안녕하세요 이번주는 Scene Complete과정에 속하는 6D Pose Estimation 논문을 리뷰하도록 하겠습니다. 단 한장의 RGB-D 앵커 이미지만 활용해 unknown 객체의 6D pose와 metric scale을 추정하는 model-free 기법입니다.
Introduction
6D Pose Estimation은 reference와 camera 좌표계 간의 rigid 6D transformation을 결정하는 문제로, 컴퓨터 비전과 로보틱스 분야에서 매우 중요한 task라고 할 수 있을 것 같습니다. Instance-level의 6D pose estimation의 경우 RGB 텍스처가 포함된 CAD 모델에 의존하기 때문에 학습 시 본 객체에만 적용 가능하다는 한계를 갖습니다. 따라서 대부분의 모델들은 로봇 매니퓰레이션과 같은 환경에서, 새로운 환경에 갑작스럽게 등장한 객체에 대해 3D 모델이나 멀티뷰 이미지를 확보하기 어렵다면 포즈 추정이 사실상 불가능합니다.
이러한 한계를 해결하기 위해 Oryon은 단일 RGB-D 이미지를 활용하는 새로운 model-free 6D pose estimation을 제안했다고 합니다. Oryon은 언어 정보를 활용해 대상 이미지와 대응점을 설정하고, 가시 영역의 포인트 클라우드를 정렬하여 포즈를 계산합니다. 그러나 이 방식은 occlusion이 심하거나, 텍스처가 부족한 경우 매칭 포인트 수가 줄어들면서 성능이 크게 저하됩니다. 이는 manipulator의 조작 환경에서는 특히 두드러진다고 합니다.

저자들의 Any6D는 이러한 한계를 극복하기 위해 단일 RGB-D 앵커 이미지만을 사용하는 model-free방법에 Image-to-3D를 추가했다고 합니다. 기존 3D 생성 모델들이 정규화된 공간에서 입력 이미지와 생성된 3D 형상 간의 광학적 일관성을 높이는 데 성공했지만, 2D-3D 정렬과 메트릭 스케일이라는 6D pose estimation의 핵심 요소를 고려하지 않았고, 저자들은 이를 고려해 2D와 3D 공간에서 동시에 객체의 크기와 포즈를 맞추는 방법을 제안했스빈다. 저자들의 contribution은 다음과 같습니다. 그 결과 5개의 벤치마크 데이터셋에서 기존의 SOTA 방법들을 뛰어넘는 결과를 볼 수 있었다고 합니다.
Methods
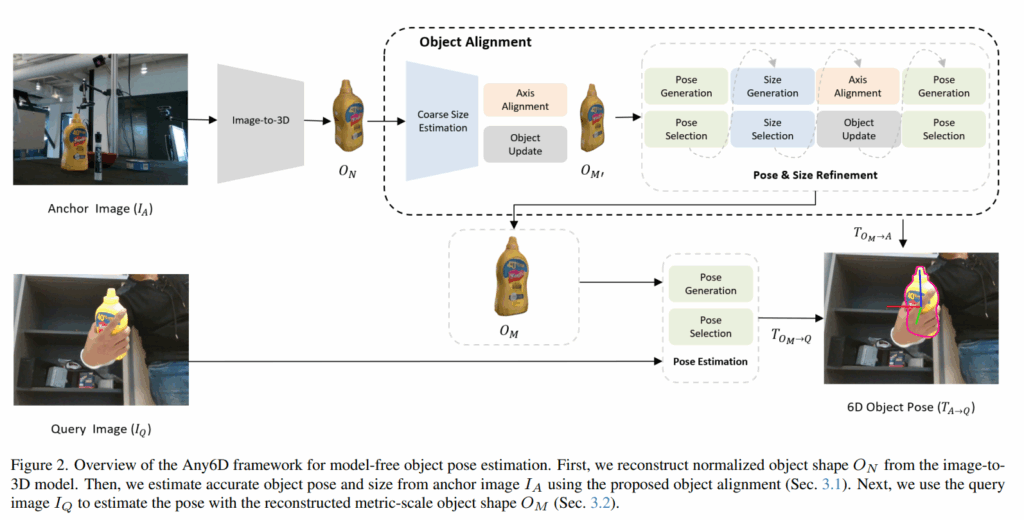
