다시 비디오 이해와 관련한 태스크 리뷰를 수행해보겠습니다. MLLM에서 비디오 표현을 위한 설계를 다룬 논문인 것 같아 읽게되었습니다.

- Conference: ICCV 2025
- Authors: Xiaoyi Bao, Chenwei Xie, Hao Tang, Tingyu Weng, Xiaofeng Wang, Yun Zheng, Xingang Wang
- Affiliation: Institute of Automation, University of Chinese Academy of Sciences, Alibaba Group , Peking University, Luoyang Institute for Robot and Intelligent Equipment
- Title: [Arxiv] DynImg: Key Frames with Visual Prompts are Good Representation for Multi-Modal Video Understanding
1. Introduction
멀티모달 대형 언어모델(MLLM)의 발전은 이미지 기반의 비전-언어 연구를 넘어 비디오 이해로 확장되고 있습니다. 하지만 정적인 이미지와 달리 비디오에는 시간 축이 존재하기 때문에, 단순히 공간적 특징만으로는 장면의 의미를 충분히 파악하기 어렵습니다. 즉, 물체가 움직이거나 장면이 급격히 변할 때 발생하는 시간적 단서(temporal cues)를 포착해야하는 것이 중요합니다.
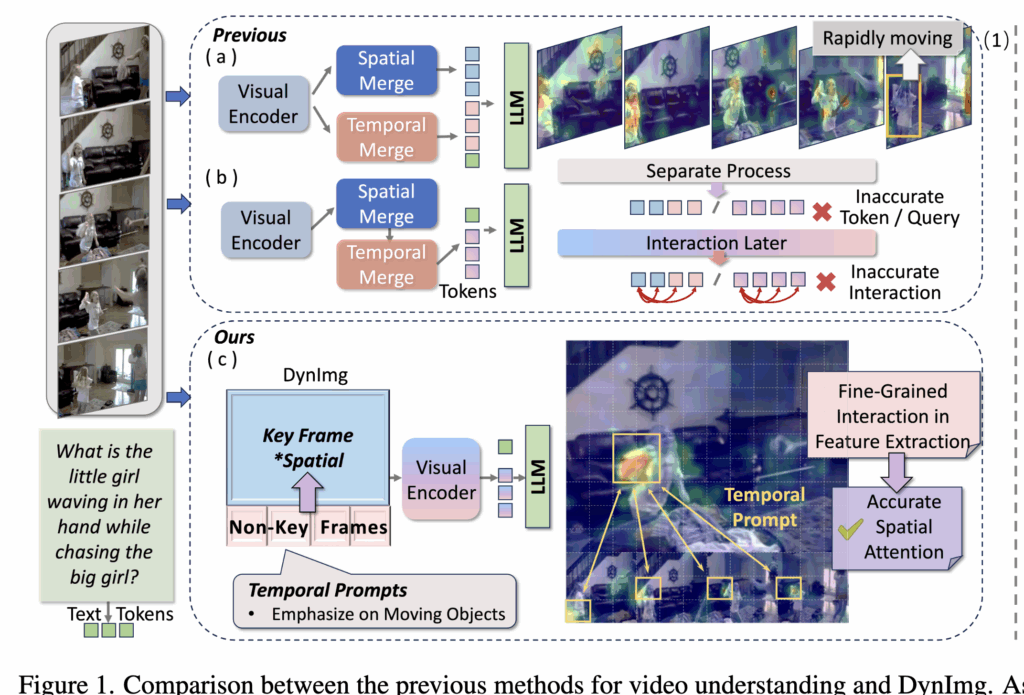
기존에는 공간과 시간 정보를 분리하여 처리하였다고 합니다. 예를 들어 상단 그림 1(a, b)처럼, 먼저 프레임 단위의 spatial feature를 추출한 뒤, 이를 압축하거나 모듈을 통해 temporal feature를 추가하는 식이죠. Video-ChatGPT나 Video-LLaMA 같은 방법들이 대표적인데, 이들은 이미지 인코더를 통해 추출한 feature를 기반으로 추가적인 temporal pooling 모듈을 거치거나, Q-former 같은 구조를 활용해 시퀀스 단위로 결합하는 식이었다고 하네요.
