이번 리뷰 논문은 VLA 논문으로 가장 핫한 트렌드인 Dual-system VLA에 대한 꼼꼼한 분석을 하고 분석 결과를 토대로 SOTA를 달성한 기법 입니다. 지속적으로 분석과 공유를 할 예정이라고 합니다.
Intro
기존 전통적인 정책 학습은 주로 경량화된 모델을 활용하여 특정 행동을 그대로 학습하는 것에 집중했습니다. 이러한 방법은 환경 변화에 매우 취약하다는 단점을 가져 일반화 능력을 갖추는 것이 어려웠죠. 이러한 와중에 사람 수준의 일반화된 지식 추론 능력을 보여주는 LLM과 Multi-modal LLM (MLLM)의 등장으로 이를 활용한 VLA는 로봇 제어 분야에서 일반화 가능성에 큰 잠재력을 보여주고 있습니다.
LLM의 지식을 활용해 VLA 개념을 처음 도입한 RT-2 모델은 internet-scale data 뿐만이 아니라 실제 로봇데이터까지 동시에 학습하는 방식을 제안합니다. 이를 통해 VLA는 전통적인 정책 학습에서는 갖지 못한 새로운 물체에 대한 적응력과 의미적으로 다양한 지시사항에 대한 높은 이해력을 바탕으로 일반화에 대한 가능성을 보여주었습니다. 해당 연구 기점으로 로봇 연구가들은 VLA 모델을 시각 정보와 언어 명령을 통합적으로 처리하여 로봇이 수행해야 하는 복잡한 작업을 수행 가능하도록 하는 지원하는 Robot Foundation Model로 개발하기 위한 노력과 기대를 가지게 되었죠.
허나, VLA도 여전히 한계점을 가지고 있습니다. MLLM의 지식을 토대로 뛰어난 잠재력을 보여주지만, 실제 도메인 특화된 환경이나, 실시간 동작이 요구되는 실제 현장에 적용하기 어렵다는 문제점이 존재합니다. 크게 2가지 문제점을 꼽을 수 있습니다. 먼저, VLA은 모델의 크기가 크고 무거워서 실시간 성능 최적화가 어렵습니다. 예를 들어, RT-2 [1]는 55B 파라미터를 가진 모델로 1~3 Hz를 처리 속도를 가지며, 5B 모델 조차도 5Hz에 불과한 반면에 전통적인 정책 모델들은 약 50 Hz로 훨씬 빠른 속도를 보입니다. 또 다른 문제점은 사전 훈련은 많은 리소스를 요구하며, 사전 학습된 모델에 대한 미세 조정은 domain shift와 catasrophic forgetting과 같은 문제가 발생합니다. 이로 인해, 뛰어난 이해 능력을 유지하면서 일관성 있고 빠른 추론을 보장하는 것을 굉장히 어려운 일입니다.
위와 같은 한계를 극복하기 위해서 LCB [2]에서는 Dual-system VLA 구조를 처음으로 채택하여 제안하게 되었습니다. 해당 구조는 인간의 인지가 서로 다른 두 시스템으로 동작한다는 dual-process theory을 기반으로 다음과 같이 system 1과 system 2로 구성됩니다.
먼저, System 1은 실시간 동작을 기반으로 하는 모듈로 빠르고 직관적이며 무의식적, 휴리스틱 기반, 전통적 가벼운 정책 네트워크와 유사한 구조를 갖춥니다. 해당 모듈은 bias와 error가 발생하기도 합니다. 이는 특정 상황에 대한 휴리스틱에 따른 지름길을 끌고 오지만 실수도 많이 하기 때문입니다. 이러한 특징으로특화된 도메인에서는 강인성을 보이지만 일반화 능력은 떨어지게 됩니다.
System 2는 느리고 신중하며 의식적, 논리적 사고와 추론 담당, 대형 MLLM/VLA와 유사하며 높은 일반화 능력 보유한 것이 특징입니다. 많은 연산을 요구하는 것이 문제이지만, 에러에 대한 검증을 수행하기 때문에 복잡한 문제에 대해 사려 깊은 결정을 내는 것이 큰 특징입니다.
두 시스템은 병렬로 작동하지만, 정보 갱신 주기는 서로 다르게 작동합니다. 느린 System 2는 고차원 추론과 신중한 결정을 위해 느리게 업데이트되는 반면, 빠른 System 1은 신속한 행동 생성을 위해 고빈도로 정보를 갱신합니다. 이로써 실시간 로봇 제어에서 필요한 빠른 반응성과 복잡한 멀티모달 추론 능력을 효과적으로 융합이 가능하게 됩니다.
Current Dual-System VLAs
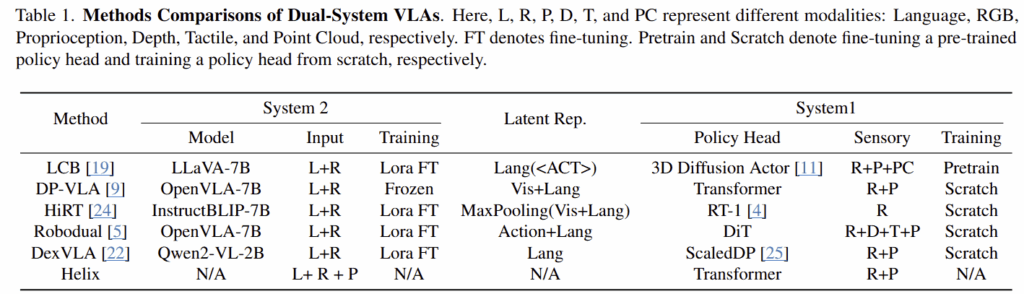
현존하는 Dual-System VLAs는 tab 1에서도 확인 가능합니다. 해당 구조에 대해서 주의할 점이 있습니다. system 1이 실시간 추론이 가능하려면 RGB와 같은 입력이 실시간으로 받을 수 있는 구조를 갖춰야만 합니다. 해당 논문에서는 pi-zero나 GROOT-N1은 dual-system VLA와 유사한 구조를 가지지만 system 1이 입력을 받는 구조를 가지지 않기 때문에 dual-system VLA로 정의하지 않습니다.
