안녕하세요, 76번째 x-review 입니다. 이번 논문은 2024년 11월 arXiv에 올라온 PriorDiffusion이라는 논문 입니다.
그럼 바로 리뷰 시작하겠습니다

1. Introduction
Monocular Depth Estimation(MDE)는 최근 diffusion 기반의 모델들을 통해 높은 퀄리티의 depth map을 생성하는 연구가 진행되고 있는데요, 이는 latent 표현력을 통해 노이즈를 제거함으로써 정확안 depth 예측이 가능합니다. 그러나 MDE는 여전히 본질적으로 모호함과 시각적인 방해 요인이 존재한다고 하는데, 스테레오와 다르게 단안으로는 여러 시점에서 제공되는 depth를 위한 단서들을 사용하기 어렵기 때문입니다. 이로 인해 물체들의 상대적인 크기나, 거리, 그리고 공간적인 정확한 관계를 파악하는데 어려움이 발생합니다.
모호함이라는건 같은 이미지가 여러 3D 장면으로부터 투영될 수 있기 때문에 발생하게 됩니다. 이러한 모호성을 크게 2가지로 예시를 들어 설명하는데, 그 중 첫번째는 텍스처 모호성 입니다. 반복되는 패턴이나 균일한 텍스처를 가진 표면은 모델이 이걸 depth가 균일하다고 잘못 해석할 수 있다는 것 입니다. 실제로는 타일 같은게 멀리 뻗어가면서 depth가 점점 달라지지만, 모델은 반복적인 패턴만을 보고 depth가 일정하다고 착각할 수 있는 것이죠. 두번째는 가시성 모호성으로, 작거나 일부만 보이거나 혹은 가려진 물체들은 순수하게 그것을 시각적이라는 시그널로 판단하는 것이 어렵습니다. 추가적으로 조도 변화나 모션 블러 같은 요소들이 시각적 방해 요인으로 적용되어 depth의 경계나 장면의 구조를 잘못 해석하도록 유도할 수 있습니다.
