
이번에 소개드릴 논문은 최근에 공개된 DINOv3 입니다. DINOv2가 CV에서 엄청난 파급력이 있음은 잘 알려져있지만 그렇다고 이번에 새로 나온 DINOv3 논문 제목이 추가적인 부연 설명이나 내용 없이 그냥 “DINOv3″라고만 띡 적혀있는 것으로 볼 때 메타가 이번 논문에 상당한 자신감과 자부심을 가지고 있다고 생각합니다ㅋㅋ.
현재 아카이브에 공개된 논문 기준으로 reference까지 포함해서 67장으로 구성이 되어있어서, 해당 리뷰에서 모든 실험과 내용을 다룰 수 없을 것 같고, 방법론을 읽어보니 모델 학습을 위해 최신 self-sup 기법들을 많이 활용을 했더라구요. 그래서 해당 방법론들을 다 소개하기에는 분량과 시간소모가 너무 커질 것 같아 저자들이 학습 동안에 사용한 기존 방법론들에 대해서는 구체적인 소개 없이 reference를 다는 형식으로 리뷰를 작성할 예정이니 양해 부탁드립니다.
Intro
일단 인트로를 최대한 간결하게 정리해보겠습니다.
- Self-Supervised Learning(SSL)으로 학습한 모델들은 입력 데이터 분포 변화에 강건하고, 풍부한 임베딩을 생성할 수 있어 물리적인 장면 이해 등에 용이하다고 합니다.
- 그리고 SSL 학습 방식은 ImageNet에서 supervised learning으로 pretraining하는 과거의 관례처럼 특정 downstream task로 학습한 것이 아니기 때문에 backbone을 freeze한 상태로 특별한 fine-tuning없이도 다양한 도메인이나 task에서 준수한 성능을 보여줍니다.
- 즉, 관측 데이터만 겁나 많고 사람의 노동력이 필요로 하는 label과 같은 meta data는 부족한 분야(위성, 의료, 생물 영상 등등)에서 DINOv2와 같은 SSL 학습 방식은 매우 훌륭한 선택지라고 저자들은 주장합니다.
- 하지만, SSL을 할 때 문제점이 크게 3가지 존재하는데 첫째로는 unlabeled data로부터 학습에 유용한 정보를 어떻게 선별해서 모을 것인지이며, 둘째로는 일반적인 학습 방식에서 활용하는 코사인 스케쥴이 large image corpora에서 학습할 땐 학습에 어려움을 준다는 점, 마지막으로, 초기 학습 이후에 local level patch들이 점진적으로 성능이 감소하는 현상이 발생한다는 점입니다. (참고로 이 3번째 문제점은 ViT Large와 같은 300M 이상의 큰 모델들 학습 때 발생한다고 합니다.)
- 그래서 저자들은 방대한 양의 데이터를 모았다면 해당 데이터를 어떻게 잘 curation할 것인가, 그리고 7B급의 거대 모델에 대하여 성공적으로 SSL을 하기 위한 다양한 학습 규제화 및 방식, 마지막으로 dense level patch의 representation이 저하되는 현상을 해결하기 위핸 새로운 목적 함수를 제안하는 것을 큰 contribution으로 제안합니다.
이정도로 정리해볼 수 있겠고 보다 더 구체적인 내용들은 아래 Method에서 다뤄보겠습니다.
Method
우선 저자들은 GPT와 같은 LLM이 모델 크기를 scale up 시킴으로써 다양한 task와 domain에서도 강건하게 동작하는 성공 사례에 큰 영감을 받았다고 하며, SSL의 방향성은 모델의 크기와 그에 걸맞은 데이터의 양을 통하여 기존의 전통적인 supervised learning 혹은 task-specific 접근법의 내재적 한계를 극복하는 것이라고 주장합니다. 특히, SSL은 풍부하고 고퀄리티의 시각 특징을 생성하며 이들 특징들은 어느 특정 테스크나 supervision에 편향되지 않았기에 다양한 다운스트림 task에 다재다능한 파운데이션 모델을 제공할 수 있다는 점이 큰 강점이라고 합니다.
위에 내용이 이론적으로는 맞는 말이긴한데, 사실 Vision Foundation model들은 현재 잘나가는 LLM과 달리 상대적으로 작은 모델들을 제공해왔습니다. 그나마 DINOv2의 경우 ViT giant model이 1.1B으로 가장 큰 모델이긴 하지만, 기본적으로 현재 공개되는 LLM들이 7B, 15B 또는 그 이상의 크기로 구성되는 것으로 보아 Vision Foundation model들의 scale-up이 생각보다 쉽지 않음을 알 수 있습니다.
이는 vision 분야에서 SSL 모델을 스케일업 하는 것이 사실 학습의 불안정성으로 인한 이슈가 있어서 이전 연구들이 시도를 했었으나 유의미한 결과를 만들지는 못했기 때문이었다고 합니다. 그래서 해당 논문에서는 우선 큰 모델과 그에 걸맞은 방대한 양의 데이터를 가지고 어떻게 학습해야 성공적인 스케일링 업이 될 것인가에 대하여 중점적으로 다룹니다.
Data Collection and Curation
우선 데이터 수집과 정제와 관련된 내용입니다. 기존의 여러 연구들에서 말하길 데이터 양을 그냥 무작정 늘리기만 한다고 해서 모델의 퀄리티가 더 높아지는 것은 아니었다고 합니다. 즉 성공적인 데이터 스케일링은 결국 신중한 데이터 curation이 필요하다는 것이라는 것이고 저자들은 이에 따라서 방대한 양의 데이터를 수집한 뒤 이를 정제하는 것에 많은 노력을 합니다.
