안녕하세요 이번에 들고온 논문은 2022년에 arxiv에 올라온 BinsFormer:Revisiting Adaptive Bins forMonocular Depth Estimation라는 논문입니다.
이번에는 이전에 리뷰했던 Scale Depth의 근간이 되는 BinsFormer를 직접 읽어보면서, 무엇이 핵심 아이디어였고 이후 방법들이 무엇을 덧붙였는지 정리해보고자 하였고 이를 리뷰로 들고 오게 되었습니다.
바로 리뷰 시작하도록 하겠습니다.
introduction
기존의 픽셀 단위 depth를 regression하는 것과는 다르게 bin 이라는 개념을 도입해서 depth를 어떠한 depth 범위의 구간으로 classification하는 연구가 진행되었습니다. BinsFormer는 마찬가지로 bin이라는 개념을 활용하고 그 구간을 adaptive하게 생성하고 이를 토대로 depth를 추정하는 방식의 방법론이라고 보시면 될 것 같습니다. 자세한 내용은 아래피규어를 바탕으로 설명드리도록 하겠습니다.
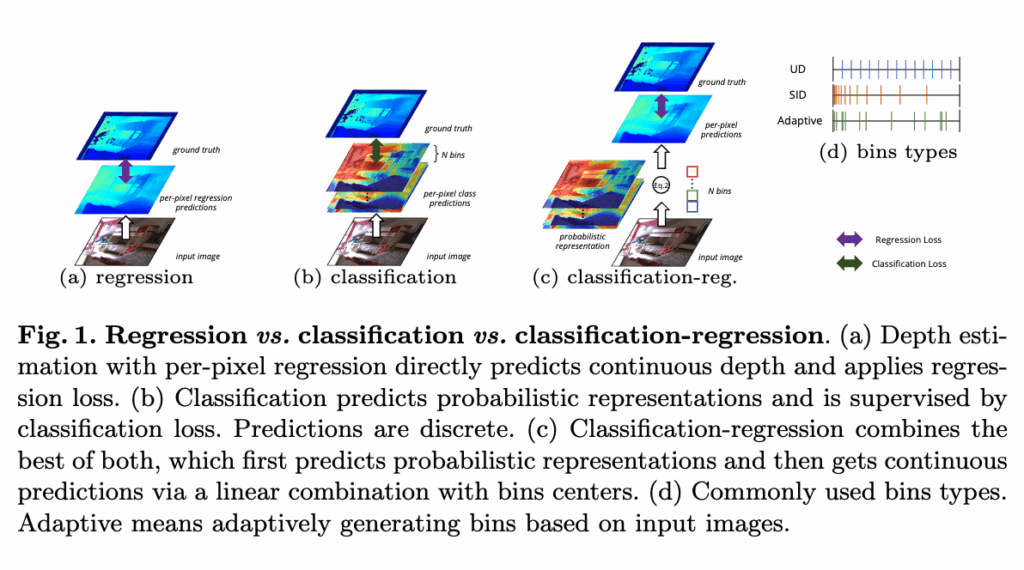
기존의 픽셀 단위로 depth를 regression하는 것(a)이 주류였는데, 이러한 방식은 깊이를 깔끔하게 예측할 수 있긴 하지만 학습과정에서 수렴이 느리고 성능 또한 아쉬운 경우가 있었다고 합니다. 반대로 연속 깊이를 여러 구간으로 이산화해서 그 구간을 픽셀별 classification하는 방식(픽셀별 분류 문제(b))으로의 접근은 성능은 오르지만, 경계가 들쭉날쭉하게 나타난다는 단점이 있었습니다. 그래서 Adabins라는 각 픽셀에 대해서 이 픽셀이 어느 bin에 속할지 확률적 표현을 학습하고 빈 중심(bin centers)과의 가중합으로 최종 깊이 값을 예측하는 즉, 분류-회귀 혼합 아이디어(c)가 등장했습니다. BinsFormer는 그 혼합 구조를 바탕으로 Adabins 처럼 bin이라는 구간을 adaptive하게 생성하는 방식을 사용하되 visual feature 생성과 bin 생성은 따로 진행을 하면서 트랜스포머를 도입하여 Bin과 visual feature 간의 상호작용을 통해 bin의 품질을 올리고자 하는 쪽에 초점을 둔 프레임워크라고 보시면 될 것 같습니다.
