안녕하세요 이번주 X-review는 Robotic Manipulation 데이터에 관한 논문을 리뷰해보도록 하겠습니다. Video Diffusion을 활용한 아이디어가 참신해서 읽어보게 되었습니다. Robots Imitating Generated
Videos (RIGVid) 라는 프레임워크를 제안한 연구인데, 비디오를 생성한 뒤 VLM을 통해 정제과정을 거친 뒤 6D pose tracking을 활용해 retargeting하는 방식으로 작동하는 방식이고, 이를 통해 로봇 데이터 수집 과정의 물리적인 의존도를 많이 줄일 수 있는 가능성을 제시한 연구라고 생각합니다. 리뷰 시작해보도록 할겠습니다.
Introduction
저자들은 로봇 매니퓰레이션 학습에서 영상 데이터가 풍부하고 표현력이 좋은 데이터임을 강조합니다. 영상을 활용하는 방식으로는 인터넷에서 얻은 대규모의 실제 영상 데이터셋을 활용하는 방법과 목표 환경과 매우 유사한 시연 영상을 모방하는 방식으로 나뉩니다. 저자들은 대규모의 영상 데이터를 활용하는 경우 domain gap 문제를 해결해야 하고, 유사한 시연 영상을 수집하는 것은 매우 노동집약적이고 제약이 많다는 한계가 있다고 합니다. 이 때 저자들은 video generation 기술 발전에 집중해서 주어진 환경과 작업에 대해 생성한 하나의 영상만으로 로봇이 실제로 작업을 수행할 수 있다는 패러다임을 제시했습니다. Video generation 기술들이 발전함에 따라 기하학적인 왜곡, 물리적으로 비현실적인 상호작용등의 문제가 해결되면서 어떤 추가 데이터나 파인튜닝 없이 로봇 작업을 위해 사용할 수 있게 되었다고 주장합니다. 생성된 비디오를 통한 조작은 ReKep의 keypoint와 같이 압축적으로 정보를 전달하는 방식보다 더 나은 퍼포먼스를 보인다고 합니다. (실험의 베이스라인으로 사용하지는 않았지만 ReKep의 VLM을 활용한 relational keypoint constraint의 성능이 안 좋다고 Appendix에서 까지 추가로 설명하면서 얘기하고 있습니다,,)
저자들은 해당 논문의 contribution으로 현실에서의 demonstration 없이 생성 비디오만으로 오픈월드 매니퓰레이션 작업을 수행하는 프레임워크 제안한 점, 고품질 생성 영상이 실제 영상과 동등한 성능을 보이고 합성 데이터가 실제 데이터를 대체할 수 있음을 입증한 점, Video generation과 6D Pose Tracking을 활용한 방법이 point tracking, optical flow, feature field, generated goal supervision등을 기반으로 최신 방법들을 능가함을 실증한 점이라고 주장했습니다.
Related Work
비디오를 직접적으로 활용한 연구를 많이 접해보진 않아서 related work도 정리를 하자면 기존 로봇 매니퓰레이션의 영상 기반 학습은 주로 동일 환경에서 수집한 시연 영상을 직접 모방하는 방식과, 오프라인 대규모 영상 데이터에서 affordance를 학습해 작업에 적용하는 방식으로 나뉜다고 합니다. 전자는 환경,시점을 맞춘 paired demonstration이 필요하고, 후자는 domain gap과 특정 작업에 특화된 정보 부족이 문제라고 합니다. 또 비디오의 visual correspondence를 track, optical flow, dense descriptor나 part trajectory와 같은 방법들이 있지만 paired demonstration이 필요하다는 한계가 있습니다. 비디오 생성 기반 접근도 시도됐었지만 여전히 실제 데이터 수집 의존성이 높았다고 하비다. Motion retargeting 역시 human demonstratoin에 의존해왔으나, 최근 object-centric한 연구들이 등장했다고 합니다. RIGVid는 이런 다양한 한계를 극복하기 위해 video generation을 활용해 작업 환경에 맞춘 demonstration을 만들고, FoundationPose로 추출한 6D object trajectory를 embodiment-agnostic하게 retargeting 했다고 합니다.
