안녕하세요, 74번째 x-review 입니다. 이번 논문은 2025년 arXiv에 올라와 있는 논문이긴 하지만, 도메인이 다른 데이터 사이에 distillation 하는 방식이 참고해볼만 하여 읽어본 논문 입니다.
그럼 바로 리뷰 시작하겠습니다

1. Introduction
MDE는 크게 supervised 방식과 self supervised 방식으로 나눌 수 있는데, 전자는 성능은 좋지만 GT 데이터를 구성하는데 많은 cost가 발생합니다. 반면에 self supervised 방식은 하나의 카메라로 촬영한 연속적인 이미지 시퀀스와 카메라 파라미터만을 이용해서 연속적인 프레임 간의 기하학적으로 일관성을 가진다는 가정 하에 수행하게 됩니다. 기존의 SSL 방식은 많은 개선을 보였지만 저조도나 안개와 같은 조건에서는 성능이 저하되는 결과를 보입니다. 이는 저조도에서는 조명이 부족하고 비가 오면 도로가 반사되는 듯 왜곡이 발생하기 때문인데요, 한 연구 갈래로 이런 특정 scene에서의 성능을 높이기 위한 연구도 진행되고 있었습니다. 그러나 이렇게 한 장면에 특화된 방식들은 real 환경으로 갔을 때 복잡한 scene이 들어오면 일반화가 이루어지지 않게 됩니다. 그래서 기존 연구에서는 distillation이나 contrastive learning 등을 합쳐서 다양한 장면에 대해 일반화된 모델을 만들기 위한 모델들이 존재합니다.

가령 Fig.1에서 보이는 것처럼 md4all이라는 방법론은 GAN 모델을 이용해서 [정상, 이상] 샘플 쌍을 생성하고 student 모델을 학습시키기도 합니다. 그러나 생성된 이미지가 조금 비현실적이고 부자연스러워서 정상 상황에서 이상 환경으로의 전달이 어려워 일반화 성능에 큰 영향을 미치게 됩니다. 또한 Fig.1(b)에서 보이는 것처럼 md4all은 scene 간의 차이가 클 경우에 성능이 크게 저하되어서 다양한 이상 환경 시나리오에 사용하는 것에 한계가 존재합니다.
이러한 기존 연구의 한계를 본 논문에서는 크게 두 가지로 정의합니다.
먼저 다양한 이상 환경을 포함하는 높은 퀄리티의 데이터셋이 부족하고, 두번째는 teacher/student 모델 사이의 제약이 분명하지 않아서 지식을 전달하는 것이 불완전하다는 점 입니다.
이 두 문제를 해결하기 위해 저자는 데이터 생성과 domain adaptation 학습을 제안하면서 이상 환경에 agnostic한 성능을 보일 수 있는 ACDepth라는 방법론을 제안합니다.
구체적으로 diffusion 모델의 표현력을 활용하면서 변환된 이미지의 자연스러움과 일관성을 유지하기 위해 consistency loss와 adversarial 학습 방식을 설계하였습니다. 또한 teacher 모델로부터 완전하게 지식을 전달 받고 alignment를 맞출 수 있도록 multi granularity knowledge distillation(MKD) 방식을 제안하고 더불어 ordinal guidance distillation(OGD)라는 알고리즘을 새롭게 제안하게 됩니다.
이러한 본 논문의 main contribution을 정리하면 다음과 같습니다.
- 다양한 이상 환경을 고려한 데이터셋 생성 방식을 제안하고 그 데이터셋을 활용한 MDE 프레임워크인 ACDepth 제안
- teacher 모델의 능력을 향상시키는 MKD 방식과 불확실한 영역에 더 초점을 맞출 수 있는 OGD 알고리즘 제안
- nuScenes 데이터셋에서 이상 환경에 대해 이전 연구들 대비 향상된 성능 달성
2. Method
2.1. Overall Architecture
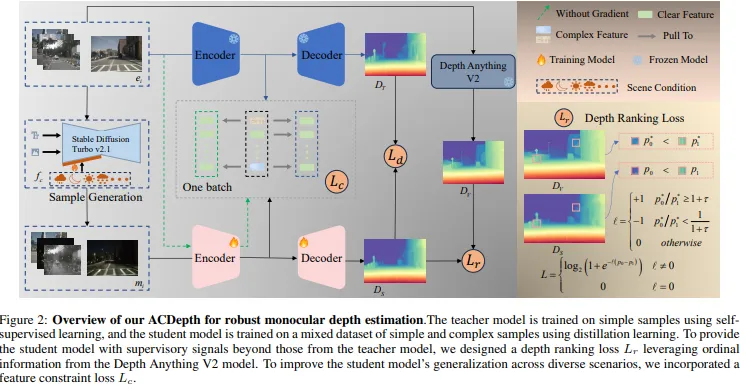
먼저 전체적인 구조를 먼저 살펴보겠습니다.
