Abstrcat
물체와의 상호작용을 위해서는 상호작용이 이루어지는 영역에 대하여 알아야 합니다. weakly-supervised affordance grounding(WSAG)은 사람의 학습 방식을 모방하여 제 3자가 물체와 상호작용하는 영상을 통해 픽셀 수준의 annotation 정보가 없이도 직관적으로 기능적인 영역 정보를 학습하는 것을 목표로 합니다. 그러나 affordance와 관련된 물체 부분은 구분이 어려운 경우가 존재하며, 모델들은 주로 classification 방식에 의존하게 되며, 그 결과 affordance와 무관하게 공통적인 카테고리 특유의 패턴에 집중하는 경우가 많습니다. 저자들은 이 문제에 집중하여, selecrtive prototypical and pixel contrastive objectives를 제안하였습니다. 이를 통해 이용 가능한 정보의 세밀한 수준(granularity)에 따라, part-level과 object-level 모두에서 affordance와 관련된 단서를 적응적으로 학습하도록 하였습니다. 구체적으로는 CLIP을 활용하여 egocentric(물체중심) 이미지와 exocentric(관찰자시점) 이미지 모두에서 affordance와 관련된 물체를 찾은 뒤, 서로를 참조하도록 하여 affordance 단서를 추출하도록 합니다. 또한, 배경과 affordance 관련 영역을 지속적으로 구분하여 학습하므로써 유의미한 영역에 집중하도록 합니다. 저자들은 실험적으로 효과와 성능을 입증하였습니다.
Introduction
사람은 물체와 상호작용을 위해 다른 사람이 사용하는 걸 관찰하므로써, 물체의 각 부분의 기능에 대하여 파악하고 물체를 이용할 수 있씁니다. Weakly-supervised affordance grounding도 이러한 방식으로 학습하고자 하는 것으로, egocnetric 이미지(물체 중심)와 action 라벨에 대하여 물체가 상호작용이 이루어지고 있는 몇 장의 exocentirc 이미지가 같이 학습에 사용됩니다. 기존 연구들은 물체의 action이 이루어질 affordance 영역의 위치를 찾기 위해 CAM(class activate map)을 이용하고, exocentric 이미지로 학습된 정보를 egocentric 이미지로 전이하는 방식으로 이루어졌으나, 이러한 방식은 정확한 위치 정보를 제공할 수 없다는 점에서 affordnace와 연관된 부분을 정확히 학습할 수 있다고 보장할 수 없습니다. 저자들은 이러한 문제를 해결하기 위해 affordance와 연관된 영역과 무관한 영역에 대하여 식별하기 위한 단서를 학습하도록 하였습니다.
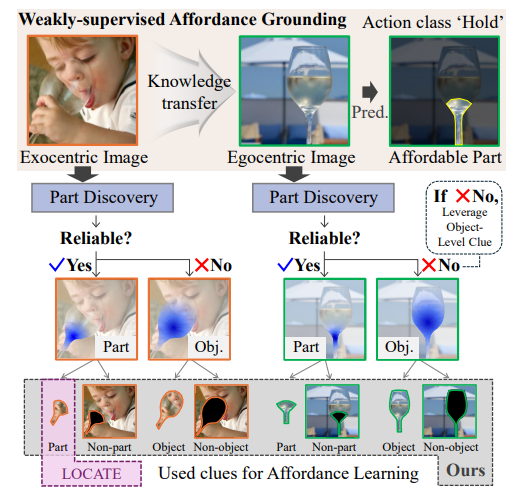
위의 그림이 저자들이 제안하는 방식의 개요로, 먼저 egocentric 이미지와 exocentric 이미지로부터 affordance와 연관있는 영역 정보를 찾고, 해당 영역이 affordance와 연관이 있는지에 대한 신뢰성을 통해 적절한 영역이라 판단될 경우 무관한 영역과 구분하는 법을 학습하고, 부적절하다고 판단될 경우 CLIP으로 영상에 대한 object affinity map을 통해 배경과 물체 영역을 구분하는 법을 학습하도록 하였습니다.
