안녕하세요, 예순 아홉번째 X-Review입니다. 이번 논문은 2025년도 CVPR에 올라온 Towards Training-free Anomaly Detection with Vision and Language Foundation Models 입니다. 바로 시작하도록 하겠습니다.
1. Introduction
본 논문은 logical anomaly task에 대해 다룬 논문입니다. 간략하게 task에 대해 설명을 드리자면, 단어 의미 그대로 logical 즉, 논리적 이상 탐지라는 뜻인데요. 예를 들어, 병에 들어있는 액체가 빨간색이지만 label이 바나나 그림이 붙어 있는 경우라던가, 핀이 정확히 15개 있어야 하지만 16개 있는 경우 등이 논리적 이상에 해당합니다.
기존에 이 logical AD task를 연구는 주로 시각적인 정보에 의존하는 경우가 많았는데요. 이 시각정보만을 가지고는 보다 high-level의 anomaly는 검출하기 어려울 뿐만 아니라, 성능을 내기 위해 정확한 annotation과 보다 복잡한 네트워크 구조를 필요로 하곤 해서 실용적 측면에서 현실적이지 못하다고 볼 수 있습니다.
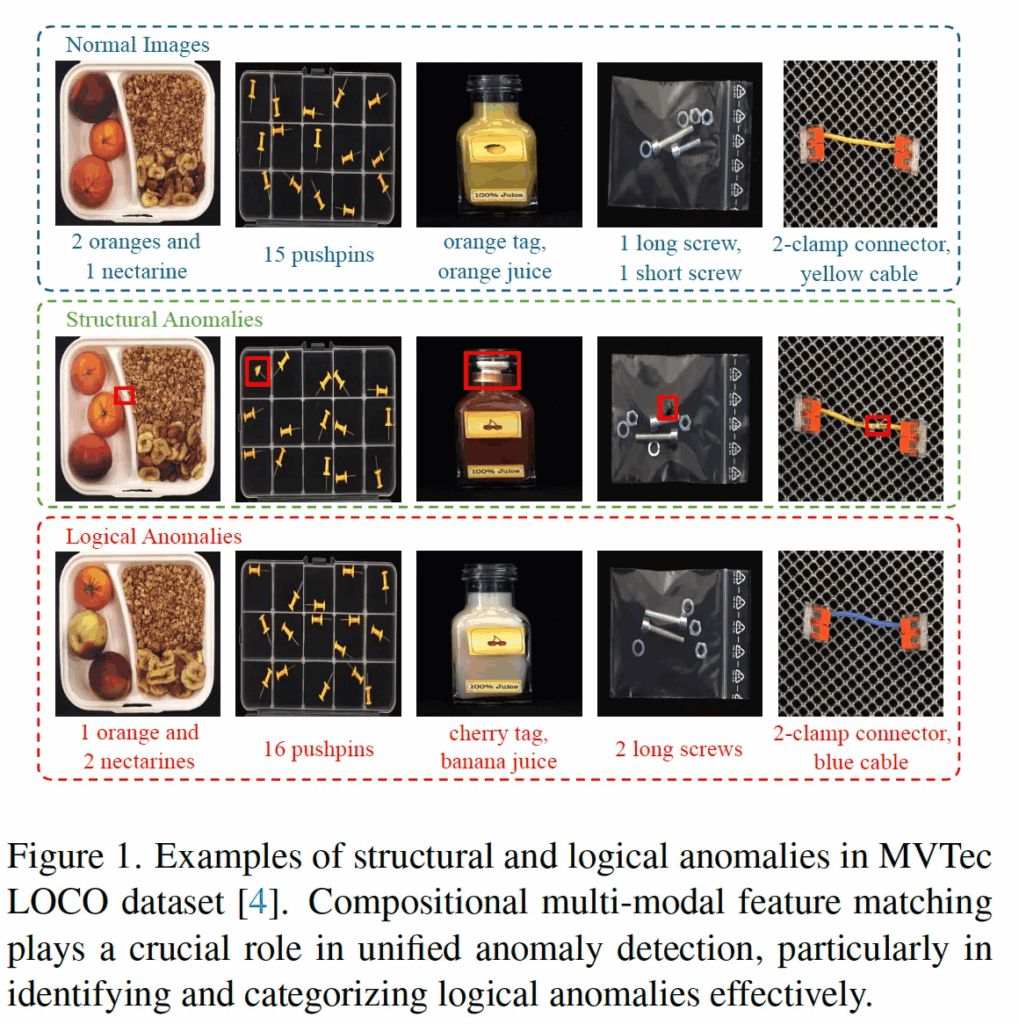
위 Fig1에서 볼 수 있듯이 초록색 점선 박스 안에 있는 structual anomalies 예시들 같은 경우에는 normal image간의 visual feature를 matching하는 방식이 주로 사용됩니다. 하지만, 그 아래 빨간 점선 박스와 같은 보다 high level인 logical anomaly의 경우에는 multi-modal feature matching이 필요하다고 저자는 주장합니다. 아직까지 연구는 VLM을 활용해 structural anomaly와 logical anomaly를 둘 다 다루는 쪽으로는 활발하지 않은 편입니다.
