1. Introduction
Scene Text Recognition(STR) task는 이미지의 feature 정보를 가지고 text 형태의 문자 시퀀스를 예측하는 즉, 두 모달리티에서의 데이터 전환을 다루는 태스크입니다. 꽤나 높은 정확도로 인식 정확도를 보이나 여전히 irregular 한 text들 (굽어있거나 문자가 기울져 있거나, 폰트가 각기 다른 이슈, 복잡한 배경)에 대한 인식 정확도는 저조하단 문제점이 있습니다. 간단히 이전 text recognition이 어떻게 설계되었는지를 설명해드리겠습니다.
초기에는 문자 하나를 찾고 찾은 문자가 어떤 문자인지를 인식하도록 설계되었습니다. 하지만 예전에는 문자를 찾는 detection 단계에서의 정확도도 낮았던 터라 뒤이은 recognition 성능에서도 한계가 있었습니다. 이후 문자 하나하나를 모두 찾는 방법론에서 벗어나 이미지를 통째로 보고 하나의 그룹화된 시퀀스로 예측하는 CRNN 모델이 처음 제안됐었습니다. 이 방법은 CTC 기반의 text recognition 모델들의 시초가 된 연구로 오늘 리뷰하는 논문도 CTC 기반의 text recognizer 모델로 추가적으로 성능을 개선시킨 연구입니다. 해당 방법론은 1) 이미지 피처를 추출하는 단계와 2) 추출된 시각 특징을 기반으로 시퀀스 모델을 사용해 텍스트를 예측하는 방법을 따릅니다. 앞서 언급했던 irregular 한 텍스트에 대해서는 인식 정확도가 떨어지지만 추론 속도도 빠르고 효율적인 방법이라 여전히 많이 사용된다고 합니다. 이후 CTC 방법 말고 attention 기반의 encoder-decoder 구조의 text recognition 모델도 제안되었었습니다. 인코더로 부터 이미지의 visual feature를 추출하는 건 CTC 기반의 모델들과 똑같지만 이후 디코딩의 과정에서 어텐션을 통해 적응적으로 필요한 특징만에 집중해 예측할 수 있게 되었습니다. 캐릭터가 순차적으로 예측되는 방법론의 auto regressive method의 경우 이전 스텝에서 디코딩된 문자를 활용할 수 있었는데 이는 단어가 가지는 문맥 정보를 확인할 수 있다는 점에서 그리고 어텐션의 매커니즘으로 해당 방법은 irregularity text에 대한 인식 정확도가 좋았습니다. 다만 캐릭터 하나하나를 순차적으로 예측하다보니 오래 걸렸습니다. 이후 어텐션 기반의 인코더-디코더 구조지만 병렬적으로 예측하게 한 모델이 제안되어인식 속도가 빨라졌었지만 auto regressive 하게 예측하는 것에 비해 정확도가 떨어져 추가적으로 LM의 언어에 대한 사전지식을 활용한 방법도 많이 제안되어왔습니다.
여기서 논문의 저자는 원점으로 돌아가 CTC 기반의 text recognizer가 가지던 문제에 대해서는 충분히 논의되지 않았음을 얘기하며 특히 이미지의 visual feature을 1차원의 시퀀스로 만드는 과정에서 단순하게 평균을 내거나 압축시키는 방식이 너무 나이브하고 문자 인식에 필요한 중요한 정보를 읽는다는 것을 지적하며 최대한 정보를 보존하면서 CTC의 방법이 요구하는 1차원의 시퀀스로 압출할 방법을 찾는 것이 필요하다고 얘기합니다. 그리하여 저자가 찾은 해결 방법은 Adative Feature Compression Text Recognization (AFCTR)을 CTC 모델에 도입할 것을 제안합니다. 그럼 아래에는 이어서 그 방법에 대해 더 설명하겠습니다.
2. Methods
A. Overview
저자가 제안하는 모델은 1) visual backbone, 논문에서 새롭게 제안하는 2) adaptive feature compression block, 3) CTC 디코더로 구성됩니다. 전체 아키텍처는 아래와 같습니다.
