이번에 소개드릴 논문은 ICCV2025에 게재된 논문으로 feature matching task를 다루고 있습니다. 제가 예전에 homography estimation 논문을 작성할 때 feature matching 방법론들 논문을 종종 보곤 했었는데 21~22년도쯤에 transformer를 기반으로 압도적인 성능을 보여주던 Loftr 논문 이후로 25년도에 들어서는 어떠한 방법론이 나왔을까 싶어 한번 찾아보다가 보게 되었습니다.
근데 결론부터 말씀드리면 해당 논문이 왜 ICCV에 됐는지 잘 모르겠어요. 성능이 좋아서인 것 같기는한데 전반적인 방법론 자체는 Loftr 논문의 framework 그리고 그 이후 후속 논문들과 결이 비슷한 것 같더라구요. loss 함수도 동일하게 사용하는 듯 보이고..
그래서 해당 논문에 대해서는 대략적인 컨셉과 해당 논문의 contribution만 다루려고 합니다. 그 외에 것들은 해당 논문에서 새롭게 제안한게 아니어서 굳이 다룰 필요는 없어보이고 혹시나 학습하는 과정이나 목적함수 등에 대해서 더 궁금하시면 제가 예전에 작성한 Loftr 논문 리뷰를 보시면 좋을 듯 합니다.
Intro
인트로 굵고 짧게 설명 들어가겠습니다.
- Learnable image matcher들은 특정 데이터 분포 또는 도메인에 과적합되는 바람에 generalization 성능 부족하더라.
- Vision Foundation model들은 대용량 데이터로 학습했기 때문에 generalization performance가 좋더라.
- 그래서 최근들어 DINOv2와 같은 Vision Foundation model의 feature representation의 도움을 받아서 learnable image matching 방법론들이 등장하더라.
- 근데 저자들이 따로 평가해보니 이러한 foundation model 기반 방법론들이 image feature matching에서 잘 좋은지 모르겠더라. 즉, 기존 Foundation model들은 single image 내 컨텐츠를 이해하는 것에만 몰두하다보니 cross-image의 관계성을 이해하는 것은 잘 못하는 것 같더라.
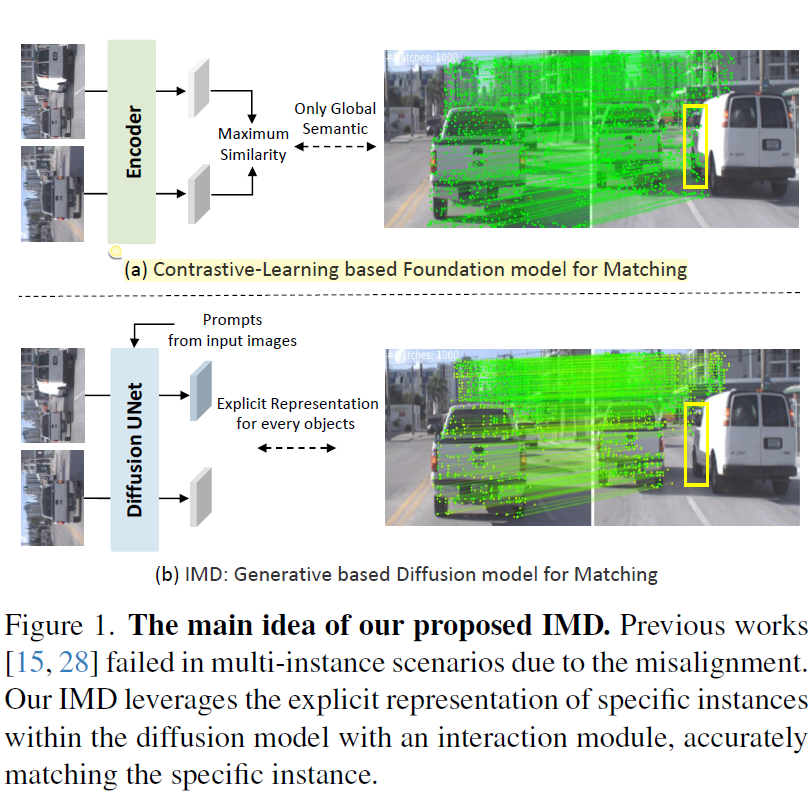
- 조금 더 구체적으로, Contrastive Learning을 통해서 Self-sup pretraining한 DINOv2 특성상 image의 global information을 중점적으로 학습하기 때문에 특정 instance에 대한 local information에 대해서 matching을 할 수준까지 feature를 뽑지 못한다는 것 같더라. <<(근데 제가 알기로 DINOv2가 image contrastive learning도 하지만 iBOT이라는 patch-level mask token modeling 학습도 같이 해서 local level도 충분히 고려가능할텐데 저자들이 DINOv1과 착각을 한것인지.. 이 부분은 너무 저자들의 주장을 곧이곧대로 믿으면 안될 것 같습니다.)
