안녕하세요. 이번엔 VLM high-level planning과 RL+IL의 low-level execution 간의 각각의 장단점을 보완해서 중간에 저자들이 제안한 symbolic bridge 방식으로 안정적으로 통합하는 general manipulation 프레임워크를 들고 왔습니다.
Introduction
다른 분야도 다들 그럴테지만 특히 로봇 분야에서 일반화라는 워딩은 그 기대 가치가 어마무시합니다. 그러다보니 open 시나리오에서 로봇을 동작시키는 것은 robotics분야에서 중요 흐름 중에 하나라고 할 수 있습니다. 그러려면 보통 로봇이 자연어 명령을 이해하고 역동적인 환경 변화와 불확실성에도 적응하면서 복잡한 작업을 정확하게 수행해야 합니다. 최근 NLP 및 MLLM 등의 발전으로 복잡한 명령에 대한 로봇 태스크 이해 능력이 향상되었지만,조작 관점에서는 여전히 open 환경에서 복잡한 명령을 처리할 때, 두 가지 주요 문제인 절차적 기술 딜레마와 선언적 기술 딜레마에 직면해 있다고 합니다. 이렇게만 들으면 뭔소린지 모르겠어서 좀 더 정리해봤는데, 절차적 기술 딜레마(procedural skill dilemma, 안정적인 실행(robust control)과 샘플 효율성/현실 적용성 사이의 트레이드오프)’와 ‘선언적 기술 딜레마(declarative skill dilemma, 풍부한 고수준 추론 능력과 실제 물리적 실행 가능성 사이의 불일치 )’ 문제라고 보시면 되겠습니다.
- procedural skill dilemma(절차적 기술 딜레마)
명령에 따라 물체를 조작하는 능력을 얻기 위해 RDT-1B(ICLR 25’) 및 \pi_0, RT1, Octo 같은 VLA 즉 imitation learning 기반 embodied model은 일반적으로 data-driven한 robot trajectory 피팅 방법론을 사용합니다. 그러나 이러한 방법은 조명 조건의 변동, 카메라 자세 차이, 상황 변화 등등의 환경 변화에 직면했을 때 성능이 급격히 저하되는 경우가 많았습니다.(이 경우는 The COLOSSEUM[RSS 24’] benchmark 연구를 언급하네요.) RL같은 경우에는 이런 면에서 robust하긴 하지만, 학습 과정 자체가 시행착오적 특성을 가지고 학습 효율이 낮아 Real world에서는 적용하기 어렵다는 문제가 있습니다.
- declarative skill dilemma(선언적 기술 딜레마)
ReKep 및 OmniManip과 같이 VLM을 로봇 시스템에 통합하려는 방식으로 대규모 멀티모달 지식을 사용하여 open 도메인 작업에 대한 작동 명령을 생성하는 접근도 있습니다. 이런 경우 이해 능력은 뛰어나지만 embodied experience 즉 low-level action에서 부족한 모습이 보입니다. 즉 output을 실행 가능한 행동의 조합으로만 제한해야 합니다. 보통 이러면 언어 모델이 물리적 직관 없이 spatial한 reasoning을 처리하도록 강요하므로 비현실적인 작업 계획이 초래되는 경우가 많습니다. 예를 들어 “블록 A를 블록 B 위에 놓기” 작업에서 불충분한 공간 이해(예: 모양, 높이)는 이러한 종류의 방법이 치명적으로 결함이 있는 작업 시퀀스를 생성하도록 유도하는 경우가 많습니다. action 관점에서의 hallucination이라고 봐도 되겠네요.
아쉽게도 위의 딜레마 문제에 대해, 기존의 대부분 방법들 (RT2, OpenVLA) 은 여전히 MLLM의 능력을 제한하여, 이들이 저수준 실행 명령을 생성하게 만들고, 이를 data-driven한 다운스트림 제어단으로 연결하는 식으로 작업을 수행하도록 합니다. 이러면 open 시나리오에서 어느 정도의 작업 수행은 가능할 수 있겠지만, 본질적으로 인지적·실행적 능력 서로를 조금씩 내려놓으면서 절충하는 식이라고 볼 수 있습니다. 저자들은 해당 문제를 통해 반대로, 만약 MLLM의 선언적(declarative) 과제 수행 능력과 RL의 절차적(procedural) 과제 수행 능력을 상호 간섭 없이 동시에 활용할 수 있다면, 로봇은 개방형 과제를 처리하는 데 있어 큰 돌파구를 마련할 수 있을 것이라 생각했습니다. 즉, 어떻게 하면 MLLM과 RL이 각자의 강점을 충분히 활용하면서 상호 보완하는 새로운 프레임워크를 구축할 수 있을 것인가, 그리고 궁극적으로 open 시나리오에서의 능력을 극대화할 수 있을 것인가입니다.
cognitive domain에서의 중앙 패턴 발생기(CPG, Central Pattern Generator) 이론연구들에 따르면, 인간이 고수준 추론에서 저수준 제어로 전환되는 과정에서 뇌가 “걷기”와 같은 메시지를 전달할 때, 특정 추상적 개념에 대응하는 특정 신경세포가 환경의 구체적 모습(외형, 색, 크기 등)과 무관하게 항상 활성화된다고 합니다. 이러한 신경세포의 활성화는 운동 영역의 활동 수준을 조절하고, 결국 환경적 조건에 맞춰 정밀한 행동이 나타나게 됩니다. 예를 들어 왼발 혹은 오른발로 얼마만큼 큰 보폭을 내딛을지를 결정하는 식입니다. 저자들은 이 이론에서 영감을 받았습니다. 고수준 추론과 저수준 제어 간의 소통은 직접적인 명령 전달이 아니라, 물리적 직관과 환경 불변성을 지닌 일반화된 상호작용 표현을 거쳐 (추상적 인지 – 구체적 실행) 간을 연결하는 symbolic bridge 역할을 할 수 있다는 것입니다.
