안녕하세요, 7번째? X-Review 작성자 손우진입니다^^. 이번에 리뷰할 논문은 ICCV 2025에 accept된 논문입니다. 최근 X-Review에서 제가 6D 관련 논문을 자주 다루고 있는데요, 6D 분야의 흐름은 model-based에서 model-free로 이동하는 추세이며, 이제는 model-free가 model-based의 성능을 바짝 따라잡고 있습니다. 불과 몇 년 사이에 발전 속도가 눈에 띄게 빨라졌고, 최근에는 model-free 내부에서도 online optimizer 방식이 주목받고 있습니다. 이 방식은 사전 학습 없이도 SLAM 기반 구조를 활용해, 대표적으로 BundleSDF와 같이 실시간에 가까운 6D pose 추적과 재구성을 가능하게 합니다.
Background
여기서 잠깐, BundleSDF를 간단히 설명드리면. BundleSDF는 사전에 학습된 CAD 모델 없이, RGB-D 카메라로 들어오는 영상만을 사용해 객체의 3D 형상과 6D 포즈를 동시에 추적하는 방법입니다. 핵심은 객체를 Neural Signed Distance Field(SDF)라는 형태로 실시간 학습한다는 점인데, 이는 3D 공간의 각 점이 표면까지 얼마나 떨어져 있는지를 부호로 표현하고, 이를 MLP로 근사하여 촬영과 동시에 업데이트하는 기술입니다.
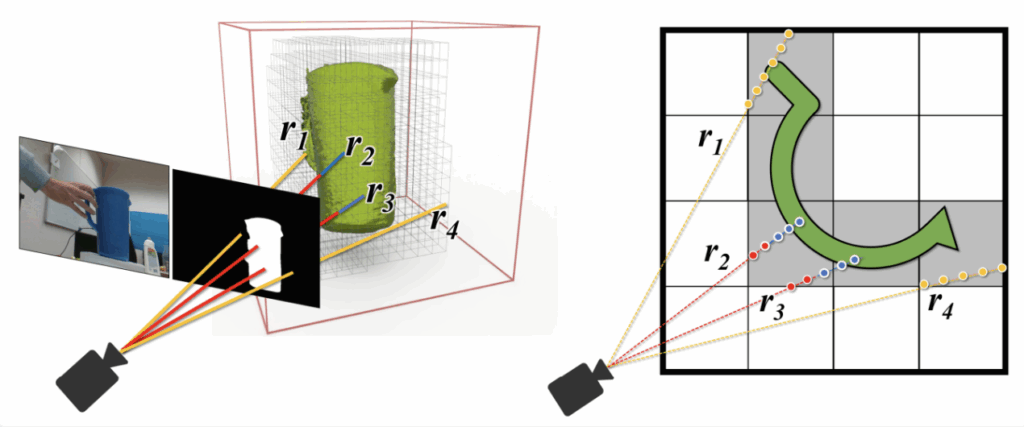
위 그림은 Neural SDF의 작동 원리를 보여주는데요. 왼쪽에서 보이듯, 카메라는 장면을 촬영하고 segmentation mask를 통해 객체 영역을 분리합니다.
카메라의 각 픽셀은 하나의 광선(ray)으로 표현되며, 이 ray는 3D SDF 볼륨을 통과하면서 각 지점의 MLP 결과값으로 SDF 값을 샘플링합니다. SDF 값이 0이 되는 지점이 객체의 표면입니다. 표면 밖에서는 양수 표면 안쪽에서는 음수가 됩니다. 오른쪽 2D 단면도를 보면, 일부 ray(r2, r3)는 객체 표면과 교차해 SDF=0 지점을 만들고, 이 지점에서의 깊이·법선 정보를 실제 관측과 비교하여 손실을 계산합니다. 이 손실을 backpropagation을 통해 Neural SDF 파라미터와 포즈R, t를 동시에 업데이트하는 것이 BundleSDF의 핵심입니다.
이러한 Neural SDF 기반 online optimizer 구조가 CAD 모델 없이도 새로운 객체(novel object)의 형상과 포즈를 실시간에 가깝게 갱신할 수 있어서 주목받는 것 같습니다.
잠시 저번 Spatial AI강의를 해주셨던 김수한교수님의 강의를 remind를 해보면, 교수님께서도 말씀하셨듯이 NeRF의 등장이 3D visual 분야나 컴퓨터 비전 분야 전반에 큰 파장을 일으키고 짧은 시간안에 변형모델들이 등장하고 다양한 분야에 적용되며 image to 3D를 만드는 가능성을 넓혔습니다.
하지만 NeRF 계열들은 여전히 연산량이 매우 크고 실시간처리가 느린 한계들이 존재합니다. 물론 이후 후속연구들로 그러한 한계를 보완했지만 Gaussian Splatting의 등장으로 이 문제를 이산적이 Gaussian 입자 들을 집합으로 표현하고 래스터라이제이션 기반으로 빠르게 렌더링하는 방법으로 완화하였습니다.
