오랜만에 Video-Text Retrieval 태스크에 대해 리뷰해보겠습니다. 성능을 급격하게 상승시킨 논문이라서 리뷰하게 되었습니다. 바로 시작해보겠습니다.

- Conference: NAACL 2025
- Authors: Yimu Wang, Shuai Yuan, Bo Xue, Xiangru Jian, Wei Pang, Mushi Wang, Ning Yu
- Affiliation: University of Waterloo, Duke University, City University of Hong Kong, Netflix Eyeline Studios
- Title: DREAM: Improving Video-Text Retrieval Through Relevance-Based Augmentation Using Large Foundation Models
1. Introduction
최근 비디오-텍스트 검색(Video-Text Retrieval, VTR) 성능 향상은 CLIIP이라는 강력한 사전학습 모델의 등장 그리고 대규모 비디오-언어 벤치마크 데이터셋의 구축 덕분에 가능해졌습니다. 그 시작으로 CLIP4Clip이 CLIP을 Fine-tuning하여 비디오와 문장 간 Contrastive를 수행하였고, 다음으로 X-CLIP에선 다양한 해상도에 대한 Contrastive Learning 구조를 통해 모달 사이의 연관성을 강화하기도 했죠.
하지만, 저자가 집중한 점은 이런 모델 구조나 학습 기법이 아닌 바로 데이터의 품질 문제였습니다. 대부분의 VTR 학습 데이터셋은 비디오와 텍스트가 1:1로 잘 매칭된다고 가정하지만, 실제로는 한 비디오가 여러 다른 문장과 의미상 맞을 수 있고, 하나의 문장도 다양한 비디오와 호환될 수 있습니다. 예를 들어, 농구 경기 장면을 설명하는 문장이 “젊은 사람들이 농구 경기를 하는 장면”일 수 있지만, “한 남자가 농구공을 던져 넣는 장면”이나 “농구 선수와 유명인을 소개하는 뉴스”처럼 의미적으로 유사한 다른 설명들도 모두 가능하죠. 이러한 애매한 매칭은 학습된 표현의 정확도를 떨어뜨립니다.
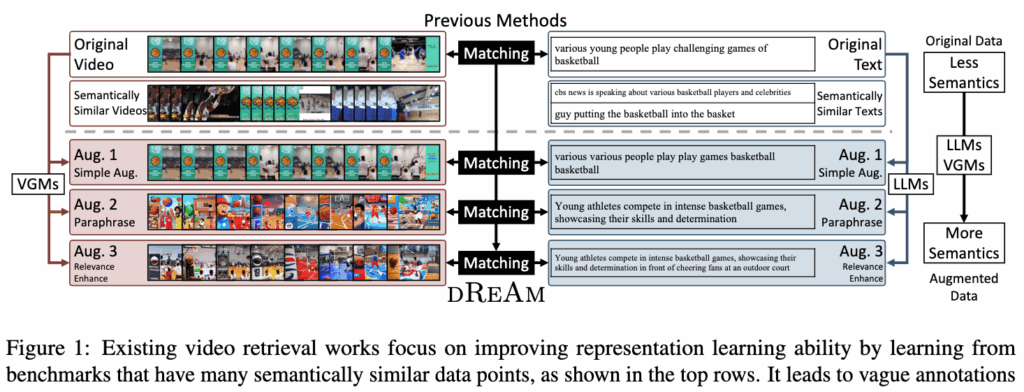
상단 그림 1이 바로 저자가 집중하는 문제를 보여줍니다. 원본 데이터에는 하나의 비디오·텍스트 쌍이 있지만, 주변에는 의미적으로 매우 비슷한 다른 비디오·텍스트들이 존재합니다. 기존 방법들은 이처럼 구분이 애매한 데이터를 그대로 학습에 사용하기 때문에, 비디오-텍스트 간의 연관성이 모호해지고 표현 학습 능력이 제한됩니다.
그러나 새로운 고품질 1:1 데이터셋을 수집하는 것은 비용과 시간 면에서 비효율적이므로, 저자들은 기존 데이터를 증강해 매칭 품질을 높이는 방법을 제안하였습니다. 저자가 제안하는 DREAM은 데이터의 의미를 보존하면서도 비디오·텍스트의 표현을 다양하게 변형하여, 기존 데이터셋의 모호함을 줄이고 모델이 더 견고한 표현을 학습하도록 도울 수 있었다고 합니다. 구체적인 방식에 대해 이제 바로 알아보겠습니다.
