안녕하세요. 이번에 소개할 논문은 사전 학습된 CLIP 모델을 비디오 도메인으로 확장할 때 시간 모델링에 대한 분석을 다룬 연구입니다. 비디오 태스크에는 Retrieval과 같은 고수준(high-level) 태스크와, Video Recognitio과 같은 저수준(low-level) 태스크가 존재하지만, 기존 방법들은 두 태스크를 동시에 잘 수행하지 못합니다. 이에 저자는 고수준과 저수준 태스크 모두 성능을 향상시는 것을 목표로 하여 STAN이란 모델을 제안하였습니다. 그럼 바로 리뷰를 시작하겠습니다.
1. Introduction
CLIP 모델은 4억 개 이상의 이미지-텍스트 쌍으로 사전 훈련되어 다양한 이미지 이해 작업에 활용할 수 있는 지식을 가지고 있습니다. 비디오 도메인에서도 다운스트림 작업을 위해 CLIP과 같은 유사한 모델이 필요하지만, 계산 자원 부담이 크고 이미지-텍스트 데이터만큼 방대한 비디오-텍스트 데이터를 수집하기 어렵기 때문에 비디오에서 CLIP 수준의 사전 학습 모델을 얻기는 쉽지 않습니다. 그래서 비디오-텍스트 사전 학습 모델을 직접 만드는 대신, 이미지-텍스트 사전 학습 모델의 지식을 비디오 도메인으로 확장하는 접근이 많이 연구되고 있습니다.
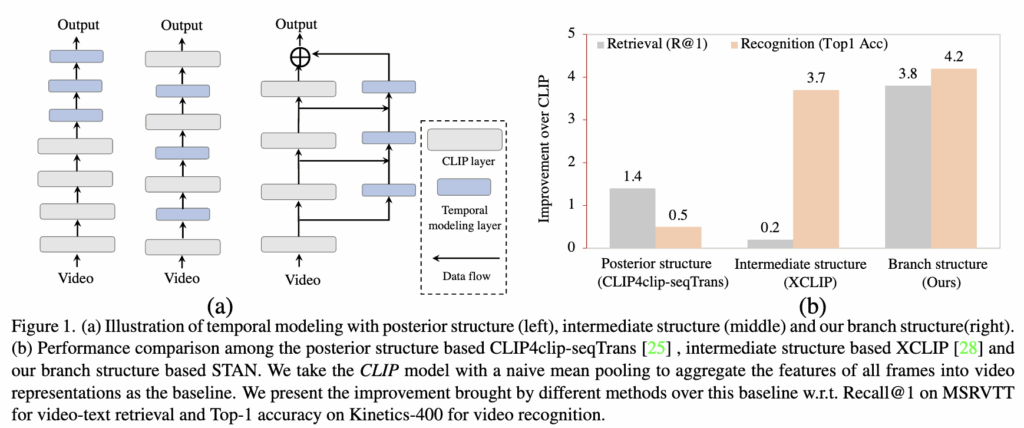
일반적으로 CLIP에 시간 정보를 모델링 하는 구조는 그림 1(a)에서 볼 수 있듯이 posterior structure 과 intermediate structure 구조로 나눌 수 있습니다.
posterior structure 구조는 CLIP에서 독립적으로 추출된 비디오 프레임 임베딩에 대해 시간을 모델링 할 수 있는 모듈을 추가하여 시간 정보를 모델링 하는 구조를 가지고 있습니다. 이러한 방식은 High-level의 의미 정보를 포함하는 임베딩을 활용하여 다운스트림 태스크로 확장 할 수 있다는 장점이 있으나, 비디오 이해에서 중요한 서로 다른 프레임 간 공간-시간적 시각적 패턴(Low-level 정보)은 충분히 학습하지 못하는 한계를 지닙니다. 그림 1(b)에서 확인할 수 있듯, 모든 프레임 특징을 단순 mean-pooling하여 비디오 특징을 추출하는 CLIP baseline과 비교했을 때, 일반적인 posterior structure 기반 방법인 CLIP4clip-seqTrans의 성능 향상은 video action recognition에서는 제한적임을 알 수 있습니다.
Posterior 구조 기반 방법과 달리, intermediate 구조 기반 방법은 CLIP 레이어 사이에 temporal 모델링 모듈을 직접 연결하여 시공간적 모델링 능력을 강화하는 기법입니다. 이는 video action recognition에서 baseline보다 약 3.7% 성능 향상을 달성했습니다. 하지만 CLIP에 추가 모듈을 삽입하면 모델의 사전 학습된 high-level 지식에 영향을 미쳐 text-video retrieval에서는 baseline 대비 0.2%의 성능만 향상 되었습니다ㅏ. 따라서 CLIP을 비디오 도메인으로 확장하려면, 다양한 level의 특징을 활용하면서 시간 정보를 모델링하는 것이 중요하다는 것을 알 수 있습니다.
