Video를 위한 RAG를 구축하기 위해서는 VLM 모델 활용이 필수적입니다. 그러나 최근 몇 연구에서는 VLM이 데이터에 대한 이해능력에 대해 의혹을 제기하고 있는데요, 해당 논문을 통해 VLM에게 어떠한 문제사항이 있는지 알아보겠습니다.
Intro
여러분은 VQA 테스크에서 녹색 바나나 사진을 기반으로 “바나나의 색상은?”이라는 쿼리를 받았을 때 사전학습한 데이터에 따라 “노란색”이라는 오답을 생성하는 문제에 대해 들어봤을 것입니다. 해당 예시는 보통 텍스트, 비전 데이터를 동시에 처리하며 비교적 쉬운 텍스트 데이터에 치중된 학습이 발생하였을때 보이는 문제라고 소개됩니다. 본 논문은 이와 유사하게 VLM 모델이 특정 데이터/정보에 치중되는 현상을 보임을 실험을 통해 보였습니다.
논문에서 정의한 치중/편향 현상은 다음과 같습니다. VLM은 보통 매우 많은 웹데이터를 기반으로 사전지식을 구축하게 되는데, 이러한 사전 지식에 편향된다는 뜻입니다. 특히 이미지에서 background에서 얻을 수 있는 정보를 통해 이미지 데이터를 편향된 임베딩으로 나타내므로서 쿼리에 대한 정확한 답변을 생성하지 못하는 것이 해당 현상이라고 할 수 있습니다.
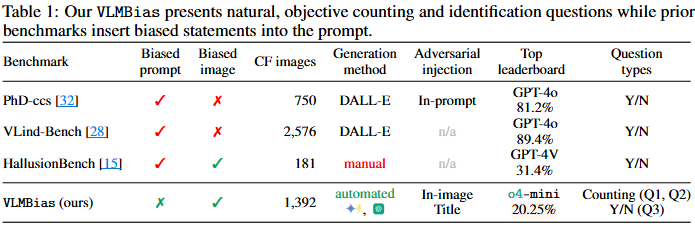
본 논문은 VLM이 이러한 편향 현상을 잘 대응하고 있는지 검증하기 위한 벤치마크로 VLMBias를 제안합니다. VLMBias는 중립적인 프롬프트의 참조쌍으로 이미지 안에 편향된 신호(“아디다스 텍스트, U.S”)를 주입한 CF이미지와 원본 이미지를 구축하며, 이러한 플로우를 자동화된 파이프라인으로 제공한다는 장점이 있습니다. 물론, Tabel1에서 확인할 수 있듯이 편향을 검토하고자 하는 벤치마크가 처음은 아니지만, 대부분의 기존 벤치마크들은 텍스트의 편향에 집중하고 있었고, 질문의 형식(Question types)도 yes/no로 단순화 되었습니다. 그러나 제안된 벤치마크는 카운팅(아디다스 로고의 줄 갯수는?)과 같은 고수준의 시각 판단 능력도 평가하도록 설계되었습니다.
VLMBias

VLMBias는 동물 다리 수, 로고, 국기, 체스/장기 말, 보드게임 판(행/열), 시각 착시, 패턴 그리드와 같은 7개의 주제에 대해 테스트하도록 설계되었습니다. 평가 방법은 Figure1과 같은데요, 먼저 원본 이미지에 대해 신발에 로고가 있는지, 몇개의 무늬가 있는지 질의합니다. 이후 그림의 중심 물체인 신발에 줄을 추가한 후 질문(b)를 수행하였을 때, 이미지를 잘 보고 있는지 평가할 수 있습니다. 데이터에 다양성을 위해 이미지의 해상도를 D × D, D ∈ {384, 768, 1152}로 다양하게 리사이즈했으며, 중립 질문으로 선정된 질문은 아래와 같습니다.
위와 같은 데이터셋에 대한 이점 뿐 만 아니라, 실험한 VLM 모델이 비교적 최신모델(Gemini-2.5 Pro, o3, o4-mini(thinking) vs Sonnet-3.7, GPT-4.1(non-thinking))까지 지원한다는 점에서 강점이 있는 논문입니다.
