안녕하세요, 오늘 소개드릴 논문은 비디오 modality를 위한 RAG 프레임워크를 제안한 논문입니다. RAG의 기본적인 동작 도메인인 텍스트 도메인보다 데이터 용량이 큰 비디오 도메인을 다루는 만큼, 효율성을 높이기 위한 알고리즘을 제시했는데요, 리뷰를 통해 논문의 내용을 알아보겠습니다.
RAG 연구 동향
해당 논문은 효율성을 개선한 RAG 프레임워크라고 소개드렸는데요, RAG 분야의 논문이 저에게 생소해서 2025년 아카이브에 공개된 서베이 논문[1]을 통해 해당 방법론이 어느 위치에 있는지 간단하게 알아보았습니다. 아래는 서베이에서 분류한 비디오 분야의 RAG 방법론 분류입니다.
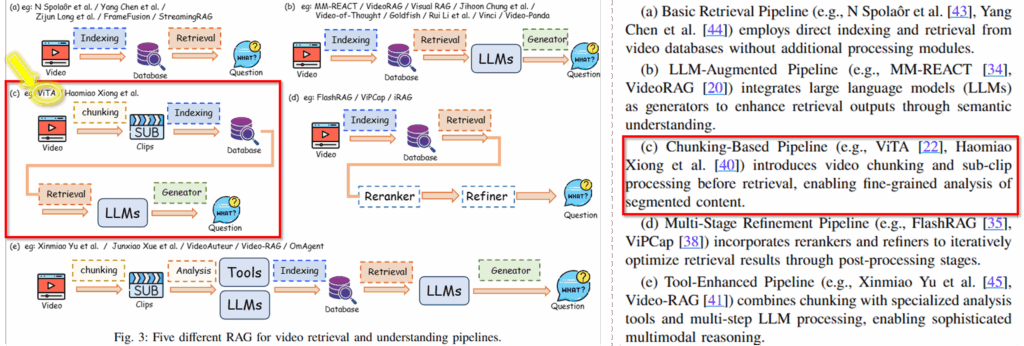
해당 논문인 ViTA는 (c)에 해당합니다. 비디오를 추가적인 방법론을 통해 clip으로 세분화하고, clip을 기반으로 데이터 베이스를 구축하며 LLMs을 통해 답변을생성하는 chunking-based 방법론에 속한다고 하는데요, 뒤에서 논문의 내용을 보시면 매우 단순해보이는데, 단순한 제안이 연구 동향 측면에서 어떠한 의미를 갖는지 생각해볼 수 있을것 같아 공유드립니다. 해당 분야에서는 다양한 파이프라인이 제시되고 있으며, 해당 방법론도 제시되고 있는 파이프라인 중 하나라고 이해하시면 좋을 것 같습니다.
연구 소개
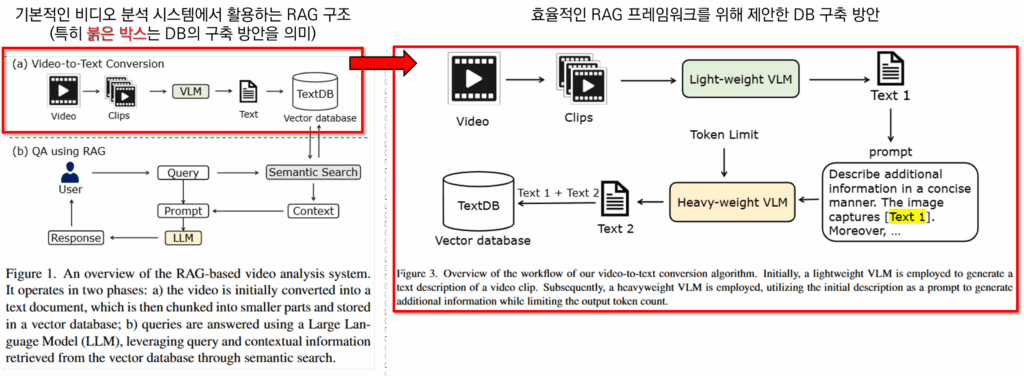
RAG 시스템은 본질적으로 텍스트 데이터를 다루기 위해 설계되었기에, 비디오 데이터를 활용하기 위해서 일반적으로 Figure1과 같은 방법을 이용한다고 합니다. 즉 비디오를 text로 바꾸어 RAG를 위한 Database를 구축하는 것입니다. 그 외의 프로세스는 일반적인 RAG와 동일합니다. 구축한 데이터베이스를 사용자의 질의에 적합한 데이터를 검색을 통해 유사한 것만 활용하여, LLM이 응답을 생성할 때 학습에 사용하지 않았던 외부(데이터베이스) 정보를 활용하도록 하는것입니다.