Method
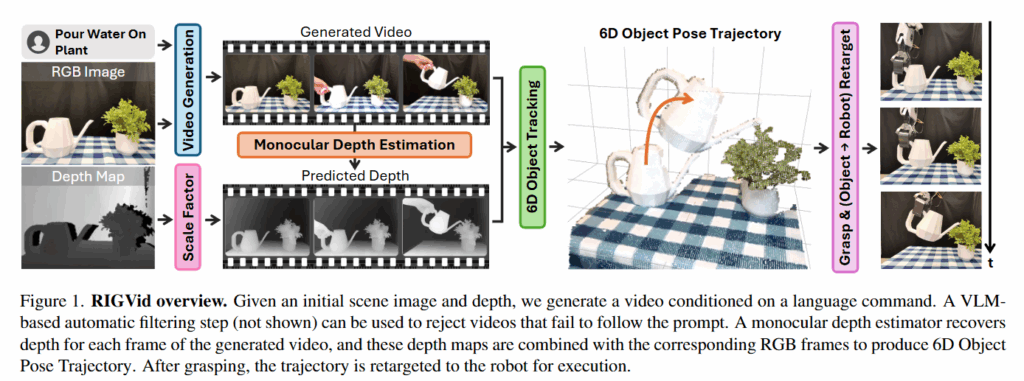
앞서 잠깐 언급했듯이 파이프라인은 RGB이미지와 Depth Map을 통해 language command를 입력으로 받아서 로봇의 EE trajectory를 예측합니다. 이를 위해 주어진 장면과 작업 환경에 맞는 비디오를 생성하고, Mono Depth Estimation 모델을 통해 프레임을 Depth로 바꿔줍니다. 이후 생성된 영상에서의 6D pose tracking을 수행한 후 Rollout을 계산하고 이렇게 추출된 trajectory를 기반으로 ee trajectory로 retargeting 합니다. 이후 로봇이 객체를 grasping 한 뒤 액션하는 과정으로 진행됩니다. 단계별로 살펴보도록 하겠습니다.
Generating Videos and Corresponding Depth
Video Generation Model은 Kling AI v1.6을 사용했다고 합니다. Video generation model을 평가하는 VBench++ 메트릭을 통해 평가된 모델중 가장 뛰어난 모델을 활용했다고 합니다. “Pour Water On Plant”를 기준으로 첫번째 이미지를 가지고 생성한 비디오를 같은 간격으로 4장 샘플링 해서 이어붙인 사진을 보면 확실히 다른 모델들 보다 정확한 표현을 하고있는 것으로 보입니다.

다만 언제나 비디오가 정확히 만들어진단 보장은 없기 때문에, 아래와 같은 프롬프트를 통해 동일한 간격으로 샘플링한 비디오 프레임들을 이어붙여 VLM (GPT-4o)을 통해 검증을 진행한다고 합니다. 논문엔 4o로 적혀있지만 supplementary에는 o1 Response로 나와있는게 좀 이상하긴 하지만 어쨌든 VLM을 통해 검증을 진행하느 ㄴ과정을 거칩니다.
