안녕하세요. 오늘의 X-Review는 24년도 ACM MM 학회에 게재된 AVQA(Audio-Visual Question Answering) task 방법론 논문입니다. AVQA task와 관련된 내용은 논문과 함께 설명드리겠습니다.
1. Introduction
저는 최근까지 비디오-텍스트 관련 task를 연구하고있었고, 여러 상황을 종합해보았을때 석사과정 남은 1년간은 오디오쪽으로 모달리티 범위를 확장해보기로 결심하였습니다. Audio-Video-Text를 모두 활용하는 task 또한 굉장히 많은데, 그 중 최근 연구가 꽤 활발하면서 제가 오디오를 처음 다룬다는 측면에서 접근하기 좋은 AVQA(Audio-Visual Question Answering) task를 살펴보고자 합니다.
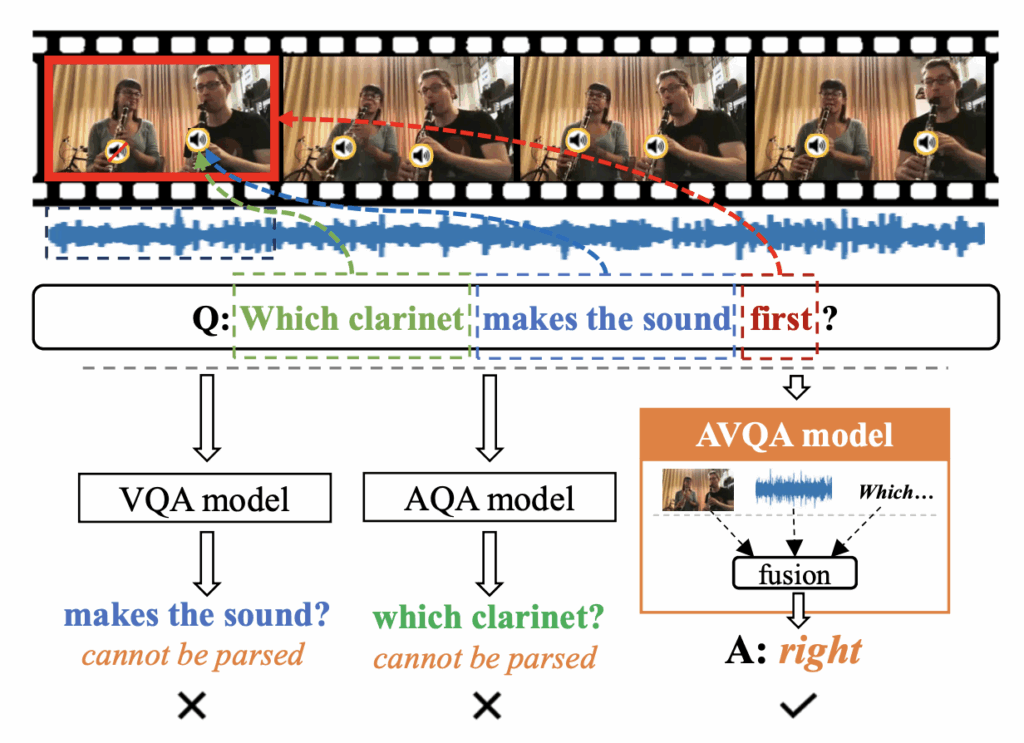
AVQA는 말그대로 텍스트로 구성된 질문에 대해, 비디오에 등장하는 시각적 장면과 오디오를 바탕으로 답변을 하는 task입니다. 위 그림 1을 예시로 보시면, “Which clarinet makes the sound first?”라는 질문에 대해 왼쪽 악기인지 오른쪽 악기인지 답변을 요구하는 상황입니다. 기본적으로 visual, audio, text feature를 중간 과정에서 잘 aggregate하고, 객관식 분류문제를 풀듯 답에 대한 index를 분류해냅니다. 이때 위 예시의 질문에 대한 답 보기를 [‘left’, ‘right’] 중 하나라고 생각했을때 이진분류를 하는 것은 아니고, 이외의 여러 질문에 대한 후보 답변을 모두 포함하여([‘1’, ‘2’, ‘3’, ‘left’, ‘right’, ‘yes’, ‘no’, …]) 총 42개 원소 중 argmax를 최종 예측으로 취하게 됩니다. 물론 데이터셋마다 후보 개수는 다르지만 대표적 데이터셋인 MUSIC-AVQA를 기준으로는 42개입니다.
이 질문에 답하기 위해 시각적 프레임만 봐서는 ‘소리를 내는지’ 자체를 파악하기 어렵고, 반대로 오디오만 들어서는 ‘어느 악기인지’ 파악하기 어렵습니다. 이때 오디오와 이미지 정보, 텍스트 질문을 모두 처리할 수 있는 모델이 있다면 해당 질문에 답변을 할 수 있겠죠. 오늘 소개해드릴 방법론도 3가지 모달리티를 처리하고, 질문에 답변을 잘하기 위해 비디오-오디오 정보와 텍스트 질문의 정보를 잘 조합하기 위해 노력합니다.
저자가 제안하는 모델은 TSPM(Temporal Spatial Perception Model)이라 칭하는데, 기존 연구의 문제점과 함께 이 TSPM이 제안하는 모듈들을 설명드리겠습니다. 기본적으로 AVQA는 비디오 속 질문에 답하기 위한 핵심 구간을 temporal하게 먼저 추리고, 추려진 구간의 프레임들에서 또 답하기 위한 핵심 영역을 spatial하게 추리게 됩니다. 여기서 추린다는 것은 명시적으로 구간이나 영역에 대해 좌표를 뽑는 것은 아니고, QA에 대해 fully-supervised로 학습을 하며 간접적으로 필요한 구간과 영역에 대해 attention을 높이는 방식에 해당합니다.
