제가 이번에 리뷰할 논문은 ICCV 2025에 paper list에 있는 논문입니다. 2단계로 이루어져서 affordance를 찾고 그에 대한 action을 생성하는 과정으로 이루어집니다. affordance learning이 실제 application에 적용되도록 하는 연구로 보시면 될 것 같습니다.
프로젝트 페이지: https://a-embodied.github.io/A0/
Abstract
로봇 조작은 복잡한 작업을 위해 어디를 잡고, 상호작용을 위해 어떻게 잡아야 할 지와 같은 공간적 affordance에 대한 이해가 필요하며, 기존 연구들은 모듈 기반 방식이나 end-to-end 방식으로 공간적 추론 능력이 부족하다는 한계가 있었습니다. 최근의 dense spatial representation에 집중한 point 기반 방식이나 trajectory 모델링에 집중한 flow 기반의 방식과 다르게, 해당 논문은 A_0라는 계층적 affordance-aware diffusion 모델을 제안하여 manipulation을 high-level의 affordance에 대한 공간적 이해와 low-level의 action excution으로 분해합니다. A_0는 Embodiment-Agnostic Affordance Representation을 활용하여, 접촉점과 이후의 trajectory를 예측함으로써 객체 중심의 공간적 affordance 를 파악합니다. 이는 100 만개의 데이터로 사전학습되어 다양한 플랫폼으로 일반화가 가능하며, A_0모델은 Position Offset Attention과 Spatial Information Aggregation 레이어로 구성됩니다. 모델의 output은 action execution모듈을 통해 실행되며, Franka, Kinova, Realman 등의 다양한 로봇 플랫폼에서 실험을 통해 복잡한 작업에 대한 적용 가능성을 보였습니다.
Introduction
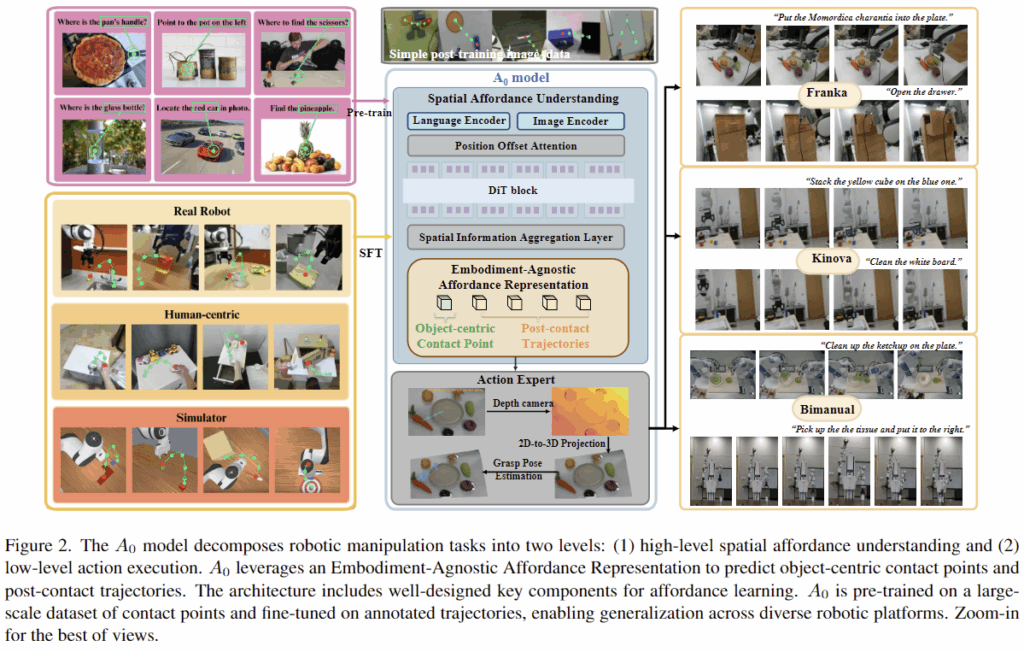
로봇 조작은 embodied AI에서 중요한 작업으로, 복잡한 환경에서 물체와 상호작용을 위해 필요한 기술입니다. 최근에는 (1) 대규모 VFMs를 활용하여 공간적 정보를 이해하는 모듈기반 방식과, (2)세밀한 조작을 위한 end-to-end 기반의 VLA 방식 2가지 흐름으로 연구가 이루어지고 있습니다. 그러나, 이러한 방식은 공간적 affordance(상호작용을 위한 물체 영역과 어떻게 잡아야 하는지)에 대한 이해 능력이 부족하다는 한계가 존재합니다. ReKep, MOKA와 같이 VFMs를 활용하는 모듈 기반 방식은 공간과 물리적 세계에 대한 이해능력이 부족하며, \pi_0와 같은 end-to-end 방식의 경우 action을 생성하는 과정에 공간적 정보를 충분히 이해하지 못하고, 복잡한 작업에서 효율적이지 못한 성능을 보인다고 합니다.