하지만 이러한 방식에는 결정적인 한계가 있는데, 바로 세밀한 시공간 정보가 추출 초기에 손실된다는 점입니다. 특히 물체가 빠르게 움직이거나 모션 블러가 발생하는 영역은 pooling 혹은 clustering 과정에서 희석이 되어 버리죠. 그림 1에서의 질문은 “손흔들고 있는 소녀의 손 안에 뭐가 있느냐?” 라는 질문이기에, 소녀가 마지막 프레임에서 갑자기 돌아보는 장면은 비디오 이해에 핵심적인 단서이지만, 기존 방법에서는 주목받지 못합니다. 결과적으로, 상위 레벨 토큰이나 쿼리에서 시공간 상호작용을 수행하더라도 이미 세밀한 정보가 사라진 상태이기 때문에 성능 저하가 발생하는 것이라고 하네요
해당 논문에서는 이러한 한계를 해결하고자 DynImg라는 새로운 비디오 표현 방식을 제안하였습니다. 핵심은 비주요 프레임(non-key frames)을 ‘시간적 프롬프트(temporal prompts)’로 활용하여, 빠르게 움직이는 영역을 인코더가 초기부터 주목하도록 만든 것이라고 합니다. 이렇게 하면 세밀한 시공간 단서가 보존된 상태에서 상호작용이 일어나 보다 정교한 비디오 이해가 가능해집니다. 또한, 이러한 입력 형식은 LLM 입장에서 낯설 수 있기 때문에, 저자들은 4D 회전 위치 임베딩(4D-RoPE)을 도입해 공간(H, W), 시간(T), 시퀀스(S)를 동시에 고려한 좌표계를 제공하고, 시공간 순서가 올바르게 반영되도록 했다고 하는데, 자세한 내용은 바로 알아보겠습니다.
2. Method
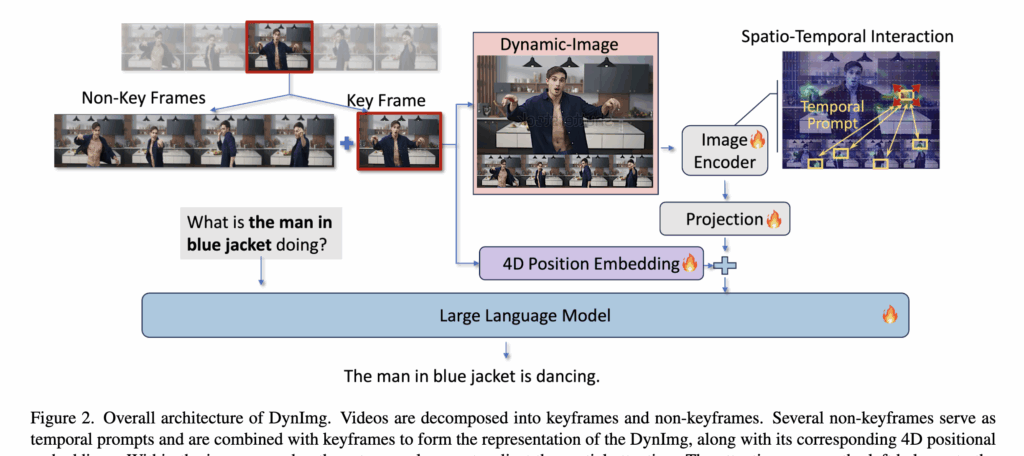
앞서 언급했듯, 저자들은 coarse-grained 수준에서 공간/시간 특징을 따로 추출하면 세밀한 정보가 손실된다는 점을 지적하면서, DynImg라는 새로운 방법론을 제안하였습니다. 핵심은 spatio-temporal interaction을 최대한 초반 단계에서 fine-grained하게 수행하는 것이고, 이를 위해 “temporal prompts”라는 개념을 도입했습니다.
2.1 Temporal Prompts
기존 방식에서는 spatial feature를 먼저 추출하고 난 뒤 temporal 정보를 얹어주는데, 이때 세밀한 local detail이 이미 사라지거나 블러 처리된 상태일 수 있습니다. 예를 들어 foreground 객체가 이동하는 순간, 혹은 배경이 바뀌는 순간과 같은 temporal하게 중요한 local region은 pooling 단계에서 희석될 수 있죠.
그래서 DynImg는 이러한 문제를 해결하기 위해, 추상적인 토큰이나 feature 수준에서 interaction을 수행하는 대신 pixel-level에 가까운 세밀한 단위에서 temporal 정보를 통합합니다. 마치 이미지 태스크에서 visual prompt(예: bounding box, annotation)가 특정 영역에 주의를 모으듯, DynImg에서는 비디오 전용 temporal prompt를 통해 움직임이 있는 구간의 spatial region을 강조하도록 한 것입니다.