- 4~5번 정리해보면 기존 DINOv2 같은 foundation model들이 단일 영상에 대한 이해 능력이 뛰어나다고 해서 이것을 cross-image understanding도 자연스럽게 할 수 있다고 볼 수 없다고 생각하더라.
- 저자들은 Diffusion 기반의 generative based foundation model들이 서로 다른 외형의 다양한 객체를 생성하는 학습을 했기 때문에 그런지 좋은 local feature를 추출할 수 있었고, 생성 기반 모델들의 condition mechanism을 cross-image information interaction을 수행하기 위한 일종의 터널 역할을 할 수 있음을 발견하여 이 generative based foundation model들이 cross-image matching에서는 더 좋은 것 같음을 발견하였더라.
이렇게 위의 1~7로 인트로 내용을 정리해볼 수 있을 듯 합니다. 조금 더 부연설명하면 아래 그림1의 예시와 같이 동일하게 차량이라는 같은 의미론적 class가 있는 객체에 대해서 matching을 수행한다고 해야할 때 DINOv2와 같은 모델들의 feature로는 semantic한 부분만 고려하기에 서로 다른 차량임에도 불구하고 같은 차량으로 matching하는 경우가 종종 발생하는 것에 비해 diffusion 기반의 생성 모델들은 instance 간의 구분력이 DINO보다 더 좋은 것 같아서 feature matching하는데 있어 좋다고 저자들은 주장합니다.
Method
그럼 저자들의 방법론을 살펴보면 되는데 기존의 Loftr과 그 이후 후속 논문들을 아시면 사실 해당 논문의 framework도 직관적으로 받아들여질 듯 합니다.
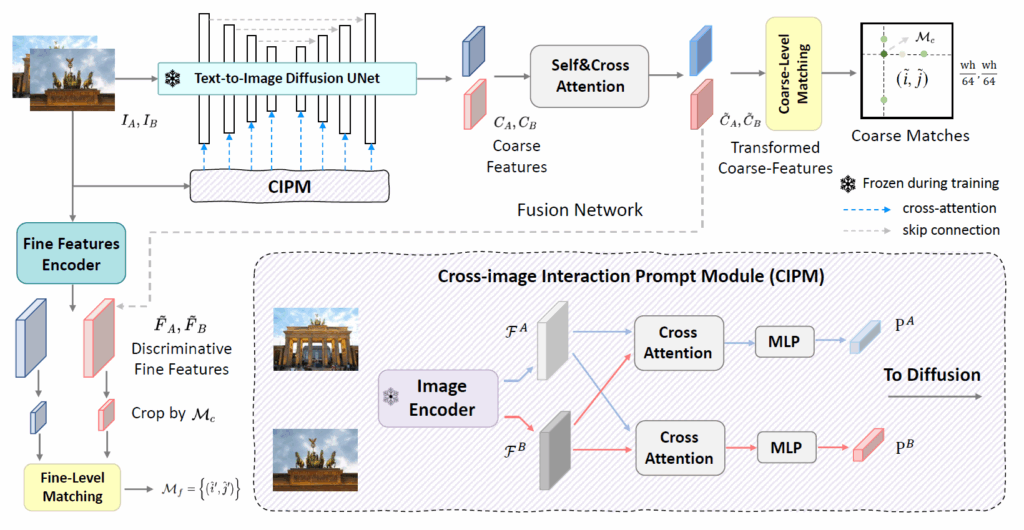
feature matching 방법론들은 크게 Coarse level과 fine-level로 구분이 되어있습니다. Coarse level은 입력 영상의 원본 해상도 대비 1/8정도 스케일의 feature map을, fine-scale은 1/2~원본 해상도 scale을 가진다고 봅니다.
