오늘 소개드릴 논문은 CVPR2025에 게재된 NVIDIA 논문이고 제목에서도 보시면 아시다시피 효율적인 VLM을 만드는 방법에 대해서 소개하는 논문입니다. 근데 제가 논문을 검색해서 찾을 때는 CVPR 포멧이 아닌 그냥 arxiv에 올라온 날 것 그대로의 버전을 읽은 바람에 그 버전의 수식과 그림자료들로 리뷰를 작성할 것 같네요.
그리고 엔비디아에서 쓴 논문이기도 하고 효율적인 VLM과 관련된 논문이라길래 한번 궁금해서 읽어봤는데 논문의 중간중간 내용이 너무 기술개발쪽 워딩으로 치우치는 바람에 제가 중간에 읽다가 포기한 부분들도 있긴 합니다ㅠ. 그리고 VLM이다보니 다루는 task도 많고 최대한 최신 기술들을 적용하려고 하다보니 자신들이 사용한 이전 기술들은 슥 언급만하고 넘어가는지라 이번 리뷰에서 논문의 모든 내용을 꼼꼼하게 다루기는 어려울 듯 하구요. 최대한 논문의 핵심 내용을 위주로 리뷰를 작성하려고 하니 한번 읽어보시고 관심있으시면 전체 논문을 읽어보시길 권해드립니다.
Intro
요즘 나오는 Vison Language Model이 참 정확도도 좋고 야무져서 다양한 task에서 널리 활용되고 있다만, 해당 모델들의 efficiency를 향상시키기 위해 집중하는 연구들이 별로 없다는 식으로 저자들은 이야기를 시작합니다.
그중에서 우선 기존 VLM의 문제점 중 하나는 VLM은 학습하는데 시간이 너무 오래 걸린다는 단점이 있습니다. 실제로 SOTA VLM 중 하나인 LLAVA one vision model의 경우 7B 크기의 모델을 학습시키는데 있어 400개의 GPU를 활용해서 하루 동안 학습을 해야한다고 합니다. 바꿔 말하면 1개의 GPU로 400일 동안 학습시켜야한다는 것이죠? (즉 웬만한 연구자들한테는 VLM 연구하기에 입장컷이 너무 높다는 것.)
두번째 문제점으로는, VLM이 아무리 활용도가 높다고 해도 처음에 pretraining한 모델을 그대로 다 가져다가 사용할 수는 없고 의료쪽과 같은 특정 모달리티의 경우에는 fine-tuning해야만 하는데 그 fine-tuning 과정 역시도 메모리를 많이 먹는다고 합니다.
실제로 아까 언급한 7B LLAVA one vision의 경우 전체 풀 파인튜닝할 때 64기가 이상의 메모리가 필요합니다. 물론 full-finetuning보다는 LoRA 같은 adapter를 추가해서 학습하는 식으로 학습에 사용되는 메모리를 줄일 수 있기에 2번째 문제점에 대해서는 저자들이 조금 과장을 보태는 감도 없지 않아있네요.
아무튼 이렇게 학습에 사용되는 비용들 뿐만 아니라 VLM 자체가 무겁긴하니깐 노트북이나 임베디드 보드 같은 연산파워가 제한된 곳에서 너무 큰 VLM을 직접적으로 활용하는데에도 어려움은 있긴 합니다. 그러니깐 결론은 VLM이 너무 무겁다. 그래서 학습 코스트도 좀 줄이고 추론 속도도 줄이면서 성능은 덜 떨어지게 하고 싶다는 것이죠. 반대로 말하면 성능을 더 높이면서 오히려 들어가는 연산량은 줄어든다?라고도 볼 수 있겠네요.
그래서 저자들은 자신들의 매우 효율적인 학습 기법 및 연산 과정들을 등을 적용한 NVILA라는 VLM을 제안합니다. 우선 VILA라는 명칭으로 CVPR2024에 엔비디아에서 논문을 낸적이 있구요. 그 VILA를 활용해서 이곳저곳으로 발전시켜서 후속 논문들을 내고 있는 듯 한데 이번에 리뷰할 NVILA라는 논문도 이 VILA를 더 효율적으로 만들었다? 정도로 보시면 될 것 같습니다.
우선 논문에서 계속 강조하고 밀고나가는 표현이 있는데 이는 바로 “Scale then Compress” 입니다. 여기서 Scale은 Scale up을 하여 정확도를 향상시키고 그렇게 Scale up을 한 다음에 압축해서 효율성을 끌어올린다는 전략인 것이죠.
이것이 모델의 추론 과정에서도 포함되는 개념이고 학습 때 데이터 처리할 때도 동일한 개념을 적용합니다. 그럼 방법론에 대해서 바로 알아보도록 하시죠.
Efficient Model Architecture
우선 저자들이 제안하는 모델 구조부터 살펴보겠습니다. 모델의 구조는 아래 그림과 같습니다.
