오랜만에 Text-to-Video Retrieval (VTR) 연구에 대해 리뷰해보려고 합니다. 최근 비디오에 포함되어 있는 ‘오디오’라는 모달리티를 활용하는 연구로도 지속적인 관심이 생겨나고 있는 것 같은데, VTR에서는 어떻게 연구가 수행되는지 알아보려고 합니다.

- Conference: ICCV 2023
- Authors: Sarah Ibrahimi, Xiaohang Sun, Pichao Wang, Amanmeet Garg, Ashutosh Sanan, Mohamed Omar
- Affiliation: University of Amsterdam, Amazon Prime Video
- Title: Audio-Enhanced Text-to-Video Retrieval using Text-Conditioned Feature Alignment
1. Introduction
Text-to-video retrieval (T2VR)은 텍스트 질의와 비디오를 동일한 공간(latent space)에 매핑해 가장 의미적으로 유사한 비디오를 검색하는 태스크입니다. CLIP과 같은 대규모 VLP 모델이 등장하면서 성능이 크게 향상되었는데, 그 시초로 CLIP4Clip 모델은 적은 수의 프레임만을 사용하고 간단한 평균 풀링 방식으로, 기존 3D 입력을 사용하는 복잡한 모델보다 뛰어난 결과를 보여 이후 다양한 연구의 기반이 되고 있습니다. 이후 cross-attention, 프롬프트 학습, 사전 학습 태스크 설계 등의 후처리 기법이 추가되며 성능 개선이 이뤄지고 있습니다.

하지만 대부분의 기존 연구는 텍스트와 영상 간의 관계에만 집중하고, 오디오 정보를 활용하는 연구는 현저히 적었습니다. 분명 상단 그림 2처럼, 경기 해설자의 멘트나 특정 효과음은 텍스트에서 언급된 사건을 이해하는 데에 중요한 단서가 될 수 있습니다. 그러나 비디오에는 장면의 맥락을 보강해줄 수 있는 오디오 정보가 있음에도 불구하고, 이를 적극적으로 반영한 연구는 많지 않은 실정이었죠.
아 그렇다고 오디오를 활용하는 연구가 아예 없던 건 아닙니다. [ECCV 2023] ECLIPSE에서는 오디오와 비디오에 대해 Cross-modal attention을 통해 검색 성능을 높이긴 했지만, 나이브하게 두 모달리티를 정렬하는 방식으로는 텍스트 query 중심의 검색에는 충분하지 않았다고 합니다. 가령 오디오에는 화면에 보이지 않는 소리나 주변 잡음이 포함되기 때문에, 텍스트와 밀접한 오디오 단서가 비디오 신호에 묻힐 위험이 있기 때문이죠
따라서 해당 논문에서는 이러한 한계를 해결하기 위해 TEFAL(Text-Conditioned Feature Alignment)이라는 새로운 방법론을 제안했습니다. TEFAL은 텍스트를 중심으로 비디오와 오디오 표현을 각각 정렬해 텍스트와 직접적으로 연관된 단서를 강조하도록 설계되었다고 하는데요. 오디오를 어떻게 모델 학습에 적용하였는지를 중심으로 리뷰해보도록 하겠습니다.
2. Method
2.1 Key Insight: Text-conditioned Feature Alignment
기존의 멀티모달 연구에서는 주로 오디오와 비디오 feature를 직접적으로 결합하거나(cross-modal attention, feature fusion), 두 모달리티를 정렬해 하나의 통합된 표현을 만드는 방식이 대부분이었습니다. 하지만 이는 단순 결합 방식은 TVR의 검색 성능을 저하시킬 수 있다고 합니다. 텍스트는 비디오보다 표현력이 떨어지고, 전체 비디오 내용 중 일부 정보만을 담고 있는 경우가 많기 때문이죠. 따라서 텍스트-비디오 검색에서는 텍스트를 기준으로 비디오 표현을 다시 조정해, 텍스트 질의와 직접적으로 연관된 비디오 정보만을 강조하는 것이 이상적이라고 하네요
이러한 가설로부터 TEFAL은 텍스트를 중심으로 비디오와 오디오를 각각 정렬하도록 설계하였다고 합니다. 먼저 Text-Video Cross-Attention (CA)에서는 텍스트 임베딩을 query로 두고, 비디오 프레임 토큰들을 key와 value로 활용하였습니다. 이를 통해 텍스트와 가장 밀접한 관련이 있는 프레임들을 선택하고, 각 프레임의 중요도를 반영해 가중합된 비디오 표현을 생성합니다. 즉, 텍스트 토큰들은 프레임 단위로 가중치를 부여하며, 텍스트 쿼리와 가장 관련성이 높은 장면을 강조하도록 학습되는 것이죠.
다음으로 오디오는 비디오를 이해하는 데 핵심적인 단서를 제공하므로, 비디오와 동일한 방식으로 Text-Audio Cross-Attention (CA) 을 적용합니다. 오디오 패치를 입력으로 받은 Audio Spectrogram Transformer (AST) 의 토큰들을 key와 value로 사용하고, 동일한 텍스트 임베딩을 query로 활용합니다. 이를 통해 텍스트와 연관성이 높은 오디오 단서를 강조하고, 화면에 보이지 않는 오디오 기반 정보까지도 검색에 반영할 수 있도록 한 것이죠.
(참고로 오디오 인코더인 AST는 ViT 기반의 모델로, 오디오를 스펙트로그램 형태로 변환한 뒤 이를 패치 단위로 나누어 시퀀스로 인코딩하는 모델이라고 합니다.)