따라서 본 논문에서는 structural, logical 이 둘을 모두 다루는 training-free 멀티모달 프레임워크(이하 LogSAD)를 설계하였습니다. LogSAD 구성은 첫 번째로 match-of-thought(이하 MoT)라는 것으로 GPT-4V와 같은 멀티모달 모델을 사용해 어떤 구성 요소가 중요한지, 어떤 조합이 지켜져야 하는지에 관련한 matching proposal들을 생성하는 것입니다. 또 두번째로 제안하는 것은 CLIP이나 SAM과 같은 모델들을 사용해 다양하게(patch level, interest level, composition matching level) anomaly를 detection하도록 하는 점이며, 마지막으로 각 detector들이 output으로 낸 anomaly score들을 calibration하고 fusion해 최종 anomaly 여부를 판단하게 됩니다. 디테일하게는 method단에서 설명드리도록 하겠습니다.
2. Methodology
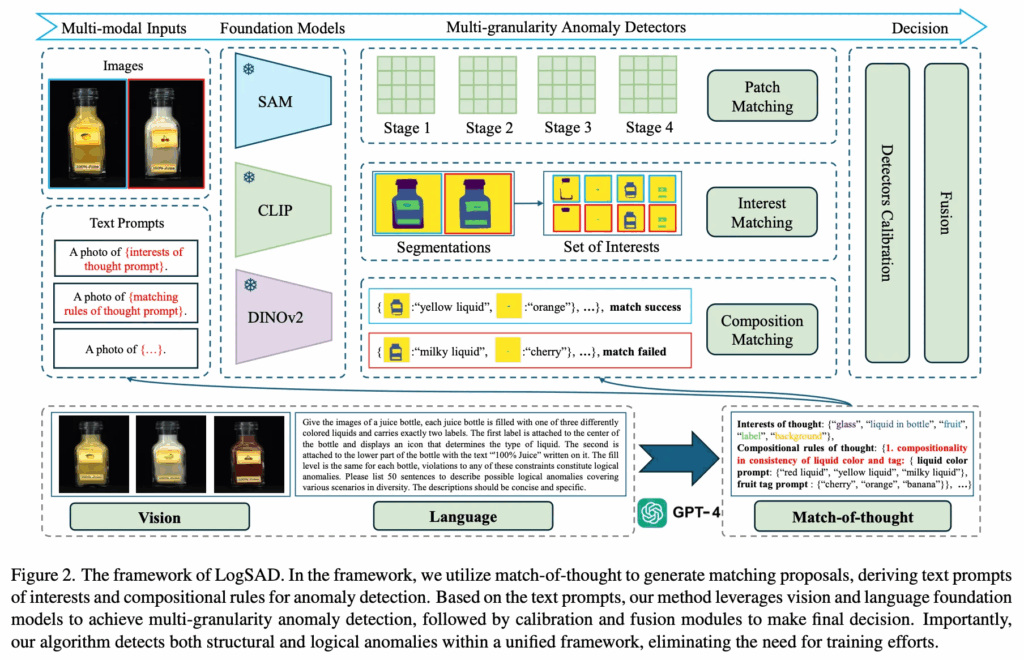
위 Fig2에서 LogSAD의 전체적인 프레임워크를 살펴볼 수 있습니다. 크게 두 부분으로 나눠볼 수 있는데, 아래쪽에 그려져 있는 gpt-4를 사용하는 match-of-thouht(MoT) 부분과 그 위에 SAM, CLIP, DINOv2를 사용하는 multi-granularity detectors 부분입니다.
2.1. Match-of-thought
먼저 Match-of-thought부분을 살펴보도록 하겠습니다.
Intro에서 짧게 언급했듯이 structual anomaly들은 보통 어디가 긁혀있다거나 찌그러져 있는 것처럼 눈에 보이는 결함에 해당합니다. 반면에 logical한 anomaly는 단순 anomaly가 아니라 compositionality(구성 규칙)이 깨진 경우를 말하는데요. 즉, 겉보기에는 멀쩡하지만 뭔가 있어야 할 것이 없거나, 잘못되게 놓여있는 경우를 말합니다.