Key Design of Dual-System VLAs
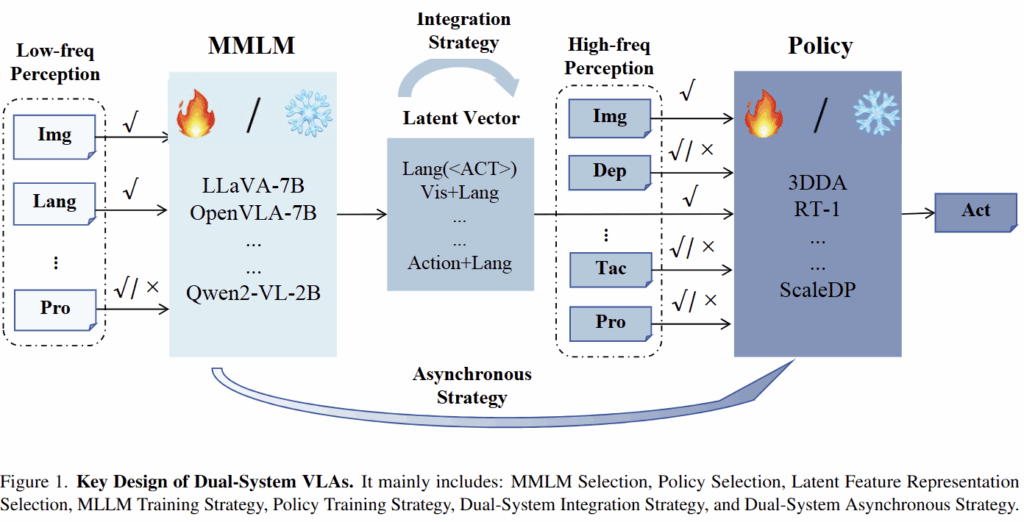
앞선 섹션을 보면 전반적인 dual-system VLAs 서로 유사한 구조를 가지고 있습니다. 해당 시스템은 system 2의 강점을 보존해 일반화 가능한 이해 능력과 system 1이 로봇 동작을 정밀하면서 빠르게 동작하기 위한 미묘한 균형을 달성해야만 합니다. 저자는 key design을 선정하기 위해 특징들을 기반으로 문제점을 정의하고 이를 기반으로 구성 요소를 fig 1과 같이 정의합니다. 저자가 정의한 핵심 문제는 다음과 같습니다.
- MLLM Selection. 로봇 시나리오에서 적합한 MLLM을 선정하는 것이 매우 중요하며, 각 VLA 시나리오에 따라 요구 사항도 상이합니다. 예를 들어, Flower [3]은 spatial awareness/low-level vision이 매우 뛰어나며, MiniVLA에서는 Qwen-VL 0.25B 모델을 활용하여 추론 비용에 대한 부담을 줄이는 방법을 책택했습니다. 또한, 로봇 데이터로 사전 학습된 MLLM이 필요 여부에 대해서는 아직 논란이 있으며, 로봇 데이터로 학습된 MLLM을 활용하면 도메인 차이가 줄여져 다양한 언어 명령 수행에서 더 강인한 성능을 낼 수 있다는 Robodual [4]에 대한 실험 결과가 있습니다.
즉, 현 시점에서는 가볍고 효율적인 MLLM 모델과, 로봇 특화 데이터로 학습된 MLLM 필요 여부가 모델 선택에 따른 중요 요소로 보이고 있습니다. - Policy Selection. Policy Model에 대한 선택에 대해서는 상대적으로 논쟁의 여지가 적으며, DiT 혹은 Flow Matching 구조가 요구 사항(작고 빠르며, 높은 성능)을 충족한다는 것이 일반적인 관점입니다. 최근 들어서는 CARP [5], Dense Policy [6]와 같이 새로운 구조를 가진 정책 모델들이 등장하고 있습니다. 또한, robodual에 따르면 system 1에는 다양한 modal 정보들이 강인성을 준다는 분석이 있어 이를 기반으로 하는 방향도 중요한 부분도 하나로 볼 수 있습니다.
- Latent Feature Representation Selection. 해당 시스템에 있어서 가장 복잡하고 중요한 요소 중에 하나로 저자가 강하게 주장하는 요소입니다. 이전 연구에서는 latent token 선정 방식에 있어 상당한 차이를 보였습니다. 예를 들어, DP-VLA에서는 MLLM의 마지막 레이어로부터 얻은 hidden embedding을 직접 활용한 반면에, GR00T-N1은 중간 레이어의 특징을 선택하여 더 많은 시각 정보를 포함하고 추론 시간을 줄이는 전략을 취하였습니다. 또 다른 방식으로 Roboflamingo와 HiRT는 MLLM의 마지막 레이어의 언어 및 시각 특징을 Max-pooling 하여 다운스트림으로 활용했고, LCB에서는 action에 대한 token을 추가 도입하여 상위 모델과 하위 모델 간의 연결고리를 fine-tuning으로 강화한 시도를 보였습니다. robodual에서는 이 두 방법을 상호보완적으로 결합시켜, 토큰와 마지막 레이어의 언어 특징을 합쳐 보다 풍부한 latent feature를 생성하는 방법을 활용하였습니다.
최근, ReKep이나 LEGO와 같이 더욱 정교한 hidden state를 활용하는 방법이 제안되고 있습니다. 향후 연구에서는 다운스트림 동작 생성 모델에 적합한 정보를 효과적으로 전달하기 위한 핵심 연구들이 VLA의 성능 향상과 일반화 능력 개선에 중요한 방향으로 작용할 것으로 보입니다. - MLLM Training Strategy. MLLM을 훈련하는 방법에 대한 주요 고려 사항은 다운스트림과 원활하게 통합되면서 모델의 일반화 능력을 손실 없이 유지 가능한 여부에 대한 부분입니다. 현재 흐름에서는 frozen 방법과 fine-tuning 방법을 활용하고 있으며, 더 나은 미세 조정 방법이 있다면 이를 탐구 하는 것도 좋은 연구 방향이라고 저자는 설명하고 있습니다.
- Policy Training Strategy. 정책 모델의 훈련 방법에 대한 주요 고려 사항은 모델의 훈련 비용을 줄일 수 있는지 여부입니다. 만약 사전 훈련된 정책 모델을 가져와 미세 조정이 가능하다면 전체 훈련 시간을 크게 줄일 수 있습니다.
- Dual-System Integration Strategy. 통합 전략에 대한 주요 고려 사항은 latent feature를 condition으로 다운스트림에 임베딩하는 방법에 대한 것 입니다. LCB에서는 CLIP Loss를 사용하여 system 2의 latent feature를 CLIP 임베딩과 유사하게 만들어 system 1과 system 2에 대한 구성 요소를 연결하는 방법을 사용했습니다. 해당 방법은 효과적인 결과를 보여주지만, 모델이 system 1에서만 학습하게 되기 때문에 MLLM의 일반화 성능을 헤칠 위험섬이 있습니다. 그리고, 새로운 임베딩을 수용하는 경우에는 두 시스템 간의 다른 차원을 일치시키기 위한 projector를 도입하는 것이 일반적입니다. 그렇기에 projector를 훈련 시킬 방법에 대해서도 신중하게 선택해야 합니다. 만약에 system 1이 사전 학습되어 있는 경우에, projector를 학습시키지 않고 모든 시스템을 한번에 학습을 시키면 모델 훈련 자체가 실패하게 됩니다. 따라서, 통합을 위한 전략을 매우 중요한 요소 중 하나입니다.