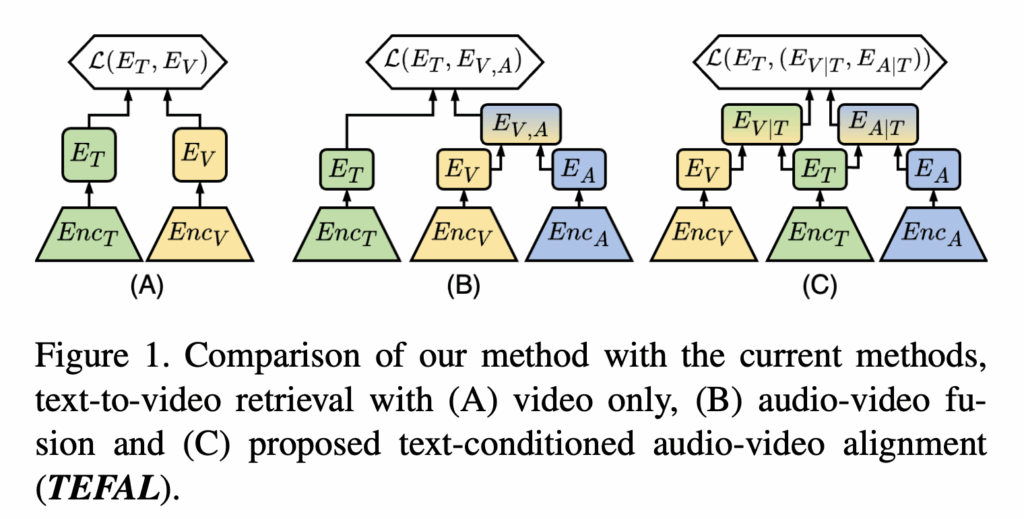
정리하면 상단 그림 중 (C)가 바로 TEFAL이 정렬을 수행하는 과정입니다: 텍스트를 중심으로 비전과 CA, 텍스트를 중심으로 오디오와 CA 수행. 이 과정을 통해 TEFAL은 비디오와 오디오 각각의 표현을 텍스트 중심으로 조정하고, 텍스트-오디오-비디오 간의 관계를 학습할 수 있다고 합니다. 결국 모델은 단순한 모달리티 간 결합이 아닌 텍스트를 기준으로 한 의미적 정렬을 수행하여, 텍스트 쿼리와 관련성이 높은 시각·청각 정보를 강조한 강력한 멀티모달 표현을 생성할 수 있게 되었다고 저자는 표현하였습니다.
2.2 Overall Architecture
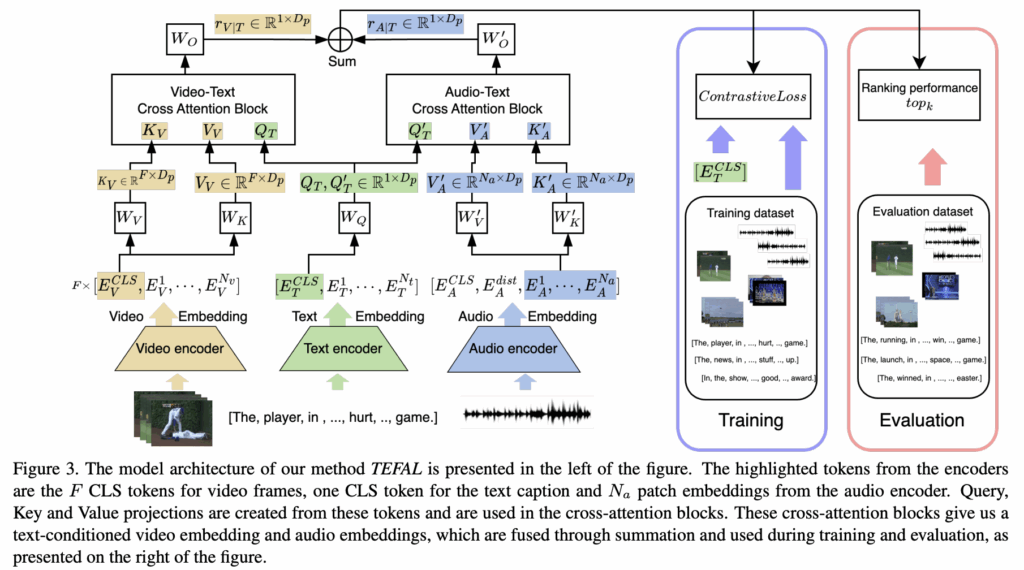
상단 그림 3을 보면 TEFAL의 전체 파이프라인이 한눈에 나타나 있습니다. 왼쪽부터 오른쪽으로 흐름을 따라가면서 살펴보겠습니다.
먼저 입력 단계에서는 텍스트 (T), 비디오(V), 오디오(A)가 각각 인코더를 통해 Feature가 뽑힙니다. 텍스트와 비디오 프레임은 CLIP 모델을 백본으로 사용해 임베딩을 얻고, 오디오 신호는 Mel-spectrogram으로 변환한 뒤 Audio Spectrogram Transformer(AST)로 feature가 얻어지죠.
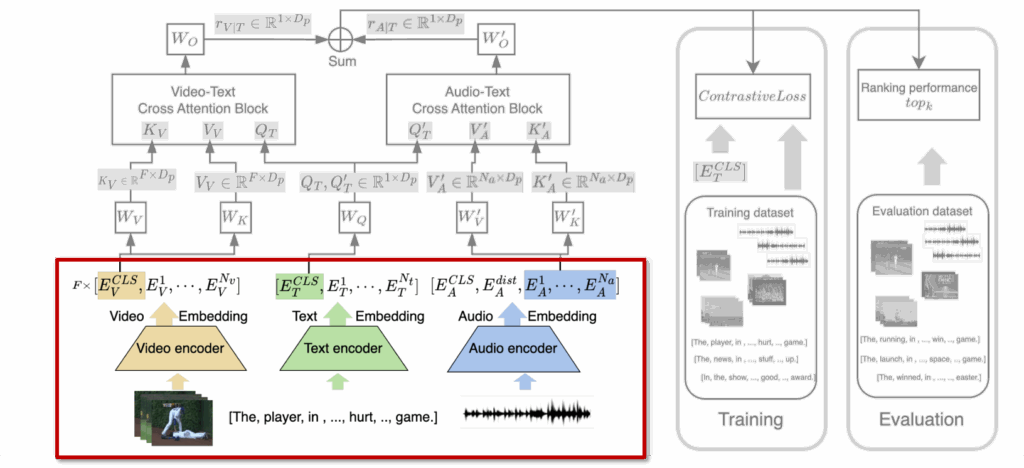
비디오 입력은 여러 프레임(F)으로 나눠지고, 각 프레임은 공간적으로 균일하게 샘플링된 패치(N_v) 단위로 처리됩니다. CLIP 모델에서 각 프레임마다 CLS 토큰 (E_V^{CLS})이 생성되며, 텍스트 입력 역시 CLS 토큰 (E_T^{CLS})으로 요약됩니다. 오디오의 경우 AST을 통해 토큰화된 N_a개의 패치 임베딩이 생성되며, CLS 및 distillation 토큰 (E_A^{CLS}, E_A^{dist})은 이후 단계에서 제외된다고 합니다.
