안녕하세요, 이번에 리뷰할 논문은 토큰 프루닝 관련 논문입니다.
토큰 프루닝 관련 논문은 처음 접해보는 분야인지라 아무리 쉬운 방법론이라고 저자가 언급하여도 저한테는 어렵고 낯설어서 읽기가 어려웠던 논문이었던 것 같습니다.
제목은 “Revisiting Token Pruning for Object Detection and Instance Segmentation”으로 해당 논문은 WACV 2024에서 발표된 연구로 기존에는 이미지 분류(classification) 분야에 주로 적용되던 토큰 프루닝(token pruning) 기법을 object detection과 instance segmentation 같은 dense task로 확장한 내용을 담고 있습니다.
물론 해당 논문이 이러한 dense task에 토큰 프루닝을 완전 처음 적용한 것은 아니지만, 기존 분류 중심의 프루닝 방식을 불필요하게 복잡하게 만들지 않고 단순한 방법으로 확장했을 때도 충분히 효과적인 성능을 낼 수 있다는 점을 보여주고자 한 연구라고 보시면 될 것 같습니다.
바로 리뷰 시작하도록 하겠습니다.
introduction
비전 트랜스포머(ViT)가 등장함에 따라서 ViT는 이미지 분류뿐만 아니라 객체 검출, 시맨틱 세그멘테이션 등 다양한 비전 태스크에서 빠르게 주류 아키텍처로 자리 잡게 되었습니다.
아시다시피 ViT의 강점은 pair wise하게 토큰 어텐션을 함으로써 global reasoning한 능력을 가질 수 있다는 점인데, 동시에 연산량이 폭발적으로 늘어난다는 단점도 있습니다. 그래서 데이터가 많을 때 ViT는 성능은 좋다고 알려져있지만, 연산 자원이 제한적인 환경에서는 적용이 쉽지 않다는 문제가 있었습니다.(토큰 수의 제곱에 비례하는 높은 연산 비용)
이를 조금 완화하기 위한 대표적인 방법 중 하나가 토큰 프루닝(Token Pruning)입니다.
입력 이미지에서 덜 중요한 토큰을 가지치기(prune)하여 연산량을 줄이는 방식인데, ViT는 Self-Attention 연산은 입력으로 들어오는 임의의 토큰 개수를 처리할 수 있기 때문에 전체 토큰 중 덜 중요한 것들을 미리 쳐내면 연산해야할 토큰 수 자체가 줄어들게 되고, 별도의 하드웨어를 건드리지 않고도 연산량과 속도를 바로 개선 시킬 수 있습니다.
실제로 기존 연구들은 게이팅 네트워크(이 토큰을 계속 쓸지 버릴지 결정하는 작은 네트워크)를 두어 토큰의 중요도를 학습하거나 클래스 토큰으로부터 어텐션 값이 작은 토큰을 제거하는 방법을 시도해왔습니다. 하지만 이런 방법들은 대부분 이미지 분류에만 국한되어 있었고 Object Detection이나 Instance Segmentation 같은 dense task에는 적용된 사례는 여전히 드물다고 합니다.
저자들은 isotropic ViT(계층을 따라가면서 토큰 해상도가 일정하게 유지되는 구조)를 기반으로 토큰 프루닝을 dense task로 확장해보고자 했습니다. 근데 단순히 분류에서 쓰던 프루닝 방법을 그대로 가져오면 detection이나 segmentation 에서 성능이 크게 떨어진다는 문제가 있었습니다. 그래서 저자는 위와 같은 문제점은 여러가지 실험을 통해서 모델 성능을 개선해보고자 하였고 설계 또한 단순화 하는데 유리한 4가지 핵심 통찰들을 제시하게됩니다.
그래서 정리하면 저자들이 도출한 핵심 통찰은 크게 네 가지로 보실 수 있습니다.
- 토큰 보존(Token preserving) – 분류에서는 프루닝된 토큰을 버려도 무방하지만 dense task에서는 이후 검출 헤드에서 활용할 수 있도록 피처맵 상에 보존하는 것이 성능 향상에 도움이 됨.
- 토큰 재활성화(Token reactivation) – 한 번 프루닝된 토큰이라도 필요하다면 이후 레이어에서 다시 활성화할 수 있도록 하면 잘못 제거된 프루닝을 복구하고 성능을 끌어올릴 수 있었음.
- 동적 프루닝 비율(Dynamic pruning rate) – 복잡한 이미지는 더 많은 토큰을 사용하게끔 하고 단순한 이미지는 더 적은 토큰을 쓰도록 동적으로 조절하면 성능과 효율을 모두 잡을 수 있었음.