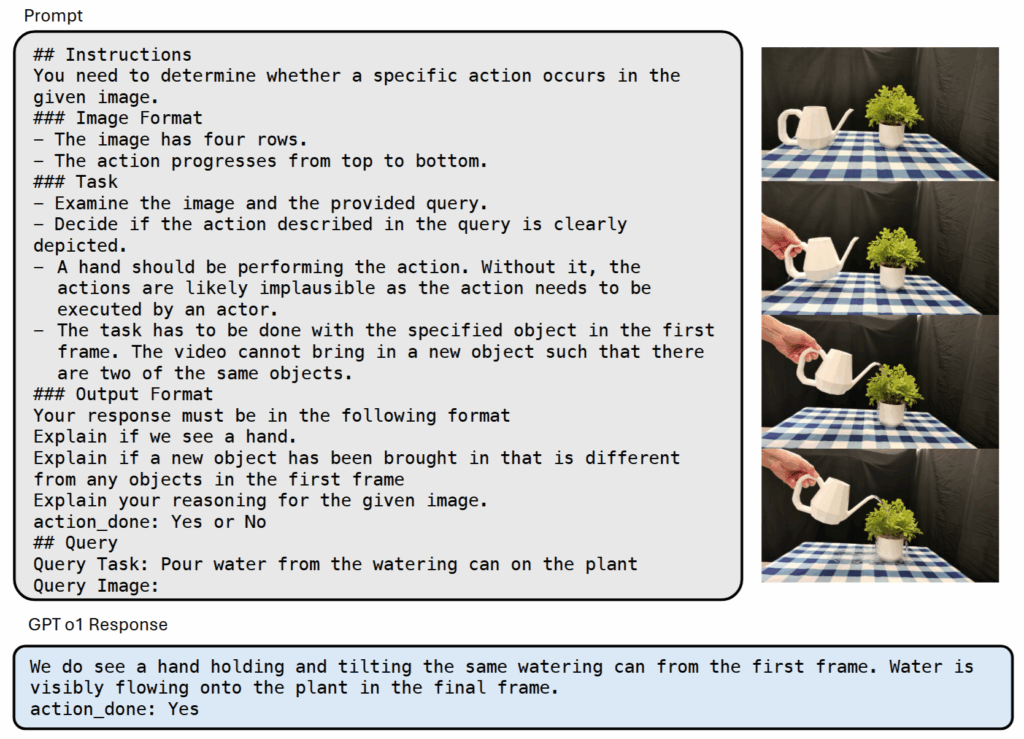
VLM이 해당 영상이 이후 절차에 사용해도 되는 영상인지를 판단하고 나면, 생성된 영상의 프레임들에 대해 depth를 예측해줍니다. RollingDepth (Vidoe Depth without Video Models)라는 모델을가지고 비디오에 대한 monocular depth estimation을 수행합니다. 다만 이때 결과물이 real-world unit과 일치하지 않기 때문에 첫번째 프레임에 대해 real world depth와 scale을 일치시키는 affine scale-and-shift 변환 계산을 진행해준 뒤, 모든 프레임에 대해 해당 transformation을 적용한다고 합니다.
이러한 과정을 거쳐서 RGB, Depth 이미지와 Language instruction을 기반으로 생성된 영상과 depth로 변환된 영상을 얻고 6D tracking 과정으로 넘어갑니다.
Identifying Active Object Mask and 6D Object Pose Trajectory
비디오를 생성했다면 다음 목표는 객체의 6D pose rollout을 추출하는 과정입니다. 이를 위해 먼저 영상에서의 조작대상 (active object)를 식별합니다. 이를 위해 맨 처음 input으로 사용한 RGB 이미지에 대해 GPT-4o를 통한 description을 생성한 뒤, Grounding DINO와 SAM-2를 통해 binary mask를 얻는다고 합니다. (이 과정에서 생각보다 SAM-2를 통해 얻은 output이 이상한 경우가 종종 등장해서 다른 방법은 없나 싶은데 지금까지 본 모든 연구가 Grounding DINO와 SAM-2를 사용하는 것을 보면 이게 최선인 것 같습니다.. )
Active object에 대한 mask를 기반으로 생성된 영상과 depth로 변환된 영상을 모두 이용해 객체의 6D rollout을 계산합니다. 저자들이 여러 6D pose tracker를 실험한 결과 FoundationPose를 적용했을 때 실제 환경에서 가장 우수한 성능을 보였다고 합니다. FoundationPose는 모델이 필요하므로 BundleSDF를 통해 사전에 mesh를 만들어두고 활용한다고 합니다. 결국 RGB 이미지와 더불어 물체를 360도 회전해 영상을 취득하는 과정은 필요한 것 같습니다. 저자들도 Bundle SDF과정이 30분정도 소요되고 real time으로 작동하기는 어렵기 때문에 model-free tracking이 발전해서 mesh 생서으이 bottleneck을 줄여주기를 바란다고 합니다. 다른 연구에서는 아니었던것 같은데 (정확히 기억은 안 납니다..) Bundle SDF가 생각보다 오래 걸리는 것 같습니다.