보통 Loftr 방법론은 CNN의 FPN을 통해서 multi-scale feature map을 만들어 낸 후 이를 self-cross attention이 존재하는 모듈을 통해 coarse level relationship을 계산, 그리고 이 정보를 fine-level로 전달해서 fine-level matching까지 수행하고 있는데, 저자들은 Coarse level Encoding과 Fine-level Encoding을 따로 하는 듯 합니다.
우선 Coarse level matching이 가장 먼저 수행되면서 가장 중요한 부분이니 해당 부분부터 설명하도록 하겠습니다.
Text-to-Image Diffusion Model
저자들의 feature extractor는 Stable Diffusion model 기반입니다. 사실 Diffusion model에 대해서 다들 개념 자체는 어느정도 알고 계신다고 생각하기 때문에 짧게만 요약하면 Diffusion model한테는 forward 과정과 reverse라는 크게 2가지 과정이 존재합니다.
forward 과정은 다양한 크기의 가우시안 노이즈가 clean data에 추가되어 노이즈 데이터 샘플을 생성하는 과정입니다. 즉 I_{0} 라는 깨끗한 원본 영상이 있다면 아래 수식과 같이 해상 영상에 대해 점진적으로 noise를 삽입하여 noisy image I_{t} 를 생성하는 것이죠.
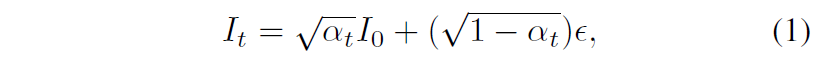
수식 1에서 e는 가우시안 랜덤 노이즈를 의미하고, t는 diffusion process의 time을 의미하며, 이 time 값이 크다라는 것은 영상 안에 더 높은 수준의 노이즈가 삽입된다고 보시면 됩니다. 그리고 \alpha^{T}_{t} 의 경우 사전에 정의된 노이즈 스케쥴을 의미합니다.
Reverse process는 모델 f_{\theta} 가 노이즈 입력 I_{t} 와 time step t 값을 입력으로 받아서 noise e 값을 예측하는 과정을 의미합니다. 일반적으로 영상 생성 분야에서는 이 f_{\theta} 를 UNet 구조를 사용하게 됩니다.한번 모델을 학습하게 되면, f_{\theta} 는 반복적으로 reverse 과정을 수행해서 노이즈가 없는 깨끗한 원본 영상을 생성하게 됩니다.
다시 저자들의 방법론으로 돌아가서, 저자들은 Stable Diffusion 모델을 활용한다고 말씀드렸습니다. SD 모델은 입력으로 노이즈 영상 뿐만 아니라 text나 image를 추가 input prompt로 활용이 가능한 모델입니다. 즉, 프롬프트 입력으로 깨끗한 input image I_{0} 와 timestep t 값이 들어오게 되면, 입력 영상은 우선 VAE Encoder를 통하여 latent representation z_{0} 로 변환됩니다.
그리고 reverse 단계에서는 latent code z_{t} 와 timestep t와 prompt embedding P가 입력으로 사용되며, denoising Unet의 중간 레이어 출력물로 F라는 feature map을 추출하게 됩니다. 즉 위의 과정들을 수식으로 나타내면 아래와 같습니다.
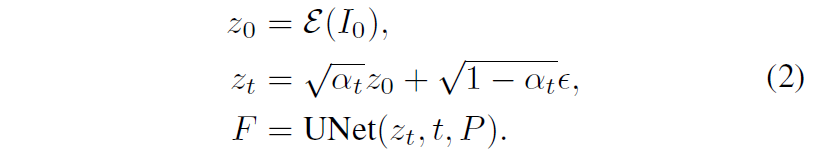
여기서 t 값이 큰 경우와 초기 network layer들에서는 semantically-aware feature를, 더 작은 t 그리고 뒷단 레이어에서는 low-level detail이 담긴 feature map F를 생성한다고 합니다. 그래서 자신들의 필요에 따라 t 값을 어떻게 설정할 것인지도 중요하다고 하네요.
그리고 Stable Diffusion Model의 경우 text와 image가 서로 pair된 데이터셋으로 사전학습이 됐습니다. 따라서 기존 SD Model 내부에는 text prompt와 image feature 간에 관계성을 고려하는 cross-attention layer들이 존재하며, 이는 Unet이 noisy image를 어떻게 denoising할 것인지 판단할 때 text 정보를 활용한다고 합니다.
