안녕하세요. 이번에 제가 이번에 리뷰할 논문은 Mask DINO라는 논문입니다. 상반기 회고에서도 잠깐 언급했듯이, 현재는 단순하게 말씀드리면 하나의 모델로 depth estimation과 object detection을 동시에 수행할 수 있게끔 하는 구조를 실험하고 있습니다. 그런데 막상 실험을 해보니깐 두 태스크 모두 성능이 오히려 떨어지는 현상이 발생했습니다.
depth estimation은 픽셀 단위에서 값을 정밀하게 예측하는 작업인 반면, object detection은 객체 단위에서 시멘틱 정보를 활용해 카테고리와 위치(bbox)를 예측하는 작업입니다. 그래서 어찌보면 두 태스크는 초점 맞추는 부분 자체가 완전히 다르다고 볼 수 있습니다. 그래서 multi-task learning 관점에서 보면, 두 작업이 서로 보완적이기보다는 상충되는 효과를 일으키는 구조일 수 있다는 생각이 들었습니다.
반면 segmentation은 특성상 depth처럼 pixel-level의 예측을 수행하는 동시에, 관심 객체 영역을 찾는다는 점에서 detection과도 개념적으로 닿아있는 부분이 있습니다. 그래서 실제로도 segmentation과 depth estimation을 함께 다루거나, segmentation과 object detection을 함께 학습하는 연구들은 꽤 많이 진행되고 있습니다.
그래서 이런 부분들을 바탕으로, 저도 object detection과 segmentation을 multi-task learning 관점에서 함께 다룰 때, 서로 간에 충돌하거나 방해가 되는 요소는 어떻게 해결하고, 서로 닮은 점은 어떤 방식으로 공유하고 있는지를 좀 더 자세게히 관찰해보고 앞으로의 실험 방향에 인사이트를 얻고자 이 논문을 읽게 되었습니다.
물론 depth estimation과 object detection 사이에는 segmentation처럼 공통된 부분을 서로 뭔가 자연스럽게 공유할 수 있는 지점이 많지는 않지만 이번 논문을 통해 multi-task 학습 구조에서 서로 다른 태스크 간의 정보 교류를 어떤 방식으로 설계했는지, 그리고 task 간 간극을 줄이기 위해 어떤 장치들이 사용되었는지를 살펴보는 것만으로도 충분히 얻을 점이 많을 것이라 판단했습니다.
리뷰 시작하도록 하겠습니다. 그리고 DINO 아키텍쳐에 대한 자세한 설명은 들어가 있지 않기 땜누에 해당 논문을 읽기 전에 DINO 논문이나 리뷰를 읽고 오시면 좋을 것 같습니다.(http://server.rcv.sejong.ac.kr:8080/2022/11/28/cvpr-2022-dino-detr-with-improved-denoising-anchor-boxes-for-end-to-end-object-detection/)
intro
컴퓨터 비전 분야하면 제일먼저 떠오르는 기본적인 2가지 태스크라고 하면 object detectionrhk image segmentation이 떠오를 것 같습니다. 물론 아직 이 두가지 밖에 모릅니다.
두 태스크 간에는 뭔가 비슷한 부분도 있지만 엄청 다른 부분도 있습니다.
예를 들어 두 태스크 모두 이미지 내에서 관심이 있는 객체를 localize하는데 초점을 두고 있지만 그 localize를 하기 위해 두 태스크는 그 초점을 두는 수준이 많이 다릅니다.
좀더 풀어서 설명하면 객체 검출은 관심있는 객체들을 찾고 활용해서 그들의 bbox와 카테고리 라벨을 예측을 하는 것인 반면 세그멘테이션은 서로 다른 sematic 정보에 따라 픽셀 단위의 어떤 그룹화를 수행하는 작업이라고 보는 점에서 어떤 관심있는 영역을 찾는다는 목적은 같지만 그 과정이 엄청 다릅니다.
- Detection은 object-level의 coarse한 시멘틱 정보에 의존
- Segmentation은 pixel-level의 fine-grained한 시멘틱 정보를 더 깊게 활용합니다.
크게보면 어떤 관심있는 부분을 찾고자 하는 관점에서 위 둘이 하고자 하는 목적은 같기 때문에 위 둘을 동시에 수행하고자 하는 연구가 수행되었습니다. 대표적으로 성공적으로 위 둘을 통합하는데 성공한 사례(detection 성능도 오르고, segmentation의 성능도 오르고)가 CNN기반 모델에서의 Mask R-CNN, HTC가 있지만 transformer 기반 모델에서는 두가지 태스크가 성공적으로 통합된 사례가 존재하지 않습니다.