근데, 기존 LLM들은 이런 구성 규칙 기반의 추론을 좀 못한다고 하는데요. 이런 점을 보완하기 위해 제안된 것이 match-of-thought(MoT)입니다. 이 MoT는 기존 CoT에서 영감을 받은 것인데요.
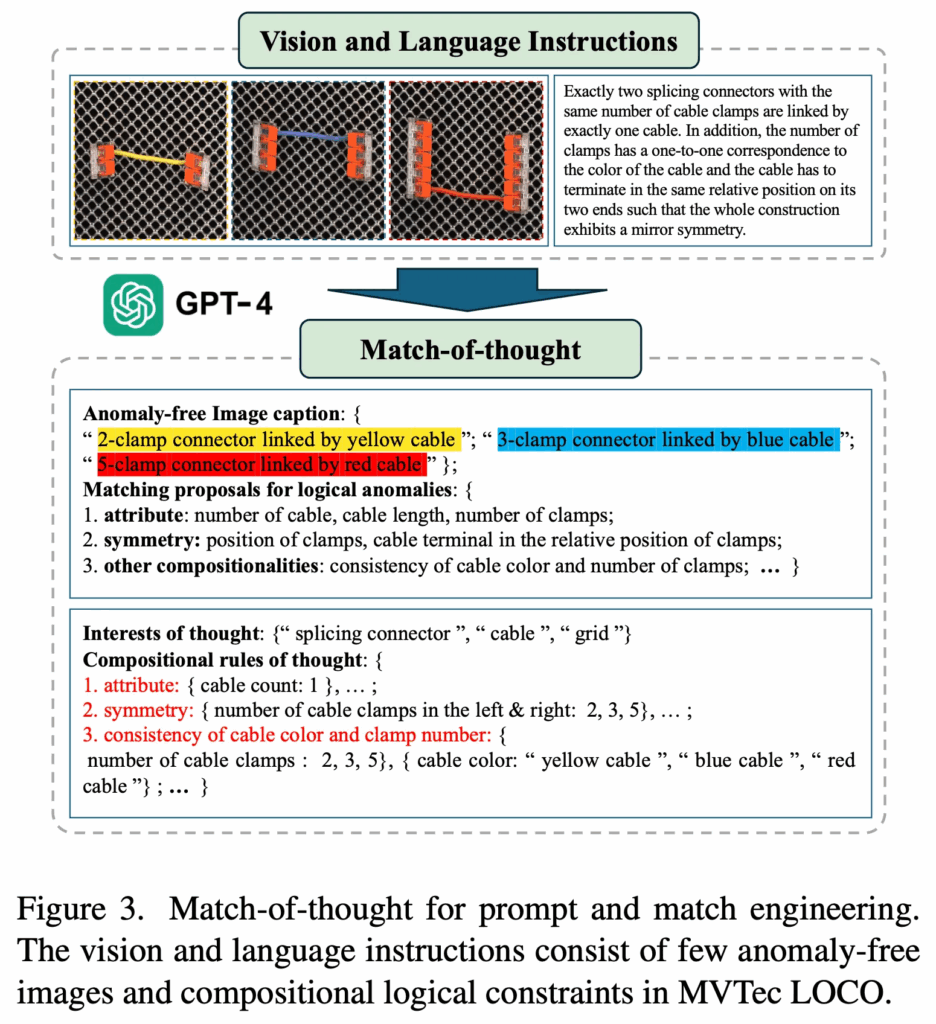
위 Fig3에서 보이다시피, MoT에서는 먼저 image와 그에 대한 설명을 바탕으로 GPT-4를 사용해 interest of thought(관심 대상)을 뽑아내고, 동시에 logical anomaly를 구성하는 matching rules을 만들어 냅니다.
구체적으로는, 저 Fig3에 있는 입력 image의 경우에는 MVTec LOCO라고 하는 데이터셋인데요. 이 데이터셋에는 class마다 특정한 논리 규칙이 포함이 되어 있습니다. 이 논리 규칙 설명을 기반으로 instruction으로 만들어서, 몇 개의 normal image와 함께 GPT 입력으로 넣은 것이죠. 그렇게 되면, GPT4 바로 아래 부분을 보시면 되는데, GPT-4V가 이 normal image에 대한 caption과 함께 matching proposals들을 뱉어내게 됩니다. 즉, 어떤 것이 정상이고, 어떤 조합이 이상인건지 gpt가 output으로 내는 것이죠. 이렇게 output으로 나온 것을 정리하여 어떤 요소를 봐야 하는지에 대한 interest를 만들고(그림에서는 “splicing connector, cable, grid가 해당), 그 사이의 조합 규칙도 구성을 합니다.