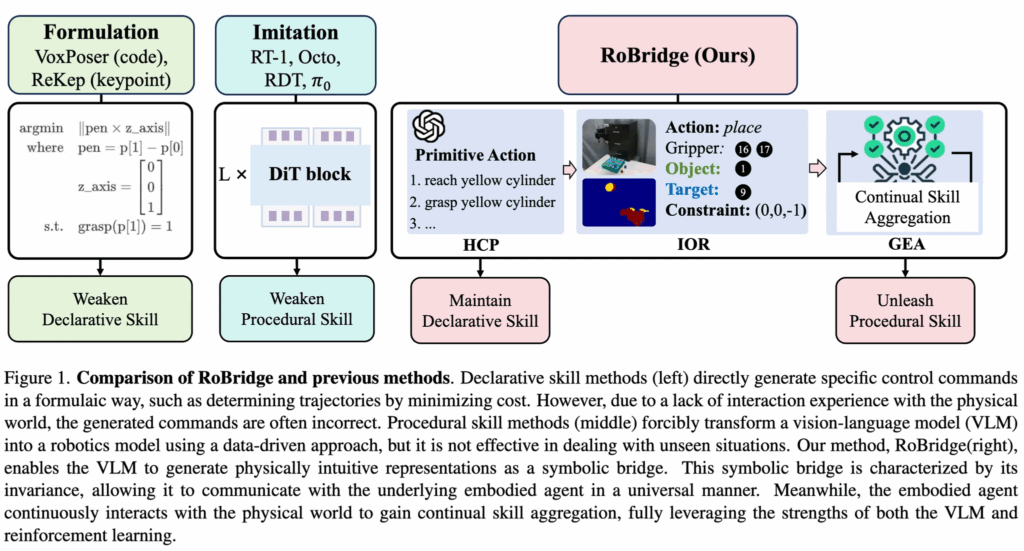
본 논문에서는 로봇조작의 일반화를 목표로 한 hierarchical intelligent architecture RoBridge를 소개합니다. 위의 그림 1에서 보듯이, 제안하는 방법은 VLM의 declarative skill을 유지하면서 강화학습의 procedural skill까지 모두 써먹는 방안을 취합니다. 세 가지 핵심 요소로 구성되는데, 크게 pre-trained VLM을 기반으로 인과적인 추론을 먼저 실행하는 High-level Cognitive Planner(HCP), 추상적 인지와 구체적인 실행 사이에서 symbolic bridge 역할을 하는 물리적 직관과 환경 불변성을 지닌 Invariant Operable Representation(IOR), 그리고 물리 세계와의 상호작용을 통해 정밀한 실행 행동을 구현하는 Guided Embodied Agent(GEA)로 구성됩니다. HCP에서 VLM으로 high-level 추론먼저하고, 그 사이를 IOR로 연결해주고, low-level output단으로 가서 GEA로 RL을 하는 연구가 기존엔 이를 일부요소만 부분적으로 다뤘었는데, 저자들이 말하길 IOR을 매개로 앞뒤단의 declare skill 과 procedural skill을 상호제약없이 통합한 최초의 시스템이라고 하네요.
실험적인 contribution만 짧게 언급하고 넘어가자면, RoBridge는 unseen 환경에서도 일반화 능력을 발휘하며, baseline 대비 새로운 5개 과제에서 75%의 성공률을 기록했습니다. 또한 작업 당 5개의 실제 데이터 샘플만 사용하는 sim-to-real 일반화에서도 탁월한 성능을 보이면서 평균 83%의 성공률을 달성했다고 합니다.