- 단순한 게이팅 네트워크(2-layer MLP) – 복잡한 게이팅 네트워크 대신 가벼운 2층 MLP만으로도 충분히 효과적으로 토큰을 선택할 수 있었음.
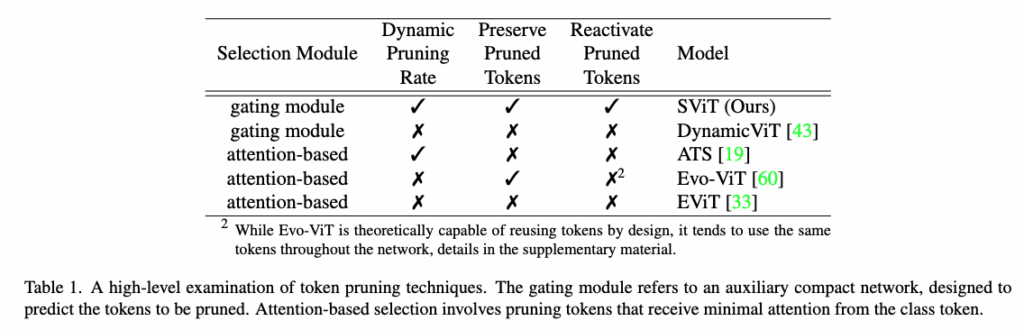
저자들은 이 네 가지 통찰을 바탕으로 SViT라는 단순한 푸르닝 모델을 제안하게 됩니다.
selection Module에 해당하는 것이 4번이고 나머지는 이름에 맞게 연결지어서 보시면 좋을 것 같은데 앞서 언급한 4가지 요소를 다 적용을 시킨 것이 SViT입니다. 물론 이 표는 토큰 프루닝 기법들을 개략적으로 비교한 것이어서 구현 세부사항이 아니라 설계 방식이나 앞서 언급한 4가지 주요 특징을 비교하는 개요 표라고 보시면 좋을 것 같습니다.
결과적으로 기존의 최신 토큰 프루닝 기법에 비해 object deteciton과 instance segmentation 에서 성능 저하를 크게 줄였고 동시에 전체 네트워크 기준 최대 34%, 백본 기준 최대 46%의 추론 속도 향상을 달성했다고 합니다. 자세한 내용은 Experiments 파트에서 다루도록 하겠습니다.
method
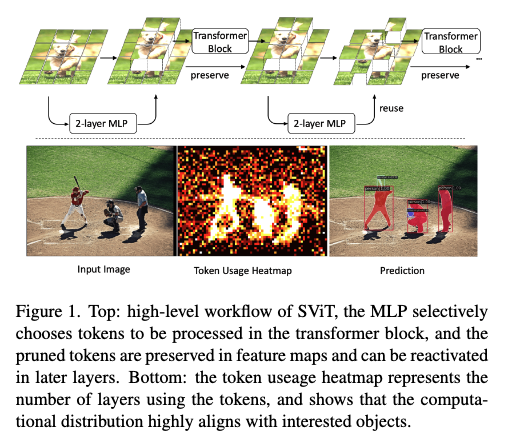
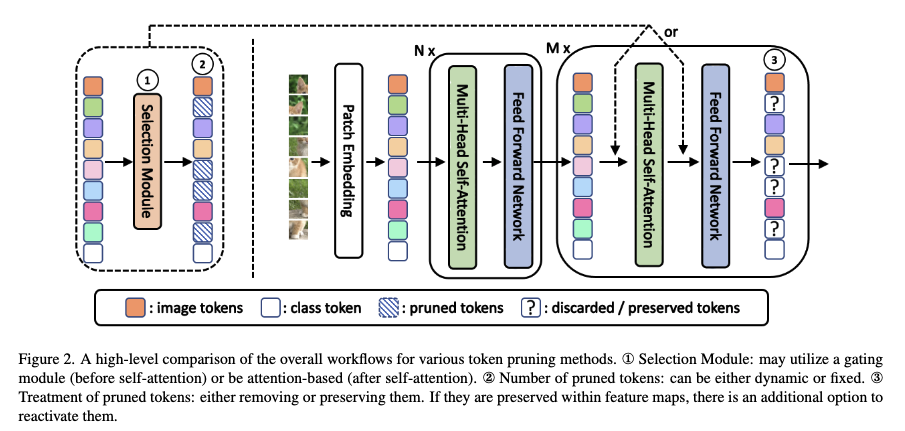
먼저 해당 논문에서 제안하는 토큰 프루닝의 전체적인 흐름을 요약하자면,
먼저 들어오는 입력 이미지를 패치 단위로 잘라서 토큰으로 변환합니다. 그 다음 변환된 토큰을 초기 ViT 블록에 통과시켜서 충분히 특징 표현들을 뽑아내고 앞서 언급한 토큰 선택 모듈을 적용해서 덜 중요하다고 생각이 되는 토큰들을 식별한 후에 선태괸 토큰은 연산에 사용하지 않게 함으로써 연산량을 줄이는 방식으로 크게 동작한다고 보시면 좋을 것 같습니다.