이렇게 만들게 되면, 기존 LLM들이 logical anomaly를 검출할 때 자주 겪었던 문제인 factuality나 hallucination을 줄일 수 있다고 하네요. 게다가, 이 MoT 방식은 전처리 단계로만 동작하기 때문에 연산량도 크지 않고 실제 application에 쉽게 적용할 수 있다는 장점이 있습니다.
2.2. Multi-granularity Anomaly Detectors
다음은 SAM, CLIP, DINOv2를 사용하는 multi-granularity detectors 부분에 대해 살펴보도록 하겠습니다. 이는 structural 이상과 logical 이상 둘을 다루기 위해 제안된 부분인데요. structural 이상은 보통 스크래치나, 찌그러짐처럼 좀 국소적인 영역에 나타나고, logical anomaly는 구성 규칙이 깨진 경우에 발생합니다.
이런 서로 다른 유형의 anomaly를 하나의 detector로 다루기는 어려운데요. 왜냐면, structural anomaly는 좀 국소적인 feature를 봐야하고, logical은 좀 더 global하게 봐야 하기 때문입니다. 이런 점을 해결하기 위해 제안된 것이 multi-granularity detectors인데, 이름 그대로 각각의 detector들이 서로 다른 수준(granularity)에서 동작한다는 것입니다. 여기서는 patch 단위와 interest 단위, 구성 조합 단위에 초점을 맞췄습니다.
Patch Matching
먼저 patch matching은, image에서 patch feature를 추출해 이를 비교하는 방식입니다.
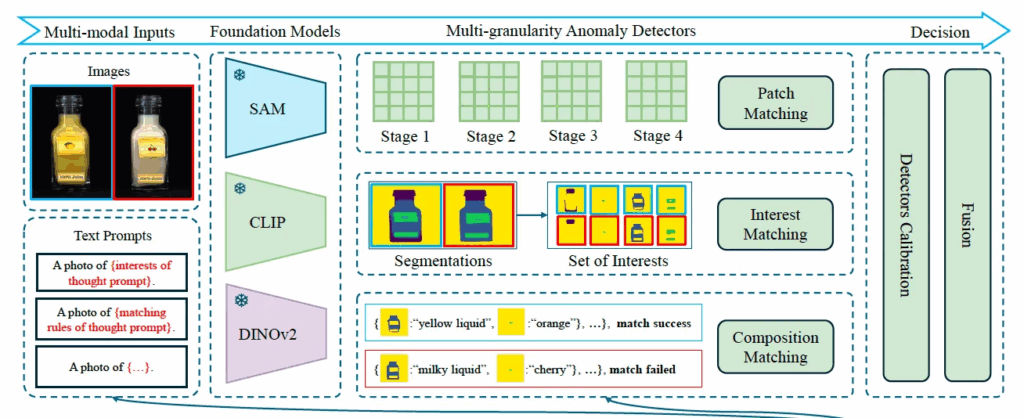
위 그림에서 맨 위에 부분에 해당을 하는데요. 여기서는 CLIP과 DINOv2처럼 pretrained된 vision backbone을 사용해 계층적으로 다양한 level의 patch feature를 뽑아내게 되고, 동시에 이후 비교의 기준이 되는 normal image feature들도 뽑아 memory bank에 저장합니다. 이후에, 이를 사용해 nearest neighbor을 찾아 query image가 normal인지 anomaly인지 판단하게 됩니다.
수식으로 살펴보면 아래와 같습니다.
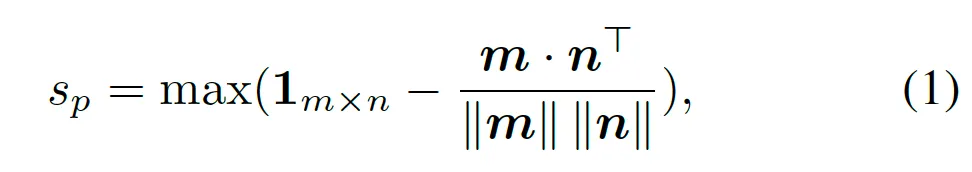
- m : 현재 image에서 뽑은 m개의 patch feature (mxd)
- n : normal image memory bank에서 가져온 n개의 patch feature (nxd)
query image와 memory bank의 patch feature간의 코사인 유사도를 계산한 다음 1에서 빼 dissimilarity를 계산하게 되구요. 이 중 가장 max값을 뽑아내어 patch level의 anomaly score로 사용하게 됩니다. 즉, 가장 높은 dissimilarity를 뽑아내어 score로 사용한다는 것이 가장 이상한 patch가 얼마나 이상한지 뽑아서 사용하는 것으로 보시면 됩니다.
