이번 x-review 로는 SAR (합성개구레이더 (Synthetic-aperture radar))이라는 데이터를 이용한 Object detection 논문입니다. 논문 제목으로 알 수 있듯 SAR 도메인의 Detection의 대규모 벤치마크를 제안하면서 동시에 어떻게 RGB와의 도메인 갭을 줄이고 해당 벤치마크에서 유의미한 성능을 낼 수 있을지 설명하는 논문인데, SAR 이라는 어쩌면 처음 들어볼만한 데이터의 특성과 그 특성을 어떻게 해결했고 어떻게 나아가야할지에 대한 설명으로 작성하겠습니다.
Abstract
SAR(합성개구레이더 데이터)에 대해 우선 설명하자면, 이는 공중에서 지상이나 해양을 향해 레이더파를 순차적으로 발사한 후, 지형의 굴곡면에서 반사되어 돌아오는 미세한 시간차를 처리하여 지상지형도를 생성하거나 지표를 관측하는 레이더 시스템입니다. 레이더를 사용하기 때문에 주간 및 야간, 그리고 악천후에도 사용할 수 있다는 장점이 있는데 보통 군용으로 개발되기 시작했고, 이 레이더 시스템이 장착되어 있는 것들도 위성, 최신형 전투기, 헬리콥터, 대형 정찰기 등입니다. 보통 이동목표 추적을 위해서 사용된다고 생각하시면 됩니다. 한가지 더 알아야할 특징으로는 SAR 레이더파가 반사되는 것은 만나는 재질에 따라 다른데, 금속재질등에서는 강한 정반사가 일어나 하얗게 변하고, 비금속 물체에 대해서는 빛이 산란하거나 소멸하여 검은색으로 보이기 쉽습니다. 아래 RGB와 SAR 데이터 사진 예시입니다.
https://www.maxar.com/maxar-intelligence/products/sar-imagery
(저자가 사용한 데이터는 생각보다 노이즈가 있습니다..)


저자는 10개의 데이터셋을 모아서 여러 라벨의 대규모 데이터셋을 만들게 됩니다. Object detection 용도의 COCO 사이즈정도의 데이터셋을 만들게 되는데, 활발하게 연구되고 있던 분야는 아니기도 하고 주류인 RGB 이미지로 사전학습된 모델에 바로 SAR로 파인튜닝하게 되면 엄청난 도메인 갭이 존재하고 모델 구조도 차이가 필요하다고 합니다. 이러한 gap 을 이어주기 위해서 저자는 Multi-Stage with Filter Augmentation (MSFA) 를 제안하고 이를 사전학습에 적용하여 데이터의 input , 도메인의 차이, RGB 이미지로 사전학습된 모델을 파인튜닝 할때의 문제점을 해결하려합니다. 이를 여러 backbone 모델들에 대해 실험하여 높은 일반화와 유연성을 보여줍니다. 이 논문은 이후 SAR object detection 의 이후 발전을 위한 길을 만드는 것을 목표로 한다고 합니다.
Introduction

해당 이미지 fig(a) 를 보면 알 수 있듯이 SAR 은 밤, 구름, 눈, 지형에 상관없이 특징을 잘 잡아내는 장점이 있습니다. 이러한 장점들의 결과로 SAR은 국방을 포함한 중요한 분야에서 광범위한 응용이 있다고 하는데, 그 예시로 인도주의적 구호, 위장 탐지, 지질탐사 분야 등이 있습니다.
이러한 관심도가 증가하지만 앞서 말했듯이 한정된 자원과 전이학습에서의 gap 차이로 문제가 존재한다고 합니다.
Limited resources.