Method
Framework
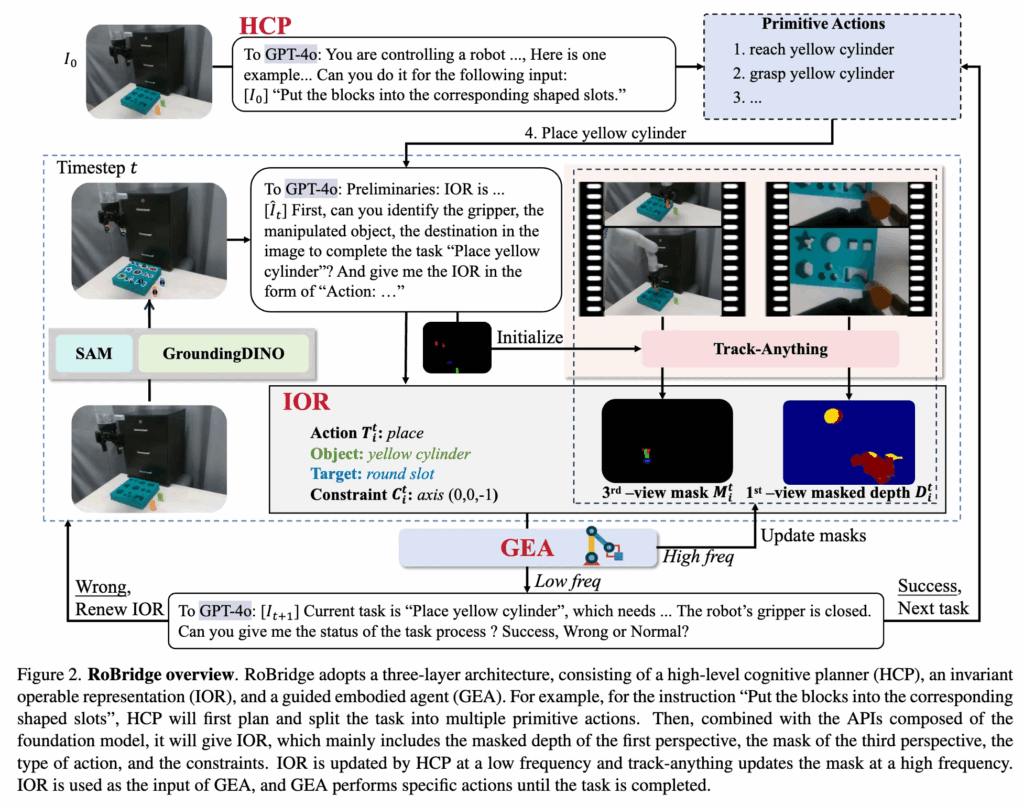
크게 세 부분으로 나뉘어서 HCP → IOR → GEA 의 흐름으로 프레임워크가 구성된다고 했습니다. 먼저, HCP는 관찰 정보와 지시에 기반하여 작업을 primitive action으로 분해합니다. 그 후, 각 행동마다 HCP는 SAM, G-DINO, Track-Anything 등의 VFM들을 사용해서 IOR을 생성합니다. 마지막으로, GEA가 만들어진 IOR 표현을 활용하여 실제 물리적 동작을 수행하며, 전반적인 실행 과정은 closed-loop control로 조절되는 방식을 취합니다.
<HCP (High-level Cognitive Planner)>
HCP는 기본적으로 GPT-4o를 이용한 high-level planning을 수행합니다. 우선 현재시점의 관찰된 RGB 이미지 I_0[latex]/ 와 instruction [latex]l 이 주어지면, GPT-4o에 쿼리해서 작업을 여러 primitive action으로 분해합니다. 각 primitive action A_i=\{T_i,obj_i,des_i\}에서의 각각의 요소는 순서대로 action type, 조작할 object 이름, destination(없을 수도 있음.) 입니다. 예를 들어 위 그림 2 에서의 분해결과를 표현해보면 다음과 같습니다.
A_1 = \{\text{reach}, \text{yellow cylinder}, \text{none}\} A_2 = \{\text{grasp}, \text{yellow cylinder}, \text{none}\} A_3 = \{\text{reach}, \text{round slot}, \text{none}\} A_4 = \{\text{place}, \text{yellow cylinder}, \text{round slot}\}
또한 각 primitive action의 language definition은 위 표6과 같습니다.
<IOR(Invariant Operable Representation)>
IOR에선 각 primitive action A_i 와 센서 데이터를 IOR R_i 로 변환하는 과정을 거치게 됩니다.
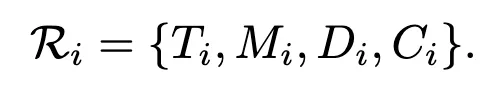
구성은 위와 같은데, 순서대로 action type, 3인칭 시점의 mask, 1인칭 시점의 depth mask, 제약 조건이 되겠습니다. 좀 더 디테일 하게 M_i에선 그리퍼, 조작 대상 객체, 목적지(존재할 경우)의 3인칭 시점 마스크를 포함합니다. D_i에선 같은 요소들에 대한 핸드 아이 그리퍼의 1인칭 시점 Depth mask이구요. C_i는 end-effector의 pose와 이동방향 axis를 나타냅니다.
과정은 다음과 같은데, 먼저 G-DINO와 SAM을 통해서 primitive action과 관련된 객체를 분할합니다. 이후 다시 GPT-4o prompting을 활용해서 SoM(Set-of-Marker) 방식으로 최종적으로 이 객체들을 선택합니다. 해당 객체 분할 mask 정보는 Track-Anything을 위한 initialize값으로 주어집니다. 서랍 열기나 수도꼭지 돌리기 같이 방향성이 요구되는 작업의 경우 HCP는 정규화된 방향 벡터 d∈R3 을 내놓고, 이를 제약조건에 포함시키는 방식으로 진행했다고 합니다. 이렇게 센서 데이터와 통합하여 최종적으로 prompting으로 IOR 구조를 formulating 합니다. 일관된 표현으로 IOR를 표현하면서 RoBridge가 도메인 불변성을 확보하고 환경이나 태스크 변화가 모델에 미치는 영향을 줄이도록 설계한 것이라고 보면 될 것 같습니다.