그래서 최근에는 텍스트를 보조적인 모달리티로 활용하여, 모호성과 시각적인 방해 요인을 해결하는 사전 정보로 삼고자 하였습니다. language description은 장면의 공간적인 관계나 그 장면이 어떤 유형인지, 그리고 물체의 실제 크기와 같은 다양한 사전 지식을 제공할 수 있습니다. 특히 물체가 작거나, 부분적으로 가려져 있을 때, 그리고 이미지 하나만으로는 물체의 종류가 불분명할 때와 같은 상황에 텍스트가 모델에 더 크게 도움이 된다고 합니다.
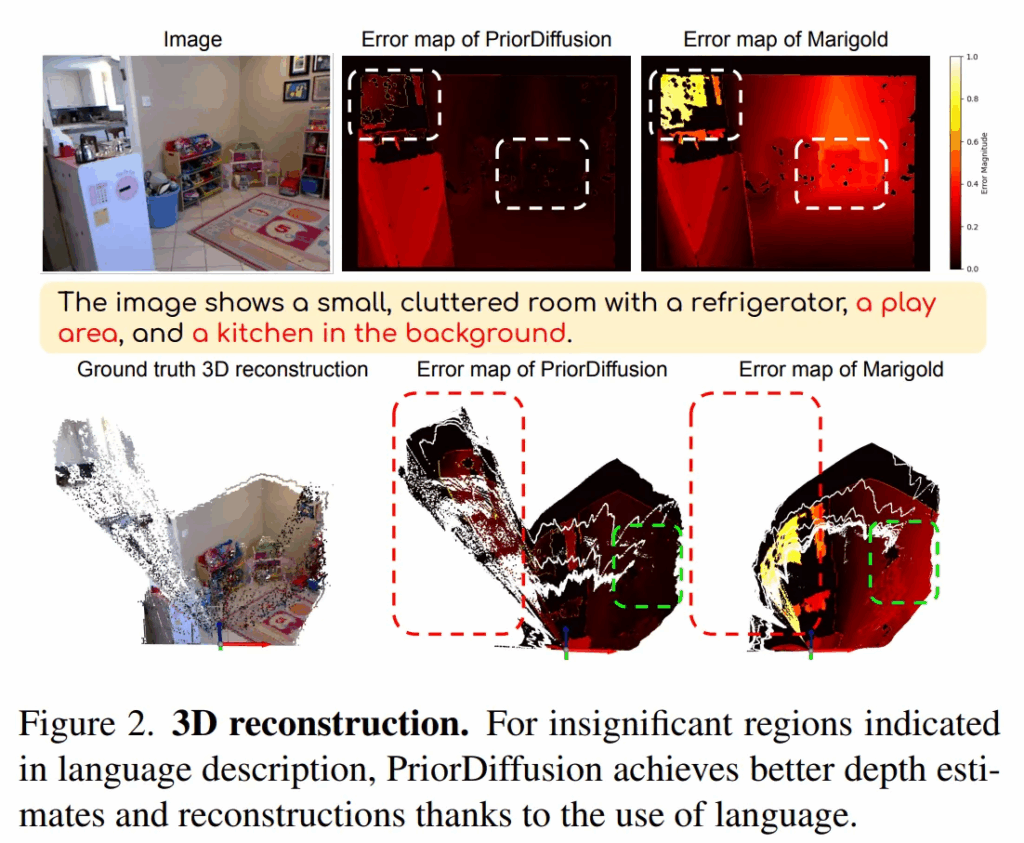
또한 텍스트는 텍스처 모호성에도 도움이 되는데요, 장면 내 표면의 유형이나 기능에 대한 정보를 포함할 수 있어서 모델이 기하학적인 특성을 파악하는데 효과적이라고 합니다. 예시를 들어보면, 하얀색 천장이라는 텍스트 설명이 들어오면, 모델은 이걸 일관된 depth로 사람의 눈 앞에 펼쳐진 연속적인 평평한 면이라고 이해할 수 있습니다. 그리고 빨간색과 검은색이 섞인 카펫이라는 설명이 들어온다면, 모델은 반복되는 패턴이 평평한 표현이라는 걸 인식해서 타일 사이의 경계를 depth가 변한다고 잘못 인식하지 않을 수 있다는 것 입니다. Fig.2를 보시면, 텍스트 설명으로 명시된 비교적 중요하지 않은 영역에 대해서도 모델이 제대로 인지하여 표현하고 있는 것을 확인할 수 있습니다.
이러한 텍스트적 특성을 이용해서 본 논문에서는 PriorDiffusion이라는 방법론을 제안합니다.
이는 입력으로 들어오는 장면에 대한 언어적 사전 정보를 inductive bias로 활용하여 depth map을 예측하였습니다. 모델도 모델이지만, 본 논문에서는 실제 application 관점에서 이 PriorDiffusion을 탑재한 에이전트가 환경을 인식하는데 있어서 사람이 환경을 텍스트로 설명해줌으로써 더 나은 depth 예측이 가능해짐을 어필하고 있습니다. 또한 새로운 환경에 대한 일반화 측면에서도, 텍스트는 이미지보다 covariate shift가 작기 때문에 사람이 새로운 환경에 대해 설명하는 것이 에이전트가 일반화를 이루는데 도움이 된다고 합니다.
이러한 본 논문의 main contribution을 정리하면 다음과 같습니다.