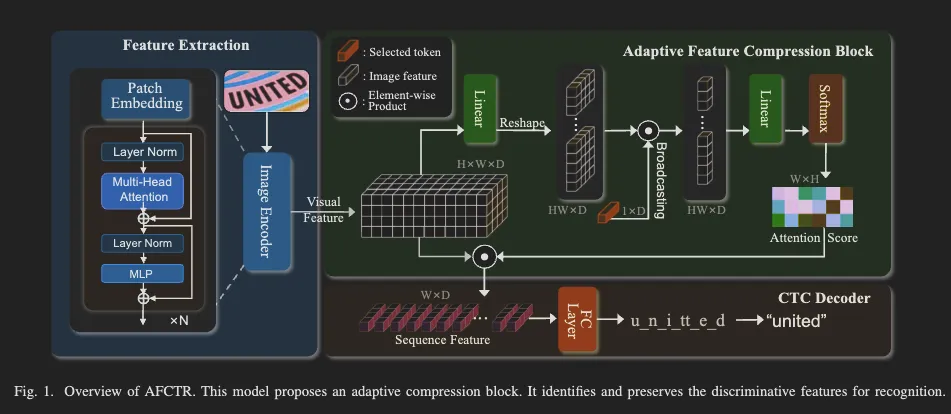
입력 이미지는 패치로 나눠지고 트랜스포머 블록에서 이미지의 시각 특징(F_v)을 추출합니다.
구별력 있는 특징을 얻기 위해 adaptive feature compression 블록이 사용됩니다. 이 모듈은 adaptive attention 매커니즘으로 텍스트에 해당하는 영역의 특징이 배경과 구별되고 텍스트에 집중하도록 합니다. 해당 모듈을 통과하게 되면 이 모듈의 입력으로 들어왔던 시각 특징 (F_v)이 캐릭터 시퀀스로 표현됩니다. (F_s) 이후 CTC 디코딩을 통해 피처 시퀀스에 대해 병렬적으로 각 영역 마다의 예측을 수행합니다.
B. Feature Extraction
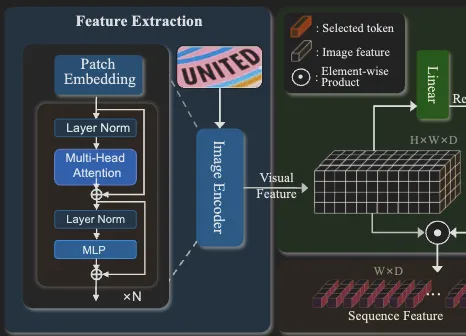
논문에서 제안하는 새로운 프레임워크는 ViT을 인코더 백본으로 사용합니다. 이미지를 패치 임베딩으로 변환하고 트랜스포머 블록을 통해 지역적인 피처 정보와 동시에 패치간의 전역적인 관계 또한 학습됩니다. 이런 방식은 텍스트 이미지로 부터 multi-granularity semantic information을 추출할 수 있게 하고 따라서 텍스트가 갖는 복잡한 형태를 이해하는 데 도움이 된다고 합니다. 이미지 인코더는 12개의 층으로 구성된 ViT를 사용하였고 cls 토큰은 제외하였다고 합니다. 입력 이미지(hxw)는 동일 크기(여기선 4)의 패치로 나뉘어져 flatten 되고 linear projection 을 통과해 D 차원을 갖습니다. 그리고 여기에 추가적으로 위치 정보의 positional encoding이 더해집니다. 따라서 이미지에 대한 인코딩된 feature (F_v)는 아래와 같이 나타낼 수 있습니다. 위 과정은 ViT의 방법을 그대로 따르기 때문에 이해하는데는 어렵지는 않았습니다.
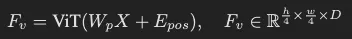
C. Adaptive Feature Compression Block (AFCB)
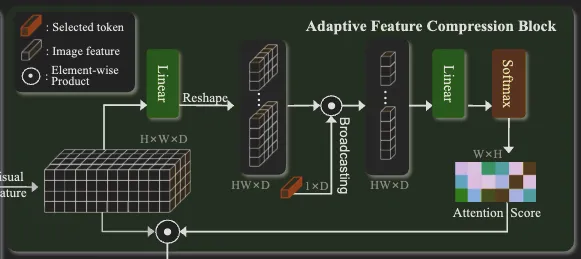
다음은 저자가 새롭게 제안한 모듈로 이전 연구들과 제일 큰 차별점을 보이는 부분인데요. 이 모듈로 저자는 비정형의 텍스트, 복잡한 형태의 텍스트에 대한 인식 정확도를 향상시키고자 했습니다. 대략적인 방법은 이렇습니다. 선택적으로 배경으로 부터 텍스트 영역을 확실히 구분하고 이렇게 취득한 텍스트의 피처를 잘 압축 시켜 다음 CTC 디코더에 전달해주는 것을 목적으로 합니다. 이 모듈은 어텐션 매커니즘 기반으로 동작합니다.