이러한 기존 방식의 문제는 DB 구축에 있어 필요한 시간인데요, 비디오에서 텍스트를 추출하는 과정이 오래걸리기 때문입니다. 예를 들어 많이 사용되는 가공 방법인 InternLM-XComposer2[3]의 경우 최대 입력 토큰이 64이고 NVIDIA GeForce RTX 3090 GPU 기준으로 추론시간이 3.8초가 필요합니다. 해당 방법론을 통해 24시간 촬영된 보안 도메인 영상을 DB로 가공할 경우 하루 이상이 걸릴정도로 많은 시간이 필요합니다. 이를 해결하기 위해 경량의 VLM을 활용하면 속도는 빨라지지만 정보의 품질이 낮아진다는 트레이드오프가 발생하는데요, 해당 논문은 이러한 트레이드오프 없이 정확도와 속도를 모두 지킬수있는 비디오 데이터의 DB 가공 방법을 제안합니다.
제안된 방법은 Figure3과 같습니다. 경량의 VLM과 대규모 VLM을 하이브리드로 활용하는 방법에 해당하는데요, 경량 VLM을 통해 초안을 생성하여 연산의 속도를 높이고, 대규모 VLM으로 디테일을 더해 DB의 품질을 지키는 방법을 제안합니다. 이러한 직관적인 접근법으로 StreetAware라는 실험 데이터셋에 대하여 비디오에서 텍스트로 전환하는 프로세스의 시간 단축을 최대 43% 까지의 이끌어냈습니다. 방법이 단순하기 때문에 제안된 내용은 거의 다 설명드린것 같은데요, 따라서 실제 예시를 통해 조금 더 디테일하게 방법론을 설명해보겠습니다.
방법론
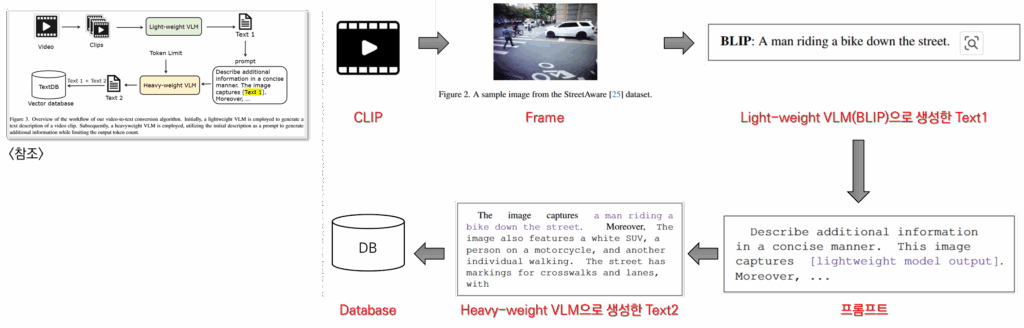
위는 논문의 overview를 실제 예시를 기반하여 구성한 그림입니다. 가장 먼저 비디오를 DB로 구축하기 위해 비디오 분석 툴인 PySceneDetect[2]를 통해 chunking하여 CLIP으로 가공합니다. 이후 하나의 클립에서 하나의 프레임을 샘플링하고 해당 프레임을 기준으로 텍스트를 가공합니다. 예를 들어 위의 그림에 우측과 같다고 하면 프레임을 기반으로 경량 VLM(Light-weight VLM)인 BLIP(247.4백만 파라미터)으로 초안과 같은 text description을 작성합니다. 이후 이를 활용해 미리 지정해둔 프롬프트에 해당 출력을 붙여넣어 대형 VLM(Heavy-weight VLM)의 입력으로 활용합니다. 대형 VLM으로는 70억개의 파라미터를 갖는 InternLM-Xcomposer2[3]와 LLAVA를 활용할 수 있다고 하는데요, 최종 출력 토큰 개수에 따른 description 결과는 아래와 같습니다.

