안녕하세요. 이번엔 text 관련 태스크이지만 detection, recognition도 아닌 segmentation 논문을 가져왔습니다. Text segmentation 모델을 제안한 연구는 아니고요 Segment Anything Model로 text segmentation 을 수행하게 하는데 이때 텍스트 분야에 더 적합한 더 fine-grained된 visual prompt를 제안한 연구입니다.
1. Introduction
텍스트를 다루는 태스크로는 텍스트 검출, 인식, spotting, 생성, VQA, visual information extraction (VIE)가 있습니다. 오늘 다루고자 하는 텍스트 세그멘테이션도 근래 많은 사람들로부터 관심을 갖는 주제 중 하나입니다. 텍스트의 위치를 보다 큰 범위에서 찾는 바운딩 박스보다 픽셀 레벨에서 텍스트 개체를 구분하는 텍스트 세그멘테이션을 통해 이미지에서 텍스트만을 지우는 text erasure, 텍스트이 스타일은 유지한 채 내용만을 변경하는 scene text editing 같은 downstream task에 보다 유용하기 때문에 더욱 주목을 받고 있다고 합니다. 하지만 픽세 레벨의 어노테이션은 많은 비용이 드는 작업이라 퀄리티 좋은 text segmentation이 없고 이를 구축하는 것 또한 어렵다는 문제가 있다고 합니다.
이전에는 text detection 데이터셋인 COCO-Text, MLT17를 가지고 준지도 학습을 해 구축한 COCO-TS와 MLT_S가 있기는 했지만, 정확도가 떨어진다고 합니다. 그렇기 때문에 더 간편하게 고품질의 세그멘테인션 데이터셋을 구축할 필요가 있다고 했습니다. 지금 소개하려는 논문도 이 문제를 다룬 논문입니다.
vision 파운데이션 모델인 Segment Anything Model (SAM)은 point, bbox, text, mask와 같은 visual prompt로 정확하게 보고자 하는 개체를 정확하게 이미지로 부터 분리할 수 있다는 장점이 있습니다. 대량의 데이터셋을 가지고 학습한 덕에 여러 도메인에서 동일하게 적용할 수 있었는데요. 텍스트 분야에서도 동일하게 적용이 될 수 있었습니다.
다만 깔끔하게 이미지로 부터 text를 character 단위로 깔끔하게 분리하는 건 어려웠는데요.. 저자는 그에 대한 원인으로 두가지 이유를 듭니다. 첫째, 단어 단위의 bounding box를 SAM의 prompt를 주는 경우 문자 하나를 독립적으로 세그멘테이션 하는 게 어렵다는 것이었습니다. SAM은 단어를 구성하는 문자들을 개별적으로 처리하기 보단 하나로 뭉뚱그려서 생각하기 때문에 아래와 같이 구분이 어렵습니다.

그렇기 때문에 문자별로 구분되어서 segmentation 되기를 원한다면 다음과 같이 character level의 바운딩 박스를 프롬프트가 필요합니다.

두번째 문제는 위와 같이 char-level bbox의 prompt를 사용한다고 해도 여전히 깔끔한 segmentation 결과를 기대하기가 어렵다는 것인데 over and under segmentation 되는 경우가 많기 때문입니다. 텍스트 영역을 전경 그 외의 것을 배경이라고 할 수 있는데 텍스트 영역 안에 있는 구멍 즉 전경에 둘러쌓인 배경을 전경과 분리해서 인식하지 못하고 통째로 하나의 전경으로 분리하는 경우가 많아 over segmentaion이 발생합니다. 아래의 예시로 부터 확인이 가능합니다. SAM이 학습한 데이터에서 실제 개체 내부에 개체가 아닌 영역인 구멍이 있어서 따로 구분해서 분리해야 하는 경우가 많이 없었기 때문이라고 합니다.