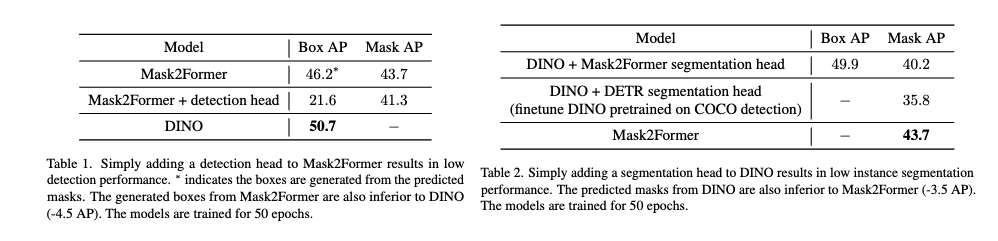
그래서 저자는 transformer 기반 모델들도 CNN기반 모델들 처럼 두가지 태스크가 통합된 아키텍쳐를 통해서 탐지와 세그멘테이션이 서로 도움을 줄 수 있을 것이다라고 믿고 여러가지 실험을 하였지만, 위 테이블과 같이 DINO(detection 하는 친구)를 세그멘테이션을 단순히 사용하거나 Mask2Former(segmentation하는 친구)를 detection에 사용하는 실험결과가 그리 좋지 않은 것을 볼 수 있습니다.
table 1번의 두번째 칸을 보시면 세그멘테이션 모델에 detection헤드(DINO 방식 활용)를 붙혀서 멀티 태스크를 수행했을 때의 결과를 보시면 박스 성능도 떨어지고 마스크 성능도 떨어지는 것을 확인하실 수있는데 특히 박스 성능이 엄청 떨어지는 것을 볼 수 있습니다. Mask2Former라는 친구는 세그멘테이션하는 친구라 저 Box AP를 측정할 때 Box를 마스크결과로 생성한 것이라 공정한 비교는 어려울 수 있겠지만 DINO라는 친구의 Box성능과 비교했을 때 이것보다 좋지 않기 때문에 기존의 탐지모델과 기존의 세그멘테이션 모델보다 성능이 좋지 않으며 오히려 박스 성능은 처참하게 하락된다 라는 분석을 할 수 있습니다.
반대로 table 2 같은 경우는 detection 모델에 세그멘테이션 헤드를 붙혀서 비교를 했는데 이부분에서는 두번째 세번째 모두 다 기존 segmentation만 수행하는 모델에 비해 mask성능이 떨어지는 모습을 확인하실 수 있습니다.
단순히 탐지와 세그멘테이션 작업을 함께 학습하는 naive한 멀티 태스킹 러닝은 오히려 앞서 말씀 드렸던 둘은 객체를 localize하는데 초점을 두고 있지만 그 localize를 하기 위해 두 태스크는 그 초점을 두는 수준이 많이 다르기 때문에 오히려 원래 각각의 작업 성능을 저하시킬 수 있습니다.
그래서 저자는 위 문제들을 해결하고자 Mask DINO를 제안합니다.
위 모델은 단순하기 설명드리면 DINO를 기반으로 기존의 박스 예측 헤드 외에 마스크 예측 헤드를 병렬로 추가한 구조, 아까 Table2 의 실험세팅과 비슷하다고 볼 수 있습니다.
이따가 메서드 파트에서 자세하게 얘기하겠지만 큰틀에서 설명을 잠깐 드리면 기존의 DINO 방식에서 사용되는 Learnable한 content query embedding을 재활용을해서 이를가지고 segmentation을 수행하는 방식으로 설계가 되어있습니다.
하지만 DINO는 픽셀단위로 regression 하는 것이 아닌 region level에서 대략적인 위치 추정에 최적화되어 있어있기 때문에 segmentation을 추가적으로 수행 하기 위해서는 pixel embedding과 상호작용하는 별도의 설계가 필요합니다.
그래서 저자는 detection 과 segmentation 사이에서 발생할 수 있는 어떤 간극(?)을 메꾸기 위해서 여러가지 구성 요소들을 설계하고 적용을 하게되는데 이것 또한 메서드 파트에서 자세하게 다루도록 하겠습니다.
