안녕하세요 오늘 논문은 CLIP을 사용하면서 fine-grained 레벨의 객체를 찾는 논문을 찾다가 제목을 보고 읽게 되었습니다. 제목을 해석해보자면 CLIP이 세밀한 레벨에서의 open-world perception에 있어서 주된 병목, 방해물인가? 를 물어보는 논문입니다. 처음 리뷰하고자 했던 논문은 해당 저자의 다음 논문이긴 했는데, 선행 연구를 먼저 진행했어서 이 논문으로 리뷰를 작성하게 되었습니다. 해당 저자의 이후 논문은 The devil is in the fine-grained details: Evaluating open-vocabulary object detectors for fine-grained understanding 으로 2024 CVPR highlight 였습니다. 리뷰 시작하겠습니다.
Abstract
저자는 XR(eXtended Reality)/ 자율주행 / 로보틱스 같은 열린 세계 환경에서는 학습 때 보지 못한 개념에서도 적응을 해야하기 때문에 추론 시 자유로운 텍스트 기반으로 물체를 찾는 OVD 가 중요하다고 먼저 언급합니다. 현재 OVD는 보통 CLIP 같은 멀티모달 백본에 기대고 있고, 일반적인 (coarse grained) 카테고리에는 꽤 잘 맞지만 색/무늬/재질 같은 미세 속성을 구분하는 데에는 약한 특징을 보인다고 합니다. 저자는 이러한 한계의 근본적인 원인을 찾고자 했습니다. 저자는 우선 CLIP의 잠재공간이 미세 속성들을 충분히 분리하지 못한다는 가설을 세웁니다. cosine similarity 하나로 매칭시키면 세부 속성 신호들이 소거될 수 있다는 주장을 하고 이를 실험적으로 개선시켰습니다. 방법을 간단히 말하면 임베딩들을 단순히 MLP 등으로 재투영시켜 fine-grained 레벨의 개념 분리도 높일 수 있음을 보여주었는데, 이후 더 자세히 설명하겠습니다.
Introduction
앞서 말했듯이 저자는 OVD 의 중요성을 먼저 언급하고, OVD가 가지는 문제점이 새 일반화 클래스에 대해서는 잘 탐지하지만, 미세 속성의 구분에는 약하다고 언급하며 그 예시로 light brown dog vs dark brown dog 구분이 흔하게 실패한다고 합니다.

해당 figure는 위에서 말하는 예시로, 색/무늬/재질 같은 fine grained 레벨에서의 detection 성능이 떨어지는 예시사진입니다.
이러한 문제의 원인 가설로 CLIP 의 임베딩이 카테고리 수준의 신호에 편향되고 속성수준의 신호는 약하게 표현될 수 있다는 점, 또는 미세 정보는 임베딩에 존재하지만, 우리가 흔히 쓰는 단순 매칭 함수(내적/코사인)가 그 정보를 끌어내지 못할 수도 있다고 주장합니다.
저자의 연구는 CLIP의 임베딩 공간에 미세 속성 정보가 아예 없는지 혹은 있는데 매칭을 못 뽑는건지에 대한 분석을 하는데, 우선 OVD (예시: owl-vit) 에서 흔히 섞여 있는 box localization 변수를 배제하기 위해 CLIP 자체를 fine grained 벤치마크에서 먼저 평가하고, CLIP 기반의 OVD 로도 같은 이미지에서 평가하여 성능 패턴을 분석했다고 합니다. 일단 결과적으로 둘의 실패 양상이 비슷했고 CLIP 단독의 성능과 CLIP 백본의 OVD 의 성능이 비슷하여 box localization 문제가 아닌 CLIP의 image-text 정렬 문제일 가능성이 높다고 합니다. 저자는 이러한 기본 CLIP 의 image/text encoder 위에 얕은 레이어를 추가하여 fine grained 데이터셋으로 학습하여 성능이 오르는 것을 확인하였고, 이러한 점이 기본 CLIP 임베딩이 매칭 단계에서는 잃어버렸던 미세수준의 정보를 가지고 있다고 주장합니다. 간단하게 정리하자면 OVD가 직면한 fine-grained 레벨에서의 성능 저하가 CLIP 의 문제점이었고, 동결된 CLIP 임베딩 위에서 학습된 경량 아키텍처가 CLIP 잠재공간에서의 미세수준 정보를 끌어낼 수 있으므로 미세수준의 정보는 잠재공간에 존재한다는 점도 입증하였습니다.