저자들은 먼저 object와 part 단서 수집 과정을 통해 학습을 준비합니다. exocentric 이미지에서는 CAM과 object affinity map을 결합함으로써 객체와 무관한 후보를 제거하고 더 정확한 affordance 관련 물체 영역을 추출하였으며, egoentric 이미지에서는 CLIP이 눈에 띄는 객체(salient object)에 더 민감하다는 특성을 활용합니다. egocentric 이미지는 객체가 더 크게 보이고 가려짐이 적기 때문에 affordance 단서가 더욱 강하게 드러나며, 이를 바탕으로 세밀한 파트 단서를 확보할 수 있습니다.
이렇게 구한 object와 part 단서를 활용하여 저자들은 2가지 contrastive learning 방식을 설계합니다. 하나는 prototypical contrastive learning으로, exocentric 이미지에서 얻은 affordance 단서를 기반으로 egocentric 이미지의 표현과는 가까워지고, 다양한 배경과 다른 행동 카테고리와는 멀어지도록 학습을 유도합니다. 다른 하나는 pixel contrastive learning으로 픽셀 수준의 정밀한 예측을 위해 egocentric 이미지에서 확보한 픽셀 수준의 정보를 활용하여 affordance와 무솬한 영역을 구분할 수 있도록 학습합니다. 추론시에는 이렇게 학습된 네트워크의 CAM 결과에 object affinity map을 결합하여 CAM이 물체 영역에 집중할 수 있도록 보정하도록 합니다.
Method
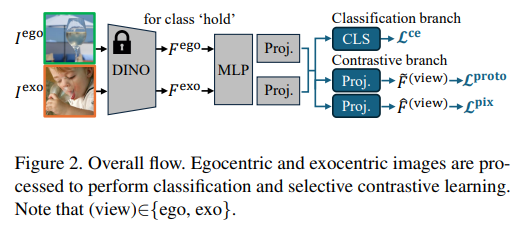
위의 Figure 2는 전체적인 개요를 의미합니다. 하나의 egocentric 이미지 I^{ego}와 E개의 exocentric 이미지 I^{exo}가 주어졌을 때, egocentric 이미지와 exocentric 이미지들은 DINO를 통과하여 F^{ego}와 F^{exo} feature를 구합니다. 이후 2개의 projection layer를 통과시켜 각 view(ego/exo)에 대하여 2가지 features \tilde{F}^{ego}, \hat{F}^{ego} \in \mathbb{R}^{B⨉H⨉W⨉D}와 \tilde{F}^{exo}, \hat{F}^{exo} \in \mathbb{R}^{B⨉E⨉H⨉W⨉D}를 구합니다. 이렇게 구한 features는 contrastive learning branch에 egocentric 이미지의 affordance 지식 학습에 사용되며, classification branch에서는 공통의 classifier를 통해 egocentric 이미지와 exocentric 이미지에서 공통된 의미론적 정보를 학습합니다. 이렇게 학습된 이후에, 추론 과정에는 classification branch에서 egocentric 이미지에 대한 CAM C^{ego}을 구하게 됩니다. 이제 각 과정에 대해 알아보도록 하겠습니다.
