안녕하세요, 허재연입니다. 오늘 다룰 논문은 AAAI 2024에 게재된 논문으로, video scene graph에서의 다양한 데이터 문제를 다루고 있습니다. 개인적으로 Action Genome 데이터셋의 annotation을 살펴보면서 positive-negative 불균형이 심해서 이걸 어떻게 처리하면 좋을까 고민하고 있었는데, 관련 내용을 언급한 논문이 있어 읽어보게 되었습니다. 리뷰 시작하겠습니다.
Scene Graph Generation(SGG)은 보다 수준 높은 장면 이해를 위한 task 중 하나로, 주어진 이미지 내의 물체들을 검출하고 이들 간의 관계를 식별하는 task입니다. 최종적으로는 각 object들을 node로, 이들 간의 관계를 edge로 나타내는 graph 형태로 주어진 영상을 적절히 모델링하고자 합니다. 이는 비디오 데이터로도 확장 가능한데, 주어진 비디오에서 등장하는 물체들을 식별하고 이들의 관계를 인식하게 됩니다. 이 때, 평가 단계에서는 각 frame에 대한 scene graph를 얼마나 정확하게 예측하는지를 측정합니다.
비디오 데이터 또한 이미지와 유사하게 SGG를 수행할 수 있지만, 비디오라는 데이터 특성 때문에 고려해야 할 점이 많아집니다. 비디오는 동적인 temporal 정보를 추가적으로 고려해야하고, 기존의 방법론들도 spatial 정보 뿐만 아니라 temporal 정보를 잘 modeling 할 수 있는 방향으로 진화했습니다. 현재 video SGG에서 가장 많이 사용되는 데이터셋/벤치마크는 Action Genome(AG) 데이터셋으로, charades라는 action recognition 데이터셋에 video SGG task에 맞춰 annotation을 추가한 데이터셋입니다. 저자들은 AG로 수행하는 video SGG의 몇 가지 문제점을 지적합니다.
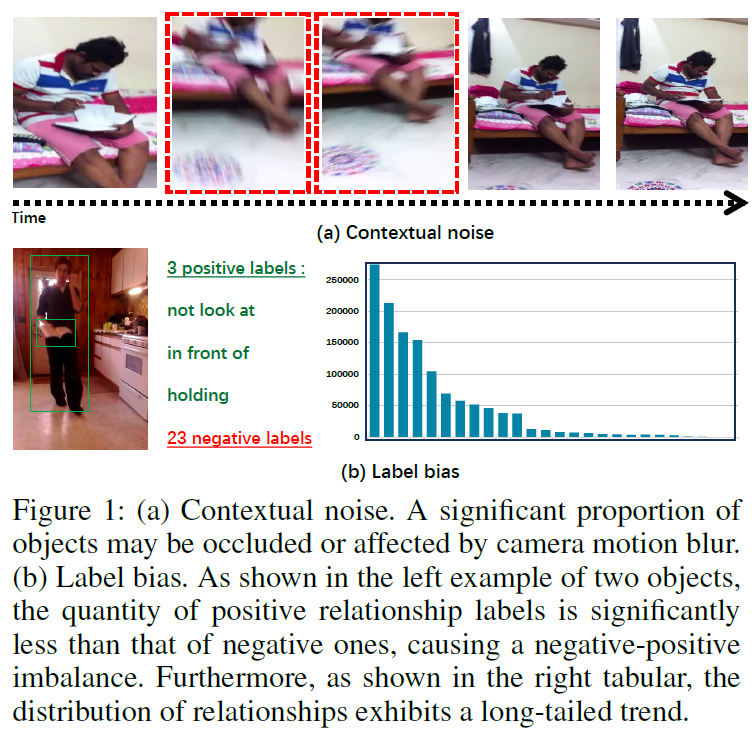
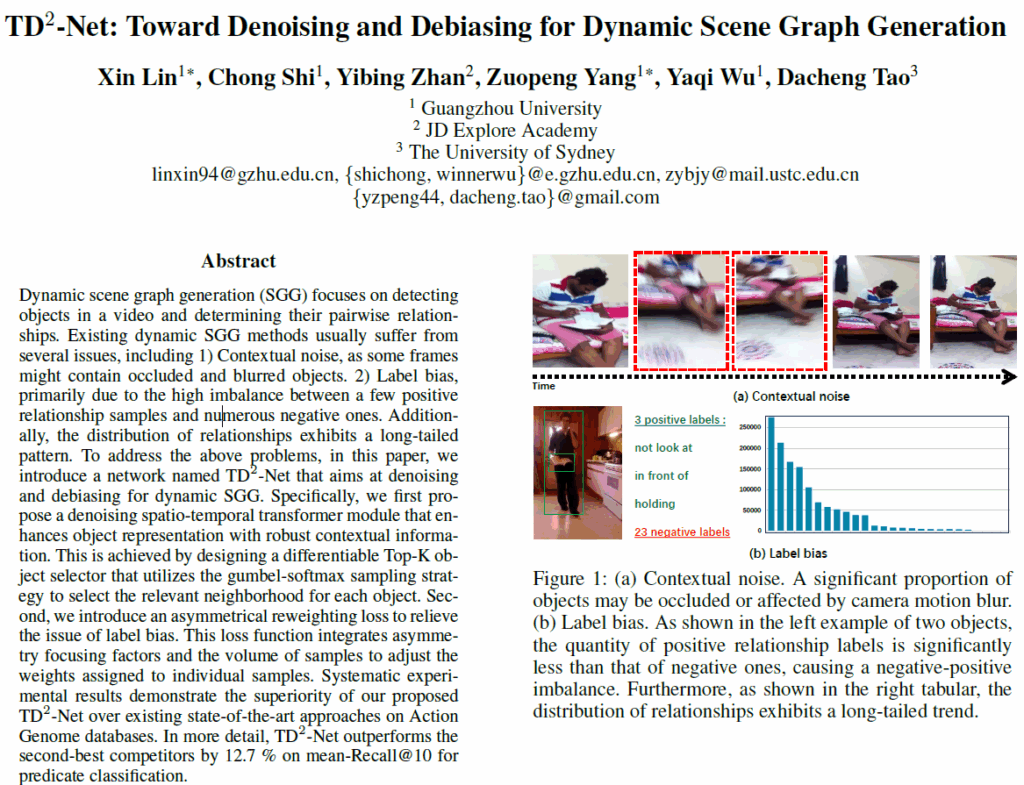
첫 번째 문제는 contextual noise입니다. 비디오 데이터는 연속된 프레임들로 구성되는데, 이들 중 일부 물체들은 occlusion이 일어나거나 motion blur가 발생하기 때문에 맥락/물체 정보를 추출할 때 노이즈나 잘못된 정보가 포함되어 모델 예측의 정확도를 떨어뜨릴 수 있습니다.