즉, 움직이는 물체가 있는 부분을 temporal prompt가 가리켜 주고, 인코더는 그 영역의 fine-grained detail을 보존한 채 시공간 상호작용을 수행할 수 있게 되는 것이죠.
Composition of the Dynamic-Image
DynImg는 비디오를 크게 keyframe과 non-keyframe으로 나누어 구성됩니다.
Keyframe
고해상도로 유지하여 세밀한 spatial base를 제공
Non-keyframe
temporal prompt로 활용되어 keyframe의 의미를 보완
구체적으로는 MPEG-4 방식의 I-frame을 keyframe으로 선택하였다고 합니다. 예를 들어 4개의 I-frame을 고르게 샘플링하여 keyframe 집합 K를 구성하고, 각 keyframe K_i에 대해 앞뒤에서 두 장씩 총 4장의 non-keyframe을 선택해 N-frames라 부릅니다. 이렇게 K_i와 그 주변 non-keyframes가 한 그룹을 이루어, 풍부한 temporal context가 보장됩니다.
여기서 재밌는건, keyframe은 한 번만 등장하는 반면, non-keyframe은 인접 DynImg 그룹 간에 중복될 수 있다고 합니다. 즉, temporal prompt는 다소 겹치더라도 중요한 temporal 정보를 놓치지 않도록 redundancy를 허용하는 구조라고 볼 수 있을 것 같네요,
마지막으로, keyframe은 고해상도로 그대로 두지만, non-keyframe은 크기를 줄여 temporal 순서대로 keyframe 아래에 이어붙(concat)입니다. 이 과정을 통해 하나의 DynImg가 만들어지고, 이때 temporal prompt 부분은 motion 정보를 강조하는 역할을 하므로 해상도 축소가 큰 영향을 주지 않습니다.
Functioning of temporal prompts
앞서 keyframe과 non-keyframe을 결합해 DynImg를 구성하는 과정을 살펴봤다면, 이제는 temporal prompt가 실제로 어떻게 작동하는지를 보겠습니다.
DynImg는 keyframe(공간 정보)과 temporal prompt(non-keyframes, 시간 정보)를 동시에 포함한 형태로 비디오 인코더에 입력됩니다. 이후 시각 인코더의 self-attention 층에서는 아래와 같은 일이 나타난다고 합니다.
첫째, keyframe patch와 temporal prompt patch가 상호작용합니다. 예를 들어, keyframe의 특정 위치 패치가 temporal prompt 영역에서 비슷한 공간적 특징을 발견하면 두 패치가 서로 연결되어 주의를 주고받습니다. 이렇게 되면 keyframe이 단순히 정적인 한 장면을 담는 것이 아니라, temporal prompt로부터 시간에 따른 변화의 힌트까지 함께 흡수할 수 있게 됩니다.
둘째, 움직임 추적(motion trend capture)이 가능해집니다. 물체가 움직이거나 변형되는 경우, non-keyframe의 대응 패치들은 연속된 프레임마다 조금씩 다른 위치나 모양을 가지게 됩니다. self-attention은 이 변화를 포착해, keyframe 패치가 동적 지역(dynamic local regions)을 인식하도록 돕습니다.
이렇게 학습 과정이 반복되면 모델은 자연스럽게 움직임이 많은 영역에 더 많은 attention weight를 두게 됩니다. 결국 temporal prompt가 제공하는 변화 정보 덕분에 keyframe은 단순히 정적인 장면을 담는 것이 아니라, 세밀한 공간적 디테일 + 시간적 역동성을 동시에 반영할 수 있게 되는 것이죠.
2.2 4D Position Embedding
앞서 살펴본 temporal prompt는 keyframe과 결합해 세밀한 시공간 정보를 제공했지만, 여전히 하나의 문제가 남아있습니다. 바로 프롬프트와 keyframe 사이의 올바른 시공간 순서 보존 문제입니다. 비디오 입력은 시퀀스 형태로 모델에 주어지지만, 단순히 프레임을 나열하는 것만으로는 “공간(H, W) + 시간(T) + 텍스트 시퀀스(S)”라는 복합적인 구조를 제대로 반영하기 어렵습니다.