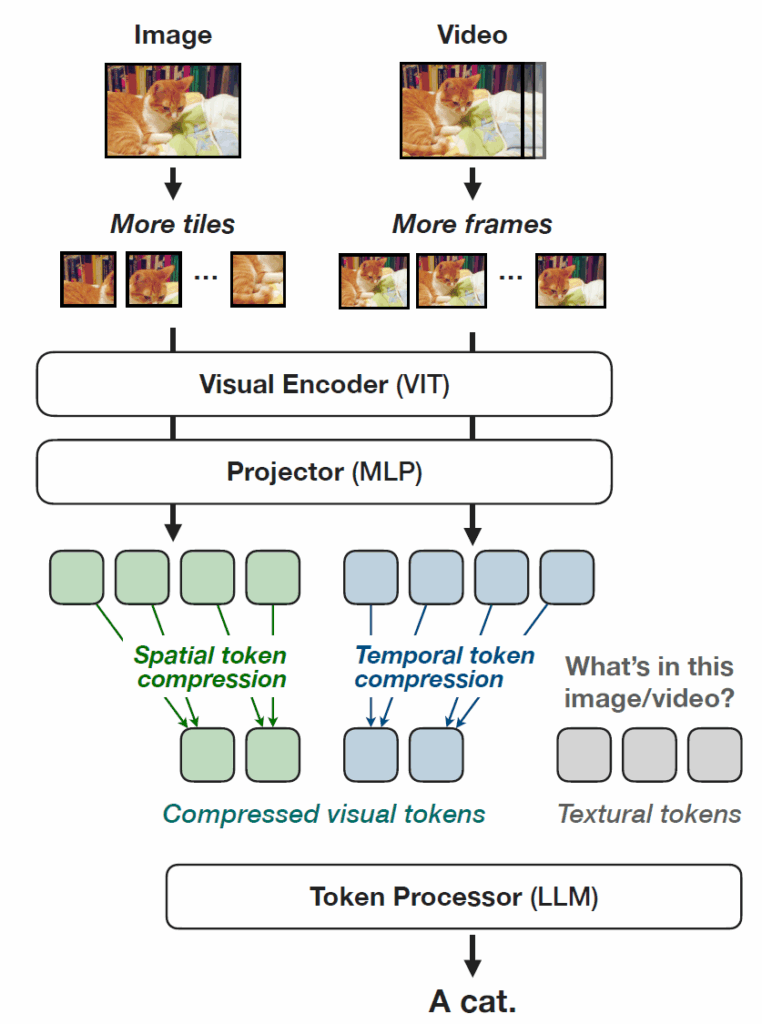
우선 VLM이다보니 Image 또는 비디오에서 Visual token을 추출하는 ViT 단이 존재하고 있고, 그다음에 Text token과의 임베딩을 정합시키는 Projector 부분, 마지막으로 Visual token 및 text token을 입력으로 하여 text token을 output으로 뱉는 LLM까지 있습니다. 우선 저자들은 Visual Encoder로는 CLIP에서 더 발전된 학습 형태인 SigLIP의 ViT를 활용하고, projector는 2개의 MLP layer를, LLM인 token processor는 Qwen2를 활용하였다고 합니다.
이러한 VLM 구조에서 이제 연산량을 많이 차지하는 부분을 찾아서 해결을 해야하겠죠? VLM의 연산을 가장 많이 잡아먹는 부분은 다 아시다시피 Visual token쪽입니다. 문장은 아무리 길어봤자 text token의 수가 그렇게 커질 수가 없지만 image의 경우 해상도가 높을수록 더 많은 visual token을 가지게 되고 이것이 video로 확장되는 순간 frame마다 visual token의 수가 늘어나는 것이기 때문에 더 많은 token이 발생하게 되는 것이죠.
그래서 기존 VLM 연구들은 이미지 해상도를 어쩔 수 없이 낮추어 사용합니다. 저자들은 자신들이 작년에 제안한 VILA를 기준으로 설명을 하는데, VILA에서는 visual token을 추출할 때 너무 제한적인 해상도를 활용하여 정보량이 역시 제한적이었다고 합니다. image resolution은 원본 영상이 어떤 ratio를 가졌는지 상관없이 448×448의 정사각형으로 resize해서 활용하고 비디오 데이터의 경우에는 sample up할 때14frame만 활용합니다.
이러한 image spatial resizing과 video의 temporal sampling 과정은 정보손실이 일어날 수 밖에 없는 구조였으며, 이로 인하여 큰 해상도의 영상과 긴 비디오를 효과적으로 처리하는 능력 역시 제한적이었습니다.
그래서 NVILA에서는 이런 부분들을 해결해야겠죠? 가장 직관적으로 해결하는 방법은 image의 사이즈를 키우고 활용하는 비디오의 프레임 수도 늘리는 것입니다. 저자들의 원문 문장을 보면 더 직관적으로 이해되실겁니다.
“we advocate for the “scale-then-compress” paradigm, where we first scale up the spatial/ temporal resolutions to improve accuracy, and we then compress the visual tokens to improve efficiency.”
정리하면, 해상도 키워서 성능 끌어올리고, 그렇게 해상도 키웠을 때 발생하는 연산량 증가는 visual token을 압축해서 해결하자는 말입니다.
Spatial Scale then Compress
그럼 우선 이미지 레벨에서 어떻게 scaling하고 Compress하는지를 살펴보겠습니다. 저자들이 Scale up을 할 때 단순히 입력 영상을 upsampling해서 ViT에 태우겠다!는 아닙니다. 그렇게 하면 입력 해상도의 제곱배만큼 연산량이 증가하는 ViT의 self-attention 특성 상 너무 비효율적이게 되버리기도 하고, 입력 영상 자체가 small resolution이라면 이를 억지로 키운 영상만을 활용하는 것은 오히려 성능에 부정적일수도 있기 때문입니다.
그래서 저자들이 도입한 방식은 ECCV2024에 게재된 S^{2} 라는 모델의 tiling 기법을 활용하는 것입니다. 아래 사진은 S^{2} 논문에서 가져온 ViT forward 그림입니다.
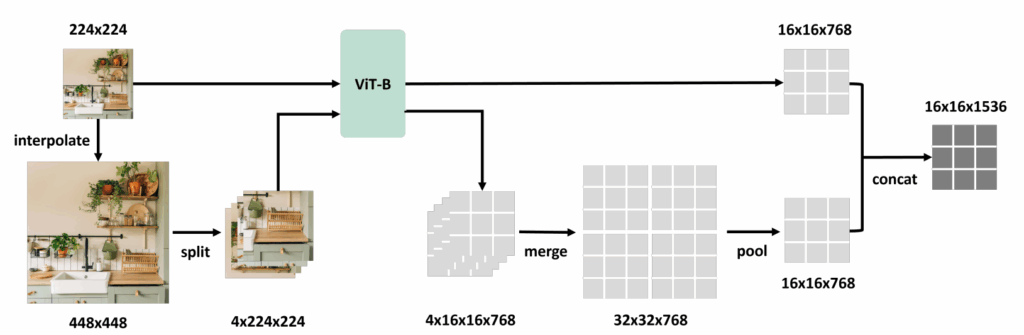
저기 그림에서는 만약 224×224로 사전학습된 ViT가 있다면 입력 영상을 224×224 뿐만 아니라 448×448로 키운다음 이를 다시 4개의 224×224로 1/4 조각씩 쪼개어 ViT에 태우는 것입니다. 이렇게 ViT 타고 나온 visual token들을 다시 이어붙여서 원래의 shape을 가지도록 만들어준 뒤 224×224의 입력 feature와 동일한 사이즈를 맞추기 위해 고해상도 visual token을 pooling해서 채널축으로 concat하는 방식이죠.