- Dual-System Asynchronous Strategy. 마지막으로, dual-system 모델을 위한 비동기 전략이 있습니다. LCB, HiRT, 그리고 Robodual은 각기 다른 비동기 방식을 사용하며, LCB가 가장 단순하게 동기적 학습을 수행하고, 비동기적 테스트를 사용합니다. 또한, 이론적으로 upstream과 downstream 구성 요소 간의 추론 빈도 차이가 최종 성능에 영향을 미칠 수 있습니다만, 이에 대한 명확한 분석은 존재하지 않습니다. 그리거 제공되는 system 2의 특징이 효과적이지 않다면, 상위 및 하위 계층 간의 비동기적 추론은 단지 유사 요구 사항일 수 있습니다. 따라서 이를 검증하기 위해 더 많은 실험이 필요하다고 합니다.
Empirical Evaluations
저자는 앞서 다룬 문제 정의를 기반으로 Dual-system VLAs의 지침을 제시하고자 합니다. 위 7가지 정의 중 1, 2, 3, 7번 조건에 대해서는 표준화하여 일관된 실험을 진행하고 4, 5, 6번 조건에 대해서 비교 가능한 실험을 제시합니다.
+ 아마 1, 2, 3, 7번 조건에 따른 비교 실험을 하기에 너무 큰 범위를 가졌기 때문에, 비교적 비교가 쉬운 4, 5, 6번을 진행하는 걸로 파악됩니다. 추후에 확장된 실험을 업데이트한다고 하니, 다른 조건에 대해서도 실험이 추가되길 희망하는 중입니다.
Experiment setup
– Model Selection. MLLM은 LLaVA 1.0 [7]을 선택, Policy model은 3DDA [8]을 선정했으며, dual-system intergration은 LBA [2]를 따릅니다.
– Dataset Processing. chat 형식을 이용하는 LBA와 다르게 언어 명령에 뒷 부분에 <ACT> token을 추가하여 사용합니다. (+ 저자가 chat 형식인 LBA를 따르지 못한 이유가 구현 이슈라고 하며, 추후에 구현?한다고 합니다.)
– Environment. 다른 기법들과 공평한 비교 실험을 진행하기 위해서 CALVIN datasets을 활용하며, Real-world로 확장하고자 한다고 합니다.
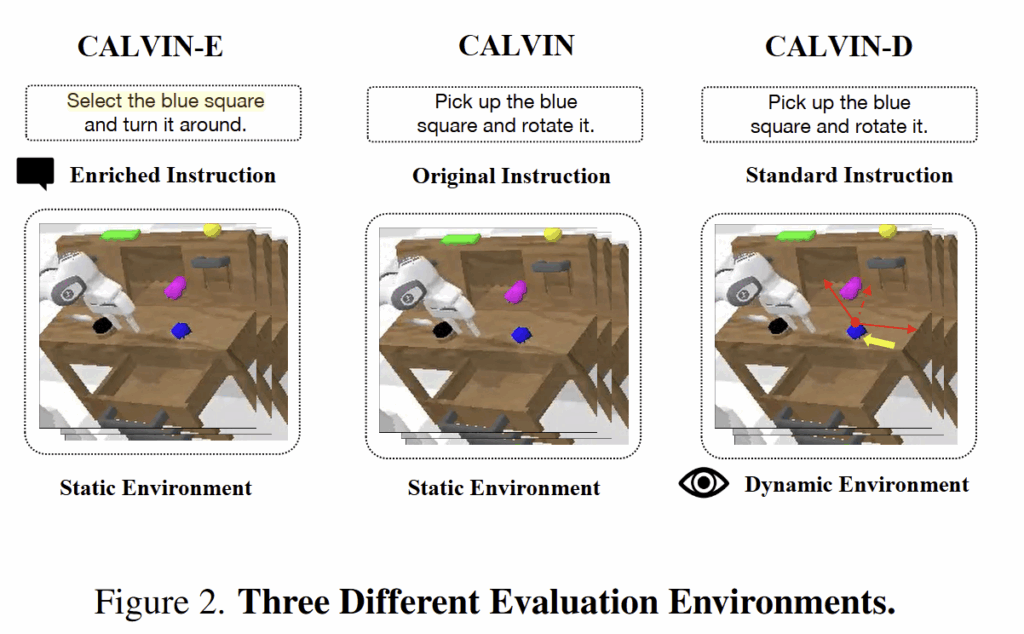
– Standard Evaluation. 기존 연구들과 동일하게 ABC-D 시나리오 방식으로 평가를 진행합니다. 테스트와 ablation study에서는 100 번의 평가만 진행하고, 전체 평가는 tab 8에서 full-set 1,000에 대한 결과를 볼 수 있습니다.
– Harder Evaluation. 저자는 객체가 정적이고 명령어가 덜 자연스러운 점을 자체 개선한 데이터 셋을 제작하여 실험을 통해 추가적인 분석을 진행합니다.
– CALVIN-E: 언어 명령어에 대한 일반화 능력을 보기 위해서 보다 풍부한 명령어를 추가한 데이터 셋
– CALVIN-D: 기존엔 정적인 대상 객체를 4가지 다른 모션을 주어 동적 시나리오에 대한 강인성을 평가하기 위한 데이터 셋
Why not single system?
저자가 밝히길 CALVIN-D 실험을 정의하고 나서 기존 single system은 해당 실험에서 실패한 것이라고 판단하여 후속 실험에서는 dual-system만 활용했다고 합니다.