Any6D는 RGB-D 앵커 이미지(I_A)와 RGB-D 쿼리 이미지(I_Q)가 주어졌을 때, 두 이미지 간의 상대적인 6D pose를 추정합니다. 앵커 이미지에서 쿼리 이미지로의 T_A→Q는 회전 행렬 R ∈ SO(3)과 평행이동 벡터 t ∈ R³로 구성됩니다. 기존 방법들은 주로 RGB 이미지의 가시적인 부분이나 pointcloud의 가시적인 부분을 이용하는 partial-to-partial 매칭을 활용했습니다. 가시적인 부분만 활용하는 방법들은 occlusion이나 큰 시점 차이가 존재하는 경우에는 partial-to-partial이 실패하게 됩니다. 이 문제를 해결하기 위해 저자들은full-to-partial 매칭을 채택했습니다. 앵커 이미지에서 객체의 완전한 3D 형상을 복원한 후 이를 기반으로 정합을 수행해서 겹치는 시야가 거의 없는 상황에서도 대응점 매칭을 가능하도록 했습니다. 이후, 정확한 포즈 추정을 위해 render-and-compare 파이프라인(FoundationPose -> 승현님이 리뷰해주셨습니다!!)을 활용했습니다. 프레임워크는 크게 metric scale의 객체 형상을 복원하고 coarse object alignment (O_M’)를 진행하고, 이후 복원한 객체를 통해 fine object alignment(O_M)후 이를 활용해 6D Pose Estimation을 진행합니다.
Coarse Object Alignment
우선 RGB-D 단일 뷰에서 객체를metric scale로 복원할 수 있는 방법은 존재하지 않습니다. 따라서 저자들은 최근 발전한 RGB 기반의 image to 3D 방법들 중 다양한 객체에서 우수한 성능을 보인 InstantMesh를 바탕으로 객체를 metric scale로 복원했다고 합니다. InstantMesh로 복원한 3D 객체 형상은 [-1, 1] 범위의 정규화된 스케일을 갖는 형태를 출력합니다. 따라서 실제 장면 내의 scale이나 위치가 반영되지 않아 pose 정합에 직접적으로 사용할 수 없습니다 (크기가 다르기 때문입니다). 이를 해결하기 위해 저자들은 먼저 객체의 크기를 대략적으로 추정한 뒤 앵커 이미지 (I_A)와 정규화된 3D Mesh (O_N) 간의 3D, 2D 정렬을 수행합니다.
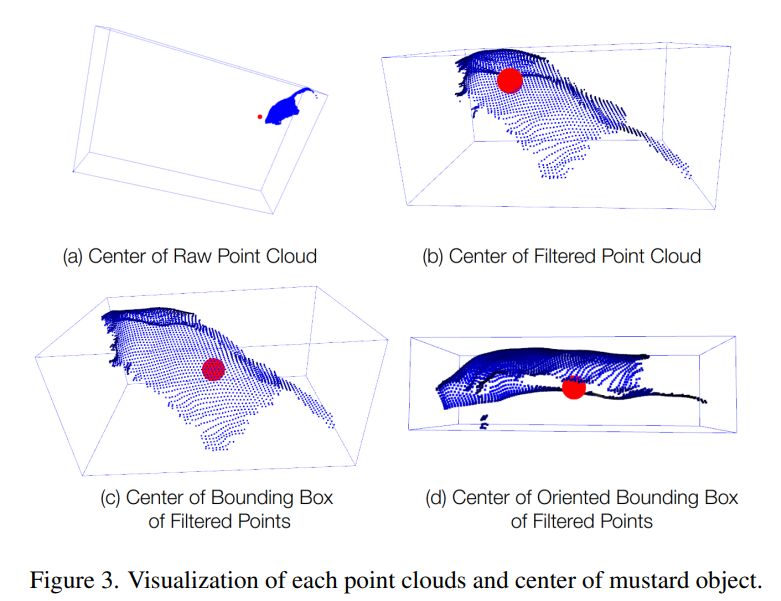
먼저, I_A와 O_N 각각의 객체 중심을 기준으로 pointcloud를 비교해 대략적인 크기를 설정합니다. 이때 중심을 단순히 포인트들의 평균을 이용해 설정했을 때는 partial viewpoint와 앵커 이미지의 outlier 때문에 신뢰성이 떨어집니다. 위의 Figure 3를 보시면서 이해하시면 편할 것 같습니다. Figure 2의 머스타드 병을 기준으로 생각하시면 됩니다. Axis-aligned bounding box를 사용하는 방법 또한 가시적인 범위가 적을 경우 부정확한 결과를 얻을 수 있다고 합니다. 이를 해결하기 위해, 저자들은 oriented bounding box를 이용하여 앵커 이미지의 객체 중심을 계산합니다(Fig.3 – (d)). 