제가 이번에 리뷰할 논문은 8월11일에 아카이브에 공개된 논문으로, Affordance에 대한 Chain-Of-Thought를 위해 reward를 도입하여 학습한 방식입니다. 새로운 접근법 같기도 하고, CoT를 위한 데이터도 공개했다는 점에서 리뷰하게 되었습니다. 아직 어디에 제출한지는 모르겠습니다.. 디테일한 정보가 조금 빠져있는 것 같아서 코드가 공개되면 한번 확인해보고 실험을 해봐야겠습니다.
Abstract
affordance grounding은 로봇이 액션을 수행하는 데 있어 물체와의 상호작용 영역을 찾는 것으로 로봇 조작에서 중요한 역할을 합니다. 기존의 연구는 일반화의 어려움과 affordance 관련 추론 능력의 부족으로 서로 다른 물체에서 공유되는 affordance 정보를 고려하지 못합니다. 해당 논문은 Affordance-R1 프레임워크를 제안하여 강화학습 방식의 GRPO(Group Relative Policy Optimization; 딥시크에서 개발한 강화학습 방식으로, 여러 정책(policy)의 결과를 그룹으로 묶어 비교하고, 그 결과를 바탕으로 더 나은 정책을 선택하는 방식을 의미합니다. 예시를 들어 설명한 글을 확인해보시면 이해에 도움이 될 것 같습니다.)를 통해 CoT 능력을 통합하고자 하였습니다. affordance 추론을 위한 다양한 reward를 통합한 affordance function을 설계하였으며, 고품질의 affordance-centric reasoning 데이터 셋인 ReasonAff를 제시합니다. 명시적인 추론 데이터 없이 GRPO를 사용한 강화학습 방식만으로도 affordance-R1은 강력한 zero-shot 일반화 성능을 보였으며, test-time reasoning 능력을 갖추었다고 합니다. 다양한 실험을 통해 기존 연구보다 성능 개선이 이루어졌음을 입증하였으며, 저자들에 따르면 최초로 GRPO 기반의 강화학습을 affordance reasoning에 적용한 연구임을 어필합니다.
Introduction
Affordance를 인식하는 것은 실제 물리적 세계에서 물체와 상호작용을 위해, 어디를 잡고 어떻게 행동해야하는 지 인지하기 위해 중요합니다. affordance grounding은 물체에서 액션이 이루어질 영역을 찾는 것을 목표로 하며, 이를 로봇 조작과 연결하고자 합니다. 최근 이러한 연구의 상당한 발전이 이루어져 HOI(human-object-interaction)이미지, 사람의 물체 조작 비디오, 3D 모델링 등으로부터 affordance 지식을 학습할 수 있게 되었습니다. 그러나 이러한 방식은 복잡하며, action에 대한 명시적 라벨을 학습하는 방식이라 사용자의 의도를 파악하지는 못합니다. 실제 물리적 상호작용이 이루어질 때, 사람은 해당 물체가 주어진 행동이 가능한지, 왜 가능한지, 가능한 영역은 어디인지 이해합니다. 예를들어, 부엌에서 “음식을 어떻게 데워?”라는 질문이 주어졌을 때, 음식을 데울 수 있는 “오븐”을 인식하고, 물건을 데우기 위해 오븐을 “열어”야 한다는 것을 알지만, 기존 연구는 이러한 affordance 추론 능력이 부족하여 실세계로의 적용에 어려움이 있습니다. 일부 연구는 MLLMs의 추론 능력을 이용하고자 하였으나, 대부분 마지막의 affordance 영역을 찾는 과정에만 사용하여 물체가 어떻게 해당 affordance를 수행할 수 있는지에 대해 설명하지 못한다고 합니다. 따라서, 저자들은 강화학습을 도입하여 단계별 reward를 통해 모델이 정답 뿐만 아니라 이에 대한 추론 과정도 학습할 수 있도록 하였다고합니다. 이러한 reward를 이용한 방식이 최근 연구되고있으나, object-level의 추론으로 한정되어있어 affordance로의 확장은 저자들이 최초로 제안한 것임을 저자들은 어필하고있습니다.
