안녕하세요, 이번주는 RoboPearls라는 비디오 기반의 시뮬레이션 환경을 제안한 논문을 리뷰해보려고 합니다. 이번 논문은 사실 승현님이 LLM과제에 활용할 수 있지 않을까 하시면서 알려주신 논문입니다. LLM과 3DGS를 활용한 연구들을 접하며 활용성이 무궁무진 하다고 생각하는 와중에 이런것도 가능하려나..?라는 식으로 잠깐 생각이 스쳐 지나갔던 연구가 구체화되어 실제로 등장한 느낌이라 좀 충격이었고 또 연구는 아이디어 외에도 구현능력이 필요하구나 라는걸 느끼기도 했습니다. 리뷰 진행해보도록 하겠습니다.
Introduction
최근 로봇 매니퓰레이션 분야는 범용적인 generalist manipulation policy 개발에 힘을 주고있고, 실제로 엄청난 진전을 보이고 있습니다. 저자는 주된 이유를 대규모의 demonstration data를 얻을 수 있기 때문이라고 주장했습니다. 다만, 많은 시뮬레이션 연구들이 주장하는 것과 마찬가지로 사람이 현실에서 이러한 데이터를 취득하는 일은 매우 비용이 크고 비효율 적이기 때문에, 데이터의 확장이 쉽지 않다는 것을 문제로 삼았습니다. 이를 해결하기 위해 많은 연구들이 Isaac Sim과 같은 물리 기반 시뮬레이션 환경에서 통제된 환경을 구성해 진행중이었는데, Sim-to-Real gap이라는 과제가 여전히 남아있다고 합니다. 저자들은 시뮬레이션에서 학습된 policy가 실제 환경에서 항상 기대에 미치지 못하는 성능을 내는 문제를 해결하기 위해 RoboPearls라는 새로운 프레임워크를 제안했습니다.
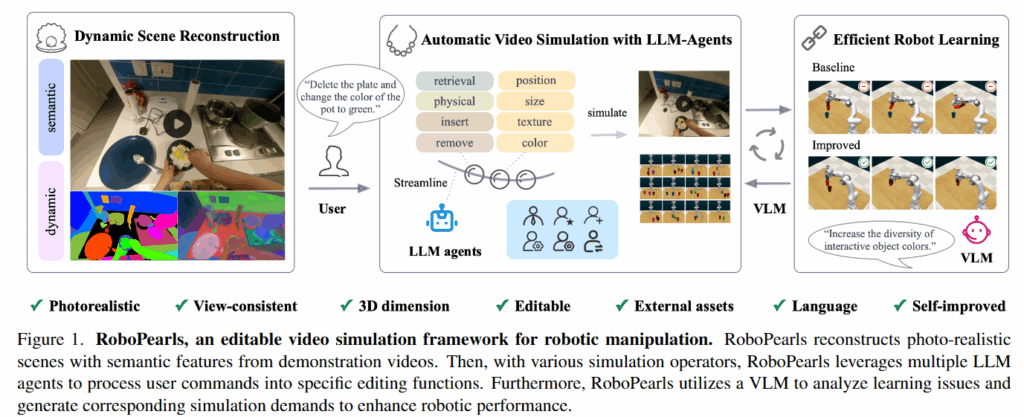
RoboPearls는 자동으로 편집이 가능한 시뮬레이션 환경이라는 특징을 가지고 있습니다. RoboPearls라는 이름을 지은 이유도 pearls라는 진주 목걸이에 비유한 것이라고 합니다. 3DGS와 시뮬레이션 연산자들을 진주에 비유하고, 변화하는 시뮬레이션 생성을 자동화하는 LLM을 진주를 엮는 실에 비유하고 마지막으로 생성된 환경을 검증하고 개선된 데이터를 제공하는 VLM을 잠금장치에 비유했습니다. 이렇게 흩어져있던 기존 연구들을 모아서 엮어 하나의 완성된 “진주 목걸이”와 같은 파이프라인을 구축했다고 합니다. 저자들은 이러한 프레임워크와 함께 프레임워크 내의 3D-NNFM Loss(이후 설명하겠습니다)와 같은 새로운 연산자와 LLM + VLM 기반의 사용자 친화적인 파이프라인, 다양한 벤치마크와 실제 로봇에서의 성능 향상을 주된 contribution으로 꼽았습니다. 더 살펴보도록 하겠습니다.