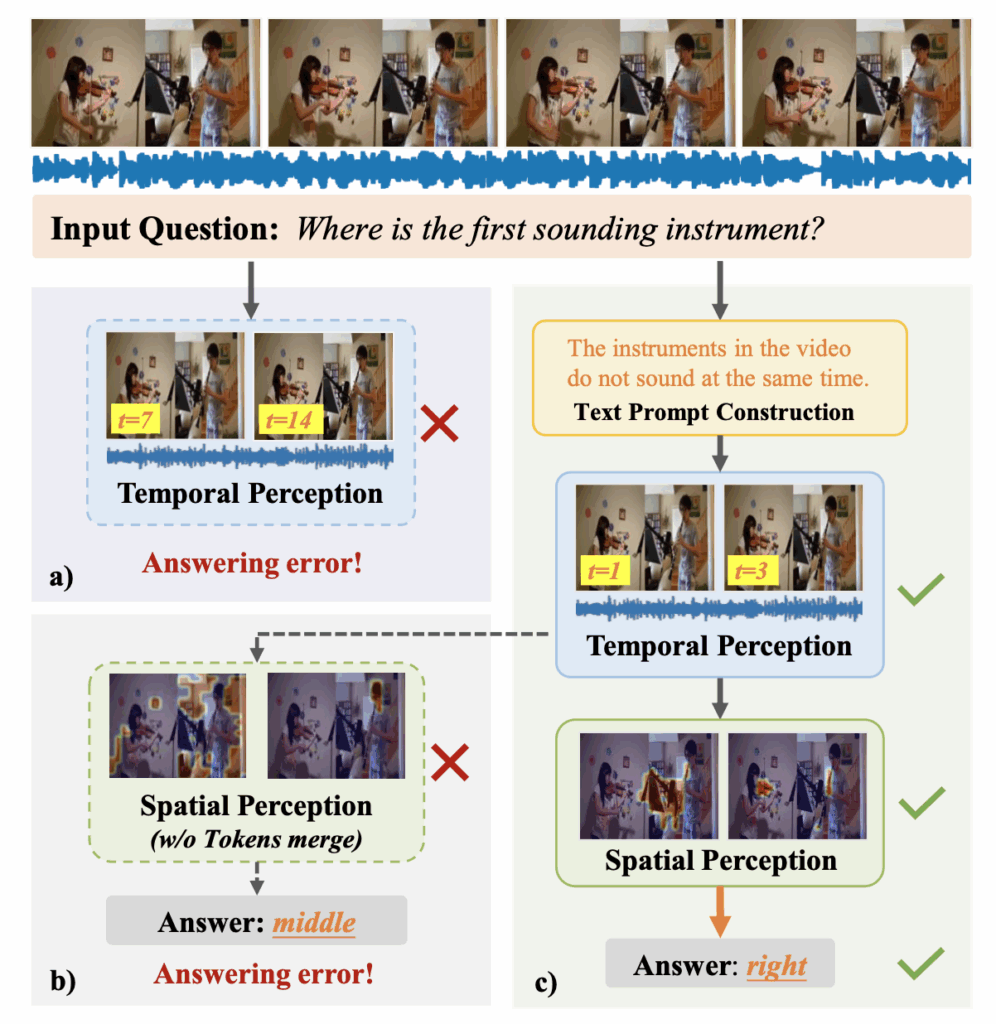
위 그림 2에서 c) 부분이 저자가 제안하는 TSPM의 방법론 흐름입니다. 앞서 말씀드린대로 Temporal Perception 모듈과 Spatial Perception 모듈로 구성되어 있습니다. 그보다 앞엔 Text Prompt Construction 모듈도 존재합니다. 먼저 a)와 c)는 Text Prompt Construction이라는 노란 박스의 유무가 다름을 볼 수 있습니다. 기존 연구와 마찬가지로 TSPM도 CLIP의 텍스트 인코더로부터 질문의 feature를 뽑아 쓰는데, 여기서 Text Prompt Construction 과정은 평서문으로 사전학습된 CLIP이 의문문 형태인 텍스트의 의미를 제대로 파악하기 어렵다는 점에서 착안합니다.
이를 해결하기 위해 Text Prompt Construction 모듈은 의문문 형태의 질문을 manual하게 평서문(declarative)으로 내려 모델이 텍스트 feature와 타 모달 feature의 align을 강화해주는 것입니다. 같은 맥락에서, 기존 연구는 비디오로부터 프레임을 uniform하게 샘플링하며 실제 유의미한 구간과 세부정보를 놓치게 되는데, 위와 같이 모델이 인식하기 쉬운 평서문 형태의 텍스트를 보조적으로 사용함으로써 uniform 샘플링보다 질문에 더욱 적합한 구간을 추려내는 효과도 가져올 수 있게됩니다. 자세한 방법은 뒤에서 다시 정리해보겠습니다.
이후 Temporal Perception 모듈에선 평서문 형태의 텍스트와 오디오, 비디오 feature를 활용해 관심 구간을 먼저 추려내고, 이어지는 Spatial Perception 모듈에선 추려진 구간 프레임에 대해 token merging 기법을 적용해 potential sound-aware area에 집중하도록 만들어줍니다. 마지막으로는 위 과정을 통해 temporal, spatial하게 highlight된 audio, visual, text feature를 aggregate하여 질문에 대한 답을 분류해냅니다. 각 과정별 자세한 내용은 뒤 Method 절에서 말씀드리겠습니다.
Contribution
- The temporal perception module designed in TSPM transforms questions into declarative prompts using a constructed declarative sentence generator.
- The spatial perception module introduced in TSPM merges visual tokens on selected temporal segments to preserve key potential targets.
2. Method
Fine-grained audio-visual scene understanding을 위해, 저자가 제안하는 TSPM 방법론을 세부적으로 살펴보겠습니다.
2.1 Input Representation
오디오가 포함된 T초짜리 비디오가 입력되면, 먼저 1초 단위의 audio-visual segment pair T개(\{a_{t}, v_{t}\}_{t=1}^{T})를 만들어냅니다. 이후 하나의 visual frame은 M개의 패치로 쪼개지고 맨 앞에 \text{[CLS]} 토큰을 붙여 인코더에 태우게됩니다. 동시에 질문 문장 Q는 N개의 단어로 쪼개져 \{q_{n}\}_{n=1}^{N} 형태로 tokenize 됩니다.