- 텍스트 사전 정보는 물체나 기하학적인 특성에 대한 inductive bias를 제공함으로써 depth estimation 모델이 해당 물체들의 depth를 더 잘 예측하도록 유도
- 텍스트 사전 정보는 유저의 의도에 따라 3차원 장면을 인식할 수 있으며, 특히 작거나 어둡고 가려져 있는 등 이미지만으로 구분이 어려운 영역에 효과적임을 증명
- 텍스트 사전 정보는 학습 시 빠른 수렴에 효과적이며, inference 단계에서도 좋은 초기화 역할로 작용하여 diffusion 모델의 효율과 resource 사용을 최적화
2. Method
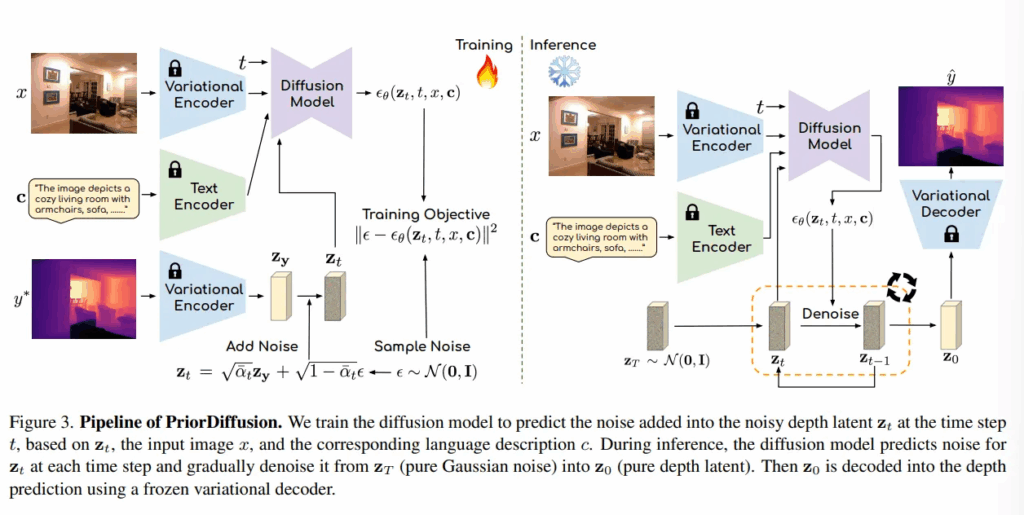
Forward diffusion process
diffusion의 forward 과정은 depth latent를 노이즈가 점점 추가된 버전으로 바꾸는 과정으로, 나중에 이 노이즈로부터 다시 원래 depth를 복원하는 학습을 할 수 있도록 준비하는 단계라고 할 수 있습니다.
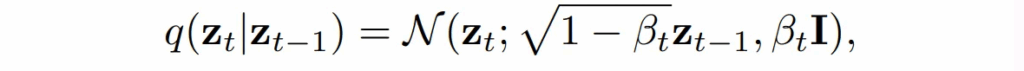
위의 식은 timestep t-1의 z에 노이즈를 추가해서 다음 스텝의 z_t를 만드는 과정을 식으로 정의한 것 입니다. depth를 점점 노이즈로 변형하면서 완전히 랜덤한 노이즈 형태인 아래의 z_T까지 만들게 됩니다.
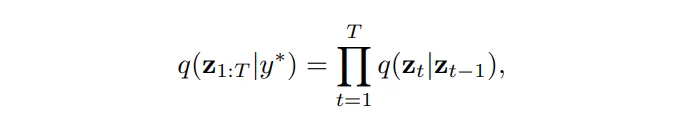
- y^* : GT depth map
Reverse diffusion process
다음 reverse diffusion 과정은 위의 forward에서 만들어진 완전한 노이즈 z_T를 다시 depth map z_0으로 복원하는 과정 입니다. 학습은 바로 이 노이즈를 제거하는 방법을 학습하게 되는 것이죠.
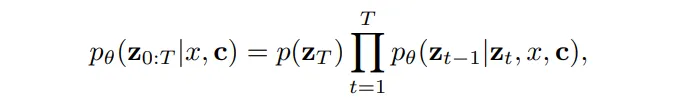
- p_{\theta}(z_t - 1 | z_t, x, c) : 시간 t에서 z_t를 보고, 그 전 timestep의 z_{t-1} 예측
- x, c : 이미지와 텍스트
즉 노이즈 상태에서 한 단계씩 노이즈를 제거하면서 원래의 depth map을 복원해나가게 됩니다.
