안녕하세요, 71번째 X-Review입니다. 이번 논문은 2025년도 CVPR에 올라온 UniVAD: A Training-free Unified Model for Few-shot Visual Anomaly Detection 입니다. 바로 시작하도록 하겠습니다.
1. Introduction
기존 Anomaly Detection 방법론들은 대부분 특정 도메인에 특화되어 왔습니다. 예를 들어, industrial 도메인에서만 동작하는 모델이라던가, medical 도메인에 초점을 맞춘 모델처럼 말이죠. 이렇게 어떤 한 도메인에서 최적화한 모델을 다른 도메인에 적용하게 되면 성능이 엄청 떨어지는 문제가 존재합니다. 예를 들어, industrial AD에서 SOTA를 달성한 모델 중 하나인 PatchCore라고 하는 모델은 industrial 벤치마크 데이터셋인 MVTec-AD에서 84.1% 성능을 보이지만, logical AD 데이터셋인 MVTec LOCO에서는 62.0%로 성능이 크게 떨어진다고 합니다. 게다가 같은 도메인 내에서도 one-category-one-model 방식이라고 해서 한 object 마다 별도의 모델을 학습하는 방식을 쓰기도 하는데요. 이렇게 학습했을 경우에 해당 object외에는 사용할 수 없기 때문에 본 논문에서는 AD 연구에서 좀 더 다양한 도메인에서 잘 동작할수 있어야 함을 주장합니다.
따라서 본 논문에서는 기존 AD 방법론들의 한계점을 해결하기 위해 UniVAD라고 하는 모델을 제안합니다. 이 UniVAD는 training-free 모델로, industrial, logical, medical 등등 다양한 도메인에서의 이상 탐지를 처리하도록 설계되었습니다.
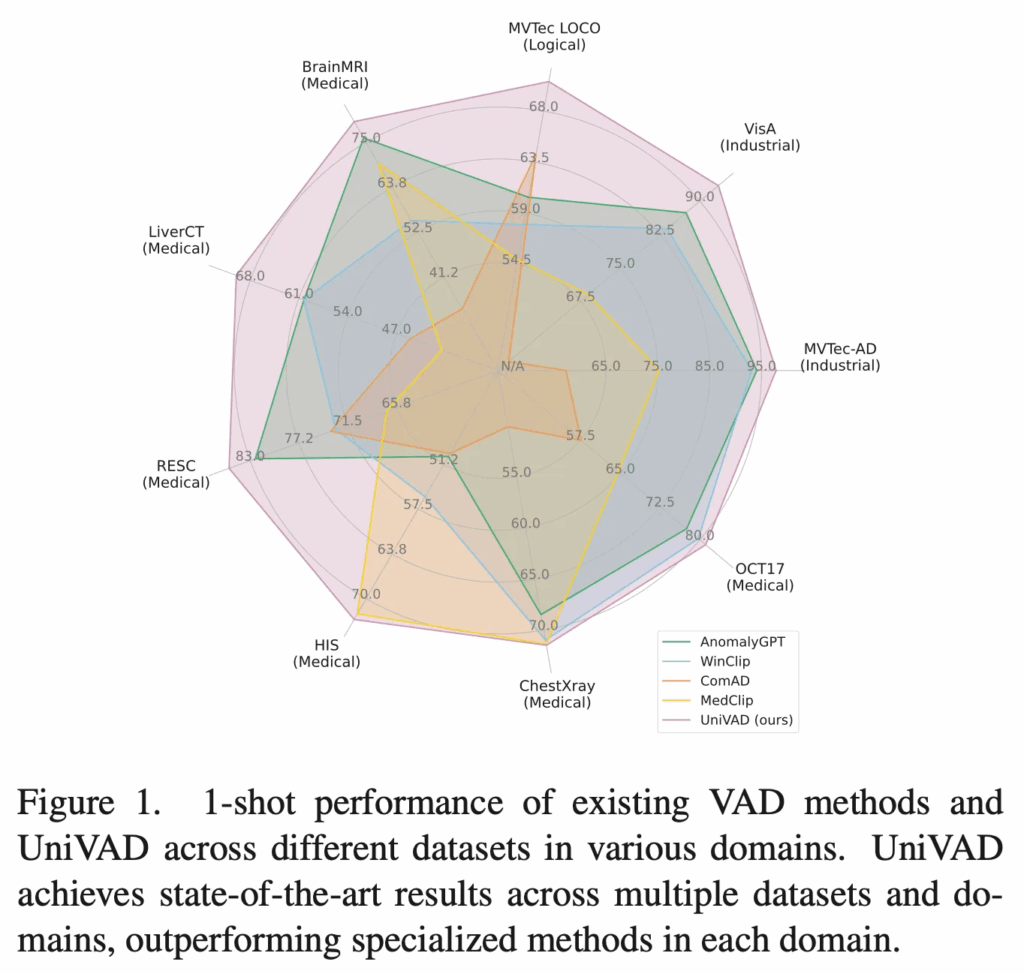
학습이 필요 없는 대신에 test할 때 그 query image로 들어온 object에 대한 normal sample 몇 개를 가지고 이상 탐지를 수행하게 되는데, 현존하는 few-shot 모델 중 1 shot 결과를 비교하고 있는 위 fig1에서 살펴볼 수 있듯이 핑크색 선인 본 논문의 UniVAD가 여러 도메인에서 가장 좋은, 안정적인 성능을 보이고 있습니다.
