오늘 소개드릴 논문은 비디오 요약과 관련된 문제를 새롭게 정의 하고 데이터셋을 구축한 논문입니다. 테스크 명은 Video Repurposing 인데요, 본문에서 소개를 해보겠습니다.
(Q)인스타그램, 틱톡, 유튜브 쇼츠등 비디오 플랫폼의 증가와 AI 기술에 대한 기대감이 맞물리면 어떤 수요가 증가할까요?
(A)비디오 데이터셋을 효율적으로 다루기 위한 다양한 기술을 기대하게 될 것입니다. 앞서 소개해드렸던 비디오 요약도 이러한 수요 기술 중 하나일 것입니다. 문제는 비디오 요약 기술이 현재 산업계의 수요와 완벽하게 맞지 않는다는 점입니다.
Intro: Why is video summarization not enough?
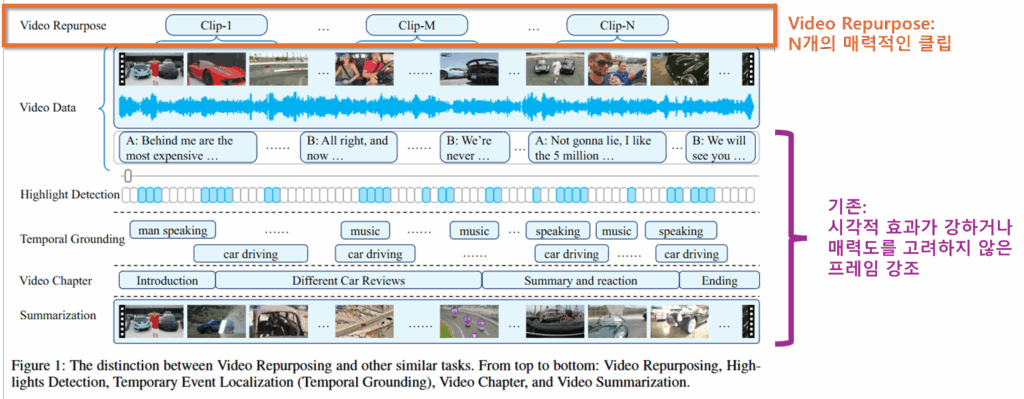
우선 해당 논문이 타겟팅하는 수요는 비디오의 재가공입니다. 사용자가 촬영한 긴 비디오를 기반으로 해당 영상의 유입을 높이기 위한 짧은 인게이징(engaging) 클립을 생성하는 테스크입니다. 앞서서 소개해드렸던 트레일러 생성과 유사한 수요로 이해하시면 좋을것같네요.
생각해 볼 것은 이것입니다. 해당 문제를 해결할 기술로 비디오 요약, 비디오 하이라이트 감지, 비디오 이벤트 영역 탐지와 같은 분야가 있는데, 왜 해당 기술이 필요할까요?
논문의 Related Tasks에 따르면, 먼저 비디오 요약의 경우는 비디오 전체를 포괄하는 요약을 만들기때문에 인게이지 요소를 고려하지 않았다고 합니다. 또한 비디오 하이라이트 감지의 경우 내용과 관계없이 매우 인상적이고 익사이팅한 순간(움직임이 많고, 빛변화가 많은 순간)을 주로 강조하며, 비디오 이벤트 영역 탐지의 경우 스포츠 경기, 강연과 같은 명시적인 분리가 가능한 도메인에서 명확한 시작, 종료 시점을 탐지하기에 수요가 높은 인게이징 클립을 찾아내는데 적합하지 않다고 합니다.
즉, 제 의견까지 더한다면 비디오의 완벽한 이해를 통해 인게이지먼트를 갖는 “볼만한” 영상을 생성하는 기술을 위해서는 기존 연구가 아닌 새로운 데이터셋과 새로운 문제정의가 필요하다는 것입니다. 세미나때 NLP 분야에서 Abstractive level 요약과 Extractive level 요약 개념에 대해 말씀드렸는데요, 기존 extractive level이던 video 요약 및 가공 분야가 abstract level로 가기 위한 중간 지점이 아닐까 하는 생각이 드네요.