우선 자신들이 meta라는 점에서 인스타그램의 public post로부터 수집된 방대한 양의 웹 이미지 데이터를 활용했다고 합니다 (인스타에 사진 올린 사람들은 DINOv3 학습 때 자신들의 사진이 활용됐을 수도..?ㅋㅋ) 이렇게 수집된 데이터 규모는 대략 170억장의 이미지이며, 이미 인스타그램 플랫폼에서 해로운 컨텐츠에 대한 사전 필터 시스템이 있어 (법적/도의적 개념에서?) 해로운 데이터들은 크게 없다고 판단하였다 합니다.
이제 이 170억장의 이미지 중에서 유의미한 데이터들만을 선별해야하는데, 데이터 curation의 방향은 크게 3가지로 데이터의 다양성/ 균형/ 유용성 등이 있다고 합니다. 저자들은 해당 관점에 맞추어 데이터를 3가지 part로 구분해서 curation을 진행합니다.
우선 다양성 관점에서, 저자들은 계층적 K means clustering 방식을 통한 자동 data curation 방법론을 적용합니다. 구체적으로 DINOv2를 이미지 임베딩 삼아 5개의 레벨의 계층적 군집을 생성하는데, 군집의 수는 레벨 별로 200M, 8M, 800k, 100k, 25k라고 하네요. 이렇게 군집을 만들고 나서는 이전 연구에서 제안한 balanced sampling algorithm을 활용하였고 결과적으로 모든 시각적 컨셉이 균형있게 다루어진 1689M의 이미지를 획득할 수 있었음.
두번째 part로는 균형 관점에서 retrieval 기반의 curation system을 적용하였다고 합니다. 구체적으로, 선택된 특정 데이터셋으로부터 유사한 데이터 풀을 가져오는 것이며, 이는 downstrema task와 연관된 시각적 컨셉 영상들을 수집하는 것을 목표로 합니다.
마지막으로, 기존 computer vision dataset인 ImageNet 1K, 22K, Mapillary Street-level Sequences를 그냥 바로 활용했다고 함. 해당 데이터셋들은 오랜 기간동안 많은 연구자들이 활용한 충분히 검증된 데이터셋으로 해당 데이터셋을 학습에 활용하는 것은 모델이 더 고퀄리티의 데이터로 학습할 수 있는 여지를 제공하는 것으로 보입니다.
이렇게 여러 source에 데이터를 수집하였다면 이제 모델 학습을 진행해야하는데, 이때 중요한 점은 다양한 source들이 존재하며 이들 데이터들을 어떻게 조합해서 모델에게 전달할 것인지도 모델 학습 관점에서 매우 중요합니다. 우선 모든 data part로부터 일정 비율만큼 데이터를을 공평히 들고와서 합치는 방식을 사용해볼 수 있는데, 해당 방식을 저자들은 heterogenous batch라고 이야기합니다.
또한 이전 연구에서 작은 단일 데이터셋으로부터 고퀄리티의 데이터들로만 구성된 배치셋을 학습시키는 것이 모델 성능에 도움이 된다는 것에 영감을 받아서, 저자들도 각 이터레이션마다 랜덤하게 모든 데이터 요소로부터 합쳐진 heterogenous batch 뿐만 아니라 ImageNet 1K의 데이터로만 구성된 homogeneous batch 데이터를 학습에 사용하였다고 합니다. 저자들은 이 homogeneous batch의 경우 전체 학습 데이터의 10% 비율정도만 차지하도록 설정하였습니다.
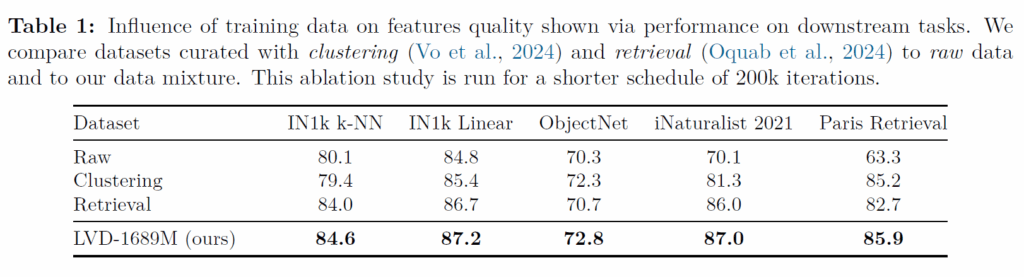
위에 표는 저자들의 data curation 방식을 적용했을 때와 적용하지 않을 때(RAW) 또는 일부만 적용했을 때(Clustering/Retrieval)의 데이터로 학습한 모델의 성능을 ablation 한 표입니다. 결론만 딱 말씀드리면 data curation을 모두 적용한 LVD-1689M 셋으로 학습하는 것이 모든 벤치마크에 유의미한 성능 향상을 보여준다는 점입니다.
Large-Scale Training with Self-Supervision
다음은 모델을 스케일업해서 학습시키는 방법에 대한 내용을 다루고자 합니다. 인트로에서도 간략하게 소개드렸다시피 기존의 SSL 방법론들은 ViT Large 수준을 넘어 몇십억 단위의 큰 모델 크기로 성공적인 스케일 업을 한 사례가 없다고 합니다.