SAR 영상은 민감한 군사/보안적 특성 때문에 공개가 어렵고 라벨링 비용도 굉장히 높습니다. 공개 데이터셋이 거의 없고 크기도 작고 다양성이 부족하다는 특징이 있습니다. 기존 공개된 SAR 객체 탐지 데이터셋의 한계는 대부분 단일 클래스의 예측만을 수행한다는 점과 배경이 단순하여 실제 환경과는 거리가 있고 샘플 수가 적고 다양하지 않아 성능의 일반화가 존재하지 않는다고 합니다. 그리고 대부분의 코드들이 비공개라 재현이 불가능하다는 단점도 언급합니다.
이러한 문제점들로 저자는 기존 데이터들을 가공하여 동일 포맷으로 6개의 클래스를 구분하여 SARDet-100k 라는 벤치마크를 만들게 됩니다.
Transferring gaps.
저자가 생각하는 transferring gap 두가지는 도메인 갭과 모델 갭입니다. 도메인 갭은 앞서 말했듯이 RGB 이미지와 SAR 이미지의 시각적 특성 차이 때문에 생기고, 모델 갭은 ImageNet에서 사전학습한 백본은 분류기 전용 구조라 탐지기 전체 구조와 다르다고 합니다. 이러한 문제로 RGB 로 사전학습된 모델을 SAR 탐지기로 전이할때 성능이 낮아진다고 합니다.
우선 input gap 을 줄이기 위해 전통적 인 feature descriptors를 사용합니다. ( SIFT, HOG, Gabor.. etc) 이를 통해 SAR 과 RGB 간의 입력차이를 줄일 수 있다고 하는데, feature 공간에서 유사해지도록 정규화 한다고 생각하면 됩니다.
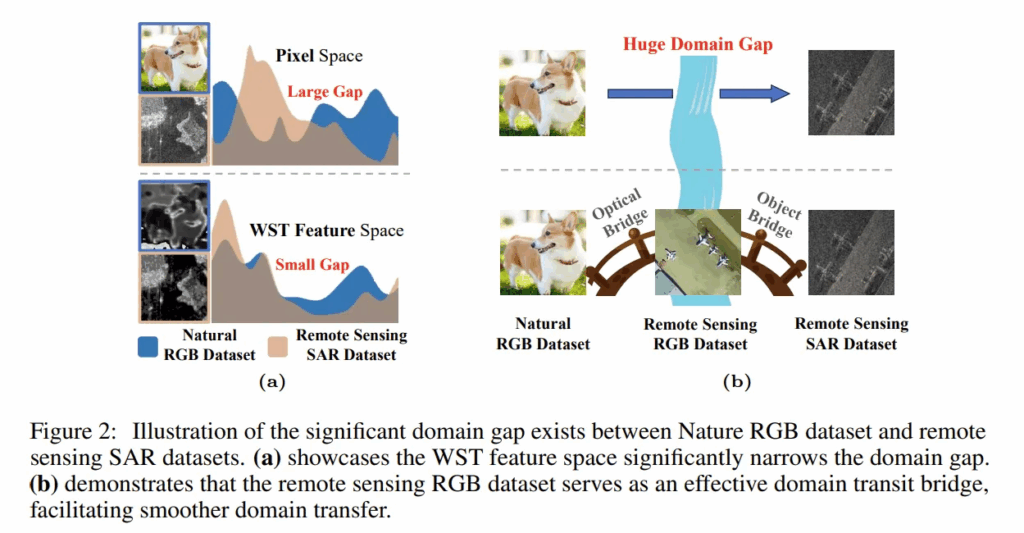
저자가 사용한 방식은 SIFT HOG 는 아니고 WST filter를 사용하는데, 이는 SAR이 가지고 있는 단점인 speckle noise 에 강건한 필터입니다. 즉 기존 방식인 RGB로 사전학습된 가중치를 가져와서 SAR 으로 detector만 학습하던 것이 아니라, RGB 자체에 WST 필터를 입힌걸 학습시켜 domain gap 을 줄인다는 생각입니다. 그림 (a)를 보면 픽셀 공간에서의 RGB 와 SAR 의 도메인이 다르지만, WST 를 거치고 나면 둘의 도메인이 비슷해지는 것을 확인할 수 있습니다.