Method
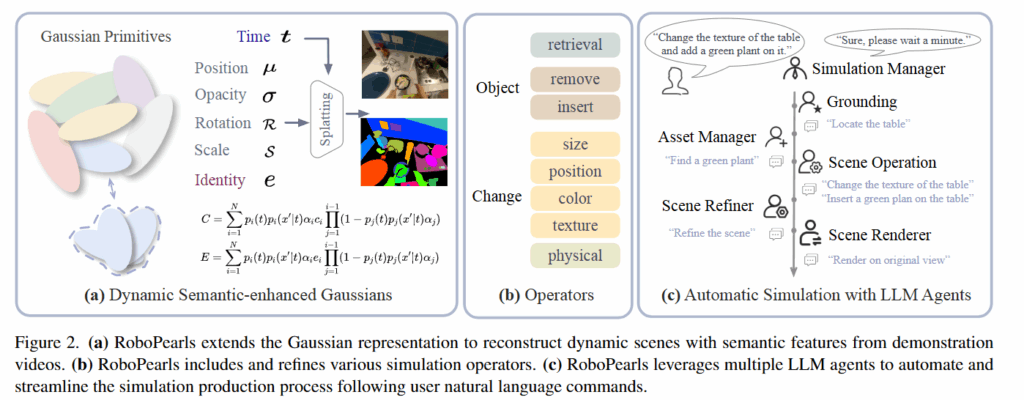
Dynamic Semantic-enhanced Gaussians
RoboPearls는 3D Gaussian Splatting 기반의 scene simulator입니다. 3DGS는 3D scene을 위치(μ), 색상(c), 불투명도(σ), 공분산(Σ)과 같은 파라미터를 가진 3D Gaussian들로 표현하고, 이를 카메라 투영 행렬과 alpha blending을 통해 다양한 시점에서 photorealistic한 재현을 가능하게 만들었습니다. Explicit한 특징 덕분에 빠른 렌더링과 표현이 가능했지만 4d gaussian splatting, gaussian splatting editing, semantic gaussian splatting(language feature를 포함하는 scene understanding이 가능한 3DGS)등 여러 donwstream task들이 생겨났습니다. 최근들어 이를 바탕으로 언어를 통한 grapsing을 시도한 GraspSplats, manipulator asset을 3DGS와 연결시킨 Robo-GS등이 등장했습니다. 다만 이러한 시도들은 저자의 표현에 따르면 데모가 toy수준이거나 단편적인 응용밖에 되지 않았다고 합니다. 이러한 한계를 넘기위해 로봇 시뮬레이션 시스템 전체를 확장하고, 실제 매니퓰레이션 성능을 높이는 체계적인 파이프라인을 구축하는것이 중요하고, 그 결과가 RoboPearls라고 합니다.
이를 위해 구성된 첫 번째 조각이 바로 Dynamic Semantic-enhanced Gaussians 입니다. 이름처럼 Dynamic Reconstruction과 Semantic Gaussian을 합친 모듈입니다. 정적인 장면만을 표현하던 3DGS의 위치(x,y,z)를 (x,y,z,t)로 확장해 시간 차원을 포함하는 gaussian으로 바꿨습니다. 이를 공간상에서도 표현하기 위해 공분산 파라미터도 4D ellipsoid로 확장했다고 합니다. 이를 통해 시간 t에 따라 변화하는 장면을 가지는 시퀀스를 그대로 Gaussian 공간에 매핑할 수 있고, 물체가 움직이는 궤적에 따른 자연스러운 움직임을 표현할 수 있게 만들어줬습니다. Semantic Gaussian의 경우 Identity Encoding을 추가했다고 합니다. 각ㄱ Gaussian에 identity라는 새로운 학습 가능한 파라미터를 추가해 SAM을 활용해 supervision 했다고 합니다. SAM으로 2D 마스크를 활용해 3D gaussian들의 identity encoding을 학습시켰다고 합니다. 이렇게 학습된 identity encoding은 identity feature map으로 렌더링 되고 linear layer 분류기를 통해 학습했다고 합니다. 정리하자면 기존에 존재하는 dynamic gaussian과 gaussian grouping연구를 합친 3DGS를 바탕으로 시뮬레이터 환경을 구성했습니다. 이러한 Gaussian을 학습하기 위해 Gaussian으로 렌더링한 이미지와 실제 영상의 차이를 최소화하는 MSE(L2d), semantic learning을 위해 Gaussian이 올바른 그룹에 속하게 하기위한 cross-entropy loss(Lsem), 3D상에서 가까운 위치에 있는 gaussian 들의 identity encoding이 유사하도록 하는 KL Divergence(L3d)를 모두 결합한 Loss를 아래와 같이 제안했다고 합니다.