저자들은 Affordance-R1 프레임워크를 제안하여 affordance에 대한 추론 능력을 강화하고자 하였고, 이 과정에 GRPO 방식의 강화학습 방식을 도입하여 MLLMs를 fine-tuning하고, 명시적인 annotation 방식을 사용하지 않고도 추론 능력을 개선하는 self-evolution potential에 대해 연구합니다. 이를 위해 affordance 인식 능력을 위해 perception reward와 affordance recognition reward를 설계하였으며, “행동하기 전에 다시 생각하라”는 말에 영감을 받아 rethinkging reward를 추가하여 모델의 추론 과정에 대하여 reward를 설계하였으며, 마지막으로 box-num reward를 추가하여 affordacne에 해당하는 모든 영역을 찾았는지를 보장하고자 하였다고합니다.
또한, 기존 데이터는 너무 단순하고, 복잡한 실세계의 맥락 정보가 부족하며, 주로 visual segmentation을 위한 학습 데이터라 MLLM을 fine-tuning하기에 적합하지 않기 때문에 해당 논문에서는 ReasonAff 라는 새로운 데이터 셋을 제안합니다. 이는 affordance mask와 GPT-4o 기반의 추론 지시문을 포함하고있으며, MLLMs 학습에 적합하도록 구성되어있습니다. 저자들은 이 데이터셋과 강화학습 프레임워크를 결합한 Affordance-R1 모델을 통해 높은 일반화 성능을 달성하고, VQA 데이터 없이도 강력한 visual QA 능력을 보였다고합니다.
해당 논문의 contribution을 정리하면
- 주어진 affordance에 대한 추론 과정을 함께 답변할 수 있는 Affordance-R1을 제안하였으며, 해당 프레임워크는 강력한 zero-shot 기반의 일반화 성능과 test-time reasoning 능력을 보임
- 추론 과정을 포함하는 ReasonAff 데이터 셋 제안
- 광범위한 실험을 통해 학ㄷ습 파이프라인의 효과를 입증하고, 강력한 일반화 성능을 통해 기존 연구 대비 뚜렷한 성능 개선을 보임. 또한, 이러한 방식이 실제 환경에서 효과적으로 적용 가능함을 보임
Dataset