앞서 언급했던 이전에 먼저 나온 비슷한 연구인 Adabins라는 방법론에 대한 한계를 관찰하면서 이를 보완한 것이 binsformer 라고 보시면 될 것 같습니다. 그래서 저자가 관찰한 Adabins의 문제점이 무엇이고 binsformer는 이부분을 어떻게 보완했는지가 해당 논문을 이해하는데에 있어서 중요한 요소라는 생각이 듭니다.
짧게 binsformer가 Adabins의 어떠한 부분을 보완하고 개선을 하였는지 언급하고 넘어가자면,
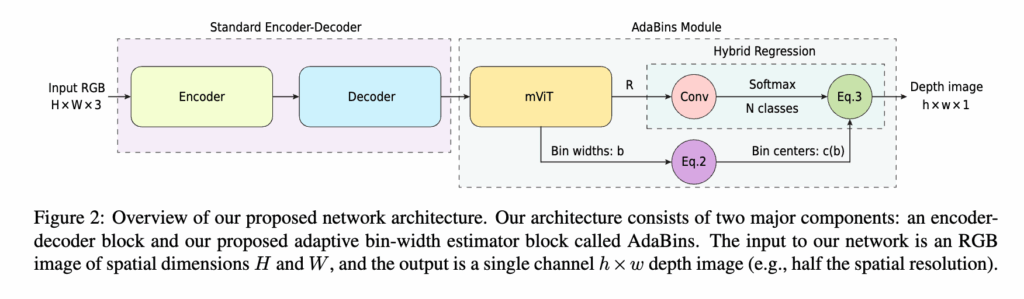
먼저 위는 Adabins의 아키텍쳐로 Adabins라는 친구는 마지막 고해상도 피처(decoder 마지막 층의 출력) 하나만을 의존해 bins를 뽑습니다. 그래서 1. 전역 문맥을 활용하기 어렵고 2. 같은 피처에서 빈과 픽셀 분포를 함께 예측해서 서로간에 학습솨정에서 간섭이 생긴다는 점 게다가 3. Chamfer loss가 불필요한 inductive bias를 만들 수 있다는 한계가 있었다고 보시면 될 것 같습니다.
3번에 대해서는 논문에서 자세하게 나와있지 않지만 찾아본 내용을 바탕으로 풀어서 설명드리면
여기서 말하는 Chamfer loss의 컨셉을 간단하게 설명드리면 예측한 점들이 정답 점들에 얼마나 가까이 붙어 있는지를 양쪽 방향으로 측정해서 더한 값입니다.
AdaBins 맥락에서는 예측한 bin 중심들의 집합과 GT 깊이 분포로부터 만든 점들 사이에서 해당 loss를 사용하게 된다고 보시면 될 것 같습니다. 어떻게 보면 좋은 빈은 GT 깊이 분포의 모양을 따라야 한다! 는 가정을 학습에 직접 주입하는 셈입니다. 어떻게 보면 제약을 거는 것이라고 볼 수 있습니다. 따라서 저자는 이러한 부분이 inductive bias를 만든다는 점으로 언급한 것 같습니다.
BinsFormer나 Adabins와 같은 분류-회귀 계열에서 bins의 중심은 어디까지나 기저 역할을 할 뿐이지 최종 깊이는 픽셀별 확률 P와 bin의 중심과의 가중합으로 나오기 때문에 정답 분포에 딱 붙은 빈이 반드시 최선은 아닐 수도 있습니다. 근데 Chamfer loss를 사용하게 되면 bin은 GT 분포를 따라야 한다!는 제약이 강하게 들어가서 위와 같은 문제점을 언급한 것 같습니다.
BinsFormer는 이 지점을 바로 고쳐버립니다. 1. bin 생성은 트랜스포머 쿼리가 멀티스케일 피처와 차례로 상호작용하면서 set-to-set으로 전담하고 2. 픽셀 분포는 별도의 픽셀 경로에서 뽑는 식으로 경로를 분리합니다. 그래서 저해상도에서 전역적인 장면의 구조나 스케일을 먼저 맞추고, 고해상도로 갈수록 디테일을 coarse-to-fine으로 다듬는 흐름으로 자연스럽게 만들어진다고 보시면 될 것 같습니다.