따라서 저자는 multi-level의 학습을 강화하기 위해 branch network를 도입하여 STAN( Spatial-Temporal Auxiliary Network)을 제안합니다. 그림 1(a)의 3번째 구조가 저자가 제안하는 STAN 구조이며 이는 CLIP의 visual backbone 외부에 새로운 branch 구조를 사용합니다. 이 구조를 통해 STAN은 CLIP의 forward-propagating에 영향을 주지 않으면서, multi level의 시공간 정보를 활용해 비디오 프레임 특징을 보강할 수 있습니다. STAN에 대한 자세한 구조는 이후 Method 섹션에서 설명 드리겠습니다.
2. Method
Introduction에서 설명드린 것처럼 CLIP 모델을 비디오 도메인으로 확장시키기 위해서는 비디오 프레임간의 시간적 관계를 모델링 하는 능력을 이미지 인코더에 추가해줘야 합니다. 하지만 기존 연구들에서는 CLIP의 이미지 인코더의 끝단(posterior 구조) 이나 중간 레이어에 모듈을 추가(intermediate 구조)하여 시간적 모델링을 수행하였습니다. 하지만 이러한 구조는 High-level의 의미 지식과 Low-level의 시각 지식을 동시에 학습할 수 없다는 단점이 존재 합니다. 따라서 저자는 이를 motivation 삼아 CLIP의 의미적 지식과 시각적 패턴 지식을 한 번에 비디오 도메인에 전달할 수 있는 STAN (Spatial-Temporal Auxiliary Network) 를 제안합니다.
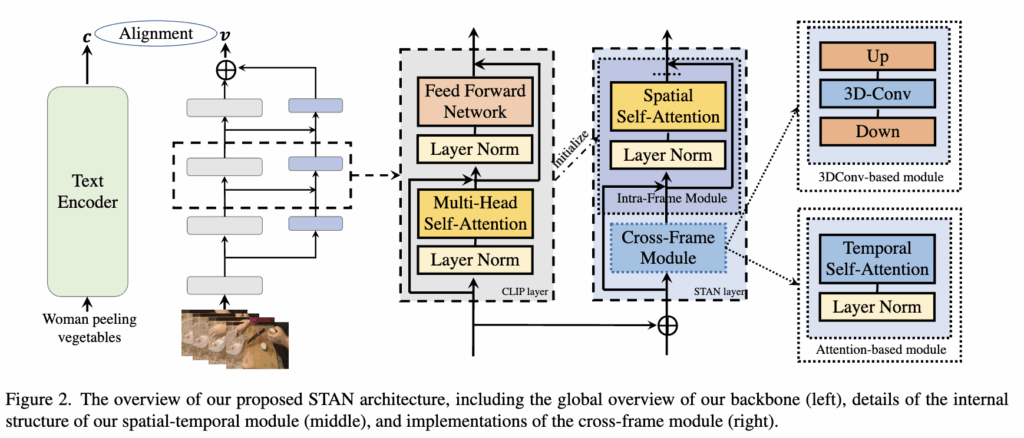
2.2. Spatial-Temporal Auxiliary Network (STAN)
STAN은 K개의 spatial-temporal layer으로 구성되며, 각 layer의 입력은 CLIP visual layer의 출력을 기반으로 구성됩니다. 예를 들어 STAN의 k번째 layer에서 입력은 다음과 같은 비디오의 임베딩 시퀀스로 표현할 수 있습니다.
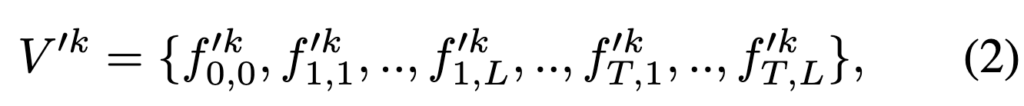
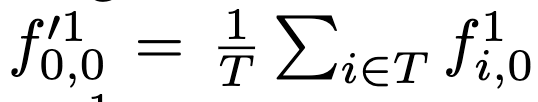
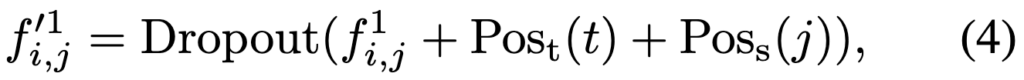
여기서 f0,0 은 전체 비디오에 대한 [CLS] 토큰의 임베딩이고, 이는 프레임들의 CLS 토큰을 평균하여 구합니다. 나머지는 서로 다른 프레임에 있는 이미지 패치이며 이는 학습 가능한 spatial, temporal 임베딩을 더해 구합니다. 이후 STAN layer의 출력 또한 입력과 크기가 같은 임베딩 시퀀스이며, 다음과 같이 표시됩니다.