추정된 객체의 pose들에 대해서는 노이즈와 jitter를 줄이기 위해 translation과 orientation에 대해 고정된 크기의 슬라이딩 윈도우를 중심으로 한 moving average filter를 적용한다고 합니다. 이를 통해서 pose가 급격하게 변화되는 구간을 완화해서 보다 안정적이고 현실감 있는 trajectory를 얻을 수 있다고 합니다.
Object to Robot Motion Retargeting
대상 객체의 trajectory를 얻고 난 뒤에는 객체를 grasp한 뒤에 trajectory를 따라 액션을 실행합니다. 먼저 AnyGrasp를 사용해서 대상 객체에 대한 가장 점수가 높은 graspint point를 골라서 grasping을 실행합니다. 다만 이 때 grasping하는 형태에 따라서 이후 trajectory를 따라가는데 제약이 있을 수도 있을 것 같은데, 이것에 대한 언급은 없었습니다.
Grasping 이후 아래 Figure2와 같이 추가적인 gripper와 객체사이의 움직임은 없다는 가정 하에 파지 순간의 객체-그리퍼 relative pose와 그리퍼-엔드이펙터의 offset을 가지고 계산한 변환을 앞서 구한 object trajectory에 적용해 최종 궤적을 생성해 해당 궤적대로 로봇이 액션을 수행하게 됩니다.
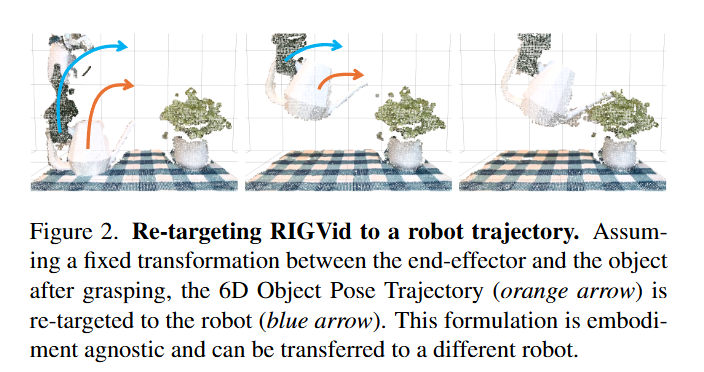
해당 방식으로 접근한 이유중 가장 큰 장점이 robot-agnostic한 수행이라고 합니다. 로봇이나 gripper의 종류를 바꿔도 엔드 이펙터와 객체 사이의 변환만 다시 구하면 object를 동일한 궤적으로 움직일 수 있다고 합니다. 또한 각종 방해에 강인하다고 합니다. 사람이 로봇을 밀어서 객체가 trajectory에서 벗어나면 가장 최근 trajectory로 다시 복귀한 뒤 나머지 trajectory를 따라서 움직인다고 합니다. 이를 통해 다양한 외부 변수를 고려했을 때도 중단없이 안정적으로 조작을 마칠 수 있다고 아래 figure와 같이 주장합니다.

실행시에 FoundationPose를 사용해서 객체의 6D pose를 실시간으로 추적해 거리가 3cm벗어나거나 각도가 20도 이상 벌어지면 마지막으로 성공적으로 실행한 trajectory로 되돌아가서 해당 지점부터 다시 작업을 이어나간다고 합니다.
Experiments
실험은 제로샷 성능 평가가 가능한 VLM 기반의 trajectory 예측 모델들을 베이스라인으로 삼아 성능 차이를 평가했다고 합니다. xArm7을 사용해 평가를 진행했고, wrist에 달린 cam과 로봇의 옆면에 고정된 view를 통한 Orbbec Femto Bolt카메라를 사용했다고 합니다. 사진상에 보이는 wrist에 달린 센서는 realsense인 것 같습니다.