2. Method
2.1 Problem Definition
- 비디오: V = [V_1, \dots, V_{N_{\text{frames}}}]
- 텍스트: T = [T_1, \dots, T_{N_{\text{words}}}]
- 쿼리(Query): 검색을 요청하는 입력 (ex. 텍스트 문장 또는 비디오)
- 갤러리(Gallery): 검색 대상 데이터 집합 G = \{ g_1, \dots, g_{N_G} \}
- Test set의 일부, Train set과는 완전히 다른 비디오·텍스트 쌍으로 구성됨
- ex. “강아지가 공원에서 뛰는 장면”이라는 쿼리가 주어지면, 갤러리는 수천 개의 테스트용 비디오 후보
- VTR 수행 방식: 쿼리와 갤러리의 모든 항목 간 유사도를 계산 → 가장 관련성 높은 항목을 검색하는 식
- 비디오 인코더: f_{\text{video}}(·)
- 텍스트 인코더: f_{\text{text}}(·)
2.2 DREAM (Proposed Method)
저자들은 기존 VTR은 데이터의 품질이 낮아 충분한 표현 학습이 이루어지지 못한다는 점에 집중하였습니다. 반면, 단순한 증강 기법(Self-Augmentation, SA)을 적용했을 때 리트리벌 성능이 개선되는 현상을 확인한 것을 토대로, 보다 풍부한 학습 데이터를 제공하기 위해 세 가지 단순하지만 효과적인 데이터 증강 기법을 제안하였습니다.
구체적으로, DREAM에서는 각 비디오 V와 텍스트 T에 대해 positive view인 \tilde{V}V~, T~\tilde{T}를 생성하여 증강 데이터를 만들었습니다. 이렇게 생성된 증강 데이터는 원본 데이터와 결합되어 학습에 사용됩니다. 기존 방법들 중 일부는 데이터 다양성을 확보하기 위해 동일한 쿼리에 대해 여러 변형을 만들어 ‘멀티쿼리 리트리벌’을 수행하지만, DREAM은 증강된 뷰를 학습 데이터에 직접 포함시키기 때문에 별도의 멀티쿼리 과정 없이도 다양한 쿼리 표현을 모델이 학습할 수 있다는 것이 차별점입니다. 그 덕분에 기존 방법과 공정하게 성능을 비교할 수 있었다는 것이 저자들이 언급한 장점인데요. 조금 더 구체적으로 알아보겠습니다.
2.2.1 Simple Augmentation (SA)
SA 기법은 사전 지식이나 사전 학습 모델 없이 자기 유사 데이터를 생성하는 방식입니다. 구체적으로, 원본 비디오와 텍스트에서 프레임 또는 단어를 무작위로 복제하거나 일부를 제거하여 순서를 유지한 채 증강 데이터를 만듭니다. 예를 들어, 2프레임 비디오 [V_1, V_2]의 경우 [V_1, V_1] / [V_2, V_2] / [V_1, V_2] 와 같이 세 가지 버전을 만들 수 있습니다. 이와 마찬가지로 2개의 단어 텍스트 [T_1, T_2] 에서도 [T_1, T_1] / [T_2, T_2] / [T_1, T_2] 와 같은 증강이 가능하죠
이 방법의 장점은 보시는 것처럼 구현이 매우 간단하면서도 데이터 다양성을 손쉽게 늘릴 수 있다는 점입니다. 특히 SA는 별도의 모델 변경 없이 기존 데이터셋을 확장할 수 있죠.
2.2.2 Augmentation by Text Paraphrasing and Video Stylization (TPVS)
이뿐만 아니라 저자들은 기존 데이터보다 더 풍부한 정보를 추가한 데이터를 만들어, 비디오 및 텍스트 표현을 보다 정밀하게 학습하여 검색 성능을 향상시키고자 하였습니다. 이를 위해 저자들은 (1) 텍스트 패러프레이징(Text Paraphrasing) 그리고 (2) 비디오 스타일 변환(Video Stylization)을 제안하였습니다.
두 가지 타이틀만 봤을 때, 뭐랄까 텍스트로 비디오를 비디오로 텍스트를 생성한 것만 같습니다. 예를 들어, 비디오와 텍스트 쌍 데이터가 부족하다면, 비디오를 보고 새 캡션을 생성하거나 텍스트를 보고 비디오를 생성해 데이터셋을 확장할 수 있죠. 이렇게 하면 학습 데이터 다양성이 늘어나서 모델이 더 많은 패턴을 배울 수 있을 것 같기도 합니다. 그러나 이 점은 평가 과정에서 문제가 된다고 합니다. 추론 시에는 하나의 모달리티 데이터만 쿼리로 들어오기 때문에, 생성된 결과물이 오히려 성능을 저하시킬 수 있다고 하죠
즉, 학습 때처럼 ‘쌍’이 이미 존재하는 상황에서 다른 모달리티 데이터를 만들어주는 건 가능하지만, 테스트 때는 원본 쌍이 없기 때문에 생성된 데이터의 신뢰성이 보장되지 않아 그대로 쓰기 어렵다는 겁니다. 그래서 저자들은 멀티모달 변환보다는, 같은 모달리티 안에서 변형하는 단일 모달리티 증강(텍스트 패러프레이징, 비디오 스타일 변환)으로 방향을 잡은 것 같습니다.