본 논문의 목표는 일반적인 환경 뿐만 아니라 비, 저조도, 안개와 같은 이상 환경에서도 정확한 MDE가 가능하도록 하는 것 입니다.
이를 위해 먼저 데이터를 생성한다고 하였습니다. Fig.2의 왼쪽에서 보이시는 것처럼 사전학습된 diffusion 모델을 LoRA adapter를 사용해서 다양한 이상 환경에 대한 이미지를 생성해줍니다. 이 때 자연스러운 이미지를 위해 circular consistency loss와 adversarial 학습을 사용하게 되는 것 입니다.
두번째로 생성한 이 데이터들을 이용해서 student 모델의 지식을 가지고 MKD를 통해 student 모델을 최적화합니다. 이 때의 loss 함수는 다음과 같이 정의합니다.
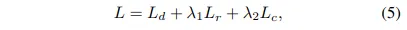
L_d는 기본적인 knowledge distillation loss로, 두 모델이 출력하는 depth map을 가지고 차이를 계산하게 됩니다. 그 다음 L_r은 OGD loss로, Depth Anything v2 모델이 제공하는 depth 정보를 가지고, 예측이 어려운 영역에 집중해서 학습을 할 수 있도록 합니다. 마지막으로 L_c는 일관성을 위한 loss로, 두 모델의 중간 feature map이 유사하도록 만들기 위한 loss 함수 입니다. 결국 최종 예측 뿐만 아니라 내부적인 표현력까지 student가 잘 따라가도록 유도하는 loss라고 할 수 있습니다.
2.2. Data Generation
이제 데이터 생성부터 자세하게 보도록 하겠습니다.
정상 상황에 대한 입력 이미지 e_i가 있으면 이를 통해 만들어지는 이상 상황 이미지는 h^c_i로 정의합니다. 이 때 c는 특정 이상 상황 조건(비, 저조도, 연기)을 나타냅니다.
그러나 기존에도 이렇게 생성하는 연구들이 있었지만 기본적으로 기본 diffusion 모델을 다시 학습했었기 때문에 많은 [정상, 이상] 이미지를 필요로 했습니다. 또한 그렇게 만들어지는 이미지들은 비현실적이고 부자연스러운 이미지들이 많았었다고 합니다.
그래서 본 논문에서는 LoRA를 이용해서 기존 diffusion 모델을 빠르게 finetuning 하는데, 특히 조건에 따라서 각 이상 환경 조건마다 전용 LoRA를 학습시켜서 이미지 변환에 있어서 정확도를 높일 수 도록 하였습니다. 여기에 추가적으로 adversarial 학습과 consistency loss를 적용하는데, 생성된 이미지가 실제적으로 보이면서 원래 이미지의 구조적인 표현은 모두 유지될 수 있도록 학습하였습니다.
이러한 과정을 식으로 표현하면 식(6)과 같습니다.
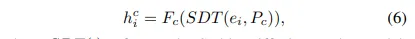
- SDT : stable diffusion turbo
- F_c : 생성된 이미지를 후처리하는 모듈 (translator 역할)
정리하면 정상 이미지와 텍스트 조건 P_c(비 오는 날의 사진)을 넣으면 조건에 맞는 이상 환경을 포함한 자연스러운 이미지를 생성할 수 있게 됩니다.
2.3. Robust Model Training
데이터를 생성하였으니 이제 이 데이터를 가지고 모델을 어떻게 학습시켰는 지에 대해 살펴보도록 하겠습니다.
Distillation Learning
teacher 모델과 student 모델을 비교할 때 일반적으로 하는 최종 출력 결과 뿐만 아니라 다중 스케일의 feature까지 비교를 하게 됩니다.
두 모델이 하나의 동일한 이미지를 볼 때 중간 feature map이 얼마나 유사한 지를 비교하는데, 이에 대한 loss 함수를 식(7)과 같이 정의할 수 있습니다.
