안녕하세요, 70번째 X-Review입니다. 이번 논문은 2025년도 ICCV에 올라온 MultiADS: Defect-aware Supervision for Multi-type Anomaly Detection and Segmentation in Zero-Shot Learning 입니다. 바로 시작하도록 하겠습니다.
1. Introduction
최근 Anomaly Detection 관련한 연구들은 CLIP이나 DINO와 같은 pre-trained된 모델을 활용하는 추세입니다.
위 Fig1의 (a)가 그 예시인데, 예를 들어 CLIP 기반으로 하는 방법론들은 CLIP이 학습한 knowledge를 anomaly detection과 segmentation task에 맞게 사용하고자 합니다. 이를 위해서 그림과 같이 normal 상태와 anomaly 상태를 각각 설명하는 text prompt를 지정한다음에(그림에서 보이듯이 A photo of perfect [cls]라던지, A photo of [CLS] with defect 등), 이 입력 영상으로부터 얻은 embedding과 normal, anomaly text prompt로부터 얻은 average text embedding과의 유사도를 비교하는 식이죠.
그런데, 이런 방식은 pre-trained된 VLM에 이미 내제된 defect 유형과 같은 anomaly detection에 특화되어 있는 knowledge를 제대로 활용하지 못한다는 한계가 있습니다. 즉, 기존 방법론은 anomaly에 대한 prompt를 구성할 때 여러 종류의 결함을 그냥 하나로 통틀어서 ‘defect’라던지 ‘damage’라고 칭해서 사용해버린다는 것입니다. 또, 특정 domain에 맞춰 model을 finetuning해버리기에 train set에 overfitting되어 정확한 detection과 segmentation에 필요한 기존 knowledge를 잃어버릴 수 있다는 문제점도 존재합니다.
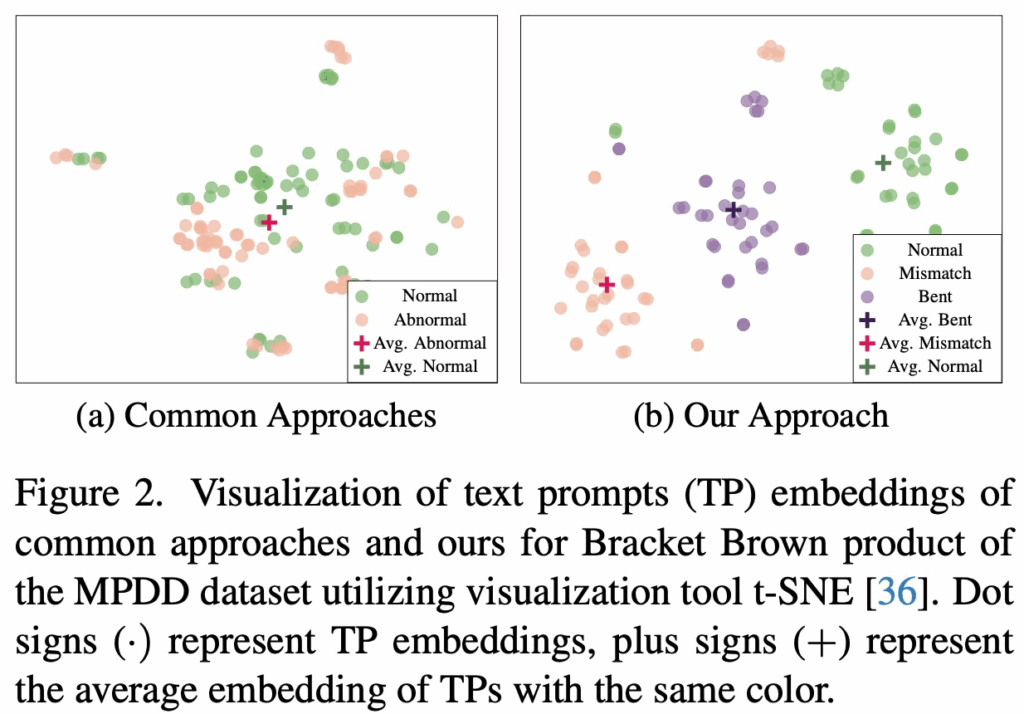
위 Fig2 (a)에서 볼 수 있듯이, 기존 방법론들은 초록색 점인 normal embedding들와 핑크색 점인 abnormal embedding이 있을 때 결국 image embedding과 유사도를 계산하는 과정에서 사용하는 것은 평균낸 avg abnormal, normal embedding을 사용하게 되는데 이는 굉장히 가까이 위치해있는 것을 볼 수 있습니다. 즉, defect 각각의 세부적인 information이 손실된다는 것이죠.