그럼 이걸 어떻게 학습하냐면, 먼저 텍스트 c는 CLIP의 텍스트 인코더를 통해 feature를 추출합니다. 그 다음 이미지 x는 VAE 인코더로 feature를 추출하고, 또 하나 노이즈 depth z_t가 있겠죠. 이 세가지를 입력으로 하여 U-Net 기반의 diffusion 모델이 z_{t-1}를 예측합니다.
Training Objective
학습 때 loss는 아래와 같은데요, 노이즈를 예측하는 loss 함수라고 보시면 될 것 같습니다.
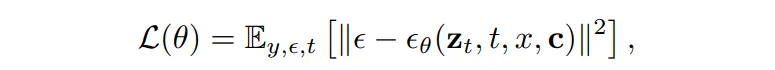
- \epsilon : 실제 샘플링된 정규 분포 노이즈
- \epsilon_{\theta} : 모델이 예측한 노이즈
두 노이즈 사이의 loss를 통해 모델이 얼마나 정확하게 노이즈를 예측하는지를 계산하게 됩니다.
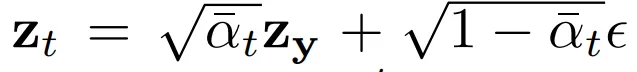
- z_y : 원래 GT depth map을 VAE 인코더로 변환한 latent 표현
각 timestep의 z_t는 위와 같이 생성할 수 있습니다. diffusion 모델은 노이즈를 제거하는 능력을 학습해야 해서 원래는 노이즈가 섞인 z_t가 필요한데, 실제 학습 데이터에는 z_t가 없죠. 실제 입력으로 들어가는건 깨끗한 depth map y 뿐이기 때문에 z_t를 인위적으로 만들어야 해서 위의 식과 같이 학습 입력을 만들게 됩니다.
Inference
inference 때는 이제 완전한 노이즈 상태에서 시작하여 반복적으로 denoising하여 depth map z_0을 생성하면 됩니다.
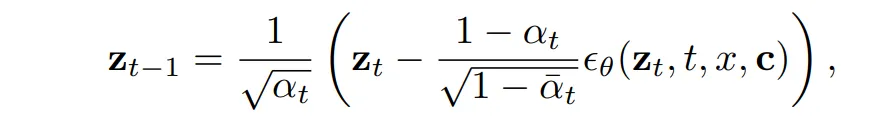
완전한 가우시안 노이즈 z_T ~ \mathcal{N}(0, I)부터 시작해서 반복적으로 위의 식과 같이 denoising을 수행합니다. 모델이 예측한 노이즈를 점점 제거하면서 최종적인 depth map으로 복원하는 과정이죠.
그 다음에는 복원하는 depth 표현은 latent 차원이기 때문에 \hat{y} = D(z_0)과 같이 VAE 디코더를 통해 원래이미지 차원의 depth map으로 변환하면 완전히 denoising된 depth map을 생성할 수 있게 됩니다.
여기까지가 본 논문의 방법론 전부인데요 .. 제가 이전에 리뷰한 WorDepth의 후속 연구라 기대하면서 읽었었는데 메소드에서 눈에 띄는 novelty는 찾지 못한 것 같습니다. 설명한 부분은 거의 기본적인 diffusion의 동작 과정 설명이고, detph estimation에 depth map과 텍스트를 동시에 넣은 것 이외의 무언가 있진 않았습니다 ㅎㅎ ; 그래서 작년 11월에 arXiv에 올라오고 아직 여느 학회나 저널에 accept되지 못한게 아닐까 생각이 들기도 하네요 . ..
3. Experiments
학습은 HyperSim과 Virtual KITTI로 학습하고, 평가는 4개의 real 데이터로 zero shot 평가를 수행하였다고 합니다. 그리고 이미지에 대한 텍스트 설명은 LLAVa v1.6을 이용하여 생성하였습니다.
