안녕하세요 이번 리뷰는 fine grained 레벨의 이미지 캡션 생성 논문입니다. 최근 GPT 계열의 foundation 모델을 통해 fine grained 캡션 생성도 가능해졌지만, 이 논문은 별도의 foundation 모델을 사용하지 않고도 세밀한 캡션을 만들어낼 수 있어서 그 방법론을 한번 살펴봤습니다. 리뷰 시작하겠습니다.
Abstract
저자는 기존의 이미지 captioning 모델들이 주로 단일 디코더를 통해 문장을 생성하기 때문에, 전반적으로 모호한 설명 (coarse caption) 은 잘 생성하지만 객체의 속성이나 세부 정보 (fine caption) 까지 반영하는 데에는 한계가 있다고 먼저 지적합니다.
이를 해결하기 위해 Dual Encoder-Decoder Framework 를 제안합니다. 해당 방법론을 간단하게 설명하자면 하나의 인코더 – 디코더는 이미지 전반에 대한 coarse caption을 생성하고, 이후 다른 인코더-디코더는 이를 조건으로 fine-grained caption을 보완하는 구조입니다. 즉 coarse caption을 바탕으로 보다 세밀하고 풍부한 문장을 단계적으로 만들어낸다고 생각하면 됩니다.
Introduction
이미지 캡셔닝은 컴퓨터비전과 자연어 처리가 융합된 복잡한 문제로, 모델이 이미지 내에 어떤 객체가 존재하는지 뿐만 아니라 그 객체들이 어떻게 연결되어 있는지까지 이해해야 한다고 합니다.
해당 분야는 기계 번역에서 영감을 얻은 Encoder-Decoder 구조가 본격적으로 도입되고, RNN/LSTM ~ Attention 매커니즘까지 오면서 캐션의 품질이 많이 향상됐다고 합니다.
저자는 이러한 일련의 발전에도 불구하고 여전히 두가지 중요한 한계가 있다고 언급하는데
첫째로 세밀한 속성의 묘사가 충분하지 않다는점을 들었고 그 예시로 사람을 “a man” 으로 묘사하는 데서 끝나고, 그 사람이 입는 옷이나 가지고 있는 물건 같은 디테일은 빠지기 쉽다는 문제점을 언급합니다.
둘째로 복잡한 장면에서 객체 간의 관계를 정확하게 설명하지 못한다는 점입니다. 이 문제는 이미지의 전역적인 특징에 지나치게 의존하거나, Attention을 활용하더라도 누락되는 정보가 많기 때문이라고 저자는 주장합니다. 그러면서 figure 1에 있는 사진의 caption을 예로 들며 문법적이나 사실적으로는 맞으나 장면 전체를 정확히 묘사하지는 못한다고 주장합니다.

이러한 문제를 해결하기 위해 저자들은 coarse-to-Fine Image Captioning 방법론을 제안합니다.
저자의 이 방법론은 단일 Encoder-Decoder 구조 대신, Dual Encoder-Decoder 구조를 사용합니다. 첫번째 Encoder-Decoder가 이미지를 보고 coarse 한 캡션을 생성합니다. 그 다음 첫번째 문장과 이미지의 특성을 비교하여 어떤 객체나 속성이 빠졌는지 확인하고 누락된 부분을 보강하기 위한 Feature Self-Enhancement 모듈이 도입됩니다. 이 모듈은 첫 캡션에서 언급되지 않거나 누락된 객체 영역을 다시 인코딩하여 두번째 Encoder-Decoder 구조에 반영합니다. 두번째 Encoder-Decoder 구조는 이를 바탕으로 더욱 정교하고 fine 한 캡션을 생성합니다.
간단하게 말하자면 처음에 전체적이고 대략적인 설명을 만들고 빠진 객체나 속성을 찾아내어 보강하는 점진적인 방법론이며 기존 모델들이 자주 실수한 속성에 관한 내용이나 객체가 빠지는 경우를 보완하여 복잡한 장면에서도 더 풍부하고 정확한 문장을 만들 수 있다고 저자는 어필합니다.