1. Object Discovery
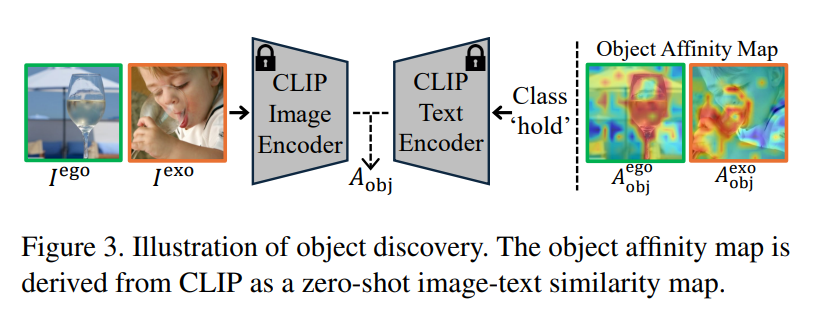
해당 과정은 CLIP을 이용하여 egocentric 이미지와 exocentric 이미지에 대하여 object affinity map을 만드는 과정입니다. object affinity map A^{ego}_{obj} \in \mathbb{R}^{B⨉H⨉W⨉D}, A^{exo}_{obj} \in \mathbb{R}^{B⨉E⨉H⨉W⨉D}, 은 각 이미지들을 CLIP의 visual feature로 부터 추출하고, action에 대한 text 라벨에 대하여 text feature와의 cosine similarity로 구해집니다. 해당 과정을 통해 object-level의 정보를 수집하는 것 입니다. (해당 과정이 어째서 object 영역인가? 하는 생각이 들 수 있는데, 저자들은 정성적 결과를 통해 물체 영역이 활성화 됨을 확인하였다고 합니다.)
2. Prototypical Contrastive Learning
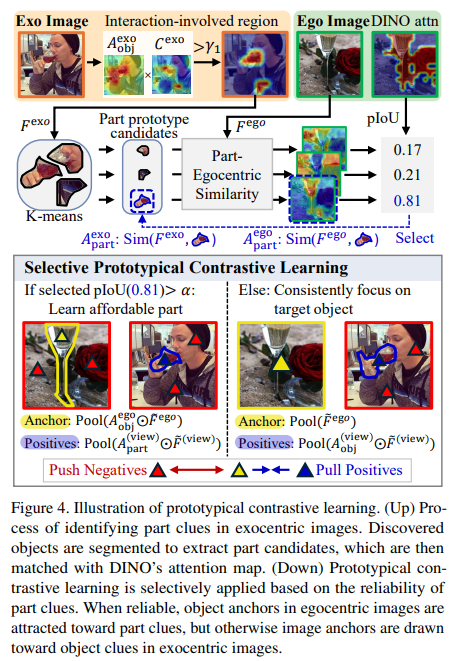
prototypical contrastive learning은 exocentric 이미지로부터 물체 부분에 대한 프로토타입을 egocentric 이미지에 대한 프로토타입으로 증류하는 것으로, 기존의 prototypical contrastive 방법론과 다르게 negative relation을 학습에 사용하므로써 affordance와 무관한 배경과 같은 정보에 대한 편향을 완화할 수 있다고 주장합니다.
[Pixel-level Clues within Exocentric Images]
기존의 연구에서는 CAM 예측값에 바로 threshold를 적용하는 방법을 사용했지만, 해당 논문에서는 앞서 물체 영역을 나타내는 object affinity map A^{exo}_{obj}를 결합한 뒤에 threshold \gamma_1를 적용하여 CAM이 가지는 예측의 부정확성을 개선하고자 하였습니다. 해당 과정은 affordance와 연관 있는 물체 부분을 찾는 과정입니다.
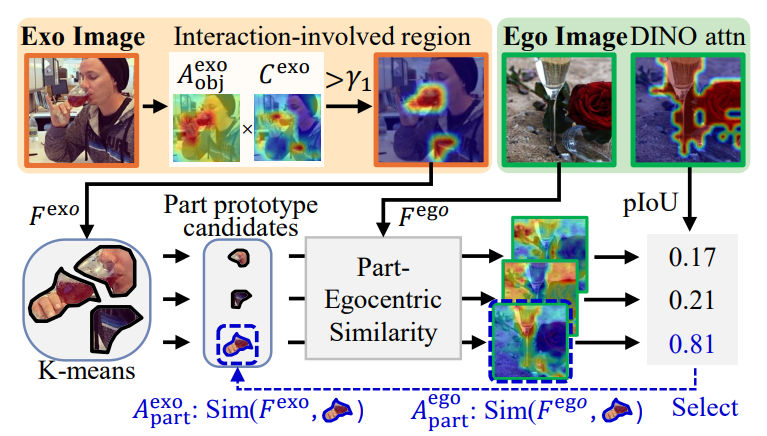
- 먼저, 배경/affordance와 관련된 물체 부분/무관한 물체 부분이 포함된 CAM 결과에는 대해 K-mean clustering(K=3)을 적용하여 part 프로토타입 후보인 centroids를 구합니다.