결국 이 논문의 contribution은 3가지로 정리가 되는데,
- 객체 탐지와 세그멘테이션 모두를 위한 통합 transformer 기반의 프레임워크를 개발했다는 것
- 탐지와 세그멘테이션이 서로 통합된 아키텍쳐와 둘을 고려한 학습 방식을 통해 둘이 서로 도움을 줄 수 있음을 실증적으로 보여준다는 것(기존 모든 모델의 개별 성능을 능가)
- 그리고 데이터셋 관점에서 세그멘테이션을 수행하는데 있어서 대규모 detection 데이터셋에서의 사전학습의 혜택을 받을 수 있다는 점.( detection 데이터셋으로 사전학습을 수행을 하니 Mask DINO에서segmentation 성능도 자연스럽게 오름)
Method
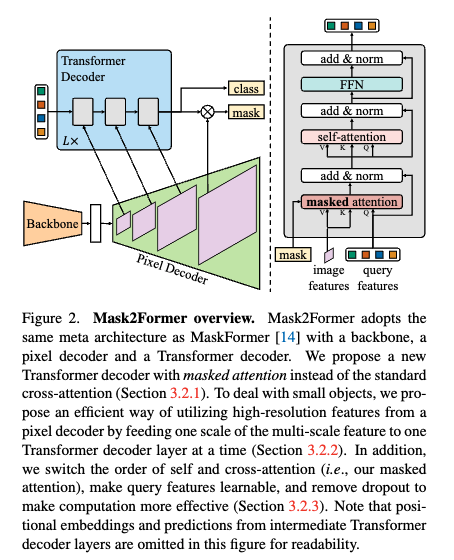
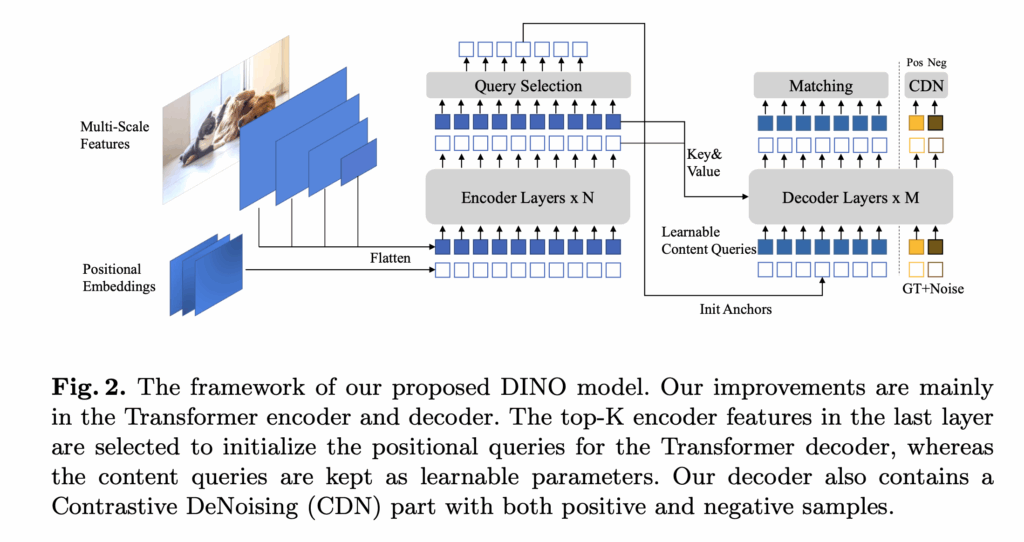
먼저 Method 파트를 설명하기 전에 Mask2Former와 DINO 가 구조적으로 어떻게 다른지 잠깐만 짚고 넘어가도록 하겠습니다. 첫번째 그림이 Mask2Former이고 두번째가 DINO입니다.
먼저 Mask2Former는 디코더 쿼리를 사용해서 고해상도 픽셀 특징 맵들과 내적(dot-product)을 수행하면서 마스크를 생성하는 구조라고 이해하기면 될 것 같습니다. 즉, 쿼리 하나하나는 전체 feature map과의 유사도를 기반으로 pixel-level에서 해당 인스턴스가 존재하는 영역을 추정하는 것에 포커스를 두고 있습니다. 하지만 이 방식은 쿼리가 픽셀 간 유사도만으로 인스턴스를 구분하려다 보니, 객체의 정확한 위치나 범위를 region-level로 명확히 파악하는 데는 한계있습니다.
반면에 DINO는 DETR과 거의 유사하게 쿼리를 통해 bounding box를 직접 회귀하도록 설계되어 있습니다. 이 쿼리들은 저 수준의 세밀한 픽셀 정보와 직접적인 뭔가 상호작용은 하지 않도록 설계되어 있고, 대신 객체의 위치 정보와 고수준의 시멘틱 정보를 활용해서 객체-level에서의 탐지에 포커스를 두고 있습니다.
이처럼 Mask2Former와 DINO는 모두 transformer 기반이지만, 쿼리가 동작하는 방식과 초점이 아예 다르기 때문에, 단순히 구조만 합친다고 해서 두 작업이 자연스럽게 서로를 도와주는 결과로 이어지지 않는다는 점이 중요한 포인트이고 Mask DINO는 이러한 차이를 가지고, DINO의 detection 아키텍처를 최대한 유지하면서도 segmentation이 잘 되도록 최소한의 설계 확장을 적용한 모델이라고 보시면 될 것 같습니다.
아래에서는 Mask DINO의 핵심 구성 요소들을 순서대로 살펴보겠습니다.
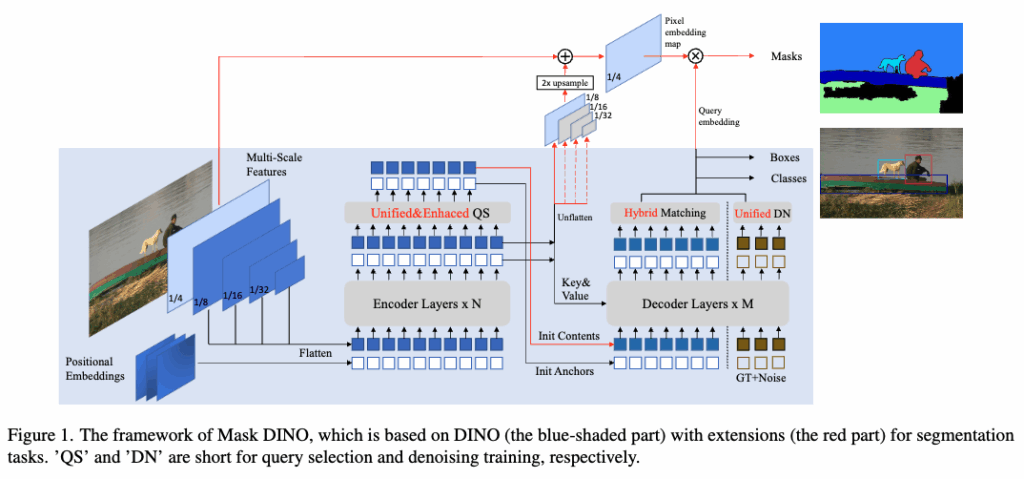
1. Segmentation Branch
Mask DINO는 기존 DINO 구조에 Segmentation을 위한 마스크 브랜치를 추가합니다.