Method
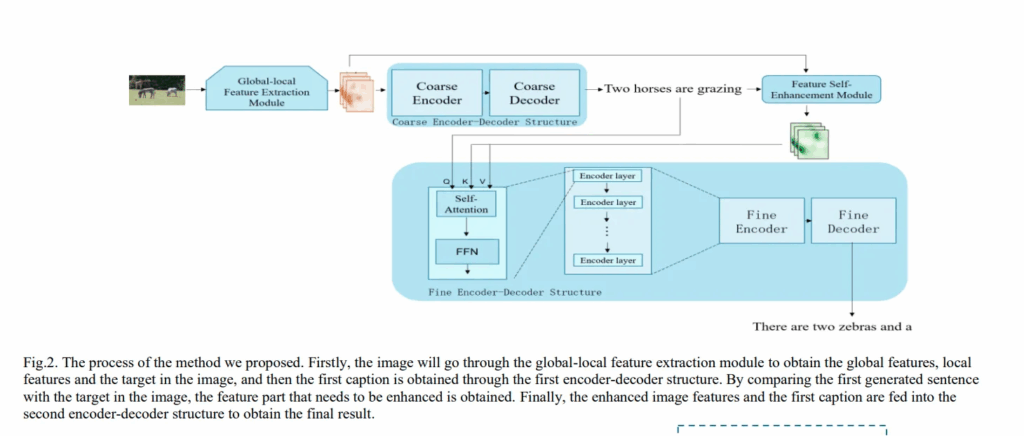
방법론의 전체적인 과정입니다. 이미지가 처음 네트워크에 입력되면 Global-local Feature Extraction Module 을 거쳐 전역 특징과 지역적 특징 그리고 이미지 안의 객체를 얻습니다.
그 후 이 이미지 특징은 첫번째 인코더-디코더 구조를 거쳐 coarse caption으로, 두번째 인코더-디코더 구조를 거쳐 최종 캡션을 얻습니다.
Global-local Feature Extraction Module
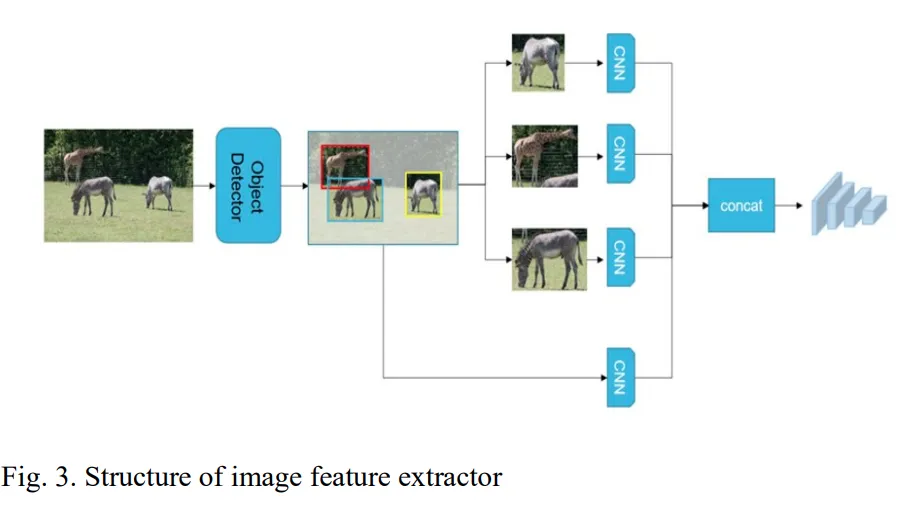
기존의 이미지 캡션 추출 네트워크와 달리, 제안하는 모듈은 이미지의 전역적인 특징 뿐 아니라 지역적 특징도 동시에 추출할 수 있습니다. 전역적 특징은 트랜스포머 인코더 레이어를 통해 추출하고 지역적 특징은 객체 탐지 네트워크를 거쳐 이미지 내 객체를 먼저 감지하고, 이를 다시 트랜스포머 인코더에 넣어 얻게됩니다.
여기서 CNN 백본으로는 YOLOvx를 사용했다고 합니다.