Interest Matching
다음은 interest matching부분입니다. 앞서 MoT 과정을 통해 interest of thought를 뽑아 냈었는데요. 이 관심 요소들을 실제 image에서 찾아내기 위해서 CLIP과 SAM을 사용해 open-vocabulary segmentation을 수행했습니다.
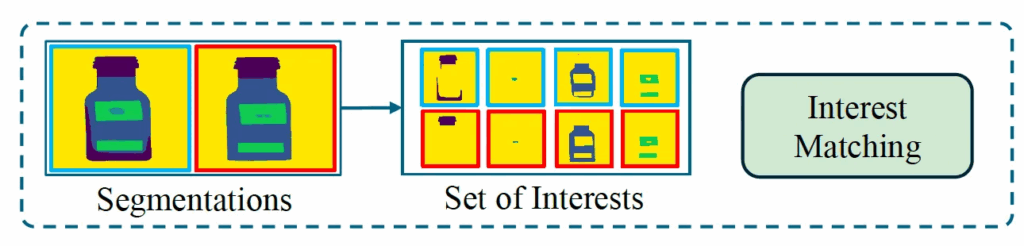
Fig2에서도 맨 아래 GPT4를 통해 뽑은 MoT중에 Interest of thought로 “glass”, “liguid in bottle”, “fruit”, “label” “background”를 살펴볼 수 있고, 이를 가져와 Text Prompts단에서 A photo of fruit 처럼만들어 넣어 위 그림처럼 해당 영역의 mask patch들을 뽑아내게 되고 이를 avg pooling해 interest feature로 사용하게 됩니다. 이런 방식으로 뽑아낸 여러 interest feature를 기반으로 matching을 하게 되는데, 이때는 bipartite matching으로 풀도록 하였습니다. 컨셉은 정상 image의 interest feature들과 매칭들 해 나가면서, 매칭이 안되는 경우에 anomaly일 가능성이 높다는 것이죠.
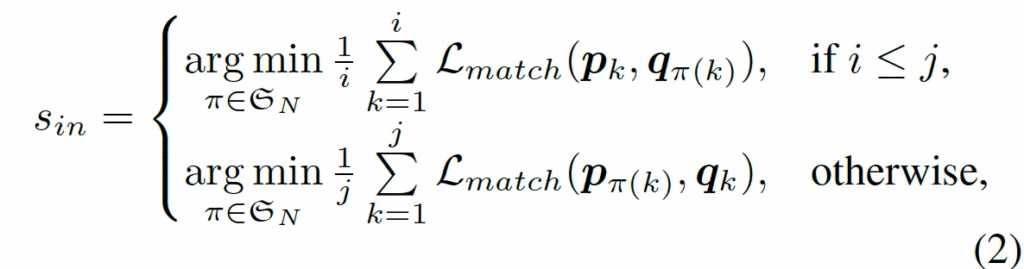
수식으로 살펴보면 위와 같은데요. 여기서 P는 현재 query로 들어온 iamge에서 추출한 i개의 interest feature vector들이며, Q는 normal image memory bank에서 뽑아온 j개의 interest vector들입니다. 이 둘간의 matching cost는 아래와 같구요.
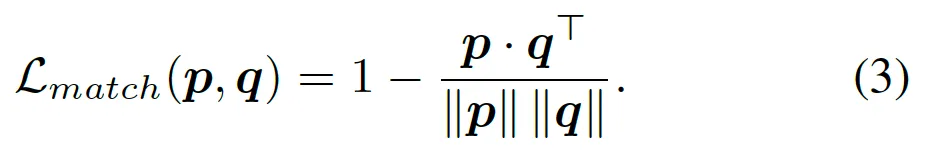
결국 정리하자면, P와 Q 사이의 이분 매칭을 하는데, matching이 안될수록 score는 커지게 될것이구요, 잘 매칭될수록 anomaly score는 작게 계산될 것입니다.
Composition Matching
마지막으로 composition matching입니다.

MoT에서 보시면 logical한 제약 조건들을 compositional rules로 표현하고 있습니다. 예를 들어 위 그림에 있는 것처럼 정상 상태에서는 액체 색깔과 label이 일치해야 한다는 규칙이 있다고 한다면, 이를 matching rule로 세팅을 해두고, CLIP을 통해 visual feature V(실제 액체 색깔)과, text feature T(라벨에 적힌 과일 이름)을 뽑아 냅니다. 이렇게 뽑힌 visual, text feature들은 이후, 조합 규칙이 잘 지켜졌는지(즉, 논리적인 이상이 없는지) 판단하는데 사용됩니다.