우선 CTC 기반의 모델이 갖는 한계점을 설명하면, CTC 기반 모델은 2D 이미지 피처를 1D의 시퀀스로 압축해 글자를 예측합니다. 그래서 가로 방향은 남겨두고 세로방향의 피처들은 평균을 냅니다. 하지만 단순히 평균을 낸다면 문자가 갖는 구조적인 특징을 잃을 수 있게 됩니다. 그렇다고 항상 이미지에 텍스트가 오는 위치 배열된 구조가 같지 않기 때문에 (특히 굽은 형태의 텍스트는 각 문자가 이미지에서 위치하는 바가 다양함) 고정되게 피처를 추출할 수 없스니다. 따라서 시각 피처로 얻은 어텐션 맵을 곱해 텍스트가 아닌 영역의 피처는 약화시킨 후 세로 방향으로 압축해 최대한 텍스트에 대한 정보를 유지하면서도 CTC가 입력으로 받는 시퀀스 형태로 전달할 수 있게 되는 것입니다.
인코더를 타고 나온 V_f(HxWxD)는 1) flatten 되고 (HWxD) 2) fc layer (Wk, W_v 각각) 통과해 (DxHW) 차원의 key x_k와 value x_v로 변환됩니다. 임의의 1xD 차원의 토큰 (Q)을 query로 앞서 (x_k)와 어텐션 연산이 적용됩니다. 결과로 이를 다시 width와 height에 대해 나눈 후(1xHW ⇒ H x W) softmax를 태워 각 요소가 확률값을 가지도록 하고 이후 해당 어텐션 마스크를 x_v에 곱합니다. 이후 height 방향으로 압축해 CTC 디코더의 입력으로 적합한 피처 시퀀스(WxD)의 형태로 만듭니다. 저자는 이 과정에서 텍스트가 있는 영역에 대한 피처만을 집중적으로 가져오게 된다고 설명합니다.
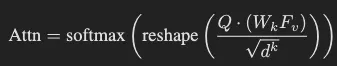
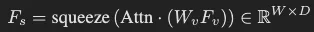
D. CTC Decoder
앞선 방법으로 하나의 시퀀스 벡터로 압축된 visual feature에 대해 디코딩을 수행합니다. feature sequence에 대해 linear precition을 수행해 각 스텝에서의 charcter를 예측합니다.
모델은 CTC loss로 학습됩니다.
3. Experiments
모델 학습은 원본 데이터셋과 합성 데이터 둘 다에 대해 따로 진행되었습니다. 합성 데이터셋으로는 MJSynth( MS), SynthText(ST)가 사용 되었고 real-word 데이터셋으로는 Union14M-L가 사용됐습니다. 그리고 6개의 벤치마크 데이텃에 대해서 성능 평가가 진행됐습니다. (ICDAR 2013, ICDAR 2015, IIIT5k-words, Street View Text, Street View Text-Perspective, CUTE80)
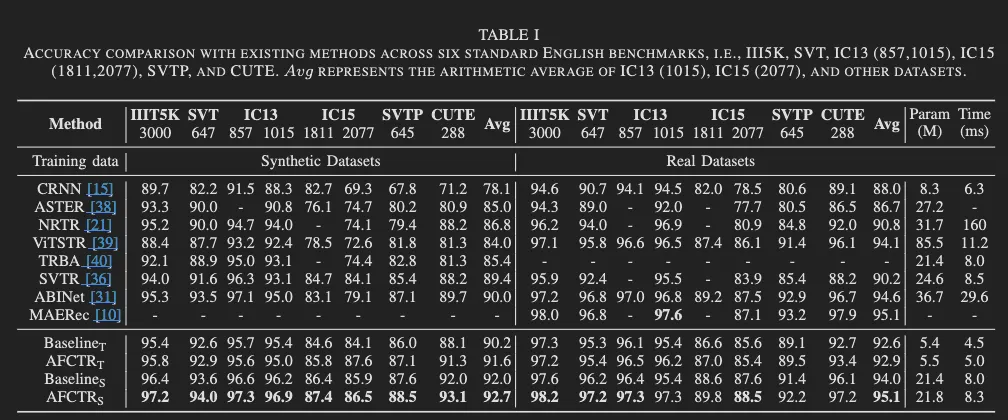
우선 AFCTR_T에 대해 결과 비교를 하자면, 5.5백만이라는 적은 수의 파라미터 만으로도 이전 모델이 달성한 성능 보다 뛰어 넘거나 거의 근사하는 결과를 보였습니다. 파라미터 수를 늘려 AFCTR_S로 평가했을 때는 대체적으로 대체적으로 6개의 벤치마크 데이터셋에 대해 가장 우수한 성능을 보입니다. 추론 속도가 다른 모델에서와 차이가 나기도 하지만 적은 파라미터수와 가장 우세한 정확도를 가진다는 점을 함께 고려했을 때 이는 충분히 경쟁력을 갖는 결과라고 설명합니다.