Method
저자의 연구는 두가지 핵심 질문을 다룹니다.
이미 introduction에서 다룬 두가지입니다. 다시한번 적어보자면
- CLIP latent space 가 fine-grained level 에서의 OVOD 성능 제한에 문제점인가?
- 만약 맞다면, latent space 자체에서의 정보 부족이 문제인지, 혹은 내적 연산과 같은 matching methods가 부적절한 결과로 이끄는 것인가?
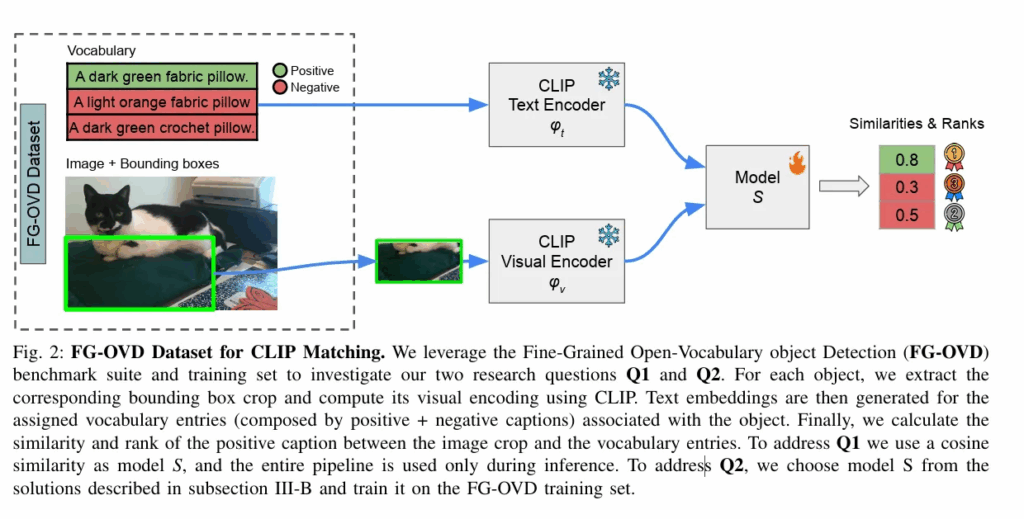
위의 Q1, Q2 를 해결하기위한 저자의 파이프라인입니다. 우선 1번문제를 다시 한번 다루자면, detector 의 문제인지 혹은 CLIP latent space가 문제인건지를 파악하기위해, GT정보를 crop해서 양과 음의 캡션에 각각 기존의 방식인 cosine similarity로 비교합니다. 이때 생각해야할 점은 정답인 “A dark green fabric pillow.” 가 오답인 “A light orange fabric pillow” 와 “A dark green crochet pillow.” 보다 높아야 합니다.
저자는 양의 캡션과 음의 캡션 모두에서 절댓값이 높게 나오는 경향이 있었고, 이를 통해 box detector의 문제이기 이전에 latent space의 정보를 내적하는 방식이 문제가됨을 보입니다. 이후 CLIP을 동결시키고 Model(s)를 내적/sim 에서 triplet loss로 변경하여 (양의점수 – 음의점수 ≥ 마진) 학습시키고 성능이 개선된다면 정보 자체는 latent space에 존재 했지만 코사인 매트릭이 그것을 충분히 꺼내지 못한거라고 주장합니다.
저자의 주장대로 matching method가 문제고 CLIP 의 잠재공간에는 미세 정보가 존재할 수 있다. 라는 가설을 정량적으로 증명하기 위해 2단계의 학습 전략을 세웁니다.