이 논문은 이러한 배경을 알고 읽는 것이 도움될거 같아 정리하였습니다. 더 자세한 내용은 다른 연구원들 분께서 자세하게 작성해주신 리뷰도 있으니 참고부탁드립니당
Gaussian Splatting에 대해서는 김태주 연구원님께서
http://server.rcv.sejong.ac.kr:8080/2024/06/16/siggraph-2023-3d-gaussian-splatting-for-real-time-radiance-field-rendering/
BundleSDF에 대해서는 이승현 연구원님께서
http://server.rcv.sejong.ac.kr:8080/2023/10/29/cvpr-2023bundlesdf-neural-6-dof-tracking-and-3d-reconstruction-of-unknown-objects/
자세하게 리뷰해주셔서 도움을 받았습니다.
Introduction
위와 같은 배경을 가지고 논문 리뷰를 본격적으로 시작하도록 하겠습니다.
Model-free 방식은 CAD 없이 RGB-D와 객체 마스크만으로 새로운 객체의 포즈를 추정합니다. BundleSDF는 Neural SDF를 활용해서 reconstruction 과 pose를 refinement를 동시에 수행하지만 Neural SDF는 연산량이 커서 평균 0.4Hz 수준에 머무르며 동적인 장면에서의 실시간 적용이 어렵다고 합니다(0.4Hz라고 한다면 0.4FPS라 보시면 됩니다).
이번에 리뷰할 6DOPE-GS는 이러한 한계를 해결하기 위해 최초로 2D Gaussian Splatting를 Object-level로 적용하여 BundleSDF 수준의 재구성 품질을 유지하면서도 5배 이상의 속도를 향상을 달성하였습니다.
하지만 Gaussian Splatting이 6D pose를 위해 설계된것이 아니기 때문에 그대로 2D gaussian splatting을 적용할 경우 안정적인 추적과 최적화가 보장되지 않는다고 합니다. 실시간으로 최적화를 하다보니 잘못된 pose를 추정하게되면 keyframe이 최적화 단계에서 잘못된 pose에 최적화가 되겠죠. 또한 매 프레임마다 새로 들어오는 관측 데이터가 기존 gaussian 집합에 계속 덧 붙여지게되는데 이 과정에서 불필요하거나 중복된 Gaussian이 추가되면 메모리나 연산량이 증가하여 속도측면에서 영향을 준다고합니다. 이를 해결하기 위해 저자는 세 가지 모듈을 도입하였습니다.
저자의 최종 contribution은 아래와 같습니다
- 우리는 효율적이고 정확한 모델 프리(model-free) 6D 객체 포즈 추정 및 재구성을 위해 2D Gaussian Splatting을 효과적으로 활용하는 새로운 방법을 제안합니다.
- Gaussian Splatting의 연산 효율이 높은 미분 가능 렌더링(differentiable rendering)을 활용하여, 2D Gaussian Splatting 기반의 Gaussian Object Field와 관측된 키프레임들의 객체 중심(object-centric) 포즈 그래프를 공동 최적화합니다. 이를 통해 정확하고 정제된 키프레임 포즈 업데이트를 제공합니다.
- 키프레임 집합의 공간적 커버리지(spatial coverage)와 재구성 신뢰도 기반 필터링 메커니즘에 기초한 동적 키프레임 선택(dynamically keyframe selection) 방법을 제안합니다. 이를 통해 포즈 추정이 잘못된 키프레임을 제외할 수 있습니다.
- 우리는 opacity 백분위수(percentile)에 기반한 적응형 Gaussian 밀도 제어 메커니즘을 도입하여, “중요하지 않은” Gaussian을 걸러냅니다. 이를 통해 학습 안정성과 연산 효율성을 향상시킵니다.
Method
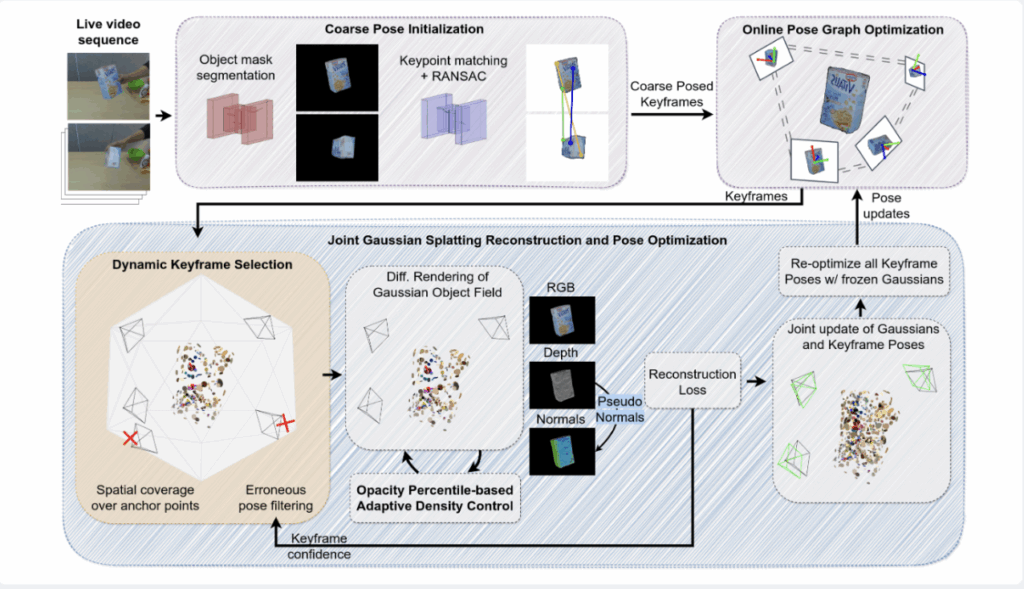
전체적인 pipeline은 위 의 사진과 같습니다.