이런 점을 해결하기 위해 본 논문에서는 MultiADS라고 하는 zero-shot 기반 multi-type anomaly detection/segmentation 방법론은 제안합니다.
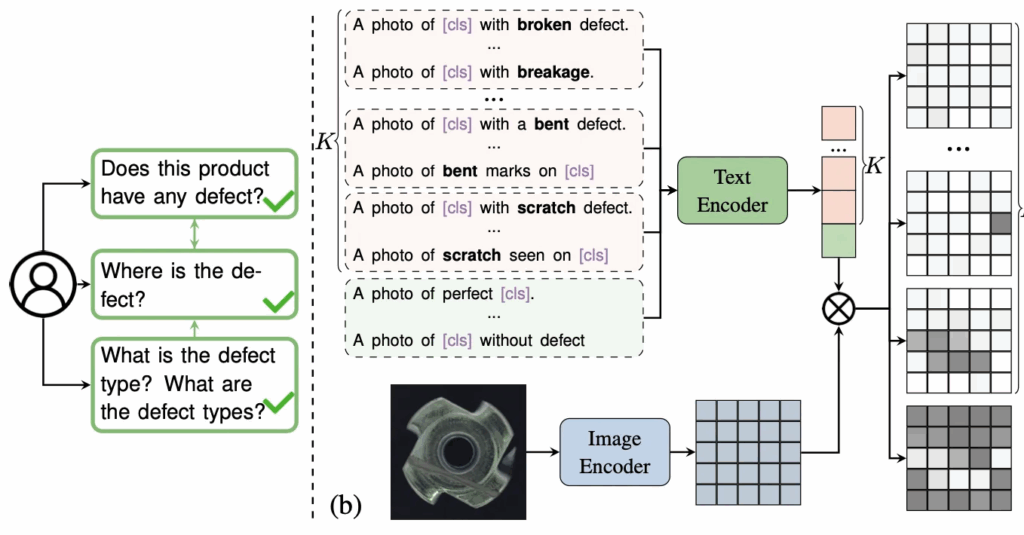
위 그림에서 대략적인 구조를 볼 수 있는데, 이 MultiADS는 기존처럼 pre-trained된 VLM을 사용하되, ‘broken’이라던지, ‘scratch’라던지, ‘bent’와 같은 결함 유형을 반영한 text embedding을 사용하고 있습니다. 즉, 기존과 다르게 단순 제품이 normal인지 anomaly인지 판단하는 것을 넘어 어떤 defect인지 묻는 질문에 답할수도 있습니다. 추가로, 아까 Fig2의 (b)부분을 보면, 제안된 MultiADS가 latent space에서 정상 상태와 다른 결함 유형들을 명확히 구분하고 있음을 확인할 수 있습니다. 이제 아래 method 단에서 MultiADS에 대해 자세히 살펴보도록 하겠습니다.
2. MultiADS Approach
짧게 본 task setting에 대해 짚고 넘어가도록 하겠습니다. 여기서 다루는 task는 Binary Anomaly Detection and Segmentation(이하 BADS)이자, Multi-type anomaly segmentation (MTAS)입니다. BADS task는 영상이 들어오면 이 영상에 이상이 있는지 여부를 판단하는 동시에, 그 이상이 위치한 영역을 segmentation하는 task라고 보시면 되구요, MTAS는 각 image가 단순 정상/이상을 판단하는 것을 넘어 여러 결함 유형을 포함할 수 있는 가정을 가지기에 multi label segmentation mask를 output으로 뱉는 것이 목표입니다.