Dual Encoder-Decoder Framework
대부분의 이미지 captioning 방법들은 인코더-디코더 구조를 한번 사용하여 이미지 특징을 인코딩하고 다시 문장으로 디코딩시키는데, 이런 단일 구조는 한 번 생성된 문장을 조정하거나 개선하기 어렵다는 한계가 있습니다. 이러한 문제점을 해결하기 위해 저자는 듀얼 인코더-디코더 구조를 택했다고 보면 됩니다.
두개의 Encoder-Decoder 구조 모두 YOLOVx가 뽑아낸 feature map을 사용한다고 생각하면 됩니다.
우선 첫번째 인코더-디코더는 입력 이미지 특징 A를 받아 첫번째 캡션 cap1 을 생서합니다.
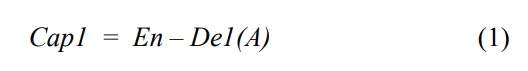
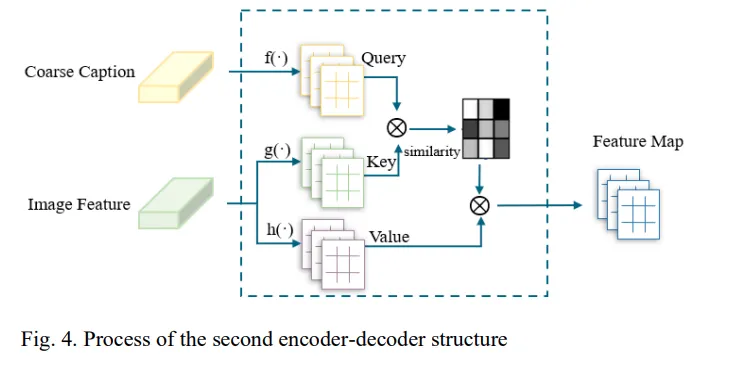
두번째 인코더-디코더는 멀티모달 방식을 사용하여 이미지 특징 A와 cap1을 함께 입력으로 받아 더 완성도 높은 캡션을 생성하고, 이는 Fig.4 를 보면 이해하기 쉽습니다.
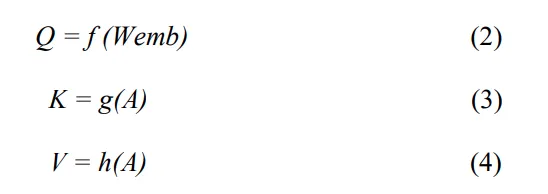
여기서 f(`)g(`)h(`) 들은 각각 다른 합성곱이며 Wemb 는 단어 임베딩 행렬이라고 합니다. 이를 통해 얻어진 Q,K,V 값으로 attention 연산을 통해 첫번째 설명과 이미지 특징간의 관계를 학습할 수 있다고 합니다.
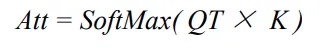

이 과정에서 모델은 첫 번째 캡션과 이미지 특징 간의 관계를 학습하고 동시에 이미지 특징을 활용해 첫 번째 캡션을 보완해 더 정밀한 문장을 생성하게 됩니다.
Feature Self-Enhancement Module
해당 모듈은 첫 번째 캡션에서 어떤 객체를 놓쳤는지 파악하기 위한 모듈로 추가되었다고 합니다.

구체적으로는
1. 판별기가 첫 번쨰 캡션에서 명사를 추출합니다.
2. 이 명사들을 객체 탐지 네트워크가 감지한 객체 카테고리와 비교합니다.
3. 그 결과, 첫 번째 설명에 포함되지 않은 객체 및 위치를 알아낼 수 있습니다.
4. 해당 객체의 이미지 영역을 다시 인코딩하여 (CNN에 태움) 원래 이미지 특징과 합쳐 최종적으로 강화된 특징을 얻습니다.
5. 이 강화된 특징을 두번째 인코더-디코더에 입력하여 더 완전한 캡션을 얻게 됩니다.

해당 수식들을 보면 알 수 있듯이, JUDGE 모듈이 빠진 객체 후보들을 찾아내고 ( v1,v2,..) 이들을 다시 인코딩하여 concat후 강화된 이미지 특징 A’ 을 만들어냄을 알 수 있습니다.