Contribution
- COCO 수준의 대규모 SAR 객체 탐지 데이터셋 최초 공개
- 기존 pretrain → finetune 의 한계점을 분석하고 대안 제시
- Multi-Stage with Filter Augmentation (MSFA) 프레임워크 제안 도메인 간 전이를 위한 단계적인 학습을 제안했습니다.
- 데이터셋 및 코드 공개로 SAR 탐지 연구 생태계 기여라고 합니다.
SAR Object Detection
최근 딥러닝의 Object Detection 모델들이 발전해왔는데 SAR 이미지는 여러 난관이 존재한다고 합니다. small object size, speckle noise, sparse information 문제가 존재한다고 하고있는 SAR image의 내재적 특성이라고 합니다.

해당 표는 SARDet-100k dataset을 구성하는 dataset들입니다. target 은 각각 table 에 설명되어있는 것들이고 T가 tank로 되어있는데 이게 저희가 아는 탱크가 아닌 oil tank입니다. (MSTAR 라는 dataset 에는 실제 탱크라서 헷갈리는 표현이네요..흠)
그리고 Resolution(m) 적혀있는 것은 지상 해상도로 1픽셀이 지상에서 1m X 1m 를 나타낸다고 보면 됩니다. 즉 값이 작을수록 high resolution 입니다.
Band 는 전자기파의 주파수 대역으로 여러 밴드를 사용한 것을 알 수 있습니다. 밴드가 다르면 주파수 대역대가 달라 해상도나 보고자 하는 대상이 달라질 수 있습니다.
polarization은 편파로서 각각 인공 구조물, 해상탐지, 자연환경 등등에 적합한 정보들입니다.
Current Status
이전까지의 dataset들의 상태에 대해서 얘기합니다. 저해상도 이미지는 풍부하지만 고해상도 이미지가 부족했고 고해상도 이미지는 보안이나 민감한 정보도 많고 획득 비용이 비싸 공개가 불가능한 경우가 많았다고 합니다. 물론 저해상도의 이미지는 scene classification에는 유리하지만 비행기, 차량, 선박 탐지등에는 불리합니다.
저자가 제안한 SARDet-100K는 총 10개의 고해상도 SAR 데이터셋을 엄선해서 통합하였고 출처도 중국의 과학기관이나 유럽 우주국, 미국 군 연구기관이라 어느정도 신빙성도 있습니다. 중복 객체 클래스를 제거하고 해상도도 정규화시키며, 어노테이션 포맷을 통일시켰다는 점에서 contribution이 있습니다.
Multi-Stage with Filter Augmentation Pretraining Framework
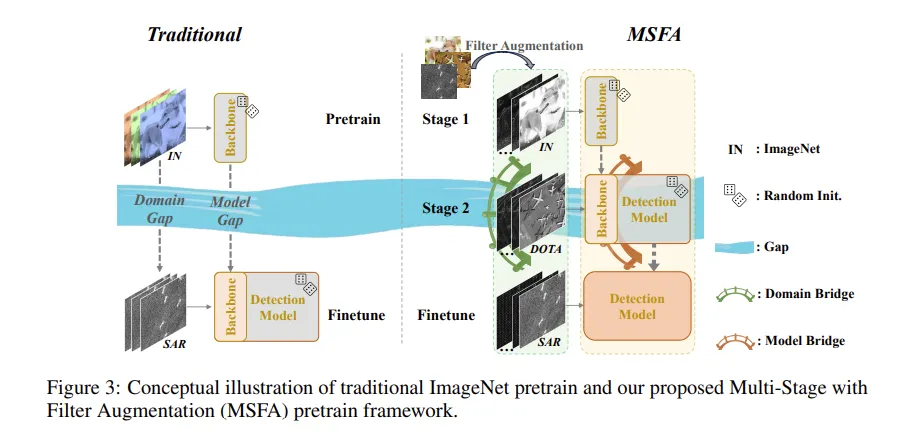
해당 방법론인 MSFA 의 도식도입니다. 생긴거에 비해서 생각보다 간단한데, 기존 방법론인 왼쪽 도식도의 Traditional을 보면 RGB 이미지로 backbone을 학습하고나서 , 이 backbone을 그대로 사용하여 Detection model을 SAR로 파인튜닝을 하게되면 엄청난 domain gap으로 학습이 불안정합니다. 저자의 방법론은 MSFA를 사용하여 stage를 나누어 SAR 도메인을 적응할 수 있게 하는 것입니다. 다.