Audio Representation
각각의 audio segment a_{t}에 대해, 사전학습된 VGGish 모델로부터 D차원짜리 feature f_{a}^{t} \in{} \mathbb{R}^{D}를 추출합니다. VGGish는 VGG와 유사한 2D CNN 네트워크이고, 대규모 오디오 데이터셋인 AudioSet을 활용해 사전학습된 모델입니다. 오디오를 spectrogram 형태로 바꿔 2D 형태로 변환하고 이를 이미지 같이 취급하는 것입니다. 이렇게 추출한 audio feature를 F_{a} = \{f_{a}^{1}, f_{a}^{2}, \cdots{}, f_{a}^{T} \}라 둡니다.
Visual Representation
프레임 segment v_{t}에 대해, 사전학습된 CLIP으로부터 feature를 뽑아냅니다. 이때 frame-level token f_{v}^{t} \in{} \mathbb{R}^{D}와 token-level feature f_{p}^{t} \in{} \mathbb{R}^{M \times{} D}를 추출하는데, 여기서 M은 한 프레임 내 패치 개수입니다. Visual frame-level token과 token-level feature는 각각 F_{v} = \{f_{v}^{1}, f_{v}^{2}, \cdots{}, f_{v}^{T} \}, F_{p} = \{f_{p}^{1}, f_{p}^{2}, \cdots{}, f_{p}^{T} \}가 됩니다.
Text Representation
질문 Q를 입력받아서, 토큰화된 각 단어 q_{n}은 CLIP 텍스트 인코더에 입력되어 문장 feature F_{Q} \in{} \mathbb{R}^{D} (EOS 토큰)을 추출합니다.
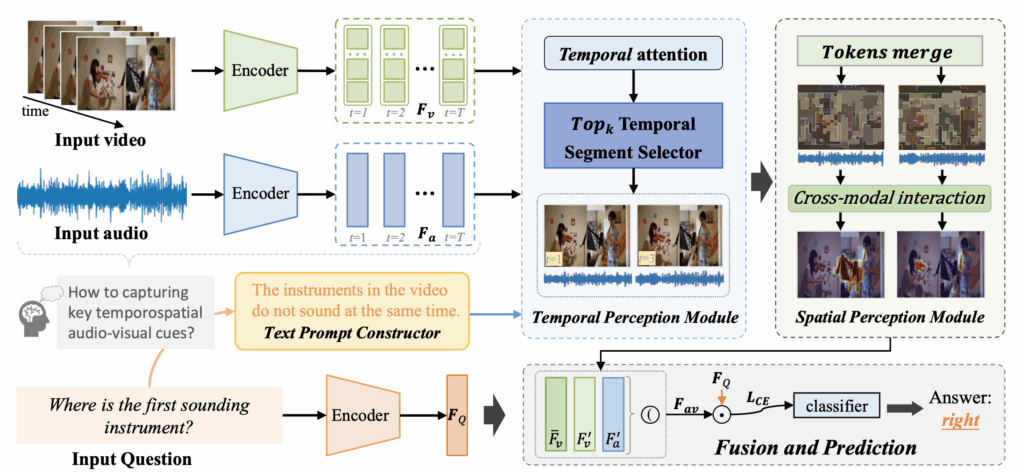
2.2 Temporal Perception Module
위 그림 3은 제안하는 TSPM의 전체 프레임워크를 나타내고있고, 파란색으로 표시되어있는 Temporal Perception Module (TPM)에 대해 본격적으로 말씀드리겠습니다. 기존 연구에서는 답변을 위한 비디오/오디오의 key segment를 뽑기 위해 의문문 형태의 문장과 visual feature 간 유사도를 활용했는데, 이 과정에서 사전학습 모델의 표현력을 더욱 잘 활용하기 위해 평서문을 뽑아내는 과정을 거칩니다.
이 평서문을 뽑는 모듈이 Text Prompt Constructor (TPC)이고, 아래 3가지 절차를 거칩니다.
- Construction Guidelines
- 주어진 질문에 대한 답을 알 수 없기때문에, 평서문으로 직접 바꾸기엔 어려움이 있습니다. 따라서 관련없는 segment를 배제할 수 있는 평서문을 manual하게 만들어줍니다.
- Construction Process
- 데이터셋에는 질문 template이 몇가지 정해져있는데, 이 template을 활용해 평서문을 만들어줍니다. 이 과정은 여러 contributor가 모여 협의를 통해 결정되었다고 합니다.
- Construction Results
- 그림 2에서 볼 수 있듯, “Where is the first sounding instruments?”라는 질문이 들어왔다고하면, 우선 모델은 ‘첫 악기’가 연주되는 시점에 집중해야합니다. 이 말은 즉 모델이 집중해야하는 구간에선 몇 개의 악기든 동시에 연주되지 않는 구간이 있다는 이야기입니다. 따라서 “The instruments in the video do not sound at the same time.”이라는 평서문을 위 질문에 같이 만들어주는 것입니다. 이 평서문을 TPrompt라고 칭합니다. 물론 비디오에서 여러 악기가 동시에 연주되는 구간이 존재할 수도 있지만, 적어도 모델이 올바르게 답변하기 위해 집중해야하는 구간에선 악기들이 동시에 연주되고 있지 않는다는 점을 활용하는 것입니다. 위와 같은 방식으로 여러개의 template 각각에 대한 평서문을 manual하게 생성해냅니다.
개인적으로는 어차피 학습이 Fully-supervised로 이루어지기 때문에, 위 과정에서 만약 처음으로 연주되는 악기가 ‘clarinet’이라면 평서문을 ‘Clarinet is the first sounding instruments.’로 두어도 되지않을까 싶었는데, 이 TPrompt는 학습때 뿐만 아니라 평가때도 사용되기에 실제 GT는 쓰지 않는 것으로 보입니다.
아무튼 이렇게 만들어낸 TPrompt에 대해서도 질문과 똑같은 과정을 거쳐 feature F_{TPrompt}를 만들어줍니다. 이후 visual feature F_{v}를 linear layer에 태워 \textbf{k}를 만들어주고, 아래 수식 (1)과 같이 attention score W를 뽑습니다.
