1. INTRODUCTION
Scene Text Recognition은 이미지에서 텍스트를 읽어내는 태스크로 Optical Character Recognition (OCR)의 하위 범주에 속합니다. 문서 속 텍스트를 읽는 document OCR과 비교했을 때 더 많은 변동성이 있기 때문에 natural scene에서의 텍스트를 읽어야 하는 STR보다 더 어려운데요. 예를 들면 텍스트를 촬영한 방향, 배경이 난잡한 경우, 조도, 가려짐 정도, 텍스트 자체의 스타일이나 형태의 다양성 등의 이유가 있습니다. 이러한 이유로 visual 단에서 얻은 정보만으로 정확히 어떤 텍스트인지 구분하기가 어려울 때가 많습니다. LLM을 활용한 방법도 근래 여럿 제안되었고 그 효과가 입증 되었지만 단어에 어떤 의미를 찾기 어려운 경우에는 더욱이 정확한 인식이 어렵습니다. 의미 정보를 활용하지 못하는 경우에도 여러 상황에서 강건하게 인식할 수 있는 방법이 필요했습니다. 저자는 의미 정보에 과하게 의존하지 않으면서 이미지로 부터 충분히 의미있는 visual representation을 학습하는 방법에 대한 연구는 여전히 필요하다고 설명합니다.
STR 태스크에서 regular text에 대해서는 어느정도 정확하게 인식이 됐었고 이후에는 irregular text나 low condition image에서도 성능을 향상시키는 방향으로 연구가 이어졌습니다. 이후 추가적으로 고려할 게 많아지면서 초기에 제안되었던 CRNN 같은 전통적인 TR 모델만으로 해당 문제를 잘 다루지 못하였습니다. 특히 비정형의 텍스트나 긴 테스트에 대해서 인식율이 떨어졌습니다. 이후에는 어텐션 매커니즘을 활용한 트랜스포머 기반의 Text Recognizer가 제안되었습니다. 특히 이 방법은 전역적인 관계 학습에 탁월하고 장기 의존성 문제로부터 자유롭다는 점 그리고 병렬적인 예측이 가능하다는 점에서 더 선호가 되는 방법이었습니다. 그러나 비정형의 텍스트나 방해요소가 많은 이미지에서는 인식이 정확하지 않은 문제는 여전히 남아있었는데 연구자들은 이를 언어 모델이 학습하는 의미 정보를 활용하는 방법으로 해결할 수 있었습니다. 하지만 이런 경우 LLM의 크기에 따라 모델의 크기가 함께 커졌으며 학습 복잡도도 높아지고 추론하는데 시간도 늘어나게 되었다고 합니다. 그리고 사전 학습된 단어의 의미 정보를 사용하는 경우 visual cue 보단 이 언어적 패턴을 따르며 올바르지 않게 인식하는 경우가 발생한다는 연구도 여럿 보고 된 바가 있습니다. 그래서 저자는 앞선 기존 방법론들의 문제점을 지적하면서 외부적인 언어 모델에 의존하지 않으면서도 under weak or noisy context texts에 대해서 충분히 시각적인 특징을 학습할 수 있는 방법은 없을지를 연구했다고 합니다.
조금 더 자세하게 얘기를 하자면 기존에 언어 모델이 학습한 언어 패턴을 활용하는 인식 모델 같은 경우는 사람의 행동을 따라 설계된 것인데 사람도 우선은 눈에 보이는 대로 단어를 읽고 정확하지 않은 경우 그 단어가 가지는 의미를 유추해 인식된 것을 교정합니다. 언어 모델 기반의 인식 모델 도 마찬가지입니다. 하지만 꽤 많은 모델들이 언어 모델에 너무 의존한 나머지 그 반대로 학습된 언어 패턴을 따르려는 경향이 더 커 오히려 잘못된 교정으로 이어지는 경우가 많았다고 합니다. 저자는 더 효과적인 학습을 위해서는 강력한 supervision 아래의 반복된 노출을 통해 점진적으로 시각적인 특징으로 문자간 구분할 수 있는 능력을 키우는 방법이 필요하다고 설명합니다. 저자는 curriculum learning과 self-paced learning을 소개하며 이런 학습 방식을 적용하는 것이 그에 대한 해답이라고 합니다. 해당 방법은 초반에는 정확하고 도움이 되는 정보를 가지고 활용하고 학습이 진행될 수록 개입하는 정도를 줄이는 방식입니다.