이를 해결하기 위해 저자들은 4차원 Rotary Position Embedding (4D-RoPE)을 제안하였습니다. 기존 LLM에서 쓰이는 RoPE는 토큰의 위치 좌표를 삼각함수(cos, sin) 기반 회전 행렬로 변환해 self-attention 안에서 상대적 순서를 반영하는 방식인데, 여기서는 이를 네 가지 축(H, W, T, S)으로 확장한 것이죠.
- H, W: 시각적 패치의 높이/너비 좌표 (이미지 내 공간적 위치를 보존)
- T: 시간 좌표 (base keyframe을 0으로 두고, 앞뒤 non-keyframe은 시간 흐름에 따라 ± 방향으로 부여)
- S: 시퀀스 좌표 (텍스트 토큰 순서와 동일하게 증가)
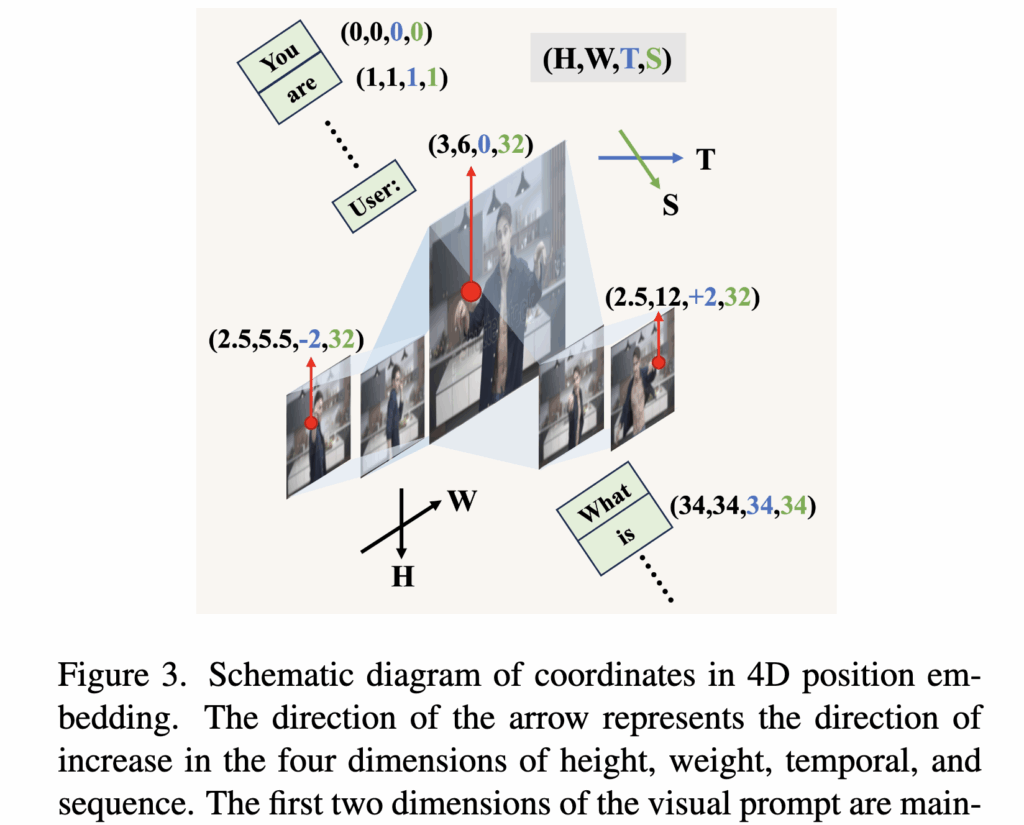
이렇게 4D 좌표계를 정의하면, 모델은 attention 연산 시 단순히 “토큰 간의 인접성”을 보는 게 아니라, 이 토큰이 어느 공간, 어느 시간, 어느 시퀀스 위치에 있는지까지 고려해 상호작용을 수행할 수 있습니다. 상단 그림 3을 보면 DynImg 입력이 (H, W, T, S) 좌표로 정렬되는 과정을 한눈에 확인할 수 있습니다.
수식적으로는 각 위치 좌표 (x_h, x_w, x_t, x_s)에 대해 가중합 형태의 회전 각도를 계산합니다.