ϕv, ϕt = CLIP 비전/텍스트 인코더 (동결) vi = ϕv(Ii) , ti = ϕt(Ti) , when I = image, T = text S(v,t) = 유사도 함수 (1~6)
[x]+ = max(x,0) , a>0 :힌지 마진
첫번째는 워밍업으로 CLIP 을 coarse 세트로 먼저 학습시킵니다. ( 힌지 기반 트리플렛 로스)
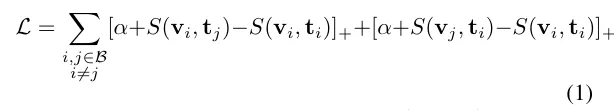
해석하자면 coarse 데이터에서 정답 쌍의 점수가 오답 쌍의 점수보다 마진 a 만큼 크도록 학습시키는 것입니다. 첫항과 두번째항은 양방향으로 학습시켜 정렬을 더 안정적으로 하기 위함입니다. (like InfoNCE)
두번째는 파인튜닝 세트로서 fine-grained 세트로 학습시키는 것입니다.
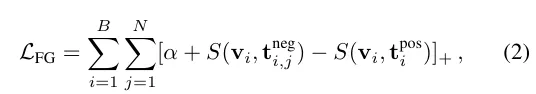
정답 캡션과 hard negative 캡션을 통해 같은 객체에 대한 속성/재질/색 등의 미세차이를 구분하도록 학습합니다. 1번 수식과 2번수식의 차이점을 보자면 1번은 배치 내의 다른 샘플로 카테고리 중심으로 학습하는 것이고 2번 수식은 같은 이미지 내의 positive & hard negative 를 학습시켜 미세 구분을 중심으로 학습하는 것입니다.
위에서 유사도함수를 1~6라 적었는데, 각각 설명하자면
- S(v,t) = cos(v,t) 로 vanilla cosine similarity 입니다. 빠르고 단순하지만 카테고리의 신호가 강력하게 반영되어 하드 네거티브에게 자주 집니다.
- S(v,t) = cos(Wvv +bv,Wtt+bt) 로 Linear projection layer 로 동결된 CLIP에서 뽑은 후 코사인유사도를 계산합니다. 선형층이 속성에 유효한 축을 weightning하여 선형 분리가 가능하게합니다. 비선형 경계가 필요한 경우가 한계점입니다.
- S(v,t) = cos(v,Wtt +bt) 로 텍스트만 선형 투영시킵니다. 이는 텍스트 쪽 표현 부족이 병목일때를 확인하기 위한 방법으로 이미지 분포는 괜찮다고 보는 관점입니다.
- S(v,t) = cos(Wvv +bv,t) 로 이미지만 선형 투영시킵니다. fine-grained 신호가 이미지 쪽 표현에서 약할때 사용합니다.
- S(v,t) = cos(Wvv +bv,t) 선형 대신 비선형으로 투영시킨 후 cos 비교를 합니다. ( 2layer MLP + GELU) 비선형 경계로 선형으로는 어려운 미세 개념을 학습합니다.
- S(v,t) = σ MHA([CLS,v,t])(0,0) 는 CLS 토큰과 임베딩을 사용하여 작은 트랜스포머처럼 사용하는 것입니다. MHA 는 multi head attention 부분으로 여러 헤드들이 서로 다른 관점에서 이미지와 텍스트를 매칭하려고 attention 분포를 학습하게 됩니다. MLP 나 선형 변환보다 더 풍부하게 학습하지만 파라미터수가 많다는 단점 혹은 과적합 위험성이 존재한다고 합니다.
각각을 Coarse grained는 MS-COCO에서 평가하고 Fine grained는 FG-OVD 데이터셋에서 평가합니다. (원래는 detection용이지만 여기서는 크롭된 객체 이미지를 사용하여 분류로 변환했다고 합니다.)
난이도는 각각 Trivial,easy,medium,hard로 구분했고 각각 간단히 설명하면 Trivial : negative 캡션이 완전히 다른 속성/객체 Easy : 속성 변화가 있지만 시각적으로 뚜렷한 경우 Medium : 속성 차이가 미묘 Hard : 속성 1개만 아주 미세하게 변경 난이도를 색,재질,무늬,투명도에 따라서도 나누었는데 각각 Color, Material, Pattern, Transparency입니다.