최근 SpatialVLA, Track2Act와 같은 point 기반의 방식과 GeneralFlow나 Im2Flow2Act와 같은 flow기반의 방힉들은 공간적 상호작용을 모델링하고자 하였으나, dense spatial representation이나 trajeoctory 모델링에만 집중하고 있으며, 연산 비용이 많이들고, 특정 로봇 플렛폼에 한정된다는 한계가 있습니다. 따라서 저자들은 물체의 접촉점과 trajectory를 예측하는 object-centric한 방식을 제안하며, Embodiment-Agnostic Affordance Representation을 제안하여 다양한 로봇 플렛폼으로 일반화가 가능하도록 하고자 하였습니다. 저자들은 Embodiment-Agnostic Affordance Representation를 활용하여 소량의 작업에 특화된 데이터로 fine-tuning이 가능함을 보이고, 이러한 방식은 real-world로의 적용을 고려하였을 때 실용적인 방식임을 어필하였습니다.
A_0는 manipulation 작업을 (1)high-level의 spatial affordance understanding과 (2)low-level의 action execution으로 분해하였으며, (1)로 구한 object의 접촉점과 이후의 trajectories를 (2)에 활용하였습니다. 또한, foundation localization 능력을 학습하기 위해 100만개의 접촉점과 이후 trajectories 데이터로 사전학습한 뒤, 이후 소량의 데이터로 fine-tuning을 수행하였습니다. 이를 통해 공간적 affordance 추론 및 물리적 이해를 강화하였으며, Franka 로봇과 Kinova 로봇에서 기존 방식보다 개선된 성능을 실험적으로 확인하였습니다.
즉 해당 논문의 contribution을 정리하면
- 100만개의 데이터로 사전학습되어 다양한 로봇 플랫폼에 적용이 가능하도록 Embodiment-Agnostic Affordance Representation을 제안하여 객체의 접촉점과 trajectories에 대해 예측
- 계층적 affordance-aware diffusion 모델인 A_0를 제안
- 다양한 로봇 플랫폼에 효과적으로 적용이 가능함을 실험적으로 확인함
Methods
A_0는 다양한 데이터로부터 학습된 Embodiment-Agnostic Affordance Representation을 통해 object의 접촉점과 trajectories를 예측합니다. 이 모델은 high-level의 공간적 affordance 이해와 low-level의 action execution으로 구분되어 계층적으로 작동하며, affordance 학습에는 Diffusion 구조를 사용합니다.
1. Embodiment-Agnostic Affordance Representation
공간적 affordance를 이해하고 물체의 어느 영역에서 어떻게 상호작용할지에 대해 포착하기 위해 저자들은 Embodiment-Agnostic Affordance Representation \mathcal{R}를 제안하였습니다. 구체적으로 real-worl와 합성 robotic 데이터 \mathcal{R}_R와 hand-object Interaction 데이터 \mathcal{R}_H, 커스텀 데이터 \mathcal{R}_C로부터 행동관련 지식을 통합한 것으로, 이는 객체 중심 RGB 이미지 I, 접촉 지점c^{2D}_0과 이후의 2D trajectories T=(t^{2D}_0, t^{2D}_1, t^{2D}_2, ... ), 자연어로 표현된 작업 지시로 구성됩니다.
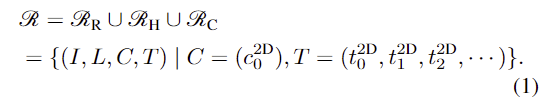
일반화된 Embodiment-Agnostic Affordance Representation을 사용함으로써 소량의 task-specific한 데이터로도 fine-tuning이 가능하며, 다양한 플랫폼에 효과적으로 적용이 가능해지도록 하였다고 합니다. 다양한 출처의 데이터들은 각 데이터에 맞춰 affordance representation을 추출하고 annotation을 생성하였다고 합니다.
