1. Introduction
이번에 소개드릴 논문 역시 Text-Video Retrieval 연구 논문입니다. Text-Video Retrieval은 서로 다른 두 모달리티를 연결하는 cross-modal alignment의 응용이라 볼 수 있습니다. 이 태스크는 텍스트 쿼리 또는 비디오 쿼리가 주어졌을 때, 해당 쿼리와 가장 관련성이 높은 비디오나 텍스트를 찾아내는 것을 목표로 합니다.
비디오 같은 경우 여러 프레임의 집합으로 볼 수 있기 때문에 기본적으로 비주얼과 텍스트 매칭을 기본 요소로 한다 볼 수 있습니다. 따라서 최근 연구에서는 대규모 이미지-텍스트 데이터로 사전 학습된 CLIP 모델을 활용하는 경우가 많습니다. CLIP을 비디오 도메인으로 확장한 대표적인 연구로는 CLIP4Clip이 있습니다. 이 방법론은 비디오를 프레임 단위로 샘플링한 뒤, 각 프레임에서 추출한 특징을 평균 풀링(mean-pooling)하여 하나의 비디오 특징으로 사용하거나, temporal fusion 모듈에 입력해 비디오 시간적인 요소를 고려한 방식을 제안했습니다.
이후 연구에서는 비디오와 텍스트 간의 더 많은 대응관계를 학습하기 위해 프레임을 패치 단위로 나누거나 문장을 단어 단위로 분해하는 등 보다 세밀한 정렬(fine-grained alignment)을 고려하기 시작했습니다. 그러나 기존 연구 대부분은 coarse-grained alignment 또는 fine-grained alignment 중 한 가지만 다루는 경향이 있었으며, 두 가지를 모두 통합적으로 고려한 연구는 부족했습니다.
그래서 저자는 이를 문제 삼아 coarse-grained, fine-grained alignment를 모두 고려할 수 있는 방법론을 제안합니다.
저자의 방법론은 전체 비디오와 쿼리 문장간의 coarse-grained 정렬로 시작해서, 개별 비디오 프레임과 쿼리 문장 매칭을 하는 프레임-문장 정렬, 더 나아가 비디오 패치와 쿼리 단어 간의 정렬을 수행하는 fine-grained 정렬을 추가하여 비디오와 텍스트간의 alignment를 맞춰줍니다.
그러나 이러한 multi-grained 학습은 더 다향하고 세부 정보를 제공할 수 있다는 장점이 있지만 cross-modal alignmenet 에서는 일부 관련이 없는 정보까지 포함될 수 있습니다. 예를 들어, 비디오의 여러 프레임에는 쿼리와 관련된 정보가 없을 수도 있고, 프레임의 일부 패치는 관련 없는 배경 정보에 해당할 수 있습니다.
이러한 문제를 해결하기 위해 저자는 ISA (Interactive Similarity Aggregation) 모듈을 제안합니다. ISA 모듈은
그래서 최종적으로는 multi-grained의 각 레벨에서 유사도 점수를 얻고 이를 합산하여 최종 유사도 점수를 얻습니다. 하지만 저자의 실험 결과에 따르면 어떤 특정 비디오는 모든 텍스트와 비교했을 때 항상 유사도 점수가 비슷하게 나오는 경우가 있다고 합니다.
이걸 논문에서는 marginal similarity 라고 부르는데, 예를 들면 비디오 A는 내용이 모호해서 여러 텍스트랑 의미가 웬만큼 맞아 떨어진다면 비디오 A의 marginal similarity가 지나치게 높게 측정될 수 있습니다. 그렇게 되면 어떤 텍스트가 입력으로 주어지든, 모델은 계속해서 비디오 A를 선택하게 되고, 정답인 다른 비디오에 대해서는 선택될 확률이 낮아질 수 있습니다. 그래서 저자는 이를 해결하고자 점수를 합산하기 전 이러한 불균형을 보정하기 위해 Sinkhorn-Knopp 알고리즘을 활용하여 유사도 점수를 정규화하고, 각각의 비디오에 대해서 marginal similarity를 동일하게 하여 비디오가 검색될 기회를 비슷하게 맞춰주는 작업을 추가해줬습니다.