- 이후, centroids를 egocentirc 이미지에 대한 DINO feature F^{ego}와 비교하여 part-egocentric similarity map을 만들어냅니다.
- part-egocentgric similarity map은 egocentric 이미지에 대한 self-attention map과 비교하여 각 centroid가 affordance와 연관되어있는지 판단하는 데 사용되며, 이에 대한 pIoU를 계산합니다.
- 마지막으로, pIoU가 가장 높고 \alpha보다 큰 centroid만을 신뢰할 수 있는 part로 간주하여 학습에 사용하며, 그 외의 centroid는 신뢰할 수 없다고 보고 모두 학습에서 제외합니다.
[Selective Prototypical Contrastive Learning]
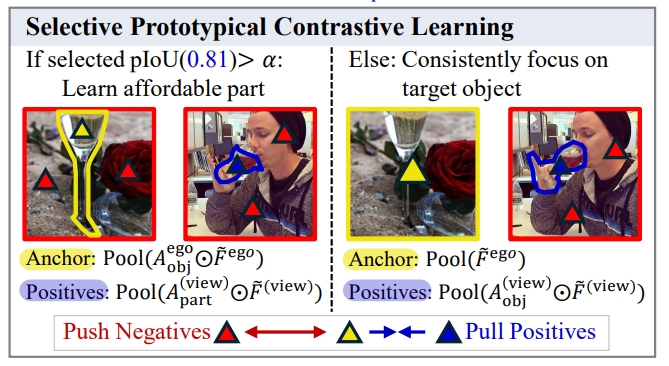
affordance에 대한 픽셀 수준의 라벨을 이용하지 않는 방식은 결국 classification task에 의존하여 행동에 대응되는 물체 영역을 학습하기보다는 물체에서 구분력 있는 영역에 집중하게 되는 문제가 있습니다. 따라서, 저자들은 학습 과정에 exocentric 이미지의 상호작용과 관련된 영역을 일관되게 사용할 수 있도록 하는 loss function을 설계하였습니다. prototypical contrastive learning은 target과 anchor representation 모두에 대하여 학습 과정에 selectivity를 부여합니다. 신뢰할 수 있는 part 프로토타입이 있을 경우에는 해당 프로토타입을 target으로 사용하여 egocentric 이미지의 object 프로토타입으로 전이하고(위의 그림에서 왼쪽 케이스로, 파란색을 target으로 노란색으로 정보 전이), 신뢰할 수 있는 part 프로토타입이 존재하지 않는다면 객체 프로토타입을 target으로 사용하여 egocentric 이미지 자체를 anchor로 사용합니다.(위의 그림에서 오른쪽 케이스로, 파란색을 target으로 egocentric 이미지 전체를 anchor로 활용) 이렇게 하면 모델이 대상 물체에 집중하면서도 배경을 무시할 수 있게되며, part 수준의 신뢰할만한 supervision이 제공될 경우, affordance와 관련된 물체 부분에 대한 세부적인 정보를 더 잘 포착할 수 있도록 합니다.
prototypical contrastive learning을 위해 물체와 부분에 대한 단서를 positive와 negative로 하여 4가지 프로토타입 P^{ego+}, P^{ego-}, P^{exo+}, P^{exo-}을 정의합니다. 이는 instance feature Z \in \mathbb{R}^{H×W×D}와, 앞서 target으로 설정한 영역에 대한 마스크 M \in \mathbb{R}^{H×W}와 CAM 예측 결과 C \in \mathbb{R}^{H×W}를 활용하여 \Phi^{+/-} 함수를 통해 구해지며 \Phi^{+/-}는 아래의 식으로 정의됩니다.