[Datasets]
- PixMo-One-Point
- PixMo-Point데이터로부터 이미지와 object 라벨에 대한 1개의 contact point로 구성된 100 만개의 데이터
- HOI4D-22k
- HOI4D 데이터로부터 추출되고 검증된 22,000개의 human-object interaction 궤적이 포함된 데이터
- DROID-3k
- DROID 데이터로부터 검증된 3056개의 궤적이 포함된 데이터
- Maniskill-5k
- ManiSkill Scene 데이터로부터 4965개의 경로를 2D로 변환한 데이터
2. A0 Model Structure
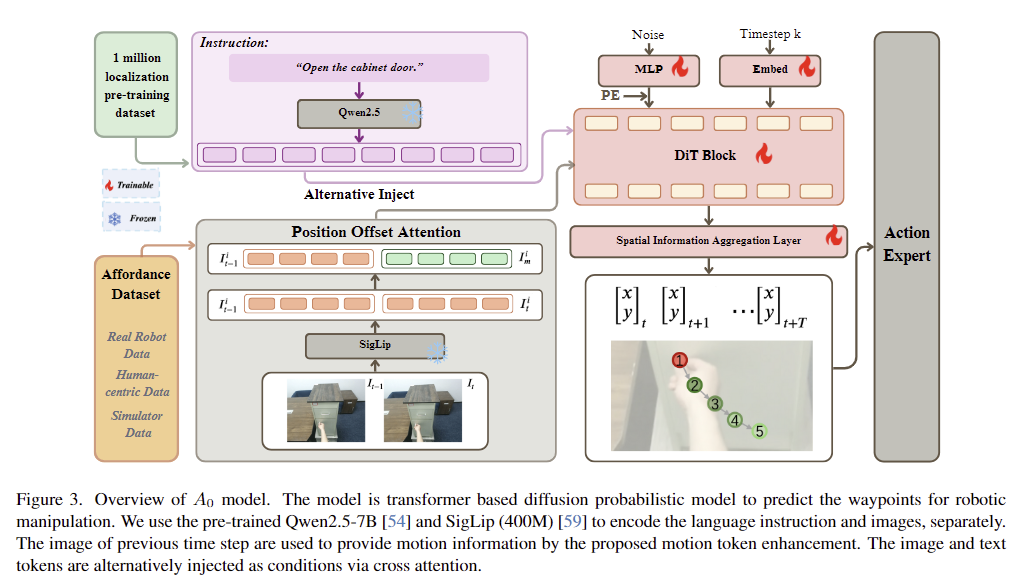
저자들은 Diffusion Transformer (DiT) 구조를 기반으로 하였으며, 이미지I_{t-1:t}와 자연어 지시문\mathcal{l}에 대해 각각 사전학습된 vision encoder와 text encoder를 이용합니다. 이미지 feature와 text token은 cross-attention을 통해 융합되어 diffusion 구조에 condition으로 활용됩니다.
T개의 waypoints(T는 chunk size로, 사전에 정의됨) \mathbf{x}_{t:t+T}는 이미지의 정규화된 좌표 \mathbf{x}_t=[0,1]^2 \in \mathbb{R}^2 이고, 이미지는 현재 프레임과 이전 프레임에 대하여 사전학습된 SigLiP로부터 N개의 토큰을 생성합니다. A_0의 입력으로는 timestep k와 noisy waypoints가 들어갑니다.
[Position Offset Attention]
로봇 작업에서 움직임이 중요한 정보이므로, 저자들은 이전 프레임 이미지의 토큰 I^i_{t-1}과 현재 프레임의 토큰 I_t^i 사이의 차이를 계산하여 I_m^i를 구하고 이를 I_t와 concate하여 최종적인 visual feature o_t=concat([I^i_t,I^i_m], dim=1)를 구합니다. 이미지 feature에는 사인파 형태의 positional embedding을 추가하고, language encoder로는 사전학습된 Qwen2.5-7B 모델을 이용하여 토큰을 생성한뒤 cross-attention 블록을 통해 결합하여 N개의 DiT 블록을 통과하며 분포 p(x_t | \mathcal{l}, I_{t-1:t})를 학습하도록 합니다.