정리하면, 해당 논문은 원본 영상을 기반으로 매력적인 짧은 클립을 생성하기 위한 Video Repurposing 테스크를 정의했고, 이를 위한 대규모 데이터셋인 Repurpose-10K과 벤치마크를 제공했다는 점에 큰 의의가 있습니다.
The Strength 1) Repurpose-10K (A new dataset for the field)
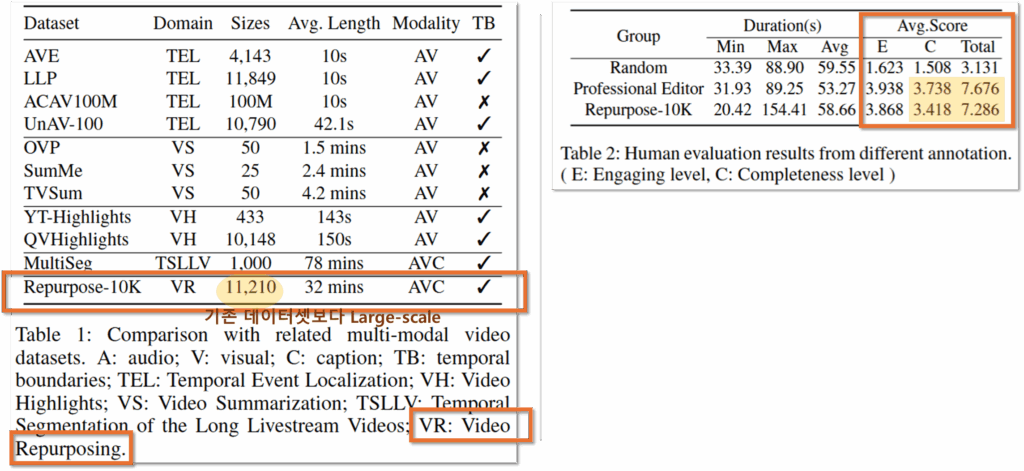
개인적으로 저자들이 제시한 문제를 해결하기 위해 데이터셋 구축에 고심 했을 것 같다고 생각했습니다. 특히 annotation을 SaaS 플랫폼의 실제 사용자에게 얻었으며, Human Evaluation을 진행했기 때문에 인게이지먼트 요소를 고려한 숏폼 비디오 생성연구를 하는 연구자들이 활용하기에 좋은 데이터셋일 것 같습니다. 먼저 기존 데이터셋과 비교하여 보면 Table1과 같습니다.
(장점1) Large-scale. 저자들은 사용자 생성 콘텐츠 비디오의 경우 (아마도 주관적인 주제가 많고 노이즈가 많기 때문에) 모델이 학습에 있어 데이터의 양이 중요하다고 주장하며 Repurpose-10K의 비디오 개수가 기존 데이터에 비해 많은 점에 있어 이점을 갖는다고 합니다. 또한 평균적으로 32분의 비디오로 길이 또한 긴편입니다.
(장점2) Caption 제공. 비디오 데이터의 경우 가공된 캡션 데이터를 제공하지 않는 경우가 많습니다. 벤치마크를 따르기 위해서는 매번 새롭게 audio 기반 캡션을 생성하는것보다는 통일하여 제공하는 가공된 캡션이 데이터가 제공되는것이 필요합니다. 그러나 기존 데이터셋의 경우 이를 따로 제공하지 않는 경우가 많은데요, Repurpose-10k의 경우 캡션을 함께 제공한다고 합니다.