<GEA(Guided Embodied Agent)>
각 시점마다 새로운 R_t^i가 생성되며, 구체적인 갱신 과정은 이후 closed-loop 부분에서 설명됩니다. 각 R_t^i를 로봇의 움직임 a_t로 매핑하여 primitive action을 진행해야 하는데, GEA는 RL방식을 활용한다고 했으니 즉, 정책 \pi(R_t^i) \mapsto a_t를 학습해야 합니다. PSL(Plan-Seq-Learn, ICLR 24’)을 따라, primitive action “reach”는 일반적으로 로봇 end-effector를 명확히 정의된 목표 위치로 이동시키는 것을 의미합니다. 이는 grasping이나 placing처럼 복잡한 객체 상호작용이나 의사결정을 포함하지 않으므로, 효율적으로 모션 플래닝으로 해결할 수 있습니다. 다른 primitive action들의 경우, RL과 IL을 결합해 GEA를 학습하여 다양한 입력 조건에서도 강건성과 일관된 성능을 확보하도록 합니다.
큰 흐름만 얘기하고 디테일은 밑에서 추가로 다루겠습니다.
<Closed-Loop Control>
동적 환경에서 primitive action의 정보 정확성과 반복 수행을 보장하기 위해 closed-loop control 을 수행합니다. 각 부분의 속도가 다르기 때문에 high-frequency 제어와 low-frequency 제어로 나눕니다.
high-frequency 제어: 새로운 센서 데이터를 수집하고 Track-Anything을 이용해 M_i^t, D_i^t를 갱신해 업데이트된 R_i^t를 얻습니다.
low-frequency 제어: 작업의 상태(success, wrong, normal)를 판단합니다. 이를 위해 GPT-4o와 그리퍼 상태(열림/닫힘)를 함께 활용합니다. 입력으로는 태스크 관련 객체 태그가 포함된 RGB 이미지 \hat{I}^t, 그리퍼 상태, primitive action을 제공합니다. GPT-4o는 이를 기반으로 현재 행동이 성공했는지 실패했는지를 판단합니다. 판단 결과가 성공이면 다음 행동으로 넘어가거나 모든 행동이 끝났을 경우 작업을 종료합니다. 반대로 실패라면 입력 R_i를 다시 생성하여 재실행합니다.
Guided Embodied Agent(GEA) Training
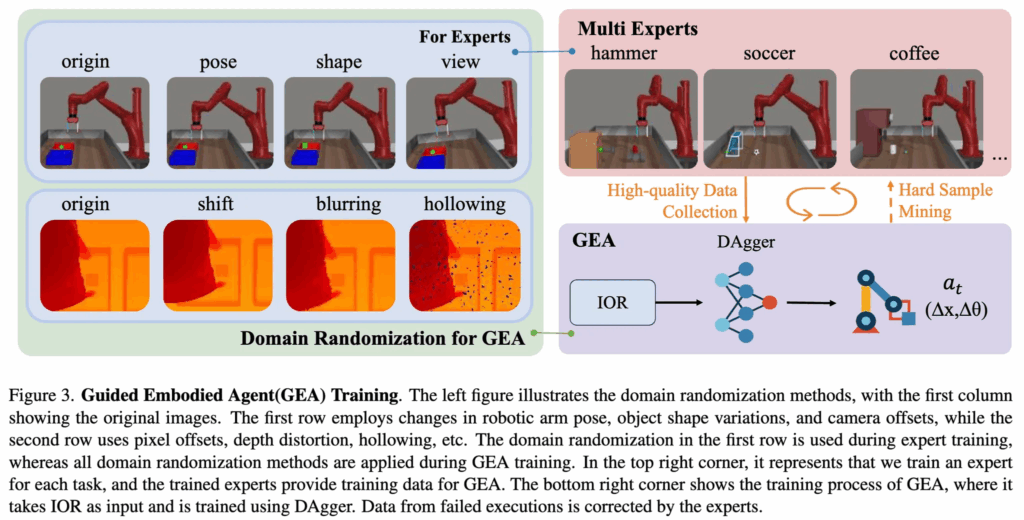
위 그림 3에서 보이듯이 Multi Experts 학습하고 GEA 가 학습되는 multi-stage training 방식이 적용되었습니다.
<RL Training>
초기 단계에서는 우수한 성능 확보가 필수적입니다. 이를 위해 강화학습 기법을 활용하여 각 특정 작업에 대해 Multi Experts Agent(\pi_e)를 학습시킵니다(위 그림3에서 빨간 영역). 이로써 각 작업이 높은 숙련도로 수행되도록 보장합니다. 또한 전문가 에이전트의 강건성을 높이기 위해, 학습 과정에서 domain randomization을 적용하여 객체 shape, 로봇 팔 pose배치, 카메라 view 등을 다양하게 변형합니다.