또 3. BinsFormer는 여기서 살짝 방향을 바꿔서 Chamfer loss처럼 빈을 직접 제약하지 않고, scene query를 도입해서 이거에 classification loss을 추가적으로 사용합니다. 그래서 씬에 대한 정보를 토대로 bin을 예측 할 수 있는 방식으로 동작하게 됩니다. 결과적으로 전역적인 문맥과 로컬의 디테일이 서로를 해치지 않으면서 서로의 장점들에 대해서 attention 하는 학습이 이루어지게 됩니다.
바로 Method 파트로 넘어가도록 하겠습니다.
Method
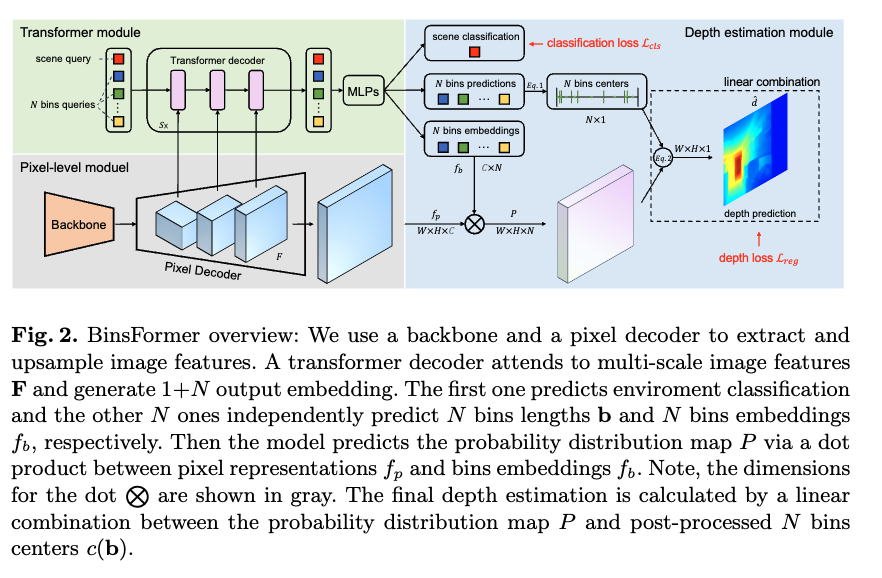
저자가 말하는 BinsFormer의 큰 틀은 딱 세 덩어리라고 보시면 될 것 같습니다. 픽셀 레벨 모듈, Transformer 모듈, 깊이 추정 모듈. 여기에 성능을 조금 더 끌어올리기 위해 보조적인 씬 분류(scene query) 와 멀티스케일 feature map의 활용을 했다고 보시면 될 것 같습니다.
큰 흐름은 입력 RGB 이미지가 들어오면, 픽셀 레벨 모듈이 먼저 이미지를 쭉 훑어서 멀티스케일 특징 F와 f_p 를 뽑습니다. 그리고 멀티스케일 피쳐맵은 Transformer의 키, 밸류로 들어가. 여러 개의 쿼리 토큰이 어텐션으로 멀티스케일 특징 F의 정보를 흡수합니다. 그리고 나온 각 쿼리는 작은 MLP 헤드를 거쳐 두 가지를 뽑습니다. 하나는 bin의 길이 b(깊이 축을 나누는 폭), 다른 하나는 각 빈을 대표하는 bin 임베딩 f_b입니다. 즉, 빈을 클래스처럼 직접 예측하게 됩니다.
마지막으로 깊이를 만드는 단계입니다. 피쳐맵 f_p와 bin 임베딩 f_b의 유사도를 구해 픽셀별 확률분포 P 를 만들고(Softmax) bin의 길이 b를 이용해 bin의 중심을 계산한 뒤, P와 bin의 중심을 가중합해서 최종 깊이를 얻게됩니다. 정리하면 이 픽셀은 각 빈에 속할 확률이 이만큼이니, 그 확률로 빈 중심을 섞어서 연속적인 깊이를 추정한다라고 보시면 될 것 같습니다.