그 다음으로 TEFAL의 핵심 단계인 Text-conditioned Alignment 입니다.
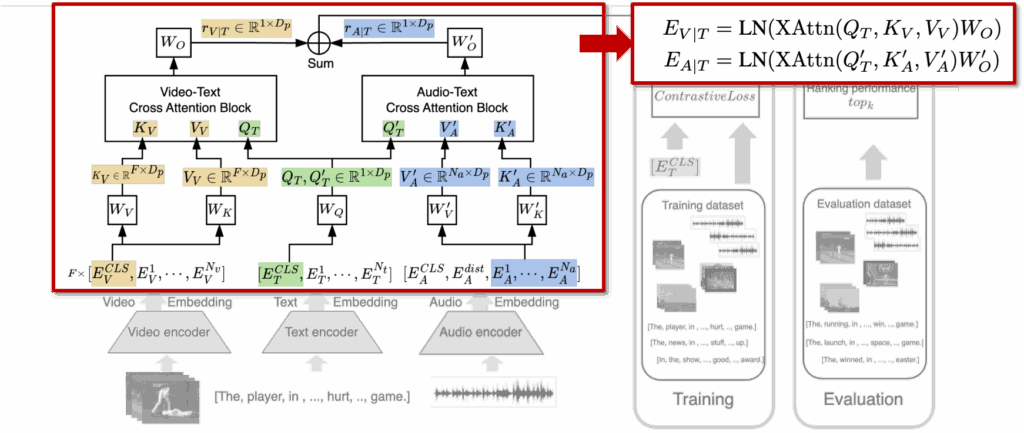
Text-Video Cross-Attention
텍스트 CLS 토큰을 query로 두고, 비디오 프레임 토큰을 key와 value로 사용합니다. 이를 통해 텍스트와 가장 연관성이 높은 프레임 정보를 강조한 비디오 임베딩(E_{V|T})을 생성합니다.
Text-Audio Cross-Attention
동일한 텍스트 CLS 토큰을 query로, 오디오 패치 토큰을 key와 value로 사용하여 오디오 임베딩(E_{A|T})을 텍스트 기준으로 다시 정렬합니다. 이를 통해 화면에 보이지 않는 중요한 소리나 배경음을 텍스트 맥락에서 이해할 수 있게 됩니다.
이제 마지막으로, 텍스트 조건부로 정렬된 비디오 임베딩(E_{V|T})과 오디오 임베딩(E_{A|T})을 간단하게 sum으로 결합해 최종 오디오-비디오 표현(E_{(V,A)|T})을 계산합니다. 이는 최종적으로 텍스트 CLS 토큰(E_T^{CLS})과의 코사인 유사도를 계산해 검색 결과를 뽑는데 사용되게 됩니다.
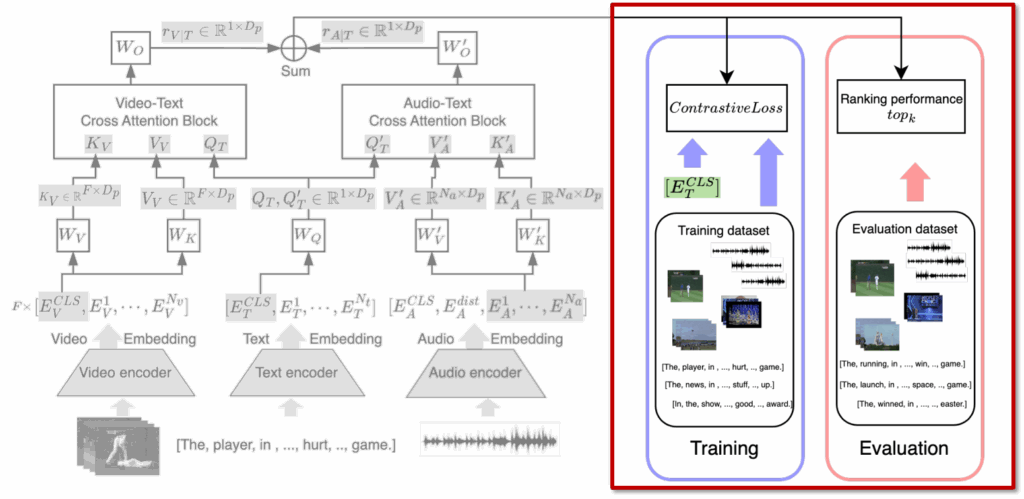
마지막으로 학습 단계에서는 InfoNCE 기반 Contrastive learning을 적용합니다. 다들 아시겠지만, 아래 수식 (4)~(6)에서 보듯, text-to-video(L_t2v)와 video-to-text(L_v2t) 양방향 Loss를 사용해 최적화하며, 두 Loss를 합산한 값으로 모델을 학습합니다.
3. Experiments
3.1 Datasets
- MSR-VTT: 10,000 web video clips between 10-32s
- LSMDC: 118,081 video clips from movies each paired with a single caption. 2-30s
- VATEX: 34,991 video clips with multiple captions per video. long-range video
- Charades: 9,848 videos with one textual description per video. avg: 28s
Data Preprocessing
TEFAL 모델은 사전 학습된 인코더를 활용해 Feature를 얻었습니다. 이 때, 오디오와 비디오 입력의 특성이 다르기 때문에, 두 모달리티를 처리하는 방식에도 차이가 있었다고 합니다.