두 번째 문제는 label bias입니다. video SGG에서 표준 데이터셋으로 사용되는 AG의 술어(predicate) 클래스는 positive-negative imbalance와 head-tail imbalance가 심각합니다. 일단 annotation 되어 있는 object가 적기 때문에 이들 간의 relation또한 적어서(평균적으로 프레임당 object가 2~3개 정도) negative label의 수가 positive label보다 훨씬 많기에 학습 도중 positive label의 gradient가 제대로 반영이 되지 못할 수 있습니다. 또한 positive label이 long-tailed distribution을 띄기에 모델이 sparse한 positive sample들을 효과적으로 인식하지 못해 예측의 정확성과 다양성에 부정적인 영향을 미치게 됩니다.
저자들은 비디오 SGG에 발생하는 이러한 문제점들(noise 및 bias)을 완화하기 위해 TD2-Net이라는 방법론을 제안하게 됩니다.
우선, contextual noise를 줄이기 위해 D-Trans(denoising spatio-temporal transformer) 모듈을 제안합니다. 물체의 외형과 프레임 간 공간적 위치 일관성을 고려하여 초기에 object matching을 수행하고, 관련성이 낮은 객체로 인해 발생하는 노이즈를 줄이기 위해 gumbel-softmax sampling이라는 것을 도입했다고 합니다. 이를 통해 각 object가 가장 연관성이 높은 주변 객체와만 정렬하도록 해서 보다 정제된 맥락 정보를 활용할 수 있게 했다고 합니다. 이후 이렇게 선택된 맥락 정보를 집계하여 object representation을 강화하게 됩니다.
두번째로, 주어-목적어 간 관계 예측(relation prediction)에서의 label bias 문제를 완화하기 위해 AR-Loss(asymmetrical reweighting loss)를 제안합니다. 위에서 언급한 positive-negative imbalance 문제를 해결하기 위해 positive sample과 negative sample에 대해 서로 다른 focusing factor값을 사용해 각 샘플이 loss function에 기여하는 비중을 제어하게 됩니다. 이 때 positive sample의 focusing factor를 negative sample보다 더 높게 설정해서 모델이 positive sample에 더 집중하도록 유도합니다. 추가적으로 long-tailed distribution 문제를 완화하기 위해 클래스별 샘플 수에 따라 가중치를 조정하는 기법을 추가 적용했다고 합니다.
정리하면, 저자들이 주장하는 본 논문의 contribution은 다음과 같습니다.
- D-Trans : 노이즈를 제거한 맥락 정보를 활용하여 object feature의 품질을 향상시켰다.
- AR-Loss : Relation Prediction 과정에서 positive-negative imbalance와 head-tail imbalance를 동시에 완화시켰다.