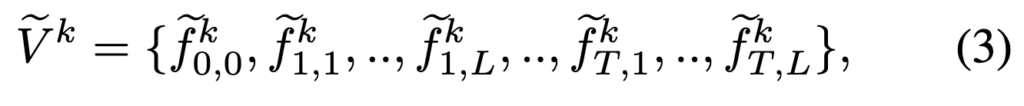
이후 STAN의 다른 layer의 경우, 입력 V’k는 이전 STAN layer Vk-1의 출력과 CLIP 출력 Vk를 기반으로 다음과 같이 구성됩니다.
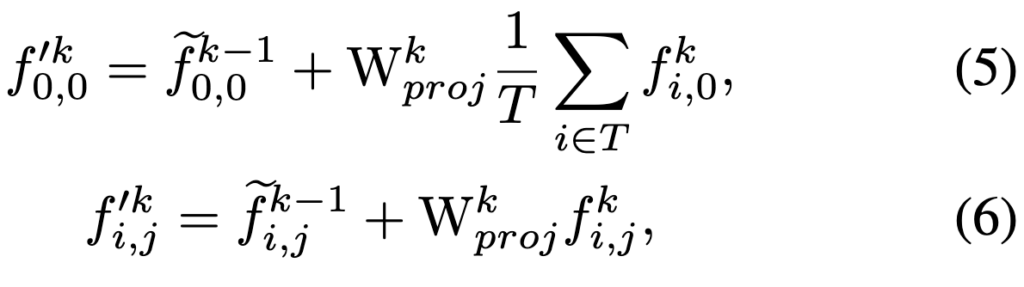
식 5번의 경우 이전 STAN layer의 비디오 토큰과 CLIP k번째 layer에서 추출된 CLS 토큰을 평균하고 학습 가능한 가중치 행렬을 곱해주어 비디오 CLS 토큰을 업데이트 하는 것을 확인할 수 있고,
식 6번도 마찬가지로 이전 STAN layer의 패치 토큰과 CLIP k번째 layer에서 추출된 패치토큰에 가중치 행렬을 곱해 패치들을 업데이트 하는 것을 확인할 수 있습니다.
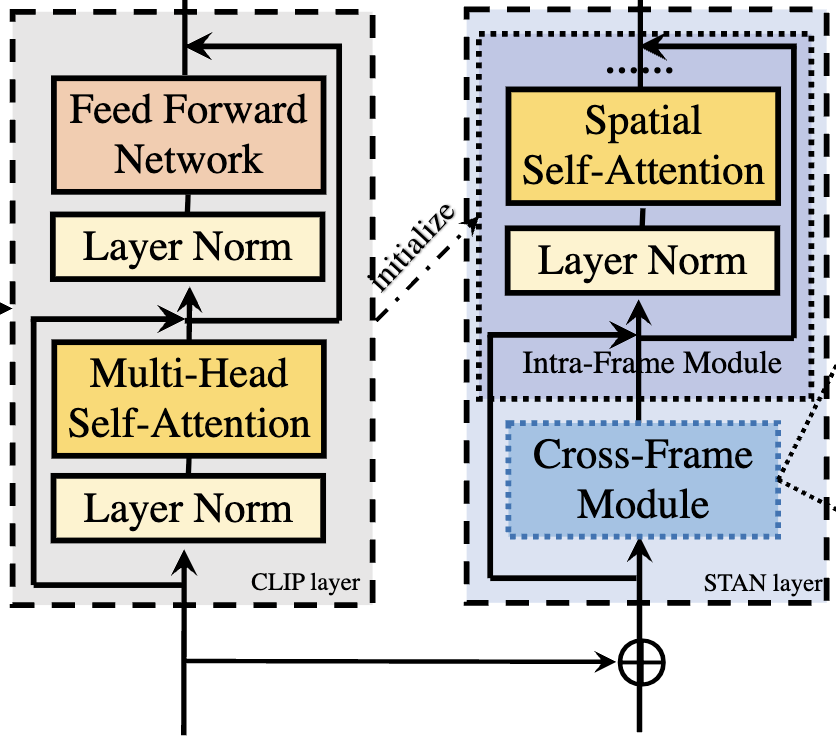
STAN layer는 비디오의 입력 임베딩 시퀀스를 받아 비디오 프레임 간의 공간-시간 정보를 학습하는 역할을 한다고 설명드렸습니다. STAN layer의 구조를 보면 intra-frame module과 cross-frame module의 모듈이 있는 것을 확인할 수 있고 이를 통해 공간-시간 정보를 학습할 수 있습니다. 먼저 Intra-frame module은 CLIP의 visual encoder 레이어를 재사용하고, 학습된 CLIP 모델의 가중치로 초기화가 됩니다. 따라서 학습된 CLIP의 Attention 가중치를 통해 프레임 내 패치들간의 self-attention을 수행하여 공간적 관계를 모델링 할 수 있습니다.