위 그림에서도 yellow liquid, orange처럼 각각 뽑힌 것을 확인할 수 있습니다. 이걸 CLIP이 서로 어떤 것이 잘 맞는지 판단하도록 비교합니다. CLIP의 image와 text vector가 같은 공간에 있기에 가능하겠죠. 이런식으로 visual feature와 text feature를 비교해서 rule이 잘 지켜졌는지 확인할 수 있습니다. 만약 잘 지켜졌다면 정상, 아니라면 anomaly가 되겠습니다. score 뽑는 부분을 수식으로 표현하면 아래와 같은데요.
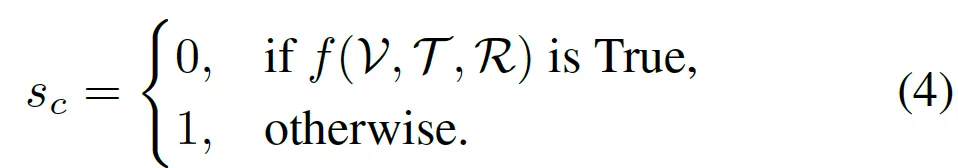
visual 정보 V, text 정보 T, 규칙 R을 넣었을 때 규칙을 만족한다면 True, 아니라면 False로 score가 1이 되게됩니다.
2.3. Calibration and Fusion
마지막으로, 앞에서 나온 세 anomaly score를 사용해 최종 output을 내야할텐데요. 이 세 anomaly score들은 각기 다른 방식으로 계산되기에 기준이 서로 다를 수 있습니다. patch는 dissimilarity고 composition은 0또는 1의 값만 갖는 것을 생각해보면 될 것 같습니다. 이걸 그대로 합치면 좀 그러니까, 본 논문에서는 이를 calibration하고 fusion하는 단계를 제안합니다.
구체적으로 이 세 가지 중에서 patch와 interest는 anomaly score를 normal image의 평균과 표준편차를 사용해 정규화하고 sigmoid 태워 0~1로 변환시켰습니다. composition은 애초에 0 or 1이기에 보정을 하지는 않도록 하였습니다. 최종적으로 이 세 anomaly score중에 가장 큰 값을 최종 score로 사용하도록 하였습니다.
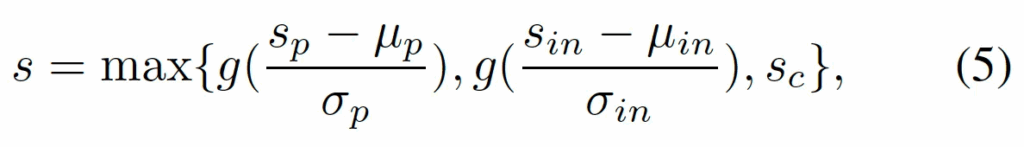
수식으로 보면 위 식5와 같습니다.
- s_p : patch-based score
- s_{in} : interest-based score
- s_c : composition-based score
한마디로, 세 detector 중에 가장 anomaly라고 판단한 detector 결과를 가져가겠다는 것이죠.
3. Experiment
Main Results
본 논문에서 제안된 LogSAD는 MVTec LOCO 데이터셋을 base로 실험을 하였습니다.
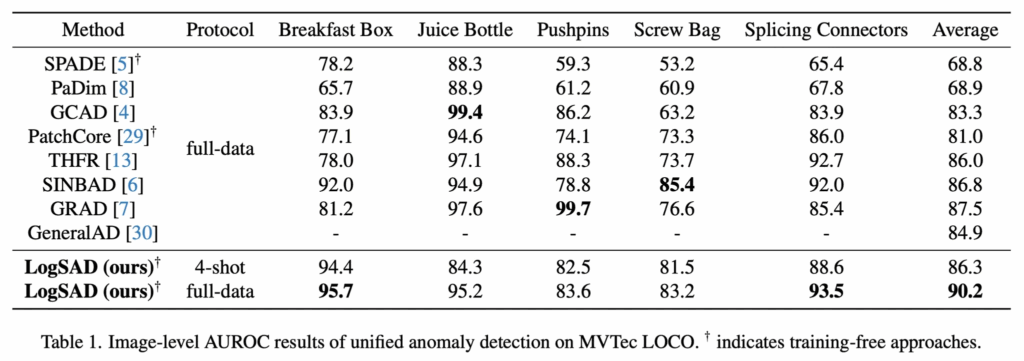
위 table1이 그 결과인데요. 실험 결과 모든 object에서는 아니지만, 3개의 object에서 sota 성능을 달성하였으며, training 없이도 full-data에서 좋은 성능을 보였습니다.