<IL Training>
다음 단계에서는 GEA(\pi_g)를 학습시키기 시작합니다(보라색 영역). 이를 위해 Expert Agent가 각 태스크에 대해 고품질 데이터를 생성하도록 하고, 그 데이터에서 일반화된 상호작용 표현 IOR R을 추출하여 \pi_g의 입력으로써 사용하게 됩니다. (여기서 의문인 점이 있긴한데,, GPT4o 없이 여기서 어떻게 IOR을 뽑아냈는지는 의문이긴 합니다.) Expert Agent 학습 시 적용했던 도메인 랜덤화에 더해, GEA에선 심화된 기법들을 추가하는데, 깊이 왜곡(depth distortion), 팽창(dilation), 무작위 시프트(random shifting), 마스크 정보의 추가 및 삭제(modification of masked information) 등이 포함됩니다. 이러한 방식으로 학습된 에이전트가 다양한 환경 조건에서도 더 나은 일반화 성능과 강건성을 발휘하도록 도운 것으로 볼 수 있겠습니다. 또한, 실제 환경에서의 노이즈가 많은 depth 센서를 시뮬레이션하기 위해 depth 이미지 처리 과정에서 ManipGen(ICRA 25’) 에서 사용된 아래의 다양한 증강 기법을 적용했다고 합니다.
- Depth warping: 가우시안 변화를 적용하여 시점 및 센서 노이즈 변화를 시뮬레이션.
- Gaussian blurring: 센서의 블러 및 초점 문제를 모방.
- Random masking: depth 맵에 인위적인 홀(hole)을 만들어 occlusion 및 누락 데이터를 시뮬레이션.
- Random offsets & random cropping: 모델이 생성한 마스크의 부정확성과 불완전성을 보완하고, 에이전트가 특정 마스크에 과도하게 의존하지 않도록 방지.
<Continual Skill Aggregation>
ALOHA를 내놓았던 ACT 방법론에서 말하길 IL에서는 종종 오류 누적(compounding errors) 문제가 발생한다고 합니다. 이를 해결하기 위해, 저자들은 DAgger (Dataset Aggregation)(2010') 방식을 이용한 반복적 최적화 전략을 도입했습니다. 하지만, 온라인 DAgger는 불안정성을 야기할 수 있고, 오프라인 DAgger는 다중 작업 환경에서 업데이트 속도가 느립니다. 따라 adaptive sampling mechanism을 갖춘 오프라인 DAgger 방식을 활용하여 다음과 같은 방식으로 학습하였다고 합니다. 해당 방법론의 핵심은 실패가 많거나 보상이 낮은 작업에 대해 더 자주 샘플링해서 작업 데이터를 뽑고, expert policy를 통해 실패 데이터를 점점 더 교정된 데이터로 보강하는 방식입니다.

[변수 설명]
- T_i: 훈련 대상의 i번째 작업(task).
- D_i: 현재까지 수집된 작업 T_i의 데이터셋(초기에는 동일한 크기).
- \pi_g: 학습 중인 guided agent(모방 정책).
- \pi_e: 각 작업별로 학습된 expert(예: RL로 얻은 고성능 정책).
- w_i: 각 작업 T_i에 대한 샘플링 가중치(초기 동일).
- f: reward → value로 매핑하는 함수(보상에서 가중치 갱신에 쓸 값으로 변환).
- w'_i: 해당 반복(또는 실험 배치)에서 누적된 가중치(임시).
[알고리즘 설명]
모든 작업에 대해 균등한 초기 가중치 w_i를 설정합니다.
f 함수(보상 → 값)를 정의합니다(예: 보상에 비선형 스케일 적용 → 어려운 작업에 더 높은 비중 부여 등).
각 작업 T_i에 대해 동일 크기의 초기 데이터 D_i를 수집합니다.
반복(수렴할 때까지):
- \pi_g를 현재 데이터셋 {D_i}로 학습합니다.
- 가중치 w_i에 따라 n개의 작업을 샘플링하여 성능을 테스트하여 reward를 뽑아냅니다.
- 각 작업 T_i에 대해 여러 번 테스트한 reward들을 f로 변환하여 w'_i를 누적합니다.
- 누적: w'_i \mathrel{+}= f(\mathrm{reward})
- 정규화: w'_i = w'_i / number_of_tests_for T_i
- 실패(혹은 낮은 보상)의 경우를 모두 기록하고, 해당 사례에 대해 expert \pi_e가 생성한 교정 데이터 D'_i를 얻습니다.
- 원래 데이터셋을 보강합니다: D_i \leftarrow D_i + D'_i
- 최종적으로 w_i \leftarrow w'_i로 가중치를 업데이트합니다.
이러한 방식으로 GEA는 점진적으로 더 안정적이고 일반화 가능한 기술을 습득합니다. 결론적으로는 RoBridge의 GEA 학습은 RL 기반 experts 학습 → IL 기반 데이터 전이 및 증강 → DAgger 기반 지속 최적화의 3단계 구조로 이루어져 있습니다.
Experiments
Experiment Settings
<Architecture and Training>
각 태스크마다 별도의 RL 정책을 사용하며, 여기서 Experts policy \pi_e이 쓰입니다. Experts policy 는 DRQ-v2(21', facebook) RL 알고리즘을 사용하여 학습하는데, 이 알고리즘은 입력으로 RGB 이미지, 로봇 상태, 작업별 원-핫(one-hot) 벡터 표현을 받아 low-level action을 출력하는 형태를 취합니다.