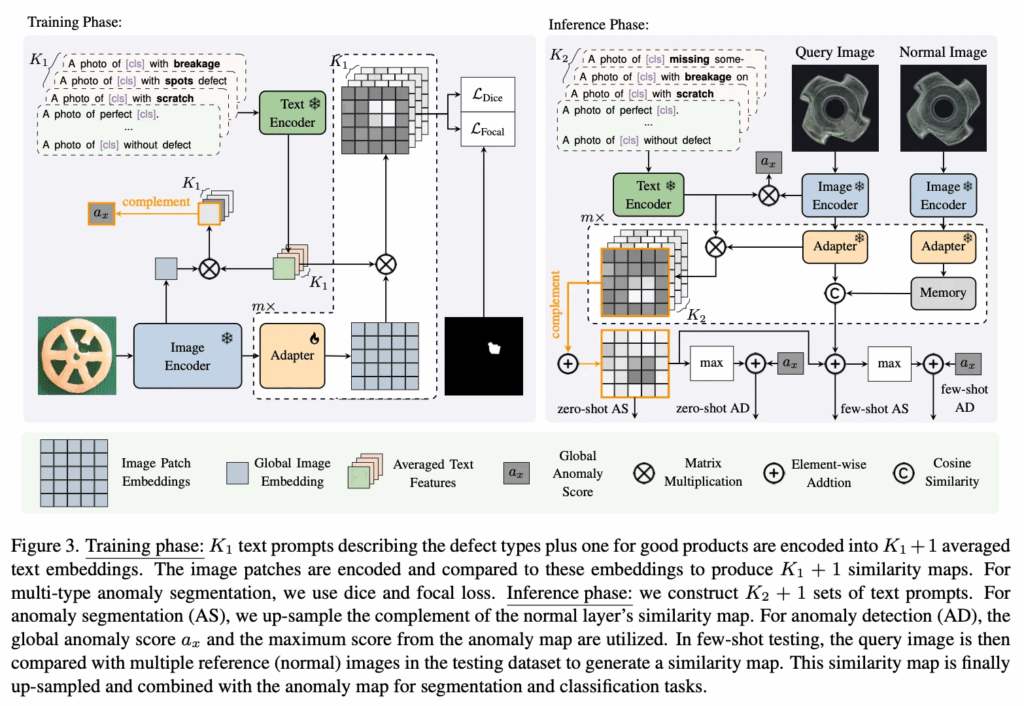
위 그림3이 제안된 MultiADS의 동작 과정을 보여줍니다. CLIP 기반의 모델로 각 결함 유형에 대한 text feature와 image feature를 정렬하도록 학습이 되며, zero-shot, few-shot setting 둘 다 가능하도록 설계가 되어 있습니다.
Knowledge Base for Anomalies
Anomaly와 더불어 어떤 defect인지도 탐지하기 위해서 우선적으로 이에 대한 정보를 수집하였습니다. 구체적으로는 MVTec-AD, VisA, MPDD, MAD, Real-IAD 등 기존 industrial anomaly detection 데이터셋의 meta-data를 활용해 각 제품의 대한 결함 정보를 수지을 하였습니다. 이 과정에서 결함의 크기와 shape과 같은 속성 정보도 같이 수집하였습니다. 이 KBA를 구축할 때 유사한 defect를 상위 class로 묶어 표현을 했는데, 예를 들어서 bent나 bent lead, bent wire는 모두 bent라는 상위 defect 유형에 포함을 시키고, scratch나 stractch head, scratch neck는 모두 scratch로 묶었습니다.
Defect-aware Text Prompts
이렇게 구축한 KBA를 기반으로 Defect-aware Text prompt를 만드는데요. Fig3에서 보이듯이 “A photo of [cls] with breakage”라던지 spots, scratch처럼 KBA에 저장된 defect 정보를 사전 지식으로 활용해 각 defect 별 text prompt를 생성해 사용하게 됩니다.
2.1. Training Phase
2.1.1. Image and Text Embedding
Fig3을 보면 그림이 training phase와 inference phase로 구분이 되어 있는데, 먼저 왼쪽에 training phase부터 살펴보도록 하겠습니다. zero-shot 세팅이기에 학습과 테스트 때 사용하는 데이터는 서로 다른 데이터셋이며, 그림에서 보이듯이 각각의 prompt set 개수를 K_1와 K_2로 구분합니다.
입력 영상이 들어오면 image encoder를 태워 image embedding을 추출하게 되구요. 이때 image patch embeddings와 global embedding을 함께 뽑게 됩니다. 또, k_1+1 개의 text prompt set을 준비하게 되는데. +1인 이유는 normal 상태를 나타내는 prompt가 필요하고 나머지 K_1는 각기 다른 defect 유형에 해당합니다. 이 각각의 prompt set들도 CLIP text encdoer로 들어가게 되고 겷마 유형에 해대 평균을 내어 각각의 prompt embedding이 나오게 됩니다.
2.1.2. Aligning Image Patches and Text Prompts
원래 CLIP의 visual encoder는 image level의 global embedding과 text embedding을 정렬하도록 학습이 되는데요. 근데, 이 MultiADS에서는 patch level의 feature와 text embedding의 alignment를 맞춰야 하기 때문에 adapter를 사용하여 CLIP의 image encoder와 text encoder에서 추출한 feature를 같은 공간으로 맞춰주고자 하였습니다. 이 과정에서 얻은 유사도 맵 S_i는 원본 영상 크기에 맞게 upsampling된 다음 gt segmentation mask M’_x와 loss 계산을 하게 됩니다. 학습 과정은 매우 단순하게 이게 끝입니다.