NVILA에서도 이러한 방식에 영감을 받아서, 448×448로 사전학습된 ViT와 어떠한 해상도의 input image를 주었을 때, 이를 896×896, 1344×1344로 multi-scale의 고해상도 이미지로 resize를 했다고 합니다. 그 다음 448×448 해상도를 가지는 4조각, 9조각의 image들로 나누어 ViT를 태워 visual token을 생성하는 것이죠. 그 다음에 쪼개진 visual token들을 다시 원래의 이미지처럼 이어붙인 뒤, interpolation을 통해 multi-scale feature map의 resolution을 맞춰주고 마지막으로 채널축 concat을 하는 것입니다.
근데 여기서 기존의 S^{2} 는 원본 영상의 ratio랑 상관없이 이미지를 정사각형으로 resize를 했었는데 이러한 resize 방식은 가늘고 긴, 비율을 가진 객체들한테 당연히 왜곡을 일으켜서 좋은 영향을 못준다고 합니다.
따라서 저자들은 ratio를 최대한 보존할 수 있도록 Dynamic S2라는 것을 제안하였는데, 제일 높은 해상도를 가지는 이미지에서, 정사각형으로 resize를 하는 것 대신에 동일한 aspect ratio를 최대한 유지하면서 448×448 tile로 나눠지는 해상도로 resize했다고 합니다. 사실 뭐 말이 Dynamic이지 그냥 ratio는 최대한 유지하면서 448로 나눌 수 있도록 resize를 한다는 것입니다.
그리고 재밌는 점은 아까 위에서 보여드린 S^{2} 는 high-resolution feature map (448×448로 뽑은 feature)를 low-resolution feature map(224×224로 뽑은 feature)과 동일한 사이즈로 pooling을 한 뒤 합치는 반면, 저자들은 오히려 모든 스케일에서 추출한 feature map들을 가장 작은 사이즈(448×448에서 추출한 feature)가 아닌 가장 큰 사이즈(e.g., 1344×1344)를 기준으로 interpolation을 거치고 concatenate하였다고 합니다. 어처피 뒤에서 compression 할 것이니 scaling up할 때는 시원하게 scaling up을 해서 visual token을 늘리자는 것인 것 같습니다.
그럼 이제 고해상도 feature map의 활용으로 인해 커져버린 visual token 수를 줄여야겠죠? 저자들은 visual token을 줄일 때 엄청 단순한 방식을 사용했는데 이는 단순히 spatial-to-channel reshape 방식으로 토큰의 수는 줄였다고 합니다. Spatial-to-Channel reshape 방식에 대해 소개드리면, 예전에 image restore task에서 아래 그림과 같이 채널축에 정보를 가지고 spatial resolution을 upsampling하는 기법들이 있었습니다(이를 파이토치에서는 pixelshuffle이라는 함수로 지원)
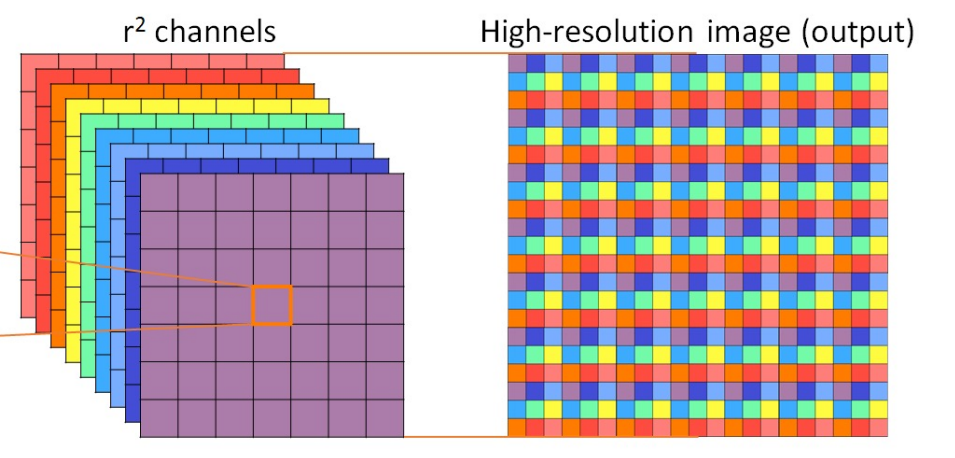
그렇다면 반대로 spatial dimension의 정보들을 channel dimension으로 변환시켜 resolution을 downsampling하는 방식도 있을 것이고, 이것이 파이토치에서 pixelUnshuffle이라는 함수로 제공이 됩니다. 저자들은 이 pixelUnshuffle 함수를 써서 spatial 정보를 대표하는 visual token들의 수를 줄였다는 것입니다.
여기서 이제 2×2 패치를 하나의 token으로 보고 reshape하였더니 성능 손실이 허용가능한 범위에서 발생하였다는 것을 VILA paper를 쓸 때 알았으며 저자들은 NVILA에서 이를 좀 더 적극적으로 활용해보려고 한 것 같습니다. 그래서 더 많은 압축을 수행하고자 2×2에서 3×3으로 압축률?을 늘렸더니 이때는 특정 task에서 성능 하락이 10%나 발생하는 등 문제점이 생겼다고 합니다.
즉 너무 공격적인 토큰 압축은 projector가 학습하는 것을 너무 힘들게 한다고 저자들은 판단하였고, 그래서 저자들은 3×3 수준의 압축 과정에서 기존의 2개의 mlp layer로만 구성된 projector만을 학습시키는 것이 아니라 vision encoder와 projector를 모두 튜닝하는 1.5? learning stage를 도입하였다고 합니다.
이를 통해 저자들은 spatial token을 감소시켰음에도 불구하고 정확도를 최대한 떨어지지않도록 복구하였으며, 결과적으로 압축 과정을 통해 뒷단의 LLM을 포함하여 전체 모델을 학습시킬 때에도 2.4배 더 빠른 학습 및 추론 속도를 가질 수 있었다고 하네요. 참고로 기존의 존재했던 학습 기반의 spatial token compression 방법론들은 1.5 단계의 additional learning stage가 있더라도 단순히 spatial-to-channel compression 방식보다 성능이 좋지 못하였다고 합니다.