Experiments
데이터셋은 MS COCO로 평가했고 5개의 캡션이 제공된다고 합니다.
GLE, DED, FSE 는 각각 위에서 언급한 방법론들입니다.
GLE : Globla-Local Feature Extraction Module
DED : Dual Encoder-Decoder Module
FSE : Feature Self-Enhancement Module
B1, B4 = BLUE-1, BLUE-4 로 기계가 생성한 문장과 사람이 캡션으로 만든 문장 사이의 중첩 정도를 측정 예시 : B1 → “dog” 라는 단어가 겹치는지, B4 → “a black dog runs” 같은 연속된 4단어 일치 해당 지표 한계점은 문맥적 의미보다 표면적 단어 일치에 따른 성능입니다.
METEOR
BLEU 의 단점을 보완한 지표로 동의어, 어간, 어순까지 고려하여 의미적 유사성까지 반영된 지표입니다. 해당 지표의 한계점으로는 사람의 평가와 더 일관된 경향성이 보인다는 점입니다.
ROUGE-L
해당 지표는 기계 번역 혹은 문서 요약등에서 쓰이는 지표로 생성된 캡션과 정답 캡션 사이에서 공통된 가장 긴단어 시퀸스를 찾는 것으로 얼마나 자연스럽게 겹치는지를 보는 지표입니다.
CIDEr
해당 지표는 이미지 캡션 전용 지표로 MS-COCO에서 제안된 방법입니다. 여러 참조 캡션과의 비교를 가능하게 한 방법이라 생각하면 되고 ”A man riding a horse “ vs “ A person is riding a horse” 도 CIDEr은 의미적으로 가깝다고 평가합니다.
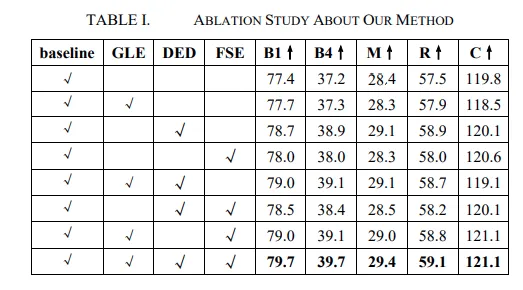
저자의 방법론중 단일로는 DED 를 적용했을떄가 성능 향상이 가장 커보이지만, 결국 ablation을 보면 전부 적용할때가 성능향상이 제일 큰 것을 알 수 있습니다. (2개씩 적용했을때는 성능이 비슷합니다.)
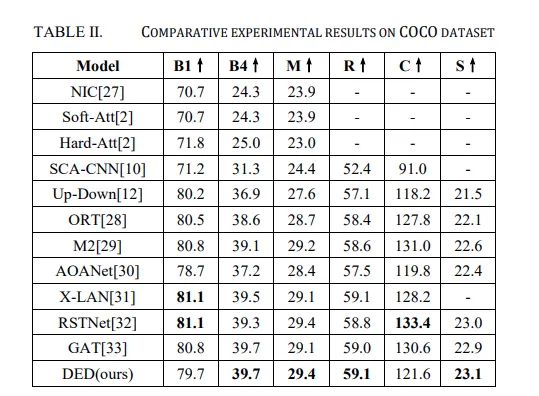
위의 table 은 ablation이며, 아래 표는 SOTA 방법론들과의 성능비교입니다.
아래 표에서 추가된 S 라는 지표는 SPICE 지표로 장면의 이해적 요소까지 고려된 지표입니다. 객체, 속성, 관계까지 고려한 지표로 BLUE 지표가 낮더라도 ( 단어 일치가 적더라도) man = person beach = ocean 등과 같이 단어를 치환하여 이해 관계를 평가하는 지표라 생각하면 됩니다.

해당 figure는 저자의 방법론을 거쳤을때 Single encoder-deocder 에서 Dual encoder-decoder 방식으로의 캡션이 더 장면적 요소나 객체의 속성, 상태등을 표현하고 있음을 알 수 있습니다.

해당 figure 는 저자의 방법론과 기존의 방법론의 caption 생성 차이입니다.