이제 앞서 요약 말씀드렸던 전체적인 흐름과 앞선 인트로 부분에서 저자가 언급한 4가지 통찰과 연결지어 방법론에 대해서 자세하게 설명드리도록 하겠습니다.
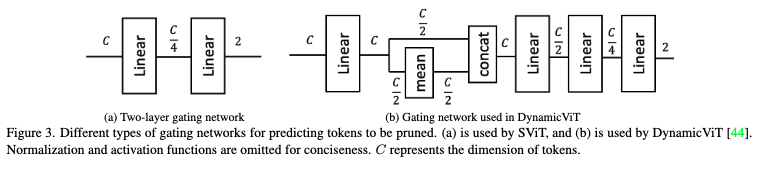
먼저 기존 토큰 프루닝 연구들은 대체로 복잡한 게이팅 네트워크를 사용하여 프루닝할 토큰을 예측했습니다.
예를 들어 DynamicViT 는 여러 개의 MLP를 평균하고 이것들을 concat해서 결합해가지고 토큰별 정보와 global정보를 모두 학습한 뒤 프루닝 여부를 결정하는 식으로 작동합니다.(그림 (b))
근데 해당 방법론은 보다 단순하게 C→C/4→2 의 얕은 MLP를 사용을 합니다.
Dense task에서는 토큰 자체의 개별의 국소 정보로도 지금 해당 토큰이 필요한지 필요 없는지 판별하기 충분하다라는 관찰을 통해서 위 (a)와 같이 얕은 네트워크로 연산량을 줄이고자합니다.
먼저 프루닝된 토큰은 버리지 말고 보존하는 것이 낫다라는 부분인데요. 사실 처음에 해당 논문을 읽으면서 헷갈렸던 부분은 토큰을 보존하는 것과 토큰을 재활용한다는 내용에 대해서 굳이 두개로 분리를 왜 했을까? 라는 생각이 들었습니다. 왜냐면 저는 단순히 토큰을 보존하는 것이 결국 재활용하기 위함이라고 생각을 하였는데, 재활용을 하지 않아도 Classification과는 다르게 Dense Task에서는 재활용되지는 않아도 보존된 토큰이 이후에 detection Head 부분에서 여전히 토큰 정보를 활용할 수 있기에 프루닝된 토큰을 피처 맵 안에 그대로 보존하는 것이 더 유리하다라는 점을 저자가 분석을 한 것 같습니다.
그래서 푸르닝된 토큰을 보존하게 될 경우에는 피쳐맵은 각 단계에서 업데이트된 토큰만 교체하게 되고 프루닝된 토큰은 변경하지 않은 채 그대로 유지된다고 보시면 좋을 것 같습니다.
실제 구현은 각 레이어 앞에서 selection module(2-layer MLP + Gumbel-Softmax)이 토큰 마스크 M\in{0,1}^N 를 냅니다.
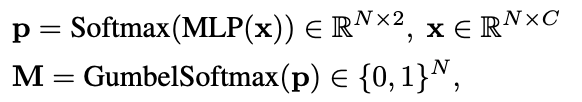
여기서 x는 토큰 임베딩이고 Selection module을 ViT 블록 앞에 두기 때문에 ViT 입력 으로는 프루닝된 토큰만 입력으로 들어가게 됩니다.
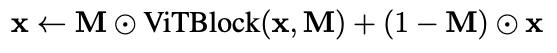
M 은 토큰 마스크로, 크기가 \mathbb{R}^{N} (토큰 개수 N)입니다. M_i = 1 같은 경우에는 i번째 토큰은 활성 토큰으로 ViTBlock 결과를 사용하게되는 것이고 M_i = 0 같은 경우에는 i번째 토큰은 프루닝된 토큰으로 이전 값을 그대로 유지하는 식으로 동작하게 됩니다.
M \odot \text{ViTBlock}(x, M) 같은 경우에는 활성 토큰만 업데이트 한다라고 보시면 될 것 같고 \odot x 같은 경우는 프루닝된 토큰은 원래 값을 유지하도록 한다고 보시면 될 것 같습니다. (토큰별로 ViTBlock 결과를 적용할지 말지 선택하는 역할)
따라서 둘을 더하면 업데이트된 토큰과 보존된 토큰이 합쳐져서 최종 출력 x가 나오게 되는 것입니다.