3.1. Coarse Pose Initialization
초기 Pose 추정은 객체 마스크 생성부터 시작됩니다. 각 RGB-D 프레임은 먼저 SAM2를 통해 객체 마스크를 얻습니다.(여기서 SAM2 prompt로 사람이 직접 프롬프트를 이미지를 줘서 마스크를 출력 한거 같습니다.) 이 마스크는 배경 픽셀을 제거하고, 관심 객체의 픽셀만 남겨 추후 특징점 매칭과 최적화를 객체 중심으로 제한합니다. 이후에는 현재 프레임과 과거 참조 플레임 과의 RGB-D 영상에서 객체 마스크 내부의 feature matching이 이루어집니다. 저자는 Transformer 기반의 Feature Matching 모델 LoFTR로 추출 하고 매칭을 한다고 합니다 매칭된 2D-3D 포인트 쌍을 이용해서 PnP + RANSAC으로 현재 프레임의 초기의 R,t를 계산하게 됩니다 .
3.2. Gaussian Object Field
여기서부터는 2D Gaussian splatting 설명입니다. 저자들은 추적 중인 객체의 시각적, 기하학적 정보를 담는 내부 3D 모델을 ‘가우시안 객체 필드’라고 얘기합니다. 이 모델을 구축하기위해 저자는 2D Gaussian splatting을 사용하였습니다. 2D Gaussian splatting을 설명에 앞서 3D gaussian splatting을 대략 안다고 생각하고 글을 적도록해보겠습니다..
6D pose를 object-level에서 추정하려면 그 object에 대한 카메라로부터 객체 표면의 각 지점까지의 Depth정보를 정확하게 알아야 합니다. 하지만 3DGS의 경우, 그림 왼쪽처럼 3차원을 가진 형태로 표현됩니다. 이로 인해 보는 viewpoint에 따라 깊이를 측정하는 기준이 되는 단면이 계속 달라지는 문제가 발생합니다. 이처럼 기준면이 일관되지 않으면 깊이 값에 오차가 발생하여 최종적인 6D 자세 추정이 부정확해질 수 있습니다.
반면 2DGS는 그림 오른쪽처럼 3차원 공간상의 단일 평면(plane)으로 정의됩니다. 따라서 어떤 시점에서 보더라도 항상 동일한 평면을 기준으로 거리를 측정하게 됩니다. 이렇게 multi-view의 일관성을 확보하여 오차 없이 깊이를 측정할 수 있다는 점이 바로 2DGS의 핵심적인 장점입니다.