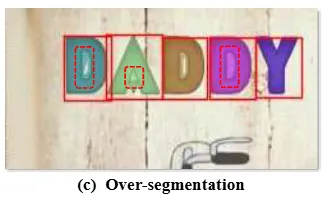
그리고 텍스트의 크기가 큰 경우 텍스트 영역을 충분히 마스킹 하지 못하는 under segmentation 문제도 있습니다.
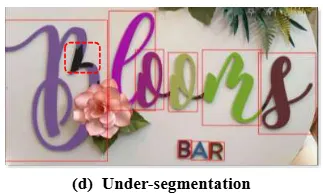
기존의 bbox 형태의 prompt로는 SAM을 통해 정확하게 text image에서 텍스트 영역에 대해서 segmentation 하는 게 어려웠기 때문에 저자는 새로운 prompt를 사용할 것과 이를 생성하는 과정을 새롭게 제안합니다. 해당 프레임워크는 논문에서 Character-level visual prompt Segment Anything Model (Char-SAM)으로 지칭됩니다. 프레임워크의 주 요소는 크게 두가지로 Character Bounding-box Refinement (CBR) 모듈과 Character Glypth Refinement (CGR) 모듈로 구성됩니다. CBR 모듈은 word-level annotation를 char-level annotation으로 refine하고요. CGR 모듈은 glyph 정보로 이미지에서 텍스트와 배경을 확실하게 구분하고 이를 이용해 앞서 언급한 over, under segmentation을 해결할 수 있게 합니다. 모든 과정은 추가적인 학습이 필요하지 않습니다.
이 논문의 기여점을 정리하면 다음과 같습니다.
- 강력한 segmentation 능력을 갖는 파운데이션 모델인 SAM에 논문이 제안하는 char level prompt로 추가적인 학습 없이도 text segmentation을 보다 정교하게 할 수 있게 하였습니다.
- CBR, CGR 모듈로 word-level annotation 을 가지고 fine-grained한 char-level annotation 을 생성하였고 추가적으로 bbox 형태의 char-level annotation 만으로도 가지는 문제점인 over, under segmentation 을 효과적으로 다루었습니다.
- COCO-Text, MLT17이라고 text detection 에 사용되는 데이터셋으로 charcter level의 segmentation 데이터셋인 COCO_TS_refined, MLT_S_refined를 구축하였습니다.
2. Methods
A. Framework
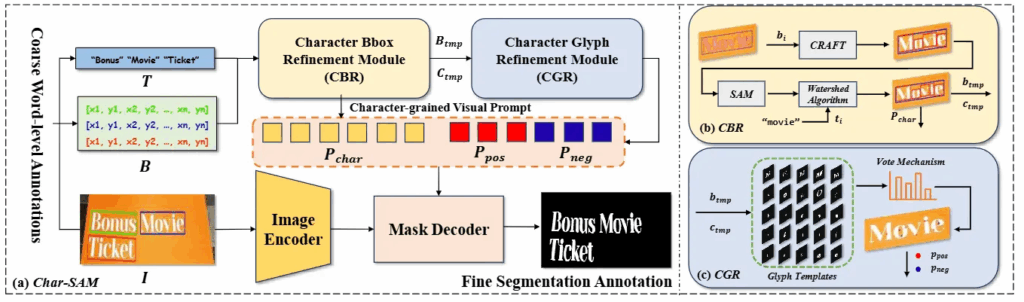
위 그림은 Char-SAM의 방법으로 실제 SAM을 이용해 text segmentation을 수행하기 위해 필요한 prompt를 재구성하고 이를 활용해서 최종적으로 segmentation 까지 진행해서 text image에 대해 pixel level의 annotation을 생성하는 과정을 그린 것입니다.