GEA \pi_g는 DRQ-v2와 동일한 네트워크 아키텍처를 사용하지만, 크리틱 네트워크(critic network)가 존재하지 않는다는 점에서 차이가 있습니다. 이 프레임워크는 입력으로 IOR을 사용하며, primitive actions은 원-핫 벡터로 표현되고, 마찬가지로 low-level action을 출력합니다.
<Hardware Setup>
real-world에서는 Kinova Gen3 로봇 팔을 사용합니다. 또한 Realsense D435i 2대를 활용하는데, 하나는 손목 1인칭 시점용, 다른 하나는 3인칭 시점용입니다.
Benchmark and Baseline
<Sim Benchmark>
Metaworld와 Robosuite(appendix에만 있음).
- Metaworld는 다양한 작업 집합을 제공하며, 총 50개의 작업을 대상으로 학습과 테스트에 활용했습니다.
- 이 중에서 학습용으로 35개 작업, 제로샷(zero-shot) 테스트용으로 5개의 독립된 작업을 신중히 선택했으며, 학습 세트와 테스트 세트 간에 상관성이 없도록 구성했습니다.
<Real Benchmark>
- Pick up: 테이블 위의 지정된 물체를 정확히 집어 들어 올리기.
- Sweep: 물체를 지정된 위치로 이동시키기.
- Press button: 버튼을 완전히 눌러 닫힘 상태를 달성하기.
- Open Drawer: 서랍을 최소 10cm 이상 열기.
이 중 Pick up과 Sweep 작업은 보지 못한 unseen objects를 사용하여 모델의 일반화 성능을 추가적으로 평가했습니다. 또한, 멀티 스테이지 태스크 설계로 블록을 집어서 해당 모양의 홈에 넣기를 하는데, 이는 모델이 long-horizon sequence를 처리할 수 있는 능력과 안정성을 평가하기 위함입니다.
- 4단계로 구성: “pick cylinder”, “place cylinder”, “pick cuboid”, “place cuboid”
- 실행 과정의 길이를 측정하여 성능을 평가했다고 합니다.
<Baseline>
[RL기반]
- DrQ-v2: 최신 강화학습 기법. RGB 입력, 로봇 고유 감각(proprioception), 원-핫 인코딩된 작업을 활용하여 멀티태스크 DrQ-v2를 구현했습니다.
[LLM 기반]
- SayCan: 대형 언어 모델(LLM)을 활용한 기술 계획(skill planning) 방법. DrQ-v2를 개별 과제별로 학습시켜 SayCan의 스킬 라이브러리로 사용했습니다.
- PSL: SayCan과 유사하게 기술을 행동 단위로 구성합니다.
- ManipGen: PSL을 확장하여 DAgger 및 도메인 랜덤화를 포함한 방식. PSL과 ManipGen의 스킬 라이브러리를 본 연구의 과제에 맞게 확장했습니다.
- RAM: 검색 기반(retrieval-based) 제로샷 로봇 조작 프레임워크. 도메인 외부(out-of-domain) 데이터에서 추출한 2D 어포던스를 3D 실행 가능한 동작으로 전이합니다.
- ReKep: keypoint 표현을 활용한 작업 계획 방법. 초기 성능이 부족했기 때문에, 추가적인 작업 설명 및 제약 조건을 포함하는 프롬프트로 성능을 보강했습니다.
- End-to-End VLA: RDT, \pi_0, 그리고 auto-regressive 버전인 \pi_0-fast를 포함.
실제 환경에서 RDT, \pi_0, RoBridge를 테스트할 때는 각 태스크당 5개의 demo를 수집하여 파인튜닝을 진행했습니다.
Results
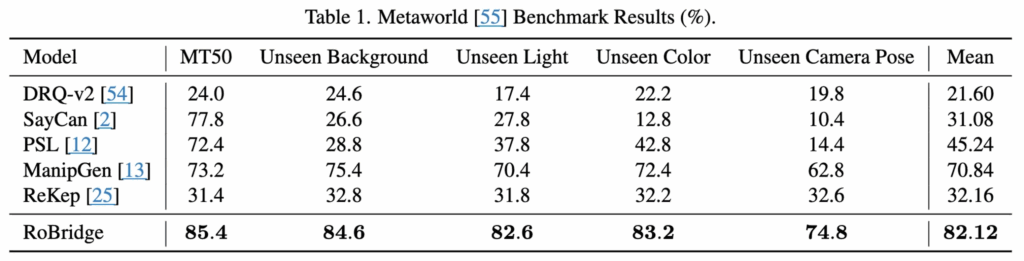
시뮬레이션 환경에서의 성능 결과입니다. 배경,조명,객체색상,카메라 위치 등도 변경하며 일반화 성능을 평가한 것인데 평균 성공률이 꽤나 높은 82.12%이었습니다. 특히 강건성을 보이기 위한 unseen 변화들에서도 많은 격차를 보인 것으로 보아 robustness를 보일 수 있었던 것 같습니다.