또한 해당 데이터셋은 구축 이후 Human Evaluation을 진행했습니다. 검토 방안은 다음과 같습니다. 먼저 데이터셋에서 110개의 비디오를 렌덤으로 선택합니다. 해당 데이터셋을 기반으로 생성된 462개의 클립과 랜덤으로 타임스템프를 선별하여 만들어진 462개의 클립, 두명의 비디오 크리에이터가 직접 구축한 330개의 비디오(3 short clips for each video)에 대하여 10명의 참여자가 매력도(Engaging leve)와 완성도(Completeness level)에 대한 평가를 진행했습니다. 그 결과는 Table2와 같으며, score 상으로 크리에이터가 생성한 비디오와 데이터셋의 라벨이 크게 구분되지 않음을 확인할 수 있습니다.
데이터셋의 구축 방안은 다음과 같습니다. 먼저 8,398개의 유튜브 영상에 대해 topic segmentatioin을 제공하는 OPUS platform을 통해 여러 클립으로 가공하고, 사용자들이 선호하는 클립에 대해 ‘like’ or ‘post’ 버튼으로 선호를 라벨링하도록 했습니다. 이후 편집자의 정밀한 후 가공을 통해 클립의 시작/끝점을 조정하여 총 120,925개의 인게이징 요소가 높은 클립의 타임스템프 라벨을 구축했습니다.
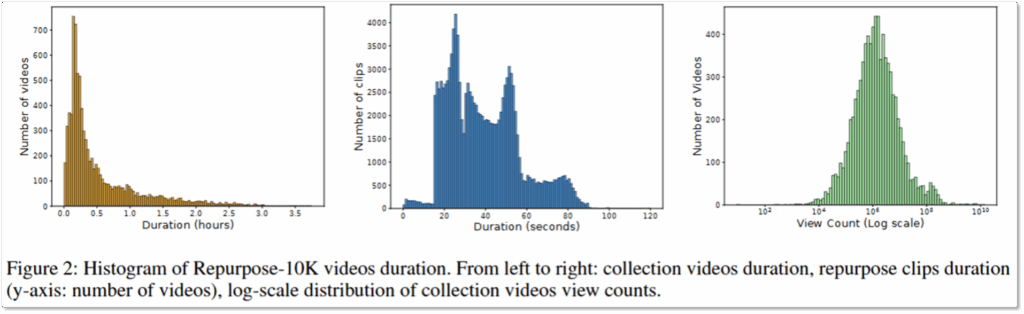
위는 제안된 데이터셋의 분포입니다. 가장 좌측은 원본 영상의 길이로 평균 0.54 시간에 비교적 길고, 다양한 길이의 데이터를 포함하고 있음을 시사합니다. 중간의 히스토그램은 라벨링된 클립의 길이이며 대부분이 100초 이하에 해당합니다. 마지막의 그래프는 원본 영상의 조회수 분포입니다. 평균 1,890만회로 높은 조회수를 갖는 비디오로 구성되며, 데이터셋에 다양한 조회수를 포함하므로 매력도 높은 숏폼 재가공 테스크를 위한 데이터셋 구축에 적합한 비디오임을 예상할 수 있습니다.