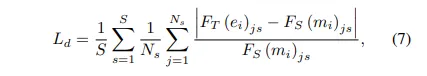
- S : feature 스케일
- N_s : 해당 스케일의 feature 채널 수
- F_T(e_i) : teacher 모델의 중간 출력 feature
- F_S(m_i) : student 모델의 중간 출력 feature
직관적으로 봤을 때와 동일하게 단순히 같은 이미지에 대해 student가 teacher의 중간 feature map을 보고 비슷하게 따라가도록 학습을 유도하게 됩니다.
단순하게 출력만 따라하는게 아니라 이렇게 중간 표현까지 따라가도록 하면 더 정확하게 distillation이 가능하도록 합니다. 특히 이렇게 이상 환경에서는 feature 표현이 중간부터 흔들릴 수 있는데 이런 다중 스케일의 distillation을 하면 모델이 그런 복잡한 조건에서도 일관된 표현을 갖도록 도와줄 수 있다고 합니다.
Ordinal Guidance Distillation
다음은 student 모델이 예측하기 어려워하는 구간에서 더 잘 학습할 수 있도록 하는 OGD에 대한 부분 입니다. teacher 모델을 따라간다고는 하지만 teacher 역시도 어두운 곳이나 복잡한 환경에서는 정확하지 못할 수가 있는데요, 그래서 본 논문에서는 DA V2를 추가적으로 활용해서 불확실한 영역에 더 집중해서 학습하는 OGD를 제안합니다.
가장 먼저 그럼 모델이 어려워하는, 불확실한 영역에 대한 정의가 필요한데, 이는 식(8)과 같이 정의합니다.
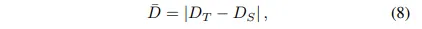
- D_T : teacher 모델이 예측한 depth
- D_S : student 모델이 예측한 depth
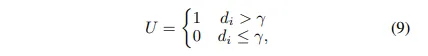
두 depth의 차이를 계산한 불일치 정도에서 상위 5% 영역만을 불확실한 영역으로 식(9)와 같이 U로 정의를 합니다. 즉 teacher와 student의 예측이 큰 차이를 보이는 곳을 집중적으로 학습의 대상으로 설정하는 것 입니다.
그럼 이 영역을 가지고 depth의 순서를 학습을 하게 되는데요, 먼저 불확실한 영역에서 픽셀을 하나 선택을 합니다. 그리고 확실하다고 여겨지는 영역에서 픽셀을 하나 또 선택을 해서 과연 이 두 픽셀에서 누가 더 가깝고 먼지에 대한 상대적인 depth 순서를 예측을 하는 것 입니다.
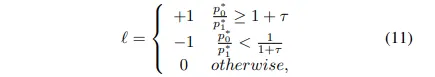
- p_0 : 불확실한 영역에서 선택한 픽셀
- p_1 : 확실한 영역에서 선택한 픽셀
- p^_0, p^_1 : DA V2에서의 불확실/확실한 영역에 대한 픽셀
순서를 판단하는 방법의 기준은 DA V2의 출력D_v 입니다.
DA V2의 출력 값을 기준으로 둘의 비율에 따라서 식(11)과 같이 순서를 정의할 수 있습니다.
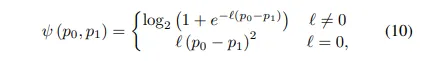
저 순서 라벨 l을 기준으로 식(10)과 같이 loss를 계산하게 됩니다.
여기에 추가적으로 과적합을 막기 위해서 주변 5×5 픽셀 영역의 평균 depth 값을 대신 사용해서 더 부드러우면서 안정적인 계산이 될 수 있도록 하였습니다. 또한 한 번에 선택하는 포인트의 수를 제한하는데, U에서 5%를 선택하고 전체에서 랜덤으로 1%를 선택해서 글로벌한 정보를 잃지 않도록 보완하였다고 합니다.
이러한 최종 loss를 정리하면 식(12)와 같습니다.
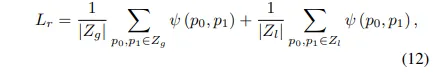
- Z_g : 글로벌 영역에 대한 랜덤 샘플
- Z_l : 불확실한 영역에서 고른 샘플
Feature Consistency Constraint
FCC는 이상 환경 이미지에서도 정상 이미지에서와 유사한 의미를 가진 표현력을 가질 수 있도록 모델을 학습하는 것 입니다.
