Recognition 데이터셋을 사용하였습니다.
- MSR-VTT: 10,000개 영상, 각 영상당 20개의 텍스트 캡션
- DiDeMo: 10,000개 이상의 영상, 5초 단위로 쪼갠 26,892 세그먼트, 각 세그먼트당 다수의 캡션
- ActivityNet-Captions: 200개 카테고리, 길이 5~10분의 대규모 비디오 캡션 데이터셋
- Kinetics-400: 400개 액션 카테고리, 약 10초 길이의 영상
- UCF-101: 101개 액션 카테고리, 13,320개 영상
- HMDB-51: 51개 액션 카테고리, 6,766개 영상
- Something-Something V2 (SSV2-MC): 22만 개 영상, 다중 선택(MC) 태스크로 변환
평가 지표는 다음과 같습니다.
- Retrieval: Recall@1 (V2T, T2V)
- Action Recognition: Zero-shot Top-1 Accuracy
추가로 SSV2-MC의 경우, 각 영상마다 173개의 캡션 중 하나만 정답이며, 나머지는 오답으로 구성해 모델이 정확히 맞히는지 평가하였다고 합니다.
3. Main Results
3.1 Text-to-Video Retrieval
(Table 2) Video-Text Retrieval 에서의 Zero-shot 성능
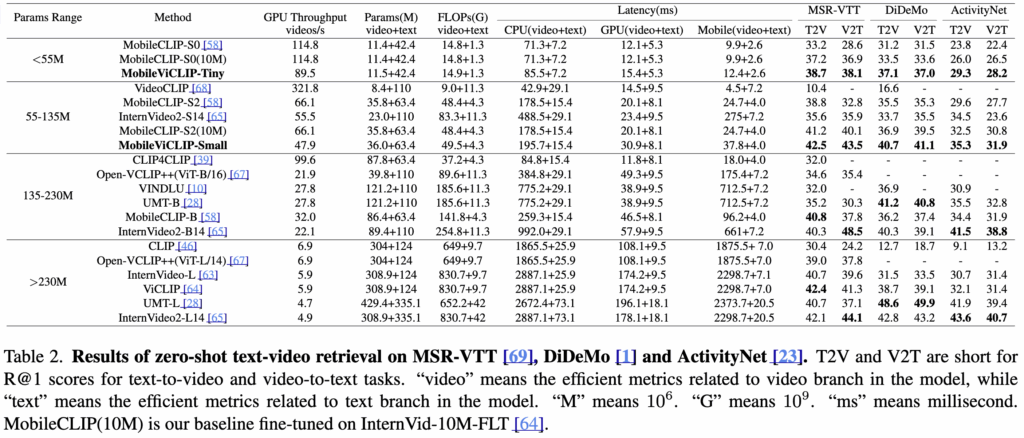
MobileViCLIP은 기존 대형 모델 수준의 zero-shot 검색 성능을 기록한 결과를 확인할 수 있습니다. 모델 크기 55M 이하의 Tiny 모델은 MSR-VTT, DiDeMo, ActivityNet에서 모두 30~40대 R@1 성능을 기록하며, 소형 모델임에도 우수한 검색 능력을 보였습니다.
특히, MobileViCLIP-Small(55~135M)은 FLOPs와 파라미터가 절반 이하임에도 InternVideo2-L14(>230M)와 거의 동급의 R@1 성능을 달성한 것을 확인할 수 있는데요 (ex. MSR-VTT: 42.5/43.5 (T2V/V2T) DiDeMo: 40.7/41.1 ActivityNet: 35.3/31.9) ActivityNet처럼 긴 영상 데이터셋에서도 대형 모델과 성능 차이가 거의 없었다는 것이 인상 깊습니다.
또한 연산 효율성 측면에서, MobileViCLIP-Small은 InternVideo2-S14 대비 FLOPs 절반, 모바일에서 6.75배 빠른 추론 속도를 기록하였다는 것도 의미있는 결과같습니다.