The Strength 2) The Framework to solve the problem
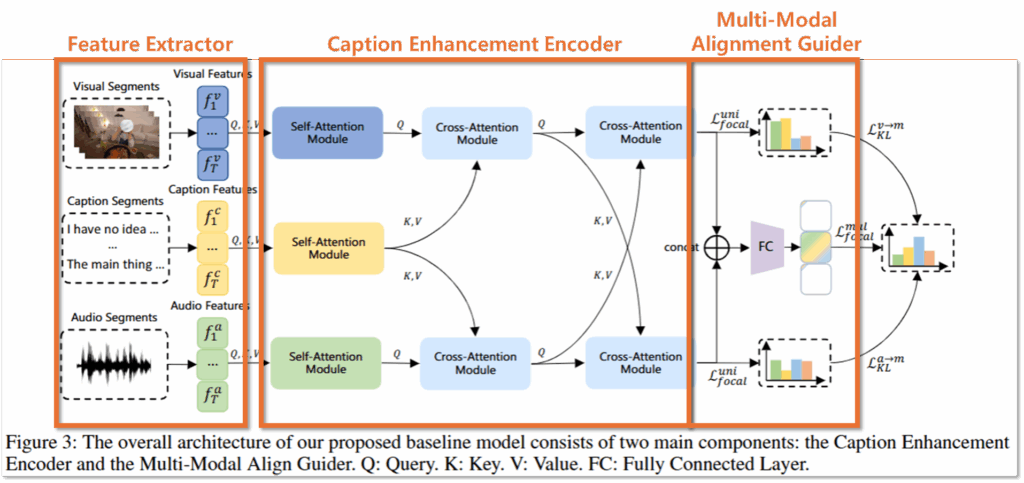
데이터셋을 제시했다면, 해당 데이터셋의 솔루션을 제시해야합니다. 일반적으로 제시한 데이터셋이 너무 쉽거나 어렵지 않게 “이제 연구를 시작해도 될만한” 난이도로 잘 구축되었음을 증명하는게 해당 프레임워크 설계와 실험 벤치마크 제시의 목적인것 같습니다. 논문에서 제시하는 프레임워크는 Figure3과 같으며 클립 영역에 대한 regression과 영역이 인게이지먼트 요소가 있는 유의미한 클립인지 이진 분류하는 classification 테스크를 동시해 수행하도록 설계했습니다. 구조는 Feature Extractor와 Caption Enhancement Encoder, Multi-Modal Alignment Guider 세 가지 요소로 꽤 간결하게 설계되었습니다.
1) Feature Extractor
입력 데이터의 경우 비전, 오디오, 캡션 도메인이 모두 잘 align되어 있으며, T개의 세그먼트로 구성되는데요, CLIP(비전), PANN(오디오), MiniLM(텍스트)과 같은 파운데이션 모델과 MLP를 통해 공통 임베딩 차원으로 특징량을 추출합니다.
2) Caption Enhancement Encoder

다음으로 임베딩된 모달리티별 특징량들은 self-attention module로 표현력이 증강됩니다. 이후 caption 도메인의 데이터는 비전과 오디오 도메인을 위해 보조적으로 사용되는데, 이는 우측과 같이 캡션이 주로 영상에 나오는 객체나 컨텍스트를 직접적으로 설명하는 역할을 하기 때문이라고 설명합니다. 이러한 설명을 통해 해당 연구의 경우 비전 도메인을 메인으로 인게이징 클립 생성을 수행하고자 함을 예측할 수 있습니다.
caption enhancement를 구현하기 위해 cross-attention module을 사용했는데요, Figure3에서 확인할 수 있는것처럼 먼저 caption feature를 통해 오디오와 비전 도메인 enhancement를 위한 연산을 수행하고, 이후 오디오와 비전 모달리티를 직접적으로 cross-attention에 사용하여 caption 데이터를 기반으로 모달리티들이 표현력이 강화되도록 설계했습니다.