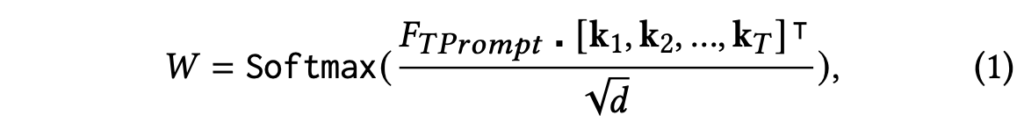
이후 위 W를 기준으로 비디오와 오디오에서 Top_{k}개 segment를 추출합니다. 이 추출 과정을 저자는 \Psi{}라 칭하고 아래 수식 (2)와 같이 표현합니다.
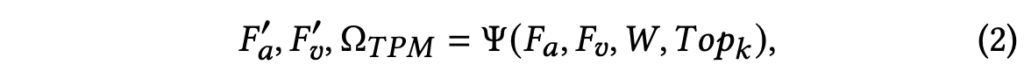
여기서 F'_{a} \in{} \mathbb{R}^{Top_{k} \times{} D}, F'_{v} \in{} \mathbb{R}^{Top_{k} \times{} D}가 전체 segment 중 W 기준 유사도 상위 Top_{k}개의 오디오, 비디오 segment인 것입니다. 여기서 \Omega{}_{TPM}은 Top_{k}개의 인덱스를 의미합니다.
2.3 Spatial Perception Module
이어 등장하는 SPM은 앞서 TPM에서 추려진 segment 구간에 대해, spatial 축에서의 highlighting을 담당합니다. 앞선 그림 1에서의 예시처럼 오른쪽 클라리넷이 소리를 먼저 냄을 인식하기 위해, 질문을 받았을때 오디오와 프레임을 파악해 오른쪽 클라리넷에 attention이 몰리도록 만들어주는 역할을 하는것이죠.
그러나 실제로는 프레임의 어떤 영역이 ‘오른쪽 클라리넷’인지에 대한 라벨 정보는 없습니다. 그럼에도 최대한 정답을 맞추는데에 도움이 되는 영역에 집중하도록 만들기 위해, 저자는 visual token merging 기법을 도입합니다. TPM에선 프레임 수준의 visual feature F_{v}([CLS] 토큰)만을 다뤘다면, 여기선 패치 수준의 feature인 F_{p}를 활용합니다. 우선 연산은 아래 수식 (3)과 같습니다.
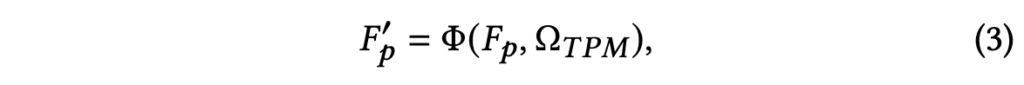
수식 (3)에서 얻어지는 F'_{p} \in{} \mathbb{R}^{Top_{k} \times{} M \times{} D}는 앞서 수식 (2)에서 뽑은 Top_{k} 인덱스 \Omega{}_{TPM}을 기준으로 추린 프레임의 token-level feature를 의미합니다. 아직 추가 연산이 들어간건 아니고 유사도가 높은 feature만 인덱싱 한것이죠.
이후엔 기존 연구 ToMe를 따라 F'_{p}에 token merging을 적용해줍니다. 이 token merging 과정은 SPM 내 모든 블록에서 attention과 MLP 브랜치 사이에 들어가게됩니다. 이 merge 과정을 저자는 아래 수식 (4)와 같이 표현합니다.

여기서 얻은 merged visual token-level feature \hat{F}_{p} = \{\hat{f}_{p}^{1}, \hat{f}_{p}^{2}, \cdots{}, \hat{f}_{p}^{\lambda{}} \} \in{} \mathbb{R}^{\lambda{} \times{} S \times{} D}입니다. 수식에서 \lambda{}는 선택받은 temporal segment의 개수, S는 merge된 visual token 개수라고 하는데, ToMe 과정을 거치면서 한 프레임 내 토큰만 merge되는 것이 아니라 temporal 축에서도 \lambda{}개로 merge 되는것으로 이해해볼 수 있습니다. 이 merge 과정을 조금 더 자세히 설명드리겠습니다.
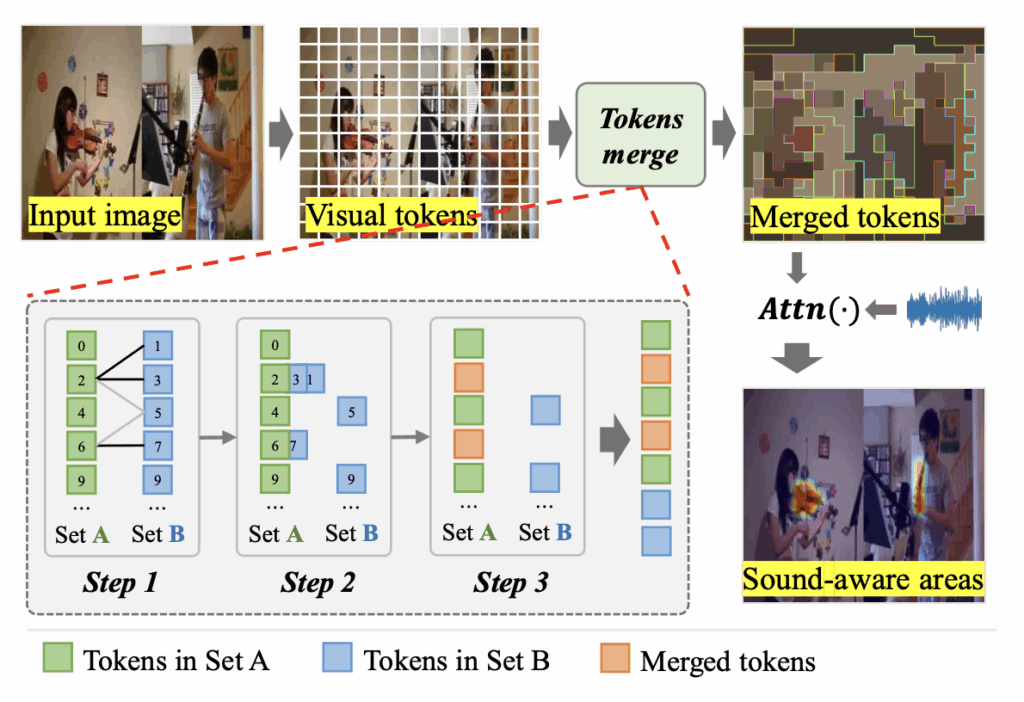
Merge 과정은 위 그림 4에 총 3개의 step으로 나타나있습니다.