즉 수식2에서 image feature는 input prompt feature P와 밀접한 관련이 발생한다는 것이고, 저자들은 이러한 SD model의 작동 방식이 두 이미지 사이의 관계성을 고려해야만 하는 image matching task에 적합하다고 판단을 하게 됩니다.
기존에 semantic correspondence task나 image segmentation task에서는 그냥 단순히 input prompt embedding과 image embedding 사이를 concat하여 사용했었는데 이 방식이 자신들의 image matching task에서는 과연 적합할 것인가에 대해 저자들은 의문을 품었다고 합니다.
즉 두 영상 사이의 관계성을 고려해야만 하는 matching task에서 단순히 concatenating 하는 방식은 좀 아니다 싶어서 저자들은 Cross-image Prompt Module(CIPM)이라는 것을 새롭게 제안하게 되는데 사실 이름만 거창하지 아까 전체 architecture 그림 보셔서 아시겠지만 CIPM은 그냥 단순히 두 이미지 간에 Query, Key, Value를 서로 번갈아가면서 전달해주는 Cross-attention에 해당합니다.
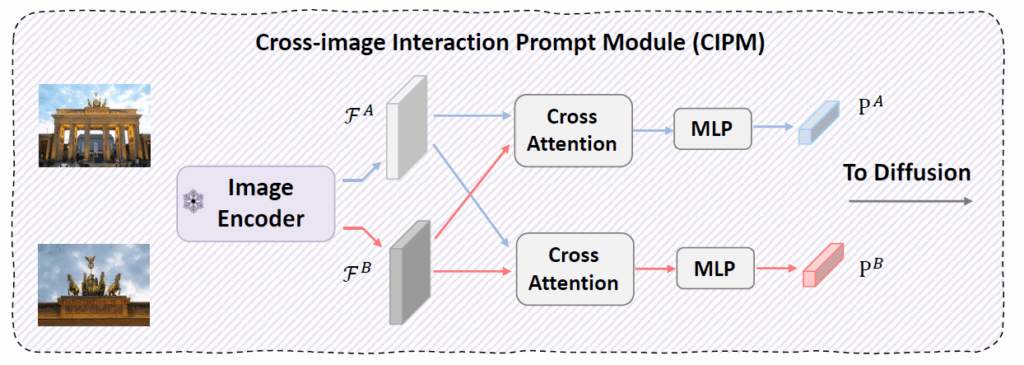
아래는 CIPM의 과정을 수식으로 나타내긴 한건데, 수식적으로만 봐도 별다른 것 없이 저희가 아는 Cross-Attention입니다.
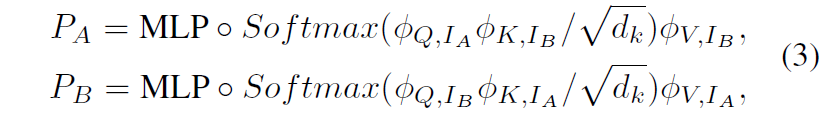
이렇게 두 영상 사이의 관계성을 잘 고려한 prompt embedding이 마무리되었다면 해당 embedding은 denoising UNet의 입력으로 함께 사용이 됩니다.
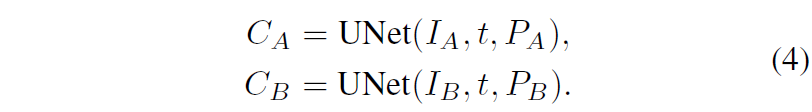
Coarse Level Matching Module
수식4를 통해 두 pair image에 대하여 Coarse level feature map들을 잘 추출하였다면 이제 두 feature 사이의 matching을 수행하는 과정이 필요로 하게 됩니다. 근데… 이 매칭 방식은.. Loftr 논문에서 제안하는 방식과 동일합니다. 그래서 해당 논문에서도 그냥 기존의 연구들과 동일한 방식을 사용했다 하고 아무런 수식과 구체적인 설명 방법 언급 없이 넘어가버립니다. 마침 제가 예전에 Loftr 논문에 대해서 리뷰를 써놓은 것이 있으니 그 부분을 참고해주시면 감사하겠습니다.