이 브랜치는mask2former와 같이 instance, semantic, panoptic segmentation 등 다양한 태스크를 수행할 수 있게 설계되어 있다고 보시면 될 것 같습니다.
그런데 문제는, 앞서 계속 얘기드렸던 것 처럼 DINO 자체가 pixel-level의 alignment를 고려하지 않은 구조라는 점인데, DINO의 positional query는 anchor box 중심으로 설계되어 있고 content query는 box offset과 object class를 예측하는 데 초점이 맞춰져 있기 때문에 pixel-level 마스크를 예측하기엔 정보가 부족합니다. 그래서 Mask DINO는 여기서 Mask2Former의 핵심 아이디어를 가져옵니다.바로, pixel embedding map을 생성해서 쿼리와 내적을 통해 마스크를 예측하는 구조입니다. 이 embedding map은 아래 두 가지 특징 맵을 더해서 만들어집니다.
- 백본에서 나온 1/4 해상도의 feature map C_b
- Transformer 인코더에서 나온 1/8 해상도의 feature map C_e(업샘플링됨)
이것들을 결합한 후에 디코더에서 나온 각 content query q_c와 dot-product를 수행해서 마스크 m을 출력하는 방식입니다.
m = q_c \otimes M(T(C_b) + F(C_e))여기서 T는 C_b의 채널을 transformer hidden dim으로 바꿔주는 conv layer, F는 C_e를 2배 업샘플링하는 interpolation 함수 M은 segmentation head라고 보시면 됩니다.
사실 정말 segmentation branch는 정말 간단하게 구현되어있습니다.
2.Unified Query Selection
기존 DINO에서는 디코더에 넣어줄 content query를 위해 anchor 기반 positional query만 초기화해줬다면 (즉 원래 DINO에서는 content quey를 랜덤 초기화 함) Mask DINO는 여기에 segmentation을 고려한 content query 를 초기화하는 방식까지 추가해서 쿼리를 좀 더 잘 선택할 수 있도록 설계를 했다고 보시면 될 것 같습니다. Transformer 인코더의 출력은 사실 굉장히 풍부한 정보를 가지고 있기 때문에 이걸 그냥 지나치지 말고 쓸 수 있게끔 디코더에 제공할 더 나은 prior 정보로 활용하면서 인코더 출력에서 세 가지 예측 헤드를 추가합니다.
- classification head
- detection head
- segmentation head
이 각각은 그림에는 나와있지 않지만 디코더의 헤드와 동일한 구조를 가지고 있고 이 헤드들을 통해 각 토큰에 대해 confidence score를 구해서 이걸가지고 상위 점수를 받은 토큰들을 content query로 선택하게 됩니다. 선택된 쿼리는 이후에 디코더를 거쳐서bounding box를 직접 regression 하고
pixel embedding과 내적해서 마스크를 예측합니다.
어떻게 보면 위 과정이 기존 DINO와 Mask DINO의 가장 큰 차이점 중 하나이기도 합니다. (anchor query 뿐 아니라 content query까지 초기화되는 구조)
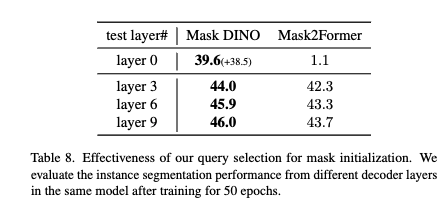
table 8 같은 경우는 Mask DINO의 쿼리 selection 방식 덕분에 layer 0단계에서도 이미 준수한 마스크 예측 성능을 발휘하는 것을 볼 수 있습니다.
3. Mask-Enhanced Anchor Box Initialization
이 부분을 읽다가 새로알게 된 부분이 있었는데, 초기 학습 단계에서는 마스크가 박스보다 예측이 더 잘 된다는 점입니다.
논문에서 말하길 왜냐면 마스크는 단순히 쿼리와 pixel feature 간의 내적을 통해 만들어지는 반면, 박스는 4개의 좌표를 직접 회귀해야 하기 때문에 학습이 난이도가 더 어렵다고 합니다. 그래서 Mask DINO는 이러한 부분을 활용합니다.
먼저 마스크를 예측한 다음 마스크가 초기에 학습이 더 잘되니깐 초기 학습 잘된 마스스킹 정보를 활용하자해서 그 마스크로부터 bounding box를 역으로 추론해서 anchor box로 초기화해주는 구조로 설계를 합니다.
결과적으로 위와 같은 구조는 detection과 segmentation 간의 태스크 간 협력(task cooperation)을 할 수 있게끔 하고 결국 detection 성능을 향상시키는 데도 크게 기여하게 됩니다.
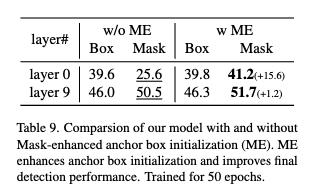
위 테이블을 보시면 Mask로부터 도출한 앵커 박스를 탐지 쿼리로 초기화에 사용했을 때 박스 예측에 있어서 성능이 향상되는 것을 알 수 있습니다.
4.Unified Denoising for Mask
기존 DINO에서는 쿼리 디노이징(query denoising)이라는 기법을 사용해서 탐지 성능 향상에 기여를 합니다. 이건 GT 박스나 레이블에 노이즈를 섞어서 transformer 디코더에 넣고 모델이 이 노이즈를 복원하면서 학습되도록 하는 방식입니다. 근데 Masl DINO에서는 더 나아가 이 디노이징 학습을 segmentation까지 확장합니다.