그리고 추론시에는 활성 토큰만 gather 해서 블록을 통과시키고, 업데이트된 결과를 원래 좌표로 scatter 하는 방식으로 동작하게 됩니다.
다시 정리하면, 여기서 M=0인 토큰은 ViTBlock을 통과하지 않고, 이전의 x 값(즉 업데이트 안 된 상태) 으로 그대로 유지되고 또 VITBlock은 앞서 구한 마스크 M을 받아 어텐션 행렬의 해당 열을 0으로 만들어서 프루닝된 토큰이 다른 토큰과 연산을 하지 않도록 합니다.
프루닝된 토큰을 보존하는 것이 결과적으로는 검출 헤드에서만 사용되는 것이기 때문에 프루닝된 토큰을 보존하는 방식과 아예 제거해서 검출 헤드에서도 사용하지 않는 방식과 비교했을 때 속도 측면에서는 거의 차이가 없다고 합니다.
그 다음은 토큰을 보존하기만 하는 게 아니라, 필요하다면 백본의 뒷단 레이어에서다시 재사용 할 수도 있습니다.
각 레이어에서 Selection module은 모든 토큰(활성+보존)의 임베딩을 입력으로 받아 새 M을 다시 샘플링하게 되는데 학습과정에서 이전에 0이었던 토큰도 다음 레이어에서 1이 될 수있습니다.
결국 레이어마다 집중하는 영역이 다르기 때문에, 어떤 레이어에서는 덜 중요해 보였던 토큰이 다른 레이어에서는 다시 중요한 역할을 할 수도 있고 또 잘못 프루닝 되었을 수도 있던 토큰을 학습과정에서 다시 재사용이 될 기회가 생긴다는 점에서 토큰을 더 효과적으로 활용할 수 있도록 했다고 보시면 좋을 것 같습니다.
모든 이미지에 동일한 비율로 토큰을 프루닝하는 것보다는, 이미지 난이도에 따라 다르게 프루닝 비율을 조절하는 것이 훨씬 효율적입니다. 복잡한 장면에는 토큰을 더 많이 남기고, 단순한 장면에는 토큰을 더 줄이는 식인데 이 방법은 연산량을 줄이면서도 성능을 유지하는 핵심 설계 중 하나라고 보시면 될 것 같습니다.
그래서 저자는 이를 위해서 동적 비율 손실로 레이어별로 평균 유지율이 목표치t_l에 맞도록 학습을 하게 됩니다.
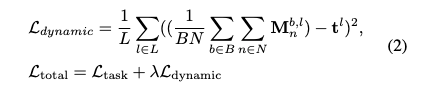
M^{b,l}_n: 배치 b, 레이어 l에서 n번째 토큰의 마스크 값
t_l: 해당 레이어 l에서의 목표 유지 비율
\lambda: 손실 가중치 하이퍼파라미터
위 수식은 결국 배치 차원에서 모든 이미지에 대한 토큰 사용량의 평균으로 이 평균이 해당 레이어 l 에서의 목표 유지 비율(t_l)까지 도달할 수 있도록 학습이 이루어지게 됩니다.
해당 방식은 토큰 사용량–정확도의 트레이드오프를 조절한다라고 보시면 될 것 같습니다. 즉 토큰 사용량 평균을 배치 단위로 계산을 함으로써 어떤 이미지는 복잡해서 더 많은 토큰을 keep, 어떤 이미지는 단순해서 더 적은 토큰만 keep해서 배치 평균만 t_l 근처가 되도록 학습이 이루어지도록 합니다.
이미지별로는 다르게 잘라도 된다, 단 배치단위 전체 평균만 맞추면 된다를 나타내는 손실이라고 보시면 될 것 같습니다. 다만 논문에서는 언급하지는 않았지만 배치가 작아지면 동적 프루닝이 사실상 고정 프루닝으로 동작해버리니깐 학습시 동적이라는 특성이 드러나기 위해서는 충분히 큰 배치로 학습을 시켜야한다라는 점이 아쉬운 것 같습니다.(실험도 실제로 전부 큰 배치를 가정한 환경에서만 진행)
다시 정리하면, Selection Module 은 가벼운 2층 MLP로 구현됩니다. 그리고 여기에 Gumbel Softmax를 붙여서 토큰을 제거할지 유지할지를 결정하게 되고 훈련 시에는 마스킹을 적용해서 프루닝된 토큰이 다른 토큰에 영향을 주지 않도록 하고, 추론 시에는 활성 토큰만 모아서(gather) 연산을 수행한 뒤 원래 위치로 다시 흩뿌려(scatter) 넣어 줍니다. 또 다이나믹하게 프루닝 비율을 학습하도록 별도의 손실을 추가함으로써 복잡한 이미지는 더 많은 토큰을 남기고 단순한 이미지는 더 적게 남기도록 학습됩니다.