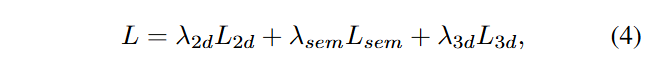
Editable Video Simulation

RoboPearls에서 가장 중요한 컨셉인 “editing”이 가능한 시뮬레이션을 위해서는 우선 원하는 대상을 정확하게 segmentation할 수 있어야 합니다. 이를 위해 저자들은 Incremental Object Retrieval 방식을 도입합니다. SAM은 가스레인지의 작은 버튼을 찾고싶어도 가스레인지 전체를 반환하는 것 처럼 세밀한 부분을 다루는데 한계가 있기때문에, Grounding DINO를 결합한다고 합니다. 원하는 쿼리에 대한 2D mask를 얻으면 이를 grounding DINO를 활용해 검증하고 만약 Retrieval failure일 경우 Grounding DINO의 bbox를 통해 identity encoding을 finetuning한다고 합니다.

다음은 Object Removal 파이프라인입니다. 3D 가우시안을 단순히 remove하는것은 구멍을 남기고 향후 observation에 큰 문제를 남기기 때문에 지워준 뒤에 “blurry hole”이 생긴 부분에 대해 각 이미지에서 LAMA inpainting을 진행해서 해당 객체가 없어진 부분에 대한 3D 가우시안을 다시 생성해 구멍난 부분을 finetune한다고 합니다.

Object Insertion같은 경우 원하는 객체에 대한 3D 가우시안을 얻는것은 굉장히 어렵기 때문에 ShapeSplat과 uCO3D와 같은 대규모 데이터셋으로 학습된 LGM 모델을 활용한다고 합니다. 사실 이러한 객체들을 만들어내는것은 LGM을 활용하면 되지만 취득한 Asset을 정확한 position과 Size로 넣는것이 굉장히 중요한데요, 심지어 color contrast가 생겨 알맞은 position과 size로 맞춰 배치해도 현실적이지 않게 보일 수 있다고 합니다. 이러한 문제를 해결하기 위해 libcom이라는 방법을 사용했다고 합니다. 조금 더 자세히 살펴보도록 하겠습니다.
먼저 크기와 위치 변경의 경우, Gaussian의 파라미터를 직접 스케일링하거나 삭제와 삽입을 조합하는 방식으로 구현됩니다. 예를 들어 객체의 크기를 키우고 싶다면 위치 벡터와 크기 관련 파라미터를 조정하며, 다른 곳으로 옮기고 싶다면 기존 위치에서 제거한 후 새로운 위치에 삽입하는 식입니다. 색상 변경은 조금 더 섬세한 처리가 필요합니다. 단순히 색만 바꾸면 광원 효과가 무시되어 왜곡이 발생할 수 있기 때문에, RoboPearls는 CIELAB 색 공간을 활용하여 원래의 밝기 정보를 보존하면서 자연스럽게 색을 수정한다고 합니다. 이를 통해 3D 장면의 기하학적 특성을 유지하면서도 색상만 안정적으로 변경할 수 있습니다.
스타일과 텍스처 수정도 진행하는데, 기존의 연구들이 diffusion 모델을 이용했지만, 멀티뷰 일관성을 유지하지 못해 아티팩트가 생기고, 학습 시간이 지나치게 길어진다는 단점이 있었다고 합니다. 저자들은 이러한 문제를 해결하기 위해 Nearest Neighbor Feature Matching(NNFM) Loss를 도입했습니다. reference 이미지와 렌더링된 이미지에서 VGG16 feature를 뽑아 코사인 유사도를 높히는 방향으로 진행했다고 합니다. 이 떄 기존의 NNFM loss를3D 객체 단위로 확장했다고 합니다.