기존 데이터셋은 affordance에 대한 추론 과정을 포함하지 안으며, visual segmentation 모델을 학습하는 데 특화되어 MLLMs의 학습에 사용하기에는 어려움이 있습니다. 따라서 affordance에 대한 깊은 추론이 어려웠으며, affordance에 대한 일반화된 지식을 학습하지 못하여 일반화 성능에 한계가 있었습니다. 따라서, 저자들은 MLLMs의 affordance grounding에 대한 능력을 강화하고, 일반화 성능을 높이기 위해 ReasonAff라는 고품질의 MLLM의 지시문 학습에 사용 가능한 데이터 셋을 제안하였습니다.
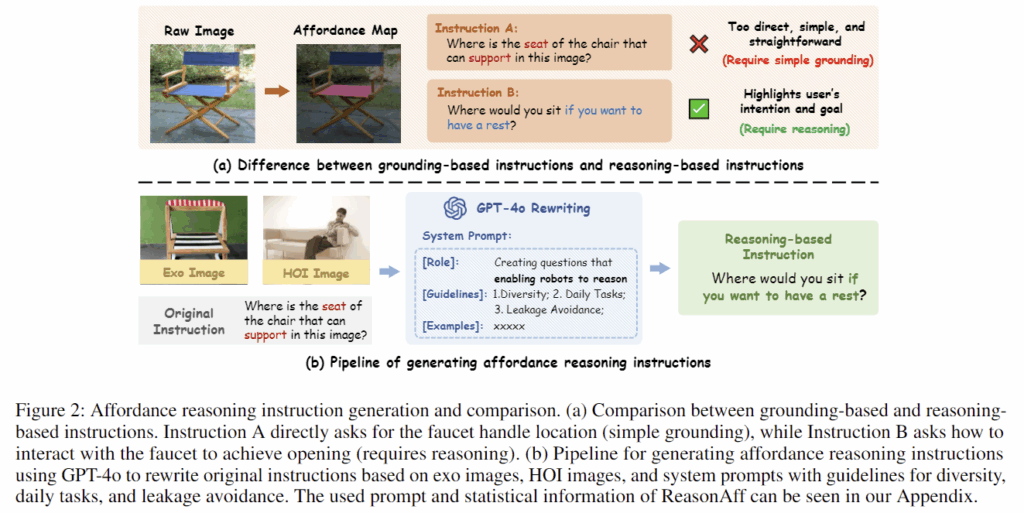
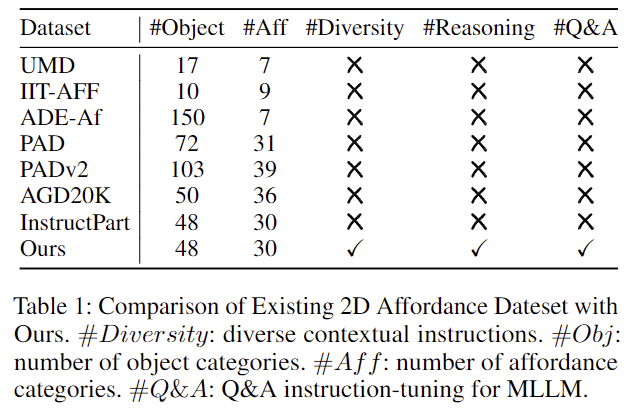
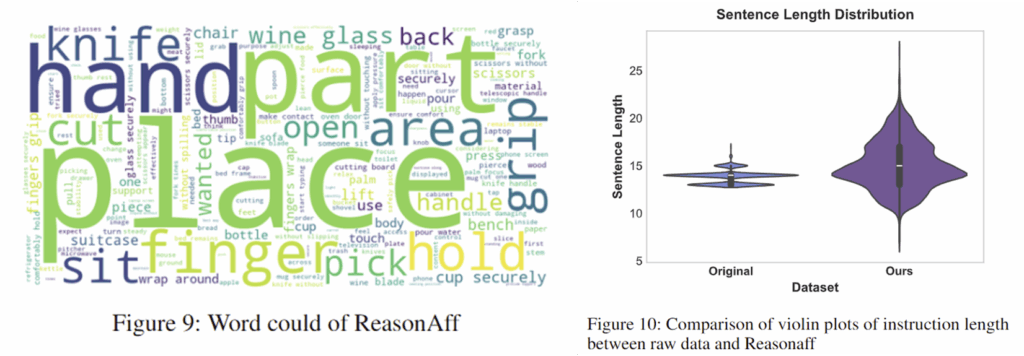
해당 데이터는 Instruct-Part라는 데이터를 기반으로 제안이 되었으며, Instruct-Part 데이터의 경우 지시문이 너무 단순하고, 문장의 구조도 한정되어있어 모델의 추론 능력을 개선하는 데 한계가 있다고 보았습니다. 이에 따라, GPT-4o에 HOI 이미지에와 원본 지시문을 추가로 함께 입력하여 hallucination 문제를 줄이고 지시문의 다양성을 높이고자 하였다고 합니다.(이에 대한 프롬프트도 논문의 appendix에 포함되어있습니다.) 또한, binary affordance mask를 이용하여 bbox의 좌표도 구하였다고 합니다. 아래의 Table 1은 기존의 affordance 관련 데이터와 ReasonAff의 차이를 나타내는 것이며, Figure 9&10은 저자들이 제안한 ReasonAff에 대하여 분석한 결과로, Figure 10을 보시면 한정된 길이의 지시문으로 이루어진 Instruct-Part(Original)에 비해 더 다양한 문장 길이의 분포를 가지고 있다는 것을 확인할 수 있습니다.
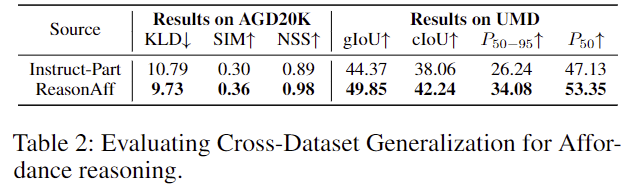
아래의 Table 2는 Instruct-Part와 ReasonAff로 학습한 뒤 AGD20K 데이터와 UMD데이터로 평가한 결과로, ReasonAff의 성능이 개선됨을 통해 저자들이 제안한 데이터가 affordance 관련 정보를 더 잘 제공함을 어필합니다. 그러나 어떤 모델로 실험을 한 것인지, 어떻게 데이터를 맞추었는 지 설명이 따로 없어 확인이 어렵지만 성능으로 볼 때 저자들이 제안하는 Affordance-R1에 적용한 결과인 것 같습니다.