이렇게 얻은 중심을 위해 이 bounding box를 XYZ 축과 맞춥니다. 이후 다양한 회전 각도를 샘플링하고, 각 회전 상태에서 IA와 ON의 bounding box 간 IoU를 계산합니다. IoU가 가장 높은 회전·스케일 조합을 선택하여 O_N을 변환함으로써 O_M′(Coarse Alignment된 객체)을 얻고, 이를 기반으로 이후의 정확한 scale과 pose를 추정합니다.
Fine Object Alignment
O_M’을 복원한 뒤에는 O_M′을 기반으로Object & Size Refinement 절차를 수행해서 앵커 이미지와 비교했을 때 metric scale의 size와 pose가 같은 3D 객체 O_M을 구합니다. 이 과정에 Foundation Pose를 활용합니다. 저자들은 FoundationPose에 크기 추정 작업을 pose refinement과정에 통합한 Joint Module을 추가해 pose를 추정하는 과정에 scale을 포함시켰습니다.
Refinement 파이프라인은 크게 pose estimation, size estimation, axis alignment의 세 모듈로 구성되며, 크기 , 포즈를 번갈아가며 refine하는 방식으로 작동하빈다. 먼저 O_M′을 이용해 초기 pose를 추정하는 동시에 객체 크기를 refine합니다. 기존 FoundationPose는 pose hypothesis 생성 시 SO(3) 회전 공간을 샘플링했는데, 여기에 size에 대한 샘플링을 추가한 것입니다. 크기 샘플은 각 축에 대해 [0.6, 1.4] 범위에서 균등하게 추출하며, 회전 샘플링과 함께 조합하여 다양한 포즈-크기 가설을 생성합니다. 범위는 경험적으로 구했다고 합니다. 각 hypothesis는 FoundationPose의 정제 모듈을 이용해 포즈를 개선한 뒤, 쿼리 이미지와 비교하기 위해 렌더링됩니다. 이후 pose 선택 모듈을 통해 가장 score가 높은 최적의 hypothesis를 선택합니다. Pose selection 단계에서는 render-and-compare 방법을 사용합니다. 먼저 pose ranking 네트워크가 각 hypothesis의 렌더링 뷰와cropped 이미지를 비교해 정합된 정도를 수치화하는 임베딩을 생성합니다. 이후, 모든 hypothesis의 임베딩을 concat하여 self attention을 적용하고, 전역 컨텍스트를 반영한 최종 점수를 산출해 최적 포즈를 선택합니다. 해당 방법은 크기와 포즈를 동시에 추정하는 Joint 방식이기 때문에, 기존 IoU 기반 정렬보다 더 높은 정확도를 제공한다고 합니다. 정리하자면 O_M과 I_A, O_M과 I_Q를 이용해 T_A->Q를 구해줍니다.