(Table 3) Video-Text Retrieval 에서의 Fine-tuning 성능
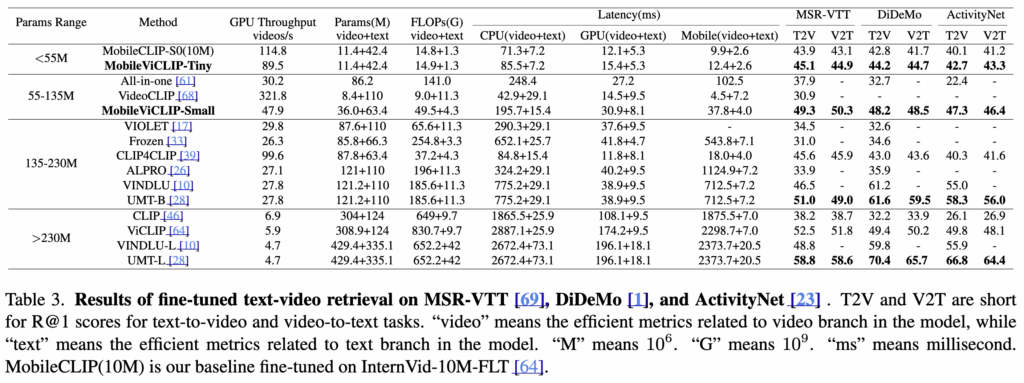
Fine-tunin에서도 MobileViCLIP은 R@1 성능이 크게 향상한 것을 알 수 있었습니다.
MobileViCLIP-Tiny(55M 이하) 에서는 파라미터 수가 적지만, 기존 중형 모델 이상 수준으로 검색 성능을 확보하였고, MobileViCLIP-Small(55~135M)에서는 ViCLIP(>230M)이나 InternVideo2-B14 같은 대형 모델에 근접한 결과를 보였죠.
3.2 Zero-Shot Action Recognition.
(Table 4) Action Recognition에서의 zero-shot 성능
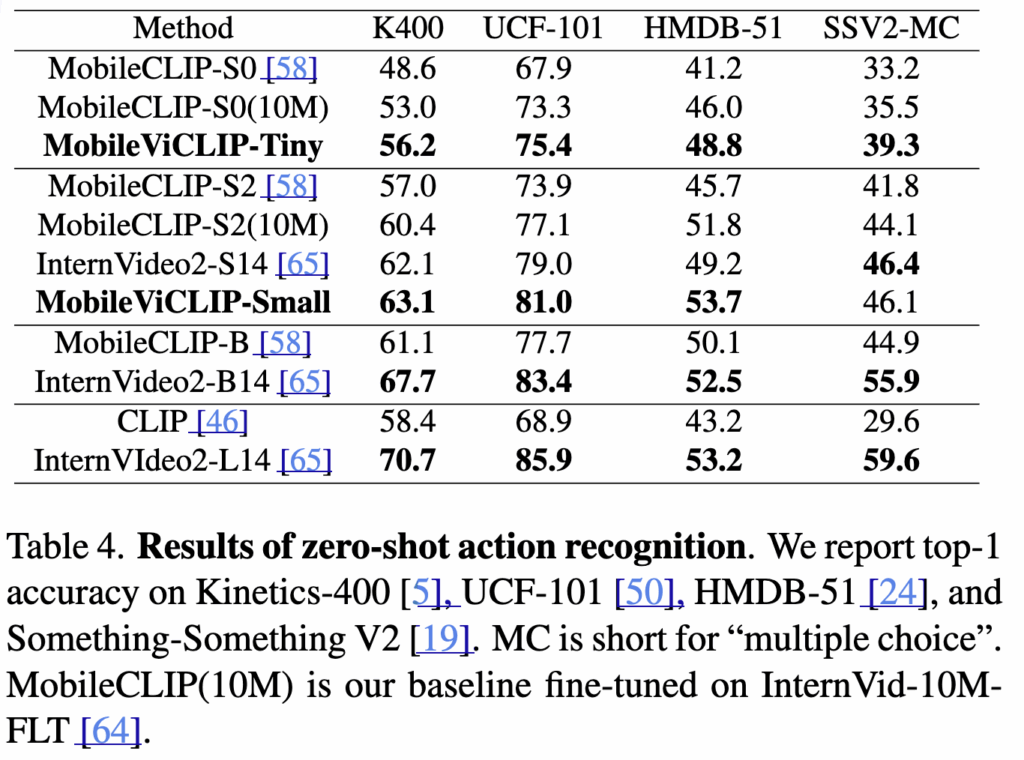
MobileViCLIP은 비디오-텍스트 검색을 위해 학습되었음에도 불구하고, 액션 인식에서도 제법 훌륭한 성능을 보여주었습니다.
MobileViCLIP-Tiny (55M 이하)에선 경량 모델임에도 전통적인 MobileCLIP 대비 모든 벤치마크에서 큰 폭의 성능 향상을 보였으며, 일부 데이터셋에서는 중형 모델에 근접했습니다. MobileViCLIP-Small (55~135M)에서는 InternVideo2-S14와 비슷하거나 일부 데이터셋(Kinetics-400, HMDB-51)에서는 더 높은 정확도를 기록하기도 했습니다.