Affordance-R1
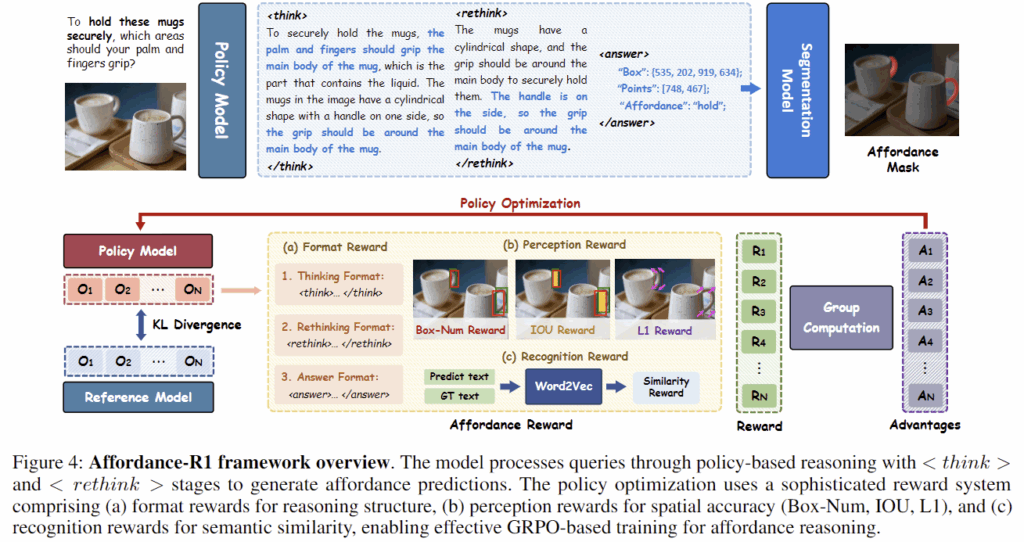
Figure 4는 Affordance-R1의 overview로, 해당 모델 \mathcal{F}는 타겟 이미지 I와 암시적이고 복잡한 지시문 T가 입력으로 주어졌을 때, affordance 영역 Aff를 찾는 것을 목표로 합니다. (Aff = \mathcal{F}(T,I))
저자들은 2-stage 방식을 설계하였으며, 첫번째 단계에서는 룰 기반의 강화학습 방식인 GRPO를 통해 모델의 추론 능력을 고도화합니다. 해당 과정에서, 저자들이 설계한 affordance reward를 활용하여 모델이 affordance 영역을 추론하고, 다시 검토한 결과를 답변할 수 있도록 합니다. 두번째 단계에서는 bounding box와 point를 추출하여 SOTA segmentation 모델(여기서는 SAM)에 적용하여 세부적인 segmentation mask를 생성합니다.
1. Architecture
타겟 이미지 I와 high-level의 text 지시문 T가 주어졌을 때, Affordance-R1은 해석 가능한 추론 과정과 T에 대응되는 답변을 생성합니다. 답변은 SAM에 입력 프롬프트로 넣을 bounding box B와 point P이며, 해당 결과를 이미지와 함께 입력하여 affordance mask A_{ff} 를 생성합니다.
2. Group Relative Policy Optimization(GRPO)
기존 강화학습 알고리즘은 policy 성능을 추정하기 위해 별도의 critic 모델이 필요하지만, GRPO는 후보 답변에 대하여 직접 비교하는 방식으로 별도의 critic 모델이 필요 없는 방식입니다. Question q가 주어졌을 때, GRPO는 policy \pi_\theta를 통해 N개의 후보 답변 \{o_1, o_2, ... , o_N\}을 생성한 뒤 각 답변 o_i를 reward function R(q,o_1)로 평가하여 질문에 대한 답변을 정량적으로 평가합니다. 상대적 품질을 계산하기 위해 GRPO는 reward를 아래의 식 (3)과같이 정규화한 advantage A_i를 구합니다.
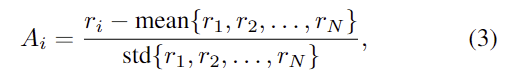
- A_i: 특정 답변 o_i가 샘플 집합 안에서 다른 응답에 비해 상대적으로 얼마나 좋은지를 의미하는 advantage
GRPO는 advantage가 큰 응답을 더 잘 생성하도록 policy \pi_\theta를 학습시키며 학습에는 아래의 수식을 이용합니다.