말이 이렇지 데이터를 미리 뽑아두자는 건 같습니다. 다만.. 단일 모달리티 증강을 사용한 명분을 굳이굳이 만들어낸 것 같다는 생각이 좀 드네요…
다시 본론으로 돌아와서.. 저자는 단일 모달리티 증강을 사용하였습니다. 더욱이 최근 LLM과 VGM(Visual Generative Models)의 발전으로 인해, 원본 데이터의 의미를 유지하면서 표현을 변형하거나 시각적 스타일을 변화시키는 것이 가능해졌기도 했죠
(1) 텍스트 패러프레이징(Text Paraphrasing)
텍스트 증강은 LLM을 이용해 원본 캡션을 의미는 유지하되 문장을 변형하고, 더 구체적인 정보를 포함하도록 하는 과정입니다.

이 때, 프롬프트를 설계할 때 두 가지에 집중하였다고 합니다:
- 질문/지시 문구(Interrogative/Instructive Hints)
“This is a hard problem”과 같이 간단한 문장을 캡션 앞에 추가하여, LLM이 보다 정교하고 고품질의 문장을 생성하도록 유도하였다고 합니다. 이는 선행 연구에서도 제안된 기법이며, 제로샷 성능 향상에도 효과적임이라고 합니다. - 스타일·맥락 가이드(Style Transfer and Contextual Captions)
“20단어 이내로 핵심 정보와 주제를 하나의 문장에 담아라”는 식의 제약을 줌으로써, 의미적으로 유사하면서도 불필요한 단어를 최소화한 캡션을 생성할 수 있었다고 합니다.
(2) 비디오 스타일 변환(Video Stylization)
비디오 증강은 최근 급격하게 성능이 좋아진 비디오 스타일 변환 및 생성 기술을 활용하였다고 합니다. 그러나 저자들은 비디오 전체를 새로 생성하는 방식은 계산 비용이 크고, 시간적 연관성과 문맥 이해가 요구되는 난이도 높은 작업이라는 한계가 있었다고 합니다. 따라서 이를 대신하여, *ControlNet 기반의 이미지 스타일 변환을 프레임 단위로 적용하는 방식을 사용하였습니다.
*ControlNet: Adding Conditional Control to Text-to-Image Diffusion Models.

ControlNet은 기본적인 이미지 생성 모델(예: Stable Diffusion)에 추가 제어 경로를 결합해, 입력 이미지의 구조를 유지하면서 스타일·색감·질감 등을 변환할 수 있는 확장 구조라고 합니다. DREAM에서는 각 비디오 프레임을 ControlNet에 입력해 의미는 보존하면서 시각적 스타일만 변화시키고, 프롬프트를 다양하게 설정해 여러 버전의 증강 데이터를 생성하였다고 합니다. 이 방식은 비디오 생성 대비 계산 효율이 높고, 원본 의미를 안정적으로 유지할 수 있습니다.
결과적으로, TPVS는 텍스트와 비디오 양쪽에서 모두 데이터 다양성을 확보할 수 있으며, 이는 DREAM의 핵심 목표인 풍부한 데이터 표현 학습을 가능하게 합니다. 특히, 학습 시 생성된 증강 데이터가 모델이 보다 정교한 매핑을 학습하는 데 도움을 줄 수 있어, 최종적으로 검색 성능 향상으로 이어질 수 있습니다.
2.2.3 Augmentation by Relevance Enhancing (RE)
저자들은 TPVS가 검색 성능 면에서는 만족스러운 결과를 보이기 했지만, 새로운 정보를 추가하기 어렵고 데이터 페어의 품질 향상에도 한계가 있었다고 합니다. 보완이 필요하다는거겠죠? 이에 대규모 데이터로 학습한 LLM과 VGM이 외부 지식을 활용할 수 있다는 점을 통해, 비디오-텍스트 페어의 시각 및 언어 정보를 강화하는 증강 방식을 제안하였습니다.
RE는 크게 텍스트 관련성 강화(Text relevance enhancing)와 비디오 관련성 강화(Video relevance enhancing)로 나뉩니다.
Text relevance enhancing
원래 자막에 기반해 핵심 정보를 보존하면서도 새로운 관련 세부 정보를 추가하는 문장을 생성하도록 LLM에 프롬프트를 제공하였다고 합니다.