2. Method
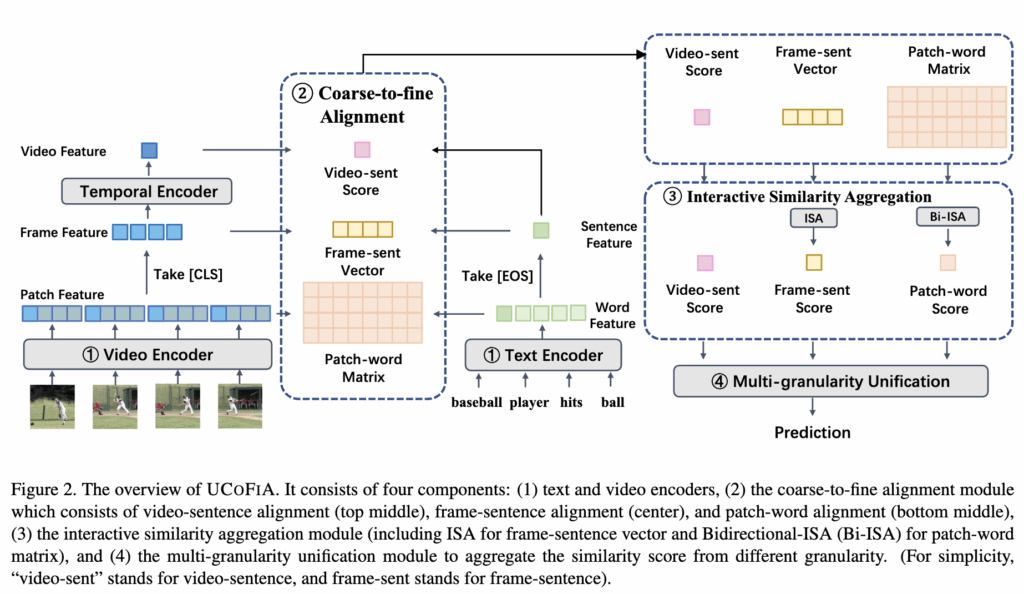
그럼 이제 방법론에 대해 살펴보겠습니다. 먼저 저자가 제안하는 UCOFIA 모델의 아키텍쳐는 그림2에 나와있습니다. 구성 요소로는 크게 4가지가 있고, 1, 텍스트, 비디오 인코더, 2 coarse-to-fine Alignment 모듈, 3 Interactive Similarity Aggregation 모듈, 4 Sinkhorn-Knopp 알고리즘으로 구성되어 있습니다.
먼저 모델의 아키텍쳐 파이프라인에 대해 정리하면, 첫 번째로 비디오,텍스트 인코더를 통해 multi-grained 특징을 추출하고,이 multi-grained 특징을 다양한 level에서 cross-modal similarity를 계산하는 Coarse-to-fine Alignment에 입력된 다음 Interactive Similarity Aggregation 모듈에서 유사도를 합치고 조합하는 과정을 거칩니다. 마지막으로 Sinkhorn-Knopp 알고리즘을 사용해 최종 유사도를 얻는 방식으로 동작합니다.
2.1. Feature Extraction
Text Encoder
텍스트 쿼리 T가 주어지면, CLIP 텍스트 인코더(Ft)를 활용하여 단어 특징(w)을 출력합니다.
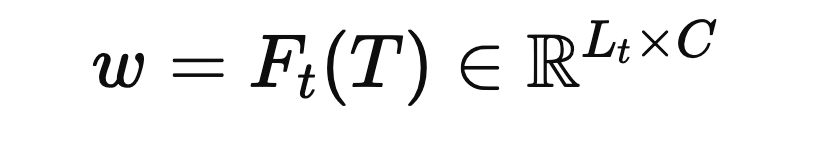
그런 다음 [EOS] 토큰의 특징을 문장 특징으로 사용합니다.
Video Encoder
비디오 인코더도 마찬가지로 사전 학습된 CLIP의 비주얼 인코더 (Fv)를 활용하여 각 비디오의 비주얼 특징을 추출합니다.
N개의 프레임을 가진 비디오는 (V = [F_1, F_2, …, F_N])으로 나타낼 수 있고,
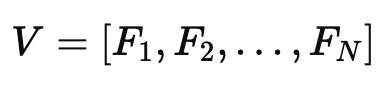
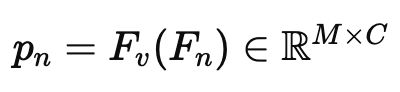
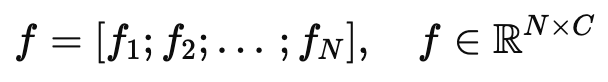
비디오 (F_n)의 n번째 프레임이 주어지면, 이를 패치로 나누고, [CLS] 토큰을 추가하여, 비전 인코더 (Fv)에 입력하여 패치 특징 (p_n)을 얻습니다. 이후 각 프레임의 [CLS] 특징을 결합하여 프레임 특징 (f = [f_1; f_2; …; f_N])를 얻습니다.