Experiments
실험은 COCO 2017 Object Detection과 Instance Segmentation 데이터셋에서 실험을 진행했습니다.
실험 프레임워크는 Mask R-CNN에 ViT-Adapter를 얹어서 ViT를 백본으로 쓰는 구조를 사용하여 실험을 진행하였습니다.
먼저 앞서 계속 말씀 드린 4가지 통찰에 대한 평가가 필요할 것 같습니다.
프루닝된 토큰을 보존
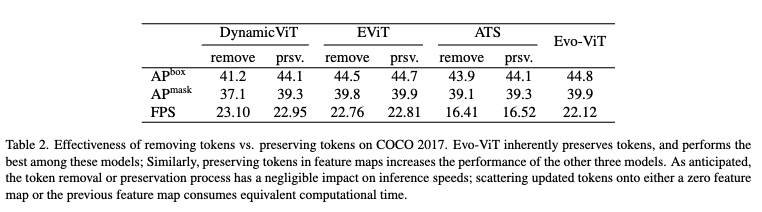
먼저, 프루닝된 토큰을 단순히 제거하는 경우 vs 보존하는 경우를 비교했습니다.
EViT, EvoViT, DynamicViT, ATS 네 가지 최신 모델에 보존 기능을 붙여 실험했는데, EvoViT는 원래부터 보존 구조라 가장 좋은 성능을 보였고, 특히 DynamicViT는 보존 기능을 켜자 성능이 크게 상승하는 모습을 보입니다.
보존된 토큰을 재사용/ 동적 프루닝 비율 적용
다음은 프루닝된 토큰을 나중 레이어에서 다시 활성화할 수 있게 한 경우에 대한 실험입니다. 근데 이 실험에서는 이전의 모델들 대신 SViT에 대해서만 실험을 헀는데 selection module이 어텐션 기반인 모델 같은 경우에는 실제로 토큰을 재사용하기 어렵다기 때문이라고 합니다. 어텐션 기반 selection module은 셀프 어텐션이후에 토큰을 쓸지 말지 결정되기 때문에 토큰을 재사용하려면 또 모든 토큰이 셀프 어텐션에 참여해야되어서 연산량 절감 효과가 의미가 없어지기 때문에 SViT에서만 평가를 진행을 하였습니다.
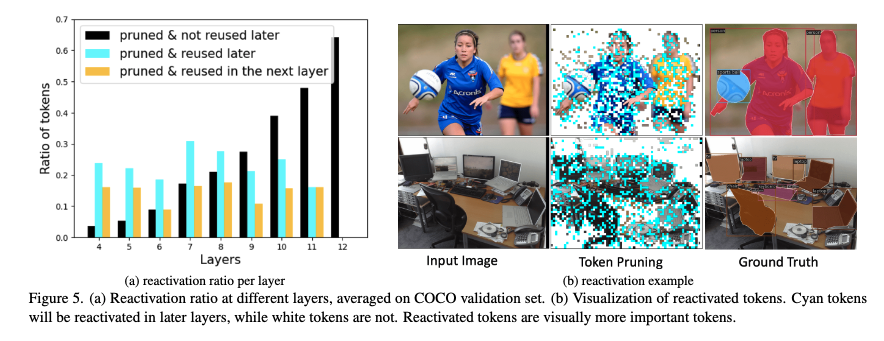
보존된 토큰을 재사용하는 경우 사용하지 않았을 때보다 성능이 향상되는 것을 확인 할 수가 있었고 이 또한 결과적으로 동적 비율만 적용을 해도 Box/Mask AP가 0.2 정도 향상되는 것을 확인 할 수 이가 있습니다. 결과적으로 두개를 동시에 적용하면 성능 향상폭이 더 커지는 것을 확인하실 수 있습니다.
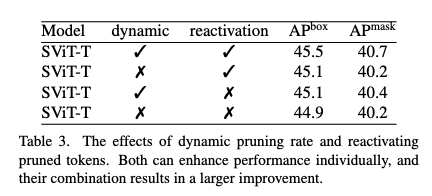
초기 레이어에서 잘못 프루닝된 토큰도 뒤에서 되살릴 수 있기 때문에 성능이 향상된 것으로 보이고 실제로도 그림 5를 보면 많은 토큰이 다시 활성화되는 패턴이 보였습니다. 그리고 재활성화 비율을 보면 초기 레이어에서 프루닝된 토큰 대부분이 후속 레이어에서 재사용되고 특히 절반 이상은 바로 다음 레이어에서 곧바로 재사용된다는 걸 보실 수 있습니다.