Setup. 먼저, ABC 시나리오에서 모델을 학습하고, D에서 100 번의 다양성을 주어 평가를 진행합니다. 동적 강인성을 평가하기 위해서 “Static” 외에도 4가지 모션 “Left,” “Forward,” “Diagonal,” “Circle”를 추가하여 평가를 진행합니다. 해당 실험에 대한 결과는 아래 tab 2에서도 확인이 가능합니다
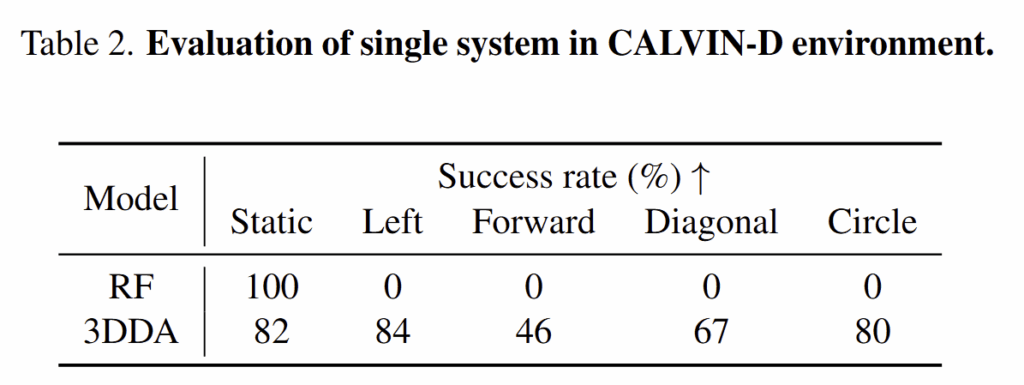
Analysis. 저자는 대표적인 단일 시스템 모델인 RF (RoboFlamingo) [9]과 대표적인 듀얼 시스템 모델인 3D Diffusion Actor (3DDA) [8]을 이용한 비교 실험을 진행했습니다. CALVIN-D에서 꽤 놀라운 결과를 볼 수 있습니다. 단일 시스템 모델인 RF는 동적인 환경에서 완전히 실패하는 경향을 보여주고 있습니다. 근본적인 이유는 해당 시스템 구조가 연속적인 6장의 영상을 입력으로 받아 LSTM-based action inference를 수행하면서 로봇이 움직이는 구조만 학습 중에만 관찰하고 동적인 객체를 보지 못한 점이 테스트 중 동적 객체에 대한 강인성을 보이지 못하는 이유라고 볼 수 있다고 합니다. 이에 반해서 3DDA는 준수한 성능을 보여주고 있습니다. 재밌는 점은 RF가 비교적 간단한 태스크 (‘Static”)에서는 굉장히 높은 성능을 보여줍니다. 즉, MLLM이 시스템 내에서 “brain”으로 활용된다고 해석할 수 있다고 저자는 주장합니다.
++ Discussion. 저자는 다른 종류의 단일 시스템인 Pi-zero, GR00T-N1에 대해서도 비교 실험이 필요하다며 추후 진행한다고 합니다.
Training strategy of dual system
듀얼 시스템을 학습 시키기 위한 전략은 3가지 파트로 구분 됩니다. 어떻게 low-level policy를 학습 시킬지, high-level MLLM을 어떻게 학습 시킬지, 두 구성을 어떻게 연결 시킬지… 해당 섹션은 이에 대한 분석을 다룹니다.
Policy Training Strategy.
Preliminary. LCB인 경우, low-level policy는 사전 학습된 3DDA를 활용합니다. HiRT는 RT-1 구조를 기반으로 처음부터 학습을 진행합니다. Robodual은 자체 설계된 다운스트림 정책을 활용합니다. 해당 섹션에서 가장 중요한 점은 정책 학습에는 scratch 방식과 사전 학습된 모델을 fine tunning 하는 방식입니다.
Setup. 공평한 비교를 위해서 large model의 구성은 LCB를 따릅니다: LLaVA1.0 backbone은 <ACT> token과 연결되어 있으며 CLIP Loss를 활용하여 downstream instruction에 대해 정렬하여 작업합니다. 기존 방식과 다른 점은 downstream policy가 사전 학습된 3DDA를 활용하는 것인지, 처음부터 실험을 진행하는지 입니다. 이는 Tab 4에서 볼 수 있습니다.
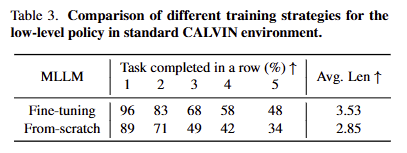

Analysis. Tab 3에서도 사전 학습된 모델을 사용하면 개선된 성능을 보인다는 것을 볼 수 있습니다. 그러므로 모든 기법들은 사전 학습된 모델에 fine-tunning을 수행하여 평가를 진행했다고 합니다.
MLLM Training Strategy.
Preliminary. LCB, HiRT, Robodual의 경우, upstream large model들은 모두 파인 튜닝을 수행하여 결과를 출력합니다. 저자도 이에 따라 파인 튜닝을 진행하는 방식을 수행합니다.
Setup. 해당 방식도 공평한 비교를 위해서 LCB 방법을 따릅니다: LLaVA1.0 backbone은 <ACT> token과 연결되어 있으며 CLIP Loss를 활용하여 downstream instruction에 대해 정렬하여 작업합니다. downstream policy는 앞선 섹션에서 정의된 바와 같이 전반적으로 fine-tunning을 수행합니다. MLLM과 policy model 간의 연결 과정에서 CLIP Loss 포함 여부를 변수로 도입했습니다.
Analysis. Tab 4에 따르면 MLLM이 Frozen된 상태라면 CLIP Loss 적용 여부가 성능에 크게 영향을 주지 않습니다. MLLM에 대해 추가적인 학습을 요구될 땐, CLIP Loss의 적용 여부가 매우 중요해집니다. CLIP Loss가 존재하지 않는다면, 비교적 작은 downstream model의 정보가 이미 학습된 MLLM의 conditioning과 attention을 헤치기 때문에 성능 저하를 발생 시킬 수 있습니다.
Intuitive hypothesis. 저자는 CLIP Loss가 성능을 두 시스템을 연결하는데에 큰 도움을 주지만, 학습 신호가 MLLM에 대한 일반화 능력을 헤칠 수 있다는 점을 지적합니다. frozen을 한 것과 같이 일반화 능력을 유지할 수 있지만, 동시에 downstream model로부터 업데이트 되는 효괄르 얻을 수 있는 방법이 있는가?
Further setup. 저자는 fig 3과 같이 MLLM에 대한 학습 전략만 바꾸어 실험을 진행합니다. 구체적으로 Prompt tunning을 추가적으로 적용을 진행합니다. 새로운 <ACT> token을 추가하면서 lm-head 레이어만 추가적으로 학습을 진행합니다. 해당 실험에 대한 결과는 아래 tab 5에서 볼 수 있습니다.
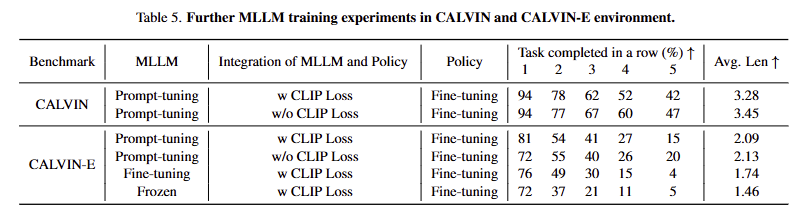
Further analysis. tab 5에서 보이는 바와 같이, prompt-tuning은 CALVIN에서 평가 결과, 성능은 다른 훈련 방식과 비슷하지만, 언어 일반화 실험(CALVIN-E)에서는 상당한 차이가 있습니다. 유사하게, CLIP 손실이 있다는 전제 하에, prompt-tuning 결과의 일반화 능력은 fine-tuning 및 frozen보다 훨씬 뛰어납니다. 더욱이 CLIP loss가 없으면 일반화가 실제로 다소 향상되는데, prompt-tuning이 일반화 능력 향상에 기여함을 보여줍니다.