하지만 CLIP의 비주얼 인코더는 각 프레임을 독립적으로 처리하기 때문에 서로 다른 프레임 간의 시간 정보는 학습할 수 없습니다. 그래서 저자는 이를 보완하고자 이전 연구(TS2-Net)를 참고하여 시간 정보를 학습할 수 있도록 모델의 마지막 두 transformer 블록에서 인접한 프레임에서 각 프레임의 토큰을 이웃한 프레임으로 조금 씩 이동시켜 줍니다. 이를 통해서 추가적인 모듈 없이 적은 cost로 프레임 간 시간 정보를 학습할 수 있도록 해주었습니다.
2.2. Coarse-to-fine Alignment
저자가 제안하는 coarse-to-fine 정렬 모듈은 coarse한 정렬이나 fine-grained 정렬만 고려하는 단점을 보완하고자 multi-grained level로 cross-modal 유사도를 계산합니다.
먼저 Video-sentence Alignment의 경우 비주얼 인코더에서 각 프레임의 특징 f를 추출한 후에 temporal encoder에 입력하여 하나의 비디오 특징 v를 추출합니다. 이후 비디오 v와 문장 특징 s의 유사도를 계산해 video-sentence similarity score sVS 얻습니다.
다음 Frame-sentence Alignment는 단순하게 프레임 특징 f와 문장 특징 s간의 유사도를 계산해 frame-sentence similarity vector cFS 를 추출합니다.
마지막 Patch-word Alignment는 패치와 단어 level로 정렬을 맞춰줍니다. 하지만 이때 모든 패치들에 대해 유사도를 계산하는 것을 비효율적이고 중복되는 패치들도 많기 때문에 MLP로 구성된 patch selection module H를 추가하여 top-k개의 중요한 패치만 선택하여 유사도를 계산합니다. 식으로 살펴보면 아래와 같습니다.
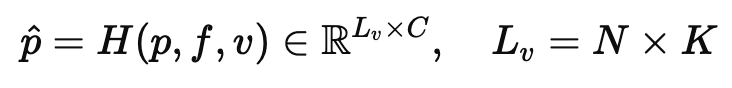
P,f,v 는 각각 프레임의 모든 패치 특징, 프레임 특징 , 비디오 특징을 의미하고 N은 프레임 개수, K는 top-k의 개수를 의미합니다. 그래서 모듈 H에 패치뿐만 아니라 프레임 단위, 비디오 단위 정보도 함께 입력하여 패치가 얼마나 중요한지를 판단하여 top-k개의 패치만 선택합니다. 이렇게 선택된 패치들에 대해서 문장의 단어 특징 벡터와 유사도를 계산해 Patch-Word Similarity Matrix (CPW)를 얻게됩니다.
2.3 Interactive Similarity Aggregation
다음으로는 여러 level에서 계산한 유사도 벡터,행렬을 하나로 합치는 방법에 대한 설명입니다. 비디오의 특징은 프레임간의 중복된 정보들이 많기 때문에 모든 프레임 또는 패치를 단순히 평균하거나 가중합하면 쓸모없는 정보까지 포함될 수 있습니다. 기존 방법들에서는 관련 없는 정보의 영향을 줄이기 위해서 frame-sentence 유사도 벡터 cFS에 softmax로 가중합하여 하나의 값으로 합쳐주었습니다. 하지만 이렇게 되면 프레임간의 상호작용은 고려하지 못하고 시간 정보 또한 고려할 수가 없습니다. 그래서 저자는 프레임간의 관계 또한 고려하기 위해서 interactive similarity aggregation module (ISA)을 제안합니다. ISA 모듈은 먼저 Frame-sentence Alignment에서 계산한 유사도 벡터 cFS에 softmax를 적용하여 관련성을 계산합니다. 이후 linear layer Ti를 적용하여 벡터 내의 모든 원소 간 상호작용을 고려해서 새로운 가중치 벡터를 추출합니다. 마지막으로 여기에 softmax를 거쳐 최종 유사도 벡터를 추출하고 원래 유사도 벡터에 곱해 최종 유사도 점수를 구합니다. 이를 수식으로 표현하면 다음과 같습니다.