Coarse Level matching 마치면 해당 정보를 활용하여 sub-pixel level의 refinement 과정도 수행해야하는데 이 과정도 역시나 이전의 연구들과 동일하게 활용하였기 때문에 논문에서 구체적인 수식과 과정 설명은 전혀 없습니다. 그리고 기존 연구들이 Coarse level matching과 fine-level matching 각각에 대해서 loss를 계산하는데 그 loss를 그대로 활용하였기 때문에 역시나 논문에서 디테일한 설명은 없습니다 허허.
Experiments
우선 feature matching 방법론들은 다양한 task에 대해서 평가를 진행합니다. 가장 무난하게는 두 영상을 주고 모델이 correspondence points들을 뽑았을 때 이들이 얼만큼 잘 매칭이 되었는지에 대해서 평가하는 방식도 있고, 대응 관계를 계산하는 task인 homography estimation 또는 두 영상 사이의 pose estimation 등등 대응관계를 기반으로 계산할 수 있는 mapping matrix의 정확도를 추정하는 방식등이 존재합니다.
근데 이제 저자들이 주장하는 바 중 하나로는, 기존에 연구들이 megaDepth dataset이나 ScanNet 데이터셋을 많이 활용하는데 megaDepth dataset의 경우 어떤 관광지와 같이 landmark가 촬영된 영상들이고, ScanNet도 이와 유사하게 어떠한 하나의 main instance를 촬영한 영상들이 평가 데이터로 구성되어있었다고 합니다.
이러한 평가 데이터 구성은 결국 모델이 영상 내 하나의 main이 되는 instance에 대해서 의미론적으로 잘 파악하고 해당 부분만 고려해도 matching을 성공적으로 수행할 수 있음을 나타내는 것이죠. 이러한 평가 방식은 아까 intro에서 보여드렸던 예시처럼 자동차와 같이 동일한 semantic class를 가지는 instance들이 두 영상 내에서 다수 등장하게 된다면 올바른 instance들 간에 매칭점을 과연 잘 구할 수 있는지?에 대해서 평가하기 어렵다고 하더라구요.
그래서 저자들이 Image Multi Instance Matching이라고 하는 IMIM 평가 방식에 대해서 새롭게 제안을 합니다. Segmentation과 Tracking task를 연구하는데 활용되는 BURST 데이터셋을 활용하게 되는데, 해당 데이터셋이 tracking도 연구하는 데이터셋이다보니 unique object와 그 외에 다른 class의 instance들이 등장을 하게 됩니다. 저자들은 이러한 video들에서 비디오 내 2개의 frame을 선별하여 학습 데이터셋을 구축하였고 결과적으로 총 50개의 비디오에서 100개의 영상 쌍을 만들어 IMIM을 평가하였다고 합니다.
IMIM의 평가 방식은 먼저, 정답 마스크(ground-truth mask)를 이용해 원본 이미지와 대상 이미지에서 관심 있는 객체 영역만 잘라냅니다. 그 다음, 이미지 간에 찾아낸 모든 특징점 쌍(i, j)에 대해, 시작점(i)이 원본 이미지의 객체 영역 안에 포함되는 쌍의 총개수(N)를 셉니다.
최종적으로 이 N개의 쌍 중에서 시작점(i)과 도착점(j)이 둘 다 각각의 이미지 객체 영역 안에 제대로 들어간 쌍의 개수(M)가 차지하는 비율(M/N)을 성능으로 리포팅하게 됩니다. 조금 더 부연설명 붙이면 source image 내에서 특정 객체 안에 뽑힌 point들을 i라고 하구요, 이 i와 대응되는 target image의 point들이 j라고 했을 때 N은 j가 동일 객체 안에 있든지 밖에 있든지 상관없이 우선 source image 내 객체에 존재하는 포인트 i의 개수를 의미합니다.
그리고 M은 target image 내 대응되는 객체 내부에 있는 point들 중 i와 실제로 매칭되는 포인트의 개수를 의미합니다. 즉 M은 올바르게 동일한 객체를 가르키는 대응점들의 개수를 의미하는 것이며 N은 한쪽 영상에서는 객체 내부의 점들을 의미하지만 다른쪽 영상에서는 동일 객체이든아니든 일단 매칭이 된 모든 포인트의 수를 나타내는 것이죠.