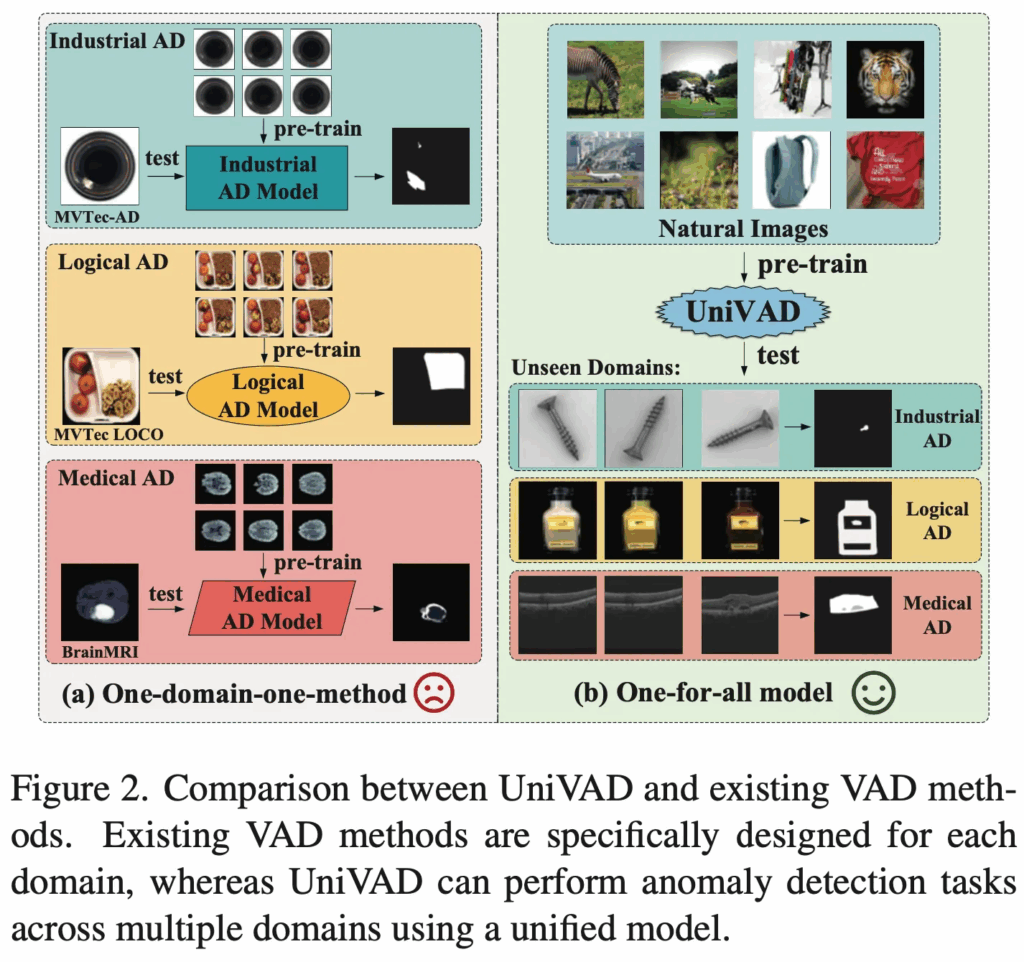
기존 AD 방법론과 UniVAD 차이를 Fig2를 보며 정리해볼 수 있겠습니다. 왼쪽에 One-domain-one-method라고 써져있는게 기존 한 도메인에서만 동작하는 모델들이며, 오른쪽이 여러 industrial, logical, medical domain을 다루는 UniVAD입니다. 그럼 제안된 모델에 대해서는 아래 method단에서 살펴보도록 하겠습니다.
2. Method
2.1. Overall Architecture
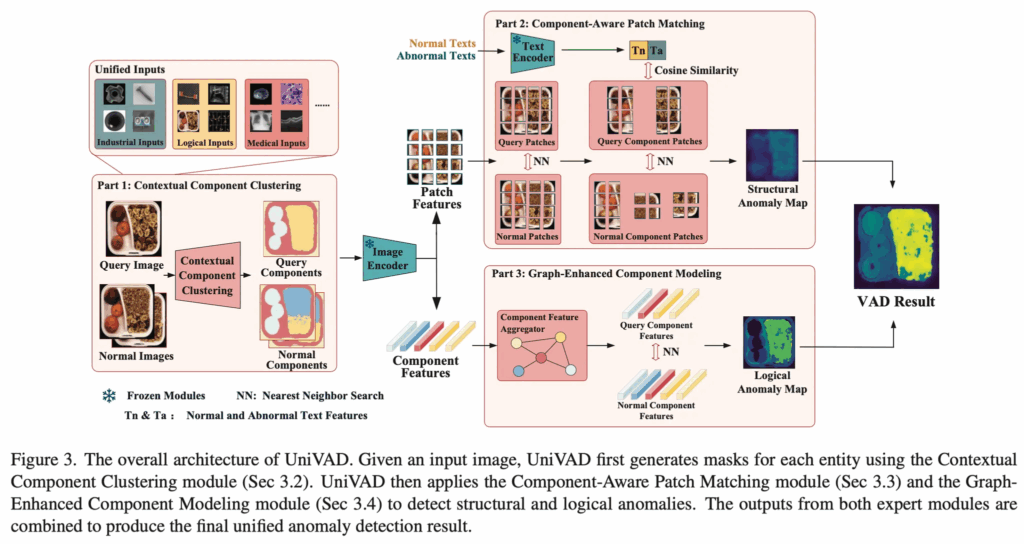
먼저 전체적인 모델 구조를 살펴보도록 하겠습니다. 먼저 이 UniVAD가 training-free로 동작한다고 했고, 대신에 test 단에서 reference로 삼아야 할 normal image가 필요하다고 했었습니다. 위 그림 왼쪽 Part1에서 볼 수 있듯이 우선 query image와 K개의 reference normal image가 주어지게 되구요. Contextual Component Clustering(이하 C3)을 수행하게 됩니다. 이 part1 단계 C3 부분은 query image와 reference normal image 각각에서 component에 해당하는 mask를 생성하는 부분이라고 보시면 됩니다. 그 이후에 pre-trained된 image encoder를 사용하여 query image와 normal image의 feature F_q, F_n을 각각 뽑아내게 되구요. 이후 part1에서 생성된 component mask를 기반으로 group average pooling을 수행해 구성 요소 단위의 feature vector를 추출하게 됩니다. 그럼 query image의 component feature는 F_{qc} ∈ R^{N_q \times C}가 되겠구요. normal image의 component feature는 F_{nc} ∈ R ^{K \times N_n \times C}가 됩니다. 여기서 N_q, N_c는 각각 part1을 통해 query image와 normal image에서 나온 component 개수를 의미합니다.
그 다음 우상단 부분에 있는 part2로 넘어가게 되는데요. 이 부분은 component-aware patch matching단계입니다. 먼저, normal과 anomalous 상태를 설명하는 text를 text encoder에 넣어 각각의 text feature를 추출한 다음 앞에 image encoder를 통해 뽑아낸 patch level의 feature를 가지고 structural anomaly map을 추출하게 됩니다. 추후에 자세하게 설명드리도록 하겠습니다.
마지막으로는, Part3 단계인데요. 앞서 C3 모듈로 얻은 query image의 component feature F_{qc}와 정상 이미지의 component feature F_{nc}가 Graph-Enhanced Component Modeling(이하 GECM) 모듈로 들어가게 됩니다. 이 모듈은 component간 relation을 graph 형태로 모델링해서 뭐가 누락됐다던가, 더 추가됐다던가, 잘못 배치던 것과 같은 좀 더 semantic한 level의 anomaly detection을 수행하게 됩니다. 이를 통해 logical anomaly map이 나오게 되죠.