Quantitative comparison
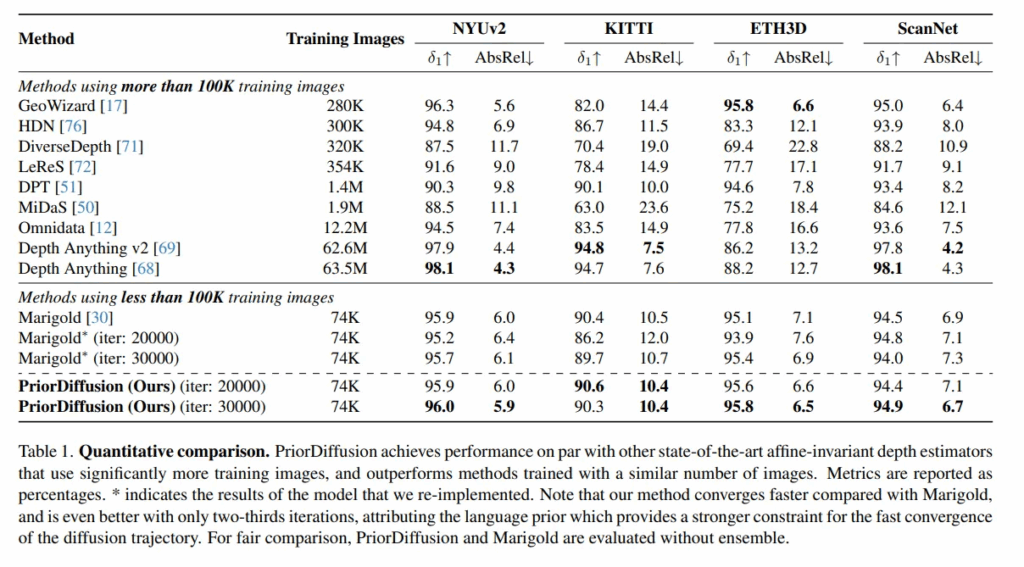
먼저 Tab.1은 정량적 실험 결과로, PriroDiffusion은 훨씬 더 많은 학습 이미지를 필요로 하는 최신 방법론들과 비교했을 때 비슷한 성능을 보이고 있습니다. 또한 비슷한 수의 이미지로 학습된 Marigold나 다른 방법론들보다는 더 좋은 성능을 달성하였습니다.
또한 PriorDiffusion의 강점은 빠른 수렴 속도인데, Marigold는 30,000번의 iteration 반복 후에 도달할 수 있는 성능이 PriorDiffusion은 20,000번 반복만으로 비슷하거나 더 나은 성능을 달성한 것을 확인할 수 있습니다. 이러한 결과는 저자가 인트로에서 말한 것처럼, 모델에 언어 정보가 통합되었기 때문으로, 이 언어 정보가 semantic하고 기하학적인 제약 조건으로 작용하여 diffusion의 학습을 가속화할 수 있었기 때문이라고 분석하고 있습니다. 다시 얘기하면, 이미지로부터 모든 정보를 학습하기 위해 많은 계산량과 resource가 필요한데, 텍스트는 텍스트 입력 안에 압축된 저차원의 형식으로 정보가 들어있기 때문에 모델이 더 쉽게 학습할 수 있는 구조가 된다고 합니다.
Qualitative comparison

정성적으로 봤을 때도, 텍스트 정보가 모델이 특정 영역을 집중해서 볼 수 있도록 유도한다는 걸 보여줍니다. Fig.4는 NYUv2 데이터셋에 대한 정성적 결과인데, PriorDiffusion은 입력 이미지에 대해 Marigold보다 더 정확한 결과를 보여주고 있습니다. 이러한 차이는 텍스트 설명에서 강조된 물체에서 두드러지게 보이는데, 첫번째 행에서 비누 디스펜서가 배경과 색깔이나 텍스터가 유사해서 입력 이미지에서는 거의 구분이 불가능한 것을 알 수 있습니다. Marigold와 같은 기존의 depth 추정 보델은 이러한 물체를 잘 구별하지 못하고 배경과 동일한 depth로 예측을 하고 있습니다. 반면 텍스트 설명에 비누 디스펜서라는 단어가 명확하게 포함되어 있으면, PriorDiffusion은 이 물체의 형태나 공간적이 위치에 대한 사전 정보를 얻게 되어, 해당 영역의 depth를 더 정확하게 추정할 수 있는 것을 확인할 수 있습니다.