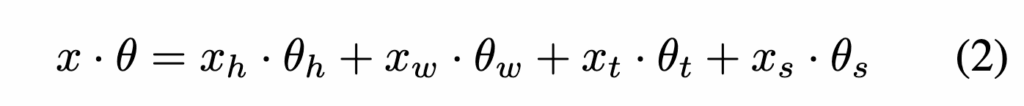
상단 수식 2와 같이 정의되며, 여기서 \theta_h, \theta_w, \theta_t는 학습 가능한 파라미터로, 학습이 진행되면서 점차 시공간적 의미를 반영하도록 조정된다고 합니다. 반면 텍스트 좌표에 대응하는 \theta_s는 일반적인 LLM에서 쓰이는 사인/코사인 기반 사전 정의 값으로 고정됩니다.
이 설계의 장점은, DynImg의 복잡한 시공간 구조가 LLM의 기존 positional encoding 체계와 충돌하지 않도록 하면서도, 훈련을 통해 점차 4차원적 임베딩을 학습하게 만든다는 점입니다. 즉, 비디오 내 시간적 순서가 꼬이지 않고, keyframe과 temporal prompt 사이의 대응 관계도 안정적으로 보존할 수 있게 됩니다.
3. Experiment
3.1 Implementation Details
Evaluation Setting
- Open-ended QA: MSVD, MSRVTT, TGIF, ActivityNet 사용. GPT(3.5-turbo)를 통해 정답 여부 및 confidence score 산출.
- Video-ChatGPT: CI, DO, CU, TU, CO 다섯 항목 기준으로 평가.
- Multi-choice QA: MVBench 사용, 20개 도메인에 걸친 객관식 문제 평가. 정확도 기준, GPT 미사용.
Model Setting
- 각 keyframe당 4개의 N-frame으로 DynImg 생성
- 비디오 인코더: Siglip-so400m-384
- 프로젝션: PLLaVA 구조 기반 (FF + Adaptive Avg Pooling)
- LLM: Qwen2.5-7B-Instruct
3.2 Comparison with State-of-the-Art
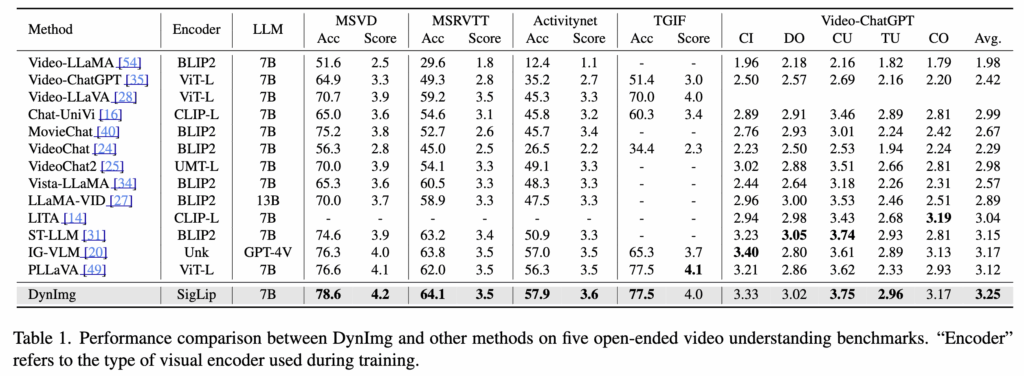
DynImg는 다양한 비디오 이해 벤치마크에서 기존 방법보다 높은 정확도를 보이며, 특히 MSVD, MSRVTT, TGIF, ActivityNet 등의 데이터셋에서 약 2.0%의 성능 향상을 보였습니다. (테이블 1)
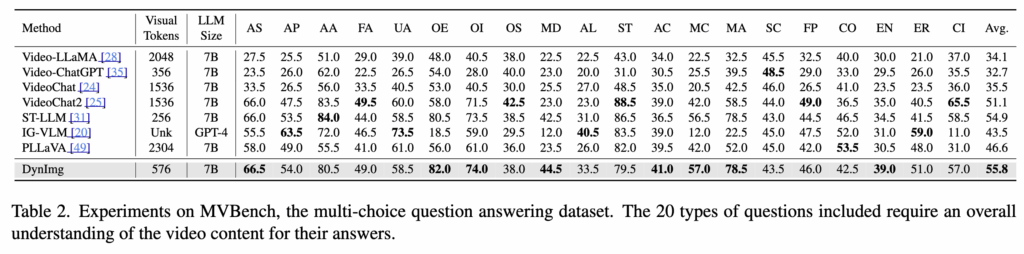
또한, 다양한 움직임 관련 문제를 포함한 MVBench 데이터셋에서도 뛰어난 성능을 보이는데, Moving Direction, Moving Count, Moving Attribute와 같은 motion-sensitive 태스크에서 각각 +21.0%, +15.0%, +26.5% 향상의 성능을 보였다고 하네요. (테이블 2)
이는 DynImg가 빠른 객체 움직임을 효과적으로 포착할 수 있다는 것을 의미한다고 합니다.