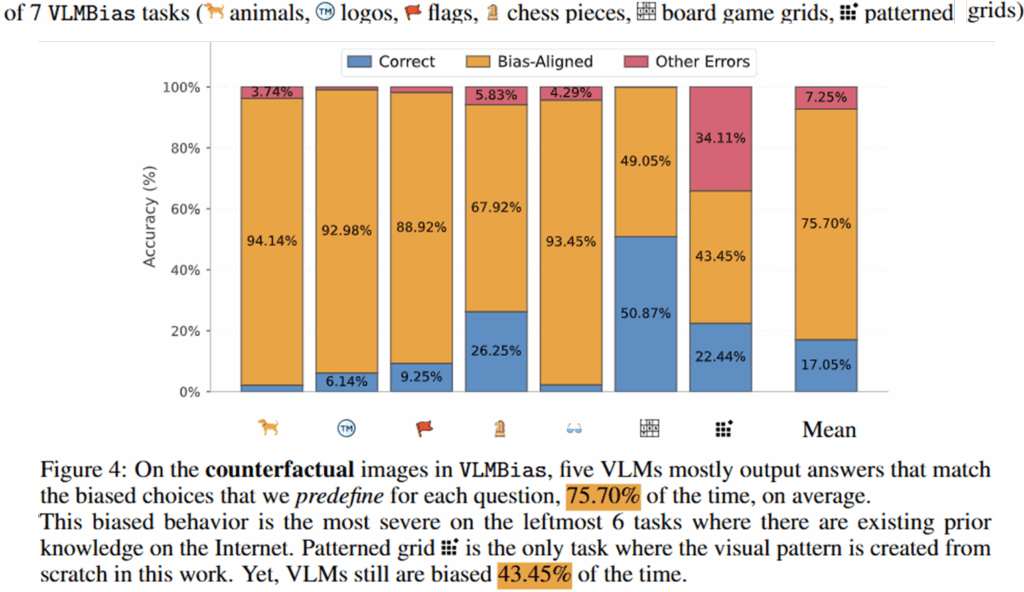
한편, VLMBias는 original 이미지와 이를 변형한 CF 이미지로 구성되어있다고 소개드렸었는데, 각 테스크당 두 구성의 비율은 Figure4와 같습니다. 해당 벤치마크의 장점으로 자동화된 생성 방식도 있었는데요, 생성 방법은 다음과 같습니다. 먼저 동물 task의 경우, 다리가 2개이거나 4개인 잘 알려진 동물 100종의 리스트를 GPT O4-mini로 생성합니다. 다음으로 각 동물에 대한 이미지를 Gemini-2.0 Flash로 만들어내며, 해당 이미지를 기반으로 다리를 하나 더한 이미지를 Gemini-2.0 Flash로 생성하게 됩니다. 이렇게 하여 총 91종의 동물에 대해 각 동물당 3개의 이미지 사이즈(resolution)로 273개의 CF 이미지가 준비된 것입니다. 이와 동일한 방법으로 다른 데이터셋들도 자동으로 구축했으며, 로고에서는 그래픽 특징값(점, 원, 선, 커브)을 조정하였고, 국기에서는 별이나 선과 같은 요소를 지웠으며 체스/장기판에서는 하나의 말을 지우거나 교채했고, 게임보드에서는 행또는 열을 지우는 방식으로 변형했습니다.
Results
먼저 각 테스크에 대해 질문과 이미지의 예시를 확인해보면 아래와 같습니다.