아래는 위 내용을 수식적으로 푼 것 입니다.
bin의 중심 계산 식
c(b_i) \;=\; d_{\min} + (d_{\max}-d_{\min}) \left( \frac{b_i}{2} + \sum_{j=1}^{i-1} b_j \right)여기서 c(b_i)는 i번째 빈의 중심 깊이이고 d_{\max}와 d_{\min}은 각각 데이터셋의 유효 깊이 최대,최소값입니다. f_p와 bin 임베딩 f_b 사이의 내적을 통해 유사도 맵을 얻고, 이를 Softmax를 태워 확률 분포 맵 P \in \mathbb{R}^{H \times W \times N}을 만들고 마지막으로, 각 픽셀에서 최종 깊이 값 \hat d 는 그 픽셀의 확률 분포와 깊이 빈 중심 c(b)의 가중합으로 계산됩니다.
\hat d \;=\; \sum_{i=1}^{N} c(b_i)\, p_i그리고 scene query의 역할도 자세하게 설명드리면 이미지가 어떤 환경(실내/실외, 주방/교실 등)에 속하는지 장면 분류를 할 수 있도록 학습이 이루어지고,학습 중 self-attention을(transformer decoder) 통해 그 씬에 대한 정보들이 빈 쿼리들에게 간접적으로 주입되게 됩니다.
참고로 Scale Depth는 여기서 더 나아가 CLIP 텍스트까지 활용해서 씬 카테고리의 언어 정보를 적극적으로 쓰는 편입니다(특히 실내 세분류). BinsFormer는 이미지 내부의 장면 분류까지만 보조로 쓰고 끝나는 느낌이고, Scale Depth는 텍스트 조건으로 스케일을 더 명시적으로 잡는다는 점이 차이 같습니다.
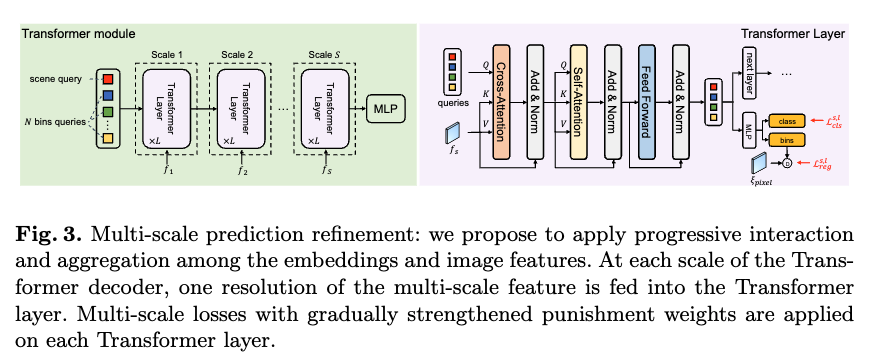
그리고 멀티스케일의 피쳐맵을 뽑아냄으로써 낮은 해상도 특징에서 전반적인 장면의 구조와 스케일을 먼저 맞추고, 해상도를 올려가며면서 로컬한 영역의 디테일을 점점 fine하게 만드는 coarse-to-fine 흐름으로 동작합니다. Transformer 쿼리들이 스케일을 하나씩 올라가며 F와 반복적으로 상호작용하기 때문에 전역과 국소 정보가 단계적으로 잘 합쳐진다고 보시면 될 것 같습니다.
결과적으로 최종 depth map을 예측하게 되면 이를 Scale invariant loss를 통해 손실을 계산합니다.
\mathcal{L}_{\mathrm{reg}} \;=\; \alpha \,\sqrt{ \frac{1}{T}\sum_i g_i^{2} \;-\; \frac{\lambda}{T^{2}}\left(\sum_i g_i\right)^{2} }여기서 g_i = \log \tilde d_i - \log d_i이고 d_i는 GT depth \tilde d_i는 모델이 예측한 depth 입니다. 그리고 T 는 유효한 GT 값을 갖는 픽셀 수를 나타냅니다.
그래 최종적으로 사용되는 손실함수식은 추가적인 멀티스케일, 멀티레이어도 활용하여 이를 모두 더한 것을 최종적인 loss로 사용합니다.
\mathcal L_{\text{total}} =\sum_{s=1}^{S}\Bigg( w_s \sum_{l=1}^{L}\big(\underbrace{\mathcal L^{s,l}<em>{\text{reg}}}</em>{\text{깊이 회귀(SI)}} \;+\; \mu\,\underbrace{\mathcal L^{s,l}<em>{\text{cls}}}</em>{\text{씬 분류 CE}}\big)\Bigg)- s=1\ldots S: 스케일 인덱스(저해상도→고해상도)
- l=1\ldots L: 해당 스케일의 Transformer 레이어 인덱스. 각 레이어에서 중간 예측을 내고 보조 손실로 사용.