(2DGS 논문의 fig입니다)
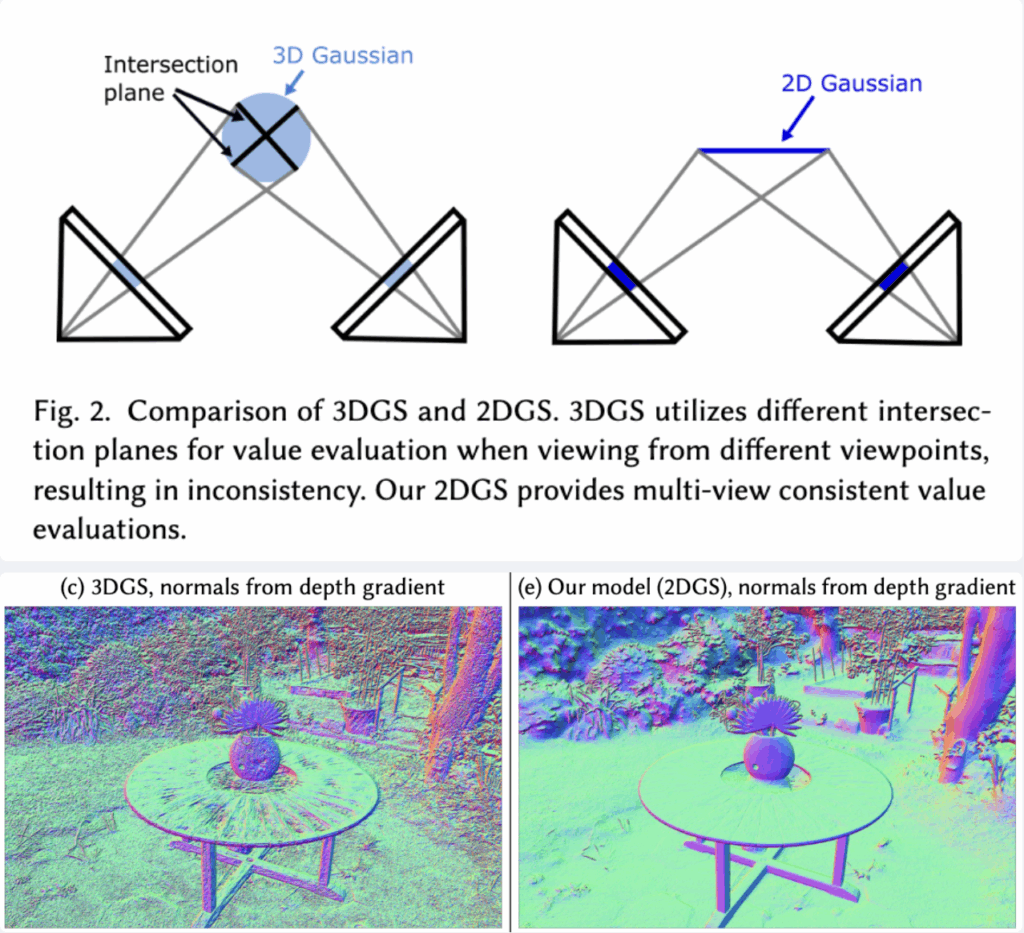
2DGS의 사용을 하는 이유는 이제 납득이 되었을거같습니다. 그럼 간략하게 3DGS와 2DGS가 어떤차이로 동작을 하는지 수식적으로 설명을 드리면,
우선 3D 공간상의 한 점을 표현하는 가우시안 입자 하나는 다음과 같은 속성들로 정의됩니다.
- 위치 (Mean): \mu \in \mathbb{R}^{3}
- 모양과 방향 (Covariance): \Sigma \in \mathbb{R}^{3\times3}
- 색상 (Color): c
- 투명도 : \chi
여기서 모양과 방향을 나타내는 공분산 행렬 \Sigma는 회전 행렬 R과 크기 행렬 S로 분해될 수 있습니다.\Sigma = RSS^{\top}R^{\top}
3DGS와 2DGS의 차이는 이 크기 행렬 S에 있습니다. - 3DGS: 일반적인 3D 가우시안은 x, y, z축으로 각각의 크기를 가지는 3차원 타원체입니다.
S = diag([s_x, s_y, s_z]) - 2DGS: 반면 2DGS에서는 이 크기 행렬의 z축 값을 강제로 0으로 설정합니다.
S = diag([s_u, s_v, 0])
이 크기 행렬 때문에 시점 불일치가 3DGS에서 일어나고 2DGS가 장점을 갖습니다.
z=0이라는 것을 이용하여 3차원-> 2차원으로 압축시키는 것 입니다. 그러고 그 평면에 수직인 방향 법선 벡터를 오차 없이 유일하게 결정할 수 있는 이유입니다.
2DGS의 회전행렬은 R = [t_u, t_v, t_w] 로 정의할 수 있다고 설명합니다.
논문에서도 이 두 주축(t_u,t_v) 벡터와, 이 둘의 외적으로 얻어지는 법선 벡터 t_w를 이용해 회전 행렬 R을 정의합니다.
이렇게 정의된 수많은 가우시안 입자들은 ‘알파 블렌딩’이라는 기법을 통해 최종 이미지로 렌더링됩니다. 특정 픽셀의 색상(\hat{c}(p))은 다음 수식 (1)과 같이, 카메라부터 가까운 순서대로 정렬된 N개의 가우시안 입자들의 색상과 투명도를 순차적으로 합성하여 결정됩니다.
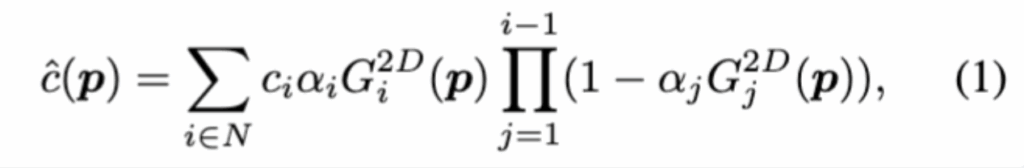
- \hat{c}(p) : 최종 픽셀 색상 이미지의 특정 픽셀 p에 최종적으로 렌더링될 색상(RGB 값)입니다.