Dual-System Integration Strategy.
Preliminary. 이전 실험에 따라 사전 훈련된 policy를 사용하고, prompt-tuning을 사용해 MLLM을 fine-tuning 하는 것이 좋은 결과를 가져온 다는 것을 확인 할 수 있습니다. 허나, 두 시스템을 어떻게 연결하는 것이 효과적인지가 남아 있습니다.
Setup. 두 시스템을 연결하기 위해서는 MLP projector가 요구되어집니다. 저자는 두가지 방식을 활용해 실험을 진행합니다. 1. 직접 unfreezing된 두 시스템에 MLP procjecotr도 연결하여 함께 학습하기. 2. (Pre-alignment) upstream model은 초기에 고정한 상태에서 MLP projector를 downstream small model과 함께 학습한 다음 upstream을 해제하고 같이 학습하는 방식으로 구분 됩니다. 이에 대한 결과는 tab 6에서 볼 수 있습니다.
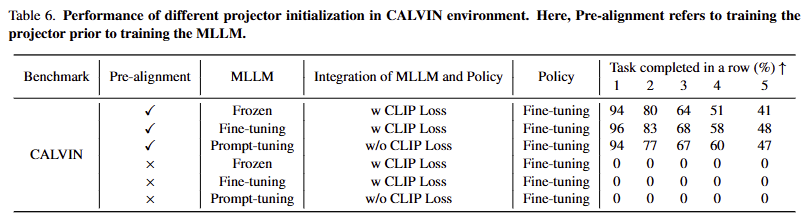
Analysis. 실험 결과, pre-alignment 없이 직접 모델을 연결하면 어떤 경우에서도 실패하는 결과를 보여줍니다. 또한, tab 2에서 보이는 바와 같이 처음부터 다시 학습을 진행해도 좋은 결과를 보여주지 않는 것을 볼 수 있습니다.
Testing strategy of dual system
Preliminary. 듀얼 시스템의 핵심은 두 시스템이 서로 비동기적 제어로 구현되어야 하는 것으로 볼 수 있습니다. LCB에서는 동기화 된 구성에서 훈련 후에 비동기 추론을 사용했습니다. HiRT에서는 훈련 중에 비동기 작업을 도입하기 위해서 추가 버퍼를 사용했습니다. Robodual은 상위 계층의 대략적인 동작을 하위 계층에서 추론된 동작으로 실시간 교체하여 비동기 작업을 수행했습니다. 여기서는 주로 첫번째 접근 방식을 검증을 진행하였고, 이외 방식은 추후 업데이트를 진행한다고 합니다.
Setup. CALVIN-D에서 1~60까지의 비동기 단계에 대한 평가를 진행합니다. 여기서 단계는 단일 MLLM 추론 단계에 동안에 action policy의 추론 단계의 길이를 나타냅니다. 3DDA의 가장 긴 단계는 60입니다.
Analysis. fig 4에서 보이는 바와 같이 재밋는 결과를 볼 수 있습니다. 대규모 모델의 추론 간 단계 수에 관계없이 성능 변화가 유사한 결과를 보여줍니다. 동적 시나리오에서 조차 일관된 결과를 보여줍니다.
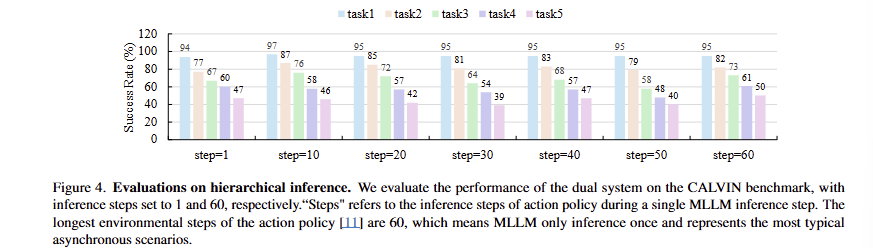
Intuitive hypothesis. 해당 결과를 토대로 현재의 MLLM이 환경 변화에 민감하지 않음을 나타낸다고 볼 수 있습니다. 직관적인 이해와 다른 분석 결과로, 저자는 이를 분석하기 위해서 상위 레이어의 특징 정보가 하위 계층으로 어떠한 정보를 전달하는지 보고자 합니다.
Further setup. MLLM으로부터 action token이 전달하는 내용을 분석하기 위해서 action token의 latent feature를 semantic space에 맵핑하고 동작에 대한 단어 간의 유사성을 계산합니다. 해당 실험에서는 파란색 블록이 지속적으로 왼쪽으로 이동하는 동적 시나리오에 대한 결과로 이는 fig 5에서 볼 수 있습니다.
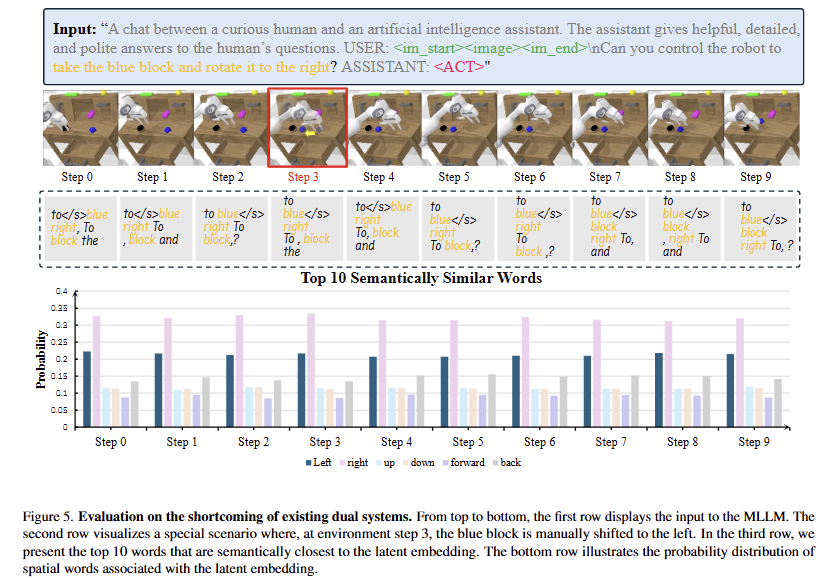
Further analysis. 1. 실험 결과, 어떤 시점에서도 공간 단어의 유사성은 로봇 팔이 왼쪽이나 오른쪽으로 이동 여부에 무관하게 “right”의 확률이 “left”보다 지속적을 높게 나타나며, 전반적인 확률 분포가 step이 지나도 동일한 것을 볼 수 있습니다. 이는 action token이 환경 변화와 무관하게 일정한 의미적 특징을 학습했음을 보입니다. “오른쪽”이 “왼쪽”보다 높은 확률을 보이는 이유는 “오른쪽”이 더 많은 의미를 담고 있기 때문 일 수 있습니다. 예를 들어 “right”은 옳음을 의미하여 더 높은 확률을 받는데에 기여 할 수 있다고 저자는 주장합니다. 2. 서로 다른 time step 별 높은 유사도를 가진 top 10 Semantically similar workds에 관련하여 나온 결과로, step에 따라 수행해야 하는 행동이나 객체의 변화를 캐치하는 것이 아니라 명령에 따른 의미를 low-level policy에 전달하는 역할만 수행하는 것으로 볼 수 있습니다.