3) Multi-Modal Alignment Guider
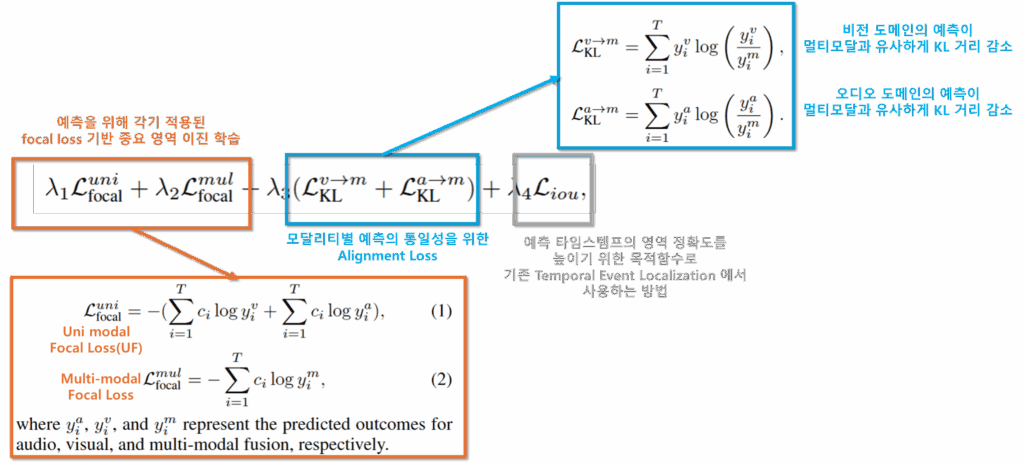
멀티 모달리티 모델의 학습의 경우 모달리티간 정보 불균형으로 인해 자칫하면 학습이 실패하는 등 안전성이 좋지 않습니다. 논문에서는 이를 해결하기 위해 비전과 오디오 모달리티, 그리고 멀티모달리티에 대해 각각 예측을 위한 MLP 구조를 도입하고 타임스템프 예측을 수행하도록 설계했다고 합니다. 또한 최종적으로 예측된 타임스템프의 확률 분포를 일치시키기 위한 Alignment Loss를 도입했다고 합니다. 모델에 사용된 Loss는 아래와 같습니다.
Experiments
1) main results: comparision with temporal grounding models
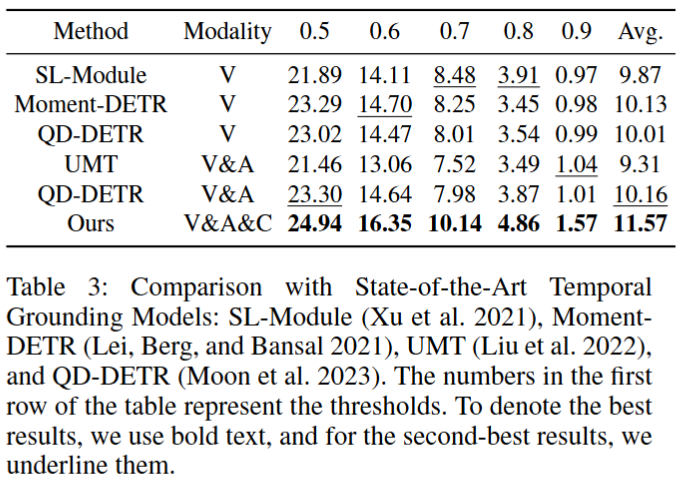
논문에서는 제안한 문제와 가장 유사한 기존 연구가 Temporal grounding models이라고 합니다. 근거는 Figure1에서 확인할 수 있습니다. 다른 기존 연구와 달리 Temporal grounding 은 영상에서 부터 n개의 클립을 생성하는 테스크이기 때문에 의미있는 타임스템프를 생성할 수 있기 때문입니다. 실험 결과 다양한 IOU를 고려했을때 제안한 방법이 매력있는 클립을 디텍션하는데 가장 효과적이였음을 확인할 수 있습니다.