그리고 Table 1에서 평가되는 데이터셋에 대해 어느정도 saturated 된 상태기 때문에 인식이 더 어려운 데이터셋 Union14M-benchmark에 대해서도 비교가 진행되었는데 평가한 결과 Union14M-benchmark를 구성하는 7개의 데이터셋에 걸쳐서도 가장 높은 성능을 보였습니다.
- 순서대로 Cur: 굽은 텍스트, M-O: multi-oriented (회전돼 있는 텍스트), Art: Artistic 화려한 폰트의 텍스트, Ctl: Contextless 즉 단어 자체에 의미가 없는 경우, Sal: salient, M-W: multi words, Gen: general 다.
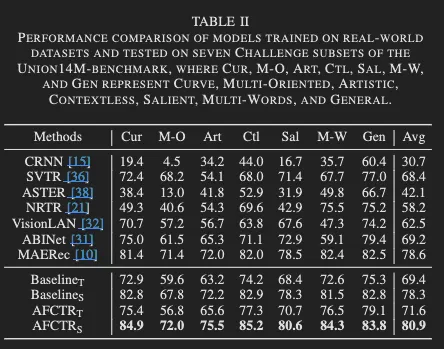
특히 굽은 형태의 텍스트나 multi diretional, artistic text에 대해서도 비교적 높은 성능을 유지했다는 점도 눈 여겨볼 점인데요 논문의 저자가 타겟하는 irregular text에 대한 인식 정확도 향상을 확인할 수 있는 결과이지 않나 싶습니다. Ctl 데이터셋에서의 정확도가 제일 높은데 이미지의 시각 특징으로 부터 문자를 예측한다는 점에서 language model의 언어적인 능력을 활용하는 모델 보다 비교적 더 방해를 받지 않았다고 설명합니다.
또한 Table. 1, 2에서 베이스라인과의 비교도 있는데요 저자가 제안하는 AFCTR_T가 작으면 0.3 많게는 1.4% 정도의 차이로 베이스라인을 뛰어 넘습니다. 그리고 그 차이는 인식이 어려운 데이터셋인 Union14M-benchmark에 대해서 더 컸습니다. (다만, M-O: multi-oriented 데이터셋에 대한 실험 중 Baseline_T와 AFCTR_T를 비교하면 오히려 성능이 하락한 경우도 있었습니다. 하락 폭 이 적지 않았는데 이에 대한 설명은 없는 것 같아서 조금 아쉽지만 추측하자면 패치 임베딩의 차원수를 어떤 걸로 선택했는지가 중요했나봅니다.) 무튼 해당 결과 비교로 저자가 제안하는 방법이 단순히 height 방향으로 평균을 내서 하나로 압축하는 것 보다 성능 개선의 효과를 주었다는 것을 확인할 수 있었습니다.
아래는 irregular text에 대한 attention map을 히트맵 형태로 시각화한 결과인 듯합니다. 복잡한 형태임에도 이미지 속 텍스트가 있는 영역만을 잘 집중해서 보고 있단 걸 확인할 수 있는데요 이 역시 저자가 제안한 adaptive feature compression이 효과가 있음을 보여준다고 설명합니다. (여기서 베이스라인과의 정성적인 결과 비교도 한다면 더 그 차이를 더 확인하기는 쉬웠을 것 같습니다. 아래에 다른 모델과의 정성적 결과 비교도 있습니다.

4. Conclusion
리뷰를 정리해보겠습니다. 저자는 CTC기반의 text recognition model인 AFCTR을 제안하였는데요. 모델을 이루는 요소 중 Adaptive Feature Compression Block(AFCB)을 제안한 것이 이전 방법론과의 차이가 있었습니다. 어텐션 매커니즘으로 수직 방향으로 피처를 압축할 때 전경인 텍스트에 더 가중할 수 있도록 배경과의 구분이 확실히 되도록 하는 방법이었습니다. 저자는 이전 모델들이 단순하게 평균을 내거나 했던 방법들이 수직 방향의 텍스트의 구조 정보를 잃게 된다는 점을 지적하며 수평 방향과 함께 수직 방향도 최대한 문자 인식에 필요한 피처를 보존할 수 있는 방법으로 제안하게 된 것입니다. 저자의 제안은 실험을 통해 훨씬 개선된 성능을 준다는 것을 확인할 수 있었습니다. 논문을 통해 이전의 시퀀스 생성 방법의 문제를 확실히 알게 되고 이와 함께 저자가 제안하는 단순하지만 차이는 확실한 방법을 알 수 있었습니다.