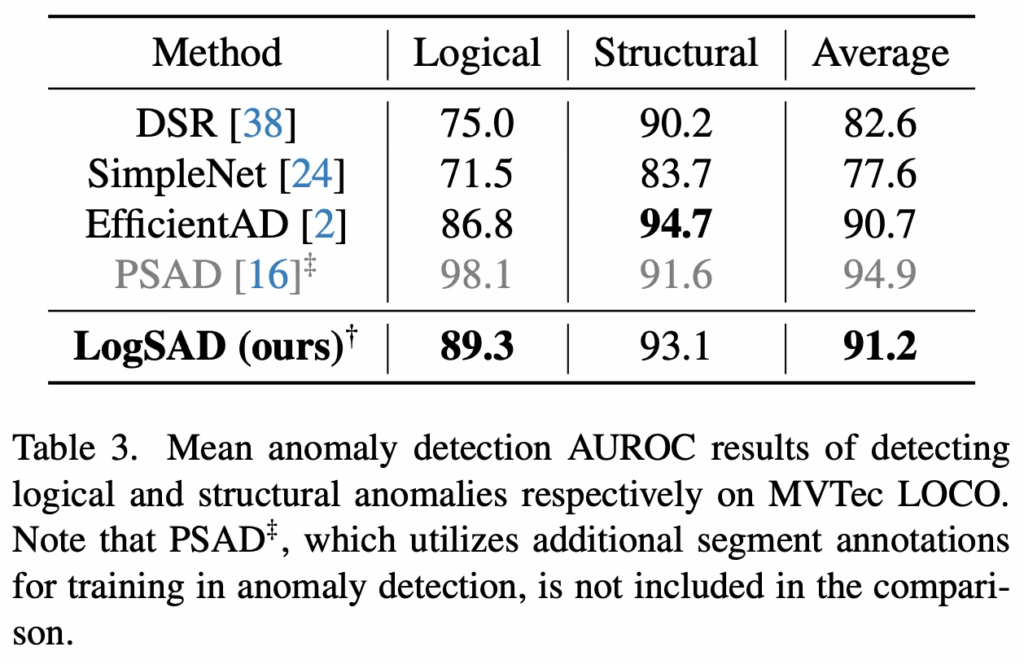
또, table3에서도 logical, structural을 구분하여 성능 평가를 했을 떄 기존 SimpleNet, EfficientAD보다 더 좋은 성능을 보이고 있으며 추가로 저기 회색 처리된 PSAD라고 하는 방법론은 다른 방법론들과는 다르게 추가적으로 segment annotation을 사용하는 학습 기법인것을 감안해서 보면 되겠습니다.
Ablation Study
다음은 ablation study인데요.

먼저 Fig4는 정성적인 결과인데, 이는 LogSAD 프레임워크에서 interest를 어떻게 정의하는지가 성능폭이 있을 것을 고려하여 이 interest 요소들을 이분매칭에 사용할 수 있도록 하기 위한 중간 segmentation 결과를 보여주고 있습니다. 그림을 보면 MoT와 VLM을 사용하여 수행한 sigmentation 결과는 엄청 정밀한 것을 확인할 수 있습니다. 이는 추가적인 학습 없이도 효과적으로 semantic segmentation이 가능하다는 점을 시사하고 있습니다.
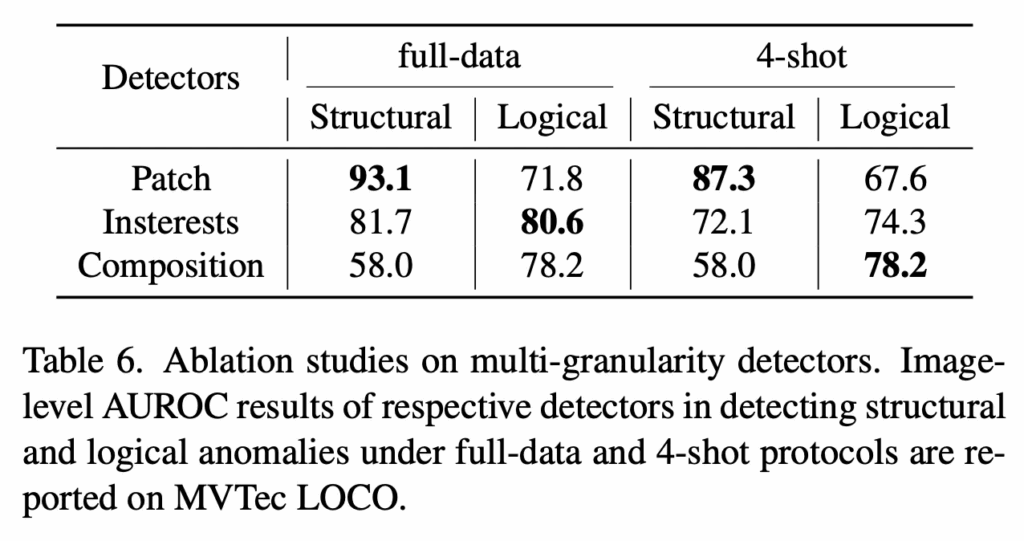
또 다음으로 table6을 보면 제안된 multi-granularity anomaly detectors에 관한 실험인데요. 각 detectors가 structural anomaly와 logical anomaly를 다루는 방식에서 일관적으로 어떤 요소가 둘 다 성능이 항상 좋지 않은 점을 볼 수 있습니다. 예를 들어 patch의 경우에는 structural에서 성능이 높지만, logical 성능은 좀 떨어지는 편이구요. composition의 경우에는 structural 성능은 좀 떨어지지만 logical은 성능이 높인 편입니다. interests는 이 둘을 보다 균형적으로 다루는 느낌이구요. 이를 보아 이 셋이 서로 상호보완적인 특징을 갖는다고 볼 수 있습니다.