그리고 이를 수식으로 보면 다음과 같습니다.
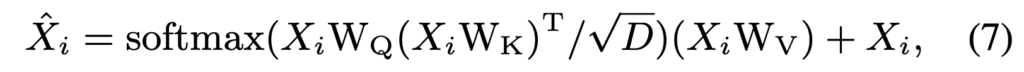
다음으로 cross-frame module은 비디오의 temporal modeling을 위해 사용됩니다. 먼저 비디오의 모든 프레임에서 동일한 공간적 위치에 있는 patch embedding들을 모아 줍니다. 이것을 수식으로 Yj 라고 할때, 이는 전체 비디오 프레임(T)을 축으로 해서 j번째 패치의 embedding 으로 나타낼 수 있습니다
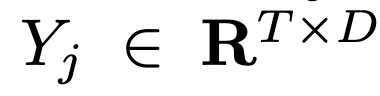
이렇게 모은 patch embedding들(Yj)은 Temp()` 함수를 통해 Yj‘로 업데이트됩니다.
여기서 Temp() 함수는 시간의 정보를 모델링 하기위해 사용되는 함수를 의미하고, 일반적으로 시간 정보를 모델링 하기위해서는 self-attention 이나 3D convolution을 사용할 수 있습니다. 저자는 두가지 방식으로 모듈을 제안하며, 그 성능을 비교합니다.
2.3 Temporal Modeling in STAN
Self-attention based module
Self-attention은 sequence modeling에 유용하며, 영상 프레임 간의 global한 시간 정보를 학습할 수 있는 장점이 있습니다.
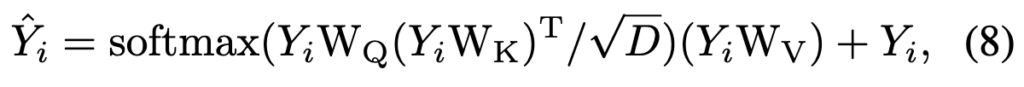
이는 각 공간 위치(spatial position)에서 다른 프레임의 패치 임베딩(Yj)과 attention 연산을 수행하여 값을 업데이트합니다.
Convolution based module
한편 3D convolution은 글로벌 정보는 볼 수 가 없지만 더 나은 로컬 모델링과 더 쉬운 수렴이라는 장점을 가지고 있습니다. 수식으로는 비디오의 패치 임베딩을 쌓아 3D feature cube Y ∈ RT ×W ×H×D 를 형성한 다음 다음과 같이 특징을 업데이트합니다.
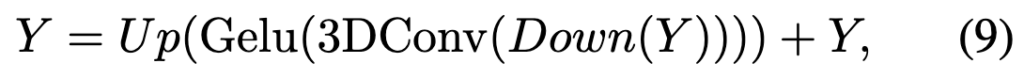
여기서 Down() ,Up()은 패치 임베딩의 차원을 줄이고 복원하는 point-wise convolution 연산자이고, 3D convolution의 커널 크기는 T, H, W 의 차원은 각각 3, 1 ,1로 설정하여 적용합니다.
3. Experiments
저자는 high-level의 의미론적 태스크와 low-level의 시각적 패턴 태스크를 모두 잘 수행하는 모델을 설계하는 것이 목적이므로 이 두 태스크를 대상으로 실험을 진행합니다.