이후, Part2인 CAPM 모듈에서 얻은 structural anomaly map과 Part 3인 GECM 모듈에서 얻은 logical anomaly map을 합쳐 Fig3에서 볼 수 있듯이 최종적인 final anomaly detection 결과가 나오게 됩니다.
정리하자면, Part1에서는 query image와 normal image의 component feature들을 뽑아내게 되구요. Part2에서는 patch feature들을 가지고 structural anomaly map을, Part3에서는 component feature를 가지고 logical anomaly map을 추출한 다음 이 두 map을 가지고 최종 결과를 내는 식입니다.
그럼 아래에서 각 part1, 2, 3단계에 대해 자세히 살펴보도록 하겠습니다.
2.2. Contextual Component Clustering
먼저, Part1 단계인 contextual component clustering, 이하 C3 모듈입니다.
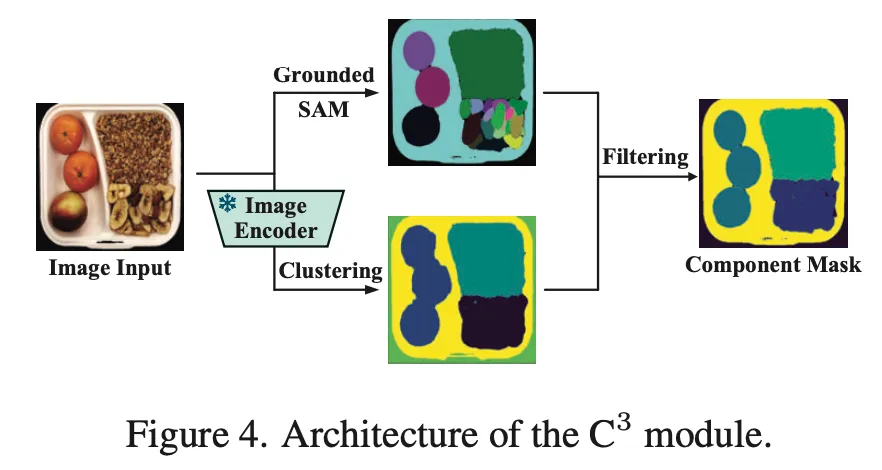
C3 모듈 구조는 위 Fig4에서 살펴볼 수 있습니다. 먼저, 입력 이미지가 들어오면 Recognizer Anything Model(RAM)을 사용해 image안에 있는 object들을 인식하게 되구요. 각 object에 대한 content tag를 생성해 내구요, 그 다음 Grounded SAM을 사용해 이들에 대한 mask를 생성하게 됩니다. Fig4에서는 위쪽 branch에 해당하겠네요. 이렇게 나온 mask는 M_{sam} ∈ R^{M \times H \times W이며, M이 검출된 component 수 입니다.
근데, 그림에서도 볼 수 있듯이 이렇게 뽑은 mask는 너무 세밀하거나 너무 rough한데요. 이런 점이 normal image와 query image간의 일관성을 깨뜨린다고 합니다. 이를 좀 보완하는 것이 아래 브랜치에 해당합니다. 보시면 pre-trained image encoder를 통해 feature map을 뽑아내구요. 이걸 가지고 K-means clustering을 진행하여 cluster mask M_{valid}들을 뽑아내게 됩니다. 마지막으로 처음 Grounded SAM으로 뽑은 mask M_{sam}과 clustering을 통해 얻은 M_{valid}를 IoU 기준으로 매칭해주고 같은 그룹으로 묶인 mask들은 합쳐져서 최종 component mask를 생성하게 됩니다.
2.3. Component-Aware Patch Matching
다음으로는 part2 단계인 CAPM 모듈입니다. 이 모듈은 기존 patch feature matching을 확장한 방식인데요.
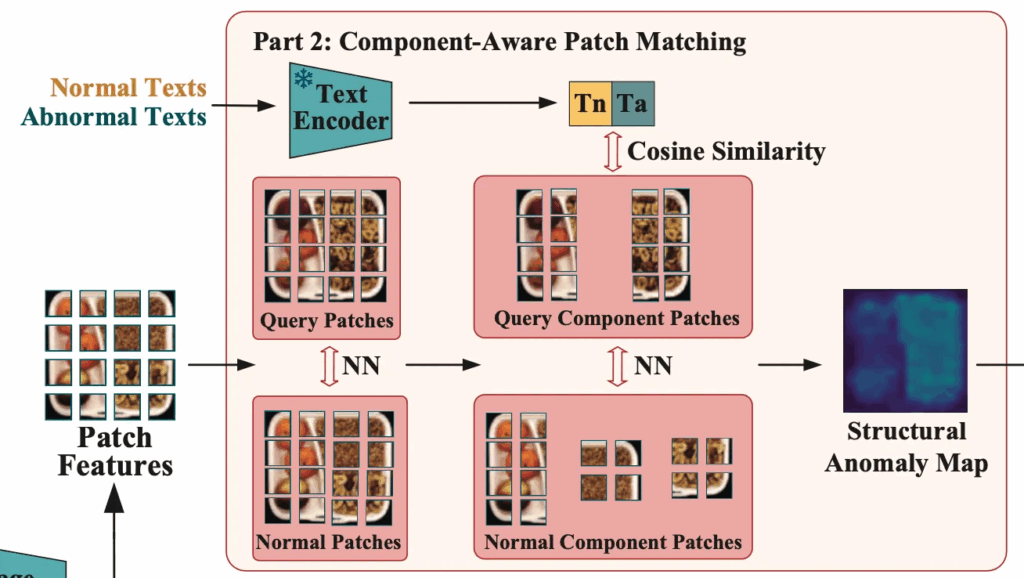
위 그림을 보시면 되는데요. 먼저 Query patch feature와 Normal patch feature가 있을 때, query image의 각 patch P_q^i와 normal patch 전체 P_n와의 cosine distance를 계산하고, 그 중 최소값을 anomaly score로 사용합니다.
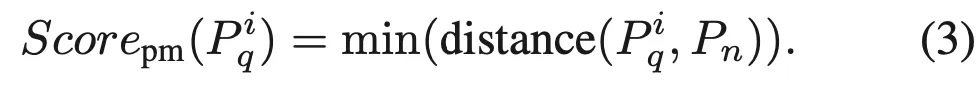
식으로 살펴보면 위와 같구요.