[Spatial Information Aggregation Layer]
latent space에서 물리적 공간으로 투영하기 위해 MLP 디코더를 추가합니다. 추론 시 noisy waypoints x^k_{t:t+T} \sim \mathcal{N}(0,\mathbf{I})를 샘플링하고, 이를 diffusion 모델과 ODE 기반의 K_D step의 de-noising 과정을 통해 waypoints를 예측합니다.
3. Training Affordance Prediction Model A0
[Pre-training]
waypoint는 시작점을 찾은 뒤 이후의 offset으로 표현이 가능하며, 따라서 waypoint의 시작점이 매우 중요합니다. 따라서 저자들은 인터넷에서 수집한 데이터로 이루어진 PixMo-One-Point 데이터셋을 사용하며, 단일 이미지와 텍스트 설명을 입력으로 받아 객체의 시작 위치를 2D 좌표로 예측하도록 학습합니다. 이때 학습에는 예측된 좌표와 실제 좌표에 대한 MSE loss를 구하여 학습합니다.
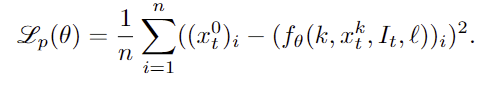
[fine-tuning]
이후 manipulation 작업으로의 fine-tuning에는 입력 텍스트를 단순 객체 라벨에서 작업 지시문으로 확장하고, 출력도 단일 웨이포인트에서 T개의 웨이포인트로 확장합니다. 학습에는 GT trajectories x^0_{t:t+T}가 주어졌을 때, 여기에 노이즈를 추가한 x^k_{t:t+T}=\sqrt{\bar{\alpha}^k} x^0_{t:t+T} + \sqrt{1-\bar{\alpha}^k} \epsilon^k , \epsilon^k \sim \mathcal{N}(0,\mathbf{I}) 로부터 원래의 궤적을 복원하도록 학습되며, 학습에는 모든 waypoints에 대한 MSE loss를 이용합니다.
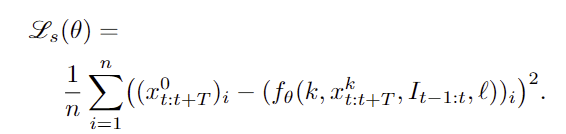
Action Execution
다음은 앞선 과정을 통해 예측한 2D waypoints를 3D 공간으로 변환하여 실제로 로봇을 실행하는 과정입니다.
1. 2D-to-3D Projection
먼저 2D waypoints를 실제 3D로 변환해야하며 이를 위해 카메라의 intrinsic 파라미터와 해당 픽셀의 depth 값을 사용합니다. 3차원 공간으로 역투영하는 식은 아래의 식으로, D(x_i)는 x_i 픽셀의 depth 값, K는 카메라의 intrinsic matrix, \tilde{x}_i는 homogeneous 좌표를 의미합니다.
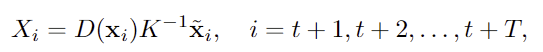
2. Grasp Pose Estimation
저자들은 기존 연구를 따라 GraspNet과 grasp samplers를 이용하여 grasp pose를 정교화하였따고 합니다. 기하학적 특징을 기반으로 후보 grasp pose 집합 \mathcal{G} 생성한 뒤, 앞서 3차원으로 역투영한 point X_t와 가장 가까운 grasp 후보 G*를 선택합니다.
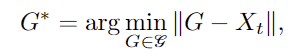
Experiments
실험 파트에서는 A0 모델 구조를 검증하고 다양한 작업에서 성능을 분석하는 것을 목표로 합니다. 구체적으로 point기반 affordance 예측의 효과와 사전학습의 효과를 확인하고, 다양한 로봇 플랫폼으로의 전이 가능성을 검토하며, 최신 VLM 및 VLA 방법론과의 성능을 비교합니다. 저자들은 사전 학습을 위해 A100(80GB) 4대를 사용하여 5일간 80,000스텝을 학습하였으며, fine-tuning은 50시간 동안 30,000스텝으로 학습하였습니다.