Experiments
저자들은 Model-free 방법들과 REAL275, Toyota-Light, HO3D, YCBInEOAT, LM-O 5개의 공개 데이터셋에서 평가를 진행했습니다. 모두 시점차이, 조명변화, occlusion을 포함하는 데이터셋이라고 합니다. HO3D의 경우 사람 손과 물체가 상호작용하는 데이터셋이고, DexYCB 데이터셋에서 같은 물체가 있는 데이터를 샘플링 해서 활용했다고 합니다. YCBInEOTA는 dual arm robot manipulation 상황을 담은 데이터셋입니다. 세부적으로는 single arm pick and place, hand manipulation등도 포함되어 있다고 하네요. 저자들은 해당 데이터셋 내의 다양한 이미지로부터 대응하는 이미지들을 DexYCB에서 매칭해서 실험을 진행했다고 합니다. Toyota-Light의 경우 조명 변화가 심한 데이터셋, REAL275은 다양한 viewpoint에서 제한된 시야와 occlusion 상태가 포함된 데이터셋이라고 합니다. LM-O는 clutter한 환경에서 textureless한 물체들로 구성되어있다고 합니다. Metric의 경우 ADD, ADD-S와 AR(BOP challenge의 평가지표)를 사용했습니다.
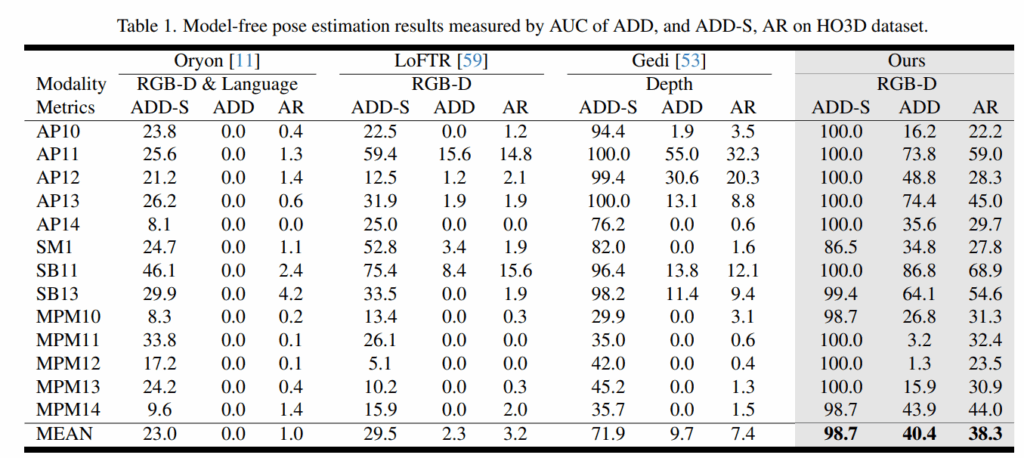
Table1은 HO3D에서 평가한 성능ㅇ입니다. 기존의 방법론들 대비 제한적인 input을 통해서 거의 수행하지 못 하던 사람 손과의 interaction occlusion의 6D Pose Estimation이 가능함을 어필하고 있습니다.
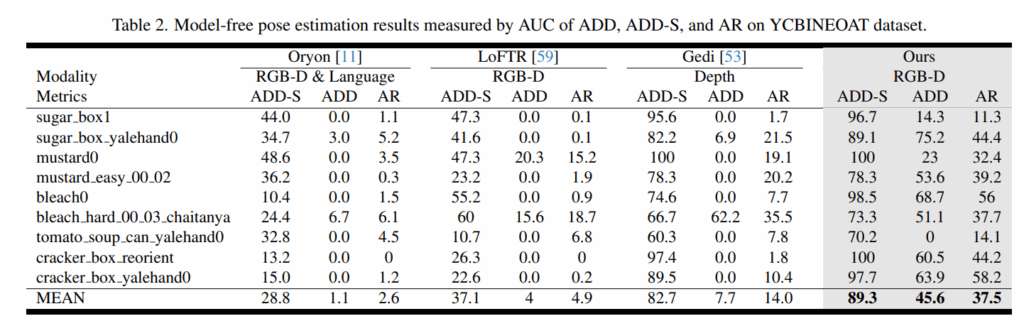
Table 2는 YCBInEOAT 데이터셋으로 평가한 것인데 ADD 메트릭에서 성능이 좋아진 점이 non overlapping viewpoint에서 저자들의 방법이 얼마나 정밀한지를 어필합니다. Table 1과 2를 통해 real world robotic application에서 활용성이 좋은 것을 어필합니다.