그러게 해서 제안된 것인 TEXT ENCODING AS CURRICULUM HINTS(TEACH)란 방법론입니다. LLM의 지식을 가져다 사용하지 않고 GT 라벨을 그대로 사용해 이를 이용해 학습 중에 지도 받습니다. 이런 방식으로 외부적으로 지도를 학습 초기에 받게 됩니다. 학습이 진행되면서는 점차 GT 입력으로 부터 지도 받는 정도를 줄이며 최대한 시각 특징에 의존해서 최종 예측을 내게 됩니다. 이러한 방식이 사전 학습된 큰 규모의 언어 모델을 거치지 않기 때문에 많은 비용이 들지 않아 light weight하면서도 challenging한 STR Scenarios에서 일반화와 강건성을 키웁니다.
2. Methods
TEACH는 여러 STR 모델에 plug-and-play 방식으로 적용될 수 있는 방법입니다. GT 라벨 임베딩을 텍스트 이미지로 부터 얻은 임베딩과 함께 디코더의 입력으로 받고 학습되며 어느 정도 학습에 도달하게 되면 사용을 하지 않습니다. 그래서 학습 초기에는 타겟 라벨에 대한 임베딩인 explicit textual supervision에 의존하며 예측을 수행하게 되고 점진적으로는 영향을 줄여 온전히 visual cue만으로 예측되도록 진행됩니다.
2.1 Overview of TEACH
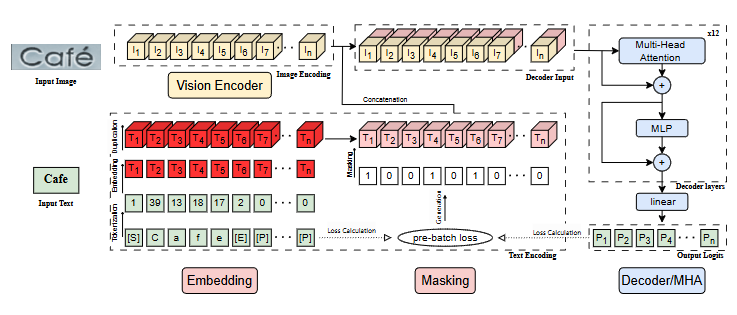
기존의 인코더 디코더 기반 프레임워크에 더해져서 구현이 됩니다. 학습 시에는 GT 텍스트를 인코딩하고 이미지의 visual feature와 concat 합니다. 라벨 토큰에 과적합되는 것을 방지하기 위해서 loss aware masking strategy를 적용해 점진적으로 textual 정보의 활용 정도를 줄여갑니다. 학습이 끝나고 실제 추론 시에는 라벨이 아예 필요하지 않게 됩니다. 기존의 인코더 디코더 구조의 TR를 생각하면 됩니다.
Visual Encoder
기존의 visual encoder에 어떤 변화도 주지 않습니다. 백본으로는 ViT, ResNet, CNN 등 어떤 게 와도 괜찮습니다. 인코더로 부터 텍스트 이미지의 visual feature를 추출해 visual token 시퀀스를 생성해냅니다. label 임베딩 벡터와 concat 돼서 디코더에 전달됩니다.
Text Encoding
어떤 라벨 시퀀스가 다음과 같이 주어졌을때 dictionary lookup 방식이나 학습 가능한 임베딩 레이어를 통해 인코딩된 임베딩 벡터를 생성합니다. 그리고 이를 visual encoder에서 인코딩된 visual token과 concat해서 디코딩됩니다.