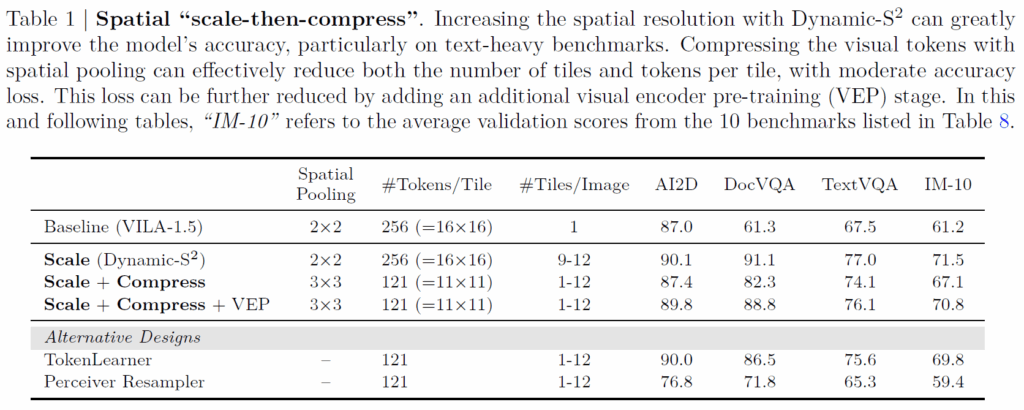
결과적으로 저자들의 scaling up과 compression 과정을 적용하게 되면 우선적으로 이미지의 고해상도 정보를 활용하다보니 text-heavy benchmark에서 30% 이상의 정확도 향상을 보았으며, 토큰의 수는 기존 baseline (이미지 한장 당 256개)보다 더 적은 수(121개)를 사용할 수 있었다고 하네요. (아래 표 참고)
Temporal Scale then Compress
다음은 Video data가 입력으로 들어올 때의 시간축에 대한 스케일링 및 압축 과정을 소개합니다. 비디오의 temporal 축에 대한 스케일링은 직관적이게도 단순히 일정한 간격으로 샘플링되는 프레임 수를 많이 가져오는 걸로 구현했습니다?즉 프레임 수를 이전에 만약 8개였다면 이를 32개로 늘렸다는 것이죠.
압축 과정에 대해서 소개드리면 비디오는 내재적으로 시간축에 대한 연속성이 있기 때문에, 저자들은 temporal averaging이라는 이전 기법을 적용하였으며, 이는 frame을 개별 그룹들로 구분을 두어 묶은 다음에 이 각 visual token들에 대해 시간축으로 pooling하였다고 합니다.
연속적인 프레임들은 종종 유사한 정보들이 많이 담겨있기 때문에 이러한 압축 방식이 시간적 중복성을 줄이면서 동시에 중요한 spatio-temporal information을 살릴 수 있었다고 하네요. 저자들은 실험적으로 4배 정도로 묶어서 압축하는 것이 어느정도 수용 가능한 성능 하락이 발생하였다고 합니다.
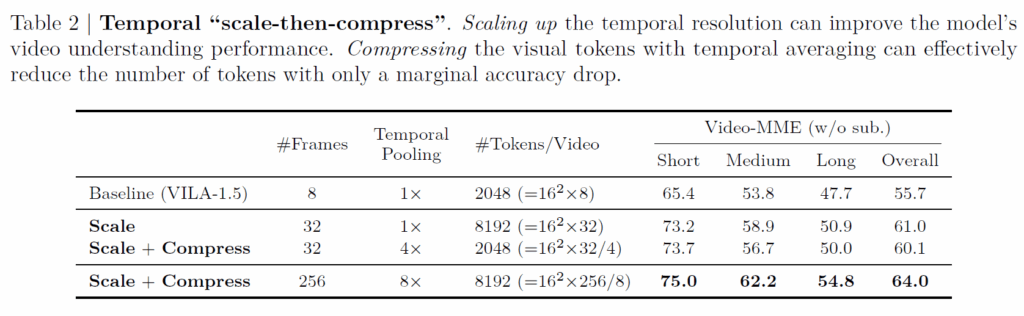
위에 표2는 temporal scaling and compressing에 대한 실험으로 기존 baseline이 8개의 frame을 사용하였다면 scale up하여 32개의 frame을 활용하였고 이때 정직하게도 기존 baseline의 2048개 visual token에서 딱 4배 증가한 8192개의 토큰 수를 가지게 됩니다.
당연히 프레임수를 늘렸기 때문에 Video MME에서 Short, Medium, Long 전체에 대해 성능이 크게 개선되는 것을 볼 수 있습니다. 그리고 연산량이 늘어나는 것을 줄이기 위해 32프레임에 대해서 4프레임씩 묶어 temporal 축으로 visual token을 pooling하는 compress 과정을 거치면 총 2048개의 visual token이 남게 됩니다.
이는 8개의 frame에 대하여 2048개의 visual token을 만들어낸 baseline과 동일한 visual token 수를 지니는 것이지만 최종적인 성능은 더 높은 것을 확인하실 수 있습니다. 근데 제일 마지막 단에 LLM을 통과할 때 사용되는 토큰 수가 일치하는 것이지 저 프레임들에서 ViT로 visual token을 추출할 때는 32개의 프레임을 모두 visual token을 뽑아야해서 앞단 연산량은 늘어나지 않나..?라는 생각이 있긴 합니다.
Dataset Pruning
지금까지 모델의 추론 과정에서 Scale then Compress 과정을 살펴보았고, 다음 설명드릴 내용은 Dataset을 어떻게 효율적으로 활용할 것인지에 대한 부분입니다.
이전 VLM 연구들은 종종 다양한 소스에서 데이터를 가져오는 것이 모델의 benchmark 성능에 좋은 영향을 준다는고 주장하였습니다. 물론 그게 사실이긴 하지만 본 논문의 저자들은 모든 데이터가 모델한테 동일한 기여를 하지 않는다고 생각하였습니다. 즉 데이터셋이 계속 커질수록 중복되는 데이터도 많이 있을 것이고 이것들이 학습에 좋은 영향을 못주고 오히려 학습 시간만 잡아먹을 수 있는 것이죠.