Char-SAM 프레임워크가 제안된 목적은 word-level annotation을 pixel-level annotation으로 재구성하기 위함입니다. 아래가 해당 프레임워크의 도식도인데. 이미지와 단어에 대한 바운딩 박스와 text transcription이 입력으로 전달됩니다 . i번째 텍스트 이미지의 bbox 정보와 transcription 정보는 각각 b_{i}, t_{i}입니다. CBR 모듈을 통과하고 나면 charcter 단위로 쪼개져 character level의 바운딩 박스 B_tmp와 해당 문자에 대한 character 정보 C_{tmp}가 생성됩니다. 여기서 문자 단위의 바운딩 박스 정보는 나중에 SAM의 prompt 로 사용될 visual prompt가 P_{char} 됩니다. 그 다음 CGR모듈은 입력 앞서 CBR에서 생성한 B_{tmp}와 C_{tmp}를 입력으로 받아 각 문자에 대응되는 glyph 정보를 활용해 pixel level로 전경에 해당하는 점을 positive point prompt로 배경인 것은 negative point prompt로 구성합니다. 최종적으로는 P_{char} , P_{pos}, P_{neg}를 SAM에 입력해 보다 정확한 Segmentation annotation 을 추출합니다.
그럼, 다음으로는 각 모듈에 대한 세부적인 설명을 덧붙이겠습니다.
B. Character Bounding-box Refinement Module
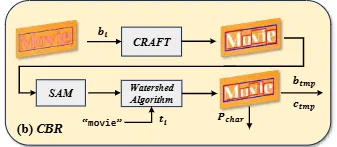
우선 문자 단위로 분리하는 text detection 모델인 CRAFT로 word level의 annotation을 character level로 쪼갭니다. 이때, 일부 근접해 있는 문자들이 하나로 detect된 되어 완전히 분리되지 않은 경우도 있었는데요. 이런 경우 transcription을 가지고 각 문자 마다 하나의 바운딩 박스가 할당되었는지를 확인하고 ‘vi’ 처럼 두개의 단어가 하나의 박스로 쳐져 있는 경우에는 SAM 모델에 입력하고 watershed algorithm을 통해 각 문자를 분리합니다. 이후 모든 문자에 대해서 나눠진 후 char-level 의 bbox를 이용해 입력 이미지를 crop한 뒤 text recognizer를 이용해 각 문자가 어떤 character인지를 예측하도록 합니다.

C. Character Glypgh Refinement Module
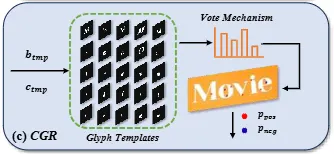
CBR 모듈로 각 문자에 대한 개별적인 bbox 좌표와 category를 알 수 있었습니다. 물론 character level의 bbox만으로 SAM으로 부터 깔끔한 segmenation mask를 얻지 못한다는 것은 앞서 설명드렸습니다. 이를 보안하고자 제안된 것이 CGR입니다. natural scene text는 각자 다른 형태와 (나열된) 방향을 갖고 있어 모두 다 다르게 생겼습니다. 하지만 저자는 그럼에도 문자들은 종류마다 각각 구분되는 특징을 가지는데 이를 기본적인 문자 구조인 glyph information이라고 설명하고 이를 사용하는데요. 각 문자 마다 다른 스타일의 폰으로 이미지 형태의 템플릿을 그립니다. 위 그림에서 이진 마스크로 보이는 것들이 glyph 템플릿의 모음입니다. 하나의 문자에 대해서 여러 종류의 템플릿이 사용되는 것을 확인할 수 있습니다. 각 문자 마다 템플릿을 쌓아 픽셀마다 전경과 배경이 등장하는 빈도수를 계산합니다. 위 그림에서는 이 과정을 ‘vote mechanism’이라고 적어두었네요. 아무튼, 모든 템플릿에서 60% 이상으로 전경이거나 배경인 경우 최종적으로 point prompt로 남게 됩니다. 그래서 전경인 텍스트에 해당하는 point들은 positive point로 배경을 negative point로 분리됩니다. 이후에는 CBR 모듈로 부터 얻었던 charcter에 대한 bbox P_char와 positive, negative point prompt를 함께 SAM에 전달해 텍스트 영역인 전경과 그 외의 배경을 잘 구분해 정교한 segmentation mask를 따게 됩니다.