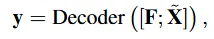
2.2 Progressive Trainig Preocess
TEACH 방법론은 학습 중에 점진적인 변화를 줍니다. 그 변화 과정을 중점적으로 하면서 학습 과정을 정리해보겠습니다. 우선 세가지 단계로 나눠질 수 있습니다. initial, intermediate, 그리고 마지막으로 final 과정이 있습니다. 이 과정은 label supervision으로 부터의 의존 정도를 기준으로 나눈 것입니다.
Initial Stage: Full Label Guidance
학습 초기에 해당합니다. 이미지 인코더는 랜덤하게 초기화된 상태입니다. 그렇기 때문에 초기에는 노이즈가 많이 껴있고 불필요한 정보로 정확한 결과를 예측하기 어렵습니다. 초기에 강한 supervision이 필요하다는 것이 저자의 생각인데요 이를 위해 full label embedding을 디코더에 주입합니다. masking 매커니즘으로 label embedding을 디코더에 전달하는 정도를 조절하는데요 이 단계에서는 마스킹을 일절 진행하지 않고 그대로 전달하다고 보시면 됩니다.
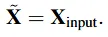
이러한 설정으로 모델은 최종 예측 단계에서 타겟 라벨을 임베딩을 한 것을 가지고 그대로 원래의 시퀀스로 재구성하기만 하면 됩니다. 텍스트 인코딩의 과정을 반전시켜 진행하면 되는 것이지요.
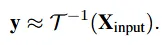
충분히 의미 있는 visual feature가 모델로 부터 추출되서 사용되기 전 까지는 실제 타겟이 되는 GT의 라벨을 임베딩으로 supervision을 받아 입력 임베딩과 출력 공간을 서로 정렬 시켜 학습을 빠르게 안정화 시킵니다.
Intermediate Stage: Loss-Aware Masking
학습이 진행되고 모델이 점차 visual feature로 부터 의미있는 값을 추출할 때 text input의 영향을 이때 줄이기 시작합니다. 이진 마스크로 정도를 조절합니다.
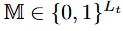
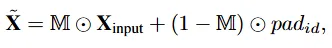
패딩으로는 고정되거나 학습 되는 패딩 벡터를 사용합니다. masking rate r은 이전 배치 loss로부터 계산되게 됩니다.
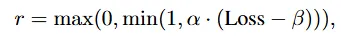
여기서 \alpha 와 \beta 는 튜닝이 필요한 하이퍼파라미터들입니다. 이전 배치의 손실이 컸다면 마스킹 비율을 줄여 label input을 키우고 반대로 loss가 낮다면 마스킹을 늘립니다. 이런 adaptive masking 매커니즘 덕분에 모델은 점진적으로 label-guide를 받다가 visual cue만을 사용하게 되는 것으로 전환됩니다. 그러면서 또 다시 label input의 도움이 필요할 때는 언제든지 masking 비율을 낮춰 지도를 받습니다.
Final Stage: Vision-Only Prediction.
손실이 \beta 아래로 떨어진다면 label input은 전부 사용하지 않게 됩니다. label input 전부에 대해서 라벨이 적용된 상태가 되겠지요.
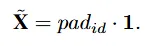
이 시점에서 모델은 그냥 기존의 인코더 디코더 기반의 STR 모델이 그렇듯 추출된 시각특징을 기반으로 텍스트transcription을 수행합니다. 이 단계에 도달해서도 손실이 증가하게 되면 다시 label 의 도움을 받을 수 있습니다. 학습 전반에서 계속 손실값이 떨어지고 증가하는 정도를 유의하며 적절히 label로 부터 도움을 받는 dynamic masking을 제안한 것이라고 보면 될 것 같네요.
2.3. Inference Phase
평가를 마치고 추론 단계 평가하는 단계에서는 어떠한 GT로 부터 보조적인 도움을 일절 받지 않습니다. 모델의 예측은 전적으로 이미지 인코더에서 추출되는 시각 특징에만 의존하게 됩니다. 이런 방식으로 기존의 LLM을 활용하던 STR 모델이 언어 패턴이나 단어가 갖는 의미에 지나치게 의존해서 생기는 문제를 해결할 수 있었다고 합니다.