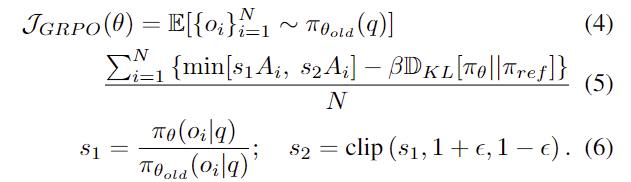
해당 수식에서 min[s_1A_i, s_2A_i]는 학습이 불안정하게 발사하지 않도록 advantage의 크기를 제한하며, \beta\mathbb{D}_{KL}[\pi_\theta||\pi_{ref}]는 학습된 policy가 기준 poilcy \pi_{ref}와 너무 달라지지 않도록 규제하는 역할을 합니다. 또한, s_1은 새 policy와 이전 policy의 비율을 의미하며, s_2는 값이 너무 크게 변하지 않도록 \epsilon 범위로 한정합니다.
3. Reward
저자들은 Figure 4에서 확인할 수 있듯 format, perception, recognition에 대한 reward들로 이루어진 affordance reward를 설계하였습니다.
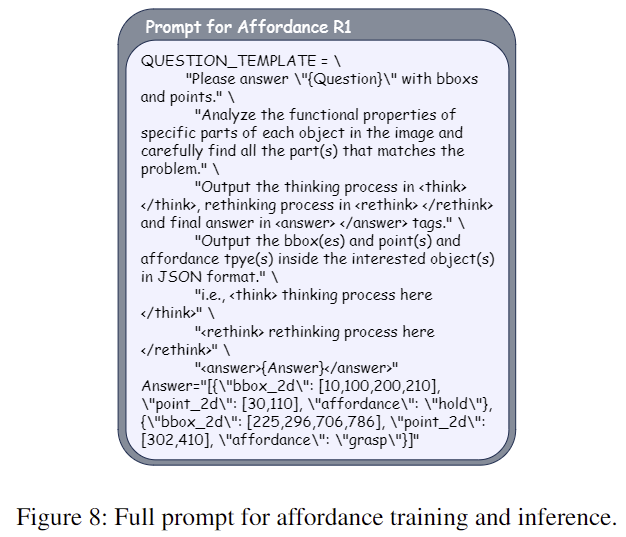
<Format Reward>
- 해당 reward는 모델의 답변이 정해진 형식을 따르도록 보장하기 위해 설계된 것으로 다음 3가지로 나뉩니다.
- Thinking Reward: 모델이 깊게 생각하도록 하기 위해
<think> ... </think>형식을 추가 - Rethinking Reward: 추론 과정에 대하여 모델 스스로 다시 평가하도록 하기위해
<rethink> ... </rethink>형식을 추가 - Answer Reward: 최종 답변에 대한 형식 제약을 위해
<answer> ... </answer>형식을 추가
- Thinking Reward: 모델이 깊게 생각하도록 하기 위해
<Perception Reward>
- 모델이 affordance 영역을 잘 grounding 할 수 있도록 설계된 것으로 다음 3가지로 나뉩니다.
- IoU Reward: GT와 예측 bbox 사이의 IoU를 측정하여 0.5 이상일 경우 reward 1, 아니면 0이 되도록 함
- L1 Reward: GT와 예측 bbox 사이의 L1 distance를 계산하여 10 이하면 reward 1, 아니면 0이 되도록 함
- Box-num Reward: 모델이 가능한 affordance 영역을 모두 착도록 하기 위해 bbox 개수에 대한 reward 를 추가함.(정확히 어떻게 단순히 reward를 주는지 작성되어있지는 않지만, 그림에서 GT와 예측된 박스 수가 같이 그려져있는 것을 볼 때, GT와 예측 박스 수가 같으면 1 다를 경우 0이 되도록 설계하였을 것 같습니다. )
<Affordance Recognition Reward>
저자들은 word2vec 모델을 이용하여 affordance text 유사도를 계산하여 유사도가 0.8 이상일 경우 reward를 1로 , 아니면 0이 되도록 하였다고 합니다. 그림을 참고하였을 때, GT와 예측 text를 word2vec으로 임베딩한 뒤 두 임베딩 벡터 사이의 유사도를 구하는 것으로 보입니다.