- \sum_{i=1}^{N} : 합산 기호 (Summation Symbol) 픽셀 p에 영향을 미치는, 카메라에 가까운 순서대로 정렬된 1번부터 N번까지의 모든 가우시안 입자의 색상 기여도를 더하는 것을 의미합니다.
- c_i : i번째 가우시안의 색상 (Color of the i-th Gaussian) 현재 계산하고 있는 i번째 가우시안 입자(타일)가 가진 고유의 색상 값입니다.
- \alpha_i : i번째 가우시안의 불투명도 (Opacity of the i-th Gaussian) i번째 가우시안 입자의 불투명도(alpha) 값입니다. 1에 가까울수록 불투명하고 0에 가까울수록 투명합니다. 이 값이 높을수록 최종 색상에 더 큰 영향을 미칩니다.
자세한 2DGS는 나중에 기회가된다면 리뷰로 남겨보도록 하겠습니다. 깊지는 않지만 논문의 설명과 2DGS논문을 참조하여 설명하였는데 어렵네요
3.3 Dynamic Keyframe Selection for Gaussian Splatting Optimization
이제는 동시 최적화 과정을 어떻게 사용하는지 그리고 실시간으로 가능하게 만들었는지 설명을 드리겠습니다. 앞서 말씀드렸다 싶이 Gaussian splatting이 6D를 타켓팅해서 설계된 것이 아니기 때문에 저자들은 이를 실시간 6D 객체 자세 추정 문제에 맞게 최적화하기 위해 keyframe selection 방식을 제안했습니다.
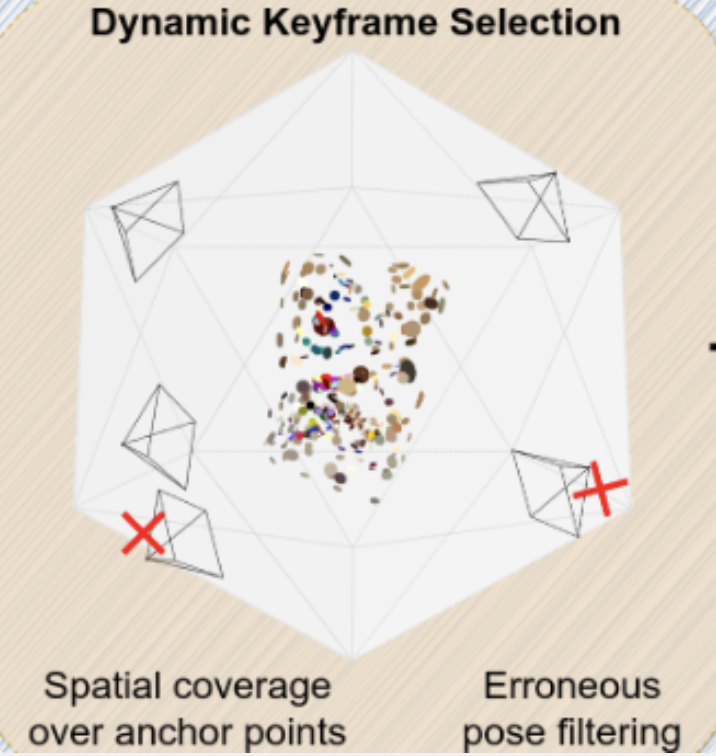
첫번째 문제로는 전체 이미지를 한 번에 하나씩 렌더링하므로 키프레임 수가 증가함에 따라 계산 비용이 선형적으로 증가합니다. 이러한 문제를 완화하기 위해, 오류가 있는 키프레임을 필터링하는 동적 키프레임 선택 접근 방식을 도입하였습니다.
먼저, 객체를 둘러싼 여러 가상 시점을 설정합니다. 여기서 가상시점이라고 하면 위 그림을 참조해주시면 감사하겠습니다. 정이십면체를 기준으로 면이나 모서리에서의 뷰를 우선적으로 선택합니다. 그 이후 키프레임들 중에서 객체 마스크의 크기가 가장 큰 프레임을 선택합니다다음으로, 최적화 과정에서 재구성 오차(reconstruction error)가 유난히 큰 키프레임을 식별합니다. reconstruction error가 큰 데이터는 전체 최적화를 방해하므로 중간값 절대 편차(MAD)를 이용하여 멀리 떨어져있는 값을 이상치로 간주하고 과정에서 제외해서 안전성을 확보했다고 합니다
Opacity Percentile-based adaptive Density Control
마지막으로, 저자들은 Gaussian splatting 기반 최적화에서 발생하는 또 다른 문제를 지적합니다. 실시간으로 새로운 프레임이 들어오면, 매번 새로운 Gaussian들이 추가되면서 기존 필드의 크기가 계속 커지는 문제가 생깁니다.이렇게 불필요하게 많은 Gaussian이 쌓이면 메모리 사용량과 연산량이 급격히 증가하여 실시간 성능이 저하된다고 합니다. 이를 해결하기 위해서 저자는 Opacity Percentile 기반의 적응형 Gaussian 밀도 제어 를 제안합니다. 기존에 사용하던 밀도 제어 방식은 미리 정해놓은 임계값보다 낮은 모든 입자를 한 번에 제거하는 방식이었다고 합니다 (3DGS에서).하지만 이 방식이 최적화 과정에서 입자의 수가 갑자기 급격하게 변하는 원인이 되어 품질이 크게 떨어지고 발산할 수 있는 가능성을 준다고합니다.