- \mathcal L^{s,l}_{\text{reg}}: 그 레이어에서 낸 depth map에 대한 Scale-Invariant loss
- \mathcal L^{s,l}_{\text{cls}}: 같은 레이어의 scene query에 대한 CE loss. NYU처럼 라벨이 있을 때만 쓰고, KITTI처럼 없으면 0이라고 보시면 됩니다.
- \mu: 씬 분류 손실에 대한 가중치
- w_s: 스케일별 가중치
Experiments
실험 부분에서는 세 가지 데이터셋으로 평가합니다.
그리고 scale depth랑은 다르게 실내, 실외 같이 학습시키지 않고 각각 따로 학습하여 독립적으로 평가합니다.
KITTI(실외), NYU-Depth v2(실내), SUN RGB-D(실내-일반화 성능 평가용)
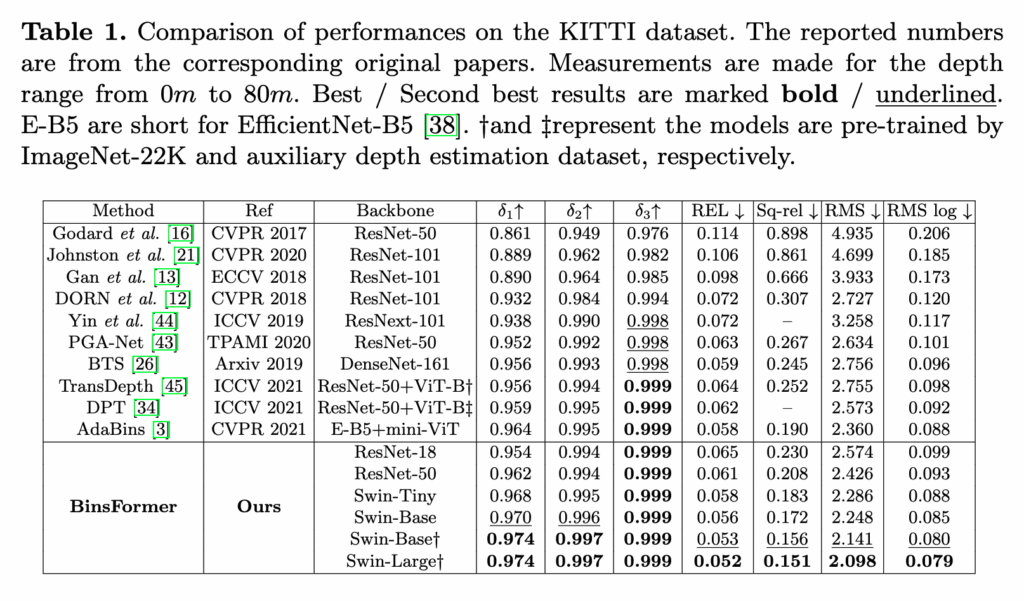

표 1은 KITTI(Eigen, 0–80m)에서의 비교테이블인데. 백본이 가벼워도 경쟁력 있다 라는 것을 확인 하실 수 있고 transformer 기반의 백본을 사용하면 SOTA성능을 보이는 것을 확인 하실 수 있습니다.
백본 스케일링을 보면, 어찌보면 당연하겠지만 ResNet-18 -> ResNet-50 -> Swin-Tiny -> Swin-Base(†) -> Swin-Large(†)로 갈수록 오차 지표가 점점 개선되는 게 보이지만 동일 백본 비교대상은 2개 밖에는 없었습니다 . 결과적으로 최종 Swin-Large(†) 는 표 내 최고 성능을 보입니다. δ3은 여러 방법이 0.999로 포화라서 실제 차이는 오차 지표쪽을 보는 게 더 낫습니다.
AdaBins(E-B5+mini-ViT)과 비교했을 때에도 모든 부분에 대해서 성능이 개선된 것을 확인하실 수 있습니다. 다만 Adabins와 백본을 동일하게 적용시켜보고 평가를 했으면 좀더 공정한 비교가 되지 않았을 까 하는 아쉬움이 있습니다.
