안녕하세요, 허재연입니다. 지난 주에 이어서 Video SGG논문을 가져왔습니다. SGG쪽 연구를 꾸준히 하시던 저자들이 ICLR2025에 게재한 논문이고, LLM 기반의 Weakly Supervised Learning 기법을 제안한 논문이라 읽어보았습니다. 리뷰 시작하겠습니다.

Scene Graph Generation은 보다 높은 수준의 장면 이해를 위한 task로, 이미지가 주어지면 해당 이미지의 물체를 검출하고 각 물체 간의 관계를 예측하는 것을 목표로 합니다. 이는 video, 3D 등의 데이터 형태에도 확장할 수 있는데, video에서는 비디오의 각 frame에 물체 및 이들의 관계가 annotation되어 있어서 모든 frame의 물체와 관계를 예측하는 형태로 연구 및 평가가 진행되고 있습니다. 비디오는 이미지와 다르게 추가적으로 temporal 정보를 갖고 있기에 이를 잘 모델링 하는 것이 중요합니다. 단순한 이미지 기반 SGG가 정적인(ex : standing on)같은 관계는 잘 예측하지만 동적인(ex : running) 관계는 잘 예측하지 못하기에, 비디오 프레임 전반의 시간적 맥락을 포착하고 동적인 관계를 예측할 수 있어야 보다 다양한 relation을 잘 예측할 수 있죠.
기존의 Video SGG(VidSGG)는 모두 fully-supervised로 학습되었는데, Video SGG는 task 특성 상 모든 frame에 대한 물체 및 이들의 관계 annotation이 필요하므로 당연히 라벨링 부담이 상당합니다. image 기반 연구에서는 최근 SGG의 높은 라벨링 비용 문제 때문에 Weakly Supervised Learning 연구가 등장했지만, 아직 video SGG쪽에서는 거의 연구가 되지 않았다고 합니다. 기존에 middle frame에 GT unlocalized scene graph가 주어졌다는 가정 하에 제안된 Weakly Supervised 기법이 있기는 했지만, 저자들은 middle frame에 GT scene graph가 주어진다는 가정 자체가 비현실적이고, 여전히 사람의 annotation이 필요하기에 본질적으로 labeling cost 문제가 해결되지 않았다고 합니다.
본 논문에서는, 사람이 라벨링한 scene graph 없이 Video SGG 모델을 학습하는 방법을 연구하였습니다. 일단 이를 위해 두가지 전략을 고려하게 됩니다.
첫 번째 방법은 zero-shot relation 예측이 가능한 사전학습된 Image SGG모델(ex : RLIP)를 비디오의 모든 프레임에 적용해서 각 프레임마다 pseudo scene graph를 얻는 방식입니다. 하지만 이런 모델들은 단일 이미지 상의 정적 관계를 위주로 학습했기에 보다 동적인 visual relationship을 예측하는 능력이 떨어진다는 한계가 있었습니다.
두 번째 방법은 Video Caption에서 언어적 정보를 supervision으로 활용하는 것입니다(아래 Figure 1.b 참고). 이는 2D 이미지 기반 SGG에서 자주 사용되는 방법으로 먼저 주어진 캡션을 <subject-predicate-object> triplet으로 파싱하고, 이 triplet을 주어진 장면에 grounding하는 방식입니다. 비디오의 경우 비디오 캡션을 파싱한 후에 이를 해당하는 frame에 정렬하는 작업이 필요하겠죠.