물리적 시뮬레이션을 위해서는 Gaussian에 밀도, 영률, 푸아송 비와 같은 물리적 속성을 추가하여 Material Point Method(MPM) 기반의 시뮬레이터로 객체의 움직임과 변형 표현했습니다. 더 나아가 GPT-4V와 material 라이브러리를 결합해 객체의 재질 속성을 자동으로 추정하고 물리 파라미터를 자동으로 할당함으로써, 사람이 직접 모든 값을 지정하지 않아도 실제 물리적 거동과 유사한 시뮬레이션을 구현할 수 있었다고 합니다. 이 또한 PhysGaussian이라는 연구를 참고해서 진행했다고 합니다.
정리하자면 각각의 필요한 downstream 연구들을 잘 통합해서 Dynamic, Semantic한 Gaussian을 editable하게 만들었다고 보면 될 것 같습니다.

Automatic Simulation with LLM-Agents
RoboPearls를 진주 목걸이에 비유하면 앞서 “진주”와 같은 여러 시뮬레이션 관련 연산자들이나 gaussian 연구들을 잘 조합했다면, 이를 엮어주는 “실”과같은 존재가 LLM입니다. 복잡한 시뮬레이션 제작 과정이 단일 LLM Agent만으로는 불가능하기 때문에 다수의 서로 다른 prompt를 갖춘 에이전트들을 도입합니다. Simulation Manager Agent가 사용자의 명령을 더 단순한 languate instruction으로 분해한 뒤 전체적인 과정을 조율하는 팀장과 같은 역할을 맡게 됩니다. 이후 Grounding Agent, Scene Operation Agent, 3D Asset Management Agent, Scene Refiner Agent, Scene Renderer Agent가 협업해서 전체적인 scene을 만들어내게 됩니다.
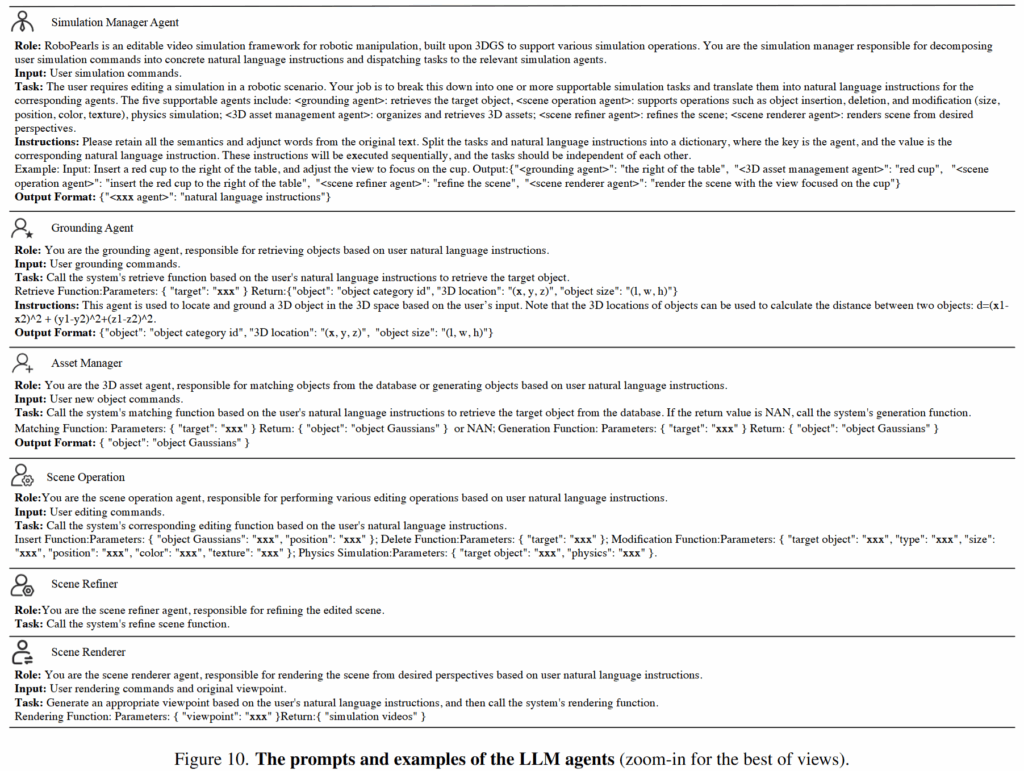
시뮬레이션 매니저가 적절한 에이전트에게 올바른 input을 분배해서 output으로 뱉으면서 시작합니다. 이후 첫 단계에서는 Grounding Agent가 관련 객체와 위치를 식별하고 Scene Operation Agent가 지정된 수정 작업을 수행합니다.이 때 만약 asset 검색에 실패해서 그에 맞는 새로운 asset이 필요하다면 3D Asset Management Agent가 LGM을 통해 새로운 asset을 생성해서 불러옵니다. 다음으로 Scene Refiner Agent가 전체 시뮬레이션의 품질을 향상시켜 일관성과 사실감을 확보합니다. 마지막으로 Scene Renderer Agent가 최종적으로 원하는 비디오 출력을 생성하여 결과를 반환합니다. 생각보다 LLM이 너무 많이 활용돼서 hallucination문제가 발생하거나 각종 오류가 많지 않을까 싶습니다..