FCC는 입력 이미지가 정상인지, 이상 상황 이미지인지에 따라 처리하는 방식이 달라지게 됩니다.
먼저 입력 e_i가 이상 상황 이미지일 경우에 두 가지를 동시에 비교하면서 학습을 합니다.
F_s(h)와 F_T(e)를 비교하면서. student 모델이 이상상황 이미지를 처리할 때 추출하는 feature와 teacher 모델이 정상 이미지에 대해 처리하는 feature를 가지고 이상 상황에서도 정상처럼 잘 인식하도록 할 수 있습니다. 또한 F_S(h)와 F_S(e)를 비교하면서, student 모델이 같은 이미지의 정상과 이상 이미지를 각각 봤을 때의 feature를 서로 비교를 합니다. 즉 student 모델이 스스로 일관된 feautre를 뽑을 수 있도록 하는 것 입니다.
반면 만약 이미지가 정상 이미지일 경우에는 단순하게 teacher와 student의 feature만 비교해서 같은 정상 이미지를 보고 feature가 일치할 수 있도록 유도하게 됩니다.
이러한 FCC에 대한 loss는 식(13)과 같습니다.
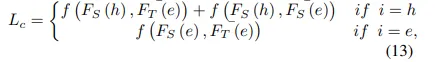
이렇게 FCC를 통해서 student 모델이 정상 뿐만 아니라 이상 환경에서까지도 일관되게 의미있는 feature를 추출할 수 있도록 학습함으로써 성능 뿐만 아니라 일반화에 대한 능력까지도 향상시켰다고 합니다.
3. Experiments
실험은 nuScenes와 Robotcar라는 데이터셋에서 진행하였습니다.
3.1. Comparison with SoTAs
Comparison on the nuScenes
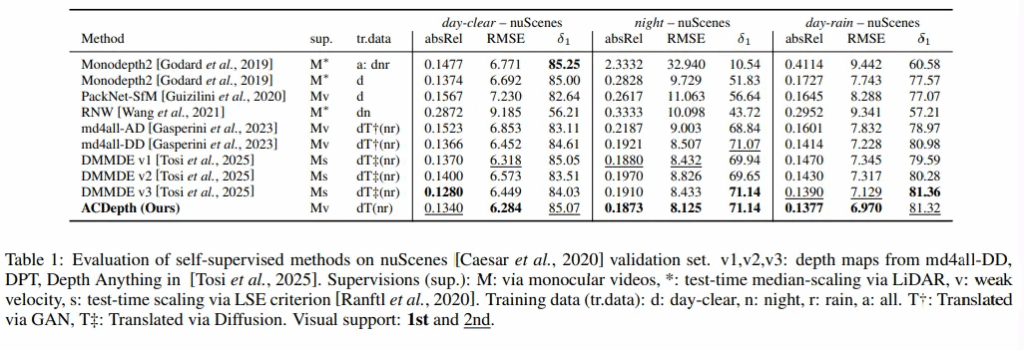
먼저 Tab.1은 nuScenes에 대한 실험 결과로, 이전의 MDE 연구들인 Monodepth2, PackNet-SfM과 인트로에서도 비교하였던 md4all 등에 대해 비교 실험을 진행하였습니다.
실험 결과, 본 논문의 방법론이 night scene에서 특히 모든 평가 지표에 대해 SOTA를 달성한 것을 확인할 수 있습니다. night 뿐만 아니라 비가 오는 scene에 대해서도 마찬가지로 오차 평가 메트릭에서 모두 좋은 성능을 보이고 있습니다.