- Step 1: M개 토큰을 짝수 인덱스, 홀수 인덱스로 균등하게 나눠 두 subset A, B를 만들어냅니다. 그리고 Set A에 있는 모든 토큰 각각에 대해, B의 모든 토큰과 유사도를 하나씩 계산해줍니다.
- Step 2: 이 유사도를 바탕으로 유사한 토큰끼리는 평균을 내어 합쳐줍니다.
- Step 3: 두 subset A, B를 concat하여 merged visual token-level feature \hat{F}_{p}를 만들어줍니다.
여기까지 진행했을때 \hat{F}_{p}는 merge 이전인 F'_{p}보다 복잡한 장면에 대해 핵심 요소만 추려진 token representation만을 갖게 된다고 볼 수 있습니다. 뒷단 audio와의 interaction 과정을 거치며 벽과 같은 배경 영역은 압축 과정에서 영향력이 줄어들고, 질문에 답하기 위해 필요한 핵심 영역은 강조되며 살아남게 된다는 방향성을 가지고 있습니다.
이제 뒷단의 multi-modal interaction 과정에 대해 아래 수식 (5)와 함께 설명드리겠습니다.
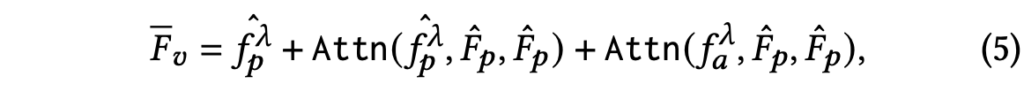
수식 (5)에서 \mathrm{Attn}(\cdot{})은 일반적인 scaled dot-product 연산을 의미하고, 앞서 수식 (4)에서 추출한 merged token-level visual feature \hat{F}_{p}에 두 가지 Attn 결과를 residual하게 더해주는 형식입니다. 뒤에있는 두 가지 Attn 연산에서 K, V는 모두 \hat{F}_{p}이고, 결국 Q를 visual로 한번, audio로 한번 두고 이들간의 유사도를 기반으로 얻은 결과를 더해주는 것입니다.
수식 (5)에서 얻은 \bar{F}_{v} = \mathbb{R}^{Top_{k} \times{} S \times{} D}이고, 논문에 쓰인 바에 따르면 유사도 기준 Top_{k}와 merge 후 프레임 개수 \lambda{}가 계속 혼용되고있습니다. 정확한 값은 코드를 확인해보아야할 것 같습니다.
결과적으로 수식 (5)까지 진행하여 얻은 feature는 학습을 거치며 입력 질문과 가장 유사한 potential sound-aware 영역을 강조하도록 만들어진다는 것이 저자의 설계 의도입니다. 추가적으로 수식 (5)와 같이 residual한 연산 설계에 딱히 큰 의도는 드러나있지 않고, SDPA를 활용할 수 있는 전형적인 구조를 채택한 것으로 보입니다.
2.4 Multimodal Fusion and Answer Prediction
앞서 TPC, TPM, SPM 절차를 모두 거치며 여러 visual, audio feature를 추출하였고, 이제는 그 feature들을 활용해 최종 정답을 분류 예측하면 되는 단계입니다.
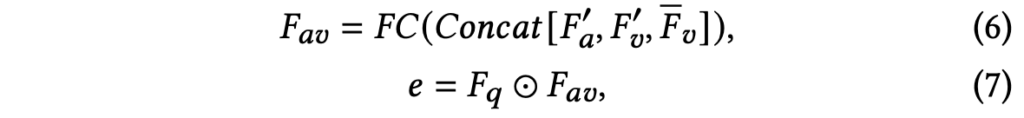
수식 (6)에서 concat되는 feature들 중 F'_{a}, F'_{v}는 TPM에서 얻었고, 각각은 평서문 TPrompt와 가장 유사한 audio, visual feature들입니다. 다음으로 \bar{F}_{v}는 SPM의 수식 (5)에서 얻었으며 token merging 후 다른 모달리티와의 유사도가 고려된 visual feature에 해당하였습니다. 이 feature들을 concat하여 FC layer에 태우고 F_{av}를 얻는것입니다.
수식 (7)에서는 질문 텍스트의 feature F_{q}와 F_{av} 간 element-wise multiplication을 수행합니다. 마지막으로는 사전 정의된 후보 정답 개수인 C차원으로 projection을 하여 CE Loss로 분류 학습을 하거나 argmax로 최종 예측을 합니다.
3. Experiments
3.1 Datasets
벤치마크를 진행하는 두가지 데이터셋 MUSIC-AVQA와 AVQA에 대해 정리하고 넘어가겠습니다.
MUSIC-AVQA
MUSIC-AVQA는 유튜브 등등에서 사람들이 악기를 연주하는 9,288개 비디오로 이루어져있고, 총 22개의 악기가 등장합니다. 비디오 총 시간은 150시간 정도의 규모이며 각 비디오는 60초 길이로 고정되어있고 45,867개의 QA 쌍을 가지고있습니다. 다섯 종류(existential, counting, location, comparative, temporal)의 질문에 대해 총 33개의 질문 template이 존재합니다. 22년도에 제안된 데이터셋인데, 서베이 결과 최근 방법론들까지 가장 활발히 벤치마크하는 것으로 확인하였습니다.
AVQA
MUSIC-AVQA보다 조금 더 큰 규모의 데이터셋입니다. 음악 동영상만 다루는 것이 아닌 일상 도메인 비디오들로 구성이 되어있으며, 총 57,015개 비디오, 57,355개의 QA 쌍이 존재합니다.