특히 상단 이미지에서 초록색으로 기입된 “feel free to add more relevant details”와 같이 모델이 불확실한 정보를 추측해 포함하도록 유도하는 설계를 도입했는데, 이는 의미적으로 유사한 다양한 정보를 포함시켜 핵심 특징을 더 잘 포착하기 위함이라고 하네요
Video relevance enhancing
TPVS와 유사하게 이미지 스타일 변환 기법을 활용하되, 추가적인 시각적 단서를 주기 위해 ControlNet을 사용하였습니다. 이때 텍스트 가이던스 없이 guess mode로 동작시켜, 원본 프레임과 의미적으로 유사하지만 세부적으로 변형된 프레임을 생성하였습니다. 이를 통해 시각적 다양성을 확보하면서도 의미적 일관성을 유지하였다고 하네요.
즉, RE는 텍스트와 비디오 모두에서 의미적 일관성을 해치지 않는 범위 내에서 새로운 정보와 시각적 변형을 추가하여, 기존 TPVS 대비 더 풍부한 학습 데이터를 제공하는 기법이라고 볼 수 있겠네요
조금 헷갈리실 것 같아 정리하면 TPVS를 먼저 제안하고, 그 한계를 보완하기 위해 RE를 새로 제안한 것이죠. 다시말해, 저자는 TPVS 다음에 RE를 “추가로” 수행하는 게 아니라, TPVS를 개선·대체하는 또 다른 증강 기법으로 RE를 제시한 거죠.
2.3 Training Objectives
베이스라인으로는 Clip4Clip로 삼았고, 비디오와 텍스트를 각각 모달리티 전용 인코더 f_{video}(\cdot)와 f_{text}(\cdot)로 임베딩한 뒤, 코사인 유사도 s = cosine(e_v, e_t)를 계산해 랭킹을 수행합니다. 여기서 e_v와 e_t는 각각 비디오와 텍스트의 임베딩 벡터입니다.
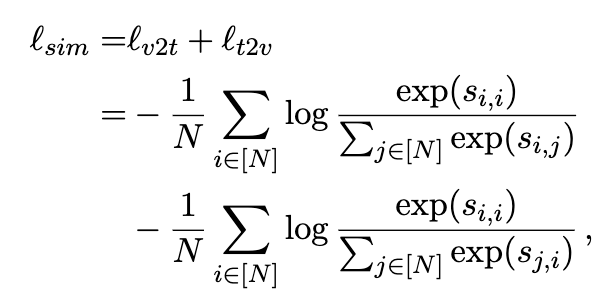
Loss 함수로는 대표적인 함수인 Symmetric InfoNCE Loss를 사용하였습니다. 상단 수식처럼 양 방향에 대한 Loss를 계산한 것이죠. 사실 데이터를 뻠핑한 방식을 제안하는 모델이기 때문에, Loss 는 기존 VTR 태스크와 동일하다고 볼 수 있죠
- \ell_{v2t}: 비디오 쿼리에 대한 텍스트 관련 Loss
- \ell_{t2v}: 텍스트 쿼리에 대한 비디오 관련 Loss
3. Experiment
3.1 Quantitative Results
저자가 제안하는 DREAM이 세 가지 벤치마크에서 달성한 정량적 성능에 대해 알아보겠습니다.