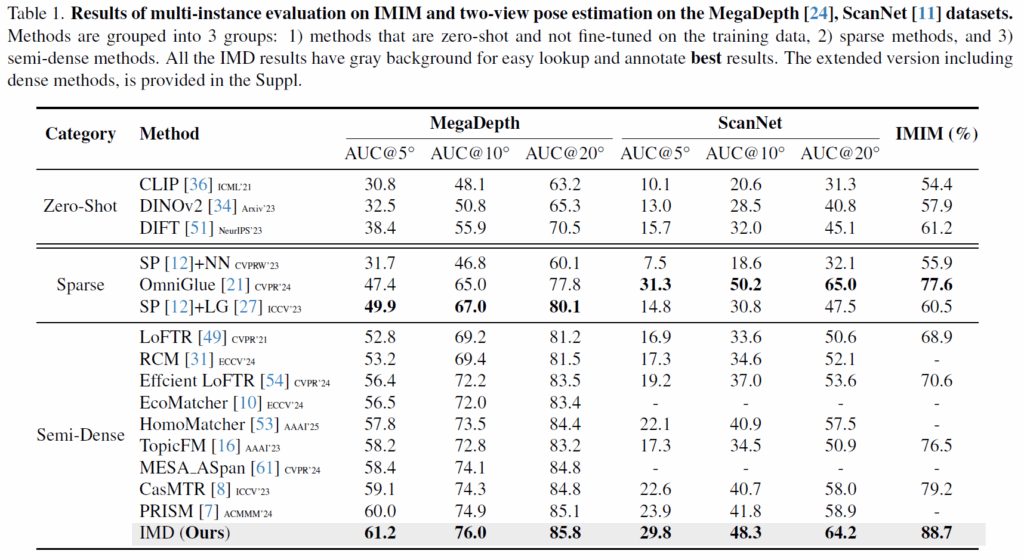
위에 표는 MegaDepth 데이터 셋과 ScanNet 데이터셋 그리고 저자들이 새롭게 제안하는 IMIM의 평가 지표를 나타냅니다.
우선 CLIP, DINOv2, DIFT와 같은 foundmation model들의 zero shot 성능은 확실히 낮은 것을 보임으로써 이들이 두 이미지 사이의 feature matching을 수행하는데 있어서는 부적합하다라는 것을 이야기 하고 있습니다. 그리고 Super point와 이 key point들을 matching하는 Sparse matching 방법론들 보다도 LoFTR과 같은 Semi-Dense 계열들이 MegaDepth dataset에서는 더 좋은 것을 확인할 수 있고, 이러한 SemiDense 방법론들 중에서는 저자들이 제안하는 방법론이 가장 좋은 것을 볼 수 있습니다.
물론 ScanNet 데이터셋에서는 Sparse 방법론들 중 OminGlue라는 방법론이 Semi-dense 방법론들보다 더 좋은 모습을 보여주고 있는 모습이네요. 하지만 저자들이 제안하는 IMIM 평가 방식에서는 저자들의 방법론이 가장 좋은 성능을 보여주는데 저자들은 이것이 유사한 semantic 정보를 가지지만 서로 다른 instance 임을 기존 방법론들이 명확하게 판단하지 못하는 반면 Diffusion 기반의 생성 모델의 feature를 활용하면 충분히 가능하다라는 점을 어필하고 있습니다.
Ablation study
다음은 Ablation study 관련입니다.
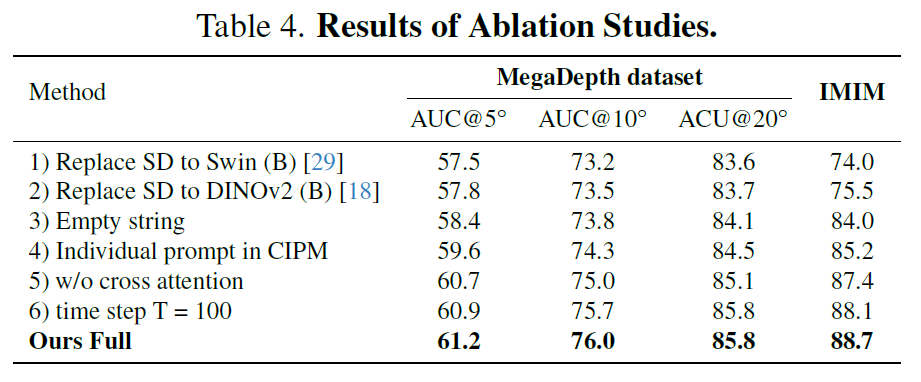
우선 Stable Diffusion model을 Swin Transformer로 바꾸었을 때 전반적으로 모든 metric에서 성능이 떨어지는 것을 볼 수 있습니다. 또한 Swin Transformer가 아닌 DINOv2로 바꾼다 할지라도 역시나 성능이 떨어지는 것을 확인할 수 있는데, 이를 통해 Supervised Learning을 하던, Contrastive Learning을 통한 self-sup learning을 하던 discriminative한 모델들은 feature matching 관점에서 구분력 있는 좋은 feature를 뽑지 못한다는 것을 주장하고 있습니다.