Experiments
Experimental Setting
저자들이 제안한 ReasonAff를 이용하여 학습을 수행하였으며, 일반화 성능 평가를 위해 Out-of-Domain(OOD) 시나리오에서 평가를 수행합니다. 따라서 AGD20K 데이터와 UMD Part Affordance 데이터를 평가 데이터로 사용합니다.(두 데이터는 2D affordance grounding에서 흔히 사용되는 데이터로, 자세한 정보는 저의 이전 리뷰를 참고해주세요.)
또한 Affordance-R1은 open-vocabulary segmentation 방법론들(VLPart, OVSeg, SAN)과 open-source MLLMs (LISA, SAM4MLLM, AffordanceLLM, Qwen2.5-VL 등)와 비교를 하였습니다. 평가지표로는 Instruct-Part를 따라 gIoU, cIoU, Precision@50, Precision@50:95를 이용하였으며, 4개의 A100 GPU로 7시간정도 학습을 진행하였다고합니다.
Results on ReasonAff
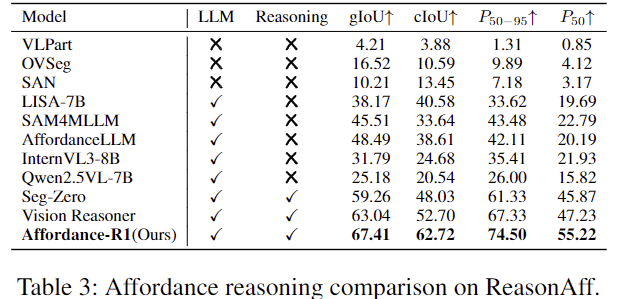
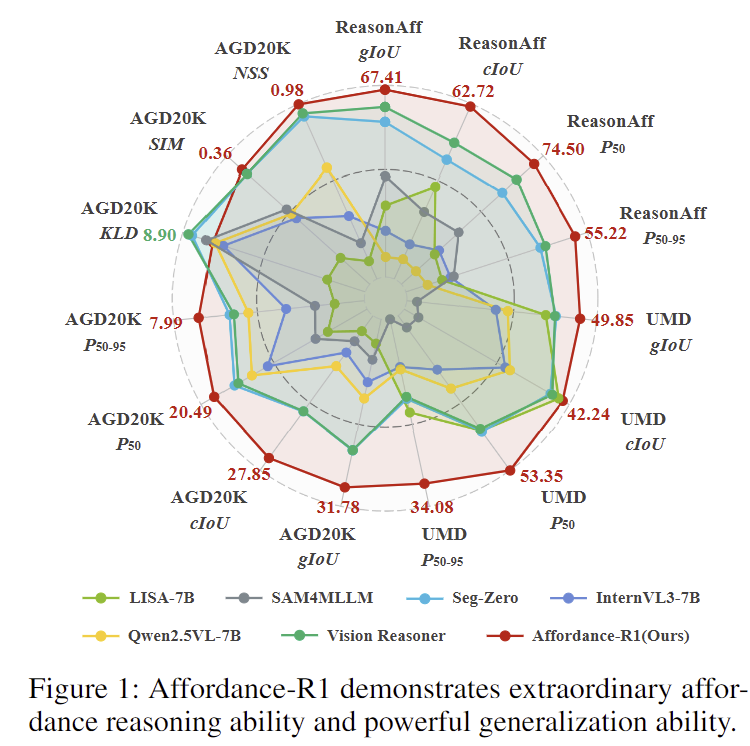
Affordance-R1은 기존의 모든 연구와 비교하였을 때 SOTA를 달성한 것을 확인하였으며, precision에 대한 지표에서 두드러진 성능 개선을 보였습니다. 아래의 Figure 5는 이에 대한 정성적 결과로, AffordanceLLM과 같이 affordance를 고려하여 설계된 모델에 대한 정성적 결과가 빠진것은 아쉽지만,, 정성적으로도 잘 된다는 것을 보였습니다.

추가로 Figure 13은 Affordance-R1에 대한 정성적 결과를 appendix에서 일부 가져온 것으로, 보시면 <think>...</think> 뿐만 아니라 <rethink>...</rethink>로 모델의 결과에 대하여 다시 한번 검증하는 과정도 확인할 수 있습니다. 저자들은 이러한 결과를 통해 Affordance-R1이 추론 및 visual grounding 능력이 고도화되었다고 어필합니다.