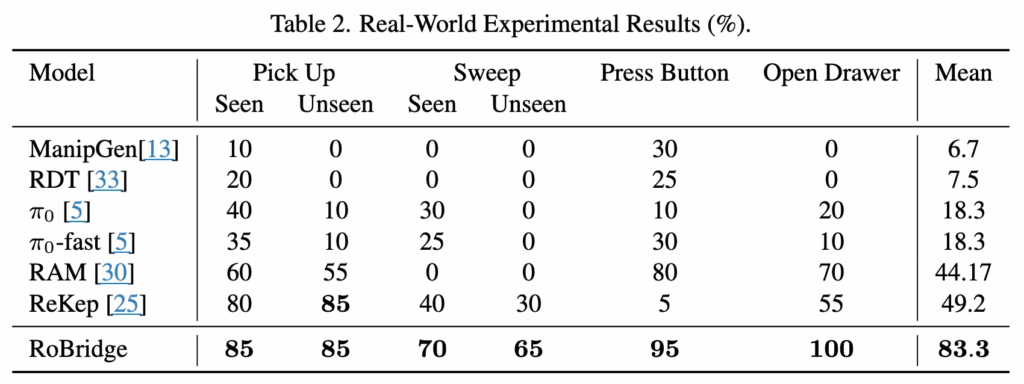
실제 환경에서는 4가지 태스크에서만 실험을 진행했습니다. 이번에도 타 방법론에 비해 정말 큰폭의 성능향상을 보여줬는데요.
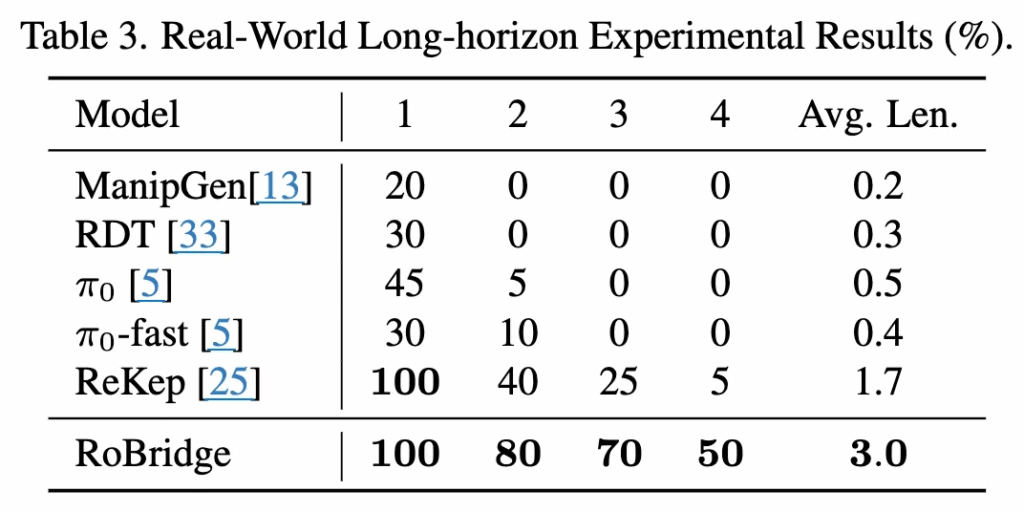
특히 Long horizon task에 대한 평가를 위해 도입한 평균 실행 길이에서 3.0의 길이로 가장 긴 태스크 수행이 가능했음을 보였습니다. 해당 성능은 planning 과 execution 사이의 IOR의 symbolic bridge역할이 잘되어서인지, 두 방식의 결합에서도 안정적인 성능향상을 보인 것 같네요.

end-to-end VLA 모델 중에서는 π0가 상대적으로 양호한 성공률을 기록했지만, 긴 시퀀스 작업에서는 불안정성(instability)을 보였습니다. ReKep 방식은 키포인트 기반으로 spatial한 걸 잘 할 수 있을 줄 알았는데, 저자들이 말하기로는 물리적 지식(예: 버튼을 누르려면 그리퍼를 닫아야 한다는 사실)을 잘 반영하지 못하는 문제가 있었다고 합니다.
Zero-shot Unseen Tasks Generalization
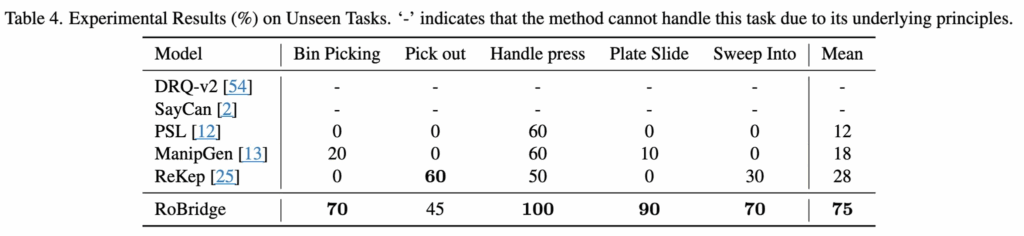
unseen task generalization 성능에 대해서는 위 표4에서 볼 수 있듯이, RoBridge가 평균 75% SR을 보였습니다. RL, IL 방식에 VLM 방식을 모두 섞어쓰면서 zero-shot 효과가 많이 생겨난 것 같습니다.