Filter Augmentation
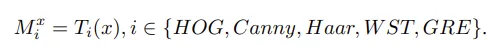
우선 원본 SAR 이미지에는 여러 종류의 고전적인 시각 필터를 적용하여 각각의 필터 출력 Mi 를 얻습니다.

그리고 원본 SAR 이미지와 위에서 얻은 필터 기반 특성 Mi 를 채널차원으로 concat 하여 탐지 모델에 입력될 새로운 입력 텐서 Inp 가 됩니다. 즉 저자는 도메인이 맞지 않는 SAR 이미지에 여러 고전 필터들을 입혀서 concat하여 비슷하거나 정렬되어 보이는 표현 공간으로 변환시켜줬다고 생각합니다. 해당 부분의 저자의 표현은 이렇습니다.
By casting the original data input from the heterogeneous pixel space to a homogeneous filter augmented feature space, the domain gaps between different image domains can be greatly reduced, as illustrated in Fig. 2(a).
전통적인 방식
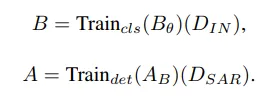
이 부분은 해석하자면 Train(t)(a)(b) 로 나타낼 수 있고, 여기서 t ∈ {cls, det} 이며 모델 a 를 b 라는 dataset으로 학습시키겠다는 뜻입니다. DIN 부분은 dataset ImageNet을 나타내고, DSAR 은 SAR dataset 을 나타냅니다. B는 백본모델로서 먼저 이미지넷 데이터셋으로 학습되는 것이며 A는 B로 학습되어진 모델을 SAR dataset으로 파인튜닝한다고 생각하시면 됩니다.
Multi-Stage 방식

백본 B를 포함한 탐지모델 AB 를 optical Remote Sensing 데이터셋 D_RS 에서 탐지 task 로 학습시켜서 중간 탐지모델인 A’ 을 만듭니다. 여기서 optical Remote sensing 데이터셋은 EO (RGB ) 도메인의 항공뷰 이미지 입니다. 이후 중간 탐지모델 A’ 을 초기화 모델로 사용하여 SAR 데이터셋 DSAR 에서 다시 탐지 task 로 학습시켜서 최종 모델 A 를 만듭니다.
간단하게 말하면
- 지상뷰 EO(RGB) ImageNet 데이터셋으로 백본 classification task로 학습
- DOTA 같은 항공뷰 EO(RGB) 데이터셋으로 전체 파인튜닝 진행
- SAR (항공뷰) 데이터셋 으로 전체 파인튜닝 진행
자연 이미지 → Optical RS → SAR 순서로 학습시켜 도메인을 천천히 학습한다고 생각하면 됩니다.