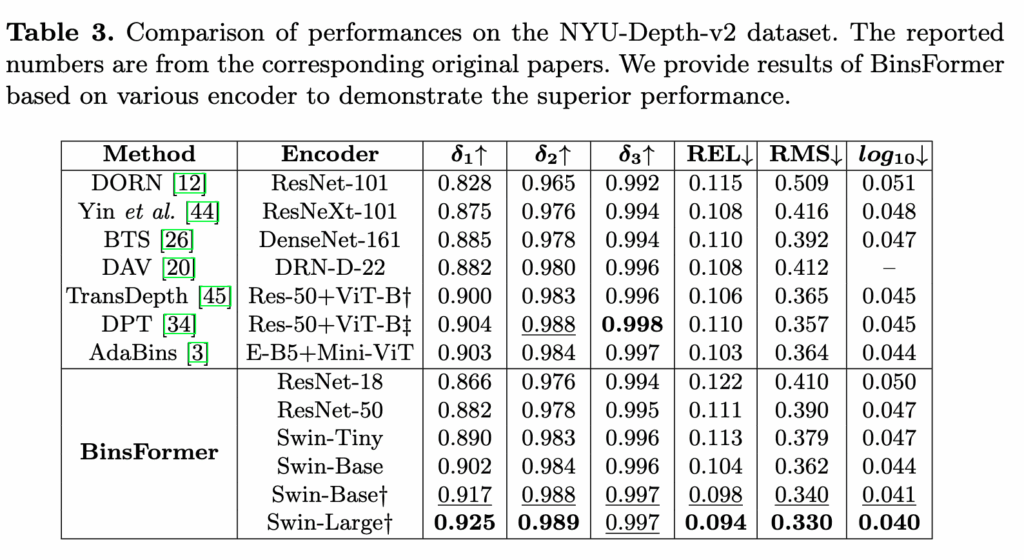
NYU-Depth v2(0–10m)에도 kitti랑 마찬가지로 백본이 강해질수록 BinsFormer가 꾸준히 올라가지만 엄청 낮지는 않지만 다소 낮은 성능을 보이는δ3의 성능에 대한 저자의 언급은 따로 없었습니다. 다만 Adabins와 비교했을 때에는 유의미한 성능 향상이 있다고 볼 수는 있을 것 같습니다.
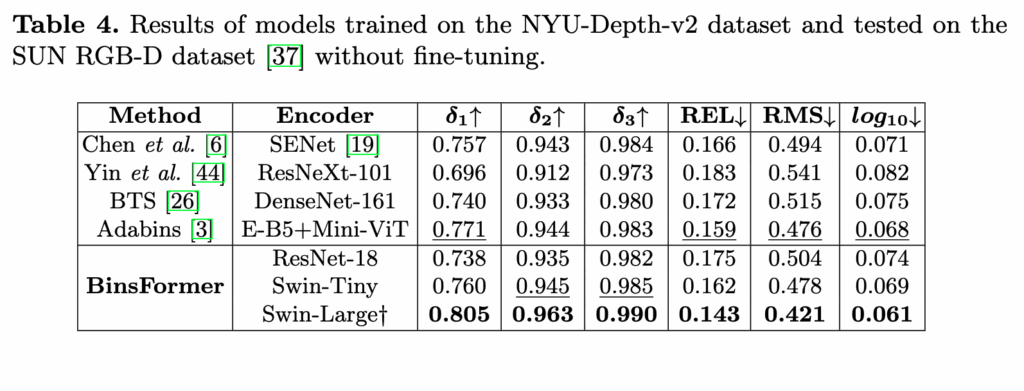
위는 NYU로만 학습하고 SUN RGB-D에서 평가했을 때의 결과입니다. 다른 실내 도메인에서의 일반화 성능을 평가하는 지표라고 생각하시면 좋을 것 같습니다.