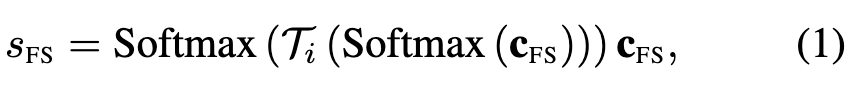
여기서 sFS는 텍스트 쿼리와 비디오 후보 간의 프레임-문장 유사도 점수를 나타냅니다.
방금까지 프레임-문장 유사도 점수를 구했다면,여기에 확장하여 패치-단어의 유사도 행렬에도 확장하여 ISA 모듈을 적용시킬 수 있습니다.
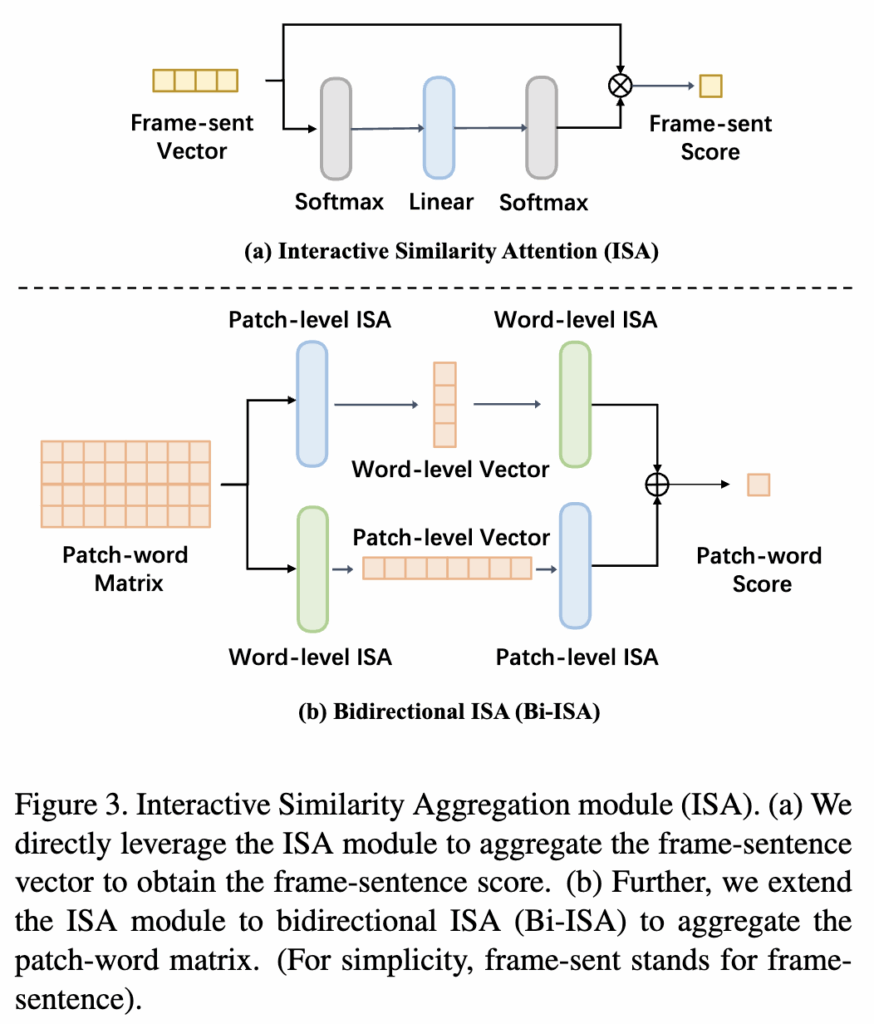
위 그림3(b)에서 보이는 것처럼 먼저 유사도 행렬의 각 행(row), 열(column)을 유사도 벡터로 분리한 뒤, 각 벡터에 ISA 모듈을 적용합니다. 그 후, 각 벡터에서 얻은 유사도 점수들을 다시 하나의 벡터로 aggregate 한 뒤, 또 다른 ISA 모듈을 적용하여 최종 patch-word 유사도 점수를 얻습니다.