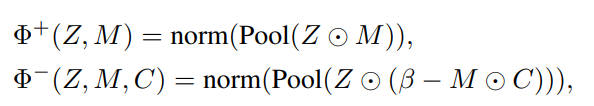
- norm(.): 채널 축을 따라 normalization
- Pool(.): average pooling 의미
- \beta: 초반의 부정확한 CAM 결과에 대하여 과적합 되는 것을 막기 위한 bias term
- ⊙: 요소 곱
즉, positive 프로토타입은 target mask M 영역으로 집중하도록 하고, negative 프로토타입은 배경 및 불필요한 물체 영역에 대하여 학습하도록 하는 것 입니다.
이후, 미니배치 내에서 정확한 파트 수준 프로토타입을 포함한 exocentric 및 egocentric 인스턴스의 집합을 \mathbb{I}라 정의하고, b번째 instance의 egocentric anchor z^{ego}_b와 프로토타입은 아래의 식으로 정의됩니다.

- egocentric anchor z^{ego}_b는 신뢰 가능한 part 정보가 있으면 \Phi^+를 이용하고, 그렇지 않을 경우 feature에 대한 평균을 구함
- exocentirc positive/negative 프로토타입 P^{(view)+}_b / P^{(view)-}_b 도 신뢰 가능한 part 유무에 따라 존재하면 part 기반 \Phi^+ / \Phi^-, 존재하지 않을 경우에는 object 기반의 \Phi^+ / \Phi^-로 정의함
따라서, b번째 인스턴스에 대한 selective prototypical contrastive learning은 아래의 식(3)으로 정의가 되며,
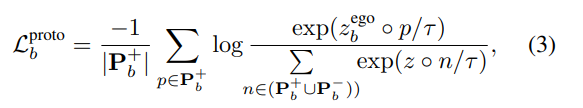
여기서 \mathbf{P}^+_b와 \mathbf{P}^-_b는 각 각 positive와 negative 프로토타입 집합을 의미하고, 아래의 식(4)와 (5)로 정의됩니다.
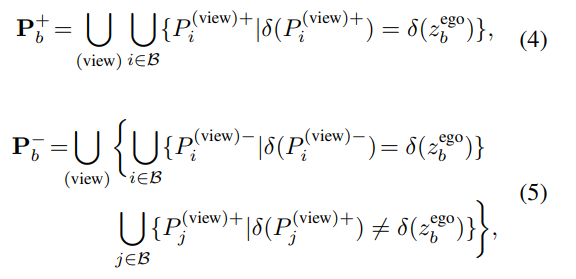
결과적으로, prototypical contrastive learning은 모델이 affordance 관련 영역이 활성화되도록 유도하며, 객체 영역에 집중하게 하고, affordance 관련 파트가 존재할 때는 객체 내에서 파트별 정보를 정밀하게 포착할 수 있도록 합니다.
3. Pixel Contrastive Learning
저자들은 픽셀 수준에서 affordance 관련 영역을 학습하지 못한다는 문제를 보완하기 위해 pixel contrastive learning을 추가로 제안합니다. 이는 egocentric 이미지 내부의 픽셀간 대응 관계를 학습하여 affordance 관련 픽셀을 더 정밀하게 구분하는 것을 목적으로 합니다.
[Part-level Clues within Egocentric Images]

exocentric 이미지들에 존재하는 part 정보를 수집하여 egocentric 이미지에서 affordance 관련 부분을 찾아내는 과정입니다. 저자들은 exocentric 이미지보다 egocentric 이미지에서 affordance 관련 정보가 두드러진다는 CLIP의 특성을 고려하여, exocentric object affinity map에서 가장 큰 activation 값을 기준으로 threshold \rho를 정의한 뒤, 이를 통해 egocentric 이미지에서 관련 영역 Q^+와 무관한 영역 Q^-를 나눕니다.