2.4. Model Integration
TEACH 프레임워크는 어떤 인코더 디코더 기반의 STR 모델에도 적용시킬 수 있었는데요. 본 연구에서는 두개의 대표적인 모델에 적용해보았다고 합니다. ViTSTR은 visual encoder 이후에 fc layer을 통해서 시퀀스 예측을 수행하는 모델이고 PARSeq은 트랜스포머 기반의 디코더를 활용해 시퀀스 모델링을 수행하는 방식인데요 두 모델의 학습 파이프라인을 변경하지 않고도 추론 성능에 영향을 주지 않고도 바로 적용이 가능했다고 합니다.
그리고 이론적으로는 순환신경망 기반의 text recognizer에도 적용이 가능하지만 RNN의 특성 상 input 시퀀스를 순서대로 처리한다는 점에서 이미지 임베딩 텍스트 이베딩이 앞뒤로 나열되었을 때 이미지와 텍스트 정보가 RNN 안에서 잘 섞이지 못한다는 점에서 gradient가 두 모달리티에 균형있게 흐르지 못해 오히려 학습이 불안해졌다고 합니다. 그래서 저자는 아직 RNN 기반의 디코더에 바로 적용하는데 한계가 있다고 얘기합니다.
LLM 기반의 STR 모델들 TrOCR, Clip4STR 또한 인코더 디코더 구조를 그대로 따르기 때문에 동일하게 적용이 가능하다고 합니다. 하지만 language model의 정보를 활용하는 과정에서 일부 파인튜닝하는 경우나 projection layer를 추가로 들여야 하는데 네트워크 크기가 커지게 됩니다 학습 비용도 증가하게 됩니다. TEACH는 external pretraining 없이 가볍게 학습시킬 수 있는 방법을 제안하는 프레임워크 이기 때문에 저자는 vision centric 한 모델에 덧붙이는 것에 집중하고자 했고 LLM 기반의 STR 모델에 적용하는 것은 가능하지만 고려하지 않았습니다.
3. EXPERIMENTS
3.1. Experiments Setup
학습과 평가에 합성 데이터셋과 real-word 데이터셋 모두 활용되었다고 합니다. 합성 데이터셋으로는 900만 개의 렌더링된 데이터셋으로 구성된 MJSynth (MJ)와 690만 개의 샘플로 구성된 SynthText (ST)를 사용하였다고 합니다. real word dataset으로는 COCO-Text, RCTW17, Uber-Text, ArT, LSVT, MLT19, ReCTS와 최근에 OpenImages로 부터 구축된 데이터셋 두가지 TextOCR, OpenVINO 까지 이용해서 학습했다고 합니다.
방법론 평가는 STR 모델에 대해서 흔히 사용되는 대표적인 6가지 벤치마크에 대해서 평가를 수행하였습니다.
3.2. Implementation Details
중간에 label embedding이 추가되는 것 때문에 TEACH를 추가하는 것이 수렴하기 위해서 기존보다 조금 더 많은 training iter가 필요했다고 합니다. 모든 학습과 평가는 두개의 V100 GPU를 사용해서 수행했다고 합니다. 아직 코드는 공개하지 않은 상태이고 추후 공개할 예정이랍니다.
3.3. Results
Effect of TEACH
아래는 TEACH를 적용한 것과 그렇지 않은 기존의 STR 모델 들간의 성능을 비교한 실험의 결과입니다. 평가 metric으로는 Acc가 사용되었습니다.