여기서 aggregate을 할 수 있는 방식은 두 가지가 있습니다. 첫 번쨰는 Patch → Word 순서 방식입니다. 이는 먼저 patch-word similarity 행렬에서 각 패치(row)마다 유사도 벡터를 만들어 ISA 모듈 적용하고, 그 다음 모든 패치 결과를 합쳐서 최종 patch→word 유사도 점수를 계산하는 방식입니다.
두 번째 Word → Patch 순서는 각 단어(column)마다 유사도 벡터를 만들어 ISA 모듈 적용하고 그 다음, 모든 단어 결과를 합쳐서 최종 word→patch 유사도 점수계산하는 방식입니다. 쉽게 말해 패치 기준에서 단어 유사도를 계산할꺼냐 아님 단어 기준에서 패치 유사도를 계산할꺼냐의 차이라고 이해하시면 됩니다.
저자에 따르면 이 두가지 방식을 모두 사용해 Aggregation 하는 것이 성능 향상에 도움이 되었다고 합니다. 그래서 저자는 이 두 가지 방식을 모두 사용하는 것을 Bi-ISA (bi-directional ISA module) 이라 정의하였습니다.
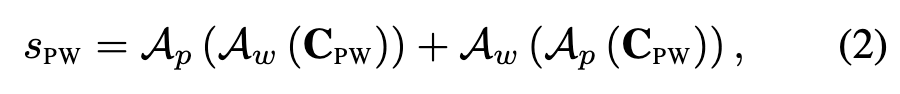
그래서 이를 수식으로 살펴보면 먼저 Bi-ISA 모듈은 패치와 단어 사이의 유사도를 나타내는 patch-word 유사도 행렬(CPW)을 입력으로 받고, patch-level ISA module(Ap)을 patch-word matrix(CPW)의 각 행(row)에 적용합니다. 각 행은 특정 패치와 모든 단어 간의 유사도를 나타내므로, 이를 통해 각 패치에 대한 word-level similarity vector를 얻을 수 있습니다.
이렇게 얻은 word-level similarity vector에 word-level ISA module(Aw)을 다시 적용하여 최종적으로 Patch-then-Word 유사도 점수를 계산합니다.
위와 반대로, 먼저 word-level ISA module(Aw)을 patch-word matrix(CPW)의 각 열(column)에 적용합니다. 각 열은 특정 단어와 모든 패치 간의 유사도를 나타내므로, 이는 각 단어에 대한 patch-level similarity vector를 얻을 수 있습니다.
이렇게 얻은 patch-level similarity vector에 patch-level ISA module(Ap)을 다시 적용하여 최종적으로 Word-then-Patch 유사도 점수를 계산합니다.
이 두 가지 방향으로 얻은 점수를 합산하여 최종 patch-word similarity score(sPW)를 얻습니다
2.4. Unifying Coarse and Fine-grained Alignment
UCOFIA 모델은 video-sentence, frame-sentence, patch-word의 세 가지 alignment level에서 유사도 점수를 계산합니다.
이 점수들은 각각 (SVS), (SFS), (SPW)라는 유사도 행렬로 표현되며, G개의 비디오와 H개의 쿼리에 대해 모든 가능한 조합에 대한 유사도를 포함합니다. 여기서 Sij는 i번째 비디오와 j번째 쿼리에 대한 점수입니다.
일반적으로 cross-modal retrieval의 마지막 단계에서는 이러한 여러 level의 유사도 점수를 직접 평균하여 최종 검색 유사도를 얻습니다. 하지만 저자에 따르면 각 alignment level의 유사도 행렬에서 비디오 간의 점수가 매우 불균형하다는 것을 발견했다고 합니다. 이는 특정 비디오와 모든 텍스트 간의 유사도 합계(marginal similarity)가 다른 비디오의 합계보다 훨씬 높을 수 있다는 것을 의미합니다. 이러한 문제는 특정 비디오가 over-represented되어 다른 비디오가 retrieval 될 수 있는 확률을 낮추는 문제를 가지고 있습니다.
그래서 저자는 Sinkhorn-Knopp algorithm을 활용하여 이러한 불균형 문제를 해결하고자 합니다.