그렇다고 다양한 소스에서 데이터를 가져오지 말아야하는 것이냐 라고 한다면 사실 그 부분도 저자들이 원하는 방향은 아니긴 합니다. 결과적으로 저자들은 앞서 소개한 Scale-Then_Compress라는 컨셉을 데이터셋에서도 적용하고 싶었던 것이죠.
근데 퀄리티 좋은 데이터셋을 다양한 소스에서 모아야 scale-up이 가능한데 그게 사실 쉽지가 않습니다. 일단 기존에 Vision input, 또는 text only input에 대해서는 양질의 데이터를 선별하는 여러 연구들이 있긴 했는데, VLM에서는 이런걸 풀려는 연구가 거의 없다고 합니다. 근데 이제 자신들의 NVILA 모델은 1억개가 넘는 데이터로 학습을 하려다보니 학습 코스트가 너무 많이 들거든요. 결과적으로 1억개가 넘는 데이터셋을 다 활용하는 것이 아닌 압축하는 기법이 필요하다라는 필요성을 강하게 느낀 것 같습니다.
저자들은 이전의 Knowledge Distillation 방법론에서 제안된 Delta Loss를 활용해서 학습 데이터의 품질에 대한 점수를 부여했다고 합니다.
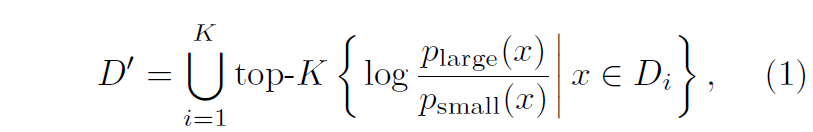
일단 수식은 위와 같은데 D_{i}, D' 는 각각 전체 데이터 셋 중 i번째 소스 데이터의 집합과 최종 압축된 데이터셋 집합을 의미합니다. 그리고 p_{large}, p_{small} 은 Large model과 Small model에서 추론한 정답 토큰의 확률 값을 의미합니다.
저자들이 생각하는 좋은 품질의 데이터 선별 기준이 무엇이냐면, 너무 쉽거나 너무 어려운 데이터들을 제거하는 것입니다. 큰모델과 작은 모델의 output 확률 값을 log 취한 것이 어떻게 데이터의 품질 스코어가 되는지를 이해하기 위해 아래 3가지 상황을 소개드리려고 합니다.
- 우선 큰 모델과 작은 모델 모두 정답을 맞췄거나 정답을 틀릴 경우에는 확률 값이 둘다 1에 가깝거나 또는 0에 가깝겠죠? 그래서 이둘의 분수값이 1이 되어 log를 취했을 때 0에 가까운 score 값을 가지게 됩니다.
- 둘째로는 만약 작은 모델의 확률값은 높은데 큰 모델의 확률값은 작다? 이러면 이제 1보다 작은 값을 가지게 되어서 log를 취하면 음수 값이 나타나게 되는데 이렇게 스코어가 음수를 가지면 이 역시도 품질이 낮은 데이터로 판정나게 됩니다. 이 부분은 쉽게 생각하면 큰 모델이 “아 이건 정답이 아니야”라고 했는데 작은 모델이 “이건 정답인데?”라고 하게 되면 뭔가 좀 꺼름칙한?데이터로 판정이 됩니다. 아무리 생각해도 큰 모델이 틀렸다고 하는데 작은 모델이 맞다라고 하면 흠.. 그런 느낌입니다.
- 셋째로는 이제 작은 모델의 정답은 틀렸는데 큰 모델이 정답을 맞추는 경우입니다. 이때는 분수 값이 1이상이기 때문에 log를 취하면 양수 값이 나오게 되고 이 데이터는 작은 모델은 맞추기 어려워하지만 큰 모델은 맞출 수 있는? 이상적인 데이터로 판단해서 좋은 품질의 데이터구나 하고 높은 품질 스코어를 주는 것이죠.
이렇게 3가지 경우를 소개드렸는데 이 3가지 경우에 대해서 예시가 아래 그림을 통해 확인하실 수 있습니다. 아래 그림에서 제일 좌측이 너무 easy한 sample, 가운데가 distracting sample, 세번째가 모델 학습에 도움이 될 것 같은 샘플의 예시입니다.

근데 사실 이 부분은 컨셉은 이해가 가는데 모델의 answer token에 대한 output probabilities가 정확히 어떤 형태인지를 잘 몰라서 실질적으로 어떻게 구현된다는 것인지는 완벽히 이해하기가 어렵네요ㅜ.
아무튼 이렇게 data를 pruning한 뒤 모델을 학습시켰을 때 모델의 성능이 어떻게 변화되는지는 아래 표를 통해 확인하실 수 있습니다.
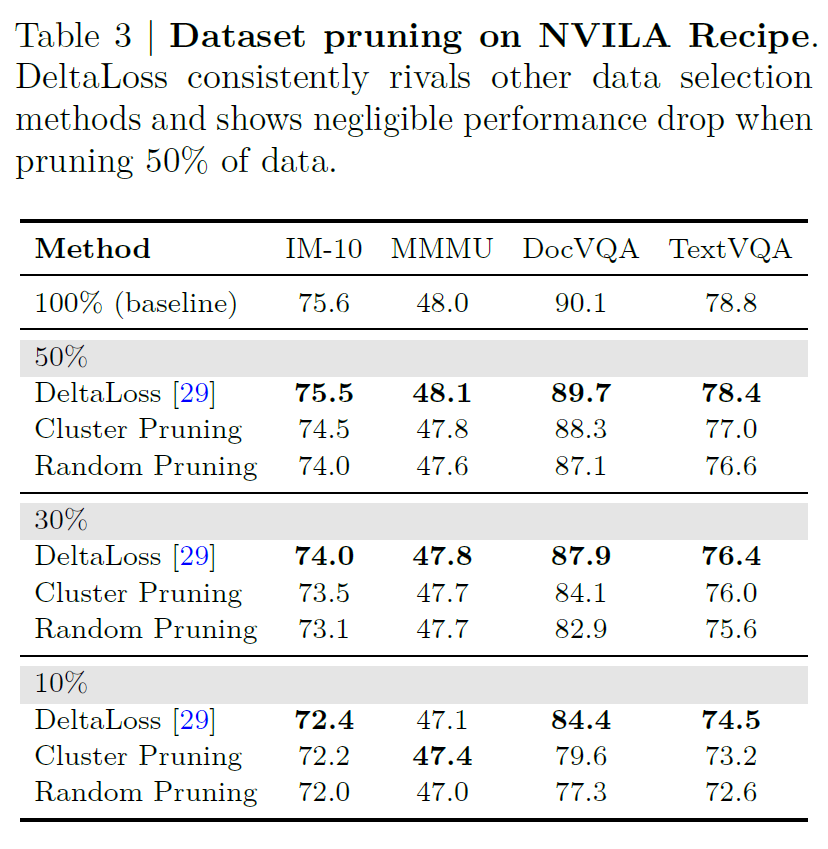
결론만 말씀드리면, 100% 데이터를 다 활용하였을 때를 베이스라인으로 선정하고, data pruning 방식을 3가지를 비교하는데 우선 랜덤하게 프루닝하는 방식, 그리고 K-means clustering을 통해 군집을 생성, 군집 중심을 기준으로 일정하게 선정해서 pruning하는 방식 그리고 위에서 소개드린 delta loss 방식의 pruning까지 총 3가지가 존재합니다.