Table 1 – MSR-VTT
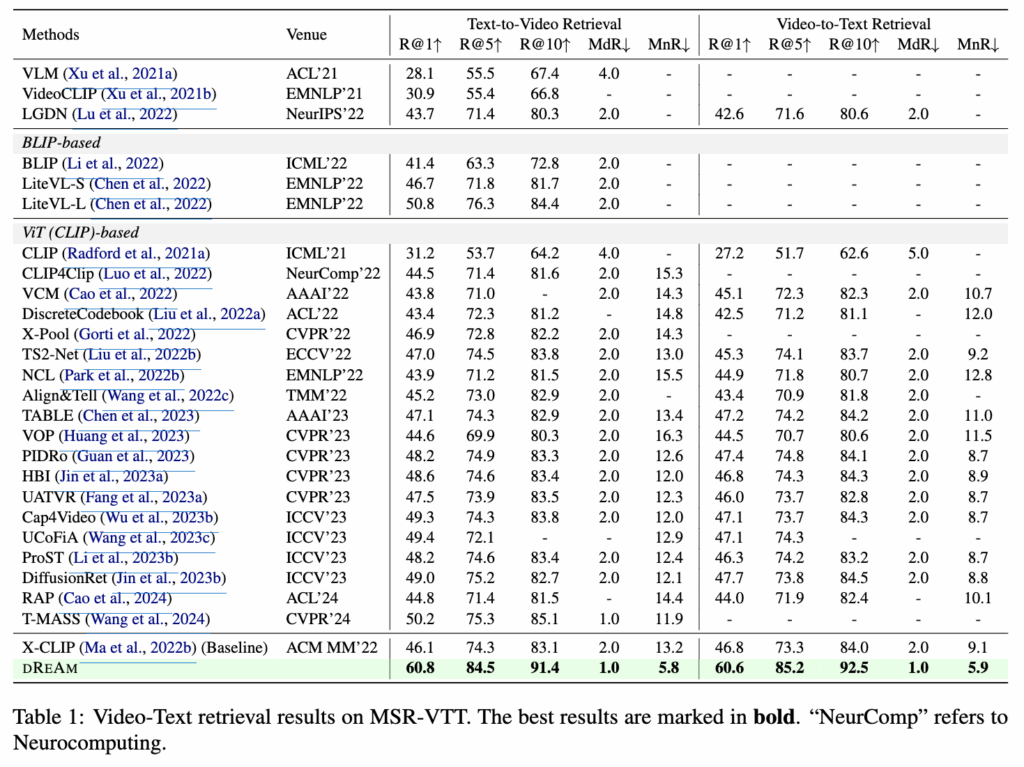
MSR-VTT에서 Text-to-Video와 Video-to-Text 모두에서 Recall@1, Recall@5, Recall@10 지표가 각각 60%대와 80~90%대로 이전 모든 기법을 크게 앞지른 것을 알 수 있습니다. 예를 들어 Text-to-Video 기준 Recall@1이 60.8%, Recall@5가 84.5%, Recall@10이 91.4%이며, Video-to-Text에서도 비슷한 수준의 성능을 보였죠. 어마무시한 성능 향상입니다.
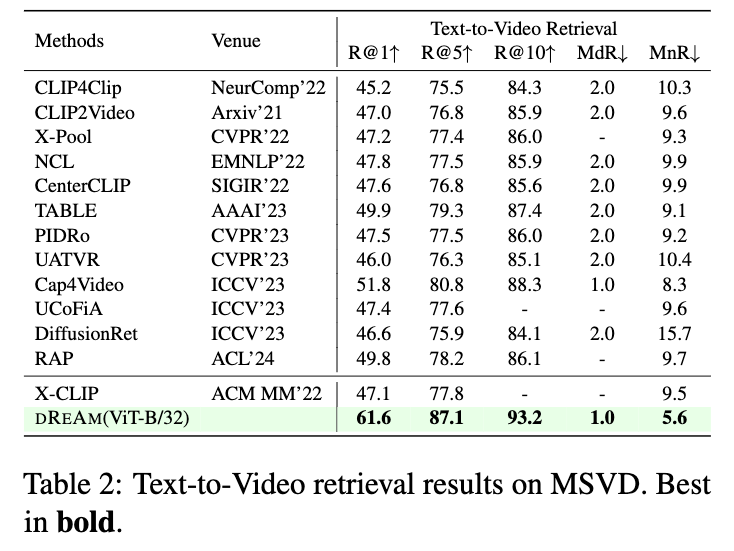
MSVD 데이터셋에서도 Recall@1이 61.6%, Recall@5가 87.1%, Recall@10이 93.2%로 기존 방법들을 크게 능가하였고, Median Rank(MdR) 1.0, Mean Rank(MnR) 5.6을 기록하며 매우 안정적인 검색 성능을 보였습니다.
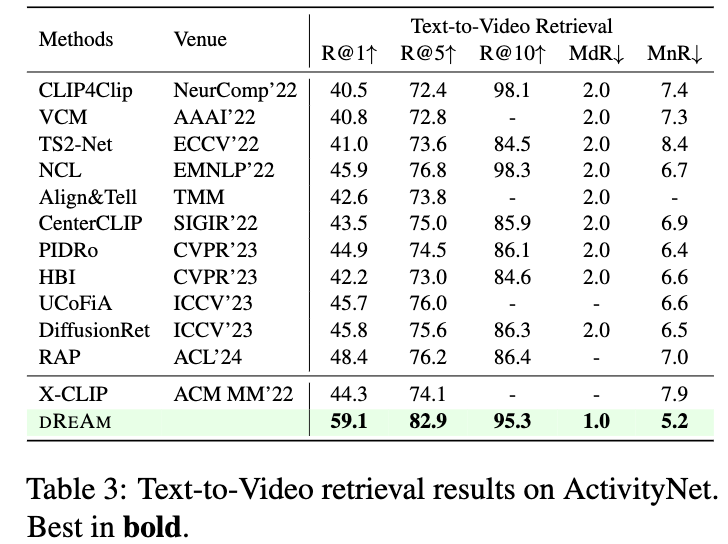
마지막으로 ActivityNet 역시 마찬가지로 두 방향 검색 모두에서 최고 성능을 달성했으며, Text-to-Video의 Recall@1이 59.1%를 달성하였습니다.