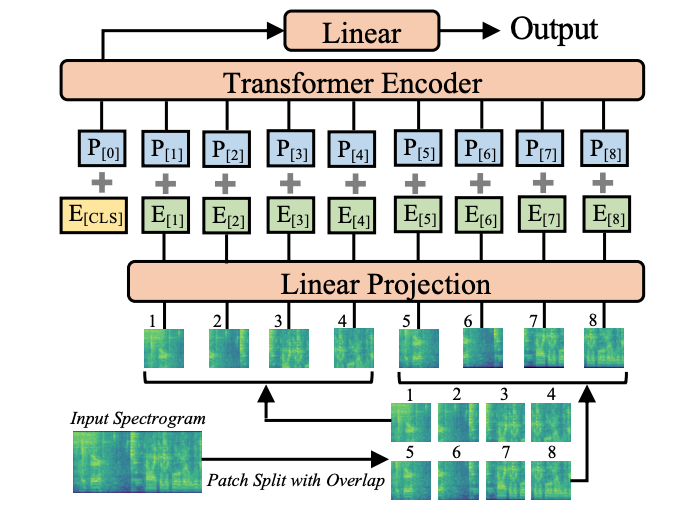
오디오 처리를 담당하는 AST(Audio Spectrogram Transformer)은 사전 학습 과정에서 모든 오디오 샘플이 동일한 길이를 가지도록 설정된 데이터셋에서 학습되었습니다. 따라서 Mel Filter Bank(MFB) 특징 추출 시 프레임 간격(f_{shift})과 타깃 길이(L_tar)가 고정되어 있는 환경에 최적화되어 있죠. 반면, CLIP 비디오 인코더는 길이가 다양한 비디오 데이터를 사용해 사전 학습되었으며, 프레임을 균일하게 샘플링해 처리하도록 설계되어 있습니다.
이 두 백본의 전처리 특성 차이를 조정하기 위해, 저자들은 오디오 전처리 단계에서 MFB의 프레임 시프트(f_{shift})를 영상 프레임 샘플링 방식과 유사하게 동적으로 설정했다고 하였습니다. 즉, 오디오 길이에 따라 프레임 간격을 적응적으로 조정해, 샘플마다 MFB 특징 길이가 고정되도록 설계한 것이죠.
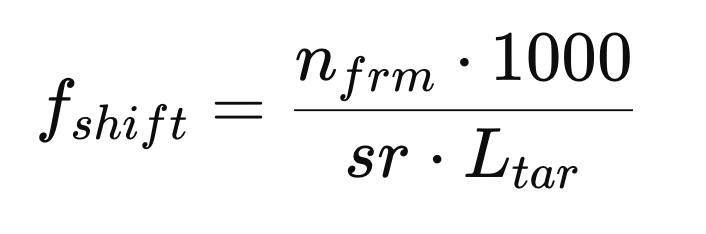
- n_{frm}: 샘플링할 오디오 프레임 개수
- sr: 오디오 샘플링 레이트(Hz 단위)
- L_{tar}: MFB 특징의 목표 길이
이 방식으로 각 오디오 샘플에서 추출한 MFB 특징 벡터가 일정한 길이를 유지하게 되어, AST 백본이 길이가 다른 오디오 데이터를 처리할 때도 안정적으로 작동할 수 있도록 하였다고 합니다.
3.2 Main Results
먼저, 저자는 오디오 모달리티가 정말 검색 성능 향상에 효과적인지를 살펴보는 실험을 진행하였습니다.
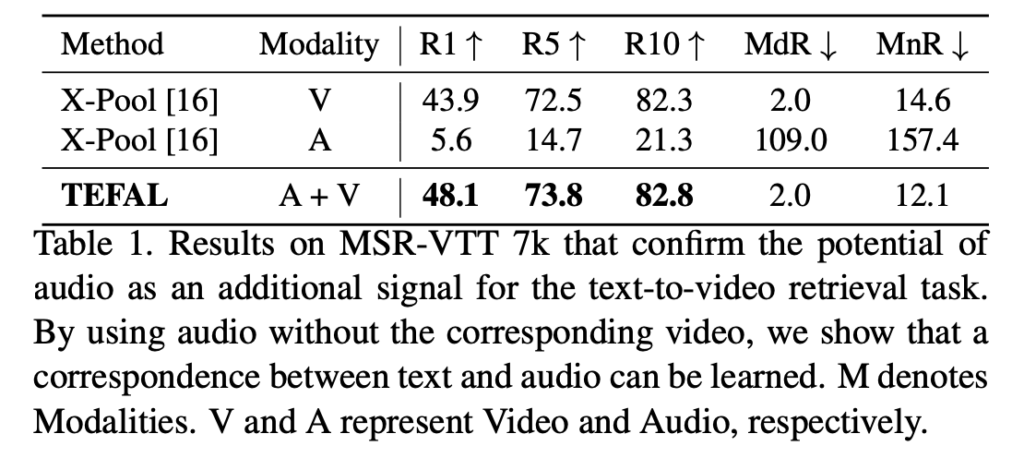
Table 1에서는 MSR-VTT 7k 데이터셋을 사용해 텍스트-비디오와 텍스트-오디오 검색 성능을 리포팅한 것으로, 텍스트-오디오 검색의 R@1(Recall@1) 성능은 5.6%로 낮지만, 텍스트-비디오 검색에서는 43.9%로 훨씬 높은 결과를 보였습니다. 그런데 두 모달리티를 결합했을 때, TEFAL은 단일 비디오 기반 검색 대비 약 4% 성능 향상을 달성하며 오디오 정보의 보완하는 결과를 보임을 통해 오디오가 정말로 비디오 이해 및 검색 성능 향상에 효과적임을 살펴보았습니다.