결론만 빠르게 말씀드리면 random pruning보다는 항상 delta loss방식의 pruning이 좋았다는 점이고, 또 50%정도의 pruning을 한 것이 데이터를 100% 전체 다 사용하는 것과 비교하였을 때 성능의 하락폭이 소수점1자리로 미미하거나 MMMU같은 경우에는 오히려 성능이 조금 더 오르는 등 정확도 측면에서 변화가 그리 크지 않더라 라는 점이구요. 대신에 학습에 사용되는 데이터는 절반이나 줄였기 때문에 아까 1억개의 데이터를 사용한다 했으면 5천만개를 일단 줄인 것이라 학습 시간을 2배 줄였다는 점에서 매우 유의미하다라는 점입니다.
Efficient Fine-tuning
다음은 VLM을 fine-tuning해야할 때 효율적으로 fine-tuning하는 방식에 대해서 소개합니다. intro에서도 살짝 언급드리긴 했는데 VLM이 잘 pretraining되었다 하더라도 결국 특정 도메인으로 넘어가면 fine-tuning을 해야할 때가 있거든요? 의료쪽 같이 사용되는 text wording이 달라지고 이미지도 크게 달라지는 경우가 그에 해당합니다.
역시나 기존 연구들은 LLM 또는 text-related task에서만 관심이 있었지 VLM에 대해서는 어떻게 파라미터 효율적인 파인 튜닝을 할건지에 대해 연구가 잘 진행되지 않았다고 저자들은 주장을 합니다. 그래서 저자들이 여러 실험을 진행한 끝에 밝혀낸 결론만 말씀드리면 우선 ViT와 LLM은 서로 다른 Learing Rate를 가져야한다는 점, 그리고 개별적인 downstream task에 대해 독립적으로 tuning 파트를 골라주어야한다는 점입니다.
아래는 Fine-tuning할 때 어떠한 조합으로 하면 좋은지에 대해 ablation study를 한 결과인데 caption을 보면 상당히 긴 것을 볼 수 있습니다. 실험세팅에 대해서 소개하는 것들이니 한번 보시면 좋을 듯 하네요.

위에 표 결과를 살펴보면 LoRA와 QLoRA같은 adapter를 활용하는 방식이 Fulling Tuning에 비해서 메모리를 적게 먹는 모습을 확인할 수 있는데, 여기서 재밌는 점은 ViT에서는 LoRA를 안붙이고 그냥 Layer Norm만을 tuning하는 것이 더 메모리도 적게 먹고 학습 시간도 25%나 줄일 수 있다는 점입니다.
저자들은 왜 Layer Norm을 tuning하였는지 그 철학을 논문에 전혀 언급하지는 않습니다만(애초에 왜 Layer Norm만을 tuning할 생각했는지 이유조차 말안해줌), 아무래도 domain gap이라는 것은 학습 때 보지 못한 데이터의 분포가 오는 것이기 때문에 해당 데이터 분포에 맞추어 normalization을 어떻게 해주는지가 중요하다는 것이 아닐까 싶네요.
그리고 Learning Rate 부분에서는 LLM 파트와 비교해서 ViT 부분 LR을 5~50배 더 작게 해주었을 때 더 좋은 성능을 얻을 수 있었다고 합니다. 저 LR 부분은 어떻게 설정하느냐에 따라서 성능의 차이가 크게 변하는 것을 확인할 수 있네요.
Experiments
대략적인 방법론은 다 알아보았고, 논문에서는 실험도 엄청 다양하게 진행을 합니다. 아무래도 VLM이다보니깐 적용할 수 있는 task들이 많아서 그런지 Image에 대한 benchmark, Video benchmark 뿐만 아니라 Navigation, Medical 등등 정말 다양한 분야에서 평가를 진행합니다.
제가 이 실험들을 하나하나 다 다룰 수 없어서 궁금하신 분들은 직접 논문을 참조해주시길 권해드리고 해당 리뷰에서는 가장 베이직한 Image benchmark에 대해서만 결과 표를 리포팅하고 마치겠습니다.

보시면 AI2D부터 시작해서 VQAv2 데이터셋까지 총 10가지가 넘는 데이터셋으로 평가를 진행하는데, 10가지 데이터 셋이 다 동일한 task가 아니라 또 데이터 셋들 별로 서로 목적하는 task가 다르게 묶인다는 점 참고하시면 좋겠습니다.
아무튼 간에 LLAVA, Llama, InterVL 등등 이름있는 VLM들과의 비교실험을 진행하고 있고 결론부터 말씀드리면 다수의 벤치마크에서 1등 또는 2등을 차지하고 있더라 라는 점입니다. 이는 기존 VLM 애들이 고해상도의 image resolution을 활용하지 못하는 반면에 자신들은 이러한 scaling이 효과적으로 작용했기 때문에 efficient하게 학습하고 추론하더라도 좋은 성능을 달성할 수 있었다는 것 같아요.