2) Ablation study:
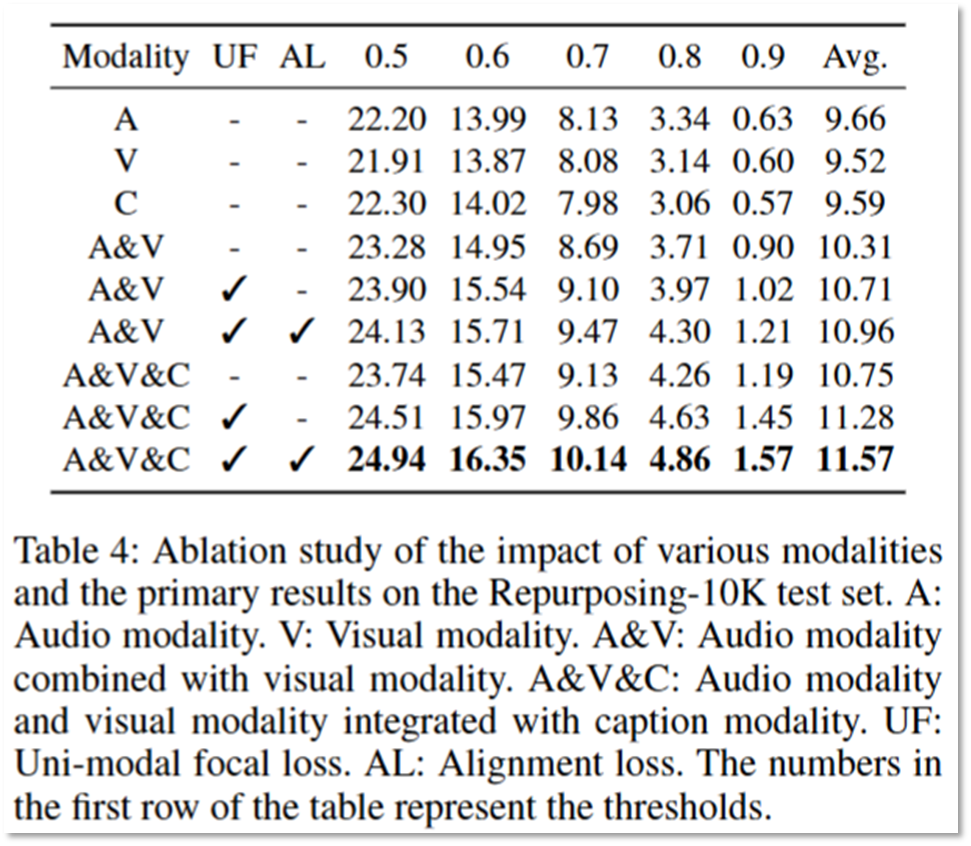
다음으로 제공된 실험은 ablation study입니다. 실험에 사용된 프레임워크가 유의미한 구조임을 보이기 위한 실험으로 모달리티가 추가됨에 따라 성능향상을 확인할 수 있으며, 사용된 목적함수(UF:unimodal focal loss, AL:Alignment loss)가 추가됨에 따라 역시 성능이 향상됨을 확인함을 통해 이를 검증하였습니다. 주목할 점은 단일 모달리티를 활용할때 (특히 IoU threshold가 낮을 때) caption 활용이 가장 효과적이였다는 점이라고 합니다. 이를 통해 video repurposing 작업에 캡션이 중요하며, 설계한 프레임워크의 캡션 가이딩이 유의미한 이유라고 설명했습니다.
3) Qualitative Results:
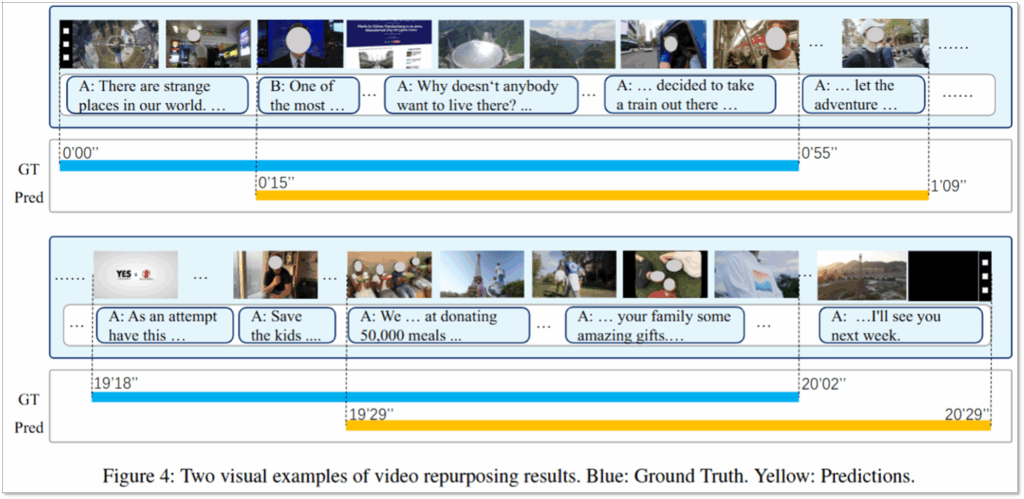
마지막으로 소개할 실험은 정성적 결과입니다. 위의 Figure4는 데이터셋의 GT와 설계한 프레임워크의 예측을 비교한 것입니다. 전반적으로 중요한 영역을 잘 잡고있으며, 특히 GT의 경우 사람이 라벨링하면서 사건상으로 중요하지 않은 부분 (Figure4의 첫줄의 경우 strange place의 나래이션부터 GT 시작하나, 예측은 사건의 직접적인 시작인 뉴스의 시작화면부터 중요 클립으로 예측했다고 함. Figure4의 두번째 줄의 경우 GT는 상푸에 대해 소개하는 광고 프레임을 포함하나, 모델의 경우 영상의 실제 중요 사건 시작 시점부터 타임스템프를 생성하고 광고보다 유의미한 정보를 클립에 포함했다고 함)을 포함하나, 예측의 경우 오히려 문맥적으로 더욱 유의미한 영역을 클립 타임스템프로 예측했다고 분석합니다.