Task는 총 4가지로 식물에 물주기, 냄비 뚜껑 열기, 후라이팬에 뒤집개 올리기, 쓰레기 쓸어담기로 구성됐습니다. Task success 여부는 사람이 판단했을 때 성공 했냐 안 했냐만 기준으로 평가했고, 모든 베이스라인들에 각 trial마다 영상을 생성해 같은 영상을 활용했다고 합니다.

Comparison to Alternative Trajectory Extraction Methods
베이스라인으로는 Track2Act (Track based), AVDC (Optical flow based), 4D-DPM(Feature Field based), Gen2Act (Generated Goal based)를 사용했습니다. Track2Act는 초기 이미지와 목표 이미지 간의 2D point trajectory를 예측하고 이를 기반으로 3D 객체의 움직임을 복원하는 방식으로, 비교할때는 목표 이미지를 생성 영상의 마지막 프레임으로 대체해 사용했다고 합니다. AVDC는 생성된 작업 영상을 기반으로 optical flow와 깊이 정보를 결합해 최적화 기반으로 3D 객체 궤적을 추정하는 방법으로, 동일 생성 영상을 사용해 비교했다고 합니다. Optical flow에 대해서는 잘 모르지만 영상의 픽셀들의 시간별 움직임을 토대로 픽셀 단위로 움직임을 추적하는 방식인 것 같습니다. 4D-DPM은 part단위로 trajectory를 만들어 내는 방식으로, 3D Gaussian Splatting과 클러스터링(GarField)을 통해 객체의 3D 운동을 추적하는 방식입니다. 비교시에는 파트 단위가 아닌 전체 객체 단위로 수정해 적용했다고 합니다만, 애초에 4D-DPM은 관절이 있는 part에 대한 움직임이 메인인 연구라 조금 아쉽단 생각도 들었습니다. Gen2Act는 학습된 policy를 통해 RGB-D를 통해 action trajectory를 예측하는 모델이라고 합니다.
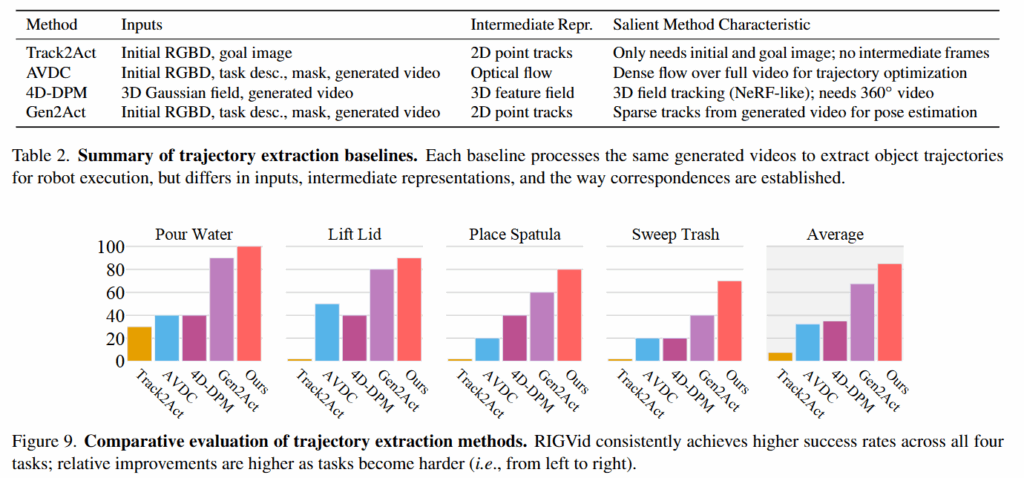
RIGVid가 전체적인 작업의 평균 성공률이 85퍼센트로 우수했고, 특히 객체가 회전됐거나 occlusion이 있는 경우 기존의 tracking 기반의 방법들은 제대로 working하지 않았다고 합니다. 또한 주걱이나 쓰레기 쓸기를 위한 빗자루와 같이 얇은 물체들에 대해서도 강인한 성능을 보여줬다고 합니다.