결과적으로, 세 데이터셋 전반에서 DREAM은 이전 SOTA 대비 굉장히 엄청난(?) 성능 향상을 보였고, 특히 Recall@K와 Rank 기반 지표 모두에서 강세를 보였습니다.
3.2 Qualitative Results
해당 논문에서는 신기하게도 정성적 성능에 대한 결과가 꽤 많았습니다. 아무래도 데이터 증강이 메인이다 보니, 그 품질을 확인하기 위함이 아닐까 하네요.
먼저 아래 그림 2, 4에 증강 데이터 예시가 나타나 있습니다. 텍스트 패러프레이징(paraphrasing)에는 LLaMA2와 OLMo를 사용하였고, 두 모델 모두 입력의 핵심 의미를 잘 유지하면서 의미적으로 유사한 텍스트를 생성할 수 있음을 확인할 수 있습니다.
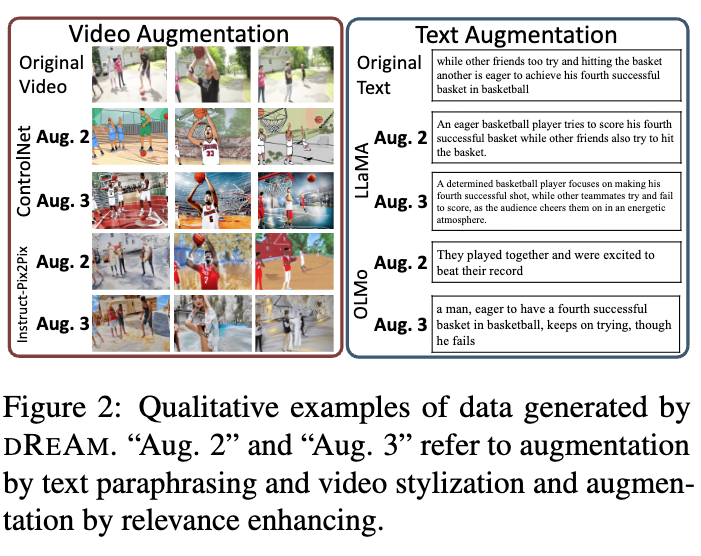

비디오 프레임 생성에는 ControlNet과 Instruct-Pix2Pix를 활용하였는데, ControlNet은 프레임 간 생성이 독립적으로 이루어지더라도 스타일의 일관성을 유지하는 반면, Instruct-Pix2Pix는 매번 다른 스타일의 이미지를 생성하는 경향이 있었습니다. 다만, 실패 사례도 존재하는데, 예를 들어 Instruct-Pix2Pix가 사람 머리를 농구공으로 잘못 생성한 경우가 있었다고 합니다.

다음으로 그림 3은 MSR-VTT 데이터셋에서의 검색 예시인데요. DREAM은 증강된 시맨틱 정보 덕분에 베이스라인 대비 더 나은 검색 성능을 보이며, 특히 객체나 인물 식별에서 뛰어난 성능을 보였습니다. 예를 들어, ‘computer’나 ‘child’와 같은 구체적이고 세밀한 요소를 정확히 알아내는 것을 통해, 이는 모델이 복잡하고 세밀한 시각적 디테일을 포착하는 능력이 우수함을 보여주는 것이라고 하죠.
3.3 Ablation Study
이제 Ablation study 입니다. 파라프레이즈된 텍스트 수, 생성된 비디오 수, 사용된 LLM 종류, 이미지 생성 방법, 그리고 베이스 모델 확장성에 대한 세부 실험을 진행하였습니다.