Whether the MLLM of dual system is enough?
Preliminary. 이전 분석에 따르면 기존 방식들은 upstream의 latent feature가 downstream model이 효과적으로 작업을 수행하기 위한 latent feature를 생성하는 것이 아님을 알 수 있습니다. 저자는 이를 수행하기 위한 분석과 실험을 수행합니다.
Setup. 이전 분석에 따라 downstream model은 fine-tuning을 사용하고 pre-alignemnt 방식의 projector를 채용하고, upstream은 prompt tuning을 사용합니다. latent feature를 효과적으로 활용하기 위한 세가지 변형에 대한 실험을 진행합니다. 1. standart MLLM, 2. 시각 정보를 배재한 LLM, 3. auxiliary loss를 도입하여 생성된 latent feature에 추가적인 head layers로 action에 관련된 정보(position or rotation)을 추론하도록 세팅합니다. 해당 실험의 결과는 tab 7에서 볼 수 있습니다.
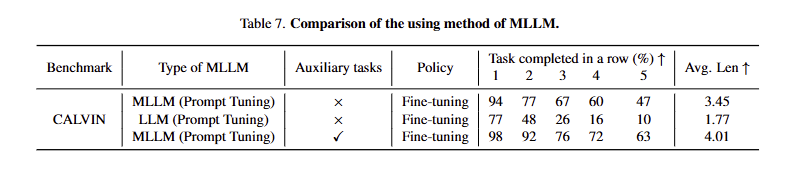
Analysis. 실험 결과, LLM만 사용하는 경우에는 MLLM보다 낮은 성능을 보입니다. MLLM이 가진 시각 인지 능력이 필요함을 보여줍니다. auxiliary loss를 추가한 경우에 성공률이 더 높아지는 경향을 보여줍니다. 이는 추가적으로 액션에 대한 정보를 추론 가능하도록 학습을 하여 시각 정보 내에 액션과 관련된 시각 정보를 포착하기를 강제하기 때문이라고 볼 수 있습니다.
A Simple yet Effective Dual System VLA
Architecture. 저자는 본 실험을 토대로 사전 훈련된 MLLM과 사전 훈련된 정책 두 가지 구성으로 모델을 설계합니다. MLLM은 텍스트 전용 large language model과 vision encoder로 구성됩니다. 사전 훈련된 정책은 비전 인코더와 Transformer 기반의 diffusion model로 구성됩니다. diffusion model은 다중 교차 어텐션 계층을 사용하여 3D scene representations, prorioception information, MLLM으로부터 condition/instruction tokens을 전달 받아 추론을 수행하는 구조로 설계되어 있습니다. 해당 연구에서는 MLLM으로 LLaVA를 활용하고, low-level policy는 사전 훈련된 diffusion policy를 활용하며 3D Diffuser Actor를 활용합니다. 또한, MLLM과 low-level policy 간의 연결을 위해서 3D Diffuser Actor의 text encoer를 대체하여 설계합니다.
Input and Output. 전반적으로 주어진 궤적 {l, (o_1, a_1)... } 을 모방하도록 학습을 진행합니다. 여기서 l은 입력 차원 d를 가진 N의 특정 작업에 대한 언어 명령을 나타내고, o_t와 a_t는 각 time step t에서의 시각적 관찰과 로봇 동작을 의미합니다. o_t는 서로 다른 시점에서 얻은 2 개의 RGB-D 이미지로 구성됩니다. a_T는 말단 장치의 자세를 정의하며, 3D position, rotation, gripper onoff에 해당합니다.
Training.
Prompt Tuning. MLLM의 성능 저하를 방지하기 위해서 전체를 freezing을 수행하고 언어 명령어 l의 끝에 학습 가능한 학습 임베딩으로 <ACT>에만 학습 신호를 전달합니다.
Multimodal Reasoning Learning. MLLM이 시각적 추론 능력을 충분하게 활용하지 못하기 떄문에 대형 MLLM 모델의 출력을 CLIP의 텍스트 인코더에 맞도록 구성합니다. 먼저, 제 연봉이 얼마인지 궁급합니다.
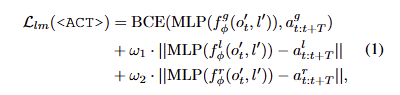
Diffusion Learning. diffusion을 활용한 이전 연구에 따라 action denoising objective를 활용합니다. 학습 중 우리는 간단하게 time step t에 맞게 작업을 수행합니다. 전반적인 구조는 다음과 같으며 3D Diffuser Actor를 따르는 loss항을 이용하여 학습을 진행합니다.
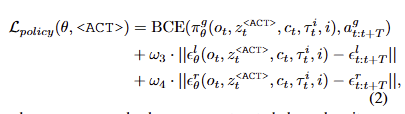
Two stage training. 이에 따라 첫 번째 단계에서는 MLLM에서 생성된 임베딩을 사전학습된 policy에 정렬하기 위해서 대형 모델과 Low-level policy 파라미터를 고정하고 prompt 및 projection layer를 학습 시킵니다. 두 번째 단계에서는 대형 모델을 고정 상태로 유지하고 low-level policy를 함께 미세 조정을 수행합니다.
Implementation Details. 저자는 LLaVA-7B와 3D Diffuser Actor를 기반으로 사용합니다. 학습 동안 2k iter동안은 정렬을 수행하고 100k iter 동안은 prompt tuning과 low-level policy를 학습합니다.