근데, 이런 방식만 가지고는 전경과 배경을 잘 구분하지 못하거나, 서로 다른 object component끼리 매칭되는 문제가 발생할 수 있습니다. 이를 해결하기 위해 앞서 C3 모듈에서 얻은 component mask를 사용해 각 patch가 속한 component 내에서만 매칭이 되도록 제약을 두었습니다.
구체적으로, normal patch feature P_n가 있을 떄 C3 모듈에서 생성한 N’개의 component mask를 사용해, 각 mask에 속하는 patch들을 하나의 set으로 묶어서 component별 patch subset을 만듭니다.
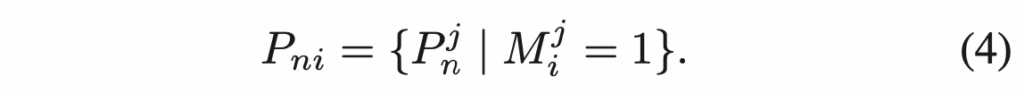
동일한 과정을 query image에도 적용해 P_{qi}를 얻어내구요. 각 query patch P^j_{qi}는 해당 component의 normal patch set P_{ni}와만 비교하여 그 최소 distance를 anomaly score로 계산합니다. 식으로는 아래와 같겠구요.
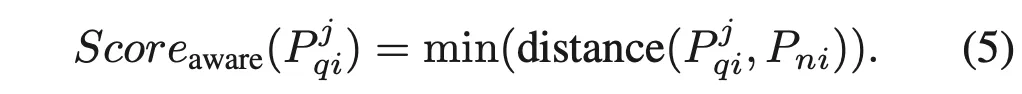
여기에 추가로 pre-trained된 text encoder를 사용하여 image-text feature-matching까지 합니다. 구체적으로, normal과 anomolous 상태를 설명하는 Text feature T_n, T_a를 추출하고 query patch P^j_{qi}와 이들간의 cosine similarity를 계산해 softmax로 정규화한 image-text anomaly score를 얻어냅니다.
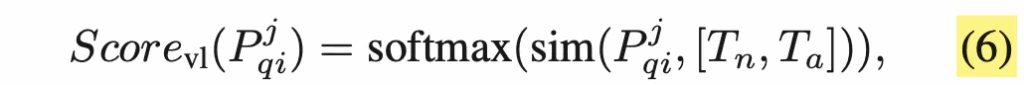
마지막으로 원래 patch matching score와 component aware score와 image-text score를 가중합하여 최종 structural anomaly score map을 뽑아냅니다.
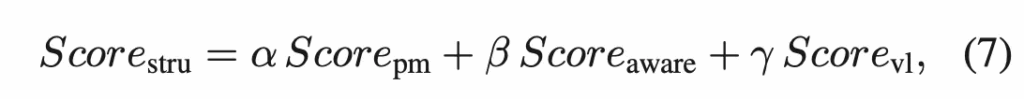
2.4. Graph-Enhanced Component Modeling
마지막으로 part3 단계인 Graph-Enhanced Component Modeling 부분입니다. 앞서 part2 CAPM 모듈이 patch level에서의 low level의 구조적인 이상을 탐지한다면, 이 GECM은 high-level의 logical anomaly를 다루게 됩니다. 예를 들어 어떤 부품이 하나 빠져있다거나, 더 있다거나 잘못 배치된 경우는 단순 patch matching으로는 구별하기 어렵기 때문에 component의 전체를 modeling할 필요가 있는 것이죠.
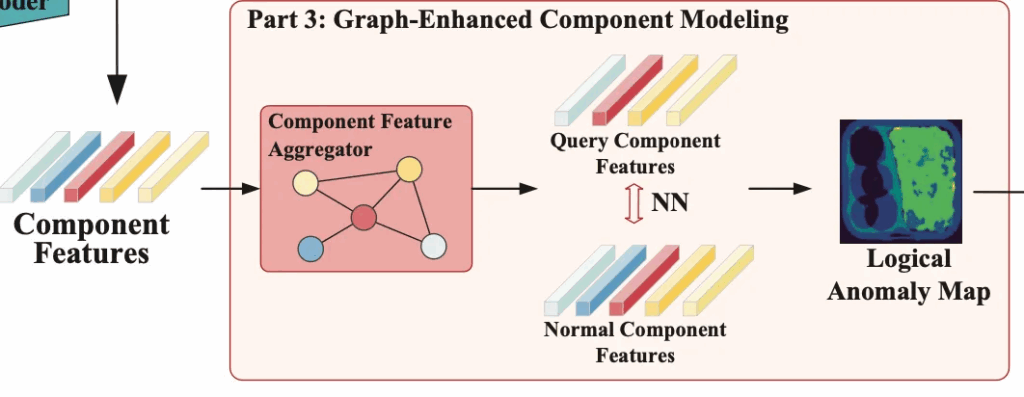
Part3 부분에 대한 그림은 위를 참고하시면 됩니다. 먼저 C3 모듈에서 얻은 component mask를 기반으로 그림에서 좀 잘리긴 했는데 pre-trained image encoder를 사용해 feature를 추출하게 됩니다. 이후에 각 component를 graph의 node로 두고, node 간의 cosine 유사도로 edge weight를 정의해 인접 행렬 A를 구성하게 됩니다.
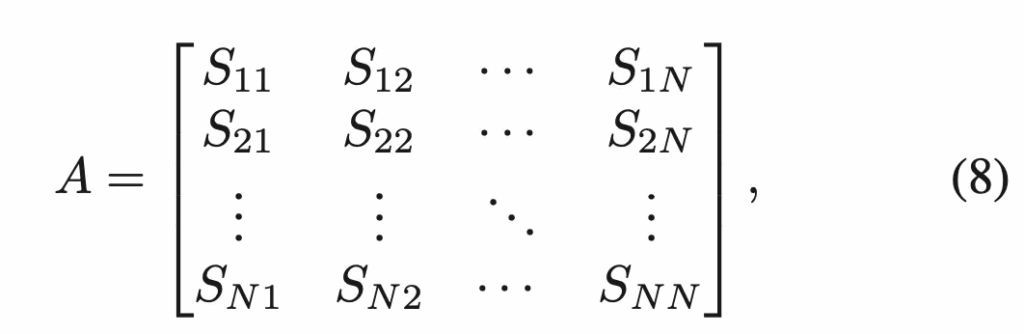
여기서 N은 graph에 있는 node 수가 되겠고, S들이 아래 식9처럼 계산되는 두 노드 간의 cosine 유사도입니다.