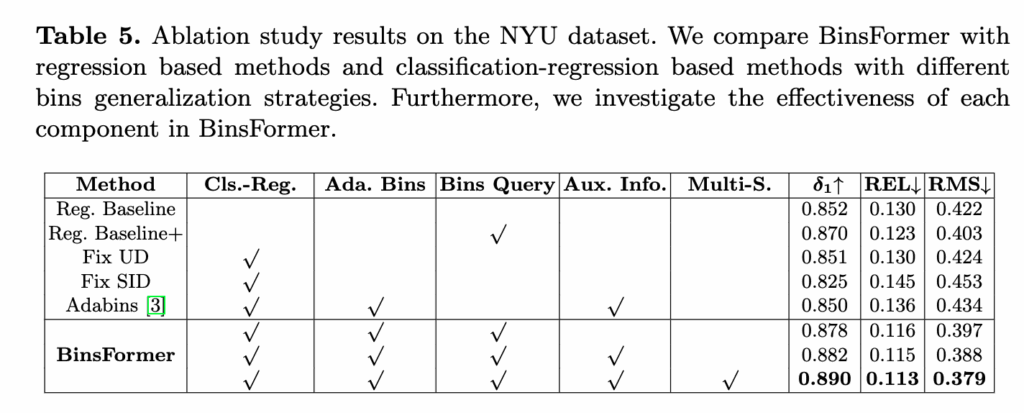
위는 BinsFormer가 어떤 구성요소로 성능을 끌어올리는지 하나씩 뜯어보는 ablation 실험표입니다. 기준선은 Reg. Baseline인데 말 그대로 BinsFormer의 픽셀 모듈만 써서(트랜스포머/깊이 모듈 없음) 픽셀별 깊이를 직접 회귀합니다. 또 여기에 트랜스포머와 쿼리 MLP만 살짝 얹고도 여전히 회귀로만 예측하는 Reg. Baseline+를 추가해 공정하게 비교했다라고 볼 수 있을 것 같고 그래서 Reg. Baseline+와 최종 BinsFormer의 차이는 회귀 vs 분류–회귀 이 부분에 있다고 보시면 될 것 같습니다. 그 다음은 분류–회귀 안에서 bin 생성 방식을 바꿔가면서 비교하는 실험을 했습니다. 고정 UD/SI처럼 미리 정한 구간을 쓰는 경우, 그리고 AdaBins처럼 adaptive bin을 쓰되 한 경로에서 같이 뽑는 경우를 포함합니다. 빈을 쿼리 기반(set-to-set)으로 전담 예측하고(=Bins Query), Aux info, 멀티스케일 피쳐(Multi-S.)까지 사용했을 때 성능이 가장 좋은 것을 확인 할 수 있습니다. (다만 저는 Aux info가 scene query를 뜻한다고 생각했는데 Adabins에 체크가 되어있는 걸 보니 헷갈리네요.. 아마 저 체크는 Adabins에서 Charmfer loss를 의미하는게 아닐까 조심스럽게 추측해봅니다.) 특히 bin의 생성을 피쳐맵 생성과 분리하고 멀티스케일을 활용하는 성능향상에 큰 몫을 하는 것으로 보입니다.
안녕하세요. 리뷰 잘 읽었습니다.
궁금한 점이 있는데, 인트로에서 Adabins의 Chamber loss가 불 필요한 inductive bias를 만들어내서 단점이다 라고 이야기를 했던 것 같은데, 이 Chamber loss를 적용하고 안하고 대해 성능이 어떻게 변화하는지 관련된 실험이 없나요? 사실 Adabins에서는 Chamber loss가 좋다고 했기 때문에 사용했지만 Binsformer에서는 이게 오히려 성능에 안좋다고 생각해서 뺀 것일텐데 정작 ablation에서는 이와 관련된 내용이 없는 것 같아서요. 괜히 Adabins를 공격하기 위해서 억지로 문제를 만든게 아닌가라는 생각이 듭니다.
그리고 Binsformer가 과연 Adabins보다 더 좋은 방법이 맞는가?에 대해서 고민해볼 필요가 있을 것 같아요. Ablation만 놓고 보면 Adabins에서 제안하는 방식이 아니라 자신들의 방식을 적용했을 때 큰 성능을 내는 것처럼 보여주기는 하거든요? 근데 테이블 3에서 Adabins과 Binsformer 성능을 비교해보면 Binsformer Swin Tiny기준으로는 Adabins가 성능이 훨씬 좋아요.
이게 Adabins는 Efficientnet B5 + miniViT를 사용하는 것이고, Binsformer는 Swin Transformer를 여러가지 쓰지만 여기서는 Swin Tiny랑 비교해야하는 것이 EfficientNet B5가 30M 정도 크기고 Swin Tiny가 28M의 파라미터 수를 가지고 있어서 인코더의 모델 크기가 비슷하므로 이 둘을 직접 비교하는게 맞는 것 같아요 (그래서 저자들도 ablation study할 때 Swin Tiny를 기준으로 실험을 진행했겠죠?).