Experiment
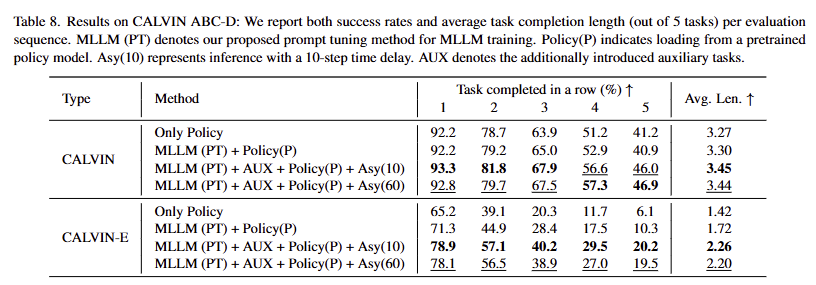
실험적인 결과, auxiliary loss를 추가하고, 비동기 스텝 Asy(10)으로 설정했을 떄, 가장 좋은 성능을 보여주고 있습니다.
—-
해당 페이퍼에서는 SOTA 모델들과 직접 비교하진 않았지만, git에서는 다음과 같이 비교한 실험 테이블이 존재합니다.
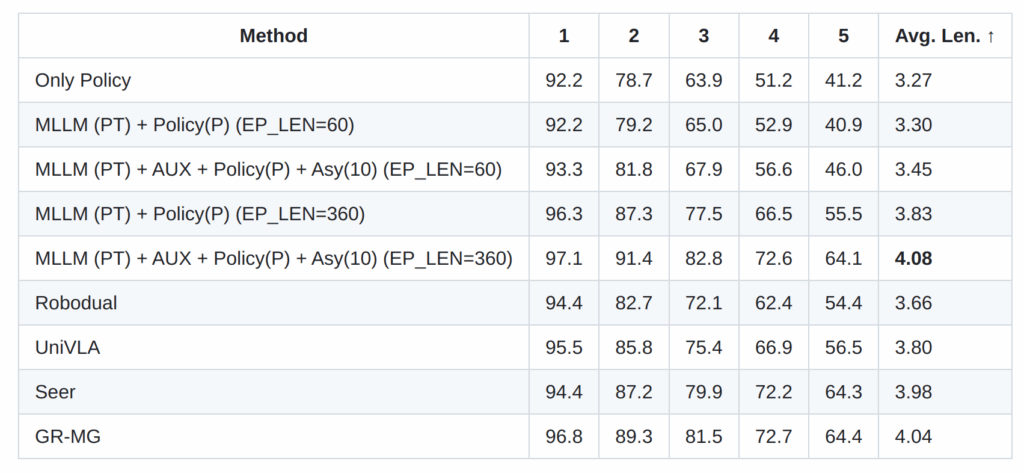
해당 테이블에서 보이는 바와 같이 CALVIN에서 2025년도 기준 SOTA를 달성한 UniVLA와 Seer, GR-MG를 웃도는 실험 결과를 보여줍니다.
+ EP_LEN이 어떤 차이인지는 readme.md에 있지 않아서 추가적으로 찾아봐야겠습니다.
References
[1] Zitkovich, Brianna, et al. “Rt-2: Vision-language-action models transfer web knowledge to robotic control.” Conference on Robot Learning. PMLR, 2023.
[2] Shentu, Yide, et al. “From llms to actions: Latent codes as bridges in hierarchical robot control.” 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024.
[3] Moritz Reuss, Hongyi Zhou, Marcel Rühle, Ömer Erdinç Ya˘ gmurlu, Fabian Otto, and Rudolf Lioutikov. Flower: Democratizing generalist robot policies with efficient visionlanguage-action flow policies. In 7th Robot Learning Workshop: Towards Robots with Human-Level Abilities . 3
[4] Bu, Qingwen, et al. “Towards synergistic, generalized, and efficient dual-system for robotic manipulation.” arXiv preprint arXiv:2410.08001 (2024).
[5] Gong, Zhefei, et al. “Carp: Visuomotor policy learning via coarse-to-fine autoregressive prediction.” arXiv preprint arXiv:2412.06782 (2024).
[6] Su, Yue, et al. “Dense policy: Bidirectional autoregressive learning of actions.” arXiv preprint arXiv:2503.13217 (2025).
[7] Liu, Haotian, et al. “Visual instruction tuning.” Advances in neural information processing systems 36 (2023): 34892-34916.
[8] Ke, Tsung-Wei, Nikolaos Gkanatsios, and Katerina Fragkiadaki. “3d diffuser actor: Policy diffusion with 3d scene representations.” arXiv preprint arXiv:2402.10885 (2024).
[9] Li, Xinghang, et al. “Vision-language foundation models as effective robot imitators.” arXiv preprint arXiv:2311.01378 (2023).
안녕하세요 태주님 리뷰 감사합니다.
저도 최근들어 VLA의 작동 원리에 대해 좀 더 알고싶어서 논문을 막 찾아서 읽기 시작했는데요, 이제 막 마구잡이로 지식을 넣는중에 궁금했던 내용들이 있어서 질문이 맞는 질문인지 정확하게는 모르겠습니다 하하,,
1. pi-zero는 살펴보지 못했지만, GROOT-N1의 경우 DiT에서 state와 noisy한 action을 입력으로 받고, 여기에 VLM의 output으로 얻은 ViT 기반 이미지 토큰과, 토큰화된 language instruction을 함께 cross-attention하여 최종 action을 산출한다고 이해했습니다. 전반적으로 dual-system VLA들도 이와 유사한 구조를 가진 것으로 알고 있습니다. 다만 GR00T-N1에도 figure에는 system1, system2로 구분이 명시되어 있지 않고, 저자 역시 dual-system VLA로 정의하지는 않았습니다. 그런데 글을 읽고도 dual-system VLA과의 핵심 차이가 명확하지 않아서 어떤 부분이 핵심 차이인지 궁금합니다.
2. Latent Feature Representation Selection이라는 것을 저자가 가장 강하게 어필하셨다고 말씀해주셨는데요, 이 부분이 VLM과 policy 담당 모듈이 지식을 공유하게 되는(?) 부분인가요? 이 latent feature representation도 VLM이나 policy 담당하는 네트워크와 다같이 학습하는 구조인지 궁금합니다.
3. 실험 부분을 보면서 이해한건 결국 dual system VLA의 policy적인 부분(DiT나 Flow 기반 등등)의 성능은 많이 차이가 없고 심지어 static 한 태스크에서는 단일 VLA들도 준수한 성능을 보이기 때문에 결국 VLM을 어떻게 학습시키고 policy 부분에 지식을 어떻게 잘 전달하느냐가 핵심이라고 크게 이해했는데, 제가 이해한 흐름이 맞을까요?