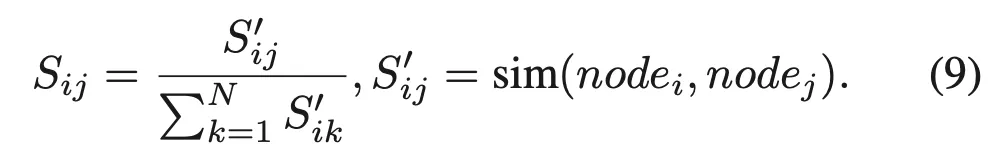
이 부분이 그림에서 Component Feature Aggregator 부분에 해당합니다.
그 다음 이렇게 나온 인접 행렬 A와 각 component feature F_{qc}, F_{nc}를 graph attention에 넣어 주변 노드 맥락까지 반영된 새로운 embedding을 얻어 냅니다. 즉, E_q = G(A_q, F_{qc}, E_n = G(A_n, F_{nc}이 되겠습니다. 이후, query image의 component embedding E^i_q를 normal embedding E_n와 비교해 가장 가까운 거리를 deep anomaly score로 정의합니다. 아래 식을 참곻면 되겠구요.
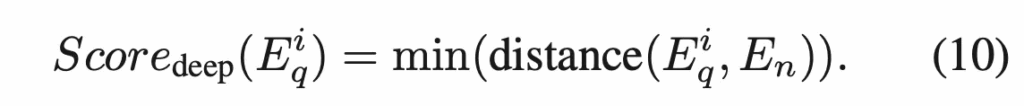
근데, logical anomaly는 feature 거리 뿐만이 아니라 area나 color, position과 같은 geometry 정보도 중요하기에 이에 대한 정보를 추출한 query와 normal geometric feature를 가지고 이 둘의 최소 거리를 계산하여 geometric anomaly score로 정의합니다.
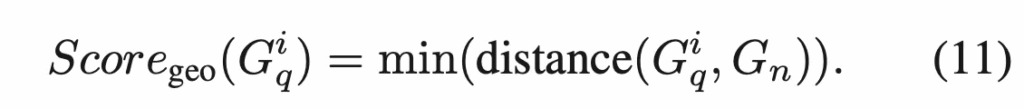
그 다음 이 deep score와 geometry score를 가중합한 것을 logical anomaly score로 사용합니다.
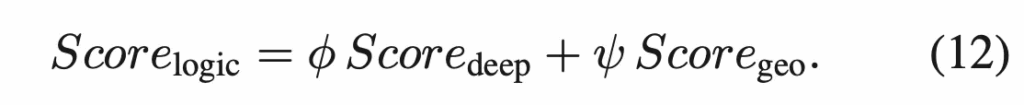
이제 최종적으로 part2에서 얻은 structural anomaly score와 part3에서 얻은 logical anomaly score를 더하여 최종 anomaly score map을 생성하는 식입니다.
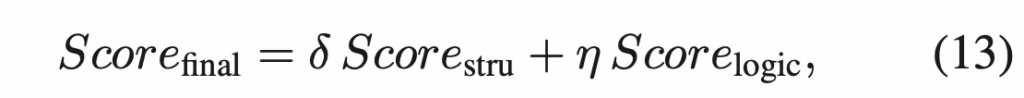
3. Experiments
이제 실험 부분에 대해 살펴보도록 하겠습니다. 실험은 industrial, logical, medical 세 분야에서 총 9개 데이터셋으로 평가했으며, Few-normal-shot과 Few-abnormal-shot setting 두 세팅에서 진행됐습니다. Few-normal-shot이라고 하면 normal data로 학습하지 않고 test할 떄 몇 장의 normal image만 참고하는 setting이라고 보심 되구요. Few-abnormal-shot setting은 주로 medical domain에서 쓰이는 방식인데, normal과 abnormal data 몇 장을 가지고 학습 후에 test하는 세팅입니다.
3.1. Matin Results
Few-normal-shot Setting.
먼저 few-normal-shot setting 결과에 대해 살펴보도록 하겠습니다.
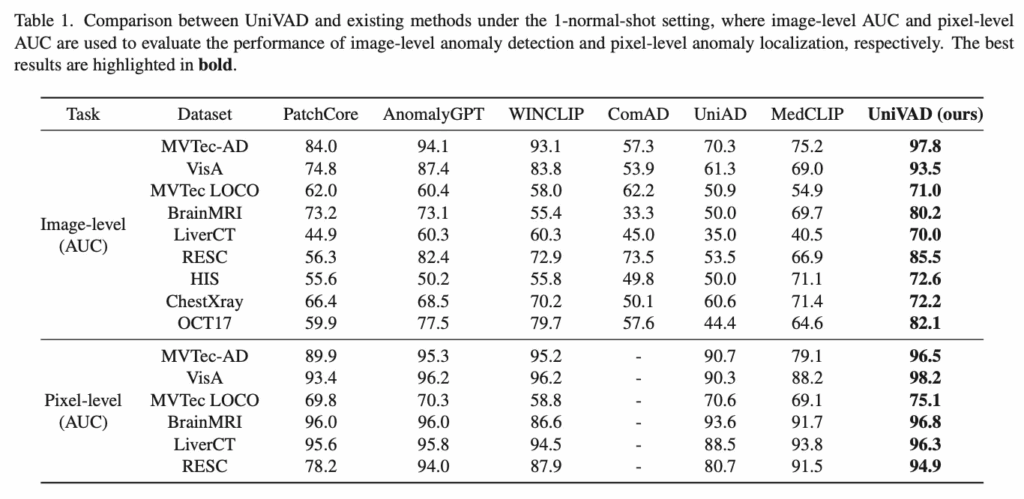
위 Table1에 결과가 나와있는데, 1-normal-shot에서의 실험 결과입니다. 보시면 맨 오른쪽에 있는 UniVAD는 image-level과 pixel-level 모두에서 기존 domain 특화된 방법론들의 성능을 모두 넘어 sota 성능을 달성한 것을 확인할 수 있습니다. 구체적으로 image-level AUC에서 평균 6.2%, pixel-level AUC에서 평균 1.7%의 성능 향상을 보이면서 단순 일부 데이터셋에 한정된 개선이 아니라 전반적으로 도메인 불문하고 일관된 성능 향상을 보여준다고 해석해볼 수 있습니다.
Few-abnormal-shot Setting.