구체적으로는 박스를 마스크의 거칠고 noisy한 표현으로 간주하고 박스를 입력으로 주고 마스크를 예측하는 방식으로 학습이 이뤄지게 됩니다.
즉, fine-grained한 마스크 GT에 coarse한 박스를 노이즈로 던져주고 복원하게 하는 구조라고 이해하시면 됩니다. 이 과정은 segmentation 성능뿐 아니라 detection과의 cooperation 측면에서도 도움을 주게 됩니다.
5. Hybrid Matching
기존의 DINO나 DETR은 Hungarian matching을 통해 classification loss + box loss를 기준으로 쿼리와 GT를 매칭해왔는데,
Mask DINO는 여기에 mask loss까지 추가해서 3가지 요소로 손실함수을 정의합니다. 즉 기존의 hungarian 매칭 손실함수에 단순히 Maks loss만 추가한 형태라고 보시면 됩니다.
\lambda_{cls} \cdot L_{cls} + \lambda_{box} \cdot L_{box} + \lambda_{mask} \cdot L_{mask}전체적으로는 단순하지만 multi-task 구조에서 두 작업이 어떻게 자연스럽게 협력할 수 있을까에 대한 해결 설계들이 잘 녹아있는 아키텍처라고 생각이 들었습니다.
Experiments
Mask DINO의 성능을 아래 크게 보면 두가지 태스크에서 비교실험을 했고 segmentation에서는 좀더 세분화해서 성능비교 실험을 진행하였습니다.
- Object Detection
- Instance Segmentation
- Panoptic Segmentation
- Semantic Segmentation
1. instance segmentation & object detection
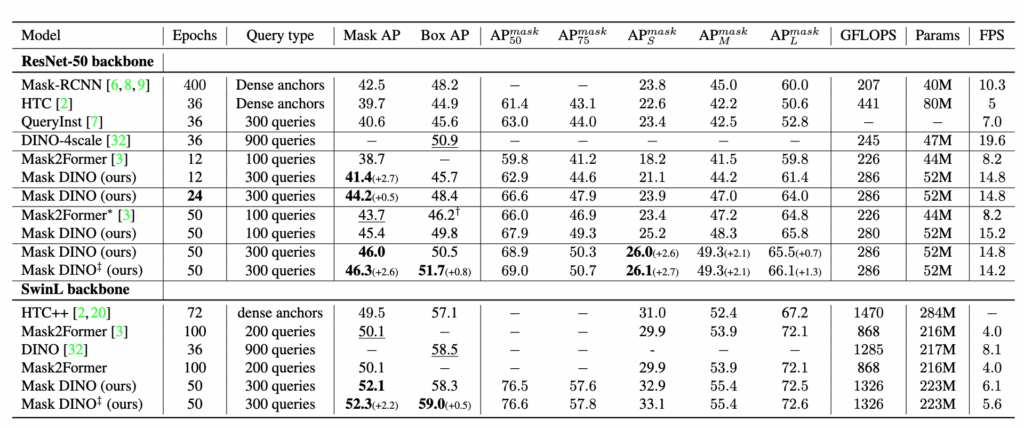
먼저 가장 기본적인 instance segmentation과 detection 성능부터 살펴보면 Mask DINO는 기존의 대표적인 단일 태스크 모델들보다도 성능이 높게 나왔습니다. 12epoch 기준으로도 Mask2Former보다 +2.7 AP 높았고 50epoch 기준으로는 +2.6 AP 더 높았습니다.
중요한 건 Mask2Former가 segmentation에 특화된 모델이라는 점을 감안했을 때 segmentation 성능이 더 높은 것은 물론이고 탐지 성능 또한 DINO보다 +0.8 AP 더 높았다는 것을 보실 수 있습니다. 게다가 수렴속도도 훨씬 빠릅니다.(24epoch만에 44.2 AP, Mask2Former의 50epoch 결과보다 높음)
또 앞서 설명드린 mask-enhanced box initialization 기법을 적용하면 탐지 성능이 추가로 +1.2 AP 더 올라가는 걸 확인할 수 있었습니다. 이 결과는 단순히 멀티태스크를 병렬로 수행하는 게 아니라 서로가 서로를 보완하는 구조로 잘 설계되었음을 보여주는 결과라고 볼 수 있습니다.
2. Panoptic Segmentation
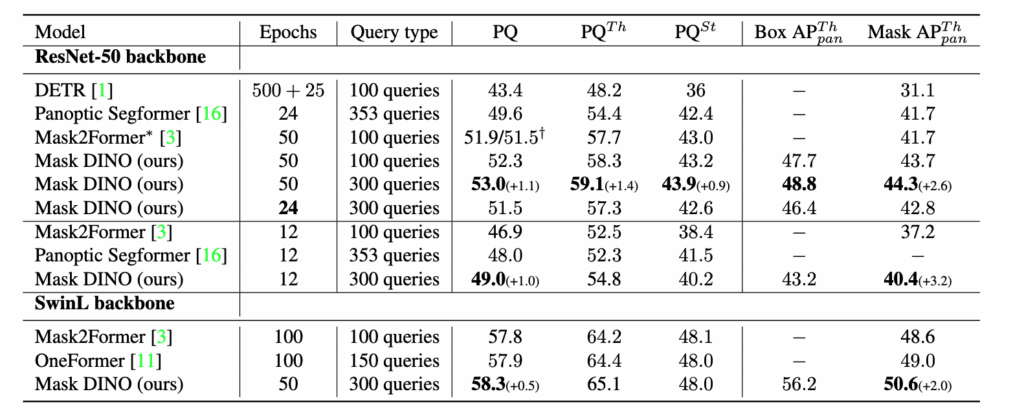
Panoptic 실험에서도 일관된 성능 향상이 나타났습니다. PQ 기준으로도 +1.0, +1.1 향상이 있었고, 특히 Mask2Former보다 PQTh, PQSt 모두에서 높은 성능을 기록한 것을 보실 수 있습니다. 추가로 Panoptic Mask AP (APThpan) 도 Mask2Former보다도 +0.6 AP 더 높은 성능을 보여줍니다.