다른 대형모델과 비교했을 때, 물론 InternVideo2-L14 가 여전히 가장 좋은 성능을 보였지만, MobileViCLIP은 훨씬 작은 파라미터와 FLOPs로 이와 근접한 성능을 보였다는 측면에서 유의미한 결과가 아닐까 싶습니다.
4. Ablation Study
(Table 5) Block Design에 대한 Ablation study

앞서 저자는 Temporal 축을 고려하기 위한 2가지 모듈을 추가했었는데요, 이 모듈의 효과를 확인하기 위한 실험에 대해 알아보겠습니다. 그 결과 두 모듈 모두 성능 향상에 기여하며, 특히 Temporal Positional Encoding(TPE)이 비디오의 시간적 변화를 이해하는 데 중요한 역할을 한다는 점을 알 수 있었습니다.
(Table 6) Text Branch Freeze 여부

다음으로 텍스트 인코더를 학습 시 함께 업데이트할지 여부를 확인한 결과, 텍스트 브랜치를 freeeze 하지 않아도 성능에는 큰 차이가 없었고 학습 시간만 늘어났다고 합니다. 따라서 최종 버전에서는 텍스트 브랜치를 freeze 하여 효율성을 높였다고 하네요.
아래 Table 7, 8, 9에서는 MobileViCLIP의 다른 비디오 태스크에서의 일반화 성능 결과입니다. 결론부터 말씀드리면, Temporal Grounding, Action Detection, Video Captioning 등 다양한 비디오 다운스트림 태스크에서 대형 모델을 상위하는 성능을 보이며 강력한 일반화 능력을 입증하였다는 실험 결과입니다.
(Table 7) Video Downstream Tasks 일반화 성능 (1) Moment Retrieval & Highlight Detection
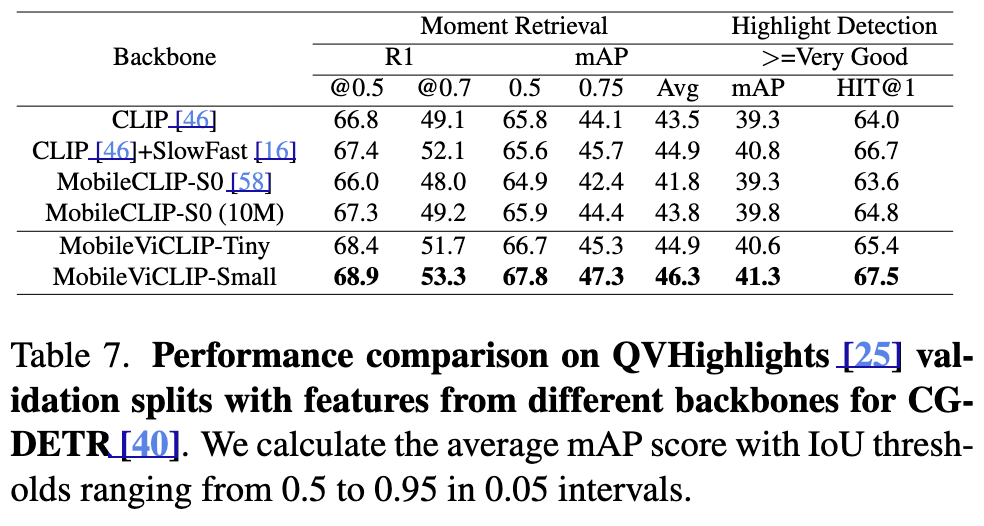
먼저, Video Temporal Grounding (QVHighlights)에서 MobileViCLIP-Small은 CLIP + SlowFast 조합보다도 더 좋은 성능을 보이며, 시간 단위로 영상을 이해하고 특정 구간을 정확히 찾아내는 데 더 강함을 확인할 수 있습니다.