이제 제안하는 방법론을 더 자세히 살펴보도록 하겠습니다.
Method
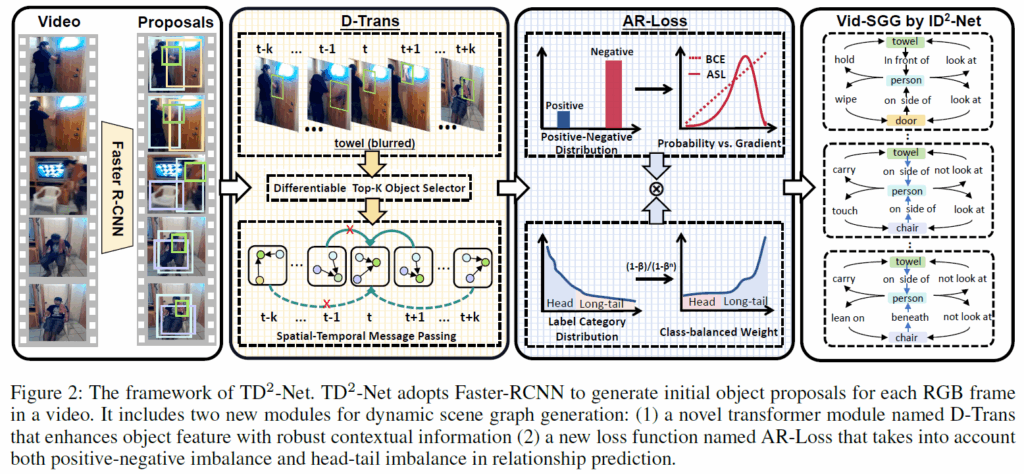
제안하는 프레임워크는 위 Figure 2와 같습니다.
가장 먼저, 각 video frame에 대해 Faster RCNN을 적용해 object proposal을 뽑아냅니다. 이 때 i번째 object에 대해서 appearance feature를 {x}_{i}, spatial feature를 {b}_{i}, classification score vector를 {p}_{i}, 그리고 proposal i와 j 간의 union box에서 추출한 특징은 {x}_{ij}로 표기하겠습니다.
이후에는 context noise 문제를 해결하기 위해 D-Trans(denoising spatio-temporal transformer) 모듈을 적용하고 label bias 문제를 해결하기 위해 AR-Loss(asymmetrical reweighting loss)를 적용합니다. 하나씩 살펴보겠습니다.
Denosing Spatio-Temporal Transformer
기존 방법론들의 경우 보통 연속 프레임에서 object를 추적하거나 매칭하여 맥락적 정보를 처리했는데, 저자는 이런 방법이 contextual noise의 영향을 받아 잘못된 물체와의 연관성을 포함시키거나 중복되는 경우가 많으며, 모델 예측 정확도를 떨어뜨리고 불필요한 리소스를 사용하게 만든다고 주장합니다. 이를 완화하기 위해 미분 가능한 top-k object selector와 시공간적 메시지 패싱(spatio-temporla message passing) 과정으로 구성된 D-Trans 모듈을 제안합니다.
Differentiable Top-K Object Selector
우선 기존 연구에서 제안된 방식을 참고해서 물체의 외형(appearance)와 공간적 위치를 기반으로 한 score function을 정의하고, 이를 통해 프레임 간 시간적 일관성(temporal consistency)를 확보합니다. 이 때 서로 다른 프레임에 존재하는 물체 i와 j의 matching score를 다음과 같이 정의합니다.
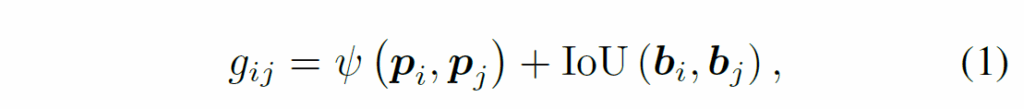
여기서 ψ는 코사인 유사도를 의미합니다. 연속된 프레임에서 탐지된 물체들은 (1)을 최대화 하는 방향으로 target object와 연결합니다. 이렇게 비디오 내 object들을 정렬하여 서로 다른 프레임에서 구성된 그래프 간 object representation의 일관성을 확보합니다. 이후 i번째 object와 정렬된 모든 object의 외형 특징을 모아 neighborhood feature matrix {Z}_{i}를 얻습니다.
저자들의 주장에 따르면 기존의 video sgg 방법론들들의 프레임 기반 object matching 전략과 비교해 (1)번 식을 사용하는 데 다음과 같은 이점이 있다고 합니다.
- 예측된 object label을 사용하는 대신 물체의 score vector를 사용하여 예측의 불확실성을 더 잘 반영할 수 있으며, IoU function을 활용해 temporal consistency를 강화할 수 있다.