Results on Out-of-Domain
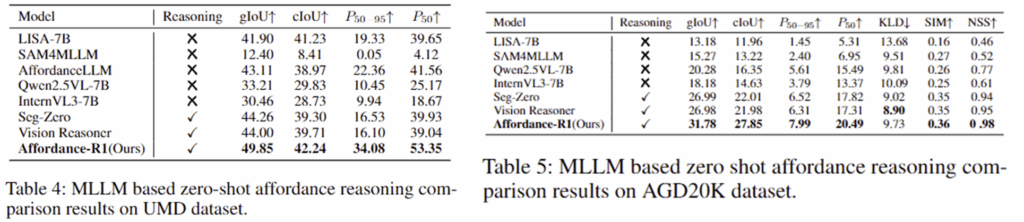
Affordance-R1은 AGD20K와 UMD 같은 OOD 시나리오에서 zero-shot 평가를 통해 일반화 성능을 입증하였습니다. 두 데이터에서 가장 좋거나 그에 준하는 성능을 보였으며, 이를 통해 저자들은 GRPO 기반의 강화학습과 저자들이 설계한 reward 시스템을 통해 Affordance-R1이 단순한 패턴을 학습한 것이 아니라, 추론을 통하여 functional한 영역을 식별하는 원리르 학습하였다고 주장합니다.
Visualization on Web Image

Affordance-R1의 일반화 성능에 대한 검증을 위해 저자들은 EPICKITCENS 데이터와 인터넷에서 부엌과 가정 장면에 대한 데이터를 추가로 수집하였으며, Figure 6과같은 scene-level의 이미지와 아래의 망치 그림과 같은 경우에도 잘 작동한다는 것을 통해 일반화 성능을 어필하였습니다.

Ablation Study
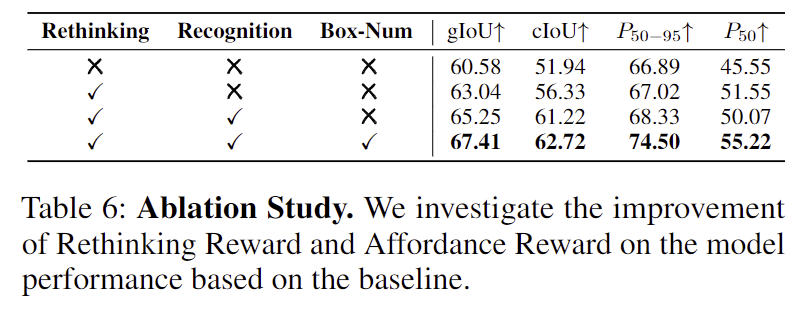
Table 6은 ablation study 결과로, 각 reward의 추가에 따라 성능이 개선된다는 것을 실험적으로 보였습니다. P@50에 대한 실험 결과에서 Recognition reward를 추가함에 따라 약간의 성능 저하가 발생하기는 하지만, 이는 다른 지표를 고려하였을 때 크게 문제는 아니라봅니다.
안녕하세요 승현님, 좋은 리뷰 감사합니다.
초반에 GRPO에 대해 잘 몰라서 링크글 읽어봤는데 링크글이 이해하기 쉬운 비유로 설명이 잘되어있어서 좋았습니다.
질문이 2가지 있습니다.
L1 reward에서 distance 기준이 10인 이유는 무엇인가요… 경험적인 것인가요?
만약에 저희가 요즘 주목하고 있는 속성 기반 멀티모달 similarity가 잘 실험적으로 먹혀든다면,, perception reward와 affordance recognition reward 사이에 그런 reward를 추가해보는 것도 나쁘지 않으려나요?
질문 감사합니다.
우선 L1 reward의 경우 distance가 10인 이유를 따로 이야기하고있지는 않아서, 경험적으로 설정한 것으로 보입니다.
또한, 말씀하신대로, 속성을 명시적으로 추론하도록 하는 reward를 추가해보면 좋을 것 같습니다. 물론 명시적으로 속성을 위한 reward를 설계하지는 않았지만, 어찌보면 해당 논문에서도 전체 답변에 대한 reward를 계산하는 Affordance Recognition Reward 과정에 어느 정도 속성에 대한 표현이 포함되었을 것 같습니다.