이후 이렇게 완성된 영상에서 VLM이 성공, 실패 여부와 함께 실패하는 경우 실패하는 keyframe을 통해 원인을 분석하고 수정된 데이터를 다시 만들어 학습에 활용한다고 합니다. 이러한 과정을 진주와 실이 목걸이로써 기능을 할 수 있게 완성해주는 잠금장치 부분이라고 언급했습니다. 아래와 같이 어떤 문제가 생겼을지 미리 정리를 해두고 이들 중 하나를 객관식으로 추론하게 합니다.

Experiments
RLBench와 Colosseum(기존 benchmark에 각종 환경변화를 주어 평가하여 강인성을 평가하는 방식이라고 합니다)에서 robopearls의 augmentation을 활용해서 평가한 결과입니다. Robopearls는 데이터 생성 파이프라인이기 때문에 기존의 RLBench SOTA모델인 RVT와 RVT-2를 robopearls 데이터로 finetune 해서 진행했다고 합니다.
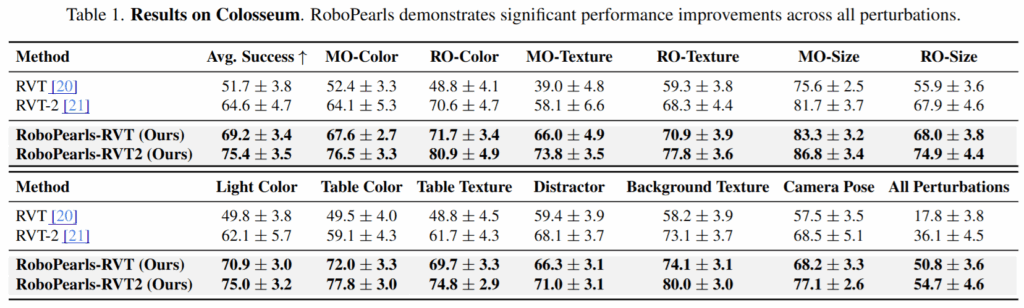
Colosseum을 통해 RLBench에 색상, 텍스쳐, 객체 크기 변화, 배경, 조명 변화, 바해물추가, 카메라 뷰 변경 등의 요소를 추가하고 평가했을 때 모든 방해요소들에 대해 큰 성능 향상이 있었음을 알 수 있었습니다.
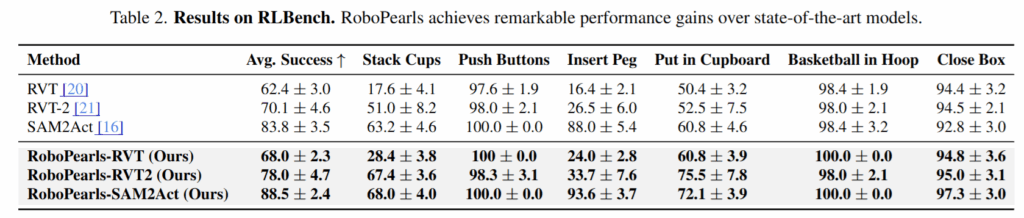
RLBench에서는 추가로 SAM2Act와의 비교도 진행했다고 합니다. SAM2Act는 colosseum용 코드가 존재하지 않아서 RLBench에서만 비교했다고 합니다. RLBench 기본 세팅에서도 성능 향상을 확인할 수 있었습니다. Real World의 경우에도 RDT라는 policy를 활용하여 평가를 진행했고, 성공률이 좋아진 모습을 볼 수 있습니다.