이러한 Vision 분야에서의 SSL Scaling up의 문제점은 크게 2가지로, 첫째는 학습의 안정성 문제가 하나 있었고 두번째는 시각적 세상의 전체 복잡성을 모델이 포착하도록 학습되기에는 pretext task가 과하게 단순하였다고 저자들은 주장합니다.
그나마 DINOv2가 1.1B 단위까지 scale up이 가능해서 CLIP과 같은 모델과 성능을 맞출 수 있었으며, 메타 내부에서 DINOv2를 최근 7B까지 확장도 해보았지만, 해당 모델의 경우 global task에 대해서만 좋은 성능을 보일 뿐 segmentation이나 depth estimation과 같은 dense prediction에서는 실망스러운 결과를 보여주었다고 합니다.
그래서 DINOv3에서는 이러한 문제점들을 해결해서 성공적으로 스케일업도 하고, dense-level prediction의 성능도 개선시키고자 할텐데 지금부터 그 과정에 대해 알아보죠.
우선 DINOv3는 DINOv2가 그러했듯이, Image-level objective에 대한 DINOv1의 loss를 사용하고, 또 patch-level의 latent reconstruction인 iBOT의 loss를 활용하여 global과 local의 balance를 학습하였습니다. DINOv2의 pretext task와 목적 함수가 무엇인지 궁금하시다면 저희 연구실 사람들이 작성한 DINOv2 논문 리뷰를 참고하시면 좋을 듯 합니다.
한가지 차별점은, DINOv2에서는 centering 기법을 활용하였지만 DINOv3의 경우 SwAV의 Sinkhorn-Knopp 방법론을 적용하였다고 합니다. 그리고 저자들은 local과 global crop에 대한 backbone output들 사이에 layer normalization을 추가로 적용하였으며 이는 ImageNet KNN classification, segmentation과 depth estimation의 성능 향상을 가져왔다고 합니다. 또한 Koleo 규제화 \mathcal{L}_{Koleo} 도 추가하여 배치 내 특징들이 동일한 공간에서 균일하게 펼쳐지도록 하였다고 합니다. 즉 DINOv3의 초기 학습 loss는 아래 수식과 같습니다.

일단 수식1만 보면 기존 DINOv2와 크게 차이는 없어요. 맨 마지막에 Koleo 규제화가 들어간다는 점과 centering 대신에 SwAV의 Sinkhorn-Knopp 기법이 사용된다는 점을 제외하면요. 그리고 이제 저자들은 본격적으로 모델 scalining을 하기 위해 아래 표2와 같이 ViT-giant를 ViT-7B로 구성하였다고 합니다.
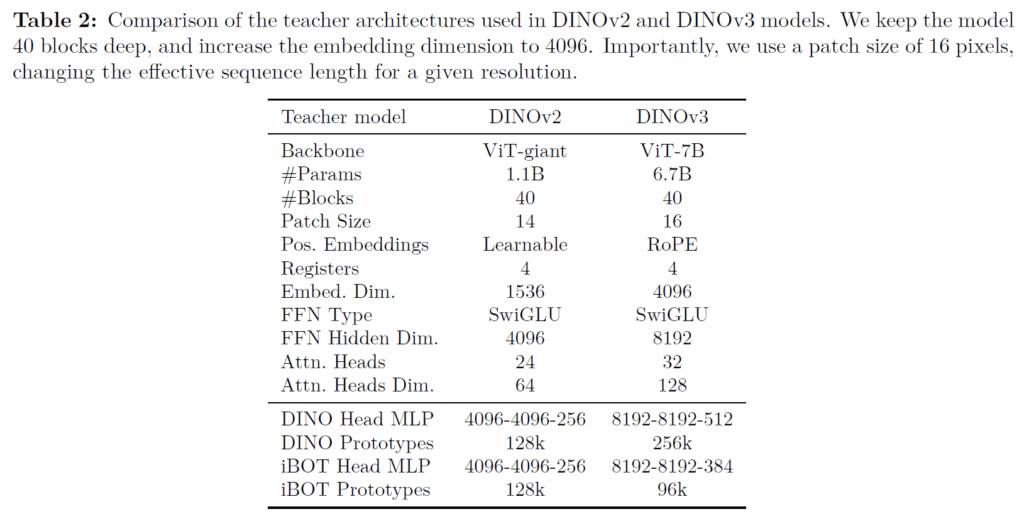
한가지 눈여겨보실 점은, Positional embedding을 할 때 기존 DINOv2는 nn.Paramter를 통하여 Learnable한 방식을 사용한 반면에 DINOv3에서는 요즘 잘나가는 Transformer 모델이면 다 활용한다는 RoPE 방식을 채택했다는 점입니다. 저자들은 이 임베딩 방식이 DINOv3가 상세하고 견고한 시각적 특징을 더 잘 학습할 수 있게 하여 성능과 확장성을 향상시키는데 도움을 준다고 하네요.
그리고 모델을 학습시키기 위한 optimization 과정에서도 저자들의 상당한 고찰?이 담겨져있습니다. 우선 7B이나 되는 거대 모델을 10억개가 넘는 데이터로 학습하는 것은 매우매우 복잡한 실험 구성이라고 저자들은 말합니다. 즉 모델의 수용 능력과 학습 데이터의 복잡성 사이에서 최적화하는 과정은 매우 복잡하고 학습 과정에서 최적의 순간을 판단하기 까다롭게 때문에, 적절한 최적화 기간을 추측하는 것은 사실 불가능하다고 합니다.