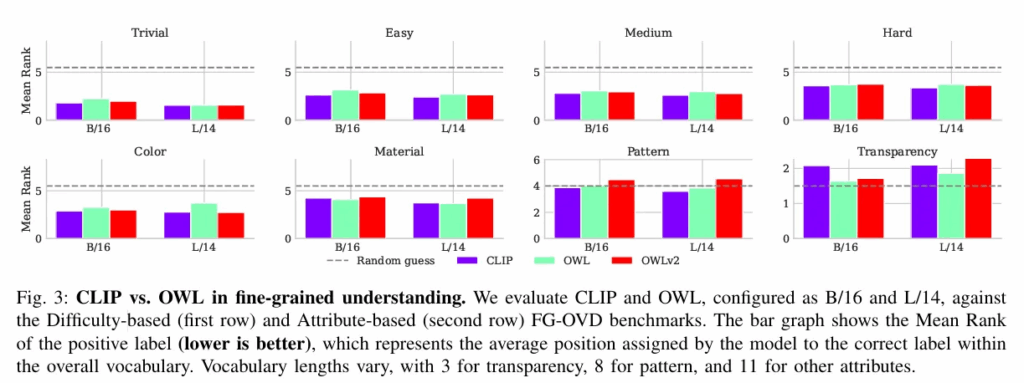
여기서 Mean rank는 양의캡션의 평균 순위로 Random guess와의 비교로 성능을 추측할 수 있습니다. 난이도가 어려워질수록 random guess와 비슷해지는 경향성을 보이고, 전 난이도에서 어느정도 미세 구분을 한다는 것을 알 수 있습니다. 또한 CLIP과 Owl-ViT와의 성능이 비슷함을 보여 detector의 문제가 아니라 CLIP 문제임을 뒷받침합니다.
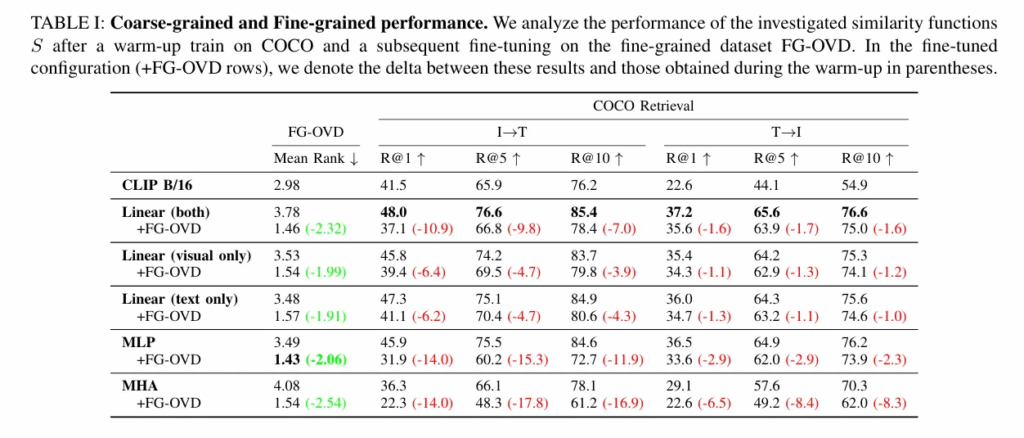
warm-up 과 fine-tuning 학습 사이의 성능 변화를 보여줍니다. Mean Rank는 앞서 말햇듯이 양의 캡션을 몇번째로 골랐는지에 대한 순위이며 fine-tuning이후 큰 성능 개선이 있었음이 보입니다. 우측 COCO Retrieval을 보면 fine grained를 진행하게 되면 coarse grained retrieval에서는 손해를 보는 것을 확인할 수 있습니다. 즉 fine-grained 정보는 이미 latent space에 존재하며 이는 MLP 만으로도 간단하게 추출이 가능하다는 것을 보입니다.
Conclusion
Q1 : OVOD fine-grained 에서의 성능 한계는 localization보다는 CLIP embedding spcae의 matching 한계이다. Q2 : Fine-grained 정보는 이미 latent space에 존재하며 cosine similarity 대신 학습된 matching 함수 사용으로 성능 개선을 이루어낼 수 있다.
이며 저자는 연구 목표인 multi modal 모델들의 open-world 이해 한계점을 분석하고 그 원인이 어디에 있는지를 정량적으로 밝혔고, 향후 연구 방향이 pre-training 관점에서 fine-coarse balance가 잡힌 데이터로 표현 학습을 하는것과, Matching 함수의 대안점에 대한 탐구라고 언급했습니다. 감사합니다.