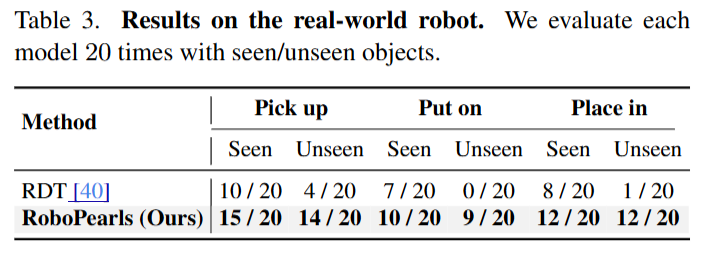
시뮬레이션 데이터셋 외에도 Ego4D, Open-X Embodiment데이터셋과 같은 real world 데이터셋에 대해서도 해당 과정을 진행할 수 있었고, sfm으로는 COLMAP을 활용하거나 실패하는경우 DUSt3R를 활용했다고 합니다.

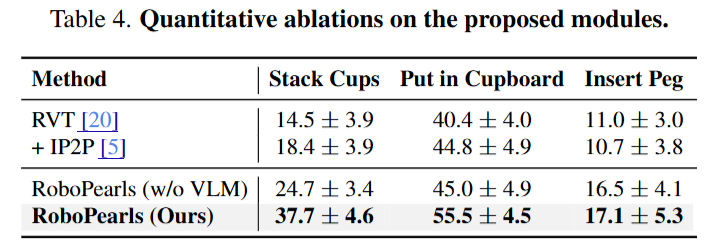
RVT를 베이스로 했을 때 2D 이미지 상에서만 변형으 시킨 IP2P와 비교해서 3DGS로 표현한 RoboPearls의 우수함을 보였습니다. 주목할만한 점은 VLM으로 실패를 감지해서 교정하는 부분이 꽤 많은 추가적인 성능 향상을 시킨다는 점인 것 같습니다.
Conclusion
정리하자면 결국 어떠한 비디오 영상이 있을 때 이를 가우시안을 활용해 reconstruction 해서 입맛대로 바뀐 환경에 대한 augment된 비디오를 반환해서 데이터를 증대시키는 framework입니다. 결국 다양한 데이터를 확보하면 그 task에 한정해서는 성능이 오른다는 것을 증명한 것 같고, 이를 이루는 방법이 좀 신선한게 아닌가 라는 생각이 들었습니다. 다만 아쉬운점은 코드가 없어서 reconstruction을 정확히 어떻게 하는지에 대한 내용이 부족했고 또 예시를 보면 결국 insert된 새로운 물체와의 상호작용은 없어서 실시간으로 동적인 gaussian 변화를 나타내는것은 불가능한것 같습니다. 배경과 texture에 대한 augmentation으로 성능 향상을 할 수 있는것은 맞지만 옆에 물체 하나를 두거나 없애는것으로도 성능 향상에 기여를 많이 하나..?에 대한 의문이 남았습니다. 다만 VLM을 활용하여 자체 개선하는 loop를 도입한것은 굉장히 의미가 있는 것 같습니다. 또한 LLM을 많이 이용하고 3DGS를 finetune해야하는 것과같은 이유로 하나의 변형된 scene을 얻을 때 약 70분의 시간이 걸리는것 또한 상당히 아쉬운 점 중에 하나라고 생각합니다.
안녕하세요 영규님 좋은리뷰 감사합니다.
마지막 conclusion을 보면 하나의 변경된 scene을 얻을때 시간이 오래걸리는 단점을 언급해주셨는데, 그러한 단점이 기존에 존재하는 data augmentation 프레임워크에 치명적인 단점인지 궁금합니다. 해당 저자의 방법론이 꽤나 성능을 올린 것 같은데, 데이터 수집 측면에서 메리트가 없다고 생각하시는지? 궁금하고 저자의 방법론이 sim to real gap을 줄였다고 볼 수 있을지도 궁금합니다. 감사합니다.
안녕하세요 인택님 댓글 감사합니다.