Token Efficiency
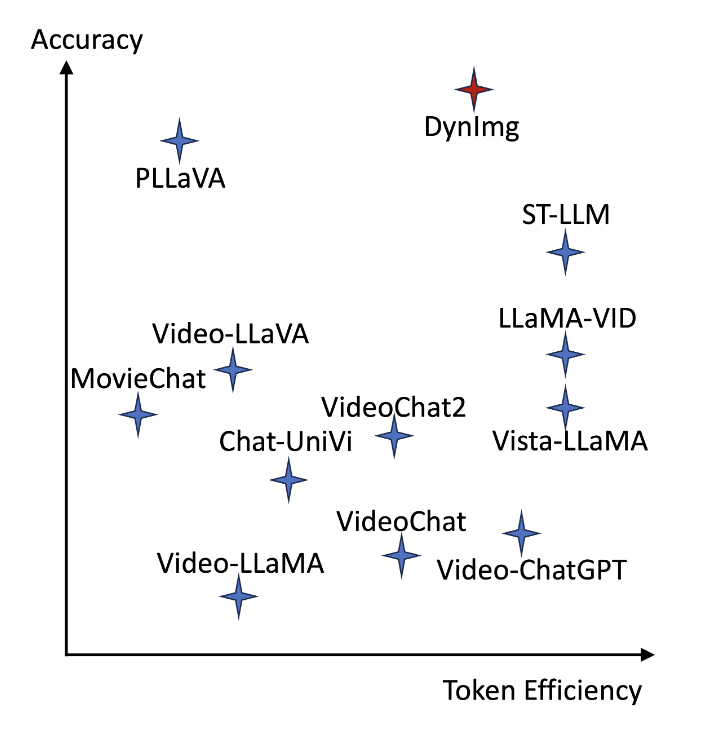
Token 효율성 측면에서도 DynImg는 경쟁력이 있습니다. 상단 그래프에 따르면, DynImg는 단 4개의 프레임(DynImgs)만으로도 기존의 PLLLaVA가 16프레임을 사용할 때와 유사한 성능을 달성했습니다. 이는 LLM에 전달되는 시각 토큰 수를 줄여 학습 및 추론 효율을 높이면서도 성능 저하 없이 표현력을 유지한다는 것을 보여준다고 하네요.
추가적으로, MPEG-4 디코딩을 활용한 프레임 구성 방식은 Decord와 같은 방법에 비해 약간의 연산 오버헤드는 발생하지만(0.06s → 0.32s), 이는 MLLM 학습 전체 시간 대비 무시할 수 있는 수준이며, 메모리도 이후 즉시 반환되므로 효율적이이었다고 합니다.
3.3 Ablation Study
이제 ablation study입니다.
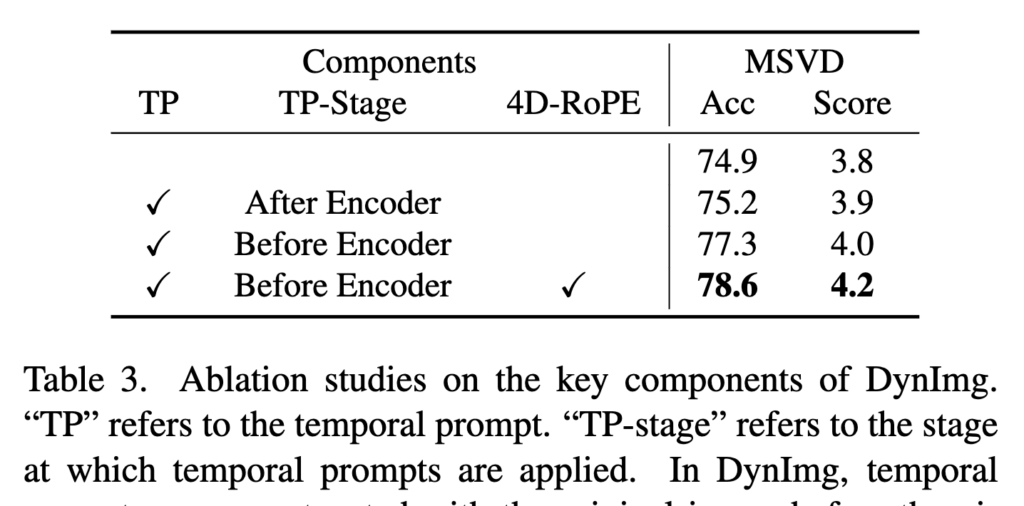
Different design choices of DynImg. (Table 3)
먼저, temporal prompt를 encoder 앞이 아닌 encoder 이후에 결합하는 방식을 비교했을 때, 후자의 성능이 약 2.4% 낮아졌습니다. 이는 encoder 이후에 삽입된 prompt는 단순한 정보 부가에 그치고, 실제로 시공간 상호작용을 유도하지 못했기 때문이라고 합니다. 반면, encoder 이전에 prompt를 삽입하면 더 풍부한 시공간적 정보가 모델에 효과적으로 전달된다고 하네요

Different numbers of N -frames in one DynImg (Table 4)
또한, 4D 위치 임베딩(RoPE)의 효과도 분석했는데, 일반적인 1D positional encoding만 사용하는 경우에 비해, 4D RoPE를 활용하면 시공간 토큰 간의 관계 혼란이 줄어들고, 더 정확한 positional 정보가 전달되어 성능이 향상되었습니다.