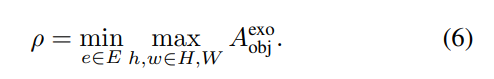
[Selective Pixel Contrastive Learning]
egocentric 이미지에서 affordance 관련 물체 part를 찾을 수 있는 경우에는 Q^+ 픽셀들을 anchor로 사용하여 contrastive learning을 수행하고, 신뢰성 있는 part가 없을 경우에는 object-level의 단서를 활용하여 배경과 객체 영역을 구분하도록 학습을 수행합니다.
픽셀 수준으로 positive set Q^+ 과 negative set Q^-를 구축한 뒤, positive 픽셀 사이의 유사도를 높이고, negative 픽셀들과는 멀어지도록 학습하며, 해당 loss function은 아래의 식 (8)로 정의됩니다. 이를 통해 모델이 픽셀 수준의 affordance 단서에 집중하도록 하며, 불필요한 배경 및 무관한 다른 물체 영역은 억제하게 됩니다.
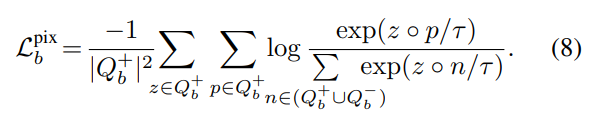
4. Calibrating the Class Activation Map
추론시에는 classifier를 이용하여 CAM을 예측하는 방식으로 affordance 영역을 찾게됩니다. 그러나 CAM은 정확한 물체 경계를 구분하지 못하는 경향이 있으므로 저자들은 object affinity map을 이진화 한 결과를 CAM 예측 결과와 요소 곱을 수행하는 방식으로 output을 보정하였습니다. 이를 통해 배경이 아닌 물체 영역으로 제한할 수 있었다고 합니다.
또한, 네트워크를 학습하기 위해 저자들은 classification 브랜치에 대한 cross-entropy loss와 앞서 저자들이 제안한 2가지 contrastive learning loss를 가중합하여 학습을 수행하였다고 합니다.