안녕하세요, 인택님 좋은 리뷰 잘 읽었습니다.
리뷰를 보니 저자들이 fine-grained 정보가 CLIP의 latent space에는 존재한다고 결론을 내린 것으로 이해했습니다.
다만 궁금했던 점이 왜 cosine similarity가 그 정보를 제대로 꺼내오지 못하는지에 대한 이론적인 근거나 설명이 논문에 있었는지가 궁금합니다. 서두에 cosine similarity 하나로 매칭시키면 세부 속성 신호들이 소거될 수 있다는 주장을 했다고는 언급하셨는데 어떤 부분에서 세부 속성 신호들이 소거 되었는지가 와닿지 않아서 질문드립니다.
감사합니다.
안녕하세요 우현님 답글 감사합니다.
이론적 근거나 설명은 저자의 실험 세팅에서 대답이 가능할 것 같습니다. OVD 에서 detector 부분을 사용하지 못하게 box localization 영향을 제거하고, 기존의 CLIP 과 owl-vit 등에서의 성능을 비교했는데 비슷했으며, 이후 인코더는 동결시키고 projection layer나 MLP 등을 추가해 학습하면 fine-grained 성능이 오르는 것을 보아 성능 저하를 일으킬 수 있는 부분을 matching 함수로 줄였다고 볼 수 있습니다. 저자의 1~6개의 ablation 대안들은 단순 cos sim 계산이 대표속성을 찾는 매칭 방식이고, embedding vector 가 기존에 가지고 있는 fine grained 성분을 MLP 나 projection layer를 추가하여 끌어낼 수 있음을 실험적으로 보였습니다. 감사합니다.
안녕하세요 신인택 연구원님 좋은 리뷰 감사합니다.
기존 OVOD 연구들이 fine-grained 구분에 약점을 가지고 있었던 것에 대해 자세하게 분석한 논문인 것 같습니다. 연구를 통해 fine-grained에 잘 대응하지 못하는 것을 CLIP 백본 자체의 문제라는 것은 신빙성있는 것 같습니다. 여기서 궁금한 점이 있는데, 학습된 matching 함수 사용하는 것이 cosine similarity를 사용하는 것보다 더 성능이 좋은 것은 실험을 통해 증명했다고 생각이 들지만, 그 이유에 대한 분석이 있었는지 궁금합니다. CLIP을 학습할 때 cosine similarity 기반의 contrastive learning으로 학습되는 것으로 알고 있는데, 학습할 때 정보를 주입한 방식이 latent space 내 존재하는 정보를 활용할 때에는 왜 비효율적인지 궁금하네요.
감사합니다.
안녕하세요 성준님 답글 감사합니다.
그 이유에 대한 분석이 자세히 있지는 않았지만 제가 이해한 바로 설명을 드리자면, 우선 기존에 사전학습시나 coarse grained 레벨에서 학습시에는 대표특성만 찾으면 되므로 cosine similarity 방식이 괜찮게 작동을 하게됩니다. 저자의 방법들이 밝혀낸 점은 임베딩 벡터의 (ex:768차원) 모든 부분이 대표 특성을 가진다기보다 각 차원들이 가지고 있는 미세 정보들이 존재하는데, 단순 내적을 진행하면 모든 차원에 동일한 가중치를 부여하여 계산하는 방식이라 전체 대표 특성만 살아남기 쉽습니다. 다만 projection 이나 MLP 를 추가하여 나머지는 동결시키고 재학습 시키면 fine-grinaed 정보들을 끄집어내도록 학습되어진다고 할 수 있습니다. 즉 cosine 방식은 coarse-grained 신호를 강조하는 구조적 편향이 존재하고, 학습된 matching이 fine-grained subspace를 강하게 만든다고 이해하면 되겠습니다. 감사합니다.
안녕하세요 리뷰 잘 읽었습니다.
CLIP의 fine-grained 속성 구분이 안된다는 문제 정의 부터 단계별로 1) detector가 아닌 CLIP에 문제가 있음을 2) CLIP latent space 자체는 fine grained 속성이 구분이 되어있지만 기존의 matching metric으로 사용됐던 cosine sim의 단순성으로 충분히 그게 학습되지 않았다라는 결론까지 탄탄한 전개의 연구였단 생각이 드네요!