(Table 8) Video Downstream Tasks 일반화 성능 (2) Temporal Action Detection
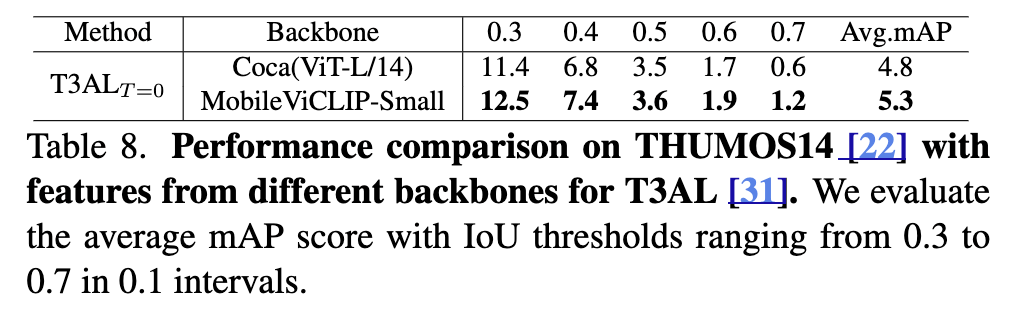
그리고 Zero-shot Temporal Action Detection (T3AL) 자막이나 액션 라벨이 없는 영상에서도 액션 위치를 찾아내는 과제에서 ViT-L/14보다 높은 성능을 보였습니다.
(Table 9) Video Downstream Tasks 일반화 성능 (3) Video Captioning
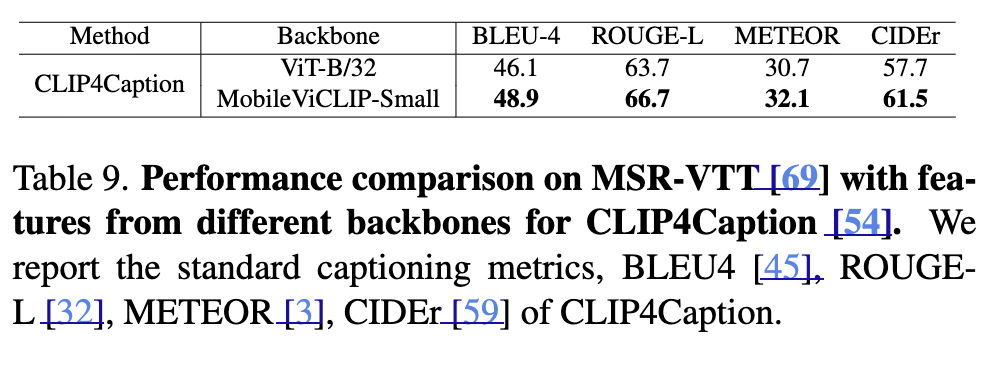
뿐만 아니라 비디오 캡셔닝에서도 MobileViCLIP-Small은 ViT-B/32 기반 모델보다 더 나은 캡션 생성 성능을 보이기도 했습니다.
5. Latency Analysis
마지막 파트입니다. MobileViCLIP은 모바일 환경에서 동작할 수 있도록 설계되었다보니 latency와 관련된 재밌는 분석들을 다루었습니다.
(Table 10) 모바일 vs GPU Latency 격차
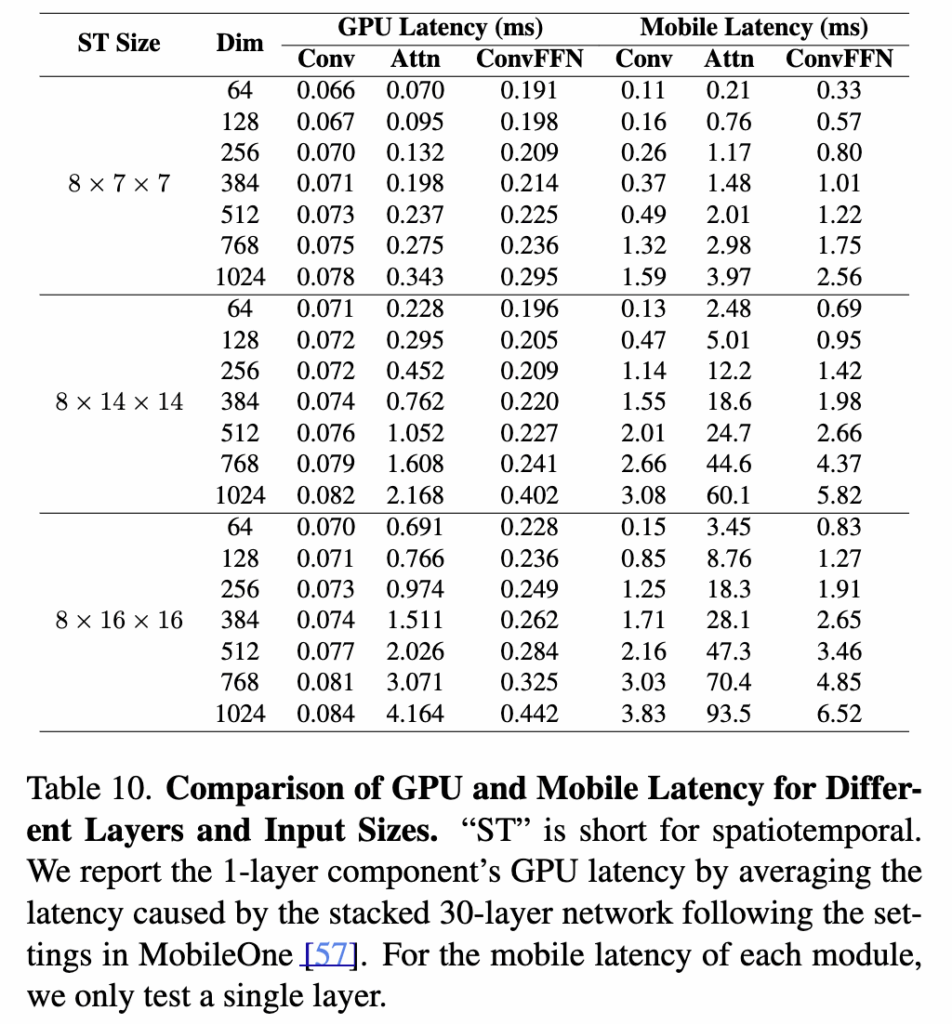