먼저, 테스트 쿼리가 한 번에 하나씩 주어지는 것을 가정하고, 테스트 세트의 분포를 근사하기 위해 학습(train) 쿼리 세트를 활용합니다. 이를 통해 테스트 비디오의 편향(bias)을 계산할 수 있습니다.
text-to-video retrieval의 경우를 예로 들어 설명하면, 먼저 G개의 테스트 비디오와 J개의 학습 쿼리가 있다고 가정합니다. 여기서 Sinkhorn-Knopp 알고리즘은 반복해서 test video bias α 와 training text bias β 를 계산합니다. 그리고 여기서 training text bias β는 실제 테스트 쿼리가 아닌 학습 쿼리에 기반하기 때문에 추론시에는 사용이 안되고, test video bias α만 사용합니다.
실제 테스트 단계에서는 G개의 테스트 비디오와 H개의 테스트 쿼리로 구성된 유사도 행렬 S를 얻고, 여기에 이전에 계산한 α를 더하여 유사도 행렬을 정규화합니다. 수식으로 표현하면 다음과 같습니다.
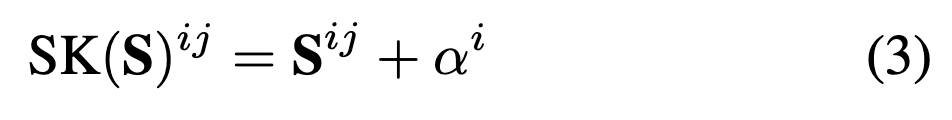
여기서 Sij는 i번째 비디오와 j번째 쿼리 간의 원래 유사도 점수이고 αi는 i번째 비디오에 대한 test video bias입니다.
그리고 저자가 제안하는 모델은 세 가지 level에서(video-sentence, frame-sentence patch-word) 유사도 점수를 계산하기 때문에 각 유사도 행렬 (SVS), (SFS), (SPW)에 대해 정규화를 먼저 적용한 후, 이들을 합산하여 최종 유사도 점수 (R)을 계산합니다.
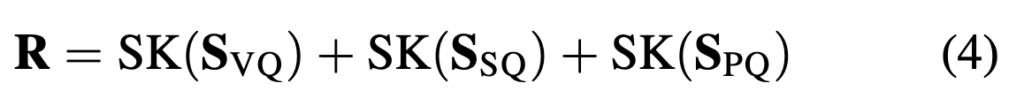
3. Experimental
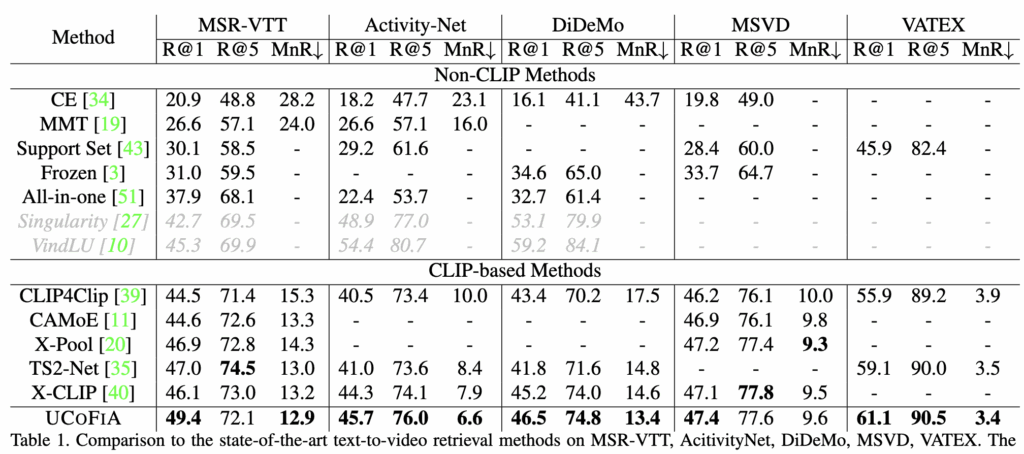
표 1에서는 UCOFIA를 다섯 가지 video-text retrieval datasets에서 비교 실험을 진행하였습니다. MSR-VTT에서는 multi-level alignment을 사용하는 X-CLIP과 비교했을 때, R@1 메트릭에서 3.3%의 성능 향상을 보였습니다. 또한 VATEX 데이터셋 에서도 R@1에서 2.0%의 개선된 모습을 보였습니다.
마찬가지로 ActivityNet, DiDeMo 데이터셋에서 CLIP4Clip에 비해 5.2%, 4.7%의 성능 향상을, X-CLIP에 비해 1.4% ,1.3%의 성능 향상을 보였습니다.