Fewer denoising steps
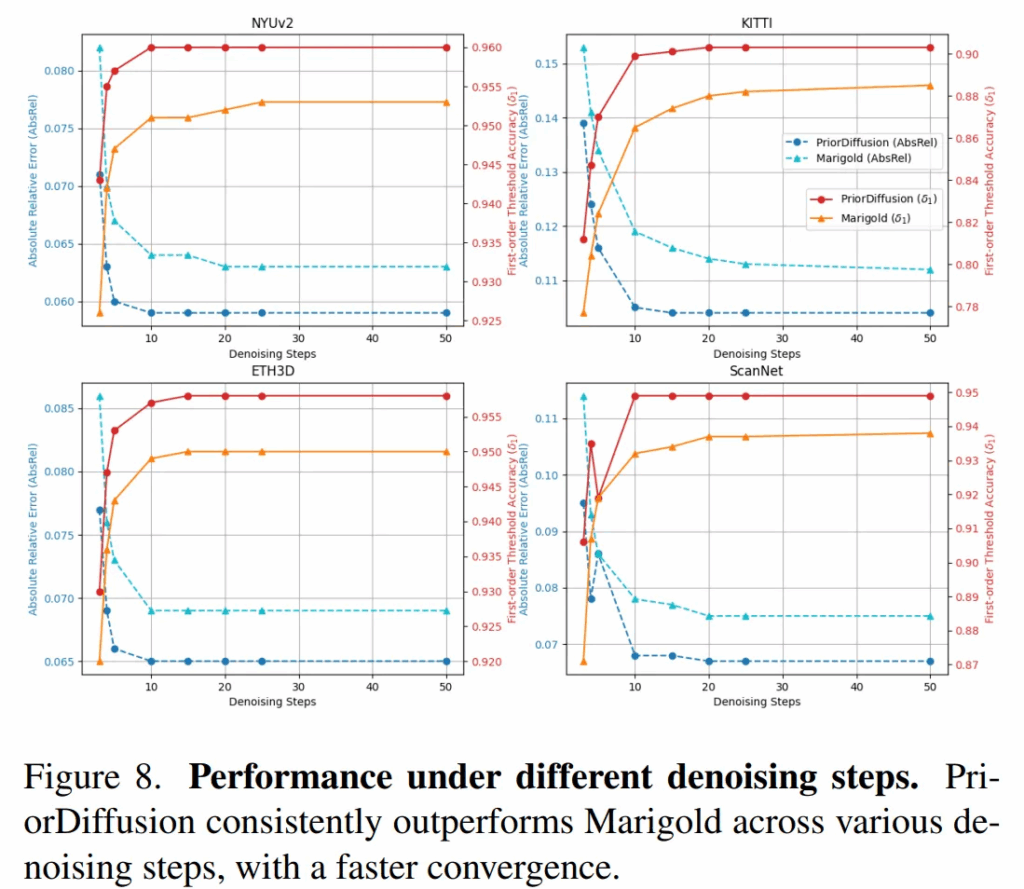
이제 ablation study로, 먼저 Tab.4와 Fig.8은 inference 단계에서의 denoising 횟수에 대한 실험 결과 입니다. PriorDiffusion은 denoiisng 단계와 관계없이 항상 Marigold보다 더 나은 성능을 보여주고 있습니다. 특히 10단계만에 수렴하는 것을 보여주는 반면에, Marigold는 수렴하는데 25 단계가 필요하다는 것을 통해 텍스트 정보가 diffusion 과정의 초기화에 효과적인 것을 알 수 있으며 전체 수렴 속도를 빠르게 하는데 도움이 된다는 것을 실험적으로 보여주고 있습니다.