((1)에 사용된 알파(\alpha_i) 값이 바로 앞서 설명드린 ‘불투명도’입니다)
저자들은 문제 해결을 위해 미리 정해놓는 것이 아니라 상대적인 비율을 이용하여 더 정교한 방법을 제안합니다. 처음으로 모든 가우시안 입자들의 불투명도 값을 정렬하고 이 중 하위 5%에 해당하는 불투명도 값을 기준으로 삼아, 그보다 낮은 값을 가진 모든 입자들을 pruning합니다.
이를 반복하여 모델 내에 충분한 수의 고품질 입자가 남을 때까지 반복됩니다.
3.5 Online Pose Graph Optimization
정교하게 보정된 키프레임들의 자세 정보가 넘어오면, 시스템은 이 정보들을 바탕으로 객체 중심의 전역 좌표계(global object-centric coordinate system)를 설정합니다
동시에, 이 고품질의 키프레임들은 언제든 꺼내 쓸 수 있도록 keyfram 메모리 풀에 저장됩니다. 다음으로는 새로운 프레임이 들어올 때마다 메모리 풀에 있는 모든 키프레임과 비교하는 것은 매우 비효율적이라. 새로 들어온 프레임과 가장 관련이 높은 keyframe만 골라냅니다. 관련이 높다는것은 view point로 비교하게 됩니다.
신뢰도 높은 키프레임들의 정보로부터 구축된 3D 객체 모델(Gaussian Object Field)에서 3D 공간상의 한 점을 가져옵니다. 여기서는 가우시안 입자들의 3D 중심점(\mu)들을 가져옵니다. 이 3D 포인트를, 현재 새로운 프레임의 R과 t를 사용하여 2D 이미지 평면으로 투영합니다. 예측된 2D 픽셀 위치와, 실제 새로운 프레임의 이미지에 있는 2D 픽셀 위치 사이의 거리를 계산합니다. 3D 모델의 점들을 새로운 프레임에 투영했을 때, 실제 이미지와 가장 오차가 적게 들어맞는 최적의 카메라 자세(R, t)를 반복 계산을 통해 찾아내게 됩니다.
Experiments
해당 논문의 실험 datasets은 YCB-Video, HO3D로 실험을 진행했습니다. 또한 6D 성능의 평가지표로는 ADD와 ADD(-s)로 평가를하고 Reconstruction 은 Chamfer distance를 측정하였습니다. Chamfer distance는 GT mesh와 reconsrtuction mesh와 차이를 나타냅니다.
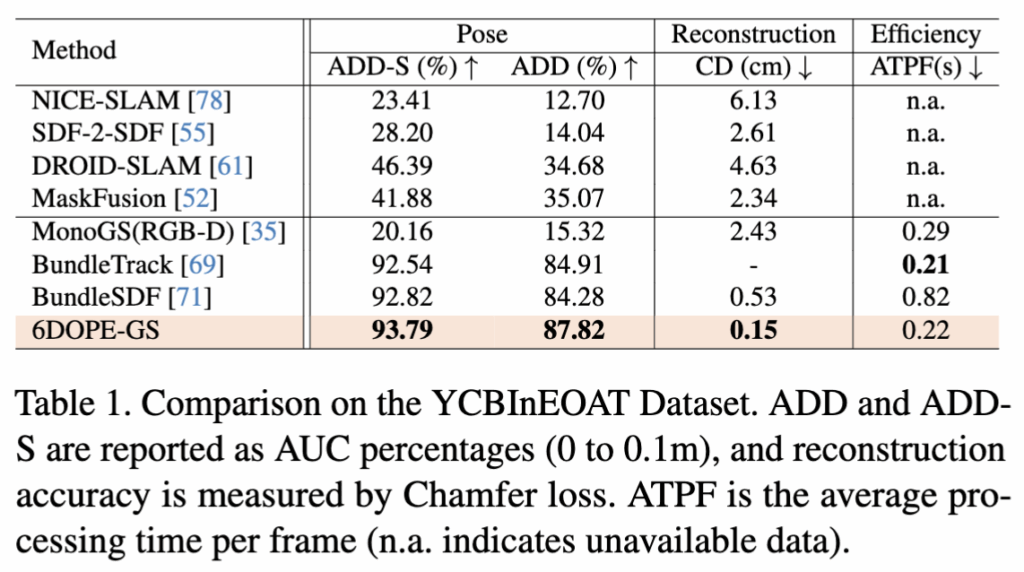
YCBInEOAT 데이터셋에서의 Table입니다 데이터 특성상 움직임이 부드럽고 시점 변화가 적은 편이라 정확도가 높게 나온것같습니다. 6D 와 Reconstruction을 모두 수행하는BundleSDF보다 좋은 6D성능을 보여줍니다. 눈에띄는 것은 ATPF(Average Time Per Frame)입니다. 0.82에서 0.22로 약 3배정도의 성능 향상을 보였습니다.