그래서 저자들은 기존의 SSL에서 많이 활용하는 파라미터 기반의 스케쥴링을 모두 제거하고 그냥 고정된 상수 LR, weight decay 그리고 teacher EMA momentum을 활용했다고 합니다. 이렇게 하였을 때 이점으로는, 그냥 downstream 성능이 최대 성능 지점으로 수렴할때까지 계속 쭉 학습시킬 수 있다는 이점이 있으며, 많은 최적화 하이퍼파라미터가 감소되어 적절한 값을 튜닝하는데 있어 오히려 더 편하였다고 합니다.
물론 그래도 학습 안정성을 위해서 Learning Rate에 대한 linear warmup과 teacher temperature는 사용했다고 합니다.
Gram Anchoring: A Regularization for Dense Features
다음은 제가 DINOv3 논문을 읽었을 때 개인적으로 가장 중요한 contribution 중 하나라고 생각되는 부분입니다. 제가 본 리뷰에서 간간히 언급한 내용 중 하나가 바로 dense-level feature(patch)의 표현력이 떨어진다 라는 식의 언급을 드렸었는데 사실 말로만 언급하고 넘어가고 구체적인 내용들은 전혀 다루지 않았거든요. 해당 파트가 그 문제점과 이를 어떻게 해결했는지에 대한 내용을 다루게 됩니다.
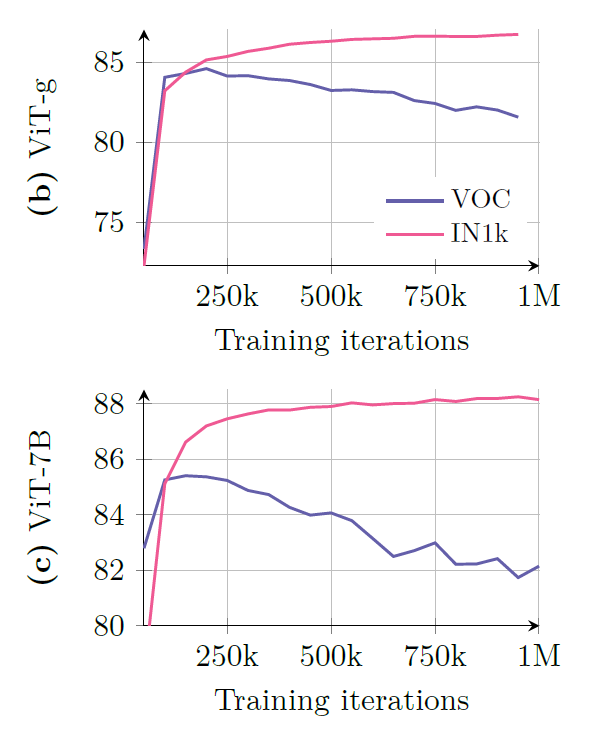
우선 위의 그림1은 ViT-G와 ViT-7B 모델이 1M iteration까지 pretrain되었을 때, 각각 ImageNet 1K 데이터셋과 pascal VOC segmentation에서 어떤 성능을 보여주는지를 평가한 결과입니다. 공통적으로 보아야할 점은, 1M까지 계속 학습하면 할수록 IN1K 데이터셋에서의 성능은 꾸준히 증가하는 반면에, VOC 데이터셋에서의 성능은 오히려 하락한다는 점입니다. 특히 그 하락의 폭이 ViT-7B와 같은 더 많은 파라미터 수를 가지는 모델에서 발생하고 있습니다.
여기서 ImageNet은 분류 문제이기 때문에 모델의 global feature representation이 성능 향상에 상당히 큰 영향을 미치고 있다는 점이고, VOC의 경우 segmentation task이기 때문에 local patch의 representation이 좋아야만 Segmentation에서도 좋은 성능을 보여줄 수 있다는 점입니다.
근데 IN1k에서는 1M iteration으로 학습을 진행할수록 성능이 좋아지는 반면에 VOC의 성능은 떨어진다는 것이고, 이는 바꾸어말하면 모델이 학습을 진행할수록 global feature representation은 좋아지지만, 반대로 patch-level feature representation에서는 표현력이 감소한다고 볼 수 있습니다. 저자들은 이를 patch-level consistency가 줄어든다고 표현을 하고 있고 해당 표현을 강하게 밀고 있어서 해당 리뷰에서도 일치/불일치 등으로 표현하겠습니다.
사실 모델 학습을 계속 진행하면 진행할수록 global level의 특징 표현력은 향상되는 반면에 local patch의 표현력은 점점 낮아지고 불일치해지는 경향성을 확인하는 것은 이번 DINOv3 논문에서 처음 발견된 사실이 아니라 DINOv2, 그리고 그 외에 다른 최신 연구에서도 관측된 결과였습니다. 근데 아직도 이 문제를 제대로 해결한 논문은 없다고 저자들은 이야기하네요.
우선 그림1을 다시 한번 살펴보면, VOC dataset의 segmentation도 대략 100~200K 정도까지는 성능이 향상이 되고 있습니다. 즉 어느정도까지는 feature의 표현력이 global과 local 모두 향상되고 있지만, 특정 지점(아마 200K 이상)부터는 점점 patch-level의 특징들이 문제가 발생하는 것이죠.
저자들은 구체적인 분석을 위해 아래 그림과 같이 patch feature들 간의 코사인 유사도를 시각화하였다고 합니다.