Effectiveness of Pre-training
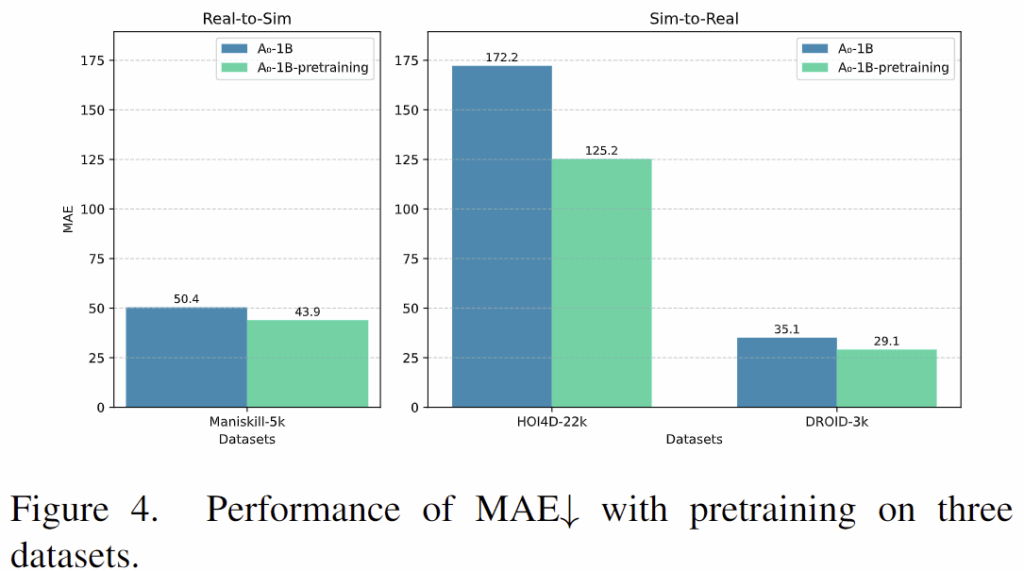
저자들은 100만개의 contact ppoint 데이터로 사전학습하여 언어 지시문에 대한 초기 contact point 예측 능력을 평가하기 위해 Real-to-Sim(HOI4D와 DROID 데이터로 학습 후 ManiSkill에서 평가)과 Sim-to-Real(ManiSkill로 학습 후 HOI4D와 DROID 데이터에서 평가)을 평가하였습니다. 위의 Figure 4가 이에 대한 정량적 결과로, 사전학습을 통해 MAE가 감소하는 것을 보였습니다.
Effectiveness of Network Structure
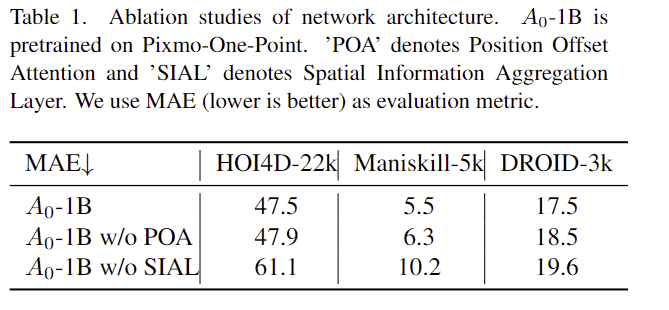
위의 Table 1은 A0의 구조에 대한 ablation study 결과로, Position Offset Attention과 Spatial Information Aggregation Layer가 성능 개선에 효과가 있음을 보였습니다.
RealWorld Experiments
다음은 A0가 실제 세계에서 작동 가능한지를 평가한 실험으로, 2D affordance-based 방식인 MOKA와 ReKep, end-to-end 방식인 \pi_0와 RDT와 비교하였으며, 다양한 로봇 플랫폼(Franka Emika, Kinova Gen3, Realman, and Dobot X-Trainer)으로의 일반화 가능성도 평가하였습니다.
각 로봇은 RGBD 카메라로 구성되어있으며, 테스트 프로토콜은 4개의 가정 환경의 작업(a: 서랍열기/b: 접시에 물건 올리기/c: 버튼 누르기/d: 화이트보드 쓸기)으로 구성하였으며, 모든 작업은 20번 시도하였을 때의 성공률을 구하였습니다. Figure 5는 1열과같이 입력 이미지가 주어졌을 때, 2D affordance prediction을 수행한 뒤(2열), 로봇팔로 action을 수행(3~6열)한 결과입니다.