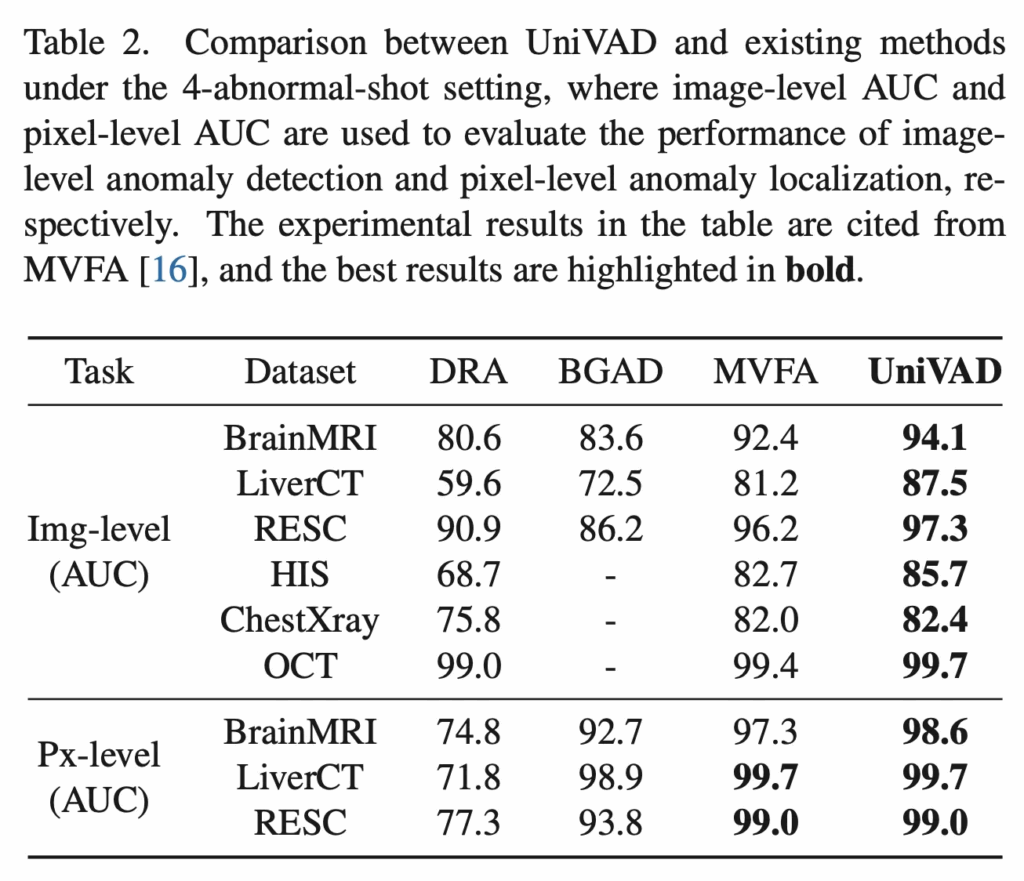
다음으로 Few-abnormal-shot-setting 결과입니다. 총 6개의 medical dataset에서 4-shot 실험 결과를 리포팅했는데, 여기서도 sota를 달성하였습니다.
3.2. Ablation Study
Contextual Component Clustering.
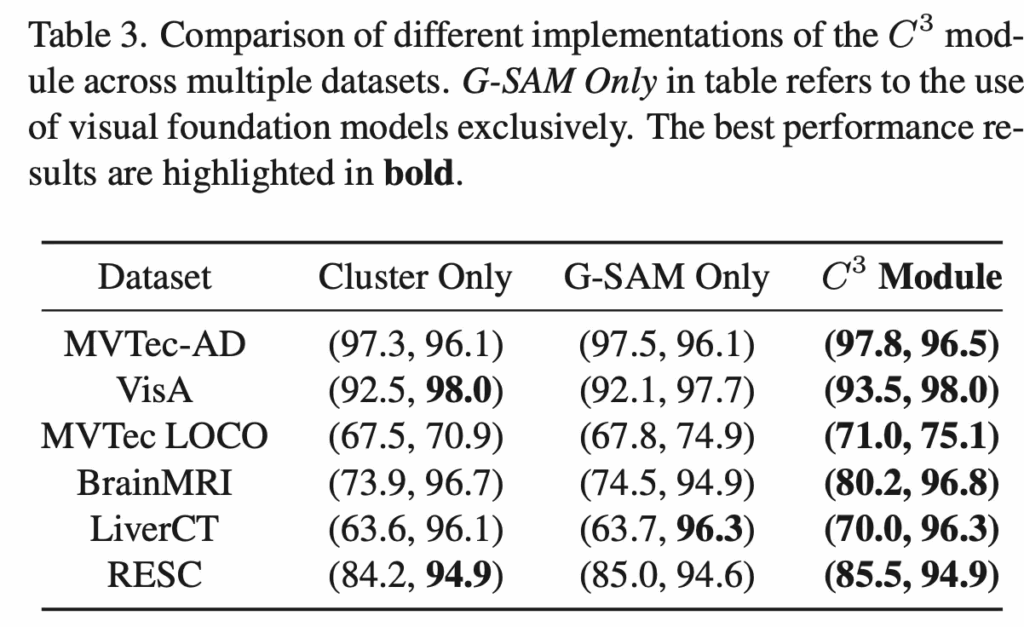
다음으로 ablation study 결과보도록 하겠습니다. 그 중 part1인 C3 모듈에 대한 검증 실험인데요. 이 C3 모듈은 기존 Grounded SAM만 사용했을 경우 너무 디테일하게 segmentation mask가 뽑이기 떄문에 normal과 query image mask를 일관성있게 비교하기 어려운 점을 해결하는 모듈이었죠. 위 Table3을 보시면 Cluster만 사용했을 경우와 Grounded SAM만 사용했을 경우, 그리고 이 둘을 함께 사용한 C3 모듈의 결과를 보이고 있습니다. 결과적으로 이 둘을 함께 사용한 C3 모듈이 모든 데이터셋에서 가장 좋은 성능을 보이며 C3 모듈의 효과를 입증하고 있습니다.