Different numbers of DynImg (Table 5)
N-frame 수의 변화에 대한 실험 결과도 확인할 수 있습니다. N-frame이 너무 적으면 시간적 변화가 부족해 temporal prompt로서 기능하지 못하고, 반대로 너무 많아지면 각 프레임의 해상도가 낮아져 정보 손실이 발생했습니다. 최적의 N-frame 수는 4개였고, 이를 초과하면 성능이 되려 감소하거나 정체되는 경향을 보였습니다.
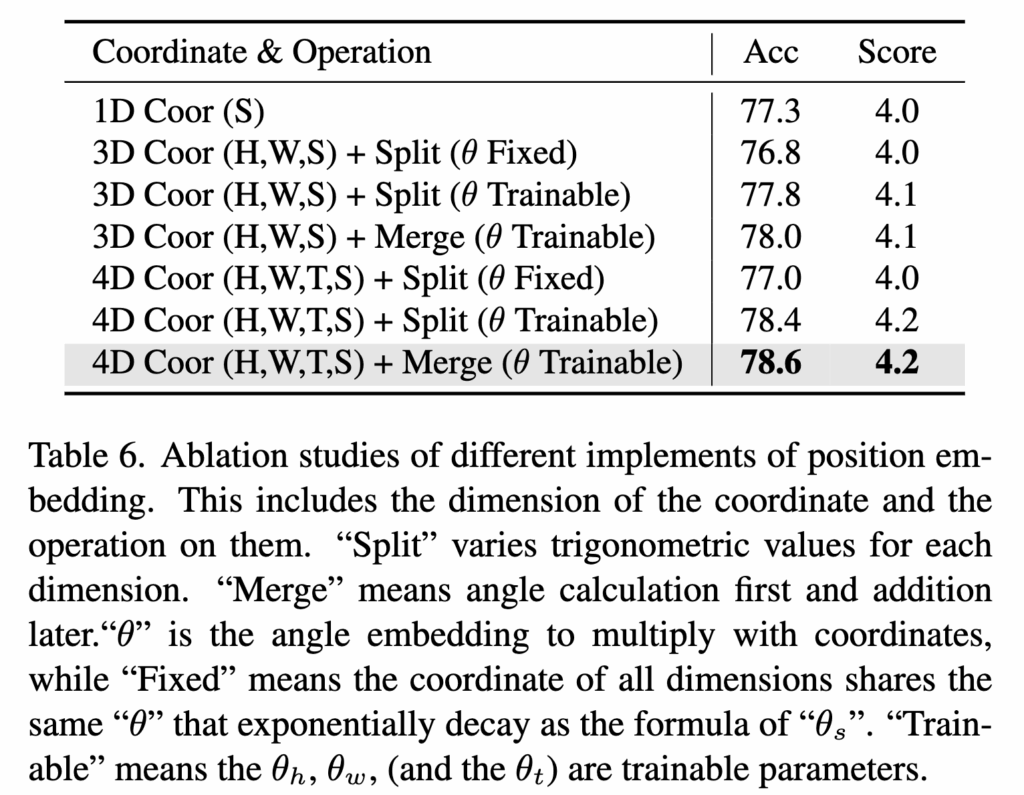
Different implementation of position embedding. (Table 6)
DynImg 수의 변화에 대한 실험으로, 하나의 비디오당 DynImg 수가 적정 수준(4개)까지는 성능이 상승하지만, 이를 초과하면 샘플링 간격이 너무 짧아져 frame 간 시간 변화량이 줄어들게 되어 오히려 temporal 정보의 표현력이 약화되었다고 합니다.