Compare with 2D Affordance Methods
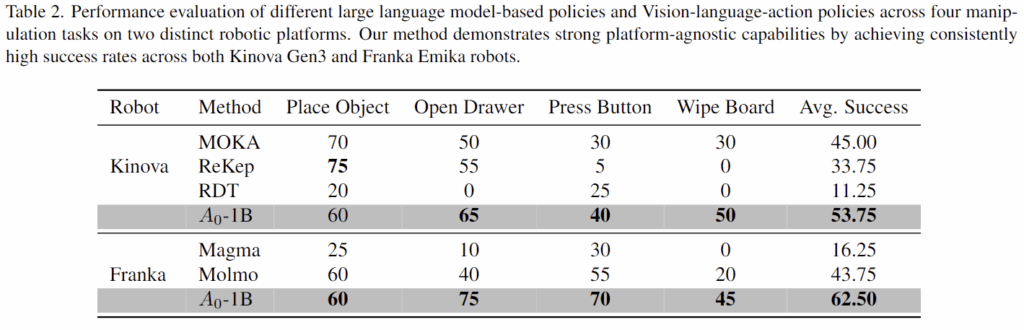
저자들은 제안한 방법을 2D 어포던스 기반의 기존 기법(MOKA, ReKep)과 비교하여 공간적 affordance 이해능력을 확인하였으며, VLM 기반 2D 포인트 예측 기법(Molmo, Magma)에 적용한 결과와 비교하여 action execution모듈을 평가하였습니다. Table 2는 이에 결과를 리포팅한 표로, 저자들이 제안한 방법은 trajectories 정확도가 중요한 Wipe Board, Open Drawer 등에서 기존 방법보다 월등히 높은 성능을 보였으며, Kinova와 Franka 두 로봇 플랫폼 모두에서 성능이 개선됨을 확인하였습니다. 그러나, Place Object 작업의 경우 MOKA와 ReKep 대비 성능이 다소 저하되었는데, 이는 기존 연구 방식이 SAM과 GPT-4 같이 실제 물체 데이터에 대한 대규모 데이터로 사전학습된 vision 기반 모델을 사용하였기 때문이라고 저자들은 분석하였습니다.
Compare with Vision-Language-Action Methods
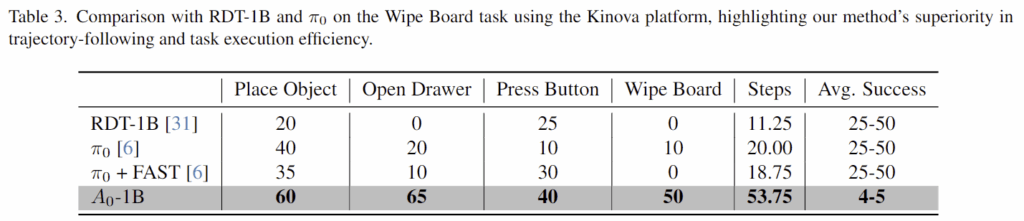
다음은 최신 VLA 모델인 RDT-1B와 \pi_0와 비교한 결과입니다. RDT-1B는 모방학습을 위해 10억 개의 파라미터를 가진 Diffusion Transformer로 100만개 이상의 로봇 작업 데이터로 사전학습되었으며, \pi_0는 사전학습된 VLM에 새로운 flow matching 구조를 설계하여 인터넷 규모의 지식을 전이시킵니다. trajectory 기반 작업에서 저자들이 제안한 방식의 효과를 입증하기 위해 각 작업당 5개의 이미지-action 데이터를 수집하였으며, 이때 데이터는 3인칭 view와 손목 카메라가 포함됩니다. Table 3은 이 두모델을 fine-tuning시켜 Kinova 로봇에 적용한 결과로, 저자들이 제안한 A0는 기존 방법론대비 성공률이 33.75% 향상되었으며, 특히 trajectory가 중요한 “wipe board” 작업에서 기존 방법론보다 40% 이상 개선이 이루어졌음을 보였습니다. 또한 기존 방법론들이 25~50번의 step을 거치는데 반해, A0는 4~5개의 waypoint 예측으로 충분한 작업이 가능하였음을 통해 속도도 개선하였음을 어필합니다.