다음으로 3번과 4번, 5번 실험은 저자들이 제안하는 CIPM과 관련된 ablation 입니다. Stable Diffusion model에게 전달할 input prompt를 embedding할 때, 3번의 경우 프롬프트를 아예 주지 않았을 때를 의미하는 것으로 보이고, 4번의 경우 source와 target image 두 입력을 넣는 것이 아닌 단일 이미지에 대해서만 CIPM 모듈에 태워서 prompt를 만드는 것을 의미합니다.
마지막으로 5번은 CIPM 내 cross-attention 연산이 아닌 단순히 A와 B embedding에 대해 concatenating한 결과를 의미하는 것으로 결과적으로 3,4,5 차례대로 성능이 개선되는 것을 볼 수 있습니다. 이 말은 프롬프트 정보가 있으면 성능이 오른다는 것이고, 하나의 이미지보다는 두 영상 간의 대응관계 차원에서 두 영상의 프롬프트 정보를 사용하면 더 좋다는 점, 마지막으로 대응 관계를 계산해야하는 관점에서 프롬프트 임베딩에도 cross-attention으로 직접적인 관계성을 고려해주면 가장 성능이 좋다는 것을 의미합니다.
그리고 6번 실험은 stable diffusion model에서 time step t값을 몇으로 설정하는지에 대한 실험인데 결론부터 말씀드리면 저자들은 t값을 0으로 하거든요? 즉 SD model에서 곧바로 feature 뽑아서 feature matching하는데 사용한다는 말인데 만약 t값을 100으로 두어서 denoising하는 과정을 수행하게 되면 오히려 모든 메트릭에서 성능이 하락한다고 합니다.
결론
음.. 솔직히 참신한 부분은 없거든요? 3년전에 제가 읽은 Loftr에서 바뀐거라고는 feature matching을 위한 feature extraction 과정에서 Foundation model들 중 Stable Diffusion model을 쓰는게 좋더라? 밖에 없어서.. 그리고 평가 방식에서 IMIM이라는 새로운 평가 방식을 제안했다는 점 정도 밖에 없다고 생각이 드네요.
그럼 과연 저자들의 발견이 이렇게까지 파급력이 있는 것인가 라고 하면 저는 잘 모르겠습니다. DINOv2가 워낙 이곳저곳에서 잘 사용되고 있고, 좋은 feature representation을 가진다고 하니깐 과연 이것이 feature matching 관점에서도 잘 될까 했는데 생각보다 별로였다는 것이고, 오히려 stable diffusion과 같은 생성 모델이 feature matching 관점에서 더 좋네?라는 것은 흥미롭게 보여지긴 하지만 이게 ICCV 논문이 될 정도까지의 대단한 발견인건지에 대해서는 사람마다 의견 차이가 있을 듯 합니다.
그리고 사실 CroCo와 같이 두 이미지 사이의 대응관계까지 다 고려한 self-sup pretrained foundation model들이 있거든요. 이 CroCo의 성공 덕분에 Dust3r라는 FM이 생겨나고 이를 기반으로 다양한 파생 모델들이 미친듯이 나오는 와중에 왜 꾸역꾸역 DINOv2를 걸고 넘어지는지 잘 모르겠어요. CroCo랑 비교했을 때도 Diffusion model 얼만큼 좋은 성과를 내는지 비교해주었다면 더 좋은 논문이 되었을텐데 그 부분이 참으로 아쉽게 느껴집니다.