- 헝가리안 매칭을 사용하는 방법보다 연산복잡도가 낮다.
하지만 비디오의 길이가 길어져 프레임 수가 늘어나면 target object와 연관된 object의 수도 함께 증가하기에, 관련성이 낮은 객체로 발생하는 신뢰도가 낮은 spatio-temporal 정보를 제거할 필요가 있습니다. 저자들은 이를 위해 target object에 대해 가장 관련성이 높은 주변 object의 맥락 정보만 선택하는 differentiable Top-K selector를 제안합니다. 이 selector는 다음과 같이 정의됩니다 :

여기서 σ는 행(row) 단위로 행렬을 flatten하는 함수입니다. K = V = {Z}_{i} + {E}_{i}이고, {d}_{k}는 K의 차원을 의미합니다. {E}_{i}는 transformer의 positional encoding으로, i번째 객체와 정렬된 각 객체으 시간적 위치 정보를 주게 됩니다.
여기서 디테일하게 top-k를 구현하는 많은 옵션이 있는데, 이 중 저자는 gumbel-softmax라는 기법을 사용했다고 합니다. Gumbel-Softmax 샘플링을 중복 허용하여 K번을 수행해서 top-k selection을 구현했다고 하네요.
Spatial-Temporal Message Passing
각 object마다 selected neighborhood가 주어지면, 이제 MHA(multi-head attention) 레이어를 활용해 비디오 내 인접 프레임에서 정렬된 다른 객체들로부터 정보를 집계하여 object representation을 정제하게 됩니다.
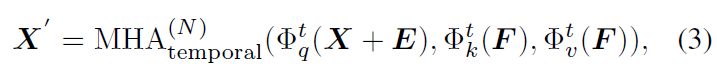
식 (3)에서 Φ는 각각 단순한 linear transformation입니다. 추가적으로, 객체 간 공간적 상호작용 정보를 처리하기 위해 또다시 M개의 MHA 레이어를 통과시킵니다.
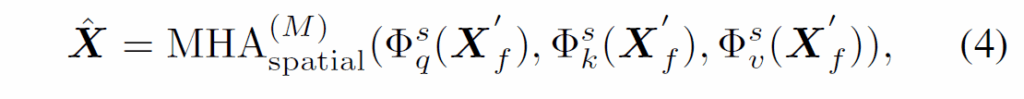
식 (4)에서 {X}^{'}_{f}는 동일 프레임 내 객체들의 representation을 의미합니다.
정리하면, object의 행동 변화를 모델링하여 dynamic action을 추론하기 위해 D-Trans 모델을 설계했으며, 특히 특정 프레임에서의 motion blur나 부분적인 occlusion이 발생하는 경우에는 object의 외형적 특징을 개선할 수 있도록 하였습니다. 말이 복잡하긴 하지면 결국 연관된 object를 집계한 다음에 MHA를 두번(공간, 시간 각각) 태웠다고 요약할 수 있겠네요.
Asymmetrical Reweighting Loss
D-Trans 모듈을 통해 object representation을 만든 다음에는 relation prediction 과정에서 label bias를 완화하기 위해 AR-Loss를 거치게 됩니다. 우선 기존의 STTran이라는 방법론처럼 두 object i와 j 간 관계에 대한 classification score vector를 다음과 같이 계산합니다.
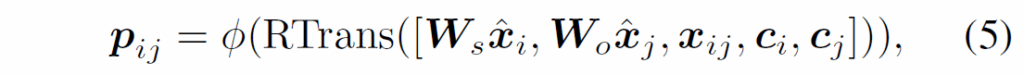
여기서 RTrans는 위에서 제안한 spatial-temporal message passing 모듈과 동일한 구조를 사용하여(MHA 두번) relation feature를 정제하는 과정이고, ϕ는 classification 연산입니다. {c}_{i}, {c}_{j}는 각각 물체 i,j의 semantic embedding이고, {W}_{s}, {W}_{o}는 fusion을 위한 projection 행렬이고, [ , , ]는 벡터 간 concat연산입니다.
기존의 Video SGG 연구에서는 학습에 binary cross-entroyp나 multi-label margin loss를 많이 사용했는데, 이러한 loss function들은 모든 샘플들의 중요도를 동일하게 간주하고 학습을 진행하므로, label bias에 영향을 받을 수 있습니다. 이를 완화하기 위해 저자들은 focal loss를 수정한 loss를 사용하게 됩니다. focal loss는 object detection쪽 공부를 하신 분이라면 잘 아실텐데, positive-negative imbalance를 해결하기 위한 loss로 예전부터 자주 사용되는 loss로 easy sample과 hard sample의 loss function 기여도를 조정하여 다수의 negative sample이 미치는 영향을 줄입니다. focal loss의 수식은 다음과 같습니다.