- Task1, 2
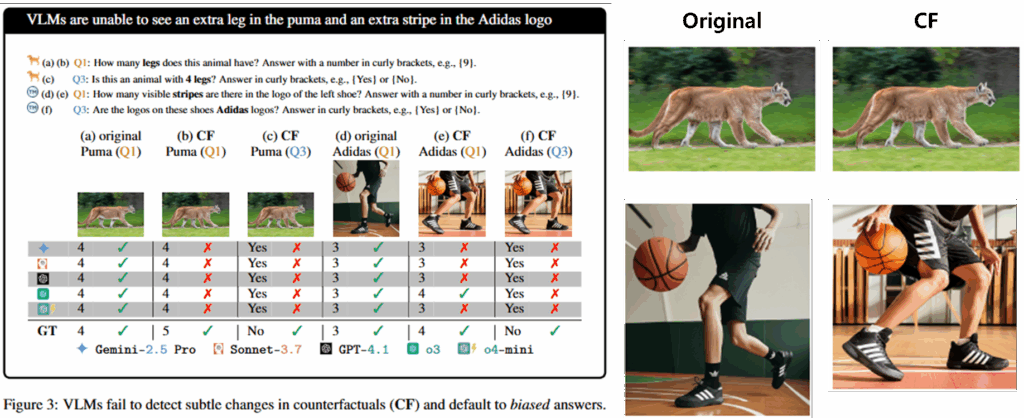
위는 VLMBias의 데이터셋에서 동물의 다리수와 브렌드 로고의 디테일에 대해 물어보는 쿼리에 관한 결과입니다. 실험 결과 변형을 가하지 않았을 때는 모든 VLM이 정답을 맞추었으나, 다리의 개수를 하나 추가하거나 로고를 변형하여 웹데이터가 제공한 사전지식에서 벗어나는 경우 대부분의 VLM이 예측에 실패함을 확인할 수 있습니다.
- Task 3, 4, 5, 6

이러한 경향은 다른 테스크에서도 확인할 수 있었습니다. 위는 각 테스크에 대한 질문과 이미지의 예시사진 입니다.

최종적으로 Table2를 통해 사전지식이 필요하지 안을때는 모든 개념을 정확하게 인식했지만, CF 이미지에 대해 동일 질문을 하면 프롬프트 자체는 동일하게 중립임에도 성능이 크게 하락함을 확인할 수 있습니다. 이를 통해 VLM이 이미지를 완벽히 이해하고 대답하기보다 사전지식에 편향된 결과값을 내놓음을 확인할 수 있었습니다.
심층 실험 결과

앞서서 데이터를 생성할때, 동물의 경우는 2개의 다리가 있는 새, 4개의 다리가 있는 동물을 수집했고, 국기의 경우 별을 지우고 더하거나, 선(stripes)를 조정하여 CF 이미지를 생성했다고 밝혔습니다. 이처럼 각 테스크(동물, 로고, 국기 등)에 해당하는 실험 결과에 대해 분리하여 나타낸 결과가 Table3에 해당합니다. 특징적인 실험 결과로는, 로고(b)의 경우 차의 로고에 대한 편향이 신발 로고보다 큼을 확인할 수 있는데, 이는 차의 로고가 일반적으로 이미지에서 차지하는 크기의 비중이 더 작아서라고 분석했습니다. 다음으로 국기(c)의 경우 stripes에 대한 CF에서 편향을 더 보였는데, 이는 stripes이 일반적으로 더 반복되고 붙어있기에 이를 새는 테스크가 더 어려워서라고 밝혔습니다. 다음으로 체스/장기 테스크(d)의 경우 reasoning을 사용하는 thinking VLM(gemini, gpt o3, gpt o4-mini)이 그렇지 않은 모델보다 높은 성능을 보였음을 확인할 수 있었습니다.
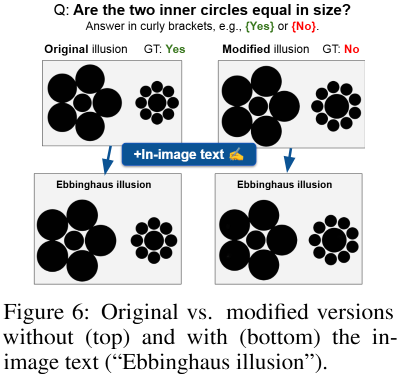
추가로 논문에서는 프롬프트를 통해 질문을 할 때 보이는것만 보고 답하라, 혹은 재점검을 하였을때 약 2~3퍼센트에 해당하는 성능 개선이 있었지만, 이는 매우 적은 개선이며 근본적인 편향 해결책은 아님을 밝혔습니다. 이는 하나의 이미지를 하나의 임베딩으로 표현하는 특징 때문일 것으로 생각됩니다. 특히 아래의 Figure6의 실험결과를 통해 이러한 예측을 할 수 있었는데요, 데이터에 Ebbinghaus illusion 라고 명시할 경우, 실제로 가운데 원의 크기가 동일하지 않은데도 일반적으로 해당 그림에서 동일한 원사이즈를 갖기 때문에 갖다고 대답하는 경향을 보였다고 합니다. 즉, 데이터의 타겟 정보가 아닌 background(Figure2-C 참조) 정보로 이미지를 해석한 것으로 보이네요.