저 붉은색 패치를 기준으로 해당 패치와 코사인 유사도가 높은 패치들은 밝은 노란색을, 관련성이 떨어지면 어두운 색으로 표현이 됩니다. 저자들이 말하길, 200K정도 iteration으로 학습된 모델의 유사도 맵은 부드럽고 localization도 잘되며, 패치레벨의 표현력이 일정하였다고 합니다.
근데 이제 600K 이상으로 학습하게 되면 feature map의 품질이 급격히 떨어지게 되는데, 사람의 주관으로 판단하였을 때는 (붉은 점)reference patch와 관련없는 패치들의 수가 증가하였으며, 이러한 경향성이 dense-task performance 성능에 하락과 연관이 있다고 저자들은 추측하였습니다.

그랫 저자들이 다음으로 분석한 것으로는 CLS 토큰과 나머지 patch 토큰들 사이의 코사인 유사도가 어떻게 되는지를 판단하였는데 앞서 그림6의 결과에서 추측할 수 있듯이, 학습 초기(200K 이내)에서는 CLS token과 patch token들간의 유사도가 높지 않지만, 학습하는 점차 진행됨에 따라 점진적으로 유사도가 커지더니 1M에서는 거의 대부분의 영역과 CLS token이 높은 유사성을 뛰는 것을 확인할 수 있습니다.
이래서 학습을 오래 할수록 global representation이 중요한 task에서는 CLS token이 더 좋은 특징을 가지고 있어 좋은 성능을 내고 있는 것이고 반대로 dense-level prediction에서는 각 patch token들 간의 유사도가 떨어지고(즉 일관성이 없음) CLS token과의 유사도만 높은 바람에 성능이 떨어지는 것이죠.
Gram Anchoring Objective
우선 위 코사인 유사도 그림과 세그멘테이션/분류 성능 실험 등을 통해 저희는 모델이 global level에서 구분력 있는 특징을 추출하는 것과 local level에서 패치들간에 일관성을 유지하려는 것은 서로 독립적인 학습 방향임을 확인할 수 있었습니다. 기존에 DINOv2가 global DINO1 loss와 iBOT loss를 통해 이 global과 local level representation 두마리 토끼에 대하여 모두 잡아보려고 했지만 여전히 둘 사이의 밸런스가 해결되지 않은 채 학습 과정이 진행됨에 따라 global representation에 지배당하고 있음을 저자들은 주장합니다.
따라서 저자들은 특징 map 자체에는 크게 영향을 주지 않으면서 패치 레벨 일관성의 품질을 강제함으로써 패치 레벨 특징들의 표현력 저하를 완화하는 새로운 목적함수를 제안하였는데 그것은 바로 Gram matrix를 통한 loss function입니다.
구체적으로, 저자들은 학습 초기 모델(예를들어 200K iteration까지만 학습된 ViT 모델)을 Gram teacher로 두고, student의 gram matrix가 gram teacher와 유사해지도록 하였습니다. 수식으로 표현하면 아래와 같이 표현할 수 있겠네요.
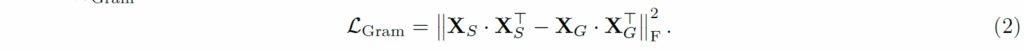
여기서 X_{S}, X_{G} 는 각각 student와 gram teacher의 feature map을 의미하고 있고, 해당 feature map은 P x d의 shape을 가지는데 여기서 P는 이미지에 대한 visual token의 개수를 의미하고 d는 해당 token의 임베딩 차원 수를 의미합니다.
즉 gram matrix란 동일 행렬의 내적을 보통 의미하는데, 차원축으로 내적하였기 때문에 해당 gram matrix의 결과값은 P x P의 shape을 가지는 행렬이 될 것이고 이는 저희 self-attention 연산 할 때 Query와 Key에 대하여 내적하는 것과 동일하다고 보시면 될 것 같습니다. softmax만 안취했을 뿐이에요.
재밌는 점은 ViT 모델을 우선 1M iteration 까지 학습시킨 이후에 gram loss를 적용하더라도 local feature가 다시 좋은 표현력을 가지도록 바뀌어간다는 점입니다. 그리고 Gram teacher의 경우에는 10K iteration마다 main EMA teacher와 동일한 weight으로 수정해준다고 하네요. 결과적으로 DINOv3는 아까 수식1로 1M까지 사전학습한 뒤 아래 수식3을 통해서 추가적인 tuning을 진행하게 됩니다.
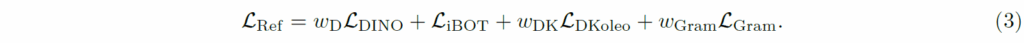
위에 그림은 수식3을 통해 1M iteration 이후의 추가로 tuning하였을 때 iBOT loss와 DINO global loss가 어떻게 수렴되는지, 그리고 gram loss 값이 어떻게 수렴되는지를 나타내는 결과입니다. 제일 좌측 bot loss의 수렴 그래프부터 살펴보시면 한 100k정도?까지는 잘 수렴하다가 학습이 진행될수록 loss 값이 점점 커지는 것을 볼 수 있습니다. 근데 이제 1M iteration 이후에 gram loss를 적용할 때부터는 다시 또 2점대로 내려가는 모습을 보여주고 있네요. 반면에 DINO global loss의 경우에는 그게 문제없이 잘 수렴하고 있다가 gram loss가 적용되는 1M 이후에는 loss의 진동폭이 커지는 모습을 볼 수 있습니다.