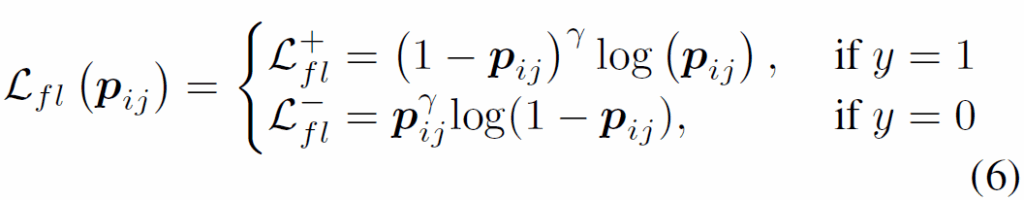
focal loss 수식 (6)에서 y는 GT label입니다. γ는 focusing parameter로, γ>0 일 때 easy negative sample이 손실함수에 미치는 영향을 줄이도록 설계되었습니다.
하지만 focal loss만으로는 다음 문제들에 충분히 대응할 수 없다고 합니다.
- Positive-Negative Imbalance : 대부분의 object pair들은 평균적으로 positive label보다 negative label을 훨씬 많이 포함한다. 식 (6)에서 γ값을 높게 설정하면 easy negative sample의 기여도를 충분히 줄일 수 있기는 하지만, 이로 인해 희소한(tail) positive sample의 graidient가 사라질 수 있다.
- Head-Tail Imbalance : 데이터셋이 long-tailed distirbution을 띄므로, positive sample 내에서도 빈도가 높은 head class와 빈도가 낮은 tail class 간 불균형이 존재한다. 이 때문에 모델이 sparse한 positive sample을 잘 인식하지 못할 수 있다.
이 때문에, 저자들은 positive sample과 negative sample의 focusing parameter를 분리하여 positive-negative imbalance를 완화하도록 하였습니다. 이 때 positive와 negative에 대해 각각 focusing paramter {γ}^{+}와 {γ}^{-}를 설정합니다. 또한, positive sample 내의 head-tail imbalance를 완화하기 위해 클래스별 샘플 수를 기반으로 각 sample의 가중치를 다음 식으로 조정합니다.
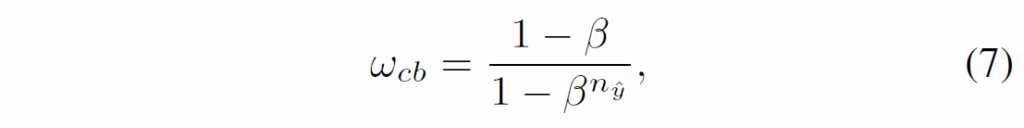
여기서 {n}_{\hat{y}}는 학습 데이터에서 GT class \hat{y}의 샘플 개수를 의미합니다. tail class에 대해 {w}_{cb}값이 커질수록 해당 샘플의 가중치가 증가하여 모델이 positive tail class에 더 집중할 수 있도록 유도하게 됩니다(반대로 head class에는 가중치가 작아집니다). β∈[0, 1)는 하이퍼파라미터로, {n}_{\hat{y}}가 증가할 때 가중치 증가율을 조정하게 됩니다.
이제 aymmetric focusing factor {γ}^{+}, {γ}^{-}와 적절하게 {w}_{cb}를 적용시켜서 최종적으로 다음과 같이 AR-Loss를 정의하게 됩니다 :
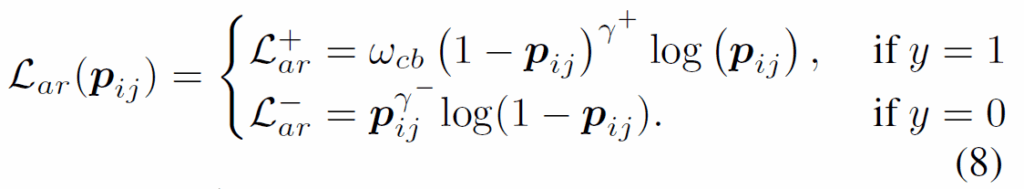
여기서 {γ}^{+} = {γ}^{-} = 0이고 {w}_{cb} = 1이면 binary cross-entropy loss와 동일해집니다. 여기서는 positive sample의 기여도를 강조하기 위해 {γ}^{-} ≥ {γ}^{+}로 설정하였다고 합니다. 결론적으로, (8) 식으로 positive-negative 샘플 간 기여도를 제어하고 희소한 positive sample로부터도 의미 있는 특징을 학습할 수 있게 하였습니다.
Training
구성 요소에 대해서는 다 살펴보았으니, 마지막으로 최종 loss를 살펴보고 실험 파트로 넘어가겠습니다.