해당 분석은 초기에 버린 토큰을 너무 일찍 영구 제거하면 해롭다는 것이고, 모델이 스스로 다시 필요한 토큰을 되살리면서 손실을 줄이고자 하는 것으로 보실 수 있습니다. 이미지 내 시각화(b)를 보면 단순 배경은 재활성화 거의 없고반대로 사람, 축구, 컴퓨터 등 관심 객체 영역은 선택적으로 재활성화되는 걸 확인할 수 있습니다.
2-Layer MLP면 충분하다
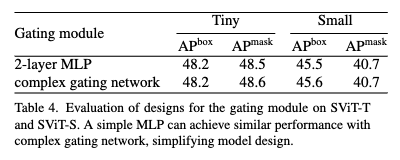
게이팅 네트워크를 복잡하게 만들지 않고, 단순한 2-Layer MLP만 써도 충분히 잘 작동한다는 것도 확인할 수 있는 테이블 표입니다. 자세하게 보면 Tiny 모델에서는 Box AP는 동일, Mask AP는 -0.1 정도 하락하였고 Small 모델에서는 Box -0.1, Mask는 동일한 것으로 보이는데 사실상 성능 차이가 거의 없는 것을 보실 수 있습니다.
다른 기법과 비교
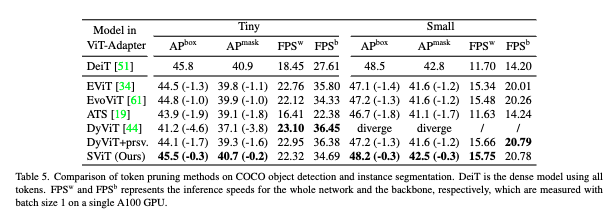
Dense 모델(DeiT) 대비 성능을 비교했을 때, 기존 모델(DynamicViT, EViT, EvoViT, ATS)은 Dense 대비 박스 AP -1.3 ~ -1.8, 마스크 AP -1.2 ~ -1.7 정도 손실이 있었습니다. 반면 SViT-S는 박스/마스크 둘 다 -0.2 ~ -0.3으로 성능 하락 폭이 가장 적은 것을 보실 수 있습니다.
결론
기존 분류 중심으로 연구하던 토큰 프루닝을 dense task의 특성에 맞게 토큰을 단순하고 가성비 있게 사용하면서 그리고 “토큰 보존”과 “재활성화”라는 개념은 단순히 속도를 빠르게 만드는 것을 넘어서 정확도와 효율 사이의 균형을 어떻게 잡을 수 있는지에 대한 좋은 통찰을 주는 것 같습니다. 앞으로는 더 나아가서pyramidal ViT나 더 다양한 백본 구조에도 이런 아이디어를 어떻게 확장할 수 있을지에 대한 고민을 해볼 수도 있을 것 같습니다. 감사합니다.
안녕하세요 우현님 좋은리뷰 감사합니다.
처음 읽었을때 와닿지 않는 토큰 보존이나 토큰 재활성화에 관한 설명을 먼저 해주셔서 이해하기 편했습니다.
토큰 재활성화에 관한 이해로 각 ViT head들이 가지는 attention 정보들이 다르므로 각 head들에 맞춤형 토큰을 사용하게 하기 위해 매 select module에서 새롭게 활성화시켰다고 이해하면 될까요?
그리고 gumble softmax가 제가 예전에 읽었던 논문에서도 적용되어 있던데 이런 토큰 pruning에서 자주 언급되는 방법인 것 같습니다. token을 선택하는 것은 0/1 같은 binary 값으로 표현되지만, gradient가 흐를 수 있게 이산적 값을 연속적인 근사치로 바꾸어 사용하는 방법으로 알고있는데 제가 잘못 이해하고있는 점은 없는지 해당 방법론도 다뤄줬으면 좋겠습니다. 감사합니다.
안녕하세요 인택님 댓글 감사합니다.
토큰 재활성화 같은 부분에 대해서는 헤드별이 아니라 레이어별(블록별)로 재활성화하는 개념이라고 보시면 될 것 같습니다.
즉 헤드별로 다른 토큰을 따로 켠다기보다는 레이어마다토큰을 다시 고를 수 있게 해서 이전에 잘랐던 토큰도 필요하면 되살리는(reactivate) 구조입니다. 레이어가 깊어질수록 어텐션할때 중요하게 보는 영역이 달라지기 때문에,이전 층에서 덜 중요하던 토큰이 다음 층에서는 중요해질 수 있기 때문에 사용하는 것이라고 이해하면 좋을 것 같습니다.