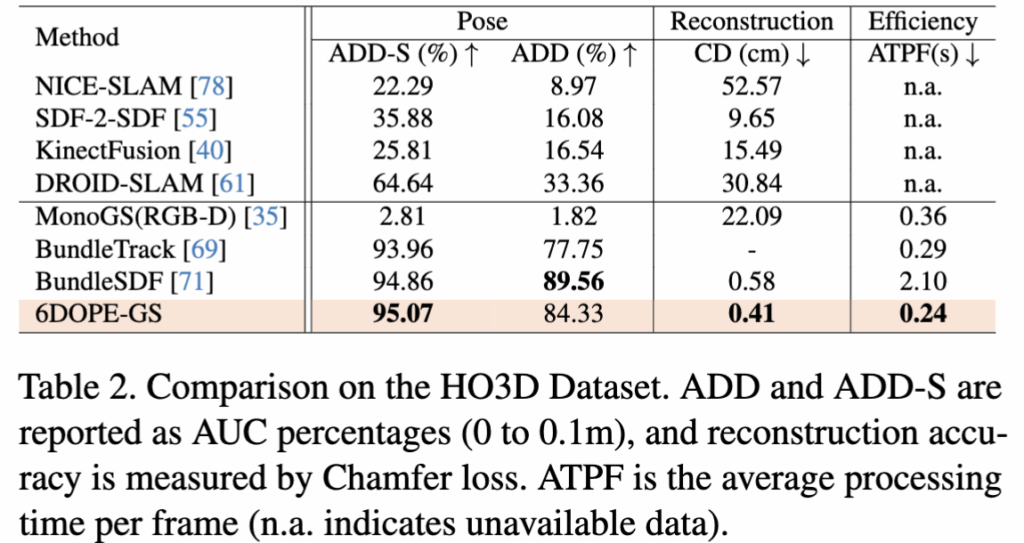
다음으로는 HO3D 데이터셋 입니다. 이 데이터셋은 사람 손으로 물체를 잡고있고 움직이빨라 평가가 어려운데요. 그럼에도 불구하고 BundleSDF 보다 높은성능을 보입니다. ADD를 제외하고는 Reconstruction과 ATPF 모두 SOTA를 달성하였습니다. ADD에 대해서는 occlusion이 심하기에 성능이 낮게 나왔다고 저자가 언급하였습니다. 하지만 속도측면이나 reconstruction을 강력 어필합니다.
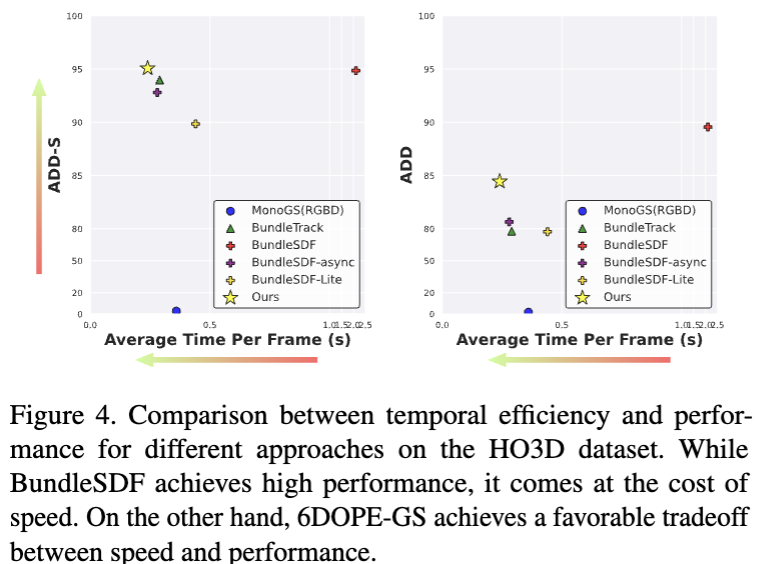
위에 보이시는 것 처럼 속도와 성능을 비교하면서 강력하게 어필을 합니다. 표를 보더라도 성능과 실시간성에서 높은 성능임을 보여줍니다. 또한 정성적인 결과로도 저자는 어필을 합니다.

HO3D 데이터셋의 실제 비디오 시퀀스에 6DOPE-GS를 적용했을 때의 정성적 결과입니다.