2.1.3. Training Objective
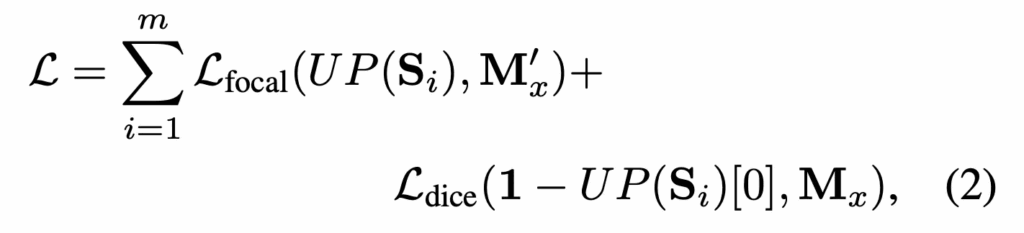
loss에 대해 살펴보자면, MultiADS는 segmentation 학습을 위해 focal loss와 dice loss 둘을 사용하게 됩니다. Focal Loss는 class 불균형이 있을 때 도입하는 loss인데, 여기서는 normal image가 학습 중에 abnormal image보다 훨씬 많기 때문에 focal loss를 사용하였습니다. 또 anomaly image 자체의 segment pixel 영역이 엄청 작기 때문에 dice loss를 적용하였습니다.
2.2. Inference Phase
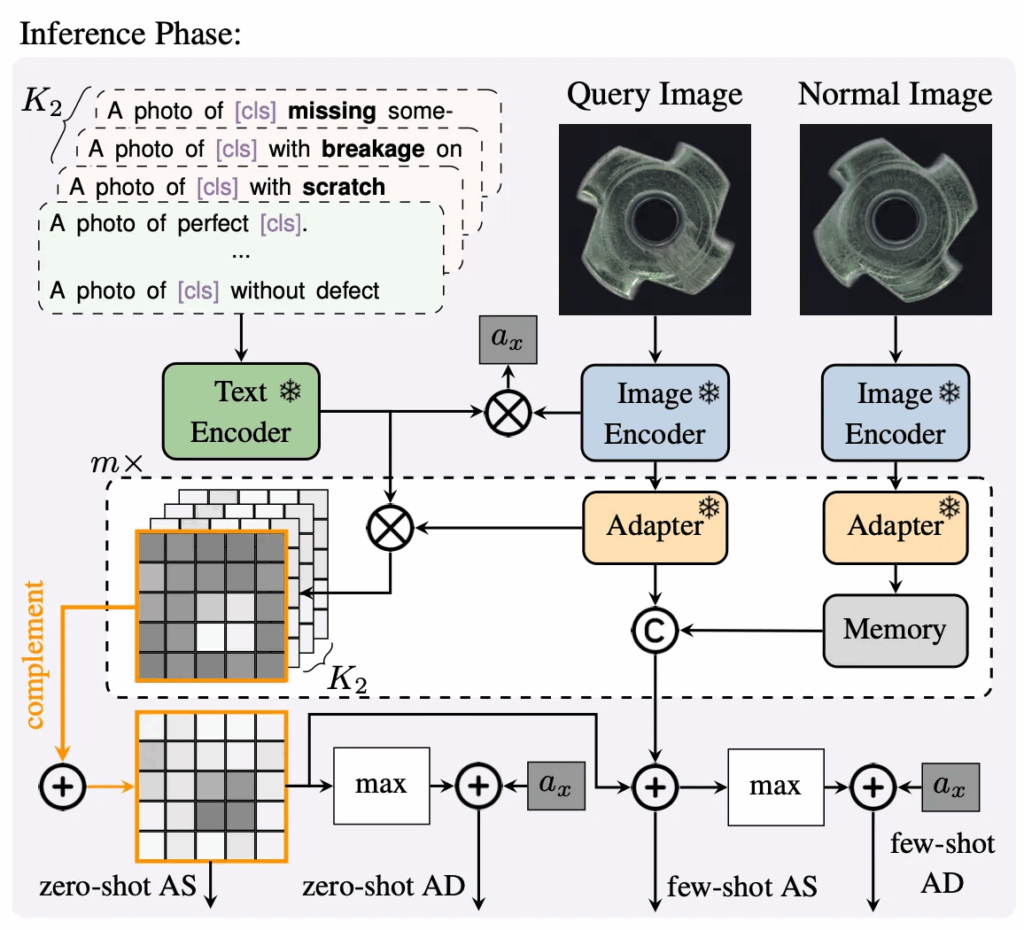
다음은 inference 부분을 살펴보도록 하겠습니다. 테스트 단에서는 train 한 모델을 대상으로 target 데이터셋에서의 성능을 평가하는데요, 우선 target domain에서 defect가 없는 normal 상태를 나타내는 1개의 prompt와 서로 다른 defect를 나타내는 K_2개의 prompt를 합쳐 총 K_2+1개의 text prompt set을 만들게 됩니다. 학습 때와 마찬가지로 각 prompt set은 CLIP text encoder를 통과해 text embedding을 변환되게 되며, test할 query image는 CLIP image encoder와 adapter를 거쳐서 text embedding과 유사도를 계산하여 similarity map S를 뽑아내게 됩니다. 각 유사도 map은 input image 크기로 upsampling되게 되구요.