단일 Encoder-decoder를 쓰는 Transformer라고만 언급되어있어서 정확히 어떻게 뽑은건지는 모르겠지만 저자의 방법론과 동일한 방식에서 Dual encoder-decoder가 아닌경우라고 생각합니다.
Conclusion
이 논문에서는 Dual Encoder-Decoder 구조를 활용하여 Coarse – to – Fine 이미지 캡션 생성 방법을 제안했습니다. 뭔가 요즘 방법론들이 API 등을 불러와서 캡션을 딸깍 생성하는 경우가 많은데, 이런 연구도 진행되고 있다는 점도 좀 개인적으로 대단하다고 생각하고, Foundation 모델들과의 직접적인 성능지표 비교도 없고, 그런 컨셉으로 논문을 만든 것은 아니지만, 나름 저자의 방법론이 가지는 장점도 있을거라고 생각합니다.
논문이 생각보다 단순한 방법으로 사진 내의 존재하는 객체들의 속성이나 장면에 대한 해석을 포함하는 캡션을 생성해냈기 때문에 내가 나중에 어떠한 데이터셋에 이런 속성들을 포함하는 캡션을 추가적으로 생성해서 VLM 같은걸 학습시키고자 할때 괜찮지 않을까 싶어서 가져오긴 했습니다.. 다만 코드공개가 되어있지 않고, 대형 멀티모달 모델과의 성능비교가 없고, 사용자가 원하는 스타일로 캡션 생성이 가능한 것이 아니라는 점도 아쉽다고 생각합니다. 물론 생성된 캡션들을 보면 꽤나 정보량이 많아졌다고 생각합니다.
읽어주셔서 감사합니다!
안녕하세요 인택님 좋은 리뷰 감사합니다.
YOLOvx를 써서 객체 정보를 뽑고 Transformer encoder로 다시 지역적 특징을 뽑는다고 하셨는데,
그렇다면 YOLO의 성능이 한계가 되면 전체 captioning의 한계도 YOLO의 한계에 묶이지 않을까 하는 생각이 듭니다.
YOLO가 놓친 객체는 caption에서도 빠지게 될 것 같은데 논문에서 이런 dependency 문제를 언급했는지 궁금합니다.
그리고 인택님께서 결론에 말씀해주신 것 처럼 추가적으로 GPT 계열 모델과의 비교는 없어서 아쉽긴 했는데 이런 Foundation 모델과의 직접적인 비교를 하지 않은 건 의도적으로 피한 것인지, 아니면 당시 연구 시점의 한계였는지 궁금해져서 답글 드립니다!
fine-grained caption이라는 주제 자체가 GPT 계열과 비교했을 때 더 설득력이 있지 않았을까 이런 개인적인 생각이 들어서요!
감사합니다.
안녕하세요 우현님 답글 감사합니다.
저도 읽으면서 그부분을 생각하기는 했습니다. YOLOvx의 자체적 성능에 의존하는 것이 맞고, 애초에 학습시키는 데이터셋에도 편향적이긴 해서 만약 객체가 엄청 많이 존재하는 데이터셋의 경우 캡션의 성능이나 빠진객체가 없는지.. 등등 생각보다 제약사항이 많을 것 같습니다. 그리고 GPT 계열의 모델과 비교가 없는 부분이 제가 조금 알아보았었는데 평가하는 지표가 다른 것 같더라구요.. 완전히 동일한 평가지표로 비교한게 없어서 의도적으로 피한건지의 여부는 잘 모르겠습니다. 연구시점이 꽤 최근인거보면 한계점은 아니었을 것 같고.. 저런 캡셔닝은 여러 연구에서 쓰이는 부분인데 foundation 모델이 하는 역할을 대체할 수 있을 성능이라면 괜찮은 연구이지 않나 싶어서 읽게되긴 했습니다. 감사합니다.