학습 과정에서 최종 loss는 다음과 같이 정의됩니다.
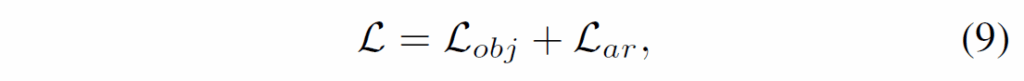
여기서 {L}_{obj}는 객체의 클래스 분류를 위한 CE입니다.
text 과정에서는 각 relation triplet <subjec-predicate-object> 점수는 다음과 같이 계산합니다
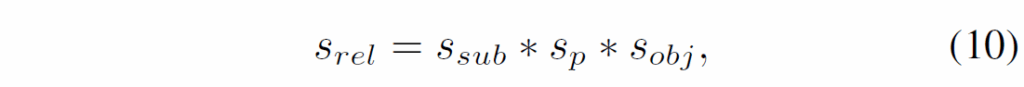
여기서 {s}_{sub}, {s}_{p}, {s}_{obj}는 각각 주어, 술어, 목적어의 예측 점수를 의미합니다. CVPR 2024의 DETR을 수정한 Video SGG 방법론 OED에서도 동일한 relation score를 사용하던데, 그냥 triplet 구성 요소의 각 예측 점수를 나이브하게 곱한 것을 자주 사용하는 것 같네요.
Experiment
성능 평가는 항상 그렇듯 Actione Genome(AG)에서 이뤄졌습니다. AG는 charades 데이터셋을 기반으로 video scene graph generation task에 맞게 추가적인 annotation을 한 것으로, 프레임 단위의 SGG 라벨링이 되어 있습니다. entity class는 36개, relation class는 26개이고, 특히 relation class는 attention, spatial, contacting 세 범주로 나뉩니다. 지표는 다른 SGG 논문들과 동일하게 predCLS, SGCLS, SGDET으로 각 recall@K와 mR@K를 리포팅 했습니다. with constraints는 각 s-o pair당 하나의 술어만을 예측하는 것이고, no constraint는 여러 관계를 예측하는 세팅입니다. 모델의 기본 detector로는 ResNet101기반 faster RCNN을 사용했다고 합니다.
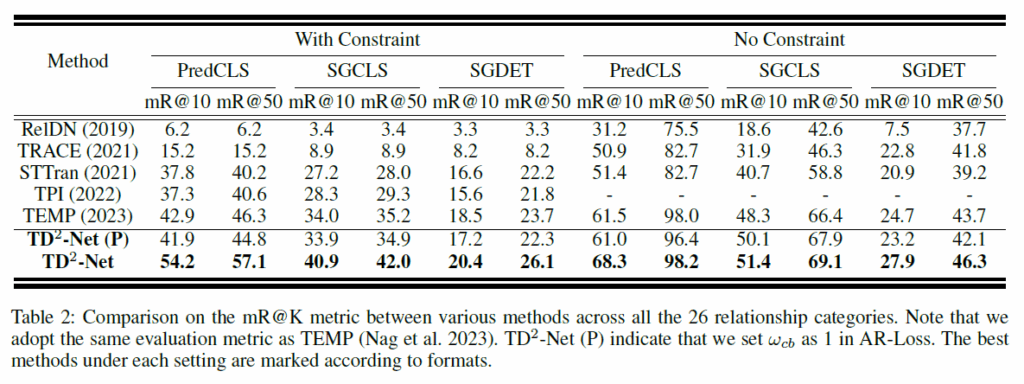
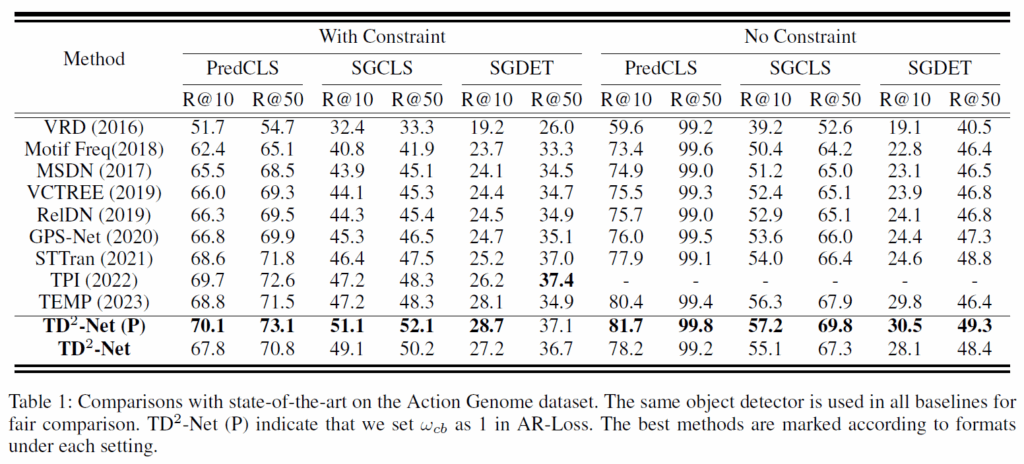
결과적으로, R@K와 mR@K 모두에서 당시 SOTA 모델이었던 TEMPURA와 비교하여 굉장히 좋은 결과를 보였습니다. 아직 해당 task가 충분히 saturated되지 않아서 그런지 성능 향상 폭이 상당히 크네요.