3. Semantic Segmentation
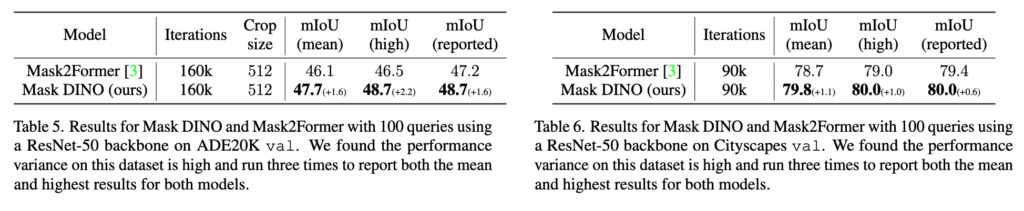
sementic segmentation또한 둘 다 Mask2Former 대비 더 좋은 성능을 기록했습니다.
4. 최신 모델들과의 비교
이번에는 스케일을 좀 더 키워서 Swin-L 백본 + Objects365로 사전학습된 DINO 기반에서 Mask DINO를 파인튜닝한 실험 결과를 살펴보도록 하겠습니다.
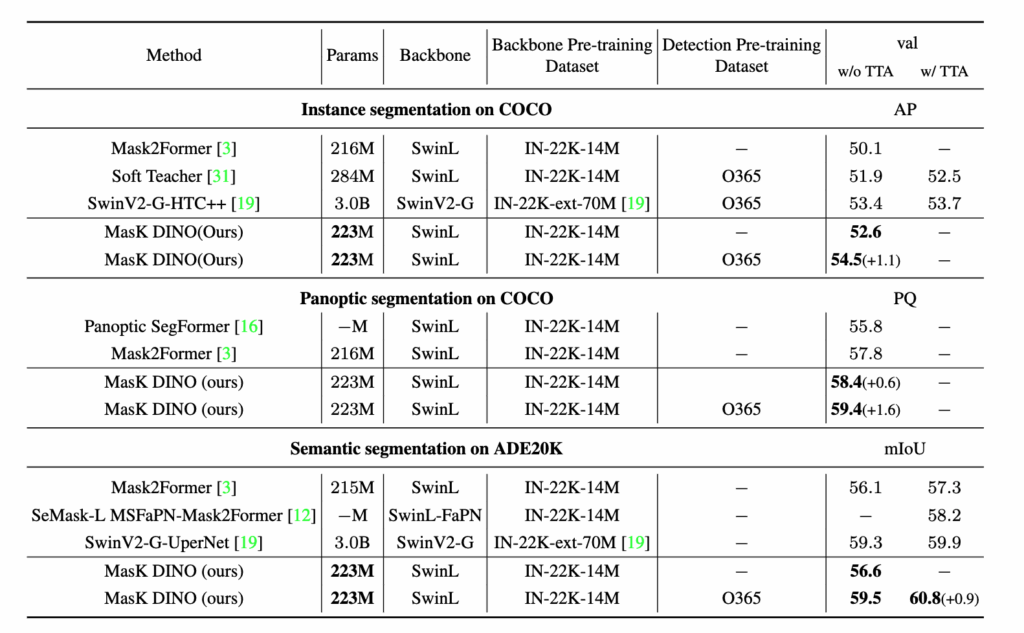
사실 해당 논문은 2023년에 나온 논문으로 그 당시 성능을 비교하는 테이블 입니다.
먼저 백본을 SwinV2-G을 사용한 초대형 모델과 비교하면 모델 크기는 1/15 수준, 사전학습 데이터는 1/5 수준밖에 안 되는데도 비슷하거나 더 좋은 성능을 기록한 것을 볼 수 있습니다.
5. Ablation Study
멀티 스케일 특징 활용
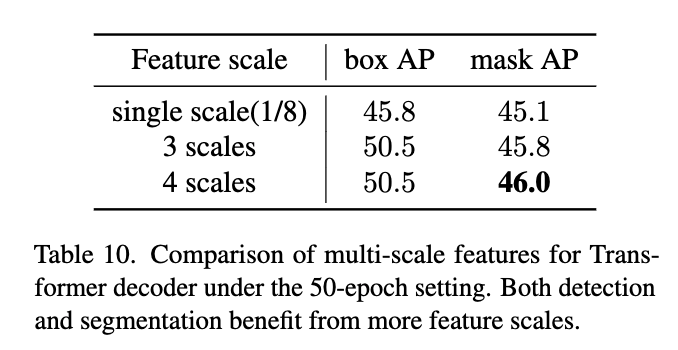
Mask2Former는 multi-scale feature가 큰 효과가 없다고 나와있지만
Mask DINO는 오히려 다중 스케일 특징을 활용할수록 성능이 증가하는 것을 확인하실 수 있습니다. 이건 아마도 Mask DINO가 detection 기반 구조이기 때문에
scale에 따른 위치 정보를 좀 더 잘 활용하는 구조여서 그런 게 아닐까 싶습니다.