근데 저 테이블에서 실제로 throughput 같이 얼만큼의 처리를 할 수 있는지를 안보여줘서.. 비슷한 추론 속도에 저 성능을 도달한건 아니겠죠..?
일단 논문에서 inference performance를 보여주는 결과가 있긴한데 image와 video benchmark에서 다른 모델들은 다 빼고 Qwen2-VL 모델과 직접적으로 비교한 결과만 있긴 합니다.
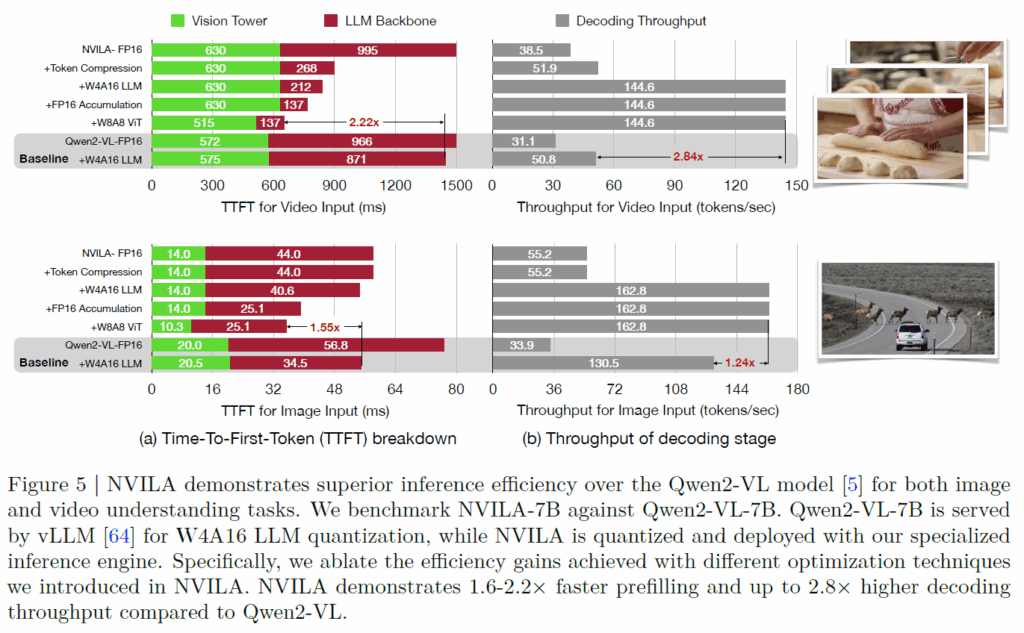
보시면 둘다 동일하게 7B의 파라미터 수를 가지고 있고, 4090 RTX GPU 1장에서 동일한 실험 세팅으로 추론하였다고 합니다. 여기서 좌측은 Time-To-First-Token 즉 TTFT에 대한 속도를 나타내는데 이 TTFT가 뭐냐면 사용자가 모델한테 입력을 딱 줬을 때 LLM이 처음으로 output 토큰을 만드는데까지 걸리는 시간이라고 합니다.
그리고 우측에 decoding stage는 이렇게 처음으로 생성된 token을 기준으로 점점 decoding 과정을 거치면서 결과물을 만들어낼 때 소모되는 throughput을 나타낸 것이네요. 우측은 throughput이기 때문에 값이 클수록 초당 처리할 수 있는 토큰 수가 많구나 라고 생각하시면 되겠습니다.
결론적으로 저자들이 제안하는 최종 모델이 Qwen2-Vl-FP16보다 TTFT가 1.55배 더 빠르다는 점, 그리고 Thoughput도 Qwen2보다 한 5배는 더 큰 것 같고 baseline보다도 1.24배 더 좋더라 라는 점입니다. 근데 이제 보시면 NVILA에 뭐가 많이 붙어있죠. 제가 방법론에서 소개드린 Token Compression 말고도 W4A16 LLM, W8A8 ViT 등등 뭐가 많이 붙어있는데 사실 저 부분이 제가 리뷰에서 미처 다루지 못한 기술적 키워드를 마구마구 넣은 개발쪽 내용들의 결과물입니다. 저자들이 method에서 소개를 하고 있는 contribution들 중 일부인데 너무 생소한 키워드 그리고 저쪽 분야에 대한 무지함으로 리뷰에 소개드리지 못한 점 양해부탁드립니다ㅜ.
결론
아무래도 NVIDIA가 GPU가 많긴 하지만 그래도 방대한 크기의 VLM을 학습시키는데 사용되는 코스트들에 대해서 문제의식을 많이 느낀 것이 아닌가라는 생각이 들긴 합니다. 그래서 단순히 추론 시간을 줄이기 위한 노력 뿐만 아니라 학습 시간과 비용을 줄이는데에도 진심을 다하려고 했던 것이 논문에 담겨 있어서 흥미롭게 읽었네요.
그리고 최신 연구들의 컨셉도 많이 활용하고 테크니컬적인 부분들도 비중있게 다루고 있어서 무언가 CVPR 논문이라기보다는 엔비디아 회사에서 발표한 기술리포트?에 더 가까웠던 것 같습니다. Quantization 관련해서 기술적인 부분들은 제가 친숙하지 않아 이해하지 못한 것이 아쉽게 느껴지긴 하지만, 이미지를 tiling해서 ViT의 태운다던지, pixelunshuffle을 활용해 visual token을 compression하는 것이 다른 learnable 방식의 token compression보다 더 좋았다는 점, 데이터를 pruning 할 때 delta loss라는 방식으로 접근한다는 등 새롭게 알게된 지식들이 많아서 모처럼 시간은 많이 걸렸지만 읽는데 보람이 느껴지는 논문이었네요.
VLM 효율화를 통해 NVIDIA의 신규 고객을 더 많이 유치하기 위한 첫 발걸음인건지, 효율화라는 키워드로 엄청나게 많은 기술들을 한번에 제안하는 논문인것 같습니다.
1. 이미지 벤치마크 성능 표 8에서, NVILA와 NVILA-Lite의 차이점은 무엇인가요? 학습-fine tuning-데이터셋 전반에 걸쳐 여러 contribution이 있는데, 각각이 NVILA와 NVILA-Lite에 어떻게 적용되어있는 것인지 설명해주시면 감사드리겠습니다.