Ablation study
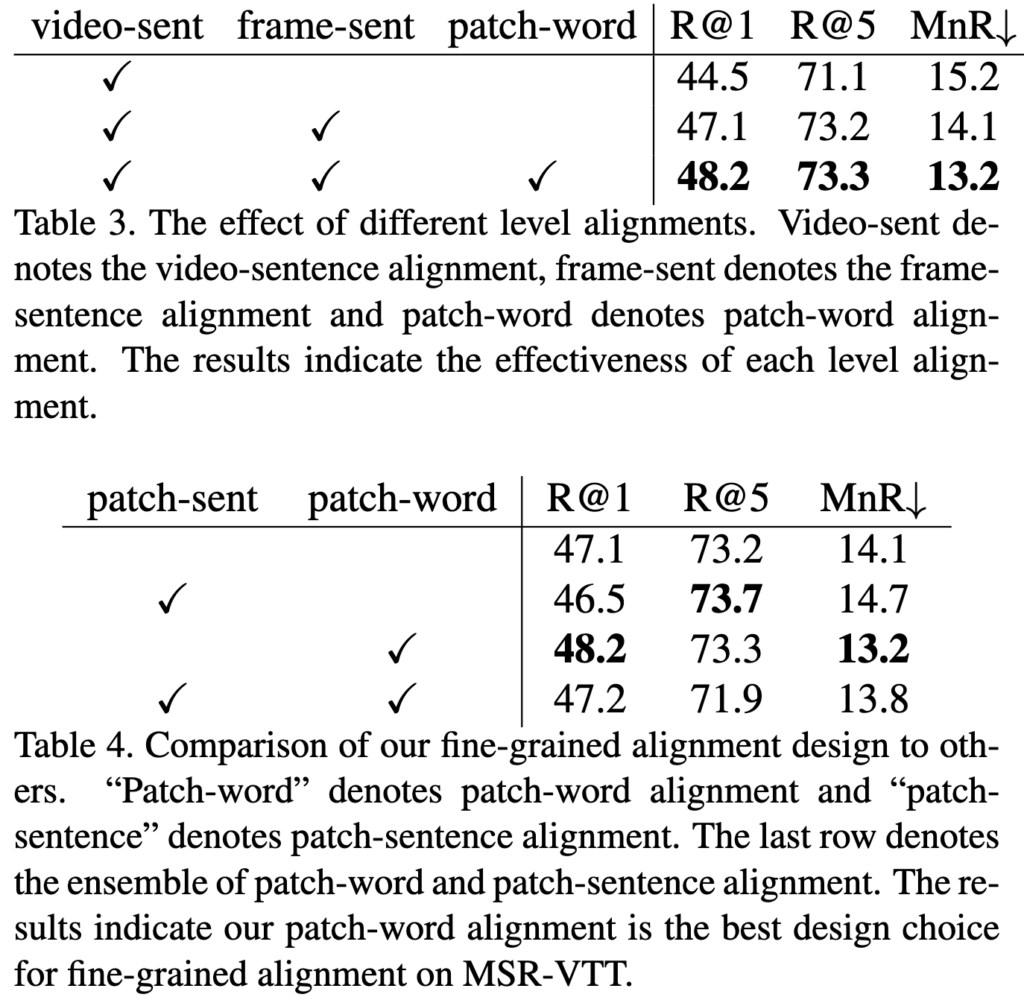
다음으로 Ablation study 결과를 살펴보겠습니다. 먼저 서로 다른 정렬 방식의 효과에 대해 살펴본 결과는 표3에 나와있습니다. 기본적으로 비디오-문장 정렬만 사용한 모델에 프레임-문장 정렬과 패치-단어 정렬을 추가하면 성능이 크게 향상하는 모습을 보였습니다. 특히 패치-단어 정렬은 R@1 성능을 크게 개선하면서도 R@5 성능은 유지했는데, 이를 통해 더 세밀하게 정렬할수록 더 적합한 비디오를 찾아낼 수 있음을 알 수 있습니다.
그리고 표4에서는 패치-단어 정렬을 패치-문장 정렬 또는 패치-단어 정렬과 같은 다른 조합으로도 실험을 진행했는데 이러한 경우 두 특징이 담고 있는 정보가 다르기 때문에 성능이 하락하는 모습을 보였습니다.