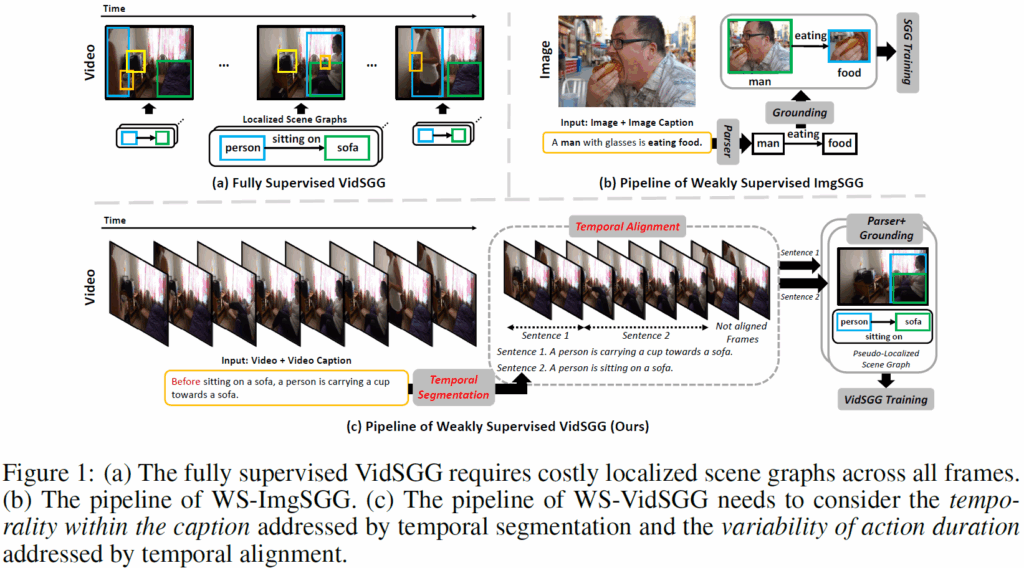
하지만 저자들은 Weakly Supervised Image Scene Graph Generation(WS-ImgSGG) 파이프라인을 VidSGG에 단순하게 바로 적용하는데는 다음의 2가지 문제점이 있다고 합니다.
Temporality within Video Captions
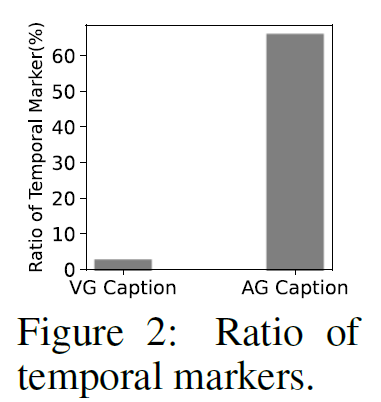
위 Fig.1(b)의 이미지 캡션과 다르게, 비디오 캡션에는 ‘before’, ‘while’, ‘then’, ‘after’와 같은 temporal marker가 많습니다. 이들이 가진 시간에 대한 정보를 고려하지 않고 나이브하게 학습을 진행시키면 모델에 틀린 정보를 정답 신호로 제공할 위험성이 있습니다. 위의 Figure1.(c)에서 캡션에 포함된 ‘before’를 무시하고 <persion, sitting on, sofa>라는 관계를 앞쪽 프레임의 학습에 사용한다면 모델이 잘못된 정답값을 가지고 학습을 하게 되겠죠? 통계적으로 ImgSGG에 대표적으로 사용되는 Visual Genome 데이터셋에는 temporal marker가 2%비율로 나타나지만, VidSGG에 사용되는 대표적인 데이터셋인 Action Genome의 캡션에는 65%정도의 비율로 포함되어 있다고 합니다. 따라서, 비디오 캡션을 활용하려면 여기에 포함되어 있는 temporal 정보를 적절히 활용해야 합니다.
Variability in Action Duration
또한, 비디오에서는 human action의 길이가 매우 다양하게 나타납니다. Figure1.(c)에서 sentence 1은 2개 프레임에 걸쳐 일어나지만, sentence 2는 4개 프레임에 걸쳐 일어납니다. 하지만 이런 행동 지속시간의 다양성을 무시하고 나이브하게 sentence 1을 앞 4개 프레임에, sentence 2를 뒤 4개 프레임에 정렬시키고 학습을 시킨다고 가정하면 3,4번째 프레임은 잘못된 annotation 정보를 가지고 학습이 진행되고 결국 이는 각 frame의 Scene Graph 예측 능력에 부정적인 영향을 미치겠죠. 각 action이 다양한 길이의 프레임에 걸쳐 발생할 수 있음을 반영해야 합니다.