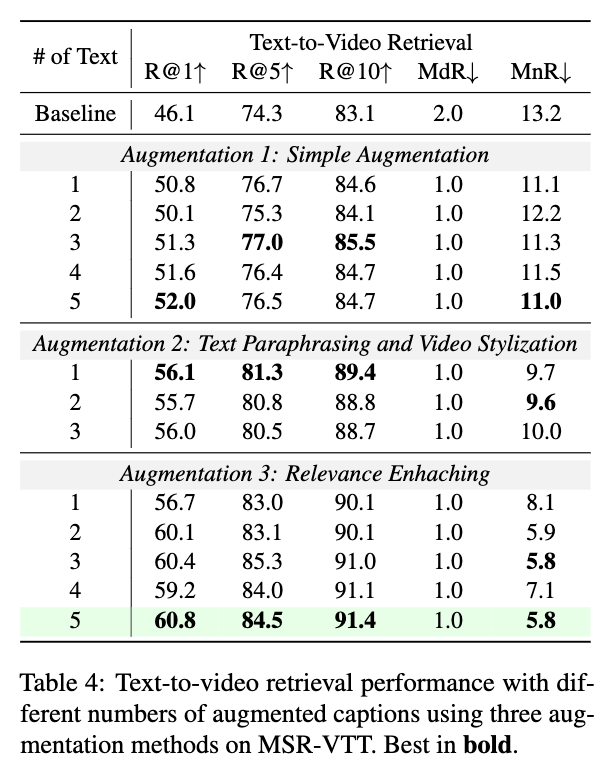
먼저 테이블 4는 파라프레이즈된 텍스트 수 변화에 따른 성능 차이를 보여줍니다. 단순 증강에서는 텍스트 수가 증가할수록 성능이 완만하게 향상되었고, 파라프레이징과 비디오 스타일라이제이션을 결합하면 성능이 확 올랐다고 합니다. 특히 Relevance Enhancing(RE) 기법과 5개의 텍스트 증강 조합은 R@1 60.8로 최고 성능을 기록했습니다.
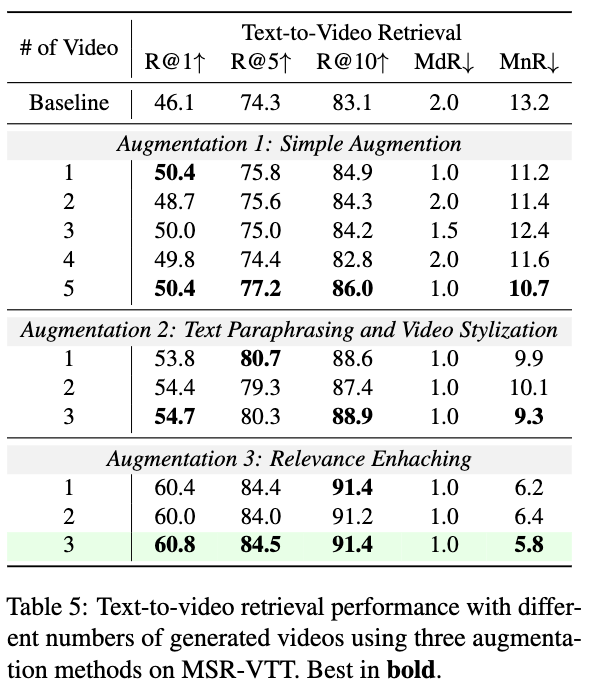
다음으로 테이블 5는 생성된 비디오 수 변화에 따른 영향력 비교실험입니다. 단순 증강의 경우 5개의 비디오를 생성했을 때 R@1이 50.4로 향상되었고, 파라프레이징+스타일라이제이션을 결합하면 T2V R@1이 54.7, V2T R@1이 56.4까지 상승했습니다
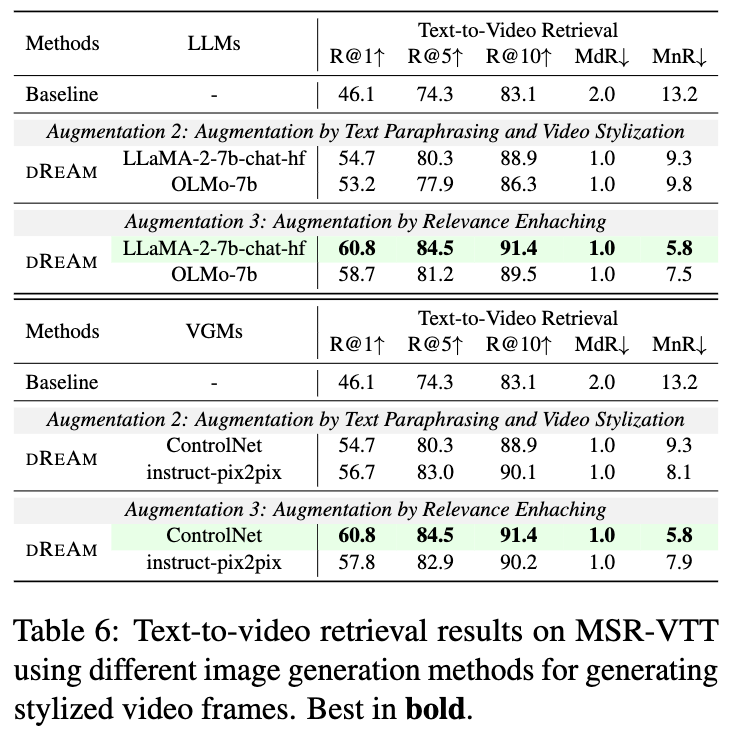
테이블 6은 LLM 종류 및 이미지 생성 기법 비교 결과입니다. LLaMA2가 OLMo보다 전반적인 성능이 높았으며, 이미지 생성에서는 ControlNet이 Instruct-Pix2Pix 대비 더 안정적이고 의미 일관성을 유지했습니다.