이를 통해 저자들은 Gram loss와 iBOT loss가 local patch level에서 특징맵에게 유사한 방향성의 guide를 주는 반면에 DINO global loss는 다르게(global feature쪽으로) 영향을 줌을 주장합니다.
Leveraging Higher-Resolution Features
다음은 gram loss를 적용할 때 조금 더 진보된? 방향으로 적용하는 방법론을 소개하는 부분입니다. 최근 한 연구에서 패치 특징들을 가중합하는 것이 더 강력한 지역 특징 표현력을 야기할 수 있음을 보였으며, 이는 패치의 outlier들을 스무딩하고, 패치 레벨의 일관성을 향상시키기 때문이라고 주장하였습니다.
이러한 기존 연구의 발견과 또 한가지 상식적인 부분인 고해상도 이미지를 넣으면 더 세부적이고 선명한 특징들을 생성할 수 있다는 점을 접목시켜 저자들은 2가지 방식을 접목하였습니다. 구체적으로, Gram teacher에 입력으로 2배 upsampling한 image를 넣어서 feature map을 추출한다음 이들을 2배 다운샘플링해서 student output가 사이즈를 맞춤과 동시에 의도한대로 smooth 특징을 취득하는 것이죠.
결과적으로, 업샘플링해서 특징 추출한다음에 downsampling하니깐 patch level 표현력들이 더 세밀하면서도 부드럽고 일관성 있게 바뀌었더라는 점이고, 이에 대한 결과들은 아래 그림8,9에서 확인이 가능합니다.
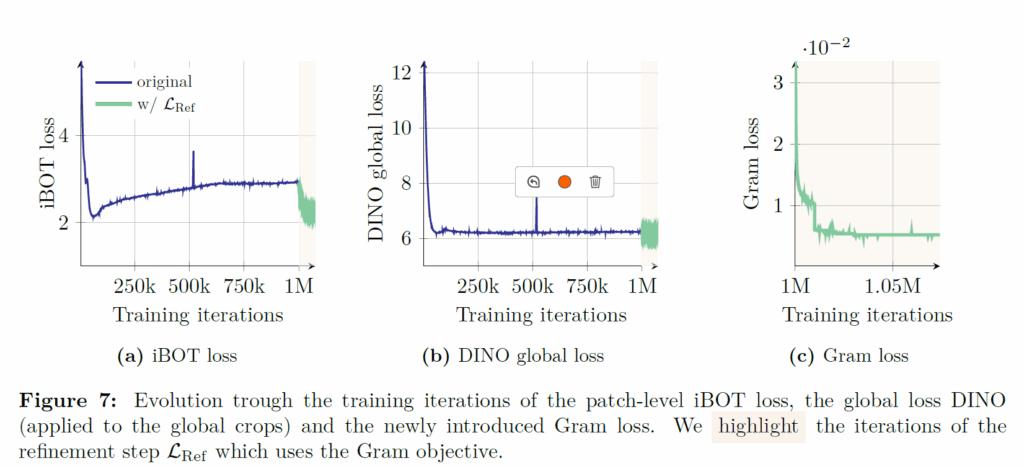
우선 그림8을 살펴보면, VOC, ADE20k이 segmentation task를 의미하는데 1M iteration까지 모델의 성능이 점점 감소하다가 갑자기 Gram loss가 적용되는 1M 이후 시점에서 모델의 성능이 초기 100~200K iteration과 동일해지거나 더 높은 성능을 달성하는 것을 보실 수 있습니다. 그리고 연두색 라인 말고 주황색 라인이 방금 소개드린 해상도를 더 높인 상태에서 feature를 추출한 뒤 down-sampling하여 gram loss를 계산하는 방식인데 이렇게 할 경우 초기 학습 단계를 능가하는 특징 성능을 달성할 수 있게 됩니다.
그리고 gram loss를 적용했다고 하여 ObjectNet과 같이 global feature representation이 중요한 task에서도 성능 하락없이 없다는 점입니다.
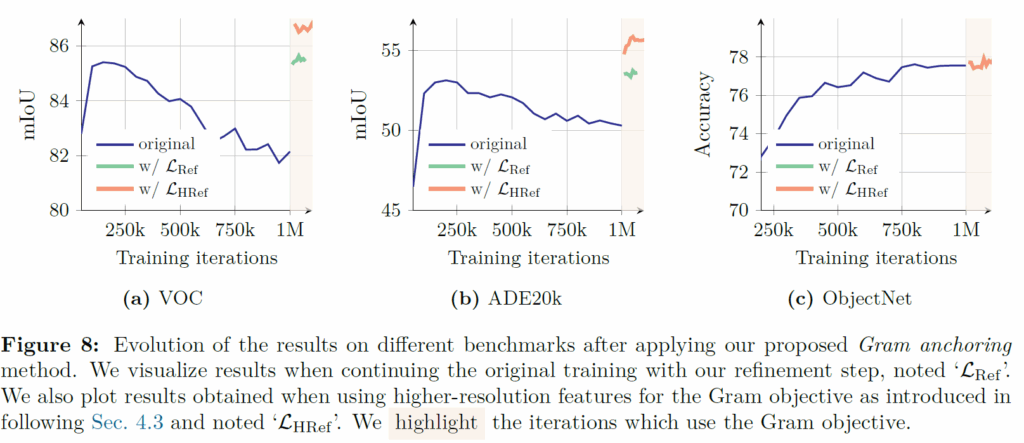
그림 9는 256 resolution에서 추출한 feature map과 512에서 추출한 feature map 그리고 512에서 추출한 feature map을 다시 256으로 다운샘플링했을 때의 feature map을 시각화한 것인데, downsample과 256의 특징 시각화 맵을 비교해보면 상대적으로 downsample이라고 명시된 feature map이 더 부드러우면서 일관성 있는 패치 유사도를 가지고 있음을 볼 수 있습니다.