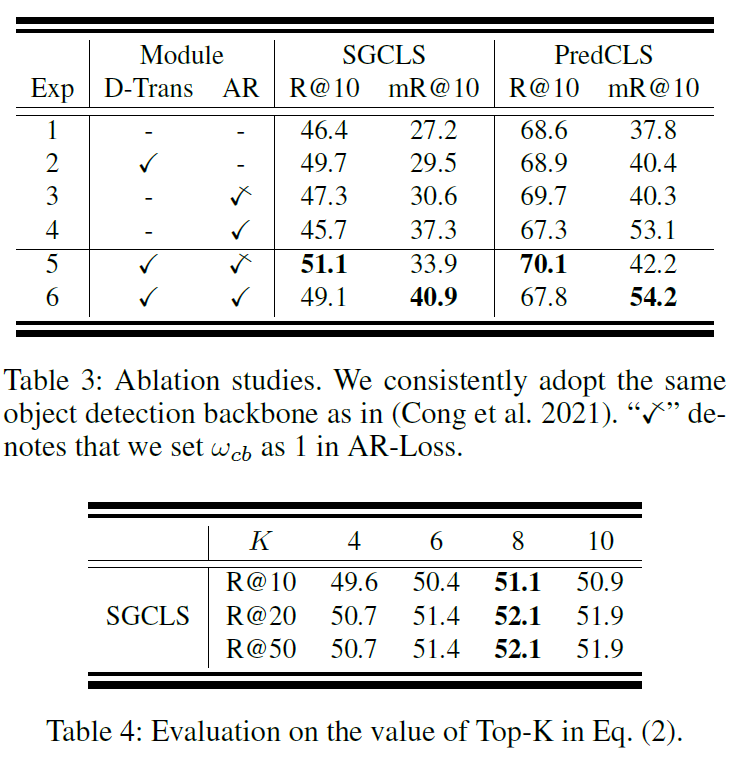
Table 3,4는 ablation study 결과로 각 모듈이 얼만큼 의미가 있는지를 보여줍니다. 제안하는 D-Trans와 AR-Loss 모두 성능 향상에 기여하고 이 둘을 조합했을 때 좋은 결과를 보였습니다. top-k 설정에 대해서는 k=8일때 가장 좋은 성능을 보여주고, K가 더 커지면 메모리 사용량이 커지는데 성능적 이득이 적어졌다고 합니다.
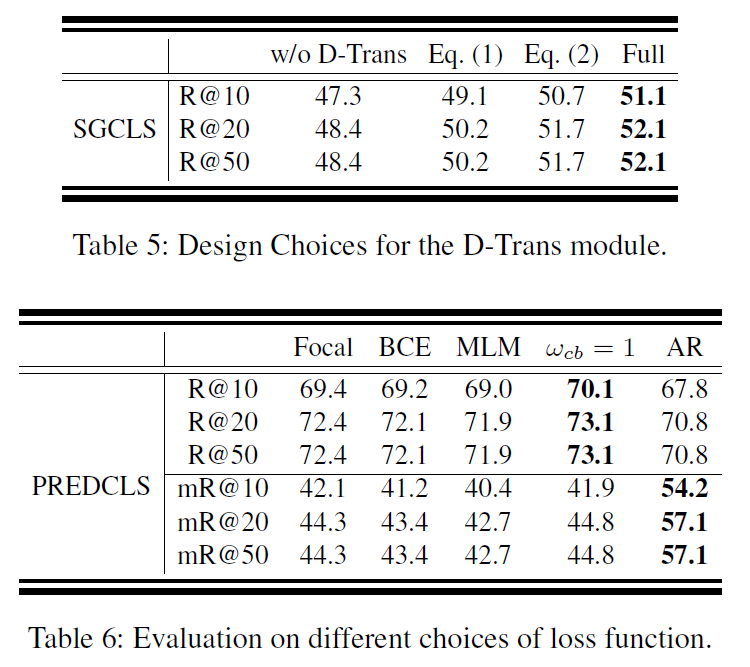
Table 5,6은 각 모듈의 구성에 대한 실험 결과를 나타내었습니다. D-Trans의 구성과 AR-Loss를 다른 loss와 비교하여 나타냈네요. 모든 평가 지표를 보여줬으면 더 좋았을텐데, 그러진 않아서 아쉬웠습니다.