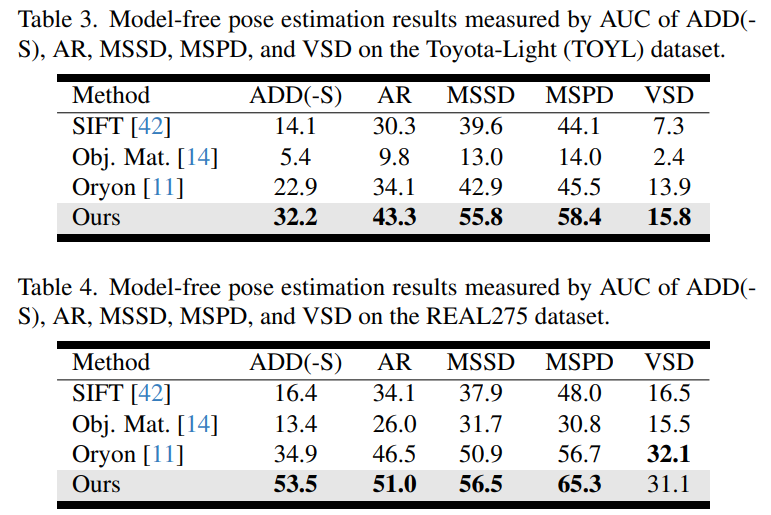
Toyota Light (조명이 강한 영상)과 REAL275 데이터셋에서도 기존의 방법들을 능가하는 모습을 보이며 다양한 lighting scenario와 real world 환경에서도 강건함을 어필했습니다.
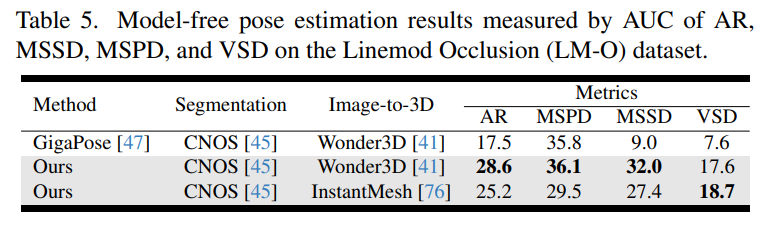
마지막으로 LM-O에서는 GigaPose와 비교했는데, 공정성을 위해 Segmentation과 Image to 3D 과정 (pose 추정 전단계)를 GigaPose의 방법을 그대로 사용해서도 비교했다고 합니다. 다양한 데이터셋에서 큰 성능차이를 보이며 저자들의 방법이 real world application에서의 믿을만한 방법임을 어필했습니다.

정성적인 결과를 봐도 GT와 거의 유사한 모습을 볼 수 있습니다. 자세히 보자면 첫 번째 예시는 white cleanser 객체로, 앵커 이미지에는 객체의 일부만 보이며 쿼리 이미지는 전혀 다른 시점에서 촬영되었습니다. 기존 방법들은 앵커 이미지에서의 핵심 부분들이 가려진 상황을 처리하지 못한 반면, Any6D는 정확한 포즈를 추정하는 모습을 볼 수 있습니다. 두 번째 예시는 SPAM 캔입니다. 앵커 이미지에는 뒷면만 보이고, 쿼리 이미지는 손에 의해 부분적으로 가려진 로고 면이 보이는 조건입니다. 이처럼 앵커 정보가 제한적이고 가림이 있는 상황에서도 Any6D가 더 강건하게 동작합니다. 세 번째 예시는 blue pitcher입니다. Gedi는 중심 위치를 대략 맞췄지만 회전 방향은 크게 틀린 반면 Any6D는 회전 정도까지 정확하게 추정했습니다.