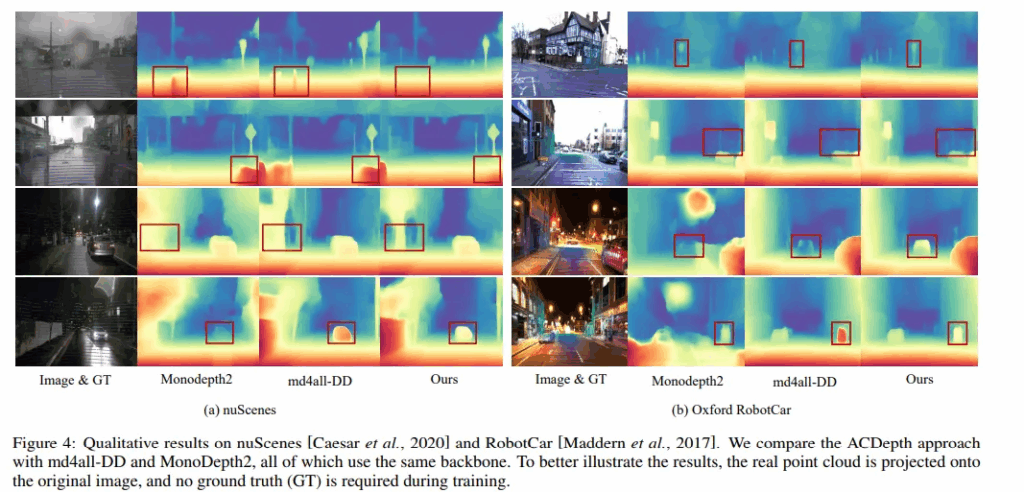
정성적으로 확인해보면 md4all-DD는 비 오는 장면에서 반사에 매우 민감하게 반응하고 night 장면에서도 어두운 영역에 속하는 부분의 depth를 잘 예측하지 못하고 있습니다. 반면에 ACDepth는 나무나 자동차처럼 조도 환경이 낮은 공간에 놓인 물체들에 대해서도 명확하게 표현하는 것을 확인할 수 있습니다.
Comparison on the Robotcar
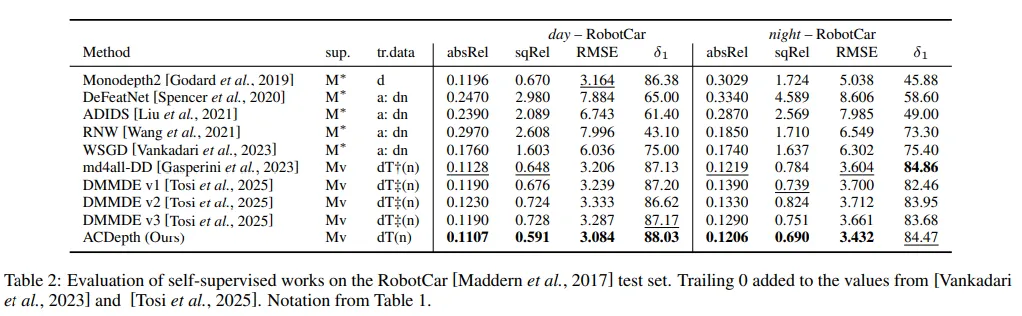
다음은 Robotcar라는 데이터에 대한 실험 결과로, 거의 모든 지표에서 SOTA를 달성하고 있습니다.
특히 md4all-DD와 비교해서 RMSE가 약 8.80% 개선되었고, 낮과 밤 장면 모두에서 더 정확한 depth map을 생성한다는 것을 실험적으로 확인할 수 있습니다.
이러한 성능 향상을 통해 저자는 신뢰할 수 있는 데이터를 생성하였고, 생성한 데이터를 기반으로 teacher와 student 모델 사이에 지식을 잘 전달함으로써 강인한 모델의 성능을 확보할 수 있었다고 이야기하고 있습니다.
3.2. Ablation Study
Evaluation on Major Design Components
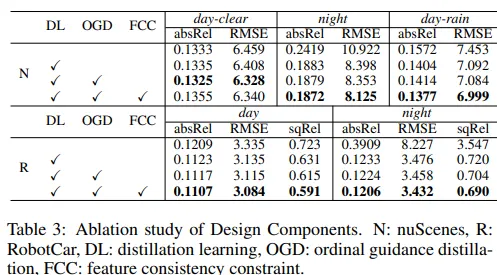

마지막 ablation study로, Tab.3은 distillation 방식에 대한 실험 결과 입니다.
먼저 낮 장면에서 학습된 베이스 모델에 distilation 학습 방식 자체를 추가하였을 때 night와 rain과 같이 이상 환경에 대한 데이터에서 성능이 향상되는 것을 확인할 수 있습니다.
그 다음 OGD를 추가하면 이상 환경 조건에 대해서 더 정확하게 시그널을 제공할 수 있게 되어 Robotcar 데이터에서는 밤 장면 뿐만 아니라 낮 장면에서도 성능이 개선되는 것을 알 수 있습니다.