3. Experiments
A. Datasets
TextSeg
4024장의 높은 퀄리티의 text segmentation 데이터셋입니다. word level, character level의 bbox와 character level의 segmentation mask도 제공됩니다.
COCO_TS
detection을 위해 구축된 COCO-Text 데이터셋의 bbox 정보를 가지고 semi-supervised learning을 통해 만든 segmentation 데이터셋으로 총 14690장으로 구성됩니다.
MLT_S
COCO_TS와 마찬가지로 text detection 용 데이터셋인 MLT에 대해서 학습으로 구축한 데이터셋으로 6896장 마련되어 있으며 TextSeg에 비해 퀄리티가 좋지 않습니다.
B. Implementation Details
어노테이션 생성을 위한 SAM은 SAM-B를 베이스라인으로 두고 실험을 진행했다고 합니다. 이미지 인코더로는 ViT-B를 사용하였습니다.
C. Comparison with SOTA Approaches
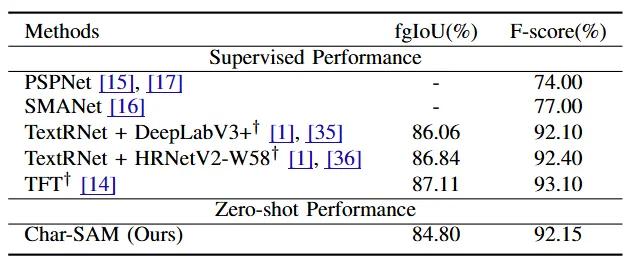
기존 supervised learning을 하는 segementation 모델과 비교했을 때 Char-SAM의 F-Score는 제일 높은 점수는 아니지만 최신 SOTA모델들과 비슷한 값을 보였고요 SOTA인 TFT 모델과 1% 정도의 차이만을 보임으로써 Char-SAM은 학습을 필요로 하지 않는 다는 점에서는 꽤 의미 있는 결과라고 생각됩니다.
D. Ablation Study

word level의 바운딩 박스를 visual prompt로 SAM에 주는 것과 비교했을 때 CBR 모듈을 추가해서 charcter level의 bbox로 조정했을 때 fgIoU와 F-Score의 향상이 있었습니다. 그리고 여기에 CGR 모듈까지 추가한 경우에는 3~4%의 향상이 됐었습니다. 테이블에서 TN은 CGR 모듈에서 사용되는 템플릿의 개수라고 보시면 됩니다. 문자에 대해서 더 많은 템플릿으로 전경과 배경을 구분한다면 보다 더 확실히 구분될 수 있었기 때문에 이런 성능 향상을 보인 것일 겁니다.
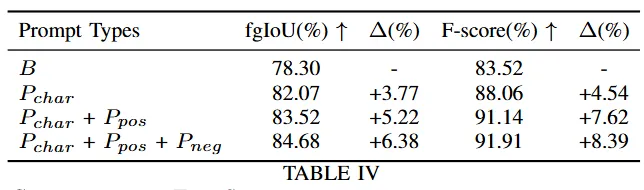
위는 prompt의 종류를 달리하며 진행한 ablation study의 결과인데요. 더 fine한 visual prompt를 사용하는 것이 더 정확한 segmentation 결과를 내는 것으로 확인이 되었습니다.