3.2 Quantitative Results and Analysis
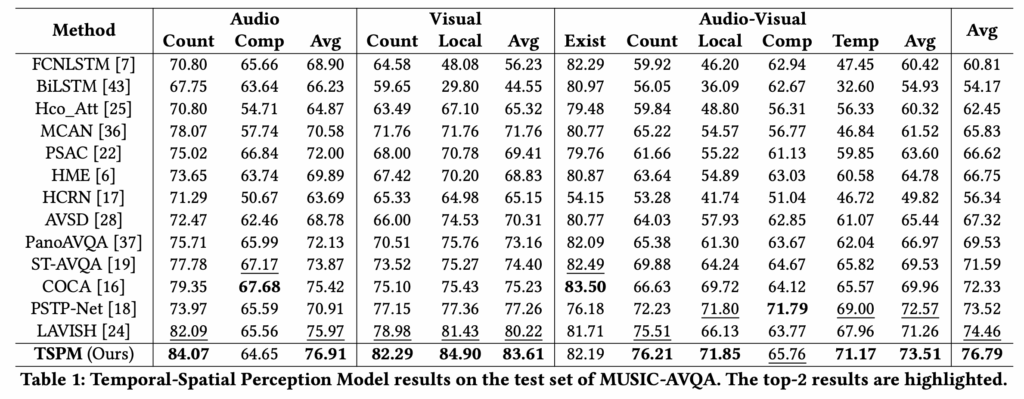
표 1은 MUSIC-AVQA 데이터셋에 대한 벤치마크 성능을 보여주고 있습니다. 평가지표는 분류이기 때문에 accuracy입니다. 표에서 Audio/Visual/Audio-Visual은 질문에 답하기 위해 입력된 모달리티를 의미합니다. 예를 들어 “이 동영상엔 몇 개의 악기가 등장하나요?”라는 질문은 시각 정보 없이 오디오만 듣고도 답변을 할 수 있어 이런 질문에 대한 정확도를 측정한 것입니다.
전반적으로 평균 성능이 기존 SOTA인 LAVISH에 비해 2% 이상 향상하였으며, 특히 Visual 입력만 받아 평가했을때 기존 최근 방법론인 PSTP-Net이나 LAVISH 대비 성능 향상폭이 꽤 큰 것을 볼 수 있습니다. 오디오를 고려하지 않고 visual 입력만 줬을때 핵심적인 역할을 하는 부분이 결국 TPM이었습니다. 이때 평서문을 만들어 CLIP text encoder가 상황을 더욱 효과적으로 인식하도록 만들어준 것이 저자의 의도대로 유의미했다고 생각해볼 수 있겠네요.
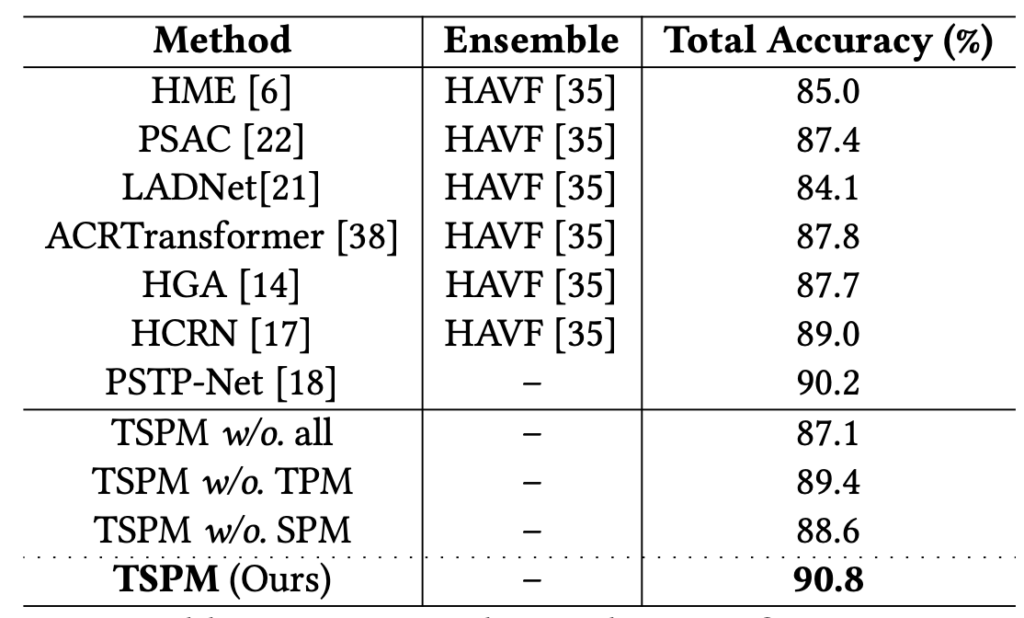
위 표 2는 AVQA 데이터셋에 대한 벤치마크 성능을 보여주고있는데, 확실히 MUSIC-AVQA보다 비교군이 적은 것을 볼 수 있습니다. 역시 여기서도 가장 높은 성능을 달성하고있고, 주류로 다뤄지는 데이터셋은 아닌 것으로 보입니다. MUSIC-AVQA에 비해 TSPM이 기존 방법론 대비 보여주는 성능 향상폭이 적습니다.(90.2->90.8) 저자는 이에 대해 아마 AVQA가 10초 정도 되는 비디오라, 이미 방법론들의 성능이 어느정도 saturate된 것이라고 주장하고있습니다.
3.3 Ablation Studies
TSPM에는 제안된 모듈들이 꽤 많아 ablation을 통해 각 모듈의 역할을 살펴보는 것이 중요할 것 같습니다. 아래 표 3은 다시 MUSIC-AVQA에서의 모듈별 ablation 성능을 보여줍니다.
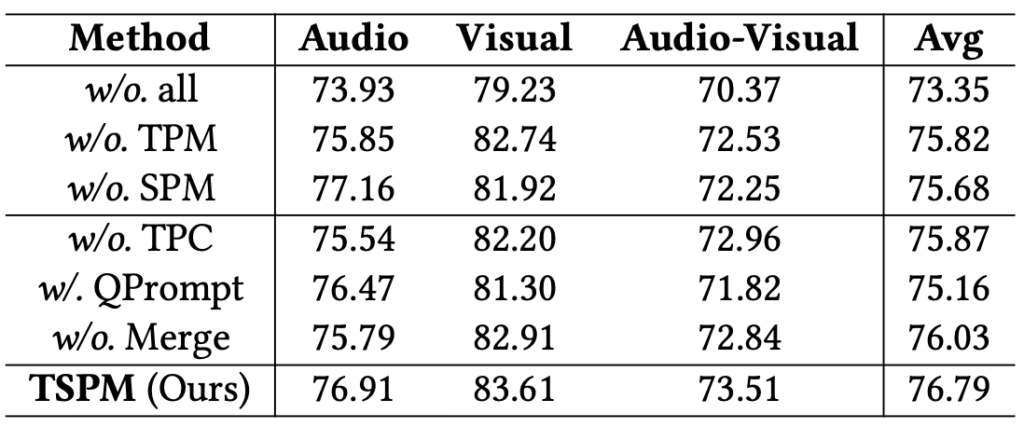
- w/o. all: TSPM에 존재하는 모든 모듈과 component를 제거하고, 간단한 멀티모달 interaction만 넣었을 때의 성능입니다. 73.35로 크게 떨어지는 것을 볼 수 있습니다.