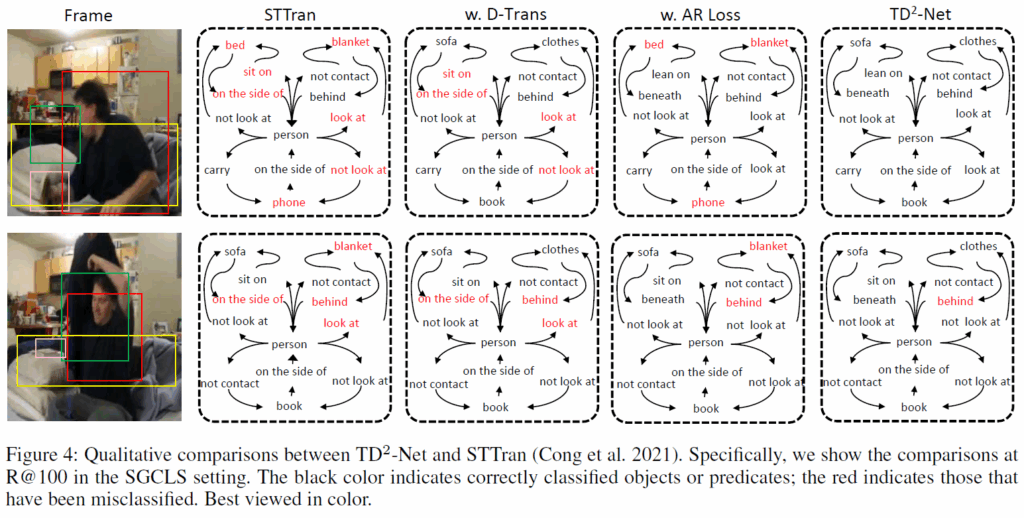
마지막으로 정성적 결과 보고 리뷰 마무리하겠습니다. Fig.4에는 STTran, D-Trans 적용 모델, AR-Loss 적용 모델, TE2-Net의 SGCLS 예측 결과를 비교한 것입니다. D-Trans의 경우 sofa, book, clothes와 같이 식별이 어려운 객체의 예측을 향상시키고, AR-Loss의 경우 relation 예측을 더 정교하게 할 수 있게 됬으며, 모두를 조합한 TD2-Net이 object와 relation 모두에서 종합적으로 우수한 결과를 냈다고 합니다.
제가 고민하던 positive-negative imblance 문제를 다룬 논문이라 흥미롭게 읽었습니다. relation 뿐만 아니라 object에 대한 분석도 있었으면 더 좋았겠다는 생각이 드네요. 코드가 공개되지 않은 것 같아서 구체적으로 어떻게 구현됐는지 까볼 수 없다는게 아쉽습니다.
리뷰 이만 마무리하도록 하겠습니다. 감사합니다.
리뷰 감사합니다. 궁금한 점 댓글 남겨두겠습니다.
D-Trans의 differentiable Top-K selector에서 Gumbel-Softmax를 사용했다고 하셨는데, 학습 과정에서 샘플링에 따른 불안정성이 발생할 가능성은 없는지 궁금합니다. 특히 동일한 객체에 대해 반복 실험 시 선택되는 구성이 얼마나 일관되는지도 궁금하네요
AR-Loss에서 클래스별 가중치 w_cb로 tail class를 보정한다고 했는데, tail class에서의 성능 향상 폭이 head class 대비 얼마나 되는지, 그리고 일부 tail class에서 과도한 가중로 인한 에러 증가 문제는 없었나요?
저자는 noisy한 object가 학습 및 예측에 사용하는것을 방지하기 위해 필터링 목적으로 top-K 선택 연산을 도입하였습니다. 이 때 미분 불가능한 top-k selection 연산을 미분 가능하도록 근사하기 위해 gumbel-softmax방식을 사용합니다. 검색해보니 딥러닝에서 이산적인 값을 역전파로 학습할 수 있게 하기 위해 종종 사용되는 기법이라고 합니다. ablation study에 최적의 K가 8이라는 실험 결과는 있지만, 샘플링에 따른 불안정성/반복 실험 시 선택 구성이 얼마나 일관되는지에 대한 별도의 언급은 논문에 없었습니다.
Table 1,2에서 확인하실 수 있듯, AR-loss를 적용했을 때 mR@K는 기존 방법론들보다 상당히 높지만, R@K 성능은 기존 방법론들보다 많이 떨어집니다. 학습 과정에서 tail class에 집중하고 head class를 suppression했기에 오히려 head class 예측 능력이 떨어져 R@K의 성능이 크게 떨어진 것으로 보입니다.