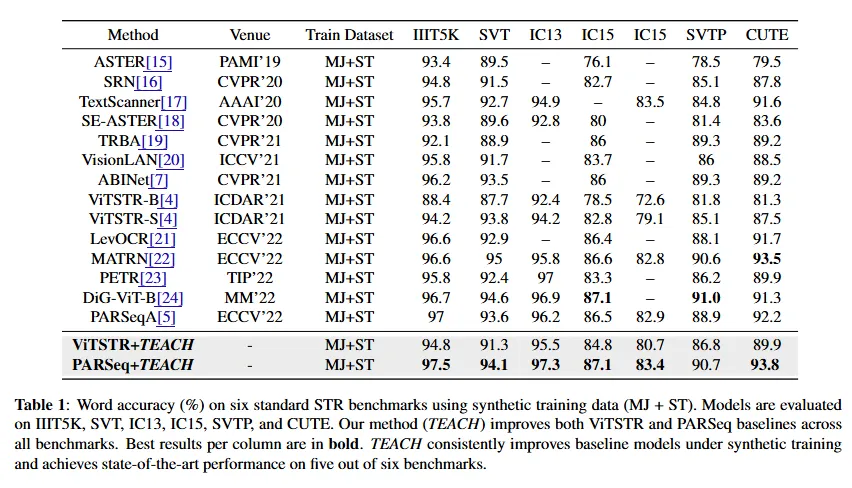
PARSeq+TEACH는 6개 중 다섯 개의 데이터셋에 대해서 높은 정확도를 보였습니다. TEACH 프레임워크를 적용했을 때 ViTSTR과 PARSeq 베이스라인에 대해서 성능 향상이 있었습니다. 학습 초기에 guidance를 주는 것의 효과라고 얘기해볼 수 있을 것 같습니다. 강력한 트랜스포머 기반의 방법론인 DiG-ViT, PETR, MATRN과 비교해보아도 추월하는 경우가 많았습니다.
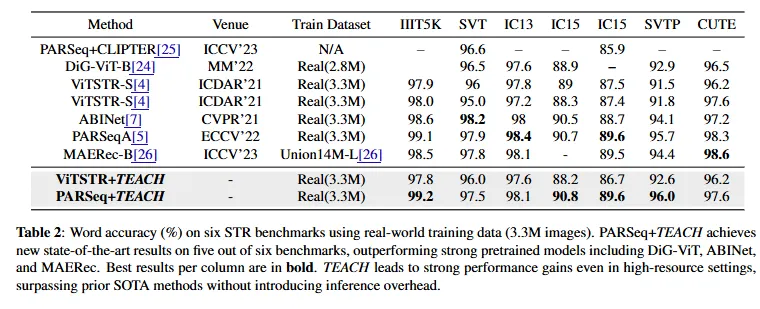
다음은 330만 개의 real-wordl 데이터셋에 대해서 학습시킨 결과입니다. 대부분의 데이터셋에 대해서 이번에도 역시 PARSeq+TEACH가 높습니다. 이는 최신 방법론인 MAERec과 ABINet보다 높은 성능입니다. ViTSTR+TEACH 도 개선된 결과를 보였습니다.
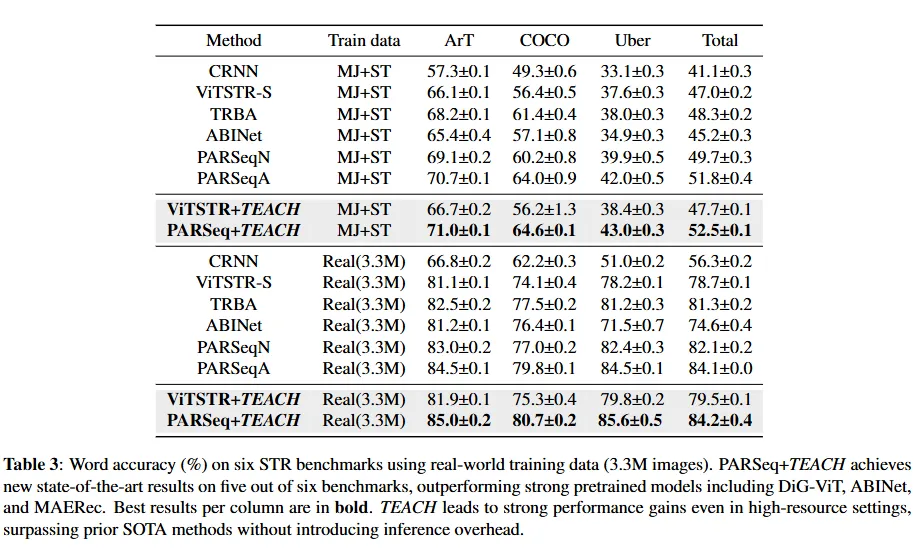
아래는 조금 더 어려운 데이터셋인 ArT, COCO-Text, Uber-Text 대한 결과입니다. PARSeq+TEACH이 모든 데이터셋에서 제일 높은 성능을 보입니다. overall accuracy의 경우도 해당 방법론이 제일 높습니다. 이 결과로 TEACH 방법론이 challenging한 real world scenarios에 대해서도 충분한 강건성을 확인할 수 있다고 정리해볼 수 있을 것 같습니다.