저자가 제안하는 Spatiotemporal RepMixer(Conv), Attention(Attn), FFN, ConvFFN 모듈의 latency를 GPU와 모바일 환경에서 각각 측정한 결과입니다.
모바일 환경의 Latency는 GPU 대비 10배 이상 높음
동일한 입력 크기와 채널 차원에서 모바일 추론 속도는 GPU 대비 약 10배 이상 느렸고(0.343ms vs 3.97ms), 입력 해상도가 커질수록 이 격차가 더 크게 벌어져, 모바일 환경에 적합한 모델 설계가 필수적이라고 합니다.
입력 해상도와 채널 크기가 클수록 Latency 급격히 증가
특히 1024 차원, 8×16×16 입력에서는 모바일의 attention latency가 93.5ms로 증가한 것을 통해, 복잡도가 O(H²W²C)로 커지는 구조적인 한계가 모바일 환경에서 특히 두드러진다는 것을 알 수 있었습니다.
Conv는 상대적으로 Latency 증가 폭이 작음
Conv 모듈은 입력 크기가 커져도 latency가 완만하게 증가하는 것을 통해, 모바일 최적화에 유리했습니다.
(Table 11) Layer 수에 따른 Mobile Latency 변화
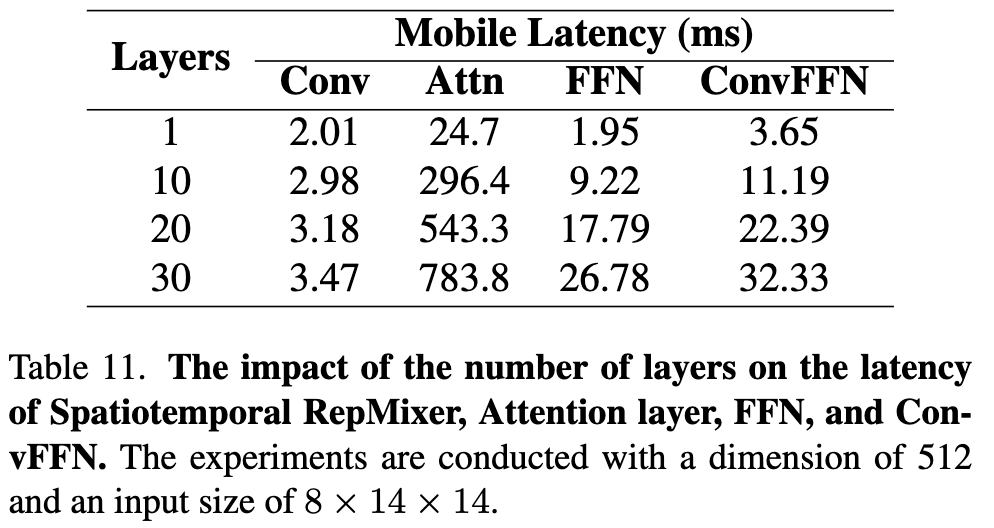
동일한 입력 크기(512 차원, 8×14×14)에서 모듈별 레이어 수 증가가 모바일 추론 속도에 미치는 영향을 분석하였습니다.