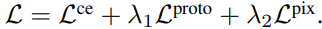
Experiments
평가는 AGD20K 데이터와 HICO-IIF([AAAI 2024]Weakly Supervised Multimodal Affordance Grounding for Egocentric Images 논문에서 제안)라는 데이터를 이용하였으며, 평가는 affordance grounding에서 일반적으로 사용하는 KLD, SIM, NSS 지표를 이용합니다.
Comparison with the SOTA
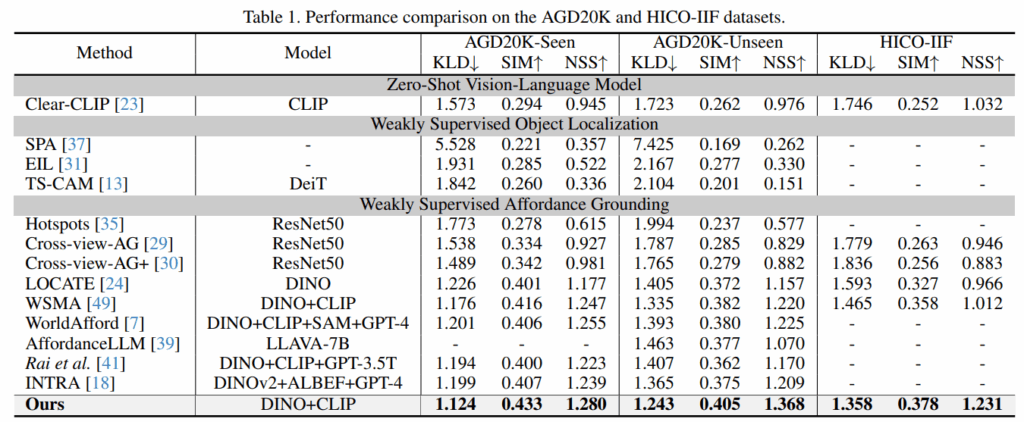
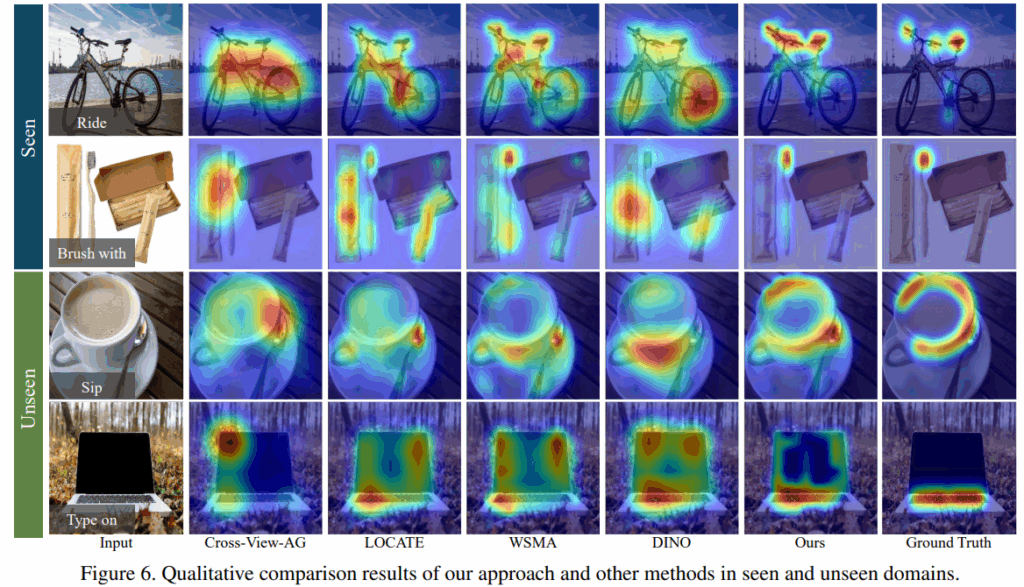
위의 Table 1은 저자들은 제안한 방법론을 다양한 백본을 사용하는 WSOL(Weakly Supervised Object Localization) 및 WSAG(Weakly Supervised Affordance Grounding) 기법들과 비교한 결과로, 보시면 모든 결과들을 비교해보았을 때 가장 좋은 성능을 달성함을 보였습니다. 특히, unseen 케이스에 대해서 성능이 두드러지게 개선되었음을 어필하며, 이러한 성능 개선이 contrastive learning의 특성으로부터 이루어졌다고 주장합니다. 아래의 Figure 6은 이에 대한 정성적 결과로, 저자들이 제안하는 방식이 기존 연구들에 비해 더욱 물체의 특정 부분에 집중하고 있음을 확인할 수 있으며, 다른 방법론에 비해 배경 영역으로의 활성화가 줄어든 경향을 확인할 수 있었습니다.
Ablation study
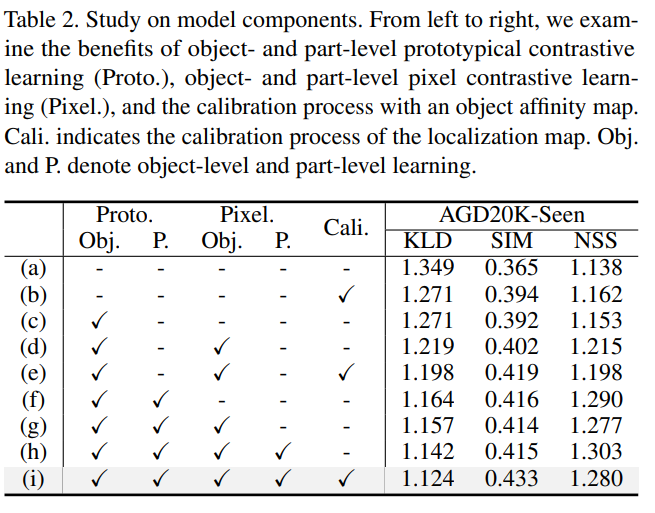
다음은 ablation study 결과로, 저자들이 제안한 요소들에 대한 효과를 검증한 결과입니다.