또한 아래 Figur10을 통해서도 Track2Act는 예측된 경로가 완전히 잘못됐고, AVDC는 개별 프레임에서는 합리적인 optical flow를 생성했으나, 이를 전체 영상에 걸쳐 합산하면 작은 오차가 누적되어 결국 물리적으로 task 수행이 불가능한 trajectory를 만들어냈다고 합니다. Gen2Act는 비교적 정확한 trajectory를 만들어 내긴 하지만 occlusion에 취약한 모습을 보였다고 합니다. 4D-DPM의 경우에도 trajectory가 불완전하는 등 다양한 문제가 있었다고 합니다.

RIGVid vs ReKep
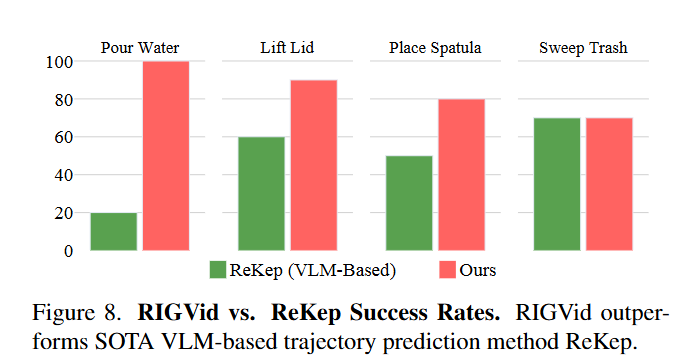
저자들은 비디오가 계산 비용이 크긴 하지만 VLM을 통한 abstract representation은 로봇이 성공적으로 액션하기 위한 세밀한 정보들이 부족하기 때문에 supervision을 위한 방법으로는 적합하지 않고, 저자들의 파이프라인의 cost가 단순히 낭비적인 방식이 아니라고 주장합니다. 다만 아직까지는 실제로 RIGVid가 더 높은 성공률을 보이고 있지만, 더 발전된 VLM기반 연구들이 격차를 줄일 가능성은 열려있다고 말합니다.
Embodiment-Agnostic, open-world tasks

Figure 11을 통해 알 수 있듯 여러 embodiment에서 강인하게 작동하는 모습을 보였고, 특히 upright ketchup, unplug charger, spill beans와 같이 작업 수행에 있어서 대상 객체의 회전이 많이 일어나는 경우에도 성공적인 task 수행이 가능했다고 합니다. Aloha에서는 camera calibration에 문제가 있어서 성능이 20퍼센트 정도 하락하긴 했지만 그건 calibration의 문제라고 하네요 허허,, 어떤게 문제인지는 적혀있지 않았습니다.
Conclusion
일단 물리적인 세계에서의 teleoperation 없이, 인간의 노동을 줄이면서 로봇 전문가 없이도 로봇 조작 데이터를 생성해 낼 수 있다는 점에서 아이디어도 참신하지만 전반적인 생성형이나 기타 등등 여러 인공지능이 정말 많이 발전했구나 라는것을 느꼈고 읽다보니 당연히 어려운거지만 왜 이런 생각을 못 했을까 싶기도 했습니다 하하..
또 어찌보면 당연하지만 비디오의 풍부한 시각적인, 공간적인 정보를 활용하는 것이 다른 VLM 기반의 제로샷 inference 보다는 성능이 잘 나오는데, 하나의 동작을 하는데 시간이 이렇게 오래걸린다면 뭔가 의미가 좀 떨어지지 않나,, 생각도 들었습니다. 다만 지금 글을 쓰는 와중에 강화학습이나 다른 방법들을 생각해봐도 인간의 개입없이 이정도 수준의 작업성공률을 보이는 프레임워크는 real world, human demonstration등 다른 cost를 줄여준 것만으로도 충분한 의미를 갖는것 같습니다.
안녕하세요 리뷰 감사합니다. 잘 읽었습니다.
꽃에 물을 따르라는 사람이 보기엔 단순한 태스크이지만 이 태스크 하나를 수행하기 위해 정말 많은 모델과 방법론이 적용된다는 점에서 놀랍네요!