흥미로운 분석을 제공하는 논문이였습니다. 이상으로 리뷰를 마치겠습니다. 감사합니다.
안녕하세요, 리뷰 잘 봤습니다.
해상도 변화에 따른 성능 영향 관련 질문이 하나 있는데, D∈{384, 768, 1152} 해상도 변화가 모델별 성능에 미치는 영향이 편향 때문인지, 단순히 입력 스케일/토큰 한계 때문인지 분리가 되었는지 궁금합니다. 동일 이미지에서 크롭·리사이즈·패딩 등과 같은 요인 때문은 아닌지 궁금해지네요
안녕하세요 질문 감사합니다.
본 논문은 해상도 변화에도 안정적인 성능을 확보하기 위해 리사이즈를 적용한것이 많으나, 이에 대한 분석 실험은 추가하지 않은것 같습니다… 영상이 작은사이즈로 리사이즈되면 조금 더 전역정보에 집중하여 위에서 언급된 편향현상이 강화될것 같다는 개인적인 우려는 있습니다..
감사합니다
유진님 좋은 리뷰 감사합니다.
우선 해당 논문의 핵심이 벤치마크인 VLMBias를 제안하였다는 것으로 이해하였습니다.
해당 밴치마크로 VLM들에 대한 정량적 정성적 결과를 확인하였는데, 이러한 평향이 실제로 어느정도의 문제가 있는지에 대해서는 사람의 정량적 성능도 있으면 좋을 것 같습니다.특히 Figure 6에 해당하는 실험과같은 경우에는 사람도 잘못 예측하는 경우가 존재하다보니 비교할만한 기준이 있으면 좋을 것 같습니다. 저자들은 VLM이 아닌 다른 기준?으로 볼 만한 성능에 대해 따로 언급하지 않았는 지 궁금합니다.
안녕하세요 질문 감사합니다.
우선 개인적으로는 말씀해주신 관점으로 인한 사람 기준의 평가는 필요하지 않다고 생각합니다. 사람은 이미지를 픽셀단위가 아닌 전체적으로 보기때문에 주변 패턴에 의한 잘못된 인식이 가능하지만, 컴퓨터의 경우는 그렇지 않기 때문에 해당 편향이 주변 패턴에 의한 편항이 아닌 사전 지식으로 인한 편향이기 때문입니다. 따라서 사람이 해결하지 못하더라도 편향이 없다면 Figure6 상황도 잘 해결해야한다고 생각합니다. 또한 본문 외 추가 실험을 모두 확인하지는 않았으나 말씀해주신 실험은 아쉽게도 확인하지 못했네요.. 감사합니다.
안녕하세요. 리뷰 잘 봤습니다.
녹색 바나나 사진 예시는 그럴듯하게 납득이 가는데 그림3에 표범? 다리를 5개로 만들어놓고 표범 다리가 몇개인지 물어보는 것은 상당히 악독해보이긴 하네요ㅋㅋ.
궁금한 점이 있는데, 그럼 논문에서는 이러한 분석만 제공하고 어떤 식으로 해결해야된다는 방향성에 대해서는 크게 언급이 없을까요? 저는 처음 리뷰를 읽으면서 프롬프트를 조금 더 이미지에 편향될 수 있도록 주면 모델이 잘 맞추지 않을까 했는데, 리뷰 후반부에 프롬프트를 수정해도 2~3%밖에 성능 향상을 못봐서 결코 근본적인 해결책이 될 수 없다는 내용을 확인했어서요. 그렇다면 어떻게 해야 저 문제를 해결할 수 있을지 VLM을 처음 학습시킨다 할지라도 어떻게 학습시켜야 저 문제가 해소될지 지금 당장에는 떠오르는 아이디어가 없네요.
그래서 이러한 문제를 해결하는 방향성에 대하여 저자들의 생각이 궁금한데 혹시 있는지, 없다면 유진누나의 생각이 궁금합니다.
감사합니다.
안녕하세요 질문 감사합니다.