안녕하세요 리뷰 잘 읽었습니다. 두번의 인코딩 디코딩 과정을 거쳐 캡션을 더 fine하게 한다는 접근이 흥미로웠습니다. Feature Self-Enhancement Module을 통해서 캡션에서 누락된 객체에 대한 정보가 추가되면서 강조되고 결국 캡션에 포함되게 된거다라고 이해했습니다! 단순한 궁금증인데요 듀얼만으로도 누락되는 객체가 모두 다뤄졌기 때문에 세번 네번 더 이상 진행할 필요성은 없었던 건가요?
안녕하세요 지연님 답글 감사합니다.
저 feature self-enhancement module은 음 메인 contribution 느낌은 아니고 듀얼 encoder-decoder로 coarse to fine 한 캡션을 만들었다는게 더 중요한 것 같아서 누락되는 객체가 모두 다뤄지는게 목표였으면 뭔가 더 추가적인 장치를 했을 것 같습니다. 이게 COCO 데이터셋에서의 객체를 찾으면 되게끔 학습되어서 그렇지 더 많은 객체 탐지가 필요로 되는 데이터셋이었다면 추가적인 장치가 필요할 것 같습니다. 위에 우현님이 언급해주셨듯이 단순 YOLOvx 의 성능에 객체탐지하는 부분이 의존적이라.. 어느정도 한계점이 있을 것 같습니다.
안녕하세요 인택님 리뷰 감사합니다.
Dual encoder-decoder 구조,, 흥미롭네요. 이러한 coarse-> fine 구조가 로보틱스 쪽에서도 응용되고 있는지 궁금하네요.
혹시 이러한 구조가 대상 객체가 어떠한 다른 물체와 어떤 공간적인 구조를 갖는지 spatial한 정보를 이해할 수 있을까요?
추가로 지금 방법론은 이미지 모달리티만을 이용해서 학습한다고 이해했는데 멀티모달로 확장할 수도 있을까요..?
안녕하세요 영규님 답변 감사합니다.
사실 이러한 연구가 다른 분야에서 얼마나 이용되고 있는지는 모르겠습니다. 해당 논문도 사실 여러 데이터셋에서 이게 확장가능성이 좋다 뭐 그런걸 어필한 논문은 아니라서 데이터의 환경에 따라서도 성능차이가 있을 것 같고, 공간적 정보의 이해가 가능할지를 잘 모르겠습니다. 모듈 구조에서 빠진 객체를 보강하는 부분은 있지만 각 객체의 위치에 따른 상황 이해나 공간적인 환경이해에 대한 부분을 추가적으로 만든다면? 가능할 것 같긴 합니다. 그리고 이미지 모달리티만을 이용해서 학습하긴 하지만 추가적인 정보를 넣어주려면 가능하긴 할 것 같습니다. 두번째 encoder-decoder 구조도 사실 recaptioning 과정에서 이전 caption 의 정보를 받긴 하기 때문에 충분히 가능할 것 같습니다.
안녕하세요, 인택님. 좋은 논문 리뷰 감사합니다.
Dual Encoder 구조를 사용해 놓친 부분을 검토한다는 점이 흥미로웠습니다.
리뷰를 읽으면서 두 가지가 궁금했는데요.
첫째, 듀얼 인코더를 사용하면 실시간성 측면에서 어느 정도 손실을 감수해야 하는지,
둘째, coarse 단계에서 발생한 오류가 fine 단계로 전파될 가능성은 없는지 여쭤보고 싶습니다.
다시 한번 좋은 리뷰 감사드립니다 🎥
안녕하세요 기현님 답글 감사합니다.
1. 실시간성 부분은 coarse 인코더가 비교적 경량 구조라 전체적으로 실시간성에서 많이 느려지지는 않을 것 같습니다. 또한 fine encoder만 사용했을때 수렴이 더 늦어질 수 도 있어서 크게 단점이 되는 부분은 아니라고 생각합니다.
2. 두번째로 생각해주신 오류가 전파될 가능성에 대해서도 충분히 생길 수 있는 문제점입니다. coarse 단계에서 잘못된 후보가 생성될 경우 fine 단게에서도 영향을 미칠 수 있는데, coarse 단계에서 recall에 신경쓰고 fine 단게에서 precision 을 보강하는 형태로 역할을 분리하면 좀더 방지할 수 있을 것 같습니다.
감사합니다.