손에 들려 빠르게 움직이거나 회전하는 객체 주위에 표시된 노란색 경계 상자가 안정적이고 정밀하게 객체를 따라가는 모습을 통해 논문이 주장하는 높은 추적 정확도를 정량적으로 보였습니다. 3D 재구성 능력도 시간이 지남에 따라 초기에는 일부가 비어있거나 거칠었던 3D 모델이 더 많은 뷰를 관찰한 후에는 객체의 색상과 질감을 잘 표현하네요.
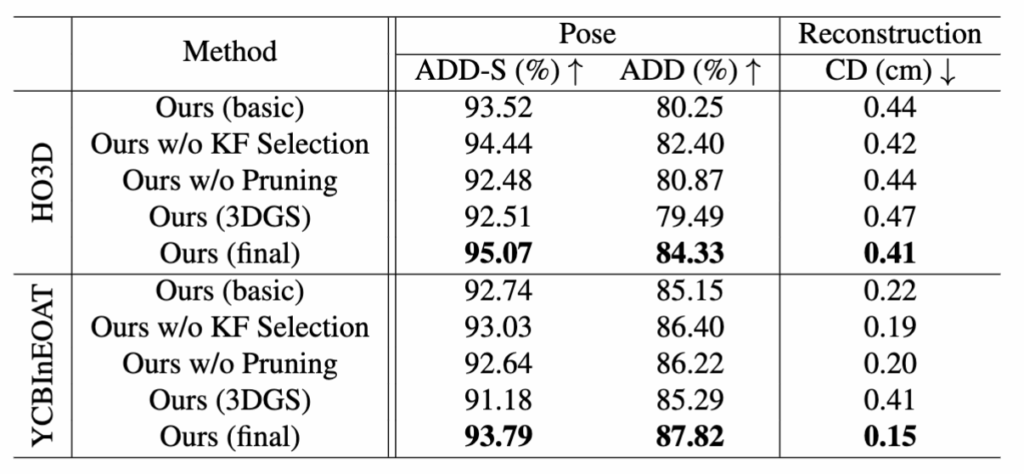
마지막으로 Ablation 입니다. 저자가 제안한 모듈을 하나씩 제거하면서 측정 결과입니다. 3DGS보다 object level의 Reconstruction이 좋은 것을 볼 수있습니다 또한 Pruninrg 과 KF Selection을 보시게되면 각각의 모듈의 성능 기여를 보실수있습니다. KF Selection이 역시나 시간적인 측면이나 성능의 기여가 더 큰걸로 보이네요.
limitation
저자는 한계점을 제시합니다.
현재 사용 중인 Gaussian rasterization 방식은 렌더링 속도는 매우 빠르지만 추정한 자세의 오차가 매우 클 경우 그 오차를 바로잡기 위한 정확한 그래디언트를 계산하는 데는 비효율적일 수 있다고 지적합니다. NeRF에서 사용하는 미분가능한 ray casting방식이 더 효과적일 수 도 있다고 합니다. 그래서 저자들도 2DGS에서도 ray casting기법을 도입하는 방향을 연구한다고합니다.
-> Gaussian splatting에 어떻게 ray casting을 도입할지 궁금하네요
앞으로도 6D가 image to 3d를 활용해서 연구가 될거같은데 GS이 해결책이 될지 두고봐야할거같습니다.
캄사합니다~
안녕하세요 우진님 리뷰 감사합니다.
Model Free pose estimation을 진행할 때 Bundle SDF 대신 2DGS 기반의 Gaussian Object Field를 만들어서 이 안에서 pose를 optimization 한다고 이해했는데요, 3D를 2D로 투영했을 때의 오차를 줄여나가는 방식으로 진행하고, 이때 2DGS가 유리하게 작용하는 것이라고 이해해도 될까요? Pose 최적화에서 어떤 절차를 통해 R,t를 구해나가는지 조금만 더 설명 부탁드립니다!!
추가로 Gaussian Splatting에 대한 Ray Tracing은 3DGRT와 같은 연구들 통해서 가능하다고 알고있는데 Ray casting은 조금 다른 개념인가요?
안녕하세요 우진님 리뷰 감사합니다.
먼가 간단한 질문이 있는데 2DGS가 3차원 공간상의 단일 평면으로 어떤 시점에서 보더라도 항상 동일한 평면이 되는건 이해했습니다. 그런 과정에서 생기는 정보의 손실은 없는지 궁금합니다. 뭔가 3차원에서 표현되던 구체적인 정보들도 사라져버리는건 아닌지 궁금합니다. 감사합니다.
안녕하세요, 좋은 리뷰 감사합니다.
초기 pose를 예측할 때 LoFTR로 feature matching을 한다고 설명해주셨습니다. 이게 제가 이해하기로는 두 프레임의 RGB-D 영상에서 이루어진다고 생각하는데, 말씀하시는 2D-3D 포인트 쌍에서 3D는 무엇을 의미하는건가요 ?
해당 모델은 model-free 기법으로 캐드 모델도 사용하지 않는 것으로 이해했는데 매칭할 수 있는 3D 구조라는게 무엇인지 궁금합니다.
감사합니다.