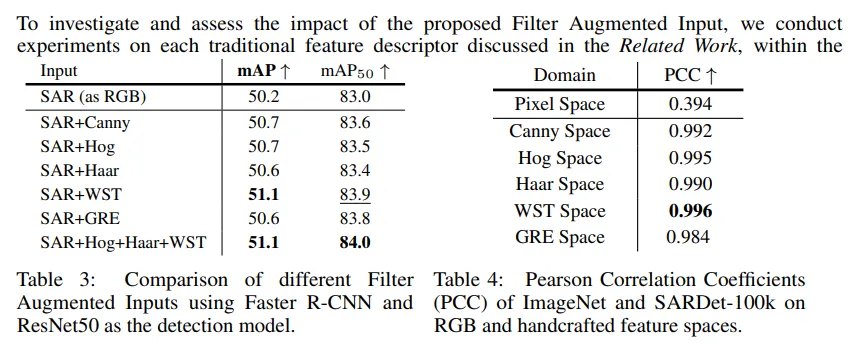
Table 3 은 filter augmentation 별 map 성능차이 ablation 입니다. 아무것도 적용하지 않은 버전보다는 filter augmentation 을 추가하는 것이 성능이 오르는 것을 확인할 수 있습니다. Table 4 는 기존 Imagnet과 SAR 데이터의 픽셀레벨의 피어슨 상관계수이고, filter augmentation을 적용시킨 space에서는 상관계수가 매우 높아지는 것을 확인할 수 있습니다. 해당 상관계수는 선형 상관관계라 생각하면 되는데, 키가 클수록 몸무게가 무거워지는 경향이 있다고 할 때 키와 몸무게는 피어슨 상관계수가 높다고 할 수 있습니다. 저자는 이러한 피어슨 상관계수가 높아지는 것으로 자연 이미지와 SAR 이미지 사이의 도메인 갭이 줄어들어 사전학습된 지식이 SAR로 더 효율적으로 전이될 수 있다고 언급합니다. 이때 WST 필터가 노이즈를 억제하고 객체 관련 세부 정보를 보존하는 특징이 강인하다고 합니다. 다른 필터들을 추가적으로 사용한다고 성능이 더 오르지 않아 Filter augmented input으로는 WST만을 채택했다고 합니다. (깃헙에는 ablation했던 가중치가 모두 존재하기는 합니다.)
Limitation and Future Work
해당 논문은 지도학습 기반인데, 대규모로 존재하는 unannotated SAR 데이터를 고려했을 때 semi-supervised나 weakly-supervised 혹은 unsupervised learning 기반의 도메인 전이 학습에 대한 연구가 유망하다고 합니다. 그리고 본 연구가 단순하고 실용적인 사전학습 기법 제안에 초점을 두고 있기 때문에 복잡한 네트워크 설계나 세분화된 전략을 접목시켜 성능과 표현력을 향상시킬 수 있을거라고 합니다.
Conclusion
본 논문은 대규모 SAR 객체 검출을 위한 새로운 벤치마크인 SARDet-100k 데이터셋을 제안하고 multi stage with Filter Augmentation (MSFA) 프레임워크를 제안했습니다. MSFA는 사전학습과 파인튜닝 간의 도메인 및 모델 불일치 문제를 효과적으로 완화하여 기존 벤치마크들 대비 SOTA 성능을 달성했고 다양한 모델 구조에 높은 일반화 성능과 유연성을 보여주어 범용적인 사전학습 기법으로서의 가능성을 입증했다고 합니다.