이에 대해, 저자들은 Natural Language-based Video SceneGraphGeneration(NL-VSGG) 라는 weakly supervised VidSGG 프레임워크를 제안합니다. 해당 프레임워크는 VidSGG 모델 학습에 명시적인 scene graph 정답값을 활용하지 않고, 비디오 캡션만을 활용해 학습을 진행합니다. 프레임워크는 크게 TCS(Temporality-aware Caption Segmentation)모듈과 ADV(Action Duration Variability-aware Caption-Frame Alignment)모듈로 구성되는데, TCS 모듈은 LLM을 활용해 시간적 정보를 고려해서 비디오 캡션을 분할하고, ADV 모듈은 이렇게 분할된 캡션들을 action duration을 고려해 비디오 내 캡션들과 정렬합니다. 여기서 각 프레임에 대해 K-Means로 클러스터링을 수행하고, 각 캡션들을 해당 클러스터 중심과 유사도를 측정하여 클러스터 내 프레임들과 매칭하는 방식으로 캡션과 프레임들을 자동 정렬시켰습니다. 다양한 실험 결과, 이렇게 Weakly Supervised learning을 수행하는 방식이 1. 사전학습된 ImgSGG 모델을 사용하는 방법과 2. WS-ImgSGG 파이프라인을 그대로 VidSGG에 적용하는 것보다 좋은 성능을 보였다고 합니다.
저자들은 특히 Scene Graph annotation 없이 비디오 캡션이라는 언어적 정보만으로 VidSGG 모델을 학습할 수 있음을 최초로 보였다는 점을 강조합니다. 캡션을 활용해서 학습하기에 데이터셋에 포함되지 않은 넓은 범주의 action class도 예측이 가능하죠. 이에 대해 자신들의 contribution을 다음과 같이 강조합니다 :
- 우리는 이미지 기반 Weakly Supervised SGG 파이프라인을 VidSGG에 단순 적용하는데 방해가 되는 두가지 핵심 원인(비디오 캡션의 temporality, action duration의 다양성)을 밝혀냈다.
- 우리는 비디오의 캡션만을 활용해 VidSGG 모델을 학습시킬 수 있는, 간단하고 효과적인 weakly supervised learning 방법을 제안했으며, Scene Graph annotation 없이 캡션이라는 언어적 정보만으로 VidSGG 모델을 학습 시킬 수 있음을 최초로 밝혔다.
- 우리는 Action Genome에서 다양한 실험을 통해 제안하는 NL-VSGG가 우수함을 입증하였다.
Weakly Supervised Video Scene Graph Generation With Natural Language Supervision
해당 방법론에서는, 우선 비디오 V = {{I}^{1}, {I}^{2}, ... , {I}^{T}}와, 이에 해당하는 비디오 캡션 S가 주어졌다는 가정에서 학습을 진행합니다. 여기서 {I}^{t}는 비디오 V의 t번째 프레임이고, T는 총 프레임 수를 의미합니다. 이를 활용해 각 프레임 {I}^{t}에 대해 scene graph를 생성하는 것이 최종 목표입니다. 기존 VidSGG 방법론에는 학습 과정에서 각 물체의 위치 정보가 주어진 Scene Graph를 활용하였지만 제안하는 방법론에서는 grounding 정보 없이 학습을 진행하게 됩니다.
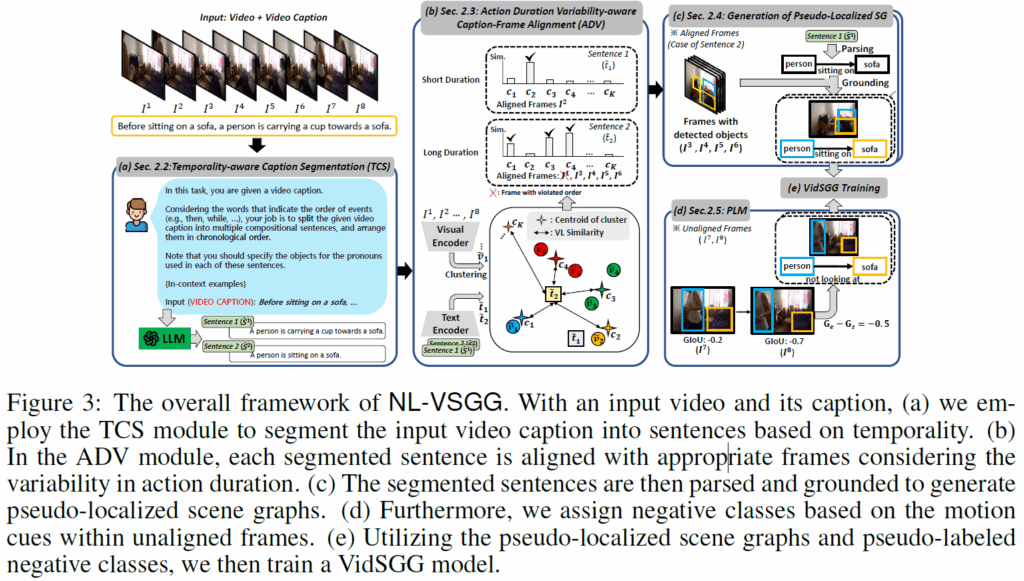
Temporality-Aware Caption Segmentation(TCS)
TCS 모듈에서는 비디오 내 action의 순서를 정확히 활용하기 위해 비디오 캡션 S를 시간 순서대로 분할합니다. 이 때 Figure3에서 확인할 수 있듯이 비디오 캡션의 시간 정보(temporality)를 인식할 수 있도록 작성된 prompt를 기반으로 LLM을 활용합니다. 프롬프트는 다음과 같이 작성되었다고 합니다.