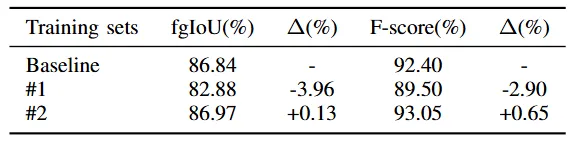
그 다음은 실제 Char-SAM 프레임워크를 따라 만든 데이터셋인 COCO_TS_refined, MLT_S_refined가 COCO_TS, MLT_S 보다 얼마나 더 정교하게 annotation이 되었고 실제 학습에 어떤 영향을 미치는지를 확인한 실험입니다. 베이스라인으로는 TextRNet+DeepLabV3+라는 모델을 TextSeg라는 데이터셋에 대해 학습해 실험했고 이후 #1과 #2는 각각 학습 데이터로 COCO_TS, MLT_S를 그리고 COCO_TS_refined, MLT_S_refined를 추가한 경우입니다. 이 논문에서 제안한 대로 annotation이 된 데이터셋을 추가 데이터로 학습하는 것이 성능 향상에 도움이 되었습니다. 반면에 #1의 경우에는 성능이 비교적 큰 폭으로 하락해 더욱 더 두 데이터셋간의 퀄리티 차이를 가늠해 볼 수 있는 결과였습니다.
마지막으로 다음은 정성적 결과입니다.

4. Conclusion
이제 정리하고 마무리를 짓자면 지금까지 소개해 드린 논문은 SAM을 이용해 text image로 부터 텍스트만을 따 와 text segmentation annotation을 수행하는 프레임워를 제안한 연구였습니다. 단위 단위의 bbox 만으로는 char별 구분이 어려워 더 fine한 char level의 bbox로 refine하는 CBR 모듈과 charcter 단위의 bbox를 prompt로 주었을 때 생기는 over 그리고 under segmentation 모듈의 문제를 glyph template 사용으로 해결한 CGR 모듈로 구성된 프레임워크 였습니다. 그리고 마지막에 sota와의 비교 실험과 여러 ablation study로 저자의 제안의 효과 또한 확인이 되었습니다.
안녕하세요. 류지연 연구원님, 좋은 리뷰 감사합니다.
Char-SAM이 학습없이도 덱스트 마스킹을 정확하게 생성하는게 흥미롭네요. 요즘에는 자세한 분석과 함께 거대 모델을 잘 활용하는 연구들이 많이 등장하고 있는 것 같습니다. text segmentation에 대한 지식이 부족하여 기초적인 부분부터 이해가 잘 안되네요 ㅎㅎ. bbox refinement 모듈에서 CRAFT의 결과가 여러 알파벳을 포함하고 있다면, transcription을 통해 확인 후 watershed 알고리즘을 통해 분리한다고 언급해주셨는데, 본문의 내용만으로는 GT가 없는 상황에서 학습 없이 여러 알파벳을 포함하고 있는 지의 여부를 판단하는 방법이 잘 이해가 되지 않습니다. 조금만 더 자세히 설명 부탁드립니다. 그리고, glyph가 무슨 용어인지 모르겠어서 검색해보니 자체라는 뜻인 것 같은데(사실 자체도 뭔지 잘 모르겠습니다), 문자를 여러개로 쪼갰을 때의 그 쪼개진 모습이라고 생각하면 될까요? 본 연구에서 glyph가 어떤 걸 의미하는 지도 궁금합니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
본 논문에서 제안된 CBR 모듈을 통과하면 SAM prompt로 사용되는 prompt가 되는 것으로 보이고, CGR 모듈은 positive point prompt와 negative point prompt를 output으로 뱉는 것 같은데, mask decoder 내에서 이 P_{pos}와 P_{neg}가 어떻기 동작하는지 궁금합니다.
또 ablation study table1이랑 2에서 각각 # 1과 P_{char}은 CGR 모듈을 안쓰는 둘 다 동일한 실험인 것 같은데, 성능 차이가 나는 것은 어떤 차이가 있어서 그런 것인가요?
안녕하세요 지연님 좋은 리뷰 감사합니다
간단한 질문하나 남기겠습니다…
Char-SAM에서 fgIoU가 뭔가요 그냥 IOU랑은 차이가 있는건지…
segmentation에서는 이게 어떻게 계산되는건가요? 궁금합니다
감사합니다