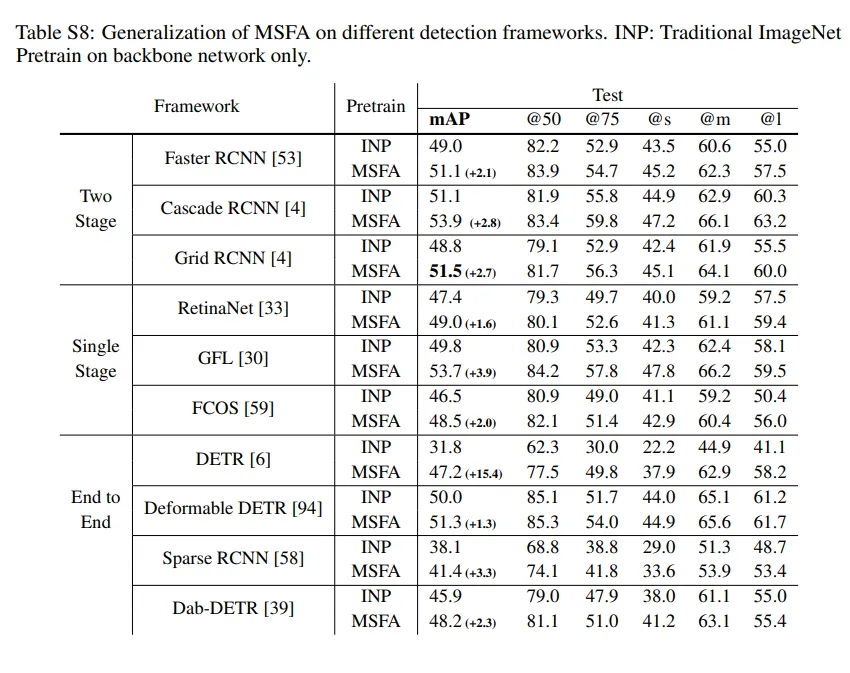
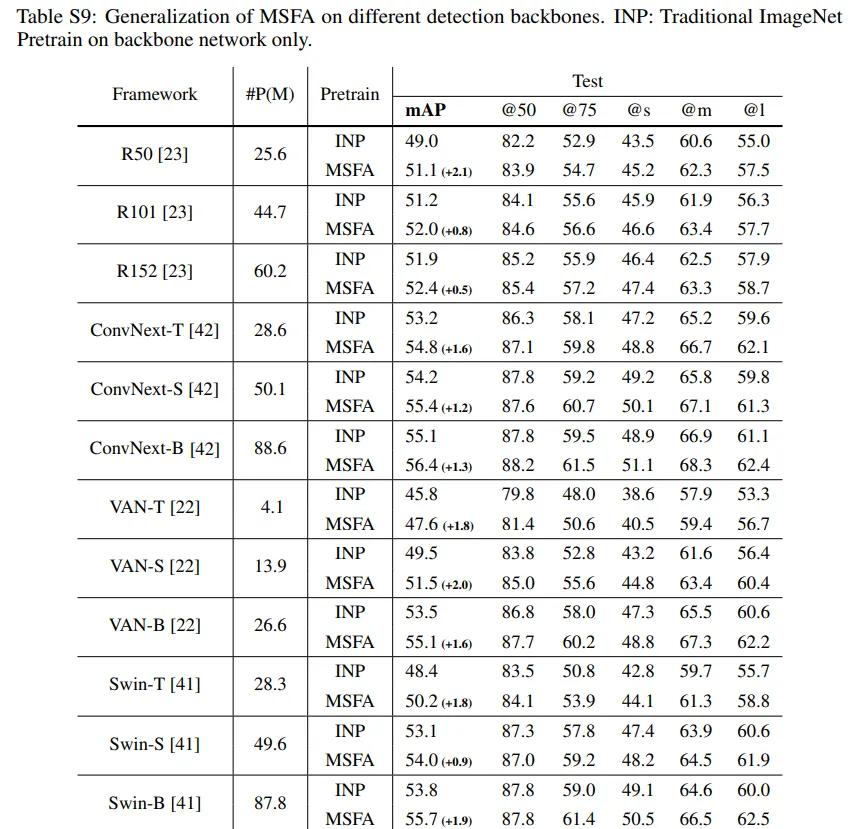
여러가지 backbone + detection모델을 이용한 ablation 입니다. 위의 conlusion에서 얘기하는 높은 일반화 성능의 증거로서 appendix에 존재합니다.
추가로 SAR 데이터셋 예시사진도 첨부하자면 이렇습니다.
감사합니다.
안녕하세요 인택님 리뷰 감사합니다
SAR이라는 키워드에 이끌려서 들어와봤는데요, 레이더 관련이었군요,, 그래도 좀 큰 규모의 국방에도 사용될 수 있는 데이터셋이 공개되있다는 것이 흥미롭네요,, 여러 데이터를 합쳤다고 하는데 annotation도 저자들이 직접 다 통일시킨건가요?