bbox와 Mask의 coorperation
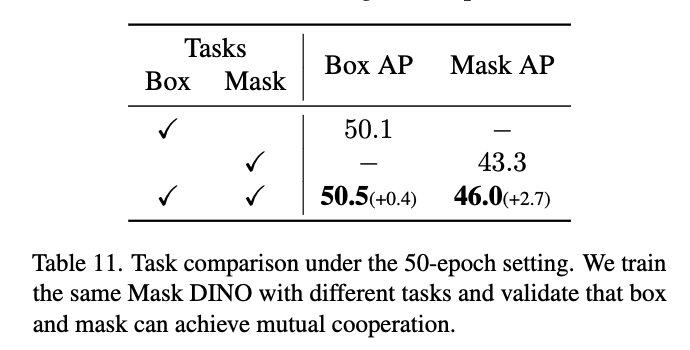
Table 11에서는 한 작업만 학습했을 때와 두 작업을 함께 학습했을 때를 비교하는 테이블 입니다. 논문에서 말하길 단일 태스크만 학습하면 성능이 빠르게 수렴되긴 하지만, 위 표를 보시면 결과적으로는 같이 학습한 경우보다 최종 성능이 떨어지는 결과를 보실 수 있습니다. 그래서 결국 task cooperation의 이점을 보여주면서
멀티태스킹이 단순히 효율성만 좋은 게 아니라 성능 자체에도 도움을 줄 수 있다는 걸 보여줍니다.
안녕하세요 우현님!
좋은 리뷰 감사합니다!
막연하게 두가지 태스크를 동시에 한다면 성능향상이 있겠지라고만 생각했지 단순히 둘을 이어붙였을 때 성능이 떨어진다는 것도 두 테스크 간의 어떤 차이가 존재하는지, 이 간극을 어떻게 하면 메꿀 수 있을지를 알지 못했는데 덕분에 알게 되었네요!
그리고 질문이 하나 있는데요! Detection 데이터셋을 대량으로 가지고 사전학습하는 것이 segmentation에도 크게 도움이 된다고 introduction 에서 설명해주셨는데요 이때, 사전학습은 detection task만 수행하는 건가요?
안녕하세요 지연님 댓글 감사합니다.
contribution 3번에 적어놓은 부분에 대한 질문을 해주신 것 같습니다!
일단 답변을 드리자면 맞습니다. 일단 사전학습으로 사용되는 object365 데이터셋은 segmentation gt가 없기 때문에 동시에 학습시킬 때 사용될 수는 없습니다. 그리고 대규모 segmentation 데이터셋은 부족하고 비용이 큰 반면에 detection 데이터셋은 object365, coco 등 대규모로 존재합니다. 그래서 탐지로 사전학습을 먼저 수행하고 이를 segmentation에 전이학습하는 구조는 데이터 효율성과 확장성 모두에 유리하다 라는 것을 얘기하는 것입니다. 또 최신 모델들과의 비교 테이블에서 detection 데이터셋으로 사전학습을 진행했을 때와 안했을 때의 성능 차이도 확인해 보실 수 있습니다!
감사합니다.
좋은 리뷰 감사합니다. 제가 segmentation쪽은 잘 모르기도 하고, 여러 perception task를 통합적으로 동작하는 프레임워크 쪽 연구를 follow-up하지 않아서 그런가 굼긍한 점이 있는데요, segmentation-detection을 묶으려는 방법론들을 볼 때마다 ‘segmentation을 아주 잘 하면 그냥 min, max 픽셀 좌표로 박스를 만들면 되지 않나? 굳이 box regression과 panoptic segmentation을 별도로 동시에 수행하도록 해야 하는 이유가 뭘까?’라는 생각이 들었습니다. 혹시 관련해서 detection과 segmentation을 별도로 했을때의 장점이 따로 있나요? 되게 기본적인 질문인데 제가 이쪽을 잘 몰라서 그런지 문득 궁금합니다.
감사합니다.
안녕하세요 재연님, 좋은 댓글 감사드립니다.
주신 질문이 단순한 기술 구현을 넘어서 왜 Detection 과 Segmentation을 명시적으로 분리해서 학습하고 예측하려고 하는지Perception 프레임워크 설계 철학에 가까운 질문인 것 같습니다..
“마스크가 있다면 박스는 쉽게 만들 수 있지 않나?“라는 생각은 자연스럽게 드는 의문점일 수 있다고 생각합니다.
사실 여기에는 제 개인적인 사견이 들어가 있어서 정확하지 않을 수 있다는 점 먼저 말씀드리고 답변 드리겠습니다.
먼저 해당 답변을 드리기 전에 마찬가지로 panoptic 하나로 모든걸 해결할 수 있는데, segmentation을 왜 3가지로 분리했는지에 대한 의문점도 드셨을 거라고 생각합니다.