큰 틀에서 gumbel softmax에 대해서는 인택님이 이해하신게 맞습니다. 보다 깊이 있는 이해를 하기 위해서는 gumbel 노이즈라던지 straight-through argmax인지 무엇인지를 설명드려야하는데 저 또한 이 복잡한 개념에 대한 이해가 부족하여 나중에 기회가 된다면 해당 방법론 또한 리뷰해보도록 하겠습니다.
감사합니다.
안녕하세요 우현님 리뷰 감사합니다
토큰 프루닝에 대한 내용을 알 수 있었던 것 같습니다. 단순히 궁금한 점이 있는데, 상인님이 연구하시는 내용을 접하면서 처음 접한 연구인데 토큰 프루닝에 대한 연구가 요즘 핫한 연구인가요? 다른 분야에 적용이 가능한지도 좀 궁금합니다. 마지막으로 토큰 프루닝 논문을 읽기 시작하게 된 계기가 궁금합니다!!
안녕하세요 영규님 좋은 댓글 감사합니다.
토큰 프루닝 자체가 요즘 핫한지는 모르겠으나 전반적으로 효율성의(효율적 추론/경량화) 흐름은 필수적인 흐름이지 않나 생각이 듭니다. 어떤 태스크가 일정 수준 성능이 안정화(?)되면, 그 다음 서비스 단계에서의 비용,latency,메모리 최적화는 중요하다고 생각합니다. 그래서 요즘 온디바이스AI처럼 모델 최적화 연구는 핫하다라고 볼 수 있는 것 같습니다. 프루닝은 그중 한 축이고, 토큰 프루닝은 ViT나 멀티모달처럼 토큰 단위가 분명한 모델에서 효과적이다라고 볼 수는 있을 것 같습니다.
그리고 다른 분야에도 무조건 적용가능하다고 생각합니다. 토큰 개념이 있거나, 가중치/연산을 선택적으로 줄일 수 있는 구조라면 대부분 후보라고 생각합니다. 그리고 토큰에 한정하지 않고, MLP에서의 가중치 프루닝, 채널/헤드/레이어 프루닝, 등도 같은 맥락에서의 효율화 기법이라 사실 토큰 프루닝이 아니라 그냥 프루닝의 컨셉은 어디에나 적용할 수 있을 것 같습니다. 긜고 제가 이 주제를 보기 시작한 계기는 개인적으로는 범용성 있는 기술(여러 태스크에 이식 가능한 효율화/최적화)을 연구하는 게 의미 있다고 느끼기도 했고 마침 상인님이 관련 연구를 진행 중이어서 상인님 졸업하시기 전에 많이 배워놔야겠다 라는 생각도 들기도 했습니다. 짧은 시간이라도 찍먹해 보자는 마음으로 관련 주제에 대한 연구에 발을 디디게 되었습니다. ㅋㅋ
감사합니다
안녕하세요. 좋은 리뷰 감사합니다.
총 4가지의 통찰을 바탕으로 SViT라는 pruning 모델을 제안한 것으로 이해했습니다. 이 중 token preserving관련된 실험인 table2에 관해 질문이 있는데요. Evo-ViT의 경우에는 기존에 preserving이 적용되는 모델인 것 같은 같은데,, 다른 방법론에 prsv를 한 경우와 비교했을 때 더 성능이 좋은 것 같은데 preserving 방식이 다른건가요? 아니면 베이스 모델이 조금씩 다르다고 보면 될까요? 또 이 task에서는 오직 tiny, small에 대해서만 평가하는건지 궁금합니다.
안녕하세요 윤선님 좋은 댓글 감사합니다.
presevin 자체가 복잡하고 정해진 수식이나 방식이 아니고 말그대로 pruning 된 토큰을 잘 보관해두었다가 이후에 dense한 태스크를 하기 위한 head에 pruning되었던 토큰들까지 같이 넘겨주는 것으로 이해하시면 좋을 것 같습니다.
그래서 위를 생각했을 때 표에서 (EVO-ViT제외하고) 리포팅이 되어있는 prev는 저자가 따로 실험을 한것이고 EVO는 그대로 가져다 썼기 때문에 컨셉은 동일한 방식이나 구체적으로 EVO는 어떻게 preseve하고 마지막 HEAD에서 어떻게 사용했는지에 대해서는 잘 모르겠으나 엄청 성능에 영향을 주진 않을 것 같습니다. 그리고 베이스 모델은 DeiT로 다 동일하며, tiny,small에 대해서만 평가진행합니다!
감사합니다!
좋은 리뷰 감사합니다. 트랜스포머의 문제점 하면 항상 연산량 폭증이 언급되기에 이를 다룬 분야들은 없나 평소에 막연한 궁금증을 가지고 있었는데, 해당 리뷰 재밌게 읽으며 어느 정도 이에 대한 궁금증이 해소됐습니다. 읽다가 궁금한 점이 있어 질문 남기도록 하겠습니다.