또 WST는 어떤 알고리즘인가요? 객체 관련 세부 정보를 보존하는 특징이 강인한 이유가 궁금합니다!!
안녕하세요 영규님 답글 감사합니다.
우선 annotation 을 합친 부분은 기존에 존재하는 데이터셋에 같은 객체를 다르게 표기하거나 하는 문제들을 직접 상위 6개 클래스로 재정의했다고 생각하시면 됩니다.
wst는 wavelet scattering Transform 으로 이미지의 다중 해상도나 다중 방향의 특징을 추출하는 필터라 생각하시면 됩니다. 제가 관련 논문까지 간단하게 찾아봤었는데 2천년도 이전부터 쓰이던 SAR 특징추출하기 위한 필터입니다. 객체 관련 세부 정보를 보존하는 특징이 강인한거에 대한 구체적인 매커니즘까지는 모르겠지만 흔히 아시는 hog sobel canny 같은거의 일종이라 생각하면 될 것 같습니다.
안녕하세요 신인택 연구원님 좋은 리뷰 감사합니다.
읽어보다보니 몇가지 궁금한 점이 생겨 질문합니다. 우선, Optical RS -> SAR 순서로 학습할 때에 정렬되어 있지 않다면, 학습 효과가 떨어질 것 같은데 이미지 사이의 정렬과 관련되어 저자의 언급이 있었는지 궁금합니다. 그리고 ablation을 보니까 백본마다 성능 향상폭이 다른 것 같습니다. 백본의 차이에서 오는 차이에 따른 성능 향상 차이에 관련해서 저자의 언급이 있었는지 궁금합니다. 그리고 백본으로 CNN, Transformer 중에 어떤 것을 사용하는 것이 더 효과적인지도 궁금합니다.
감사합니다.
안녕하세요 성준님 답글 감사합니다.
흠 우선 DOTA같은 optical RS 에서 SAR 순서로 학습할때 어떤 정렬이 필요한지 크게 떠오르진 않는데, 이미지 사이의 정렬같은 언급이 따로 존재하진 않았던 것 같고, EO 도메인에서 EO 항공도메인 SAR 항공도메인 순서로 천천히 adaptive하게 적응시키는 방식입니다.
백본에 따라서 성능차이가 좀 심하긴한데, CNN 을 이용하는 방식이 보통 성능이 더 좋은 것 같고, 이런 점이 CNN이 가지고 있는 inductive bias 때문인지 혹은 SAR 도메인이 CNN에 유리한건지 좀더 생각을 해봐야할 것 같긴 합니다. 뭔가 트랜스포머를 사용하는 것보다 CNN을 사용하는 것이 WST 같은 필터 정보를 더 잘 보존하 수 있을 것 같기도 합니다. 감사합니다.
안녕하세요 인택님, 좋은리뷰 감사합니다.
SARDet-100k의 기존 데이터셋 통합 방식에서 궁금증이 들어서 답글 드립니다.인택님께서 해상도 정규화, 어노테이션 포맷 통일, 클래스 중복 제거 등은 언급해주셔는데 사실 어떤 기준으로 클래스 통합을 했고, annotation 신뢰도 문제도 있을 것 같은데 이를 어떻게 해결했는지가 궁금하네요 감사합니다.
안녕하세요 우현님 답글 감사합니다.
제가 아는 기준에서는 상위 6개의 클래스로 저신뢰 데이터를 일부 필터링하고 reannotate 한거로 알고 있습니다.
뭐 동일 상위클래스로 묶일 수 있지만 기존에 다른 label로 존재했다면 그걸 하나하나 묶어서 상위 클래스로 재정의했다고 생각하시면 됩니다. 생각보다 복잡한 그런 기준이 있는 것은 아닙니다!