그러면 이제 저자들이 제안하는 방법론보다 Adabins가 절대 성능이 꿀리지 않고 NYU에서는 모든 메트릭 기준으로 훨씬 더 좋은 걸 볼 수 있어서 솔직히 말하면 Binsformer가 정말로 Adabins의 문제점을 해결해서 더 좋은 방법론인가?라고 볼 수 있는지 진지하게 고민해봐야한다고 생각해요.
만약 Adabins가 추론속도나 메모리 측면에서 Binsformer보다 더 불리하다면 저자들이 그 부분을 논문에서 충분히 강조했을 것 같은데 (가령 Adabins보다 SwinT의 Binsformer가 더 GFLOPS가 낮다, 또는 FPS가 빠르다와 같이) 리뷰에서의 실험결과만 보면 그냥 성능만 리포팅하지 속도나 메모리 관점에서는 전혀 언급이 없는 것 같아요. 만약 논문에서 이와 관련된 내용이 전혀 없다면 이는 Binsformer 저자들도 속도 측면에서 강하게 어필하기 어려웠던 것이 아닐까 싶어요.
즉 Swin Tiny로 Adabins랑 맞붙으면 성능에서 지니깐, Swin Base, Large까지 다양한 크기의 모델들에 대해서 성능을 다 보임으로써 (결과적으로 Large 모델이 당연히 가장 성능이 잘 나올 수밖에 없는데) 자신들의 방법론이 타 방법론들보다 더 좋다는 식으로 비춰지게끔 테이블을 구성했다는 생각도 드네요.
그리고 아까 첫 질문에서도 이야기했지만 Adabins의 Chamber loss가 불필요한 inductive bias를 학습시킨다고 했잖아요? 그러면 NYU로 학습하고 SUN RGB-D로 inference하는 표4의 zero-shot 평가에서 Adabins는 성능이 낮게 나와야하거든요. 불필요한 inductive bias를 만들어냈으니 학습 때 보지 못한 환경에서 추론할 때 잘못된 inductive bias로 인해 뎁스 성능이 떨어져야한다는 것이죠. 근데 결과적으로는 Swin-T의 binsformer보다 더 좋긴 하거든요 성능이. 그런 관점에서도 정말 Inductive bias가 잘못된게 맞나? 라는 생각도 들긴 해요.
아무튼 저는 Binsformer가 주장하는 내용들, 특히 Adabins과 비교해서 정말로 우수한 방법이 맞는지에 대해 의문이 있긴 했어서 우현님은 이에 대해 어떻게 생각하는지 궁금합니다.
안녕하세요 정민님, 양질의 댓글 정말 감사드립니다.
사실 이런 비판적인 글쓰기와 글읽기 이런 부분에 대해 요즘 많은 부족함을 느끼고 논문을 읽을 때 마다 다 새롭고 좋게 느껴지는 이 상황에서 요즘 정민님의 피드백이 이런 비판적인 시각을 갖게 되는데 많은 도움이 되는 것 같습니다.
논문을 읽을 때마다 ‘새롭다, 좋다’라는 쪽에만 초점이 맞춰지다 보니, 상대적인 비교나 저자들의 주장에 대한 검증 가능성은 잘 못 보고 넘어가는 경우가 많았습니다. 그런데 말씀해주신 부분처럼 “Chamfer loss가 정말 문제라면 왜 동일 조건에서 비교 실험이 없는가?”, “Adabins과 동급 파라미터 기준에서의 직접 비교가 왜 빠져 있는가?” 같은 질문들이야말로 논문을 비판적으로 읽을 때 반드시 짚어야 하는 부분이라는 걸 다시 느끼게 되네요.. 결국 논문에서 실험표가 보여주는 건 프레임워크 자체의 우월성이라기보다는 백본을 키울수록 제안 구조의 잠재력이 발현된다는 메시지 같더라고요. 그렇다면 소형 모델 구간에서 불리한 성능을 어떻게 해석해야 하는지, 저자들이 의도적으로 피했는지, 아니면 정말로 한계가 있는 건지 더 고민해볼 필요가 있는 것 같습니다.
감사합니다!