Different Similarity Aggregation Methods
마지막으로 UCOFIA의 similarity aggregation methods에 대한 ablation 결과를 살펴보고 마무리 하겠습니다
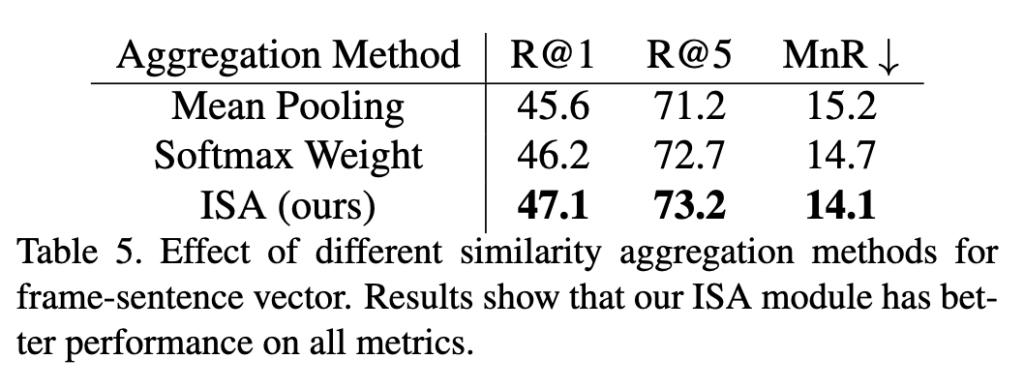
먼저 ISA (Interactive Similarity Attention)는 앞서 프레임-문장 정렬에서 사용된 모듈이었는데, 이를 mean pooling, softmax-based weighted 방법과 비교 실험을 진행했습니다. 결과는 ISA를 적용했을 때 가장 좋은 성능을 보였고, 단순 mean pooling이나 softmax를 사용하는 것 보다 프레임과 문장 간의 상호작용을 학습하는 것이 효과적이라는 것을 알 수 있습니다.

그리고 Bi-ISA는 패치-단어 정렬에 적용되는 모듈입니다. 실험에서는 이미 ISA를 적용한 상태에서, 패치-단어 정렬에 대해 Bi-ISA와 다른 방법들을 비교했습니다. 여기서도 마찬가지로 Bi-ISA 모듈이 다른 방법들보다 성능 향상에 도움이 되는 것을 확인할 수 있고, Patch-Word Matrix와 같이 더 복잡한 구조의 유사도에 대해 양방향으로 학습하는 것이 효과적임을 알 수 있습니다
안녕하세요 리뷰 잘 읽었습니다.
중간에 Sinkhorn-Knopp 알고리즘을 왜 적용하고자 하는것인지까진 이해하였는데, 알고리즘이 결국 특정 셋에 대한 bias를 어떻게 구한다는것인가요? 테스트 비디오 G개, 학습 텍스트 쿼리 J개 중엔 서로 짝이 없는 샘플들도 많을텐데 무엇에 대한 편향을 반복적으로 계산하는것인지 궁금합니다.
안녕하세요 현우님 질문 감사합니다.
먼저 테스트 비디오 G개, 학습 텍스트 쿼리 J개 가 있을때, 이 둘의 유사도 행렬 S(G*J)을 구합니다.
Sinkhorn-Knopp을 적용시키는 목적은 이 유사도 행렬 S이 균형을 이루도록 스케일링 계수 α,β를 구하는 것이고, 나중에 테스트 비디오 G개, 테스트 텍스트 쿼리 H를 통해 구한 유사도에 편향 α만 더해 normalization에 활용합니다.
그럼 Sinkhorn-Knopp 알고리즘을 α,β를 구하는 과정에 대해 설명드리면, 먼저 유사도 행렬 S를 지수화해서
L을 만들어줍니다. 그리고 L의 각열의 합을 구하고 이것에 역수를 취해 텍스트 스케일링 벡터 β를 구합니다.
이후 L과 β를 곱해 나온 행 합의 역수를 각 비디오의 보정치 α로 설정하고, α를 L에 곱해 다시 열의 값을 조정한 뒤 다시 한번 각 열의 합을 구해 이것에 역수를 취해 텍스트 스케일링 벡터 β를 업데이트 합니다. 이 과정을 반복해서 최종적으로 α를 로그 값으로 바꿔 반환한 뒤에 나 중에 테스트 할때 구한 유사도에 α를 더해 최종 유사도를 구하게 됩니다.
감사합니다.