실험
실험 세팅의 경우 StreetAware, Tokyo MODI라는 데이터셋을 기반으로 5~7개의 질문에 대한 답변을 베이스라인과 제안 방법을 비교하는 방식으로 진행했습니다. 해당 세팅이 해당 분야 연구의 통상적인 세팅은 아닌것 같아 아쉽습니다.. StreetAware[4]는 2023년 Sensors에서 출간된 논문이 제시한 데이터셋으로 46분 45초의 도로 영상이고, Tokyo MODI[5] 역시 2시간 23초로 구성된 도로 영상입니다. 실험 세팅이 통상적이지 않은 만큼 5개의 질문에 대한 베이스라인 방법과 제안 방법의 결과를 모두 공개하여 제안 방법의 우수성을 확인할 수 있었습니다.

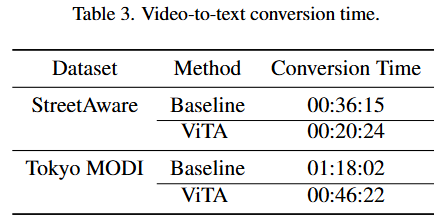
비교 실험을 위해 InternLM-Xcomposer2[3]를 직접적으로 활용하는 것을 베이스라인 방법으로 하였는데요, 위의 프롬프트에서 좌측을 통해 50개의 토큰을 생성하였고 제안 방법(ViTA)의 경우 BLIP 출력을 활용하여 우측의 프롬프트를 화룡해 25개의 토큰만 생성하도록 제한했습니다. 이미 BLIP의 출력이 있기 때문에 생성 토큰 제약에 따른 시간 비교의 통일성 문제는 고려하지 않은것 같으나, 최종 생성 토큰 개수의 실제 비교 결과가 없는것은 아쉽습니다. 아래의 실험 결과가 제안한 방법론의 메인이라고 할 수 있을 것 같습니다. 각 데이터셋에 대해 DB를 구축할때 발생한 시간을 리포팅 한 것입니다. AMD Ryzen 5950X 16-Core processor와 an NVIDIA GeForce RTX 3090 GPU 서버를 기준으로 StreeAware 데이터셋에 대해서는 43.7%, Tokyo MODI 데이터셋에 대해서는 40.58%의 가공 시간단축을 보였으며 정량적 실험 결과 역시 베이스라인대비 우수함을 뒤에서 보였습니다. 즉, 논문의 원래 목적인 정확도와 효율성을 모두 지키는 프레임워크의 개발을 성공한 것입니다.
정성적 결과는 논문에 자세하게 리포팅 되어 있습니다. 먼저 StreetAware 데이터셋에 대해서는 아래의 다섯가지 질문을 수행했습니다. 실험 결과 모든 답변에서 ViTA과 baseline과 동일하거나 더 나은 답변을 제시했음을 확인했습니다.