- (c)와(d) 결과를 통해 object-level의 학습을 추가하였을 대 성능이 크게 개선되었음을 확인하였으며, 이를 통해 WSAG에서는 객체 수준의 학습이 효과가 있음을 보였습니다.
- (f)와 (h) 결과를 통해 part-level의 학습을 통해 affordance와 관련되 물체 영역에 대한 성능이 개선되었음을 보였습니다.
- (h)와 (i) 결과를 통해 단순히 CAM 결과를 이용하는 것 보다 object affinity map을 결합하므로써 성능이 개선되었음도 보였습니다.

Study on Part and Object Level Supervision

Figure 7은 object-/part- level의 학습에 따른 효과를 정성적으로 나타낸 결과입니다. (a)는 object affinity map을 의미하며, 픽셀 수준으로 정밀하지는 않지만, action에 대응되는 물체 영역을 나타내고 있음을 확인할 수 있습니다. (b)와 (c)는 affordable part에 대하여 exocentric 이미지와 egocentric 이미지 결과를 나타낸 것 입니다. 종종 노이즈가 포함되기는 하지만, (b)가 일반적인 affordance 학습에 신뢰할만한 영역 정보를 제공하며, (c)는 part-level pixel contrastibe learning을 위해 affordance와 관련된 영역이 픽셀수준에서 활성화가 되어있음을 보였습니다.
안녕하세요, 좋은 리뷰 감사합니다.
egocentric 이미지와 exocentric 이미지의 특징들을 서로 주고받으면서 affordance 성능을 높인다고 이해하였습니다.
다만 조금 의문인건 exocentric 이미지는 contrastive learning에서 positive로 여겨지는 부분이 affordacne 대상 물체와 affordance를 하기 위해 어딘가를 잡고 있는 사람 손 같은 영역까지 같이 고려되는 것 같습니다. 그런데 egocentric 이미지에는 정말 타켓 물체만 존재하다보니 그 사이에 contrastive learning을 하게 되면 존재하는 노이즈가 있진 않은지, 그게 고려되지는 않는지 궁금합니다.
감사합니다.
리뷰 잘 읽었습니다, 한 가지 궁금한 점이 있어서 댓글 남깁니다.
CLIP 텍스트(액션)와 비주얼 사이 코사인 유사도로 만든 A_obj 가 “객체 영역”을 안정적으로 표시한다는 정성적 근거 외에, 정량 검증(예를 들면… GT box/part 대비 IoU 개선 수치?)이 있었는지 ?
안녕하세요 승현님 좋은 리뷰 감사합니다.
질문이 한가지 있는데, contrastive learning을 위해 negative로 사용될 배경 영역(Figure 4에서 빨간 세모에 해당하는)은 어떻게 선정이 되는지 궁금합니다!
감사합니다!
안녕하세요 승현님, 좋은 리뷰 감사합니다.
CAM의 coarse함으로 인해 object affinity map을 결합했다는 것에 대한 언급이 많이 나오고 나름의 contribution이기도 한 것 같아서 그러는데, object affinity map이 단순 cosine similarity map이라는 건가요?
리뷰 잘 읽었습니다.
간단한 질문 하나 남기고 가겠습니다
해당 방법론은 명시적인 라벨이 없는 데이터에서 Contrastive learning을 exocentric과 egocentric 간의 지식 전이로 활용한 방법론입니다.
Q1. exocentric으로부터 affordance 영역을 뽑기 위해서, object를 찾기 위해서? CLIP을 사용하는데요. 전반적으로 의존도가 높은 것 같아요… 근데… 재찬님이 진행하면서 결과를 보셔서 아시겠지만… 이게 0.81 로 임계값 처리가 될 수있나요? 저자가 뭔가 트릭을 사용한 걸까요?