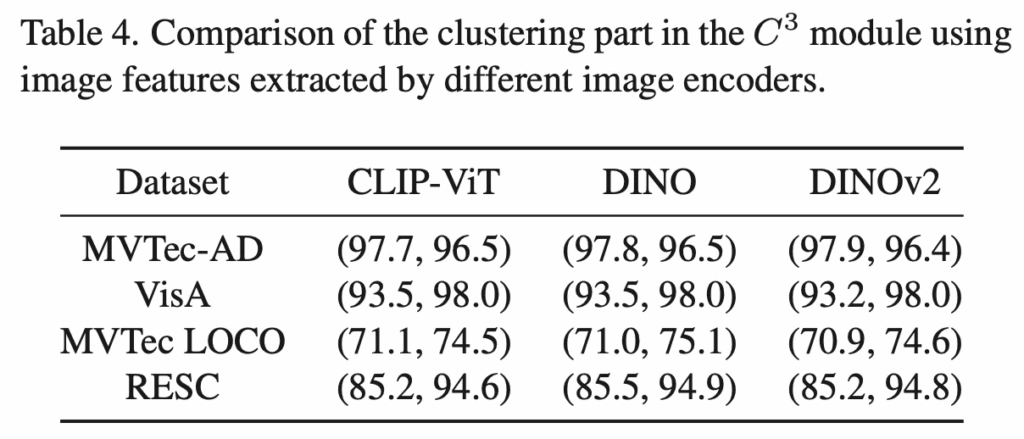
또 위 Table4에서는 clustering 단계에서 사용되는 pre-trained image encoder에 대한 검증 실험인데요. CLIP-ViT와 DINO, DINOv2를 사용하는 세 경우가 있는데 이 셋 image encoder 간의 성능 차이가 거의 없는 것을 확인할 수 있습니다. 이는 곧 C3 모듈이 어떤 encoder를 사용하더라도 안정적으로 강인하게 동작한다는 점을 시사합니다.
Component-Aware Patch Matching.
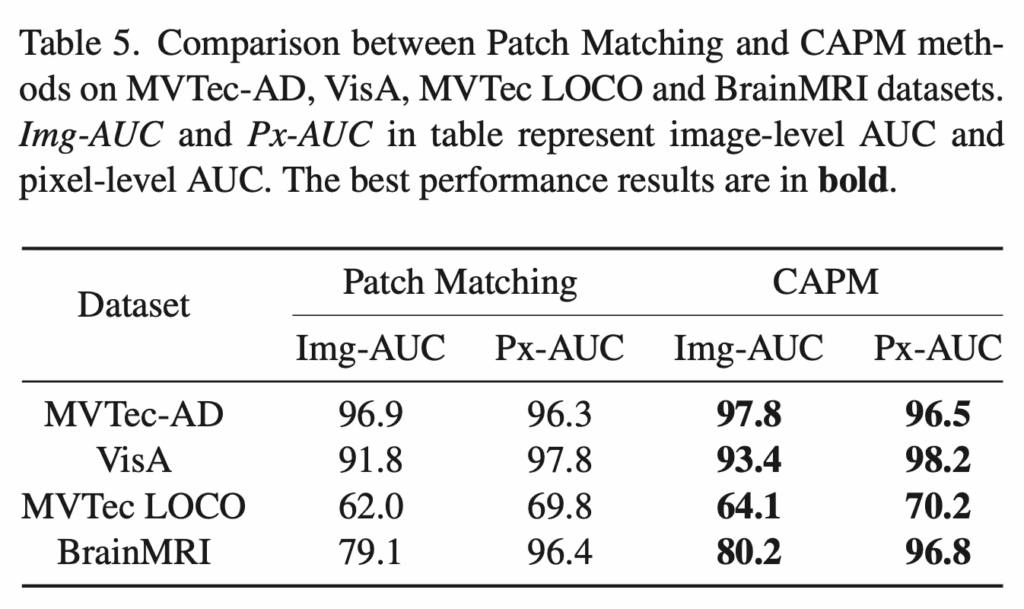
다음은 Part2인 component-aware patch matching에 대한 검증 실험 결과입니다. 기존 patch feature matching 방식은 이미지 전체에서 patch를 추출한 다음 모든 patch끼리 matching을 하게 되는데, 이럴 경우 배경 영역이나 전혀 상관없는 부분의 patch가 비슷한 색이나 texture를 가졌을 때 잘못 매칭되는 경우가 생기게 됩니다. 이 때문에 탐지 성능이 떨어지게 되죠. 반면에 CAPM 모듈은 이런 한계를 보완하고자 C3 모듈에서 얻은 component mask를 기반으로 matching 영역에 제한을 두는 방식이었습니다. Table5를 보시면, 원래 patch matching 방식과 CAPM을 여러 데이터셋에서 비교한 결과 모든 데이터셋에서 structural anomaly를 훨씬 잘 잡아내는 모습을 보입니다.
Graph-Enhanced Component Modeling.
마지막으로 part3 부분인 Graph-Enhanced Component Modeling 부분인데요. 이 부분은 part2의 CAPM 만으로 잡아내기 어려운 logical anomaly를 탐지하기 위해 제안된 부분이었습니다. 왜냠 CAPM에서 사용하는 patch-level feature는 local feature에 가깝기 때문에 어떤 component 전체의 semantic한 feature를 포착하기 어렵기 때문이었는데요. 그래서 GECM은 GNN을 바탕으로 각 component를 graph node로 두고, 그 deep feature와 geometric feature를 함께 고려해 node간의 상호작용을 모델링했었습니다.