Table 2-3) Benchmark (MSR-VTT 7K / 9K)
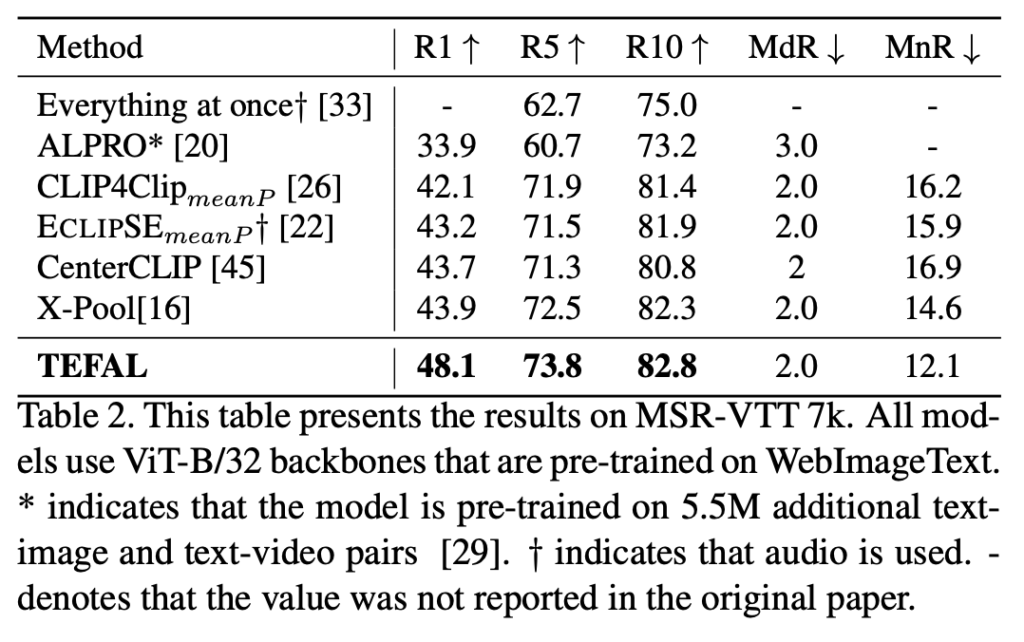
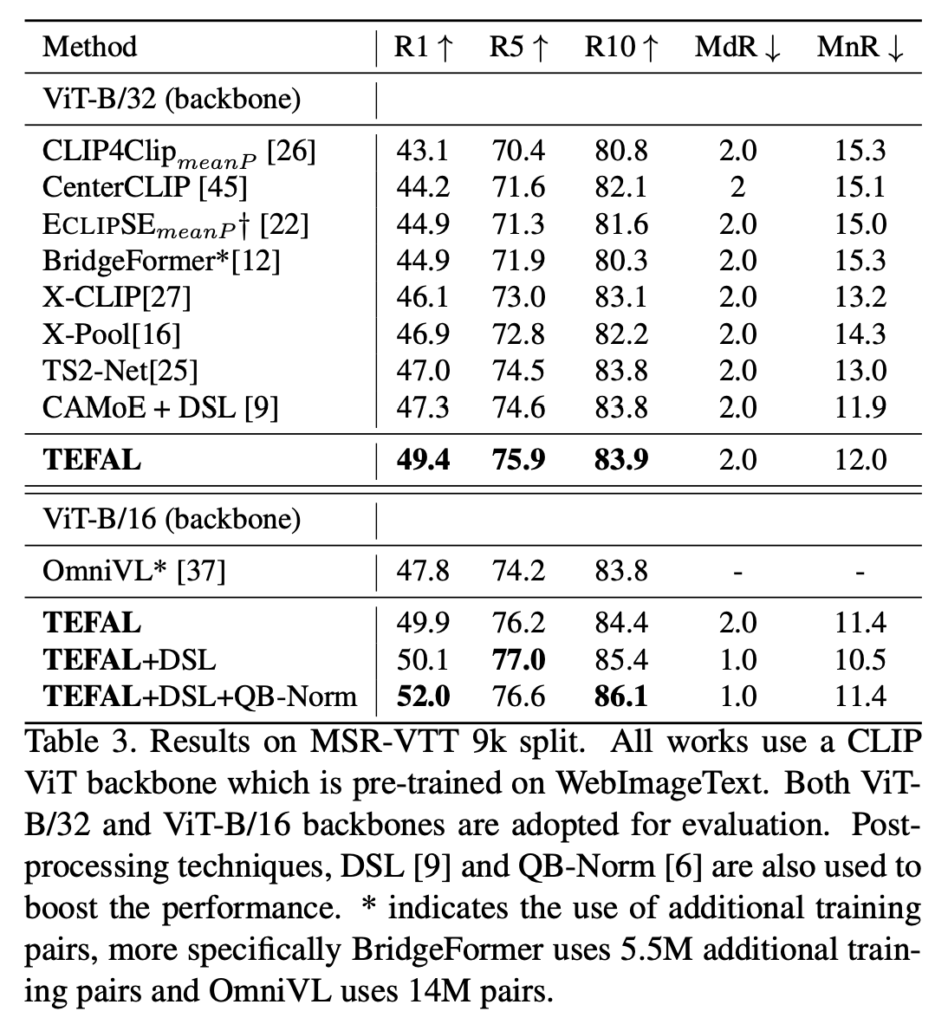
Table 2와 Table 3에서는 MSR-VTT의 7k와 9k split에서의 성능을 비교한 결과입니다. TEFAL은 오디오를 활용한 기존 최고 성능 모델인 ECLIPSE를 R@1 기준으로 각각 4.9% (7k split), 4.5% (9k split) 뛰어넘은 것을 확인할 수 있습니다. 또한 오디오를 활용하지 않는 최신 모델들과 비교해도 2.1% 향상된 성능을 기록했습니다. 여기에 더해, 더 큰 백본 모델(+0.5%)과 Querybank Normalization(QB-Norm, +2%)을 결합하면 성능이 추가로 개선될 수 있음을 보였습니다.
Table 4, 5, 6에서는 LSMDC, VATEX, Charades 등 다른 오디오 포함 데이터셋에서도 일관되게 SOTA 성능을 기록했습니다. 특히 LSMDC와 VATEX에서는 약 1%의 R@1 개선, Charades에서는 최대 2.4% 성능 향상을 확인하였습니다.
3.3 Analysis
3.3.1 Audio Feature Extraction
다음으로 오디오 feature를 뽑는 과정이 모델 성능에 미치는 영향을 확인하기 위해 MSR-VTT 9k 데이터셋에서 여러 가지 ablation 실험 결과입니다. 오디오 인코더의 학습 기법과 프레임 시프트(frame shift) 설정 방식을 달리한 실험입니다.

먼저 오디오 인코더(AST) finetuning 여부에 따른 실험입니다. 기존의 ECLIPSE 모델은 사전 학습된 오디오 인코더의 출력을 그대로 사용하고 마지막 레이어만 학습했지만, TEFAL에서는 AST 전체를 finetuning하는 방식을 사용했습니다. 그 결과, R@1 성능이 3.8% 향상되어 오디오 인코더를 전체적으로 학습하는 것이 검색 성능 향상에 효과적임을 보였다고 합니다.