해당 부분도 재연님이 궁금했던 부분과 밀접하게 관련이 있을 거라 생각해 이에 대해 먼저 말씀드리면,
sementation 태스크에서보면 panoptic segmentation만 할 줄 알면 이거만 가지고instance segmentation, sementic segmentation 둘 다 수행할 수 있습니다.
근데 이렇게 3가지고 분리하는 이유가 3가지가 각각 다른 목적을 가지고 있기 때문이라고 볼 수 있습니다.
예시로 들면 로봇 팔로 어떤 사물을 잡을 때 물체를 1개씩 구분해서 좌표를 뽑는게 목적이라면 이 경우에는 배경이 필요 없으니깐 instance segmentation이면 충분할 수 있고
또 자율주행 같은 경우에는 도로나 차선 보행자가 다니는 공간을 넓게 분할해야하기 때문에 인스턴스보다(ID)보다 사람자체, 도로, 차선, 인도 이런 부분만 알면 되므로 이 경우에는 sementic segmentation 더 간단하고 효율적일 수 있습니다.
그래서 결국에 재연님께서 주신 질문에 해당하는 답변이 후자에 가까울 수 있다라고 생각은 하는데요,
물론 object detection 같은 경우도 각 박스마다 ID가 존재하기 때문에 instance 구분이 가능합니다만 이 관점이 아니라 둘의 목적성을 보았을 때 좀더 해당 상황에서 효율적이고 적합한게(학습난이도, 모델의 크기, 연산 비용 등등) 무엇일까를 고려한다면 둘을 왜 나누었는지 이해하기 편하실 것 같습니다.
결과적으로 포괄적인 방법이라고 해서 항상 적절한 방법은 아닌 것 같다 라고 저는 생각합니다. 필요에 따라 더 단순한 sementic 혹은 instance segmentation 혹은 object detection이 적합한 상황이 존재한다고 생각하고 실시간성, 정확도, 데이터 특성들을 고려해서 task를 선택해야하기 때문에 이렇게 나뉘지 않았나 싶습니다.
그리고 위가 아니라면 물론 단순히 목적의 차이도 있을 수 있지만 기술적 제약이 중요한 요인으로도 작용했을 가능성도 있다고 생각하빈다. 예를 들어 annotation 과정에서만 보더라도, 픽셀 레벨에서의 라벨링이 필요한 segmentation은 작업 난이도와 비용이 훨씬 높은 반면에 bbox 기반의 object detection은 비교적 라벨링이 간단합니다.
실제로 먼저 둘중에 어떤 태스크가 먼저 나왔는지를 찾아보았는데 object detection같은 경우 deep learning 시대 이전(2001)부터 존재를 했고 segmentation 같은 경우에는 딥러닝 시대(2014)에 들어가서야 본격적으로 연구된 태스크입니다. 따라서 그 당시 상황을 보았을 때 segmentation과 같은 pixel 단위로 라벨이 있는 태스크의 라벨을 생성하기에는 사실 어려움이 존재하기 때문에 상대적으로 annotation이 쉬운 object detection이 먼저 수행되었을 수도 있겠다라고 생각합니다. 그래서 그런 현실적인 제약 속에서 먼저 구현 가능했던 태스크가 선택이 되었고 이후에 모델 성능이나 하드웨어 성능이 점차 발전되면서 점점 더 복잡한 태스크들로 확장되었을 수도 있겠다 라는 생각도 듭니다.
답변이 잘 되었는지 모르겠습니다.
감사합니다!
안녕하세요 우현님 리뷰 감사합니다
학습 초기에 마스크가 bbox 보다 더 예측에 유리하다는 사실이 흥미롭네요, 생각해보지 못 했던 부분입니다. 그런데 마스크로부터 bbox를 역으로 추정한다는 것은 그냥 마스크 크기에 맞춰서 bbox를 그리는 식으로 진행하나요? 아니면 따로 수식이 있을까요??
안녕하세요 영규님 좋은 댓글 감사합니다.
저도 학습 초기에 마스크가 bbox 보다 더 예측에 유리하다라는 부분이 되게 흥미로웠습니다!
마스크로부터 bbox를 역으로 추정한다는 것은 그냥 마스크 크기에 맞춰서 bbox를 그리는 식으로 진행하나요?에 대한 답변을 드리자면 질문하신 내용이 맞습니다!
초기에 마스크가 박스보다 상대적으로 예측이 유리하기에 해당 마스크의 min max 값을 가지고 박스를 추정합니다.
감사합니다.
안녕하세요 우현님
좋은 논문 리뷰 남겨주셔서 감사합니다!
Segmentation Branch가 굉장히 간단하게 구성되어 있음에도 좋은 성능을 보인다는게 흥미로웠습니다.
저는 pixel embedding map에 관련해서 의문이 하나 들었습니다
현재는 backbone에서 추출한 1/4 해상도의 feature map과
encoder에서 추출한 1/8 해상도의 feature map을 upsampling해서 pixel embedding map을 만든다고 읽었습니다.
그런데 굳이 1/4 해상도를 사용해야하는 이유가 의문입니다.
더 upsampling해서 원본 해상도까지 올려서 더 세밀한 mask를 만들 수도 있을 거 같고,
아니면 1/8 해상도를 사용한다면 feature map을 upsampling하는 비용을 아낄 수도 있을 것 같다는 생각이 들었습니다.
논문에서 pixel embedding map에서 1/4 해상도를 선택한 이유가 특별히 있는지 궁금합니다.
감사합니다!