우선 기본 지시문으로는 LLM에게 어떤 작업을 시킬 것인지 설명하고 비디오 내 action들의 시간 정보를 고려하도록 합니다 : “Your job is to split the given video caption into multiple compositional sentences and arrange them in chronological order”. 추가적으로 비디오 캡션에는 동일한 객체를 가리키는 co-reference 대명사 문제가 발생할 수 있으므로, 보다 정확하게 triplet을 추출하기 위해 추가적인 프롬프트를 추가합니다 : “Note that you should specify the objects for the pronouns used in each of these sentences”. 이 지시문에 추가적으로 LLM이 해당 task를 더 잘 수행할 수 있도록 예제를 몇개 첨부합니다. 이렇게 만들어진 프롬프트를 바탕으로, LLM에게 비디오 캡션 S를 시간 순으로 segmented sentences를 반환하라고 명령을 내립니다.

Action Duration Variability-Aware Caption-Frame Alignment(ADV)
캡션을 분할하였으면, 각 분할된 캡션들을 대응되는 프레임들과 정렬해주어야 합니다. 이 때 앞에서 말했듯 프레임과 이에 해당하는 캡션이 잘못 매칭되면 학습에 부정적인 영향을 미칠 수 있으니 action durability가 다양함을 고려해야겠죠(action의 길이가 다양하게 나타날 수 있으니 고정된 프레임으로 나누는 것은 피해야 합니다). 이를 위해서는 각 프레임 {I}^{1}, ... , {I}^{t}의 visual semantic 정보와 각 segmented caption의 textual semantics 정보가 얼마나 연관성이 있는지 추정하는 과정이 필요합니다. 여기에는 textual 정보와 visual 정보 간 유사도를 측정해야 하기 때문에 당연히 VLM을 사용하는데요, 여기서는 compositional reasoning 능력 때문에 DAC라는 CLIP을 변형한 VLM을 사용했다고 합니다. 각 이미지 프레임은 이미지 인코더를 거쳐 visual feature로 만들고, segmented caption은 텍스트 인코더를 고쳐 textual feature로 만든 다음 visual feature들에 대해 K-Means clustering을 적용하여 textual feature를 정렬시킬 수 있도록 K개의 cluster proposal을 만들어냅니다.
이후 정렬 방식에도 디테일이 있습니다. 가장 단순한 정렬 방법은 text feature와 cluster centroids 간 유사도를 계싼하여 가장 유사도가 높은 클러스터에 가까운 프레임들을 할당하는 것일텐데, 이 방법은 (Fiure 3의 sentence 2와 같이)action duration이 긴 경우 action duration의 가변성을 제대로 포착하지 못한다고 합니다.
이에 저자들은 지속 시간이 긴 action에 해당하는 caption은 여러 클러스터에 걸쳐 높은 유사도를 보이고 짧은 action의 경우 단일 클러스터에 집중하여 높은 유사도 분포를 보이는 것에 착안하여, 각 segmented caption의 feature에 대해 해당 클러스터 centroid와의 유사도를 내림차순으로 정렬한 후, 유사도 점수가 가장 급격하게 감소하는 지점을 찾아 이 지점 이전에 위치한 클러스터들을 선택해 이에 속한 프레임들을 text feature와 정렬시킵니다 . 유사도 점수가 급격하게 감소하는 지점이 action duration에 따라 관련된 클러스터 수를 결정하는 것이죠. 이 때 클러스터 수는 K = |V|/β로 설정했다고 합니다. |V|는 비디오 프레임의 수이고, β는 하이퍼파라미터입니다. 추가적인 후처리로, 시간 순서를 위반하는 모순된 alignment는 제거하게 됩니다.