Video-Text Retrieval
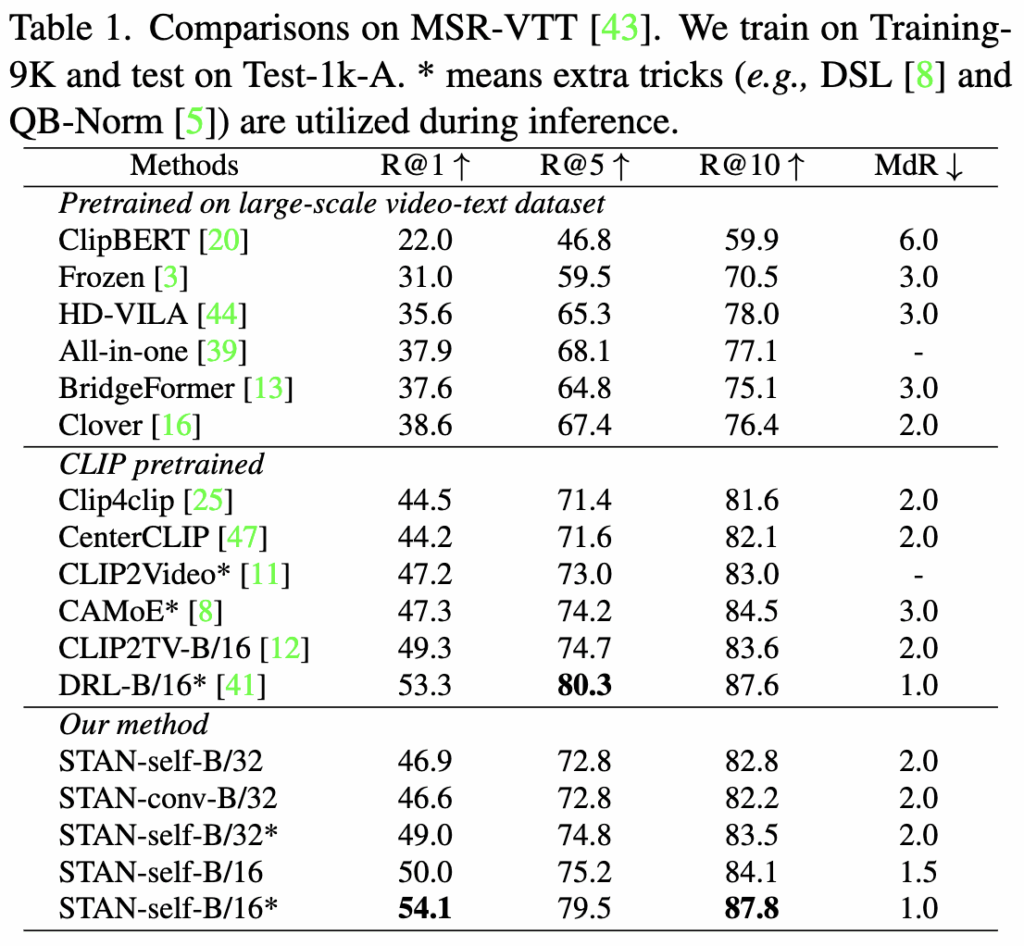
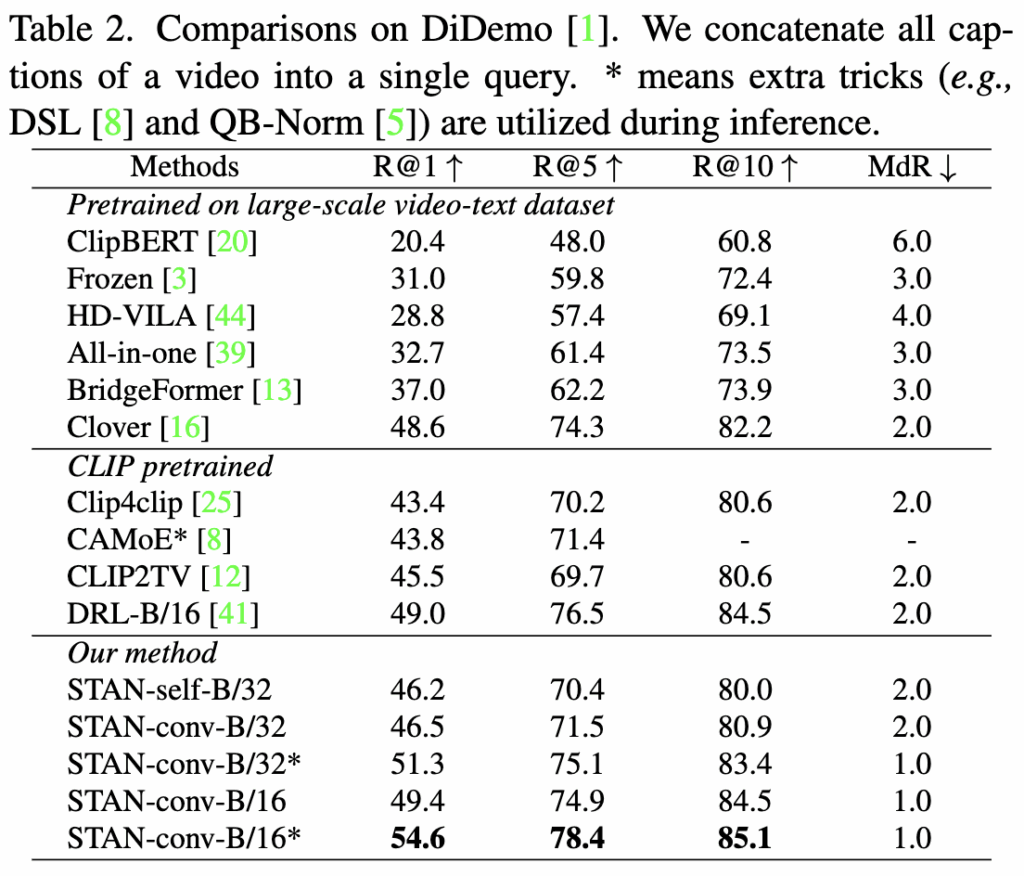
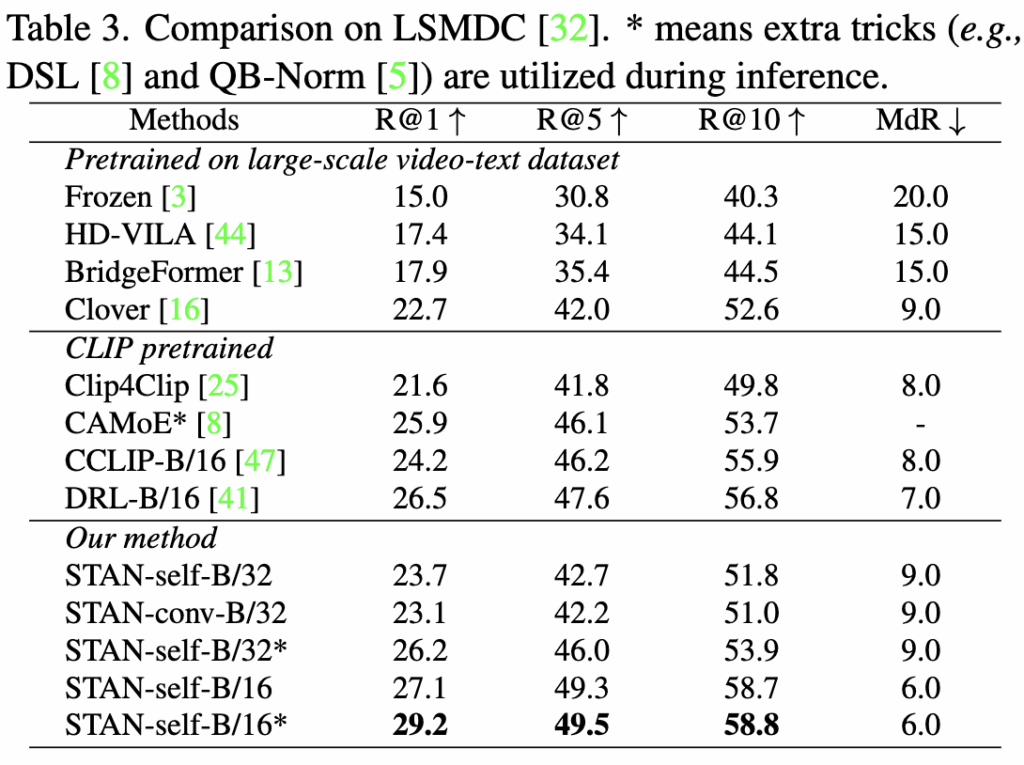
먼저 Text-Video Retrival 태스크의 성능을 살펴보겠습니다. Table 1,2,3에는 각각 MSR-VTT, DiDemo, LSMDC에 대한 성능이 나와있습니다. 표에서 볼 수 있듯이 저자의 방법론은 세가지 벤치마크 모두에서 SOTA 성능을 달성했고, 유사한 모델 크기를 가진 posterior 구조 기반 방법인 CLIP4clip 대비 평균 R@1에서 2.9% 높은 성능을 보여 branch 구조의 이점을 입증하였습니다. 또한 다른 이전 SOTA 모델인 DRL은 CLIP의 출력에 대해 cross modality를 적용하여 성능을 개선한 반면, 저자의 방법론은 CLIP 인코더 자체에 시간 모델링을 설계하여 성능을 향상시켰습니다.
그리고 STAN-self와 STAN-conv 모두 높은 성능을 보였는데, STAN-conv는 작은 규모의 데이터셋에 보다 적합하여 MSR-VTT에서는 R@1에서 -0.3, DiDeMo에서는 +0.3의 성능을 보였으며, STAN-self는 대규모 데이터셋에서 더 나은 성능을 보여 LSMDC에서 R@1에서 +0.6 향상을 기록하였습니다. 이러한 결과는 대규모 downstream 데이터셋에는 self-attention 기반 STAN이, 소규모 데이터셋에는 3D convolution 기반 STAN이 더 적합하다고 저자는 분석하고 있습니다.
Video Recognition
다음으로 spatial-temporal modeling 성능을 검증하기 위해 비디오 인식 벤치마크인 Kinetics-400(K400)과 Something-Something-v2(SSv2)에서 최신 기법들과 비교를 진행합니다. 결과는 각각 Table 4와 Table 5에 제시되어있습니다.