그림 9 좌측에 테이블은 Gram Teacher 계산할 때 몇 iteration까지 학습한 모델을 사용할 것인지와 resolution을 원본으로 사용했을 때, 2배 키워서 사용했을 때에 대한 성능 결과표를 나타낸 것인데 결론만 말씀드리면 100k든 200k든 학습 초기에 모델을 사용하는 것이라면 iteration 수가 모델 정확도 관점에서 크게 중요하지는 않으며 다만 1M과 같이 학습이 이미 많이 진행된 모델을 gram teacher로 활용하는 것은 성능 향상 폭이 제한적이긴 하다.(근데 또 생각보다 아무것도 적용안한 baseline보다는 더 좋아보이는데 아무래도 resolution을 2배로 키워서 인것 같기도 하네요.)
그리고 resolution을 더 높여서 특징을 추출한 뒤 down-sampling하여 gram matrix 계산하는 것이 모델 성능에 더 좋은 영향을 준다는 점이 있겠네요.

위에 그림10은 gram loss를 적용할 때 고해상도 feature를 썼는지 안썼는지 그 여부에 따라서 학습된 모델의 feature map 표현력이 어떻게 되는지를 나타낸 것으로 고해상도 feature로 gram loss를 계산한 경우 더 부드러운 결과값을 얻을 수 있음을 보실 수 있습니다.
Experiments
다음은 실험 결과입니다. 우선 정말 다양한 down-stream task에서 실험을 진행하였는데, 저는 깔끔하게 Dense level prediction task인 segmentation과 depth estimation, 그리고 3D correspondence estimation task에 대해서만 리포팅하고 리뷰 마무리 짓겠습니다. 더 많은 실험이 궁금하신 분들은 논문을 읽어보시는 것을 추천드립니다.
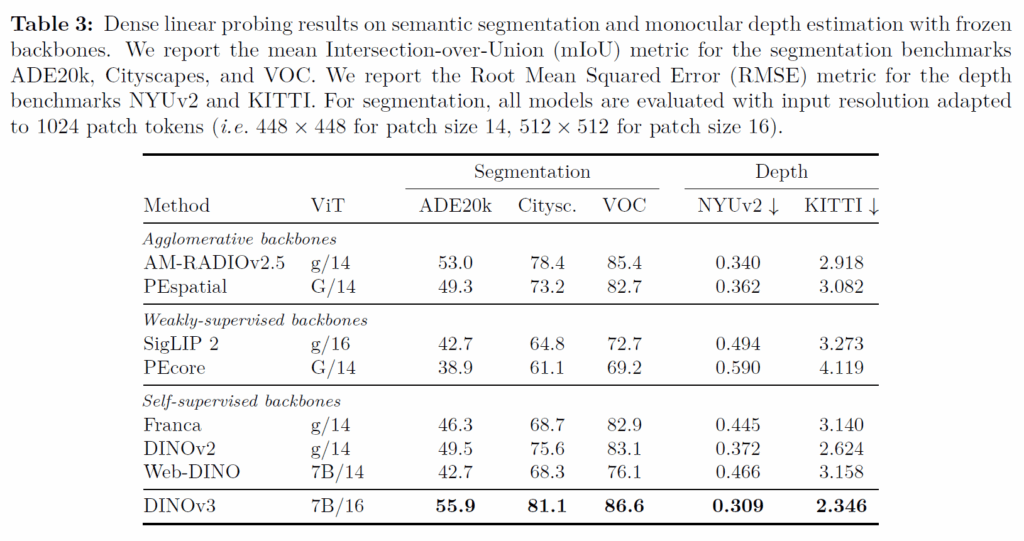
위에 표는 Segmentation과 Depth estimation에 대해서 총 5개의 데이터셋으로 평가한 결과값이고, 현재 테이블에서는 해당 task의 SOTA와 비교한 것은 아니며 기존의 쟁쟁한 Self-supervised learning 기반의 Foundation model들과 downstream task에서 얼만큼의 성능 차이가 나는지를 평가한 것입니다.
참고로 모든 실험들은 백본들은 freeze 된 상태에서 task-specific한 layer들만 새로 학습된다는 점을 말씀드립니다. 결과적으로 DINOv3가 그냥 압도적인 결과를 내고 있습니다. 물론 Web-DINO를 제외하고는 다른 모델들의 사이즈가 ViT giant 수준이에요. 그래서 모델 크기가 DINO-7B랑 비교했을 때 대략 6배정도 차이가 나는 것 같은데, 일단 비교할만한 상대가 7B가 없고 giant 수준밖에 없다는 점에서 이미 저자들이 계속 문제 삼아왔던, vision쪽 SSL이 모델 scale up이 잘 되지 않더라는 문제점이 드러난다고 볼 수 있겠습니다.