- w/o. TPM: TPM은 기존 방법론처럼 프레임을 uniform하게 sampling하는 대신 평서문과의 유사도를 기준으로 주요 segment를 추리는 모듈이었습니다. 이를 제거했을때 성능이 TSPM 대비 1%가량 떨어지는데, 저자는 이 1%를 noticeable하다고 이야기합니다. 평서문과의 유사도를 기반으로 segment를 추리는게 답변에도 큰 영향을 줬음을 알 수 있습니다.
- w/o. SPM: SPM은 visual token merging을 통해 sound-aware한 영역을 추리는 것이 목적이었습니다. SPM을 제거했을때 TSPM 대비 1.1%가 떨어지며 TPM의 부재보다도 더 큰 하락폭을 보여줍니다. 아무래도 token merging을 비롯해 들어갔던 수식 (5)에서의 multi-modal interaction이 성능 향상에 주요 역할을 했던 것 같습니다.
- w/o. TPC: 문장과의 유사도를 기반으로 추리지 않고 모든 비디오 프레임을 다 썼을때, redundancy로 인해 성능이 떨어지는 것을 볼 수 있습니다. 입력 프레임이 많으면 비효율적이나 성능은 당연히 좋을줄 알았는데, 그렇지 않다는 점에서 이 AVQA task만의 특성이 느껴지는 것 같습니다.
- w/o QPrompt: 아마 본문에서의 TPrompt를 잘못 적은 것 같은데, 저자가 manual하게 정한 평서문 대신 입력 질문을 그대로 유사도 계산에 사용하는 방식이고, 여기서 성능이 가장 크게 떨어지는 것으로 보아 실제로 CLIP 텍스트 인코더와 의문문은 안맞는다는 점이 증명되었습니다. 후에 참고할만한 중요사항인 것 같습니다.
- w/o Tokens merge: 이 실험을 통해서도 저자가 적용한 token merging 방식이 유효했고, 불필요한 배경은 잘 지우며 필요 영역은 잘 강조했다는 것을 정량적으로 알 수 있습니다. 그러나 정성적으로 어떻게 token들이 merge 되었는지 보는 것이 또 다른 하나의 연구 방향성으로 잡힐 수 있겠네요. 아무래도 지금은 rule-based로 merge되고있어서 이걸 dynamic하게 바꿔봐도 좋을 것 같습니다.
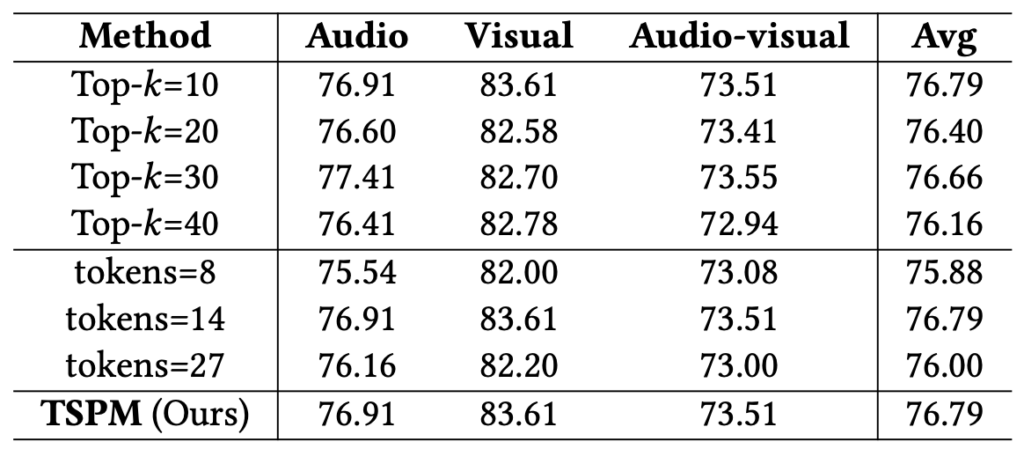
위 표 4는 segment에서 추출하는 Top_{k} 개수와 token merging 시 남기는 토큰의 개수 tokens에 대한 ablation 성능입니다. 최종적으로 Top_{k}=10, tokens=14가 가장 좋은 성능을 보여줬다고 합니다.
3.4 Computational Costs
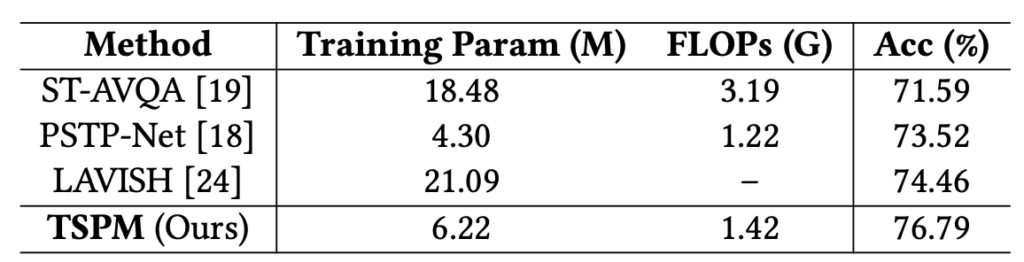
마지막으로 연산량에 대한 정량적 값들을 보고 리뷰를 마치겠습니다. 저자가 제안하는 TSPM의 연산량은 딱 PSTP-Net과 LAVISH라는 최근 방법론들 사이라고 볼 수 있는데, 성능에선 압도적으로 높은 수치를 달성하고 있습니다. 특히 LAVISH는 거대 사전학습 모델을 fine-tuning해서 쓰다보니 연산량 측면에서 비효율적이라고합니다. 아무튼 효율과 효과를 다 잡은 괜찮은 방법론임을 강조합니다.