다음으로 프레임 시프트 설정 방식인데, 일반적으로 AST 모델은 모든 데이터셋에 대해 고정된 10초 단위 프레임 시프트를 사용하지만, TEFAL은 오디오 길이에 따라 동적으로 프레임 시프트를 조정해 Mel Filter Bank(MFB)의 길이가 일정하게 유지되도록 설계함으로써, 긴 오디오에서도 중요한 정보를 놓치지 않고 표현할 수 있도록 도울 수 있엇다고 합니다. 실험 결과, 고정된 프레임 시프트 대비 0.8% 성능 향상을 확인할 수 있습니다.
3.3.2 Variations on Multimodal Fusion
뿐만 아니라 오디오와 비디오 임베딩을 결합하는 방식을 변화하는 실험도 진행하였습니다. Table 8과 Figure 4에서 자세한 내용을 확인할 수 있는데, 이때 E_{V|T}는 텍스트 조건부 비디오 임베딩, E_{A|T}는 텍스트 조건부 오디오 임베딩을 의미합니다.
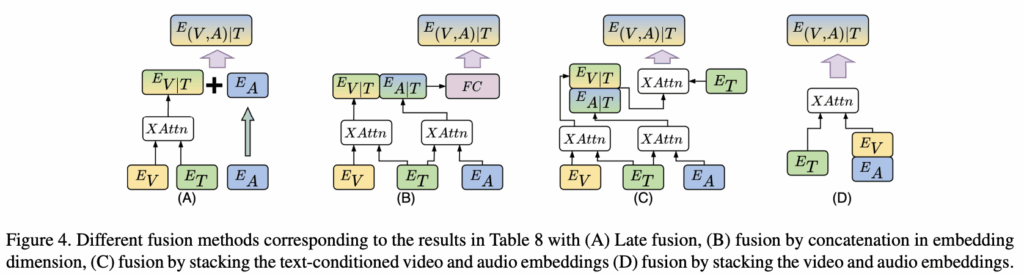
(A) Late Fusion
Late Fusion에서는 오디오 임베딩을 텍스트로 정렬하지 않고, 오디오 인코더에서 바로 추출한 특징을 비디오 임베딩과 단순 덧셈으로 결합한 것으로, 성능이 R@1 기준 5.9% 하락하여, 텍스트와 오디오의 명시적인 정렬 과정이 매우 중요함을 알 수 있었다고 합니다.
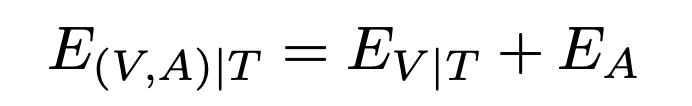
(B) Concatenation
Concatenation 방식에서는 텍스트 조건부 비디오와 오디오 임베딩을 concat한 후, FC Layer를 통해 차원을 1024에서 512로 줄이는 방식입니다. 그러나 이 방식은 6.3% 성능 저하가 발생했다고 하네요. 이는 추가된 파라미터가 많아 학습이 복잡해지고, 텍스트-오디오-비디오 간의 관계를 충분히 반영하지 못했기 때문으로 보입니다.
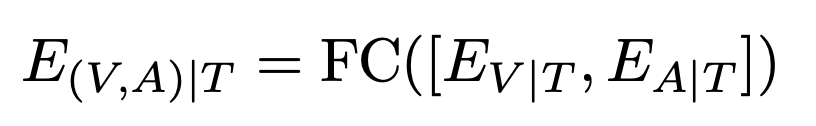
(C) Fusion by Cross-Attention
여기서는 두 임베딩을 쌓은 뒤(text-conditioned audio/video embeddings) 텍스트를 query로 하여 한 번 더 cross-attention을 수행했습니다. 이 방법은 3.5% 낮은 성능을 보였습니다. 설계상 추가 cross-attention이 오디오·비디오 정보의 중요도를 오히려 반영하지 못했음을 알 수 있었다고 합니다.
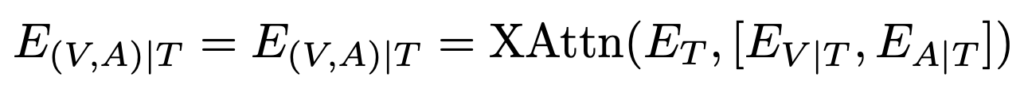
(D) Stacking Audio and Video
마지막으로, 오디오 CLS/DIST 토큰의 평균값을 사용해 비디오 프레임 임베딩과 함께 하나의 cross-attention 블록으로 결합한 방식입니다. 그러나 초기 오디오와 비디오 프레임 임베딩의 표현 공간이 정렬되지 않아 성능은 46.1% R@1에 그쳤다고 합니다. 이는 두 cross-attention 단계를 통해 각각의 모달리티를 텍스트에 맞춰 정렬하는 TEFAL이 적절한 방식임을 알 수 있었다고 하네요.
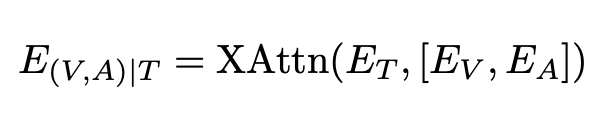

지금 말씀드린 실험을 정리한 테이블입니다. 결론은, 단순히 오디오와 비디오 임베딩을 합치는 것이 아니라, 텍스트를 중심으로 각 모달리티를 정렬한 뒤 단순 덧셈(addition)으로 융합하는 방식이 가장 효과적임을 알 수 있었다고 합니다. 그 결과 TEFAL은 R@1 49.4%로, 오디오 없이 비디오만 활용한 X-Pool 대비 2.5% 성능 향상을 달성했습니다.