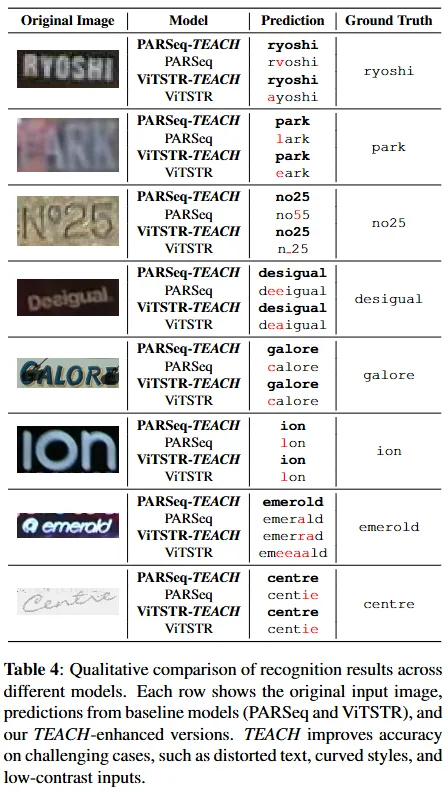
다음은 두 모델의 베이스라인과 TEACH를 적용한 것 의 인식 결과를 확인해 비교한 정성적 평가 내용입니다. 특히 blurred 텍스트, occluded text, 배경과와 텍스트간의 대비가 낮아 뚜렷하지 않은 경우에 대해서 그 효과가 더 강조되는 듯 싶습니다.
3.4. Ablation Analysis
아래는 ablation study의 결과입니다.
Effect of Masking Schedules
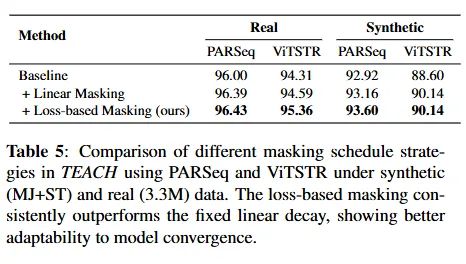
마스킹 비율을 계산하는 방법을 달리 한 다음 비교한 실험입니다. Linear Masking이란 step이 증가할 수록 masking 비율을 점진적으로 줄이는 방법입니다. 베이스라인과 linear masking 대비 저자가 제안하는 대로 loss 기반의 마스킹을 수행하는 것이 제일 정확한 결과를 보이는 것으로 dynamic 한 supervision을 주는 것이 효과적이었음을 확인할 수 있었습니다.
Impact of α and β Hyperparameters.