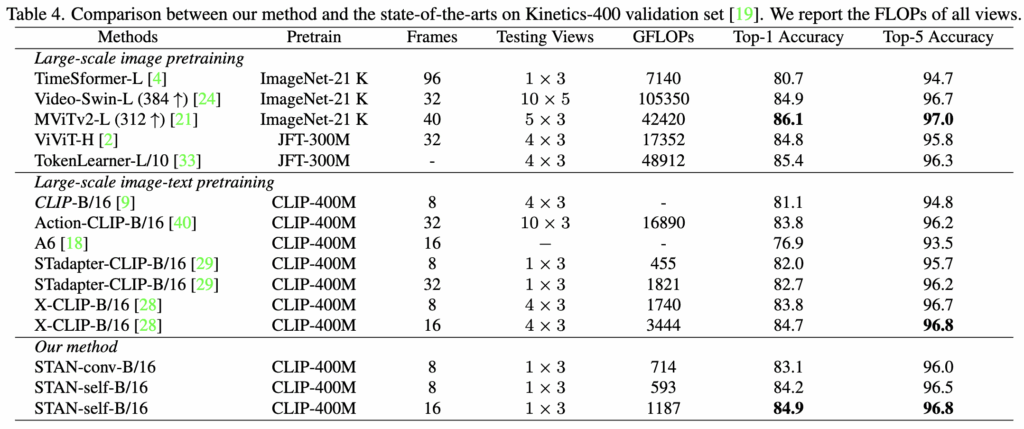
먼저 K400 벤치마크에서 CLIP-based 방법론은 상대적으로 작은 모델 크기에도 불구하고 image-pretrained methods에 비해 비슷하거나 더 좋은 성능을 달성하며, 이미지-텍스트 사전 학습의 강점을 보여줍니다.
예를 들어, ViT-B/16 기반 STAN은 ViT-Huge 기반 ViViT ,Swin3D-L 기반 Video-Swin보다 더 높은 성능을 기록했는데, ViViT과 Video-Swin은 각각 저자의 방법론보다 15배, 88배 더 많은 GFLOPs를 필요로 합니다. 또한 저자의 방법론은 CLIP 기반 방법들 가운데서도 SOTA 성능을 달성하여, CLIP의 비디오 도메인 확장에 효과적임을 입증하였습니다.
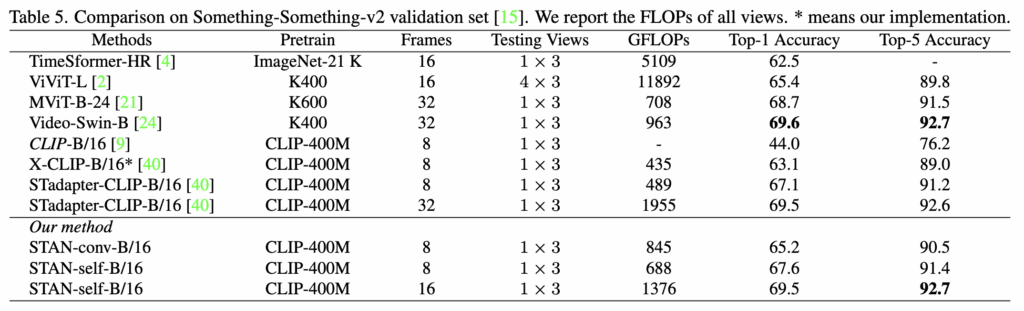
SSv2 벤치마크에서는 기본 CLIP 모델이 44.0%의 성능을 보여주었고, 이는 훨씬 더 큰 이미지-텍스트 데이터셋에서 사전 학습되었음에도 불구하고 ImageNet-21K로 학습된 Timesformer보다 훨씬 낮은 성능을 보이고 있습니다. 이 결과는 SSv2와 CLIP 모델 간의 도메인 차이가 크고, action recognition 태스크에서는 시간적 모델링이 필수적임을 보여주고 있습니다. 이에 비해 저자의 방법론은 CLIP baseline 대비 20% 이상 성능을 향상시켰으며, 다른 CLIP 기반 방법들과 비교했을 때도 더 좋은 성능을 달성하였습니다.
Ablation Study
마지막으로 Ablation study를 살펴보고 마무리 하겠습니다.

Table 6의 결과를 보면, STAN의 구성 요소들은 서로 잘 호환되고 동시에 CLIP의 비디오 도메인 확장에 기여한다는 것을 알 수 있습니다. 구체적으로 branch 구조와 multi-level feature learning을 제거하고 STAN을 posterior 구조로만 적용했을 때 네 가지 벤치마크 전부에서 성능이 저하되었는데, 이는 posterior 구조보다 제안한 모델 구조가 더 효과적임을 보여줍니다. 또한 Cross-Frame module 없이도 STAN은 baseline보다 성능이 향상되었으며, Cross-Frame module까지 포함된 구조가 baseline보다 더 좋은 성능을 기록하면서 video-text retrieval과 video recognition 태스크에서 모두 성능을 향상시킬 수 있음을 확인할 수 있습니다.