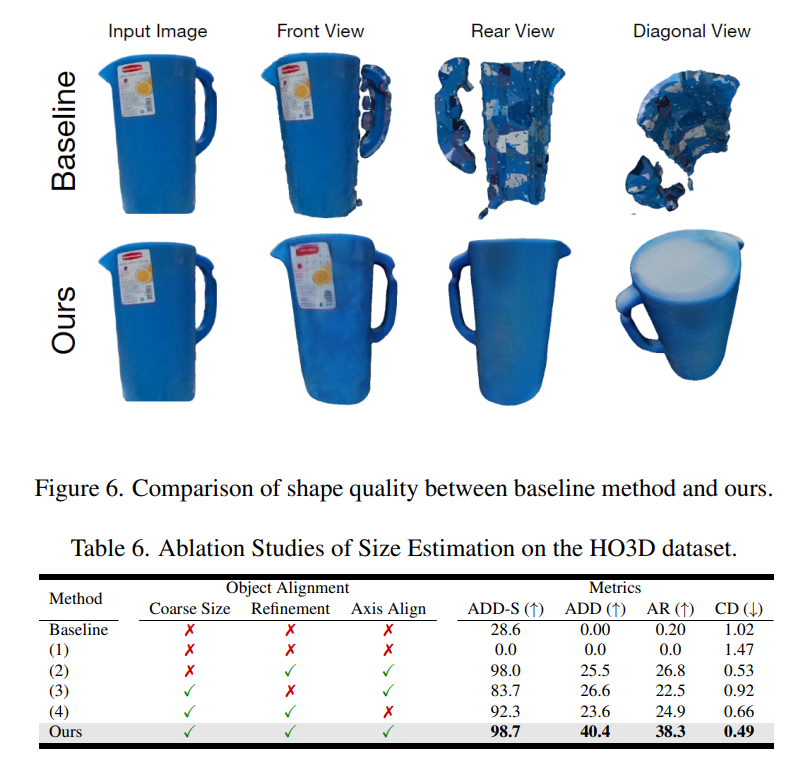
Ablation입니다. Baseline을 object centric한 NeRF를 훈련시켜 Marching Cube알고리즘을 통해 얻은 메시로 설정하고 비교했다고 합니다. Image to 3D의 경우 완전한 형상을 예측하기 때문에 당연하지만 CD도 훨씬 좋은 결과를 볼 수 있습니다. 이후 coarse한 size 정렬, axis alignment를 통해 개선되는 점도 보였습니다.
Conclusion
저자들은 해당 방법이 image to 3D에 의존하기 때문에 image to 3D가 잘 이루어지지 않는 불완전한 shape인 경우에는 성능이 크게 떨어진다고 합니다. 따라서 추후 연구 방향도 shape refinement를 통해 더 robustness를 강화하는 방향으로 진행해야 한다고 말합니다. 어찌됐건 occlusion이 있는 상황에서는 image to 3D를 사용하는 쪽으로 가는게 맞는것 같다는 생각을 더 하게됐습니다.
안녕하세요, 좋은 리뷰 감사합니다.
RGB-D 단일 뷰에서 물체의 metric scale을 복원할 수 있는 방법이 없어서 InstantMesh를 이용하여 복원하였다고 설명해주셨는데요, 그럼 InstantMesh는 어떤 방식으로 복원하게 되는건가요 ? 제가 image to 3D의 컨셉은 알지만 정확한 과정을 몰라서 조금만 더 자세하게 설명해주시면 감사하겠습니다. 활용 가능한 데이터는 동일할텐데 어떤 차이점이 있어서 복원이 가능한 지 궁금하네요 . . .
안녕하세요 건화님 댓글 감사합니다.
제가 설명을 부정확하게 한 것 같습니다. 단일 RGB 이미지를 통해 3D mesh를 만들어내는 image to 3D모델을 파이프라인에 사용하는데, image to 3D 모델들은 normalized scale로 메시를 만들어내기 때문에 결과물에 후처리를 해줍니다.
이 때 후처리하는 방식이 RGB-D를 통해 얻은 pointcloud 와 coarse하게 계산한 뒤에 fine alignment 단계에서 추가로 맞춰줍니다. foundationpose 기반의 refinement에 scale을 추가해서 Hypothesis들을 구성할 때 [0.6, 1.4] 구간의 scale 값도 같이 샘플링 해서 구성합니다.