3.3.3 Applicability at Scale
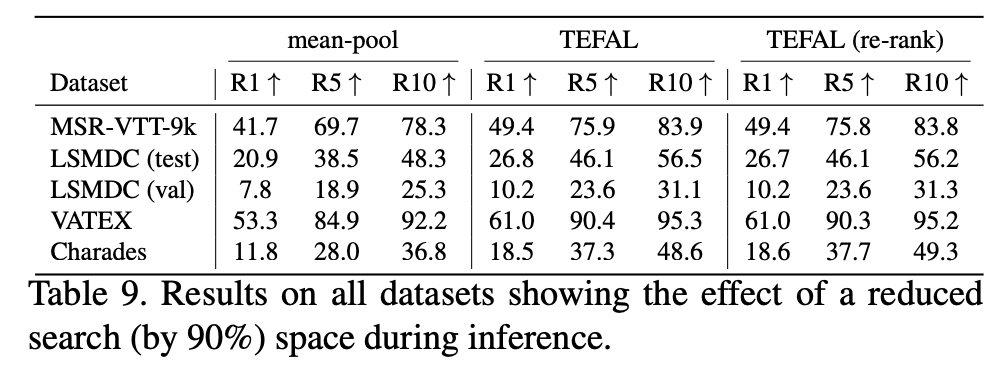
TEFAL은 텍스트 기반으로 오디오·비디오 임베딩을 동적으로 계산하기 때문에, 대규모 데이터셋에서 효율성이 중요했다고 합니다. 저자들은 mean-pooling으로 사전 계산된 임베딩을 사용해 상위 K개의 후보 영상을 먼저 추린 뒤, TEFAL로 재순위를 수행하는 방식을 적용했습니다. 이로써 시간 복잡도를 O(T \cdot V)에서 O(K \cdot T + V)로 줄일 수 있었다고 하네요. 7,408개 비디오를 포함한 LSMDC 검증셋에서도 이 방식은 성능 저하가 거의 없었으며, TEFAL이 대규모 환경에서도 실용적으로 동작할 수 있음을 보였습니다.
3.3.4 Qualitative Results

마지막으로 정성적 결과입니다. MSR-VTT 데이터셋 예시를 통해 오디오 정보가 검색 성능을 높이는 데 중요한 역할을 한 것을 보였는데, 상단 Figure 5에서, 텍스트는 “person is driving his black car fast on the street”입니다.
- TEFAL w/ audio: 해당 영상을 top-1로 정확히 검색
- TEFAL w/o audio: 같은 영상을 5위에 위치
이 예시에서 핵심 단어는 “fast”로, 빠르게 주행하는 모습이 영상 프레임에서는 뚜렷하게 보이지 않지만 엔진 가속 소리로부터 그 의미를 파악했다고 합니다. 이는 오디오가 비디오 프레임만으로는 부족한 맥락을 보완해주며, 모델이 텍스트를 더욱 잘 이해하는 것이라고 말하며 마무리 하였습니다
4. Summary
해당 논문은, 텍스트-비디오 검색에서 오디오 정보를 활용해 성능을 높이는 TEFAL (Text-conditioned Feature Alignment) 프레임워크를 제안했습니다. 모델은 텍스트를 중심으로 오디오와 비디오 임베딩을 각각 cross-attention으로 정렬한 뒤 단순 합산해 최종 임베딩을 구성합니다. 이 방식은 오디오 없이 비디오만 사용하는 기존 모델 대비 MSR-VTT에서 최대 4.9% R@1 성능 향상을 기록했습니다.
방법론 자체가 워낙 간단하다보니, 다양한 실험을 논문에서 볼 수 있었습니다. 오디오를 직접 사용하는 것만으로도 제법 큰 성능 향상을 가져왔네요. 리뷰 마치겠습니다.
홍주영 연구원님 좋은 리뷰 감사합니다.
모든 모달리티에 대하여 CLS 토큰이 추가되었다고 하셨는데, 오디오의경우 distillation 토큰이 추가로 존재하는데 해당 토큰이 어떻게 정의되고, 역할이 무엇인지 궁금합니다.
댓글 감사합니다.
오디오 인코더로 사용한 AST 모델은 이미지 분류용 DeiT 모델과 유사하게, CLS 토큰 외에 distillation 토큰을 추가로 사용하였다고 합니다. 이 토큰은 사전 학습 단계에서 teacher network로부터의 지식을 전달받기 위해 설계된 것으로, CLS 토큰과 함께 학습되어 오디오 입력에서 중요한 global 정보를 보강하는 역할을 한다고 합니다.
그러나 본 논문에서는 text-to-video retrieval에 직접적으로 활용할 오디오 특징으로 patch 임베딩만 사용하고 distillation 토큰은 최종 표현 계산할 때에는 제외했다고 합니다. 따라서 distillation 토큰은 사전 학습 시 중요한 의미를 가지지만, 검색 단계에서는 모델 성능을 간결하게 유지하기 위해 활용하지 않은 것 아닐까 싶네요
안녕하세요 주영님 좋은 리뷰 감사합ㄴㅣ다.
궁금한점이 하나 있는데, 오디오를 사용하는것이 좋지만 배경음악이 전혀 관계없는 경우로 인해 오히려 성능 저하 발생할 것 같습니다. 단순 Attention 기법으로는 이걸 해결하기 어려울 것 같은데 이에 대한 내용이 있을까요?
감사합니다!
아주 좋은 질문 같습니다.
물론 저자가 텍스트와 의미적으로 연관된 오디오 토큰에 더 높은 가중치를 부여해 불필요한 신호를 억제하도록 설계하긴 했다지만, 논문에서도 모든 잡음을 완벽히 제거하는 데 충분하지 않다는 점을 인정하였습니다.
그래서인지 향후 연구인 CVPR 2025 AVIGATE 논문에서는 잡음을 줄이는 방향으로 오디오를 Resampling 하는 모듈을 추가하기도 했습니다.
안녕하세요. 좋은 리뷰 감사합니다.
문제 정의와 방법론을 잘 설명해주시어 이해가 잘 되었습니다.
저도 Audio-Visual QA task를 보고있다보니, 아무래도 3.3.3의 표가 눈에 들어왔는데요.
표에서 TEFAL에 비해 mean-pool은 비디오를 먼저 추림으로써 search space가 90% 감소했을때의 성능으로 이해했습니다. 여기서 성능이 데이터셋마다 거의 적게는 15%에서 많게는 25%까지 감소한 것으로 보이는데, 이정도면 저자의 주장대로 ‘성능 하락이 거의 없었다’라고 보시는지 궁금합니다.
그리고 TEFAL과 TEFAL(re-rank)의 성능 차이가 얼마 나지 않는데, re-rank에 대해서 간단히 설명해주시면 감사드리겠습니다. 만약 원래 TVR 학계에서 re-rank가 검색 성능에 꽤 도움되는 기법이었다면, 그럼에도 불구하고 일반 TEFAL과 큰 차이가 없는 상황이라 앞서 언급한 mean-pool 방식의 성능 하락이 더욱 크게 느껴질 것 같아 여쭤봅니다.