안녕하세요. 정의철 연구원님 좋은 리뷰 감사합니다.
모델 구조에서 궁금한 점이 있습니다. CLIP layer 내에 있는 Multi-Head Self-Attention의 가중치로 STAN layer의 Spatial Self-Attention으로 가중치를 초기화하는건가요? 만약에 맞다면, STAN layer 내에서는 temporal modeling을 수행한 이후에 spatial modeling을 수행하는 것으로 생각됩니다. 대부분의 기존 연구에서는 Spatial 정보를 가지고 있는 상태에서 Temporal 연산을 수행하는 것으로 알고 있습니다. Spatial 정보를 토대로 Temporal 정보를 더 효율적으로 추출할 수 있다는 생각에서 비롯된 것으로 알고 있는데 STAN에서는 Temporal modeling을 먼저한 이유가 있을까요?
감사합니다.
말씀하신 것처럼 STAN layer의 Spatial Self-Attention은 CLIP의 Multi-Head Self-Attention 가중치로 초기화합니다. 그리고 대부분의 기존 연구에서는 말씀하신 것처럼 Spatial 정보를 먼저 추출하고, 이를 바탕으로 Temporal 관계를 모델링합니다. 하지만 저자는 Temporal modeling을 먼저 수행하고 Spatial 정보를 학습하였는데, 이에 대한 추가 설명이나 Ablation 실험 정보는 없습니다.
제 생각에 저자가 제안하는 모델 구조는 Branch 구조를 가지고 있어서 기존 CLIP 인코더에서는 프레임 내 패치들간 attention 연산이 수행되는 과정은 유지되고 있습니다. 때문에 Temporal modeling을 적용한 후에 한 번더 attention 연산을 수행하여 공간정보를 강화해주지 않았나 생각하고 있습니다.
감사합니다.
안녕하세요 의철님 좋은 리뷰 감사합니다.
제가 Video Recogintion 테스크가 조금 생소해서 질문을 드립니다! Video Recogintion 가 저수준의 패턴 인식 기반이며 SSv2와 Kinetics-400 데이터로 실험되었는데, video classification으로 이해하면 될까요? 고수준과 저수준으로 나눈 이유가 맵핑되는 텍스트의 세분화 정도로 이해하면 되는지 확인받고 싶습니다.
우선 위와 같이 이해했는데, 일반적으로는 두 테스크가 유사해서 방법론에 따라 성능 등락률이 추세가 비슷할 것으로 생각했습니다. 긂에도 Figure1에서 Posterior structure와 intermediate structure가 정반대의 성능 개선을 보이는 이유를 알 수 있을까요? 혹시 Intermediate structure가 비교적 쉬운 데이터셋으로 학습하여 시간적 정보를 해당 도메인에서만 암기해서 이러한 격차가 발생한 것인지 궁금합니다.
만약 위와 같다면 StAN은 네트워크를 추가하는 intermediate 구조를 활용하되, 인코더의 끝단 등에 제약을 두는 posterior 구조를 통해 제약을 준 것으로 이해하고 싶은데, STAN 구조 만으로는 postierior의 구조적 특징이 적용된지 파악이 어렵더군요. 혹시 attention layer 내부에 branch를 추가하는 것이 아닌, layer를 병렬적으로 추가해 합하는 구조가 해당 연구에서 처음 제시된 것일까요? 아니면 위와 같은 기존 방법론의 확장이 아닌 아예 새로운 구조의 제안인가요?
감사합니다!
의철님 안녕하세요. 좋은 리뷰 감사합니다.
저자가 언급한 기존 연구인 posterior, intermediate에서도 마찬가지겠지만,
STAN의 branch 구조를 CLIP 백본의 어느 layer에 총 몇개를 끼워넣는지에 대한 분석 결과가 논문에 있나요?
레이어별로 보는 정보가 다를 것 같은데, STAN 네트워크도 그에따른 영향을 받을지 궁금하여 질문드립니다.
추가로 마지막 표 6에서 Testing techniques는 어떤건가요? 성능이 엄청 오르는 일종의 기법으로 보이는데, 대략 어떤 컨셉인지 소개해주시면 감사드리겠습니다.
안녕하세요 의철님 리뷰 감사합니다~!!
기존 접근방법 중에 Intermediate structure도 결국 CLIP 안에 temporal 모듈을 삽입하는 거라면 여기서 제안하는 방법처럼 외부에 보조 branch를 두는것도 단순하게 생각하자면 비슷해 보이는데,
그럼 외부 구조로 temporal 정보를 모델링 하는게 직관적으로 왜 더 안정적인가요?!