1. 지금 방법론들은 vit 가반으로 detection 및 segmentation을 수행하는데, 제가 트랜스포머 기반 detector는 DETR계열쪽만을 봐서 vit 기반의 detection / segmentation 동작 프레임워크는 잘 알지 못합니다. ViT를 백본으로 사용하면 어떤 식으로 detection이랑 segmentation을 수행하게 되나요? 그냥 CNN이랑 똑같이 인코더 출력을 multi-scale feature map로 만들어서 후처리하나요?
2. pruning하는 과정을 보니 selection module에서 토큰의 feature를 MLP->Softmax 태워서 0~1값으로 정렬한다음 GumbelSoftmax 로 top-k를 선별하는 방식으로 pruning을 수행하는걸로 보입니다. 결국 MLP가 각 토큰의 중요성을 잘 예측해야 하고, 이 학습은 L_dynamic term에서 주요하게 이뤄지는 것 같습니다. 여기서 L_dynamic loss가 구체적으로 어떻게 구성되어있는지 이해가 잘 안되는데, 동작 과정을 설명해주실 수 있을까요?
안녕하세요 재연님 댓글 감사합니다.
Q1. 지금 방법론들은 vit 가반으로 detection 및 segmentation을 수행하는데, 제가 트랜스포머 기반 detector는 DETR계열쪽만을 봐서 vit 기반의 detection / segmentation 동작 프레임워크는 잘 알지 못합니다. ViT를 백본으로 사용하면 어떤 식으로 detection이랑 segmentation을 수행하게 되나요? 그냥 CNN이랑 똑같이 인코더 출력을 multi-scale feature map로 만들어서 후처리하나요?
넵 일단 제가 아는 선에서 답변을 드리면 multi-scale feature map로 만들어서 사용하는 것 같습니다. 일단 제가 봐왔던 것들은 ViT encoder에서 특정 블록들의 출력을 intermediate feature로 뽑는 경우도 있고 예를 들어 Block 3, 6, 9, 12 같은 위치에서 토큰을 꺼내 각기 다른 scale의 feature map으로 변환합니다. 오히려 이것보다 최종 출력을 가지고 multi scale을 만드는게 더 효과적이다(ViT -adapter 논문)라고 하면서 이 순수 ViT 백본으로만은 multiscale의 feature 표현력이 약해서 그런가 뭔가 피쳐를 잘 뽑아 낼 수 있는 그런 장치들을 심는 경우도 보았습니다. segmentation 같은 경우에는 제가 detr 기반 segmentation만 봐서 이 부분은 잘 모르긴하는데 코드만을 보면
ViT backbone -> FPN -> detection head (Detection)
ViT backbone -> pixel decoder -> segmentation head (segmentation)
약간 위와 같은 느낌으로 흘러가는 것 같습니다.
Q2. L_dynamic loss가 구체적으로 어떻게 구성되어있는지 이해가 잘 안되는데, 동작 과정을 설명해주실 수 있을까요?
먼저 해당 과정은 정말 단순합니다. 사전에 정의한 keep ratio 비율과 MSE를 계산하는데 이거를 sample 단위가 아니라 배치 단위로 계산한다고 생각하시면 됩니다. 그래서 배치내에 이미지들 끼리는 keep ratio는 유지하되 동적으로 토큰을 노나먹을 수 있게됩니다. 예를들어 토큰 50개만 남겨야하는 상황에서 2배치가 들어왔다고 하면 복잡한 이미지1에대해서는 토큰 100중 80개를 남기고 단순한 이미지2는 20개만 남기게끔 학습이 될 수가 있습니다. 이렇게 되면 평균은 50에 맞아지게 되어서 각 이미지에 똑같이 50개씩 남기는 상황보다 dynamic 하게 동작한다고 보실 수 있습니다.
감사합니다.
안녕하세요 우현님, 좋은 리뷰 감사합니다.
동적 비율 손실을 정의할 때, 레이어별 목표 유지 비율은 사용자가 직접 정의해야 하는 건가요?
직접 정의해야 한다면 어떤 기준으로 정의할 수 있는지 궁금합니다.
안녕하세요 재윤님 댓글 감사합니다.
레이어별 유지 비율은 사용자가 직접 정의해야 합니다.
어떤 기준으로 정의할 수 있는지는 저도 잘 모르겠으나 경험적으로 해당 값을 구한다거나 아니면 각 레이어별 모델이 어느 부분을 얼만큼 중요하게 보는지에 따라 정할 수 있을 것 같습니다.
프루닝을 어떻게 하느냐는 통계나 분석에 따라 기준을 정의할 수 있을 것 같습니다.
감사합니다.