기존에 Active Learning 연구를 많이 팔로우했었던 제가 느끼기에는 해당 분야에서는 데이터셋이 끊임없이 구축되어 공개되는 것 같습니다. (물론 로봇분야보다야 변화가 덜하지만요) 해당 데이터셋들의 구축 의도와 설계에 공이 들어간 것이 느껴지는데요, 벤치마크로 끝나고 후속 연구가 진행되지 않는 벤치마크도 꽤 있는것 같아 보여 아쉬운 마음입니다. 또한 비디오 요약이라는 테스크가 주관성을 내포하고 있다고 생각하는데요, 이러한 정의의 명료하지 않음으로 새로운 접근법이 계속 등장하는 것 같습니다. 본 논문이 추구하는 바가 제가 추구하는 바(goto abstract level summarization)와 유사하다고 생각하는데, 이러한 연구를 수행하고자 하는 경우 데이터셋 구축까지 함께하는것이 일반적인것 같네요. 리뷰 읽어주셔서 감사합니다.
안녕하세요 유진님 좋은 리뷰 감사합니다.
Ablation 실험에서 단일 모달리티 사용 시 caption만 사용해도, 특히 IoU threshold가 낮을 때 좋은 성능을 보였던 점이 인상 깊었습니다! 이건 단순한 궁금증일 수 있을 것 같은데요, 혹시 이 성능 향상이 caption이 가지는 장점(영상 속 배경이나 등장인물사물 정보가 잘 표현되어있는) 때문인지,아니면 Repurpose-10K 데이터셋의 특성(유튜브 영상 위주의 높은 품질의 자막) 때문인지 궁금합니다! 그래서 혹시 Repurpose-10K 데이터셋 이외에 다른 데이터셋에 대한 평가도 있었는지가 궁금합니다!
감사합니다.
안녕하세요 우현님 답글 감사합니다.
질문해주신 Table4의 Ablation 실험에 대해서는 단일모달리티에서 caption의 유의미함을 통해 제안한 caption enhancement 구조의 타당성을 주장했는데요, caption에 대한 상세한 분석은 다루지 않은 것 같습니다. Repurpose데이터셋의 경우 캡션의 유의미성을 실험으로 다룰만큼 구체화 정도가 세분화 되지 않았기 때문입니다. 예를 들면, 1단계: 당나귀 / 2단계: 노란색 빛나는 당나귀. 따라서 질문해주신 caption 성능 향상의 원인이 캡션 구체성 때문인지는 답변드리기 어렵습니다. 다만 캡션이 구체화된다면 caption enhancement를 통해 더욱 성능 향상이 가능할 것 같네요. 또한 해당 논문에서는 Repurpose-10K를 활용한 실험만을 다루었음을 알려드립니다.
감사합니다.