마지막으로 테이블 7은 DREAM의 베이스 모델 확장성 평가입니다. CLIP4Clip이 아닌 UCoFiA를 베이스로 사용했을 때도 성능이 크게 향상되어, DREAM의 강력한 일반화 능력을 보였다고 합니다.
4. Summary
Video-Text Retrieval 성능을 향상시키기 위한 데이터 증강 중심의 DREAM 을 알아보았습니다. DREAM은 단일 모달리티 데이터 증강인 텍스트 파라프레이징, 비디오 스타일라이제이션, 그리고 Relevance Enhancing(RE) 기법을 통해 데이터 증강 품질을 극대화하며, 이를 통해 의미 다양성과 관련성을 동시에 강화할 수 있었습니다.
실험에서는 MSR-VTT를 포함한 벤치마크에서 Clip4Clip, UCoFiA 등 다양한 베이스 모델 기반으로 성능 향상을 확인하였으며, 특히 RE와 5개의 텍스트 증강 조합에서 최고 성능(R@1 60.8)을 기록했습니다. 또한 LLaMA2와 ControlNet의 활용이 OLMo, Instruct-Pix2Pix 대비 우수한 증강 품질을 제공한다는 것도 실험을 통해 확인할 수 있었습니다.
단순 데이터 뻠삥(?) 만으로 정말 엄청난 성능 향상을 보여준 논문인 것 같습니다. 이제 머지않아 비디오 생성 모델로 데이터 뻠삥(?) 하는 연구가 곧 나올 것만 같다는 생각도 드네요.
안녕하세요 좋은 리뷰 감사합니다.
1. 평가할 데이터셋의 학습 split을 제안하는 방식대로 증강한 것으로 이해하였습니다. 만약에 MSR-VTT 학습셋이 1,000개 쌍이라면, 각각 비디오와 텍스트를 몇 개씩으로 증강했다고 보면 될까요?
2. 작성하신 리뷰에서, 이전 연구에도 데이터 증강 방법론들이 존재한다고 말씀해주셨는데, 성능 향상 폭은 이전과 본 방법론이 꽤 다른 것 같습니다. 혹시 이 원인이 무엇이라 생각하시는지 궁금합니다. 데이터의 양이나 데이터의 품질 등 측면에서 정말 데이터 증강만으로 이정도의 성능 향상 폭이 가능한지?에 대한 주영님의 의견이 궁금합니다.
3. 본 방법론의 베이스라인이 글에서는 CLIP4Clip이라고 말씀해주셨는데, X-CLIP이 맞는건가요? 표에는 X-CLIP이라 적혀있어서 여쭈어보았습니다.
1. 네, 이해하신 대로입니다. DREAM은 MSR-VTT 학습 split을 기준으로 증강을 수행합니다. 예를 들어 학습셋이 1,000개 비디오–텍스트 쌍이라면, 각 텍스트에 대해 최대 5개까지 파라프레이즈 버전을 생성하고, 각 비디오에 대해서도 최대 5개의 변형 버전을 생성하였다고 합니다. 정확한 개수는 Ablation Study(Table 4, Table 5)에 나와있고, 실험에서 가장 좋은 성능은 텍스트·비디오 각각 5개 였다고 하네요.
2. 저도 이 부분이 흥미로웠습니다. 일반적인 데이터 증강 연구와 비교했을 때, DREAM의 성능 향상 폭이 큰 이유는.. 글쎄요 일단 데이터의 품질 때문이 아닐까요? 단순 랜덤 변형이 아니라 LLM 기반 파라프레이징과 ControlNet 기반 비디오 스타일 변환, 그리고 Relevance Enhancing(RE) 단계를 통해 의미적으로 원본과 밀접하면서도 다양성이 확보된 데이터가 만들어진다는 점? 그리고 MSR-VTT처럼 비교적 작은 규모의 데이터셋에서 의미 있는 다양성을 확보하면, 학습 모델이 비디오–텍스트 매칭에서 일반화 능력을 크게 끌어올릴 수 있어서 때문이 아닐까 싶습니다.
3. 엇 맞네요 본 논문의 기본 실험은 X-CLIP(ViT-B/32)을 베이스 모델로 수행되네요. 제가 리뷰에서 CLIP4Clip이라고 잘못 작성해둔 부분은 수정해두겠습니다 ㅎㅎ