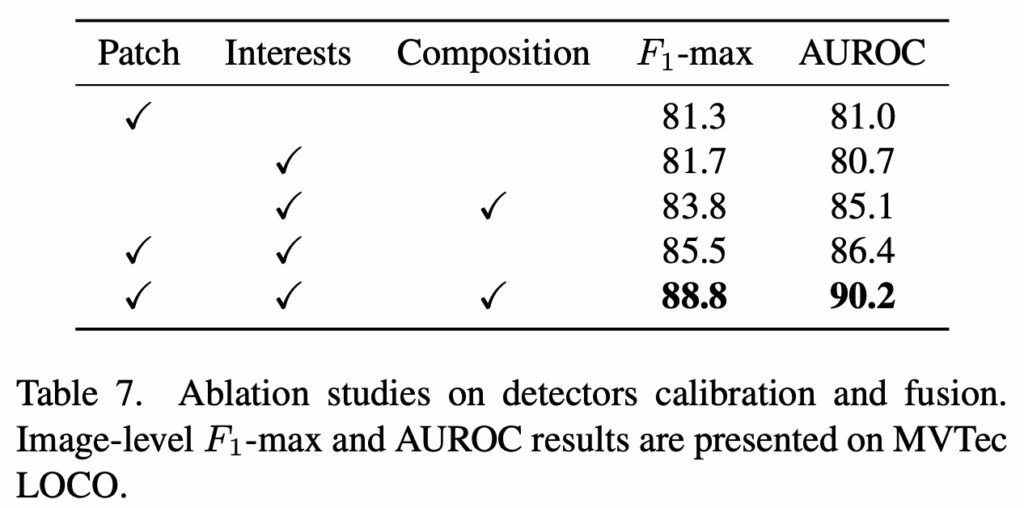
그 다음 table7에서는 각 개별 detectors들의 F1max 성능과 auroc 성능, 그리고 이들을 fusion한 성능을 함께 보여주고 있습니다. 세 patch, interest, composition을 한번에 fusion하여 사용한 경우가 가장 좋은 성능을 보이는 것을 보아 여기서도 table6과 마찬가지로 서로 다른 detector들이 structural anomaly와 logical anomaly를 상호 보완적으로 처리할 수 있다는 점을 보여주죠. 이로써, 제안된 multi-granularity detector에서 제안된 score calibration과 fusion 부분의 효과가 있음을 확인할 수 있습니다.
안녕하세요, 좋은 리뷰 감사합니다.
제안된 부분이 multi-granularity anomaly detectors라고 patch, interest, composition matching을 한번에 하는 것으로 이해했습니다. 그렇다면 보통 이전 연구들에서는 patch level의 matching만 수행했던 것이고 interest나 composition은 전혀 고려되지 않았나요? 아니면 patch level 자체도 계층적으로 뽑아 매칭하는 것 자체가 새로 제안된 부분인지 궁금합니다. 또 ablation study에서 patch는 structural 성능이 높이 나온건 이해가 가는데 interests는 왜 균형있게 성능이 나왔다고 봐야할까요?
감사합니다.
댓글 감사합니다.
네 이전에는 patch level의 matching이 중점이고, interest나 composition matching은 거의 없다고 봐도 될 것 같습니다. 또 interest가 균형있는 성능이 나온 이유에 대해, 논문에서는 언급하고 있지만 간단히 생각해보자면 이 interest matching이 segmentation 기반의 feature matching이기에 구조적이라던지, 논리적이라던지 둘 다 일정한 성능을 유지할 수 있지 않았나 싶습니다.