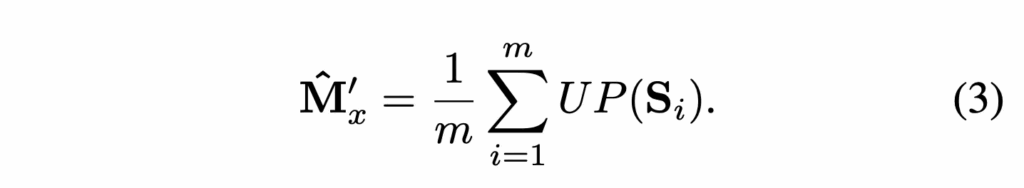
위 수식과 같이 m개의 layer에 대해서 뽑힌 Similarity map S_i이 있으면 이를 upsampling해 평균내어 segmentation map M을 만들게 됩니다. 이 map의 각 채널이 normal 또는 특정 defect 유형에 해당하는 score를 나타냅니다.
또, anomaly map을 만들게 되는데, 위에서 만든 \hat{M}’_x은 결함 유형을 반영한 map이라고 하면 anomaly map은 단순 해당 pixel이 anomaly인지 normal인지 나타내는 map이라고 보심 됩니다.
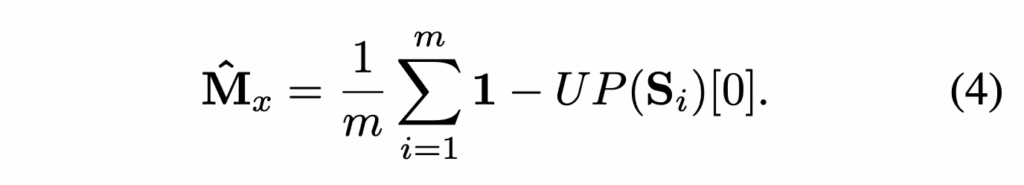
수식으로는 위 식4와 같이 진행이 되는데, 유사도 맵의 첫 번째 채널 (normal class)를 1에서 빼서 defect map을 만들게 되고 마찬가지로 m개의 stage에서 생성된 map들을 전부 평균내어 최종 anomaly map M을 계산하게 됩니다.
추가적으로, CLIP image encoder에서 얻은 global image embedding z_x도 K_2+1개의 text embedding과 비교해 global 유사도 score를 계산하게 되고, 이 score를 1에서 빼서 anomaly score a_x를 계산하여 image-level의 평가도 가능하도록 하였습니다.
3. Experiments
3.1. Results
3.1.1. Multi-type Anomaly Segmentation
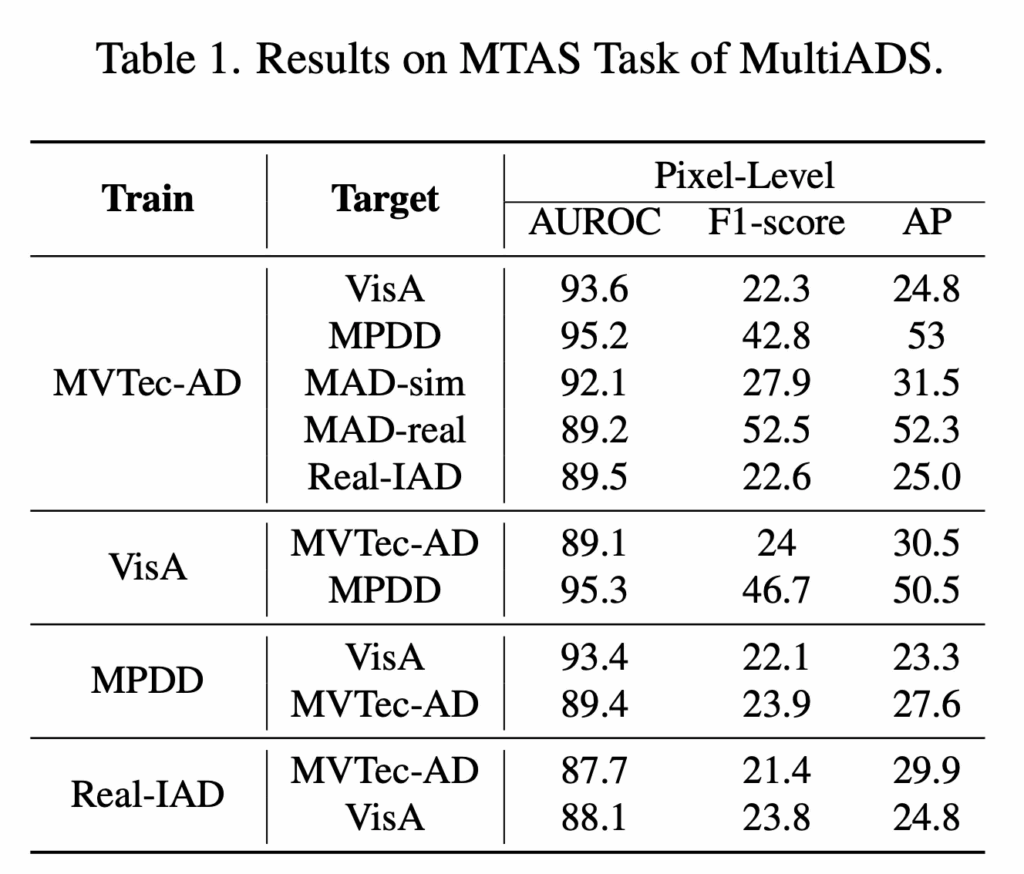