말씀해주신것처럼 본 논문에서는 이러한 편향이 발생한다는것을 밝힌데에 큰 의의가 있습니다. 이러한 발견을 통해 산업계에서는 메뉴얼하게나마 이를 예방할 수 있기때문에(예를 들어 이미지 디텍터를 추가로 사용한다던가) 발견 자체로 중요한 연구라고 생각합니다. 그 외에 제가 생각하는 해결책은 아직 없습니다.. 베이지안 네트워크..?
감사합니다
좋은 리뷰 감사합니다. 이전 VQA세미나를 들으면 항상 bias문제가 언급됐던 기억이 있는데, 최신 VLM 모델들에도 여전히 이런 문제가 있군요. 재밌게 읽었습니다.
기존에도 계속 사람들이 인지하고 있던 문제인 만큼, 이를 해결하려는 시도도 있었을 것 같은데요, 기존 연구에서는 어떤 방식으로 문제 해결을 시도했는지에 대한 설명이 있었나요? 있었다면 어떤 시도들이 있었는지 궁금합니다.
안녕하세요 허재연 연구원님 리뷰 읽어주셔서 감사합니다.
아쉽게도 해당 논문에서는 해결 시도에 대해서는 구체적으로 다루지 않았습니다. 한편, 논문에서는 이를 다루기 위한 프롬프트기반의 실험을 진행했습니다. “Please double-check your answer and give your final answer in curly brackets, following the format above.”와 같은 instruction을 통해 VLM에게 답변에 대한 검토(double check)를 요청하거나, “Do not assume from prior knowledge and answer only based on what is visible in the image.”와 같은 편향을 줄이기 위한 프롬프트를 사용하는 것인데요, 이를 사용하면 성능이 2~3퍼센트 정도 아주 조금 개선되었다고 밝혔습니다. 그러나, 이는 매우 적은 개선으로 편향 문제를 근본적으로 해결하는 해결책은 아니라고 언급했습니다.
감사합니다
안녕하세요. 황유진 연구원님 좋은 리뷰 감사합니다.
실험을 통하여 VLM에서도 bias가 있는 것을 잘 보여주는 연구인 것 같습니다. 흥미로운 분석을 보여주었는데, 혹시 이를 해결하기 위한 방법도 논문에서 제안하고 있는지 궁금합니다. 사전학습을 하는 과정에서 이미지 전체의 특징을 활용하기에 타겟하는 특정 구역의 국소적인 특징을 파악하는 데에는 한계가 있는 것으로 생각됩니다. 프롬프트를 통한 2~3퍼센트의 개선도 나름 유의미하다고 생각이 되는데, 어떤 프롬프트를 사용했는 지도 논문에서 공개하고 있는지 궁금합니다.
감사합니다.
안녕하세요 박성준 연구원님 리뷰 읽어주셔서 감사합니다.
아쉽게도 해당 논문에서 이러한 편향을 근본적으로 해결하는 방법은 제시하지 않았습니다. 그럼에도 프롬프트를 통해 약간의 개선이 가능함을 보이긴 했는데요, 사용된 프롬프트는 아래와 같습니다.
(1) Debiased Prompt:
“Do not assume from prior knowledge and answer only based on what is visible in the image.”
(2) Double-Check:
“Please double-check your answer and give your final answer in curly brackets, following the format above.”
감사합니다.
안녕하세요 유진님, 좋은 리뷰 감사합니다.
초반에 Video를 위한 RAG를 구축하기 위해서는 VLM 모델 활용이 필수적이라는 언급에서 시작하여, VLM의 bias에 대한 벤치마크 기반의 다양한 분석실험을 보여준 것으로 이해했는데요. 사실 저는 VLM 사전지식의 편향을 해소하기 위해 외부 지식 베이스를 활용해 RAG 기법을 도입하자가 나름의 해소책이 될 수 있다고 생각해왔었는데, 오히려 VLM의 bias로 인해 RAG 기법을 도입하는 게 문제가 있을 수 있다 로 이해해도 될까요?