마지막으로 FCC까지 추가하였을 때 이상 환경에서의 정확도가 크게 향상되며 제안하는 모듈 각각이 신뢰할 만한 시그널을 제공할 수 있을 뿐만 아니라, 불확실한 영역에 확실하게 집중하도록 유도하면서 정확한 depth 추정이 가능하도록 하고 있습니다.
안녕하세요. 리뷰 잘 읽었습니다.
Distillation Learning파트에서 중간 출력을 활용해서 loss를 설계하는 모습을 보이는데,
이게 그럼 출력이 아니라 feature map만으로 loss를 설계하는건가요? 출력이라면 생각했을 때 중간 feature map으로 예측을 하는건지 했는데, feature map만으로 distillation을 했단 점이 새로워보여 질문 남깁니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
말씀하신대로 이 논문은 최종 출력이 아니라 중간 feature map만으로 distillation loss를 설계하는게 맞습니다. 중간 feature로 최종 depth를 예측하는 것처럼 depth map을 뽑는 건 아니고 feature 사이의 차이를 줄이는 방식으로 설계되어 있습니다.
감사합니다.
안녕하세요 건화님 리뷰 감사합니다.
Feature Consistency Constraint 과정에서, 모델이 정상 환경 이미지와 이상 환경 이미지를 구분하여 서로 다른 feature 비교 전략을 적용한다는 것은 이해가 됐는데 구체적으로 모델이 입력 이미지가 정상인지 이상 환경인지 어떻게 판별하는지 이해가 잘 되지 않아서 혹시 조금만 풀어서 설명해주실 수 있을까요??
안녕하세요, 리뷰 읽어주셔서 감사합니다.
정상인지 이상인지에 대해서 판별하는건 모델이 자동적으로 학습을 한다던가 판별하는게 아니라, 학습 데이터를 구성할 때 명시적으로 구분이 되어있는 상태 입니다. 입력 이미지가 들어갈 때 정상 이미지인지 이상 상황이 포함된 이미지인지에 대해서는 이미 알고 있는 상태로, 알고 있는 정보에 따라서 alignment 맞춰지는 요소가 달라지는 것 입니다.
감사합니다.
안녕요. 리뷰 잘 읽었습니다.
Teacher model을 distillation하는 것에 관심이 있으신 것 같아서 비슷한 논문 하나 추천드립니다.
https://arxiv.org/pdf/2211.03660
위 논문은 dynamic object를 잘 학습하지 못하는 self-sup monodepth 방법론을 개선하기 위해서 지금 리뷰해주신 논문과 마찬가지로 depth order ranking loss를 활용하는데 지금 논문도 그렇고 위에 추천드리는 논문도 그렇고 depth order를 활용하는 논문들은 어떤 지점들을 ranking loss 계산을 위해 뽑을 것인가?가 contribution으로 중요하게 동작하는 것 같습니다.
추천드리는 논문에서는 dynamic object에 관심이 많기 때문에 dynamic object를 위주로 depth ranking loss 계산을 계산하고 global한 부분도 적당히 챙겼다고 하네요. 코드도 공개되어있으니 참고하세유.
안녕하세요 정민님
관련된 논문 추천해주셔서 감사합니다.
추천해주신 논문도 컨셉이 비슷해 보이는데 꼭 읽어도록 하겠습니다 👍👍👍👍👍
안녕하세요, 좋은 리뷰 감사합니다.
모델이 어려워하는 영역을 더 집중적으로 학습하기 위해 OGD를 설계하였다고 이해하였는데, 이 때 비교하는 확실한 영역의 픽셀은 하나만 선택을 하게 되나요 ? 뭔가 depth 사이의 관계를 파악하기 위해서는 불확실한 영역의 픽셀 하나 당 여러 영역에 대한 픽셀을 정보로 주어 상대적인 depth를 예측하는 것이 더 좋지 않나 생각이 드는데, 이에 대한 실험이나 언급은 없었는지도 궁금합니다.
감사합니다 !
안녕하세요, 리뷰 읽어주셔서 감사합니다.
본 논문에서는 불확실한 영역과 비교적 확실한 영역에 대해 1대1 쌍으로 구성하고 있습니다.
말슴하신 것처럼 여러 픽셀의 위치를 비교로 하는게 더 좋을 수도 있겠지만 우선 이 논문에서는 그런 세팅에 대한 실험이나 언급은 딱히 없었습니다.
감사합니다.