Better perception in small areas
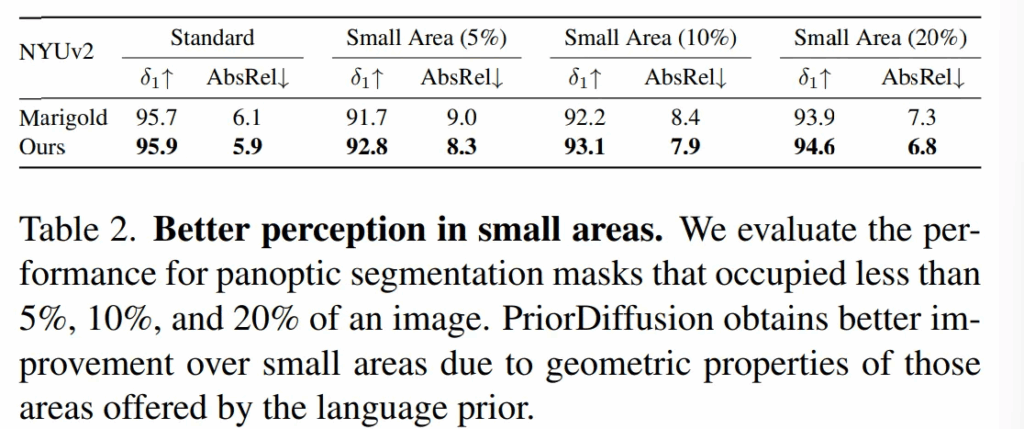
마지막으로 Tab.2는 작고 세부적인 영역에 대한 성능 결과 입니다.
이러한 평가를 하기 위해 우선 NYUv2 테스트셋에 포함된 모든 이미지에 대해 MaskDINO를 이용하여 panoptic segmentation 마스크를 생성하고, 전체 이미지 중에 5%, 10%, 20% 미만의 면적을 차지하는 마스크에 대해 모델 성능을 평가하였다고 합니다.
작은 영역일수록 추정하기가 어렵지만, PriorDiffusion은 이러한 작은 영역에서도 기존 방법론보다 좀 더 성능 향상을 보이고 있습니다. 이러한 결과 역시도 텍스트 정보가 제공하는 정보들이 diffusion 모델이 작고 일반적으로 구별하기 어려운 영역까지 더 잘 인식하고, 추정해야하는 영역이라는 것을 각인시키는데에 효과적이라는 것을 증명하고 있습니다.
안녕하세요. 리뷰 잘 봤습니다.
제가 알기로 WorDepth는 학습때만 text 정보를 사용하고 inference 때는 text 정보를 사용하지 않는 것으로 아는데, 해당 방법론은 inference 단계에서도 text 정보가 필요한건가요? 그림만 봤을 땐 필요해보이는데 또 리뷰 설명 글에서는 없어도 되는 것처럼 보여서 헷갈려서 질문드립니다.
감사합니다.
안녕하세요 리뷰 잘 읽었습니다
Text Input으로 넣어서 Depth의 정확도를 높인다는 아이디어, 심플하면서도 최신모델들에 비해 좋은 성능을 보이는게 인상깊었습니다. 한가지 궁금한 것이 평가지표가 다른 논문들에 비해 제한적인거같다는 개인적인 생각이드는데 원래 delta랑 절대상대깊이만 다루는가요?
감사합니다.
안녕하세요 좋은 리뷰 잘 읽었습니다. 감사합니다
해당 논문은 small area에서의 성능 향상이 이루어졌다고 제시하고 있고, delta와 absrel에서 전반적으로는 각각 0.2퍼씩 향상되었음을 보여주었습니다.
저자가 작은 물체들에 대해서는 0.2보다 큰 성능 향상이 있다고 보여준 점을 봤을때, 큰 물체들에 대해서는 오히려 성능하락이 있지 않았을까 의문이 들어 질문드립니다.