즉 7B 이상으로 모델을 학습시키고 싶어도 오히려 성능이 더 떨어진다는 점이고 그걸 잘 보여주는 것이 바로 Web-DINO가 7B 사이즈임에도 불구하고 오히려 DINOv2로 학습한 ViT-G보다 모든 dataset에서 성능이 떨어진다는 점입니다. 즉 무작정 모델 사이즈 키운다고해서 dense-level prediction 성능이 오르는 것이 아니라는 것을 잘 보여주는 것이죠.
하지만 DINOv3의 경우에는 Gram loss와 data curation, 다양한 SOTA 학습 방법론들을 적용한 덕에 충분히 7B에서 스케일 업이 가능했으며 결과적으로 가장 좋은 성능을 달성할 수 있었습니다.
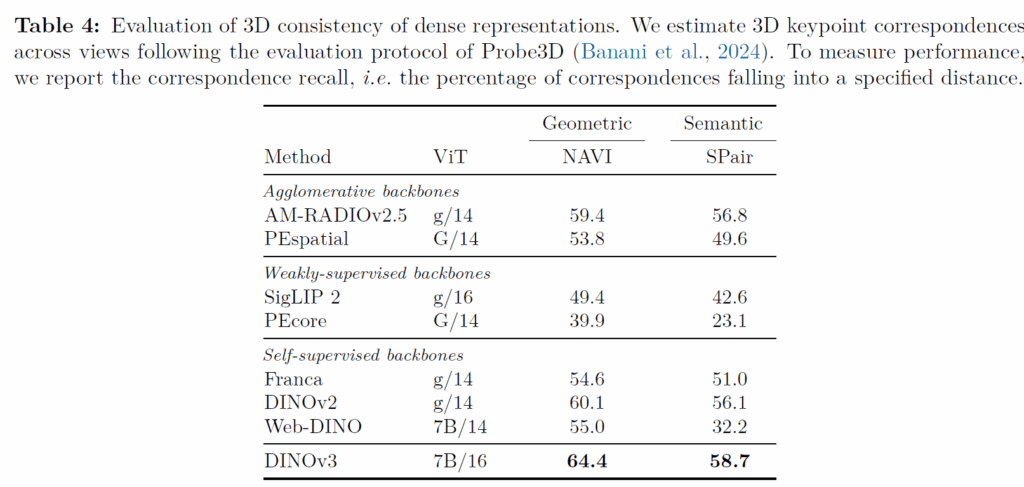
다음 표는 3D consistency에 대한 실험인데, 저 Geometric이라고 적힌 부분은 동일 객체에 대해 서로 다른 view point에서 촬영한 영상에서 key point matching을 해야하는 task이며, semantic의 경우에는 동일한 object class이지만 실제로는 다른 객체들끼리 의미론적으로 유사한 영역을 매칭하는 작업을 의미합니다. (즉 철수네 강아지와 영희네 강아지의 눈,코,입,꼬리 등은 같은 강아지기 때문에 의미론적으로 같은 부분이므로 매칭할 수 있어야 한다는 것)
이것도 결론만 말씀드리면, 저자들의 방법론이 가장 좋은 성능을 보여준다는 점이며, semantic matching의 경우에는 사실 DINOv2도 원래 잘하긴 했어요. 그래서 DINOv3의 경우에도 성능 향상폭이 2.6%밖에 안난다는것이 아쉽긴 한데 Web-DINO가 성능이 크게 감소하는 것을 보아 7B으로 스케일링 업하면서 모델의 local patch에 대한 일관성이 하락하는 현상이 심해지는 것을 DINOv3는 잘 해결하여 모델의 스케일링 업을 성공적으로 마칠 수 있었다는 점에서 긍정적으로 보아야한다고 생각이 드네요.
마지막으로 아래 사진은 이전의 Vision foundation model들과의 feature map을 비교 시각화한 결과입니다. 해당 결과는 featutre map을 PCA를 통해 눌러서 계산한 것인데, SigLIP이나 PE Spatial, DINov2의 경우에는 자글자글한 noise? 고주파 성분들이 많이 보이는 반면에 DINOv3의 경우에는 Gram loss를 통해 잘 학습시켜서 인지 상당히 인접 patch들 간의 일관성 있는 결과값들을 보여주는 모습입니다.

결론
우선 논문이 너무 길고 그러다보니 제가 본 논문의 내용을 다룬 것보다 못 다룬 내용들이 더 많다고 생각합니다. 시간이 되신다면 한번쯤 직접 읽어보시는 것을 추천드리고, 저 같은 경우에는 depth estimation과 같은 pixel-level prediction task에 관심도 많고 연구를 해왔기 때문에 이번 DINOv3의 결과가 상당히 인상깊고 흥미롭게 다가오네요.
그리고 이전 DINOv2의 경우에는 224×224 resolution에 토큰 길이를 16×16으로 맞추기 위해 패치 사이즈가 14라서 feature map의 해상도를 1/14로 다운샘플링하여 CNN과 같이 2배씩 다운샘플링하는 방법론들과 엮기에 은근히 불편하고 아쉬움이 많았는데 이번 V3에서는 256×256 해상도를 기준으로 16×16개의 토큰수를 유지하기 위해 패치 사이즈가 16으로 늘었습니다. 즉 입력 해상도의 1/16배로 다운샘플링을 한다는 점이죠. 이 점이 저는 개인적으로 가장 마음에 들었습니다ㅋㅋ.
아무튼 제개 생각했을 때 DINOv3의 시각화 결과값이 DINOv2를 처음봤을 때만큼 상당히 인상적이니 다들 개인 연구에 DINOv3를 잘 활용해보면 좋을 듯 싶습니다.