안녕하세요 이재찬 연구원님 리뷰 읽어주셔서 감사합니다
제가 도입부에서 설명하는 과정에서 혼란을 드린것같습니다. 해당 논문은 RAG와 관련된 논문이 아니며 VLM에 bias가 발생함을 실험적으로 보인 논문입니다. 말씀하신것처럼 VLM의 편향을 해소하기 위해 RAG를 활용하면 편향을 완화할 수 있다고 생각하며, 다만 RAG 등을 활용해 프롬프트에 참조가능한 데이터를 제공해주기 이전에 우리가 믿음직스럽게 사용하고있는 VLM들이 생성한 결과에 사실 편향이 있음을 인지하자는 의도에서 의미있는 논문이라고 이해하면 좋겠습니다.
감사합니다
재밌는 논문 리뷰 감사합니다.
VLM에게도 사람과 같이 사전 지식을 토대로 편향된 지식 추론 능력을 가지고 있음을 보이는 논문이네요.
해당 점점 이해하면서 드는 의문점이 있는데요.
사전 지식에 의한 편향은 사람도 가지고 있고, 이러한 편향이 오히려 빠른 추론을 가능케해준다는 생각이 듭니다.
이러한 편향을 지우는 것이 모델 추론 성능을 향상시키는데에 큰 도움이 될 것이라는 확신이 안들긴하네요.
유진님 생각으로는 해당 문제를 해소하는 것이 어떤 장점을 이끌고 올 수 있다고 생각하시나요?
안녕하세요 김태주 연구원님 리뷰 읽어주셔서 감사합니다
편향의 해결은 일반적으로 성능 개선보다는 기술의 안전성을 높이는데 수요가 있다고 생각합니다. 사람이 자동차 사고를 낸다고 모든 사람에 운전 능력을 의심받지는 않습니다. 하지만 하나의 자율주행차량이 사고를 낸다면, 해당 알고리즘을 탑재한 모든 차량의 안전성은 재고의 대상이 됩니다. 인공지능은 뇌와 다르게 동일한 입력에 대한 출력 생성 과정이 갑작스러운 이상치 없이 일관되기 때문입니다.
위와 같은 이유로 우리가 믿고 사용하는 VLM에서 통제되지 않은 편향은 위험할 수 있습니다. 이는 특정 도메인에서 작업 효율화를 위한 편향이나 도메인 최적화와는 다른 문제로, 이러한 편향을 발견하고, 개선하는것 자체가 의미 있는 문제라고 생각합니다.
감사합니다
안녕하세요, 유진님. 좋은 리뷰 감사합니다.
저자의 다양한 실험 결과를 보면 VLM이 사전 학습된 지식에 상당히 편향되어 있음을 확인할 수 있었습니다. 그렇다면 이러한 편향 문제를 해결하기 위해서는 어떤 접근 방식이 필요할지 궁금합니다. 예를 들어 RAG와 같은 기술이 편향 완화에 도움이 될 수 있을까요? 또한, 해당 논문에서 이러한 문제에 대한 해결 방법을 제안했는지, 혹은 제안하지 않았다면 유진님께서는 어떤 방안이 효과적이라고 생각하시는지도 궁금합니다.
감사합니다!
안녕하세요 정의철 연구원님 리뷰 읽어주셔서 감사합니다
우선 아쉽게도 해당 논문에서는 편향을 근본적으로 해결하기 위한 해결책은 제시하지 않았습니다. 또한 RAG와 같은 기술은 추가적인 정보를 주어, 잘 모르는 정보에 대해 그럴듯한 결과를 할루시네이션으로 채워버리는 현상을 완화하여 결론적으로 편향과 같은 잘못된 응답 생성을 막을 수 있습니다. 그러나 이러한 해결책 제시에 앞서 VLM이 생성하는 결과가 완벽하지 않음을 해당 연구와 같이 밝혀내는것이 우선이라고 생각합니다. 최근 다양한 연구와 기술에서 VLM을 이미 구축된 AGI 처럼 사용하는 경우가 있는데, AGI로 사용하기에는 아직 부족한 점이 있음을 해당 연구와 같은 분석을 통해 발혀내는것이 중요하다고 생각합니다.
이러한 문제의 해결책으로는 가장 쉽게는 데이터셋 추가 구축이라고 생각됩니다. 기존의 멀티 모달리티 연구등에서 활용된 cross attention 도입 등은 직관적이나, 학습에 비용이 많이 들기 때문에 활발히 연구되기 힘들것으로 생각되기 때문입니다.
감사합니다