Generation of Pseudo-Localized Scene Graphs
ADV 모듈을 통해 각 segmented caption과 이에 대응하는 프레임들을 정렬시켰습니다. 이제 모델 학습을 위해 pseudo-localized scene graph를 구성하게 됩니다.
Scene Graph parsing (caption -> triplet 변환)
먼저, 학습에 사용할 수 있도록 각 segmented caption을 <subject, predicate, object> triplet 형태로 변환합니다. 이때 LLM을 활용하거나, 전통적인 rule-based parser를 사용할수도 있습니다. 이때 아직 bounding box 정보는 정의되지 않았고, triplet <s,p,o>의 클래스도 classification class에 속하지 않을 수 있기에 parsing된 <s,p,o>의 각 class들을 action genome 데이터셋의 object, relation 클래스에 매핑시키는 과정이 필요합니다. 여기에서 WordNet의 동의어 집합(lemmas)와 상위어(hypernyms)기반의 정렬(alignment)을 활용하거나 LLM 기반의 정렬을 활용합니다. 이 과정을 통해 pseudo-unlocalized scene grpah를 얻습니다(클래스 매핑 과정을 생략하면 모델이 action genome 데이터셋에 정의된 클래스 외에 다른 action class까지 예측할 수 있게 됩니다).
Scene Graph Grounding
이제 bounding box를 예측하기 위해 사전학습된 object detector를 사용합니다. 이후 bounding box를 해당하는 주어, 목적어 클래스에 매핑시키고, subject와 object 사이에 predicate(action)을 할당해줍니다. 정렬된 프레임들 전체에 이렇게 grounding을 수행한 후 최종적으로 pseudo-localized video scene graph를 얻어냅니다.
이후, 이렇게 얻은 정답값을 활용해 기존의 방법론들(STTran, DSG-DETR)과 동일한 방법으로 학습을 진행하게 됩니다.
Experiment
저자들은 실험에서 GT video SG 정보 없이, Action Genome 캡션 데이터셋, MSVD 캡션 데이터셋, ActivitiNet 캡션 데이터셋을 사용하여 모델을 학습시켰습니다. AG caption 데이터셋의 경우 평균 길이 29.9초의 비디오 7,454(총 프레임 166,785개)를 사용하였으며, MSVD는 총 1,970(40,863개 프레임)개의 비디오, ActivitiNet은 총 4,640(569,836개 프레임)개 비디오로 구성된다고 하네요. Action Genome에는 36개의 object class와 25개의 action class가 있고, 특히 action class는 크게 attention, spatial, contacting 3개의 카테고리로 나눌 수 있습니다.
비교 베이스라인으로는 1. 학습 없이 각 프레임을 정적인 이미지로 간주하고 zero-shot ImgSGG를 수행하는 모델(RLIP, RLIPv2)을 사용한 zero-shot supervision, 2. GT localized video scene graph로 학습한 Full supervised(이건 성능의 upper bound로 볼 수 있겠죠. STTran과 DSG-DETR 모델을 사용합니다), 3. 기존에 제안된 GT unlocalized SG 기반의 방법론이 사용되었습니다. pretrained object detector는 기존의 PLA라는 방법론과 동일하게 VinVL을 사용했다고 합니다. 해당 모델의 백본은 ResNeXt-152 C4이고 confidence score 0.2 이상인 객체만 남겼다고 하네요. TCS 모듈에서는 LLM으로 ChatGPT의 gpt-3.5 turbo를 사용했고 ADV 모듈에서는 vision-language model로 DAC를 사용하였습니다. 클러스터 수 K를 정하는 하이퍼파라미터인 β는 4로 설정했다고 합니다.