질문이 몇개 있는데요! gpt를 이용해서 생성된 비디오에 대한 검증 과정이 이뤄지는 부분에서 영상에 사람의 손이 나와야 하고 이전 프레임과의 다른 점이 있어야 하며 결국 action_done에 대한 답이 Yes가 나와야 해당 프레임을 쓸 수 있게 되는 것인가요?
그리고 추정된 pose에 대해서 슬라이딩 윈도우를 중심으로 한 moving average filter가 적용된다고 하셨는데요 그게 어떻게 적용되는지가 조금 와닿지가 않아요 조금 더 설명 부탁드려도 될까요?
감사합니다!
안녕하세요 지연님 댓글 감사합니다.
GPT에게 일정 간격으로 샘플링된 영상을 보여주고 주어진 명령이 실행된 영상인가? 에 대한 답변을 위에 프롬프트 예시와 같이 주고 Yes라는 답변을 받으면 전체 비디오를 사용합니다.
moving average filter같은 경우는
윈도우 정의 -> 특정 프레임 N을 중심으로 앞뒤 각 몇 프레임씩 묶어 윈도우를 구성
평균 계산 -> 해당 윈도우 내의 여러 프레임에 대해, pose trajectory 의 평균값을 계산한 뒤에
프레임 N의 pose를 이 평균값으로 대체하여, 갑작스러운 변동 (노이즈)을 줄여줍니다.
영상의 프레임들에 대해 위 과정을 반복해주면 됩니다.
영규님 좋은 리뷰 감사합니다.
video generation을 통해 시연 연상을 만들고 이를 활용하여 로봇 작업에 적용한다는 점이 새로운 접근인 것 같습니다. 또한 해당 파이프라인에 대한 성능이 확실한 성능 개선을 보이고 있어 인상적입니다. 이러한 파이프라인을 고도화하는 연구들이 많이 이루어질 것 같습니다.
한가지 궁금한 점이 있습니다. 영상을 생성한 뒤, 4개의 프레임을 샘플링하여 VLM(GPT)으로 검증한다고 하셨는데, 프롬프트를 보면 영상 내 action이 완료되었는지에 대한 이진 분류(yes/no)로 검증을 수행하는 것으로 보입니다. 해당 논문에서 다른 기존의 이미지 생성 결과에서 보면 KingV1.6은 물뿌리개의 외형(색상)이 조금 달라지는 것을 확인할 수 있는데, 이러한 것은 영향을 따로 주지 않을 지 영규님의 의견이 궁금합니다.
안녕하세요 승현님 댓글 감사합니다.
액션 완료에 대한 이진 분류로 검증을 수행하는 것이 맞습니다. 물뿌리개의 외형같은 경우는 실제 성능에는 영향이 적지 않을까,, 싶습니다. 영상의 핵심은 액션이 올바르게 수행 되었느냐의 관점이기 때문에, 외형은 로봇의 인식에 문제가 생길만큼의 변형이 아닌이상 영향을 크게 미치지는 않을 것 같습니다.
안녕하세요 영규님 좋은 논문 리뷰 감사합니다.
가끔 들었던 생각이 실제로 이렇게 논문에서 사용되니까 신기하네요!
읽으면서 느꼈던게 이 모델의 성능은 비디오 생성 모델의 성능에 많은 영향을 받을 것 같네요.
질문 드리겠습니다.
Q1. task를 학습할 때 하나의 비디오 데이터만 가지고 하는건가요?
Q2. 주전자로 물을 주는 task를 보면 camera view가 글에서 나온 저거 하나만 사용하나요? 로봇 ee에 붙어 있는 camera는 없는건가요?
Q3. Q2질문과 이어지는 것 같은데 지금 사용하는 ai worker처럼 로봇 ee쪽에 카메라 view를 추가해서 학습에 사용한다면 더 좋은 성능을 기대할 수 있지 않을까요?! (비디오 생성 모델이 이런 view는 생성을 잘못하나요?)
좋은 리뷰 잘 읽었습니다. 감사합니다 !!