이제 실험 부분을 살펴보도록 하겠습니다. 먼저 표1을 보시면, 본 논문에서 다루고 있는 Multi-type Anomaly Segmentation task에서의 MultiADS 성능이 나와있습니다. 이 task는 image내에서 defect 위치 뿐만 아니라 각 pixel의 defect 유형까지 구분하는 task였는데요. 기존 연구에서는 이런 task를 수행하지 않았기에 MultiADS를 이 task의 새로운 baseline으로 제시했다고 언급하고 있습니다. 표를 보시면 pixel level의 AUROC 기준으로는 모든 데이터셋에서 성능이 높은 것을 확인할 수 있습니다. AP측면에서는 target dataset이 MPDD일 때나 MAD-real일 때 50정도로 다른 데이터셋 성능(20~30)정도에 비해 좋은 성능을 보이고 있는데요. 이들은 다른 데이터셋에 비해서 defect 유형이 좀 적은 편에 속하는 데이터셋이라 그런 것으로 보입니다. 이에 반해 defect 유형이 다양한 Real-IAD나 VisA의 경우에는 AP가 다소 낮은 것을 확인할 수 있죠. 엄천 높은 성능은 아니지만 MultiADS는 어느정도 다양한 결함 유형을 구분하고 있음을 입증하고 있습니다.
Multi-type Anomaly Awareness
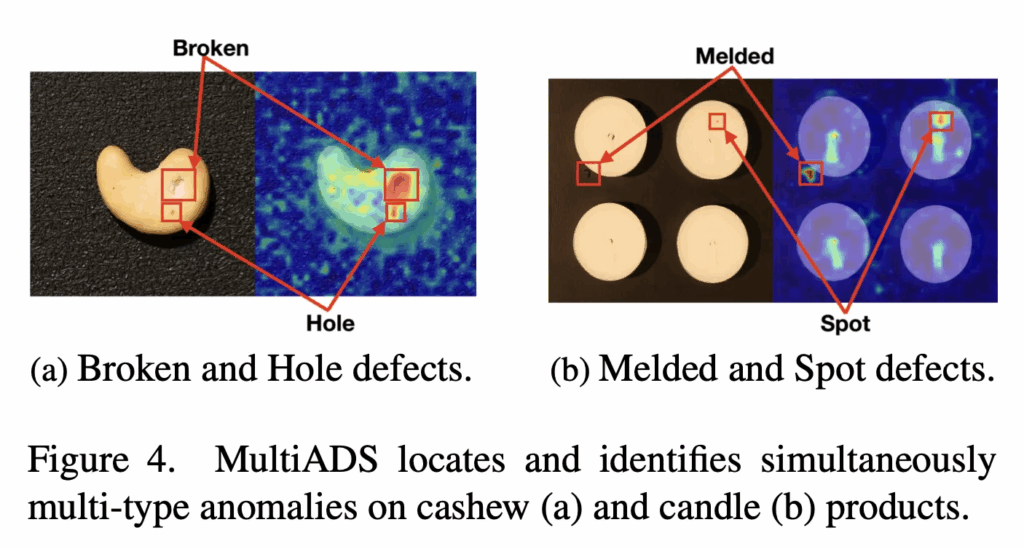
위 Fig4에서는 하나의 image안에 여러 defect 유형이 동시에 존재하는 sample들인데요. (a)는 broken과 hole이 들어있는 경우이고 (b)는 melded과 spot이 동시에 존재하는 경우입니다. 이 정성적인 결과는 제안된 MultiADS가 이들 각각의 결함에 대해 정확하게 위치는 파악하고 유형까지 구분하고 있음을 보여줍니다.