Attention Layer가 Latency의 가장 큰 원인
1개 레이어에서 24.7ms였던 attention latency가 10개에서는 296.4ms, 30개에서는 783.8ms로 폭발적으로 증가한 것을 볼 수 있는데요. 이는 GPU 환경에서의 attention 최적화가 모바일에선 적용되지 않음을 다시 한번 알 수 있었습니다.
Conv Layer는 Latency에 큰 영향을 주지 않음
Conv의 latency는 레이어 수가 30개로 늘어나도 2.01ms → 3.47ms로 매우 완만하게 증가한 것을 알 수 있습니다. Conv 기반 구조가 모바일 추론에 훨씬 효율적이었다고 합니다.
6. Summary
본 논문에서는 MobileViCLIP이라는 경량 비디오-텍스트 모델을 제안하여, 기존 대형 모델 대비 모바일 환경에서도 동작 가능한 성능과 효율성을 보였습니다. MobileCLIP을 백본으로 사용해 하이브리드 CNN-Transformer 구조를 유지하면서도, 시간축 고려를 위한 Spatiotemporal RepMixer와 Spatiotemporal Attention 모듈을 추가하였습니다 (구체적으로 1D Depthwise Convolution과 Temporal Positional Encoding를 추가). 학습 시 복잡한 연산 구조를 추론 단계에서 단순화하는 Structural Reparameterization을 적용하여 연산량을 최소화하였습니다.
모바일 환경과 latency 사이의 관계를 체계적으로 분석한 결과가 제법 인상적입니다. Attention 모듈이 모바일 환경에서 bottleneck이 된다는 점이 가장 기억에 남네요. 경량화를 위한 비디오 연구를 가볍게 알아본 논문이었습니다.
안녕하세요 주영님 좋은 리뷰 감사합니다.
MobileViCLIP 모델은 학습 시에는 Skip Connection과 BatchNorm을 사용하지만, 추론 단계에서는 이를 제거해 연산을 단순화한다고 설명해주셨습니다. 하지만 Skip Connection과 BatchNorm을 제거하면 연산량은 줄어들지만 성능이 저하 될 수 있을 것 같다고 생각하는데, 혹시 추론 시에도 Skip Connection과 BatchNorm을 유지했을 때 성능 차이가 실제로 있는지 궁금합니다.
또, MobileViCLIP에서 CNN과 Transformer을 함께 사용하는 이유가 주로 연산 효율성을 위한 것인지, 아니면 성능 향상에도 기여하는지 알고 싶습니다.
감사합니다.
Q1. Skip Connection & BatchNorm 제거하면 성능 저하되지 않는가?
-> 학습과 추론 과정 중 모델 구조를 다르게 가져가는 이유는 Structual Reparameterization 때문인데요, 여기서 학습 시의 복잡한 연산 구조(Residual Connection, BN 등)를 단일 Convolution 연산으로 수학적으로 등가 변환할 수 있어, 추론 시 성능 손실 없이 연산량을 크게 줄일 수 있다고 합니다.
즉, 학습 단계에서 Skip Connection과 BN을 통해 학습 안정성과 표현력을 확보하고, 추론 단계에서는 이 구조를 수식적으로 병합하여 동일한 파라미터로 동작하게 하기 때문에 실제로 성능 저하는 거의 발생하지 않고, MobileCLIP 논문에서 이미 이를 실험적으로 증명했다고 하네요.
Q2. 또한 MobileViCLIP이 CNN과 Transformer를 함께 사용하는 이유?
-> 함께 사용하는 이유가 단순히 연산 효율성 때문만은 아닙니다. 아시다시피 CNN은 local 패턴 추출에 특화되어 파라미터 효율성이 높고, 모바일 환경에서 속도가 빠른 장점이 있습니다. 반면 Transformer는 global 문맥 정보와 프레임 간 관계를 모델링하는 데 강점이 있다고 알려져있습니다.
MobileViCLIP은 이 두 가지를 결합하여 연산 효율성을 확보하면서도 비디오의 시공간적 맥락을 효과적으로 학습할 수 있도록 설계된 것이라고 봐주시면 좋을 것 같습니다. 실제로 Ablation 실험 결과에서도 CNN 기반 RepMixer와 Transformer 기반 Attention을 함께 사용했을 때 성능이 가장 높았고, 특정 모듈만 단독으로 사용하는 경우보다 효율성과 성능의 균형이 훨씬 좋았죠