Fig 3에서 CLIP과 Owl-ViT와의 비교 실험이 진행되었는데요 둘을 비교하는 이유가 뭐고 설명해주신 ‘CLIP과 Owl-ViT와의 성능이 비슷함을 보여 detector의 문제가 아니라 CLIP 문제임을 뒷받침’한다란 결론을 내릴 수가 있는 지 설명해 주시면 감사하겠습니다.
안녕하세요 지연님 답글 감사합니다.
fig 3에서 CLIP 과 owl-cit를 비교실험하는 이유는 저희가 잘 아는 CLIP 과 이를 백본으로 사용하는 (저자가 논문을 쓸때에는 그나마 SOTA였던 OVOD 모델) owl-vit를 사용함으로써 성능저하의 원인이 detector head에 있는지를 집중했다고 보면 되겠습니다. owl-vit는 CLIP 을 OD 용으로 detection head를 달았다고 보면 되는데 둘의 성능저하 경향성이 비슷함을 보여 detector head가 아닌 CLIP 에 문제가 있음을 직간접적으로 알 수 있습니다. (만약 owl-vit에서의 성능저하가 더 심했다면 matching 방식이 아닌 head에 문제가 있음이 보여집니다.) 감사합니다.
인택님 좋은 리뷰 감사합니다.
CLIP 임베딩이 속성 표현이 어렵거나 단순한 매칭 방식에 부족함이 있다는 두가지 가능성을 두고 이에 대한 분석을 통해 image-text 정렬 문제일 가능성이 높다고 이야기하셨는데, 즉 두번째 가능성인 매칭 방식의 부족함이 있다고 분석한 것으로 이해하면 될까요? 저자들이 추가로 학습하는 과정에서 CLIP 임베딩에 부족한 속성 정보가 추가로 학습된 것은 아닐지 인택님의 의견이 궁금합니다.(저차원으로 압축한 뒤 복원하는 네트워크처럼 일종의 decoder 역할을 하며 feature 표현력을 늘린 건 아닐지..?)
또한 워밍업으로 caorse set을 먼저 학습시키고 이후에 fine-grained로 학습하는 이유가 있는 지 궁금합니다.
Fig 3에 대한 내용 중 전 난이도에서 어느정도 미세구분을 한다는 것을 알 수 있다고 하셨는데, random guess는 어떤 결과인지 궁금합니다.
안녕하세요 승현님 답글 감사합니다.
우선 두번째 가능성인 매칭 방식의 부족함 때문에 fine-grained 정보를 끄집어내기 힘들다고 이해하시면 될 것 같습니다.
그리고 저자들이 추가로 학습하는 과정에서 CLIP 임베딩에 부족한 속성정보가 추가로 학습된 것은 아닐지 라는 의견에서 우선 저자들의 실험 세팅이 detector head를 제거하고 encoder부분은 freeze 시켰으므로 embedding space 의 정보는 기존 CLIP 과 동일한 상태에서 시작하게 됩니다. 이 상태에서 바로 cosine sim 을 계산하게 된다면 전체 특성인 coarse grained 특성을 갖게되는데 이는 위에서 말했듯이 임베딩 벡터의 모든 차원을 동일한 가중치로 계산하여 전체 특성이 두드러지게 학습하는 방식이기 때문입니다.
저자가 MLP 나 projection 연산등을 쓴 이유는 기존에 CLIP encoder에서 나온 임베딩 벡터에는 이미 fine-grained 정보가 존재하며, 이를 MLP 나 projection matching 방법으로 끄집어낼 수 있고, fine grained 의 성능이 올랐다는 점으로 정량적으로 증명했다고 생각합니다. (projection 이나 MLP가 기존에 존재하는 차원을 다시 weighting 하여 fine grained 속성을 더 보기 쉽게 바꾼다고 생각하면 됩니다.)
워밍업으로 coarse set을 먼저 학습시킨 이유도 기존 CLIP을 사용할때 coarse grained로 대규모 사전학습을 하기때문이라 생각하고, 여기서 이미지 임베딩 공간에는 이미 fine-grained 정보가 들어있음을 보이기 위해서 입니다. 감사합니다.