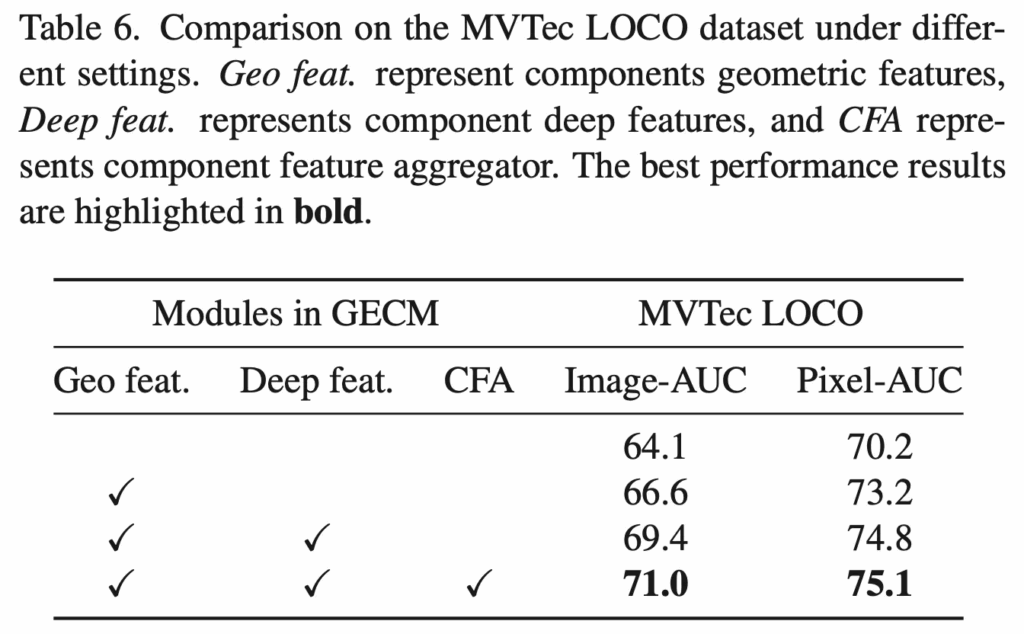
이에 대한 결과를 table6에서 보시면 단순 part2인 CAPM만 썼을 때가 맨 위에 아무 체크 표시 안되어 있는 행에 해당하겠구요. 그 아래에 Gemoetric feature만 썼을 경우 추가로 deep feature를 쓸 경우, component feature aggregation을 함께 할 경우가 있습니다. 보시면 하나씩 더 사용할 경우에 성능이 점진적으로 향상된 것을 보아 GECM이 logical anomaly detection에서 좋은 효과가 있다고 해석해볼 수 있습니다.
3.3. Visualization Results
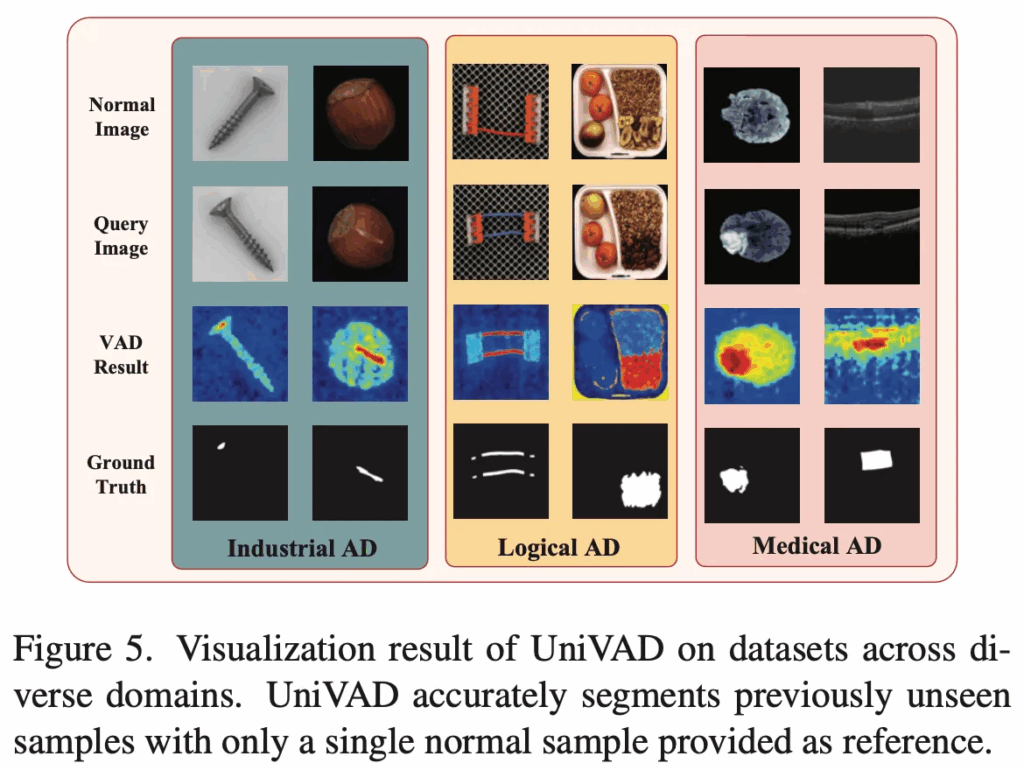
마지막으로 시각화 결과를 보고 마무리하겠습니다. FIg5 예시는 industrial, logical, medical anomaly detection 세 도메인에서 가져온건데, 여기서는 단 하나의 normal sample만 참고하도록 하였습니다. 보시면 본 논문에서 제안된 UniVAD는 이전에 한 번도 본 적 없는 새로운 object의 anomaly를 정확하게 탐지하고 있습니다. 이는 다른 학습이 필요하거나, 하나의 domain, 하나의 object에서만 잘 동작하는 다른 모델들과 비교했을 때 좀 더 application 측면에 잘 맞는 모델이라고 볼 수 있겠네요.
안녕하세요. 리뷰 잘 읽었습니다.
궁금한게 하나 있는데 파트 1 contextual component clustering 과정에서GroundedSAM이 너무 세세하게 다 masking해버리니깐 이를 좀 완화시켜주려고 pretrained image encoder와 k-means clustering으로
merging하는 과정이 있었잖아요. 여기서 Kmeans clustering을 통해서 segmentation을 했다면 K 값은 몇으로 하는게 좋은지 없나요?
K값이 너무 크게 되면 GroundedSAM과 같이 region들이 너무 세세하게 segmentatioin될 것 같고, 그렇다고 너무 작은 값으로 하면 오히려 명확히 분할이 되어야하는 부분이 서로 같은 영역으로 합쳐질 것 같다는 생각이 들어서요.
그림4와 같은 예시가 이상적이긴한데 저 예시만 보면 K값이 4처럼 보이거든요? 근데 입력되는 영상, 그리고 도메인마다 중요하게 봐야하는 영역들의 수가 달라질 것이니 적당하게 세팅 잘 해야할 것 같은데 논문에서 따로 K를 어떻게 설정하는지에 대해서는 언급된 게 없나요?
그리고 이 pretrained encoder에서 K-means로 군집화하는 것이 segmentation을 잘 하는 것이라면 해당 성질을 지연님 연구에 활용해볼 수는 없을지 궁금하긴 하네요.
캄보디아.
안녕하세요 윤서님 좋은 리뷰 감사합니다.
geometric feature도 anomaly score 계산에 반영한다고 하셨는데 이때 사용하는 geometry 정보(area, color, position)가 구체적으로 어떻게 구해지는지가 궁금합니다. encoder feature에서 별도로 추출한 건지 아니면 간단하게 gemometry 정보에 대해서 어떤 수식(평균 등등)으로 geometry 정보를 추출하는지가 궁금합니다.
감사합니다.