A1. 말씀하신대로 Table 9에서 mean-pool 기반은 검색 공간을 90% 줄였을 때, 검색 성능이 15-25% 하락한 것은 분명 무시하기 힘든 차이로 보이긴 합니다. 논문에서 “성능 하락이 거의 없었다”는 표현은 실제 대규모 데이터셋에서 계산 복잡도를 크게 줄인 상황에서도 TEFAL이 여전히 경쟁력 있는 수준의 성능을 유지했다고 보는게 더 나을 것 같긴 하네요.
A2. re-ranking 방식은, mean-pool로 계산한 간단한 비디오 임베딩으로 상위 K개의 후보를 먼저 선정한 뒤 TEFAL로 정밀하게 순위를 재조정하는 단계라고 합니다. TVR에서 re-rank는 보통 성능 향상을 위해 활용되기에, 저자들도 이를 통해 TEFAL의 효율성을 검증한 것으로 보입니다. 여기서, TEFAL과 TEFAL(re-rank)의 성능 차이가 크지 않은 것은, TEFAL의 text-conditioned alignment 자체가 강력하기 때문에 re-rank의 이점이 상대적으로 작게 나온 것으로 해석할 수 잇을 것 같습니다.
안녕하세요. 홍주영 연구원님 좋은 리뷰 감사합니다.
비디오에서 Audo를 같이 활용하는 연구가 점점 늘어나고 있는 것 같습니다. 오디오를 활용한 초기 연구로 방법론은 심플한 것 같습니다. Ablation Study에서 Audio의 유무에 따른 성능 변화에 대한 분석은 없었는지 궁금합니다.
감사합니다.
Ablation Study에서는 오디오의 인코더 학습 방식(finetuning 여부)과 프레임 시프트 조정 방식 등 오디오 feature 추출 방식에 초점을 맞추었기 때문에, 오디오를 제거했을 때의 결과는 따로 리포팅하지는 않았습니다.
대신 Table 2에서 오디오가 없는 기존 모델(X-Pool 등)과 TEFAL을 직접 비교해 오디오의 기여도를 간접적으로 확인할 수 있도록 한 것을 보면 좋을 것 같습니다
방법론 설명에서 “비디오 임베딩과 오디오 임베딩을 텍스트 조건부로 정렬한다”는 표현이 와닿지 않아 질문드립니다. 제가 이해하기로는, 텍스트와 비디오 인코더를 통해 임베딩을 얻은 뒤 프레임 임베딩(F * CLS)이 생성되고, 여기에 video-text attention 연산을 적용하면 텍스트를 조건부로 하나의 비디오 임베딩이 추출되는 것으로 보입니다.
이 과정에서 attention 연산을 한 후에 F개의 프레임을 단순 평균하여 하나의 비디오 임베딩으로 만들 수도 있고 다른 방식으로도 비디오 임베딩으로 만들 수 있는데 이 방법론에서는 어떤 방식으로 만들었는지가 궁금합니다.
그림에서 평가 단계에 Top-k가 사용된 것을 보면, 여러 프레임 중 텍스트와 가장 연관성이 높은 k개의 프레임(또는 오디오)을 선택하는 것 같은데 설명해주시면 감사하겠습니다.
좋은 질문 감사합니다.
말씀해주신 대로 본 논문에서 말하는 “텍스트 조건부 정렬”은 텍스트 CLS 토큰을 query, 비디오 프레임 토큰을 key/value로 하여 cross-attention 연산을 수행해, 텍스트와 가장 연관성이 높은 비디오 표현을 강조하는 과정을 의미합니다. 이 과정을 통해 각 프레임은 텍스트와의 연관성을 반영한 attention weight를 얻게 되고, 최종 비디오 임베딩은 weighted sum으로 계산됩니다. 즉, 단순 평균을 쓰지 않고 attention score를 기반으로 프레임별 중요도를 반영한 합산 방식을 사용하는 것이죠.
다만, 그림에서 보이는 “Top-k”는 학습 및 평가 효율성을 위한 후처리 단계로, 전체 비디오 중 상위 K개의 후보를 먼저 선택해 TEFAL로 재순위를 매기는 방식이라고 합니다. 이는 프레임 수준에서 K개를 선택하는 것이 아니라, 비디오 전체 단위로 후보를 좁히는 과정으로, 프레임이나 오디오 토큰은 attention 연산을 통해 이미 가중합으로 통합된다고 하네요.
다시 정리하자면, 이 방법론은 attention 기반으로 텍스트와 연관성이 높은 프레임을 찾아 가중합으로 단일 비디오 임베딩을 생성하며, Top-k 전략은 최종 검색 효율성을 위한 비디오 레벨 후보 추출 기법으로 이해하시면 됩니다.
오디오 인코딩에 대해서 제가 이해하기론 오디오의 파형을 이미지화해서, 이 이미지를 원래 이미지 인코딩 하듯이 처리한다고 이해했는데, 알맞은 이해인지 궁금하고..
추가로 제가 생각해봤을 때 단순히 오디오의 파형을 바로 숫자형으로 표현할 수도 있지 않을까 싶은데, 이처럼 혹시 다른 오디오 인코딩 방법론도 있는지 궁금합니다.
네, 맞습니다. 현재 Audio Spectrogram Transformer(AST) 같은 오디오 인코더들은 오디오 신호(파형) 를 바로 쓰지 않고 Spectrogram(주파수-시간을 나타내는 2D 이미지) 으로 변환해서 ViT 같은 이미지 인코더로 처리합니다.
다른 오디오 인코딩 방법론에 대해 질문주셔서, 저도 좀 찾아보았습니다
말씀하신 “파형을 바로 숫자형으로 표현”하는 방식도 연구가 되고 있습니다.
보통 Raw waveform 기반 인코딩이라고 부르는데, Google에서 WaveNet 을 발표하며 오디오 파형 자체를 직접 모델링 (Autoregressive) 하는 경우도 있었습니다.
그 외로 SampleCNN, Wave2Vec, HuBERT 등등 파형을 작은 단위(샘플/프레임)로 쪼개서 직접 학습에 활용하는 연구도 등장한 것 같습니다.
다만 해당 연구에서는 오디오를 어떻게 feature로 추출할지 보다는 이미 뽑힌 audio/visual/text feature를 어떻게 Fusion 할 지를 메인으로 고민하였습니다.