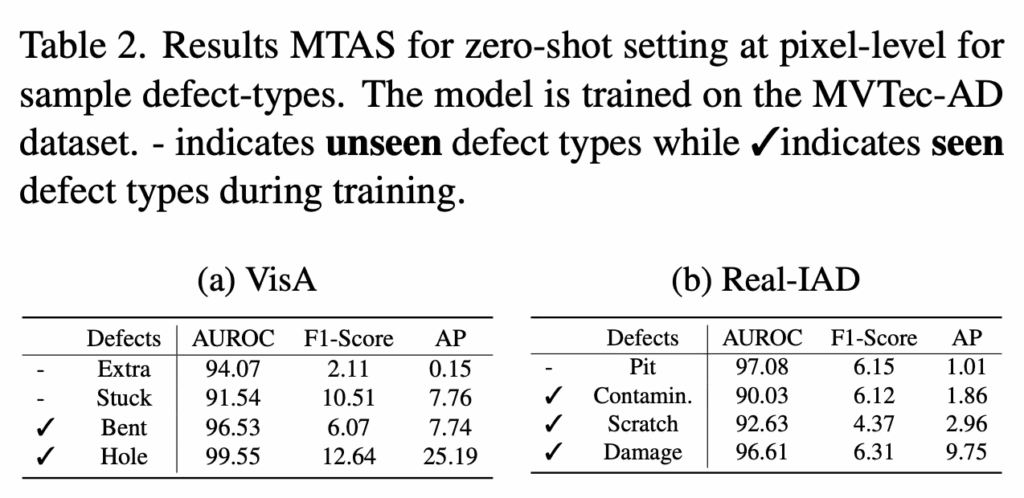
또 table2에서는 학습 단에서 본 적 있는 (seen) defect 유형과 본 적 없는 (unseen) defect 유형 각각에 대한 성능을 보여주고 있습니다. 표에서 체크 표시된게 seen이고 – 표시가 unseen입니다. 결과를 보시면, seen defect인 bent나 hole, scratch, damage같은 경우에는 학습 데이터셋(MVTec-AD)에 이미 존재하는 결함 유형인데요. 이에 대해서는 모양이나 특성이 유사하기 때문에 비교적 성능이 높게 나온 것을 확인할 수 있습니다. (그래도 hole을 제외하고는 나머지 seen 성능도 좀 아쉽긴 한 정도입니다.) 하지만, unseen인 extra나 stuck의 경우에는 학습 데이터에 없기에 성능이 떨어진 것을 확인할 수 있습니다. 그 대신 pit 같은 경우에는 AUROC가 굉장히 높은데(seen보다 높음), 이는 모양이나 패턴이 학습했던 다른 defect와 유사하기에 나온 결과라고 해석해볼 수 있겠습니다.
Ablation Study
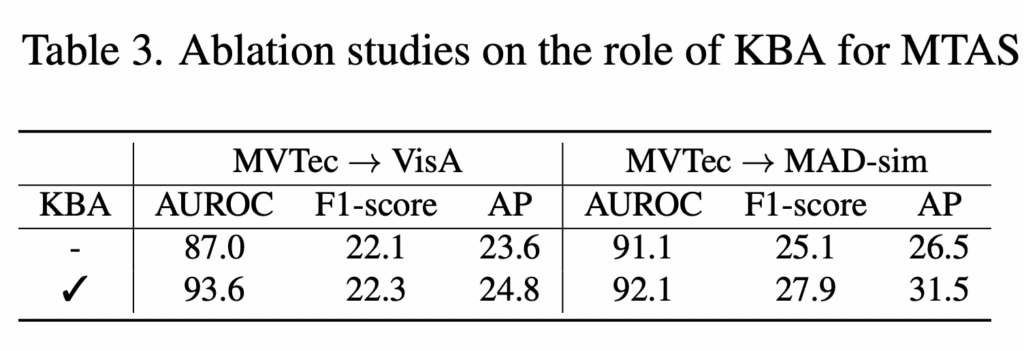
다음으로는 간단한 ablation study인데, 구축했던 KBA가 얼마나 성능에 기여하는지 확인해본 실험입니다. Table3에 따르면 KBA로 만든 detail한 defect text prompt를 사용한 경우 성능이 전반적으로 상승하는 것을 확인할 수있습니다. 즉, defect 유형별로 모양이나 크기 등의 속성을 반영하여 만든 prompt가 단순 일반적인 prompt보다 결함을 구분 능력을 향상한다는 것을 입증합니다.