4. Conclusion
AVQA라는 task를 연구하기로 하고, 위 TSPM을 베이스라인으로 삼고자 원복을 해보았습니다. 공개된 코드가 온전치 않아 논문을 꼼꼼히 읽어가며 반쪽짜리 코드를 많이 고쳐 결국 1% 정도의 차이로 원복을 해두었는데, 코드를 보다보니 논문과 코드가 다른 부분이 꽤 많아 당황스러웠습니다. 아무튼 베이스라인으로 잡을만하도록, 성능도 준수하고 방법론도 간단한 논문인 것 같습니다. 또 리뷰를 적고자 꼼꼼히 다시 읽다보니 분석해볼만한 건들이 보여서, 천천히 진행해보면 좋을 것 같습니다. 이상으로 리뷰 마치겠습니다.
리뷰 잘 읽었습니다. 몇 가지 질문 남겨두겠습니다.
Q1. 제가 최근에 읽은 2019년 논문에서도 audio feature 추출하는데 VGGish 를 사용했던 것 같은데… audio feature를 추출하는데 저 방식이 최선인가요…?
Q2. TPC에서 의문문을 평서문으로 manual하게 바꾸는 방식이 CLIP text encoder의 한계를 보완한다고 주장했는데, 다른 AVQA 데이터셋이나 자유도 높은 질문에서도 여전히 유효했는지 확인한 결과가 있는지 궁금하네요
Q3. 실험이 사실상 MUSIC-AVQA 중심으로 이뤄진거 같고, AVQA에서는 성능 향상 폭이 미미한거 같습니다. 해당 태스크에서는 보통 이렇게 두 가지 벤치마크만 보이나요? 일단 성능 자체로 봤을 때는 다른 멀티모달 QA 데이터셋에서도 동일한 개선을 보일지 궁금해지네요
안녕하세요 질문 감사합니다.
1. 찾아보니 VGGish는 2017년에 나왔는데, 제가 본 오디오 단일모달리티의 특징을 추출하는 방법론들도 VGGish를 거의 대부분 사용했던 것 같습니다. 최근에는 텍스트와의 상관관계를 고려한 CLAP이나 오디오를 텍스트로 내릴 수 있는 Whisper와 같은 강력한 모델들이 있어 오디오를 텍스트로 내려서 쓰는 방식도 좋을 것 같습니다. (물론 MUSIC-AVQA같이 음악만 나오는 동영상에선 발화가 없어서 못쓸듯 합니다.)
2. 일단 벤치마크는 제가 리뷰에 언급한 두 가지 데이터셋이 전부였습니다. 그런데 최근 등장한 AVQA 방법론 QA-TIGER의 프로젝트 페이지(https://aim-skku.github.io/QA-TIGER/)를 보니 TSPM이 MUSIC-AVQA-R에서도 굉장히 뛰어난 성능임을 확인할 수 있었습니다. MUSIC-AVQA-R의 R은 Robustness를 의미하여 기존보다 더욱 다양하고 복잡한 질문을 포함하고있는데, 거기에서도 좋은 성능을 보였다는 것은 주영님이 질문하신 내용에 대해 여전히 유효했다고 볼 수 있을 것 같습니다.
3. 우선 AVQA는 한 비디오당 길이가 10초라 성능 향상폭이 미미하다고 저자가 언급하고 있습니다. 아마 난이도가 쉽다보니 복잡한 TSPM의 효과를 제대로 못봤다라는 의미인 것 같습니다. 앞서 말씀드린대로, 더욱 신뢰할만한 연구인 QA-TIGER(CVPR 2025 Highlight) 논문도 MUSIC-AVQA류의 데이터셋만 벤치마킹 하고있는 상황입니다.
안녕하세요 리뷰 잘 봤습니다.
한가지 궁금한 점이 있는데 해당 방법론도 Tome?라고하는 기존 연구의 방식을 따라 visual token을 merge한다고 하셨는데 저자들의 merge 방법론은 ToMe 방법론과 어떤 차이가 있을까요?
그리고 merge 하는 방법론에서 짝수 index와 홀수 index로 나눈다고 해서 저는 merge 후 최종 결과물이 기존 전체 token 수의 절반에 해당하는 개수가 남는다고 생각했는데 ablation study를 보면 token merge 이후 남는 토큰의 수를 조정할 수 있는 것처럼 보여서요. 이 말은 짝수 index와 홀수 index로 나눈 다음에 다시 임의로 또 n개의 토큰만을 샘플링해서 merge한다는 뜻인가요?
감사합니다.
정민님 안녕하세요. 질문 감사합니다.
1. 코드를 확인해보니 처음부터 ToMe라는 연구에서 제안한 백본 네트워크를 가져와 원하는 개수만큼 패치를 병합한 뒤 기타 temporal pooling 등이 시작됩니다. 따라서 방법론 측면에서는 기존 ToMe와 다를 것이 없습니다. 다만 찾아보니 ToMe는 token merging을 통해 이미지 분류 성능을 조금 잃는 대신 효율성을 올렸음을 주장하고 있었는데, 본 논문에서는 효율성과 성능이 함께 오름을 보인게 차이점인 것 같습니다.
2. 말씀주신대로 최초에는 두 set으로 나누는 것이 맞습니다. 다만 논문에서 유사도를 기준으로 병합한다고는 하지만 기준이 없어도 계속 병합은 가능합니다. 즉 원하는 횟수만큼 병합을 반복할 수 있는 것입니다.
예를 들어 수백개의 이미지 패치 중 14개만 남기고 싶다면, 대충 절반으로 나눈 뒤 병합을 한 사이클(한 set이 모두 다른 set으로 병합될때까지) 진행합니다. 병합 한 사이클이 끝나면 대략 절반만 남게될 것이고, 다시 두 세트로 나누어 정확히 14개가 남을때까지 계속 병합을 진행하는 것입니다.