마지막으로, RoPE 임베딩 방식의 구현 차이에 따른 영향도 동일한 테이블에서 확인할 수 있습니다. 좌표 표현 방식을 (1D, HWS, HWTS)로 다양하게 실험한 결과, DynImg의 시공간 구조를 가장 충실히 반영하는 HWTS 방식이 가장 우수한 성능을 보였습니다. 또한, 각 차원별 회전 각도 계산 시, 삼각함수 값을 “분할(split)”하여 적용하거나 “각도 결합(merge)” 방식으로 적용하는 방법 모두 성능 향상을 이끌었지만, merge 방식이 약간 더 높은 이해 성능을 보였습니다.
4. Summary
해당 논문에선 Multi-modal Large Language Model(MLLM)이 긴 비디오 입력을 처리함에 있어 발생하는 연산량 증가와 표현력 저하 문제를 해결하고자, 정적인 이미지가 아닌 동적 이미지(DynImg)라는 새로운 비디오 표현 방식을 제안했습니다. DynImg는 비디오 전반의 temporal motion 정보를 단일 이미지에 효과적으로 요약하는 방식으로, 기존 프레임 기반 접근보다 훨씬 적은 수의 토큰으로 의미 있는 시공간 정보를 전달할 수 있도록 설계되었습니다.
모델 구조 측면에서는 DynImg의 temporal 정보를 효과적으로 활용하기 위해 temporal prompt, 4D RoPE positional encoding, θ-angle을 통한 token 위치 재정렬 등을 도입하였고, 이로써 LLM 기반 멀티모달 모델이 정적 장면뿐 아니라 동적인 비디오 이해에도 강점을 가질 수 있었다고 ㅎ바니다.
안녕하세요 주영님 좋은 리뷰 감사합니다.
Method 그림에서 Keyframe으로 선택된 이미지는 비디오에서 동작이 크게 변하는 장면처럼 보여집니다. 그리고 이후 설명에서 keyframe을 MPEG-4 방식으로 추출했다고 하셨는데, 여기서 궁금한 점은 MPEG-4 방식이 비디오의 동적인 구간을 분석하여 keyframe을 추출하는 방식인지, 아니면 단순히 일정 간격이나 다른 기준으로 프레임을 선택하는 것인지가 궁금합니다.
감사합니다.
안녕하세요 주영님 좋은 리뷰 감사합니다.
4D Position Embedding이 매우 참신한 아이디어 같습니다. context에 대한 좌표를 생성할때는 얼라인이 된 데이터셋을 기준으로 텍스트 토큰 순서를 활용하는 것 같습니다. 이때 텍스트 정보는 LLM 등으로 자동생성되거나 사람이 라벨링한 문맥적 정보를 담은 캡션 같은 것으로 이해하면 될까요? 또한 얼라인이 된 데이터셋을 활용한다는 제약이 있는것인지 궁금합니다. 실험에 사용한 데이터가 많은데 해당 데이터셋이 모두 얼라인이 맞추어진 멀티모달 데이터셋인지 궁금해서요 ㅎㅎ
감사합니다!
홍주영 연구원님. 좋은 리뷰 감사합니다. 리뷰 꼼꼼히 작성해 주신 덕분에 읽으면서 비디오 분야의 VLM 설계에 대해 더 잘 이해할 수 있게 되었습니다.
질문이 있는데, Functioning of temporal prompt 부분의 ‘keyframe patch와 temporal prompt patch 간 상호작용이 일어난다’ 는 부분에서 temporal prompt patch가 정확하게 무엇인가요? keyframe patch는 말 그대로 키프레임 이미지의 트랜스포머 패치인 것 같은데, temporal promopt patch가 정확히 어떤 형태로 사용되는지 모르겠습니다. 그냥 여러 장의 non-keyframe의 모든 패치랑 키프레임 패치를 전부 attention 연산 때리는 것인가요? 만약 그렇다면 연산량이 크게 늘어날 것 같은데, 이와 관련된 언급도 있는지 궁금합니다.