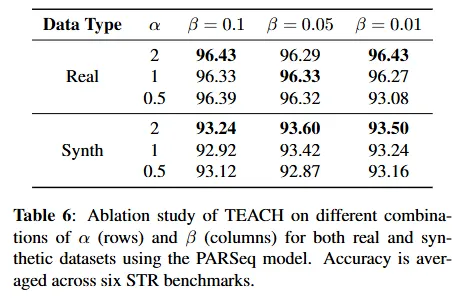
다음은 loss-based masking ratio 계산에 들어가는 하이퍼파라미터인 \alpha 와 \beta 의 값에 대한 ablation입니다. \alpha 는 손실 변동에 대한 민감도를 정하는 값이고 \beta 는 수렴을 결정하는 임계값입니다. 거의 대부분의 조합으로 베이스라인 보다 성능 향상은 대체적으로 보였습니다.
Training Dynamics and Convergence Behavior
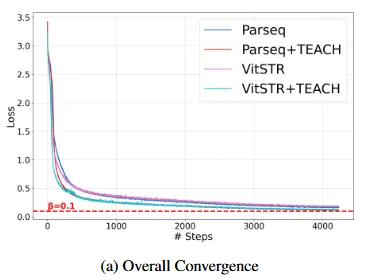
다음은 실제 손실이 떨어지는 경향을 비교하며 저자가 제안하는 방법론이 실제 학습과 수렴에 어떤 영향을 미치는지 보겠습니다. 학습 초기에 TEACH를 적용한 경우에 더 빠르게 수렴하는 것을 확인할 수 있었고 (b)
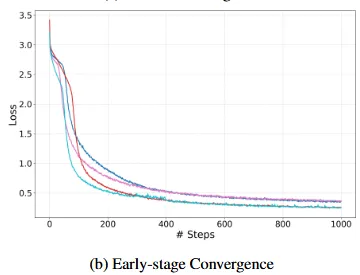
실제 학습 마지막 단계에서도 TEACH를 적용한 경우가 최종적으로 낮은 손실을 갖게 됨을 확인할 수 있었습니다.
위에서 확인된 바로 학습 초기에 text input의 supervision이 효과적인 guidance의 역할을 했음을 알 수 있었고 그리고 학습 데이터와 평가 데이터간의 분포가 비슷하다는 것을 전제로 했을 때 낮은 loss 가 평가 때 높은 정확도로 영향을 주었을 것이라고 생각해볼 수 도 있습니다.
4. Conclusion
마무리하기 전에 조금 정리를 해보겠습니다. 저자가 제안한 TEACH라는 학습 전략은 학습 초기에 실제 정답 라벨의 임베딩을 사용하고 학습이 진행되면서는 이렇게 직접적인 supervision을 주는 것의 비율을 줄여가며 최종적으로는 visual cue만으로 예측을 수행하도록 합니다. 학습 초기에 디코더의 입력으로 text 임베딩을 전달해 초기에 visual feature로 부터 의미있는 정보를 얻기 전임에도 충분히 정답에 근접하게 예측하고 결과적으로 학습 시 수렴이 빠르게 되도록 합니다. 실제 기존 모델과의 비교나 ablation study를 통해 저자의 제안이 실제 성능 향상에 효과가 있다는 것 또한 확인할 수 있었습니다. 또한 가볍고 인코더 디코더 기반의 모델이라면 거의 대부분 쉽게 적용이 가능하다는 것도 특징이었습니다.
안녕하세요. 좋은 리뷰 감사합니다.
Text embedding을 만들 때 dictionary lookup 방식을 사용한다고 했는데, 이게 정확히 어떤 방식인건가요? 또 다른 방식인 learnable한 embedding layer는 어떤 구조인지도 궁금합니다.
그리고, 학습 단계가 총 3가지로 나눠진다고 이해했는데, 이 str에서는 synthetic data로 학습하고 fine-tuning은 안하나요 ? 그렇다면 synthetic data를 학습 하는 과정에서 label supervision 정도가 달라지는것으로 이해하면 될까요?
마지막으로 final stage인 vision-only prediction에서는 label input 전부 사용하지 않는다고 했는데, 다른 어떠한 loss도 사용하지 않는건가요?그럼 학습이 어떻게 되는건지.. 궁금합니다. overview에 있는 pre-batch loss는 어떻게 계산되는건가요?