Ablation Study
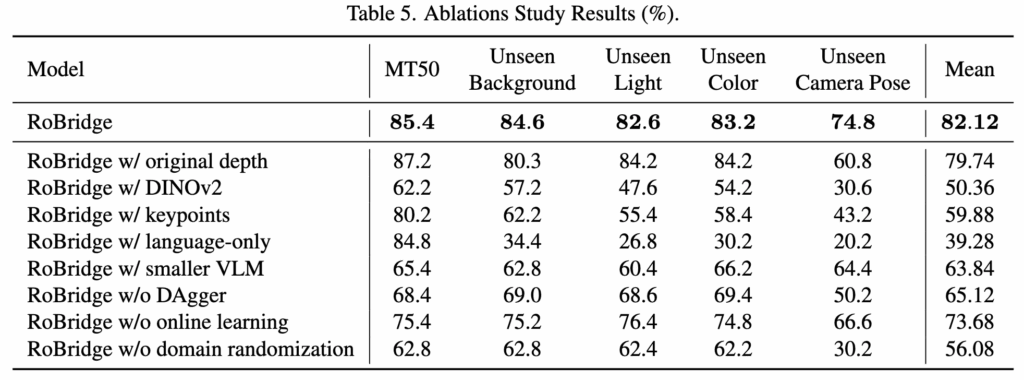
IOR 내 각각의 구성 요소와 GEA 학습 유무에 대한 ablation 이라고 보시면 될 것 같습니다. ManipGen은 1인칭 masked depth 대신 original depth를 사용했고, DINO-WM은 3인칭 마스크 대신 입력으로 DINOv2에서 얻은 특징을 사용했습니다. 이러한 두 가지 방법을 사용하여 모듈에 대한 ablation을 수행했다고 합니다. (정확히 어떻게 사용한건지는 자세한 언급이 안나와 있어서 크게 와닿진 않네요.)
표 5의 두 번째 및 세 번째 행에서 볼 수 있듯이, 원래 depth는 더 많은 세부 정보가 존재하기 때문에 모델이 학습하기가 더 쉬울 수 있으며, 결과적으로 MT50작업에서 더 높은 성공률을 보입니다. 그러나 카메라 포즈에 변화가 있을 때 성공률이 급격히 떨어집니다. DINOv2의 성능이 특히 낮았는데, 이는 사전학습된 특징이 로보틱스 도메인에 완전히 적합하지 않기 때문이라고 생각합니다. unseen 카메라 포즈에서 두 방법 모두 성능이 급격히 감소하는 것은 이러한 표현에 좋은 불변성이 부족하여 일반화하기 어렵다는 것을 나타냅니다. 이로써 저자들은 키포인트와 language-only를 사용하는 것과 비교했을 때 RoBridge 성능향상은 더 풍부한 supervision 때문만이 아니라 IOR 설계 속에 담긴 요소들로 인해 더 나은 불변성과 직관성을 제공할 수 있기 때문이었다고 말합니다. 또 GEA방식에서 ablation이 있었는데, 이 또한 GEA의 효과성을 보인것이라고 볼 수 있겠습니다.
안녕하세요 재찬님 리뷰 감사합니다.
IOR이라는 컨셉이 결국 강건성과 일반화를 확보하는 주역이었던 것 같습니다. RL, IL뿐만 아니라 DAgger를 할때도 그렇고 GEA의 학습까지 IOR 덕분에 이뤄진것 같습니다.
혹시 IOR 구조에 affordance나 trajectory같은 정보를 담는 것도 생각해볼 수 있을까요? Reasoning이나 zeroshot 성능을 높여주거나 Imitation Learning을 더 효과적으로 진행할 수 있으려나,, 싶기도 해서 여쭤봤습니다.
재찬님 좋은 리뷰 감사합니다.
IOR의 경우 3인칭 시점의 mask와 1인칭 시점의 depth mask라 하셨는데, 이 두 데이터의 시점이 다를경우 어떻게 이 둘을 통합한 인식이 가능한지 궁금합니다.
안녕하세요 재찬님 좋은 리뷰 감사해요 굉장히 흥미롭게 읽어 내려갔습니다. 본문에 ‘본질적으로 인지적·실행적 능력 서로를 조금씩 내려놓으면서 절충하는 식이라고 볼 수 있’다고 하면서 기존 방법론들이 두가지 문제를 완전히 해결하지 못하고 있다고 얘기를 해주신 것 같아요 .제가 와닿지가 않아서 그러는데요 기존 방법들이 어떻게 해결하려고 했고 이게 왜 한계가 있는지를 조금 더 설명해주실 수 있을까요? 감사합니다.
안녕하세요, 좋은 리뷰 감사합니다.
1인칭 뷰와 3인칭 뷰 이미지는 동일한 타임에 대응되는 이미지가 맞을까요 ? 그럼 data augmentation을 할 때 1인싱 뷰에서 사용하는 blurring은 3인칭 뷰에도 동일하게 적용이 될 필요는 없는걸까요 ? 어쨌든 동일한 scene과 타임의 데이터를 제공하는데 별도의 data augmentation이 적용되어도 되는 지가 궁금합니다.
그리고 Table5의 ablationstudy에서 background나 color 같은건 사실 depth를 마스킹 하고 안 하고의 depth map에서 큰 차이가 없을 거 같은데 성능 차이가 나는 이유가 무엇일지 재찬님은 어떻게 생각하시나요 ? 특히 color는 depth map으로 넘어갔을 때 다른 점을 만들어내지 않을 거 같은데 1% 정도 향상이 있어서 어떤 점이 성능 향상에 기여했는지 궁금합니다.
감사합니다.