다음으로 Tokyo MODA 데이터에 대해서는 Q1.Is there a large Sony billboard? Q2.Is there any car seen making a left turn? Q3.Describe the buildings near the street. 에 대한 응답을 비교하였으며 그 결과는 아래와 같습니다. 아래의 색상표기 처럼 Q1은 baseline과 동일한 결과를 Q2는 ViTA가 답변 생성에 실패했고 Q3의 경우 Baseline이 예측에 실패했습니다. 아쉽게도 이에대한 분석 없이 제안된 ViTA가 baseline에 상응하는 성능을 보였다는 언급으로 실험을 마쳤습니다.

추가
이대로 끝내기에는 아쉬우니, 앞서 살펴본 RAG 서베이 논문[1]의 내용 일부를 가져오겠습니다. 아래의 테이블은 video 도메인을 활용한 RAG 연구들을 소개합니다. [20]번 논문은 앞서 제가 소개드렸던 논문(x-reivew)에 해당합니다. 아쉽게도 실험 데이터셋의 통일되지 않은것 같지만, 본 논문의 데이터셋은 매우 짧으니 [20]번을 기준으로 벤치마크를 구성하는것이 좋을 것 같습니다. 아마 워크숍 논문이여서 그런 것 같네요..😣

참조
[1] Zheng, Xu, et al. “Retrieval augmented generation and understanding in vision: A survey and new outlook.” arXiv preprint arXiv:2503.18016 (2025)
[2] Pyscenedetect: Video scene cut detection and analysis tool. https://www.scenedetect.com/, 2023. 3, 4
[3] Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Bin Wang, Linke Ouyang, Xilin Wei, Songyang Zhang, Haodong Duan, Maosong Cao, et al. Internlm-xcomposer2: Mastering free-form text-image composition and comprehension in vision-language large model. arXiv preprint arXiv:2401.16420, 2024. 2, 3, 4
[4] Yurii Piadyk, Joao Rulff, Ethan Brewer, Maryam Hosseini, Kaan Ozbay, Murugan Sankaradas, Srimat Chakradhar, and Claudio Silva. Streetaware: A high-resolution synchronized multimodal urban scene dataset. Sensors, 23(7), 2023. 2, 4
[5] Ferdinand Kossmann, Ziniu Wu, Eugenie Lai, Nesime Tatbul, Lei Cao, Tim Kraska, and Samuel Madden. Extract-transform-load for video streams. arXiv preprint arXiv:2310.04830, 2023. 4
실험과 제안된 접근 방법이 간단하여 아쉬움이 있는 논문이였습니다. 특히 데이터셋과 질문의 구성이 구축 의도가 밝혀지지 않아 잘된 결과를 리포팅한 것인지, 정말 분석 실험이라고 할 수 있는지 아쉬움이 있습니다. 다만 실험을 통한 우수성 검증 방식과 RAG 분야의 연구 동향을 파악할 수 있는 시간이였던것 같습니다. 읽어주셔서 감사합니다.
안녕하세요 유진님 좋은 리뷰 감사합니다.
소개해주신 ‘효율적인 RAG 프레임워크를 위해 제안한 DB 구축 방안’ 그림에서 경량 VLM 모델로 text1을 생성한 뒤 이를 대규모 VLM에 입력하여 추가적인 text2를 생성하는 과정이 나와있습니다.
여기서 궁금한 점은, Token Limit이 대규모 VLM이 출력할 때 생성할 수 있는 토큰의 최대 제한을 의미하는 것인지, 아니면 VLM에 입력으로 주어지는 이미지 토큰의 제한을 뜻하는 것인지 궁금합니다.
만약 대규모 VLM이 단순히 경량 VLM이 생성한 텍스트만 입력으로 받아 답변을 생성한다면, 이미지와 직접 관련 없는 내용까지 생성될 수 있을 것 같다는 생각이 드는데 이 부분에 대해 설명해주실 수 있을까요? 감사합니다.
리뷰 재밌게 잘 읽었습니다. RAG라고 해서 저희 과제를 생각하며 재밌게 읽었습니다.