2. 그림 5에서, Qwen2-VL과의 비교를 위해 입력한 비디오의 정보가 궁금합니다. Qwen2-VL은 최대 768프레임 내에서 초당 2프레임을 샘플링하고, NVILA는 uniform하게 32프레임정도를 가져다 compress하는 것으로 이해했습니다. 만약에 비디오가 딱 384초라 Qwen2-VL은 768개 프레임을 뽑아 처리해야하고, NVILA는 고정적으로 32개 프레임만 뽑아 처리하는 것이라면 위와 같이 효율성 면에서 NVILA가 이기는 것이 당연하다고 보여서, 혹시 이러한 조건이 통제되어있는 것인지 궁금합니다. 혹은 제 이해에 잘못된 부분이 있는 경우 정정해주시면 감사드리겠습니다.
댓글 감사합니다.
질문에 대해서 답을 드리면, NVILA와 NNVILA-Lite의 차이점에 대해 논문에 전혀 언급이 없더라구요. 그래서 현우님같이 궁금함을 느낀 다른 사람들이 깃허브 이슈에 관련된 글을 남겼고 저자들이 다음과 같은 답변을 남겼습니다.
“NVILA-Lite is designed is to optimize the efficiency over NVILA while maintaining a competitive performance. The main differences between NVILA-Lite and NVILA include that NVILA-Lite uses 3×3 downsample instead of 2×2 in the mm projector, and NVILA-Lite uses dynamic res instead of dynamic s2.”
요약하면 Spatial to Channel Reshape을 NVILA는 2×2로 했다면 NVILA는 3×3으로 진행한 것으로 확인됩니다. 그리고 입력 resolution을 키울 때도 dynamic s2가 아닌 dynamic resolution을 활용했다는데 솔직히 dynamic resolution이 뭔지는 저도 잘 모르겠어요;; 이게 실험도 방대하고 학습 단계가 5개까지 있거든요? 그러다보니 이 논문 한편에 28명이나 있는데 그래서인지 논문의 글도 불친절한 경우가 있고 자기들끼리도 표현하는 방법이나 실험 세팅이 묘하게 달라지는 등 이해하는데 어려움이 많네요ㅜ.
두번째 질문에서 프레임 수를 어떻게 처리했는지에 대해 답변드리면 저자들이 논문에 다음과 같은 이야기를 합니다. “For a fair comparison, both models process video inputs by sampling 64 frames, with all experiments conducted on a single NVIDIA RTX 4090 GPU.”
즉 제가 기존의 Qwen2라는 모델이 어떤식으로 샘플링을 하는지는 모르지만 그림5에서 비교할 때 만큼은 두 방법론들 모두 동일하게 64프레임으로 샘플링을 진행하였기 때문에 말씀해주신 걱정은 문제 없을 것으로 보입니다.
감사합니다.
안녕하세요 좋은리뷰 감사합니다.
뭔가 읽으면서 드는 이거 ablation 있나? 싶던 부분들이 전부 반영되어있어 탄탄한 논문이라 생각이 드네요..
Table 2 에서 4배정도 압축하는것이 허용 가능한 범위라 했지만 뭔가 토큰수를 맞춰서 frame 256 도 2048개일때의 성능이 있었으면 ( 성능 드랍이 얼마나 있는지는 모르겟지만) 어땠을까 하는 생각도 있습니다.
궁금점으로 3*3 으로 spatial pooling 진행하는 부분에서 projector가 어려워하는 부분을 encoder 단도 학습시키는 방법이 모든 인코더를 학습시키는 것이 아닌 projector 와 가까운 단만 일부 학습시키는 것이라고 이해하면 될까요?
그리고 다시 읽어보면서 이해해본거지만 아래 Table 5 의 LoRA와 LN 학습하는 ablation 부분에서 (ViT의), LoRA와 LN의 학습 방향성이 다르다는걸 생각하게 됐습니다. 정민님이 언급해주셨듯이 domain gap 관점에서 보지못했던 분포를 학습해주기 위해 LN만을 파인튜닝 하는 방법을 생각한 것 같네요..더 깊게 생각하기엔 task나 데이터에 따라 다를 것 같기도 하고, 변수가 많아지는 것 같기도 하고 어렵네요. 이러한 여러 ablation을 한 표에 담았을때 저자가 증명하고자 한 부분과 어떻게 이런 표 구성을 만들게 됐을지 생각해보는 것도 도움이 되는 것 같습니다.
감사합니다.
댓글 감사합니다.
사실 논문이 VILA 논문의 후속 논문?이어서 그런건지 아니면 엔비디아의 자신감을 드러내서 그런건진 모르겠지만 논문이 하나하나 디테일을 언급하는 듯이 그렇게 친절하지는 않습니다. 오히려 내가 하는 말 무슨 말인지 알지? 우리는 이렇게 했어~ 같은 느낌 메인페이퍼 내에서는 그냥 일방적으로 언급하고 넘어가더라구요.
따라서 Vision Encoder와 Projection을 같이 tuning하는 과정에 대해서 디테일한 설명과 loss function은 언급되지 않고, ALLAVA, DocMatrix, PDFA, LSVT, ArT라는 이름의 다양한 task를 지닌 데이터셋을 가지고 학습한다 정도로만 간단히 언급되어있네요.
근데 제 생각엔 뒷단만 학습하는 것이 아닌 전체 네트워크에 대해 full tuning하는 것 같아요. 만약에 뒷단만 학습하는 거였으면 차라리 LoRA를 쓰는 등으로 접근하거나 아니면 뒷단만 학습했다는 점을 언급했을건데 그런 내용이 다 빠져있기도 하고, 리뷰에 담지 못했는데 다시 논문 확인해보니 각 학습 스테이지별로 Visual Encoder, Projector, LLM이 각각 언제 tuning되고 언제 freeze 되는지 나타내는 표가 있는데 거기서 Visual Encoder가 trainable이라고 언급하는 것을 보니 전체 네트워크를 tuning했다고 보는게 맞는 것 같습니다. 그리고 활용되는 데이터셋의 규모가 결코 적지가 않기 때문에 full-tuning하는 것이 더 좋을 것이구요.