1. pi-zero는 살펴보지 못했지만, GROOT-N1의 경우 DiT에서 state와 noisy한 action을 입력으로 받고, 여기에 VLM의 output으로 얻은 ViT 기반 이미지 토큰과, 토큰화된 language instruction을 함께 cross-attention하여 최종 action을 산출한다고 이해했습니다. 전반적으로 dual-system VLA들도 이와 유사한 구조를 가진 것으로 알고 있습니다. 다만 GR00T-N1에도 figure에는 system1, system2로 구분이 명시되어 있지 않고, 저자 역시 dual-system VLA로 정의하지는 않았습니다. 그런데 글을 읽고도 dual-system VLA과의 핵심 차이가 명확하지 않아서 어떤 부분이 핵심 차이인지 궁금합니다.
A1. GR00T-N1은 VLM과 action head가 하나의 흐름을 가지는 구조를 가집니다. 이에 반하여 Dual-system VLA는 VLM과 action head가 비동기적으로 처리된다는 점이 가장 큰 차이라고 보시면 됩니다.
======================================
2. Latent Feature Representation Selection이라는 것을 저자가 가장 강하게 어필하셨다고 말씀해주셨는데요, 이 부분이 VLM과 policy 담당 모듈이 지식을 공유하게 되는(?) 부분인가요? 이 latent feature representation도 VLM이나 policy 담당하는 네트워크와 다같이 학습하는 구조인지 궁금합니다.
A2. 넵, VLM과 Policy가 서로 같은 표현을 가지도록 하는 부분이라고 보시면 됩니다. 그렇기에 해당 부분을 어떻게 모델링 혹은 학습 파이프라인을 구축하나에 따라서 성능 영향이 크게 달라질 것 이라고 봅니다. 같이 학습 하는 부분이라고 봐도 무방합니다.
==============================
3. 실험 부분을 보면서 이해한건 결국 dual system VLA의 policy적인 부분(DiT나 Flow 기반 등등)의 성능은 많이 차이가 없고 심지어 static 한 태스크에서는 단일 VLA들도 준수한 성능을 보이기 때문에 결국 VLM을 어떻게 학습시키고 policy 부분에 지식을 어떻게 잘 전달하느냐가 핵심이라고 크게 이해했는데, 제가 이해한 흐름이 맞을까요?
A3. 흠.. 해당 부분은 다른 핀트로 보신 것 같아요. static 파트에서는 비동기 연산의 중요성을 강하게 어필했고, 지식을 어떻게 잘 전달할지는 부가적인 포인트라고 이해하시면 좋을 것 같습니다.
안녕하세요 태주님, 좋은 리뷰 감사합니다!
아직 VLA에 대한 지식이 전무한 저에게는 꽤 어려운 내용일 것이라 생각했는데요. 그래도 세미나 때 발표해주신 내용이 굉장히 흥미로워서 나름대로 열심히 읽어보았습니다.
Q1. 기존 dual-system VLA에서 MLLM이 시각적 정보(localization이나 dynamic한 변화)를 downstream에 잘 전달하지 못하는 것으로 이해했습니다. 관련해서 Fig. 5에 드러난 실험이 인상깊었는데요, 이 현상이 MLLM이 구조적으로 텍스트-이미지의 전체적인 의미를 global하게 임베딩하는 방식 때문인가요? 구조적 원인 외 추가적인 요인이 있는지 궁금합니다. 임베딩만을 학습하는 것이 prompt-tuning이고, 이 에 MLP 헤드를 붙여 행동 요소를 예측하도록 하는 것이 auxiliary task라고 이해했습니다. 제가 이해한 바가 맞나요?
Q2. 제가 이해한 바에 따르면 MLLM의 파라미터를 frozen하여 일반화 능력은 유지하면서
Q3-1. MLLM이 시각적 정보를 잘 반영하지 못한다는 문제점의 대안으로 나온 것이 auxiliary task인데, L_lm을 통해 엔드 이펙터의 위치/회전, 그리퍼의 상태 정보를 예측하도록 학습하고 있습니다. 이를 통해 올바른 행동 예측을 유도한다는 것은 이해가 되는데, 이게 왜 시각 정보를 활용하도록 강제하는 것이 되나요? 제가 생각한 시각 정보는 픽셀, 박스, 마스크와 같은 직접적인 형태인지라 이런 궁금증이 들었습니다.
Q3-2. 이런 직접적인 시각 정보를 추가로 활용하는 연구도 있는지 궁금합니다.
감사합니다.
Q1. 기존 dual-system VLA에서 MLLM이 시각적 정보(localization이나 dynamic한 변화)를 downstream에 잘 전달하지 못하는 것으로 이해했습니다. 관련해서 Fig. 5에 드러난 실험이 인상깊었는데요, 이 현상이 MLLM이 구조적으로 텍스트-이미지의 전체적인 의미를 global하게 임베딩하는 방식 때문인가요? 구조적 원인 외 추가적인 요인이 있는지 궁금합니다.
A1. 해당 실험에서 활용된 MLLM의 목적은 text로 답변을 하는 것이 목적입니다. 허나, Policy는 action에 대해서 임베딩된 정보를 요구하게 되죠. 즉, 다른 목적을 가진 모델을 다른 목적으로 끌고가야하기 때문에 잘 못하고, 더 나아가 large-scale로 학습한 모델이기에 모델의 이점을 유지하면서 변경하기가 어려운거죠.
===================================
Q2. 제가 이해한 바에 따르면 MLLM의 파라미터를 frozen하여 일반화 능력은 유지하면서 임베딩만을 학습하는 것이 prompt-tuning이고, 이 에 MLP 헤드를 붙여 행동 요소를 예측하도록 하는 것이 auxiliary task라고 이해했습니다. 제가 이해한 바가 맞나요?
A2. 넵 맞습니다.
==============================
Q3-1. MLLM이 시각적 정보를 잘 반영하지 못한다는 문제점의 대안으로 나온 것이 auxiliary task인데, L_lm을 통해 엔드 이펙터의 위치/회전, 그리퍼의 상태 정보를 예측하도록 학습하고 있습니다. 이를 통해 올바른 행동 예측을 유도한다는 것은 이해가 되는데, 이게 왜 시각 정보를 활용하도록 강제하는 것이 되나요? 제가 생각한 시각 정보는 픽셀, 박스, 마스크와 같은 직접적인 형태인지라 이런 궁금증이 들었습니다.
A3-1. 이를 이해하려면 기존 MLLM이 학습하는 방식에 대해서 이해를 해야합니다. 대체로 기존 MLLM은 액션에 대한 학습을 수행하지 않습니다. 그렇기에 저자는 시각적인 정보를 기반으로 액션을 예측하도록 강제하는 것이죠.
===========================
Q3-2. 이런 직접적인 시각 정보를 추가로 활용하는 연구도 있는지 궁금합니다.
A3-2. MLLM이 시각적인 정보를 활용하여 물리적인 추론을 하도록 강제하는 연구들은 RT-1, RT-2, RoboFlamingo, DreamVLA 등등 꽤나 많습니다.