Q1. ViTA는 PySceneDetect로 클립을 나누고 CLIP 기반으로 처리한 뒤 DB를 구축하는 방식인데, 이 방식이 도로 영상(StreetAware, Tokyo MODI) 이외의 비디오 도메인(예: 스포츠, 교육 영상)에도 일반적으로 적용 가능한지 궁금합니다. 도메인별로 chunk 분할 기준이나 효과가 달라질 가능성은 없을까요? 아무래도 저희 과제가 특수한 도메인에 최적화되어있다 보니… 이런게 궁금하네요
Q2. 경량 VLM의 출력을 대형 VLM 입력으로 활용하는 것이 효율적이라고 하셨는데, 만약 경량 VLM이 초기에 잘못된 설명을 하면 대형 VLM이 오히려 그 오류를 증폭할 가능성은 없는지 궁금하네요. (저희도 경량 VLM을 사용하는 것을 약간 염두해두고 있다보니…)
황유진 연구원님, 좋은 리뷰 감사합니다. Video RAG에서 vector DB를 구축할 때 video->text 추출에 필요한 시간을 단축하며 정보 품질을 지키기 위해 가벼운 VLM인 BLIP을 먼저 사용해 text description을 만들고, 이후 이를 활용해 대형 VLM임 InternLM-Xcomposer 및 LLaVA를 사용한 것으로 이해했습니다.
video RAG라는 task 자체에 질문이 있는데요, text 분야에서는 LLM등에 어떤 정보 요청이 들어왔을 때 정보 소스를 참고하기 위해 RAG가 사용되는 것으로 알고 있는데, video에서 구체적으로 RAG가 어떤 방식으로 활용될 수 있는지가 궁금합니다. user 의 자연어 쿼리에 대응되는 비디오를 가져오는게 목적이라면 비디오 검색과 동일한 task로 보이는데, 구체적으로 어떤 차이가 있는건가요? 비디오를 텍스트로 추출해서 벡터 db로 저장했다가 검색하는걸 비디오 RAG라고 하는 것인지(그럼 검색의 하위 분야로 볼 수 있는지), 그리고 구체적으로 어떤 application들에 활용될 수 있는지 궁금합니다.
감사합니다.
유진님 안녕하세요. 좋은 리뷰 감사합니다.
리뷰 첨부자료에 여러 색깔과 메모를 달아주시어 이해에 도움이 많이 되었습니다.
RAG 파이프라인 자체가 DB 구축에 소요되는 시간을 중요하게 생각하다보니,
방법론과 실험에서 계속 텍스트 생성의 token limit 조건을 언급하는 것으로 이해하였습니다.
InternLM은 decoder로부터 텍스트를 생성해내고, 이때 이 토큰 개수 제한을 프롬프트로 주는 것(“25 토큰 이내로 만들어줘”)이 아니라 생성 조건 dict에서 {“max_token_length”: 25} 이런식으로 절대 25토큰 이상 생성하지 못하도록 설정하는 방식으로 알고있습니다.
만약 위 방식이 맞다면 25토큰이 최대로 딱 생성되었을때 문장이 중간에 끊기는 경우가 많을 것 같은데, RAG 성능 보장을 위해 마침표를 기준으로 뒷 토큰을 버리거나 하는 후처리가 들어가는지 궁금합니다.
중간에 토큰 제한 개수별 초록, 빨강, 파랑으로 생성 결과 예시를 담아주셨는데, 실제로 저렇게 ‘.’ 기준으로 문장이 잘 나올것같진 않아 질문 드렸습니다.
안녕하세요 유진님 리뷰 감사합니다!
경량의 VLM으로 초안을 생성하고 지정된 프롬프트에 이 출력을 합쳐서 대규모 VLM을 사용한다고 하는데 그럼 경량의 VLM 따라 성능차이가 꽤나 날수있다고 생각이 되는데 혹시 관련된 실험이 있었을까요?!
또 이렇게 생성된 데이터베이스에 대한 품질은 어떻게 보장하는지(평가하는지) 궁금합니다!