3.1.2. Binary Detection and Segmentation
ZSAD
다음으로는 zero shot anomaly detection 성능을 pixel level과 image level에서 확인한 실험입니다. 위 table4를 보시면 되는데, 거의 대부분의 데이터셋과 지표에서 sota를 달성하였습니다.
FSAD
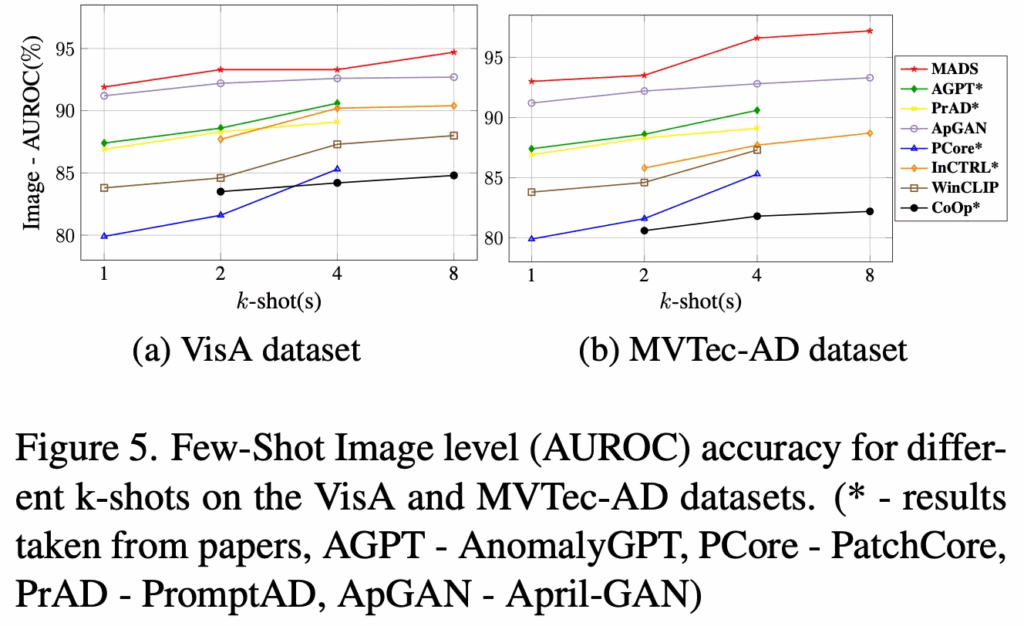
방금 위 table은 zero shot 성능이였으면, 위 fig5에서는 few-shot 결와인데요. 두 데이터셋에 대한 그래프가 있는데, x축은 shot 개수(1, 2, 4, 8)이고, y축은 성능(AUROC)입니다. 실험은 MVTec-AD에서 학습해 VisA에서 test하거나, 그 반대로 수행이 되었습니다. 보시면 빨간색 그래프가 제안된 MultiADS인데 가장 높은 성능을 보이는 것을 확인할 수 있었습니다. 다른 데이터셋에 대해서도 동일하게 좋은 성능을 보였다고 하는데, 이렇게 few-shot 세팅에 대해 좋은 성능이 보이는 이유에 대해서는 MultiADS가 defect awareness에 기반하여 detection을 확장할 수 있다는 점 때문이라고 합니다. 즉, 기존 anomaly다 아니다만 판별하던 기존 방법론과 다르게 결함별 유형을 학습했기 때문이라는 것이죠.
안녕하세요, 좋은 리뷰 감사합니다.
Inference 과정 관련해서 질문이 있는데, 그림에 세 번 정도 ax가 등장하는 것이 보이고 리뷰 본문을 통해 이게 anomaly score라고 보았고 이 ax가 zero-shot AD와 few-shot AS를 수행할 때 사용되는 것 같은데 구체적으로 어떻게 사용되어 최종 결과가 나오는 것인지 궁금합니다. 또 이게 global score인 것 같은데 segmentation에는 어떻게 사용하는 건가요?
감사합니다.
안녕하세요? 댓글 감사합니다.
네 ax는 global anomaly score라고 보심 됩니다. ax은 일정 threshold 이상이면 anomaly라고 판단하고, 이하면 normal이라고 판단하는 식입니다. 즉 image-level ad 수행하는 것이죠. pixel level의 output을 낼 때는 few-shot인 경우에만 해당이 되는데 normal image를 통해 얻은 reference map과 비교해 query image의 map을 보정하는 식으로 사용됩니다.