사실 데이터를 증식하는 방법중 영상을 변형시키는 것이 아니라 환경을 변화시킨다는 점에서 시간이 엄청 적게 들어야 하는것은 아니지만, 어떤 과정을 자동화 한다는것은 시간적인 이점도 분명히 존재해야 한다고 생각하는데, 시간이 오래 걸려서 아쉽다,, 라는 표현이기도 하고 과제를 진행할 때 이러한 3DGS의 update를 수행해야 하는데 그 관점에서는 시간이 너무 오래걸린다는 의미이기도 했습니다. 데이터 수집 측면에서는 그래도 메리트가 있다고 생각합니다.
Sim to real gap 같은 경우도 실험을 통해 real 환경에서의 작업 성공률로 gap을 줄인것을 증명했다고 생각합니다. 전체적으로 매우 의미있는 연구이지 않나 생각합니다.
영규님 좋은 리뷰 감사합니다.
Editable한 시뮬레이션을 만들기 위해 저자들의 방식으로 고도화한 3DGS를 적용하고 이에 대해 LLM으로 검증하는 하나의 파이프라인을 제안한 것으로 이해하였습니다.
해당 논문에 대해 몇가지 궁금한 것이 있습니다.
먼저 Identity Encoding를 통해 인스턴스를 식별하도록 학습한 것으로 이해하였슺니다. 이를 위해서는 temporal한 데이터기 필요할 것 같은데 저자들은 어떻게 하였는지 궁금합니다. 수동 라벨링을 하였을까요? 혹은 동일 물체가 없다는 가정하에 카테고리를 이용한것일까요?
또한 Object Removal 파이프라인에서 물체를 지우고 빈 공간을 inpainting하는 과정이 이루어지는데, 보든 물체를 순차적으로 지우는 것인지 한 물체만을 지우는 방식인지 궁금합니다.
마지막으로, Retrieval failure일 경우 Grounding DINO의 bbox를 통해 identity encoding을 finetuning한다고 하셨는데, 이유가 궁금합니다. 왜
Grounding DINO의 bbox를 기준으로 하는지, identity encoding을 finetuning하는것이 어떤 의미인지 설명 부탁드립니다.
안녕하세요 영규님, 좋은 리뷰 감사합니다.
Semantic Gaussian에서 Identity Encoding을 추가하여 각 gaussian에 identity라는 새로운 학습가능 파라미터를 추가해 이후, SAM을 활용해 supervision을 줬다고 하는데, 이 identity라는 게 정확히 무슨 의미인가요?
Object Insertion에서 libcom이라는 방법을 사용해서 새로 넣은 asset에 대한 gaussian 파라미터를 직접 스케일링하는 것으로 이해했는데요, 그럼 해당 상황마다 사람 개입이 계속 필요하다는 의미인가요? 아니면 libcom이라는 방법이 이걸 자동으로 해준다는 건가요?
물리적 시뮬레이션에 대해서는 material 라이브러리 를 결합해서 객체 재질이나 물리 파라미터를 자동으로 추정하고 할당한다고 했는데, 해당 라이브러리가 영규님이 사용하는 Isaac Sim과 호환이 가능한 건가요? 아니면 저 MPM 기반 시뮬레이터에서만 동작 가능한 건가요?
dynamic하게 gaussian을 editing 한다는 관점에서 자동화가 굉장히 중요해보였는데, 혹시 저자들의 contribution이 이 editing 파이프라인을 구성한 거 자체도 해당이 되나요?
안녕하세요 영규님 좋은 리뷰 감사합니다.
제가 로봇 관련해서 모르는 게 많아서 드릴 수 있는 질문일 수 도 있는데요,
마지막 conclusion에서 insert된 새로운 물체와의 상호작용은 없어서 실시간으로 동적인 gaussian 변화를 나타내는것은 불가능 한 것 같다라고 하셨는데 그러면 결국 RoboPearls가 주로 다루는 건 환경 변화(배경)등 수준이지, 물리적인 조작까지는 못 다룬다고 이해하면 될까요? 예를 들어 새로운 컵을 테이블 위에 두었을 때, 로봇 팔이 그 컵을 집는 행동까지 시뮬레이션이 가능한지, 아니면 단순히 시각적 데이터 증강에 가까운지가 헷갈렸습니다.
감사합니다!