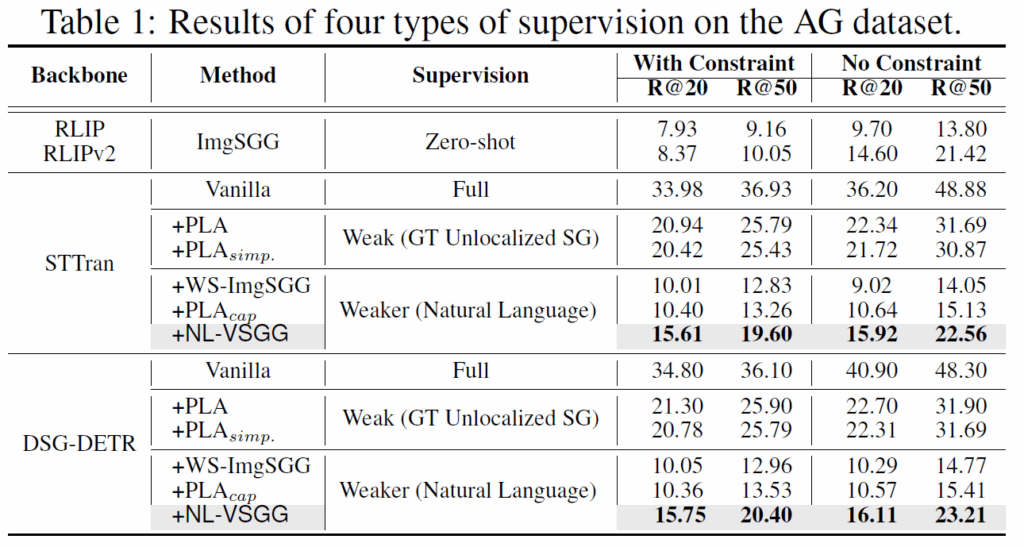
실험 결과, 제안 방법론인 NL-VSGG를 사용했을 때 비교 방법론들보다 훨씬 높은 성능을 달성합니다. LLM 기반 TCS를 통해 캡션을 시간 순서로 나누어 영상의 흐름을 반영해 학습이 가능하고, ADV 모듈을 통해 각 action의 지속 시간 차이를 고려해 프레임에 정렬시켜 noise를 줄인 것이 효과적이었다고 하네요.
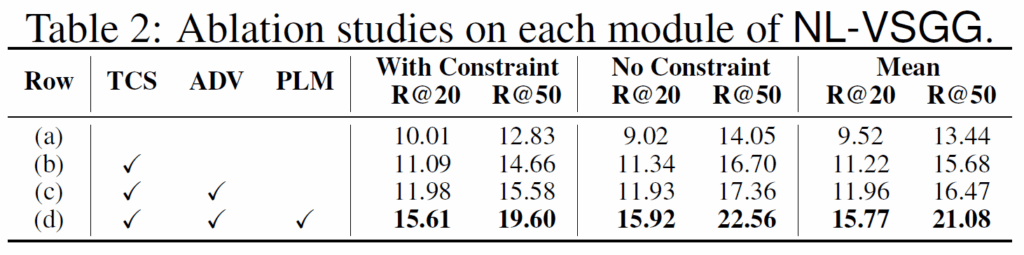
Ablation study에서는 각 모듈들의 효과를 나타내었습니다. 항상 그렇듯 모든 모듈을 함께 사용했을 때 좋은 결과를 보여줍니다. 해당 실험에는 STTran을 기본으로 사용하였다고 합니다.
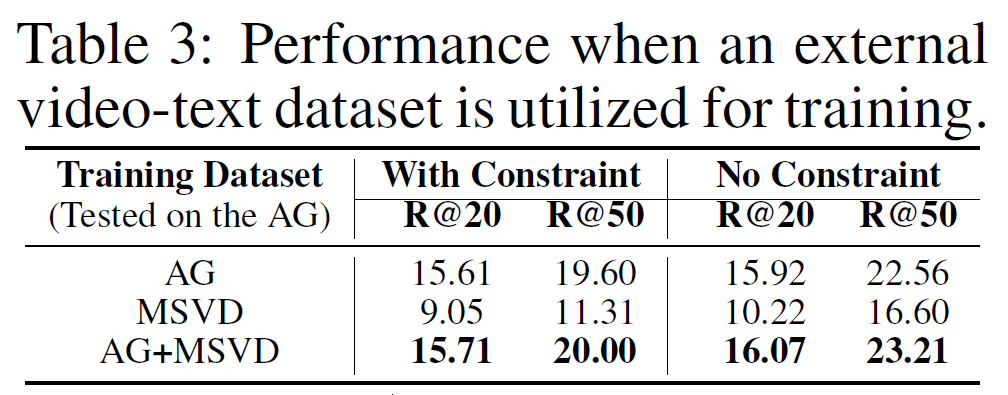
기존의 VidSGG는 Action Genome 데이터셋에 국한된 한계를 보였는데, 제안하는 NL-VSGG는 외부 video-text 데이터셋인 MSVD를 함께 사용했을 때 좋은 결과를 보여줍니다. action genome은 실내 위주의 장면이고, MSVD는 실외 장면을 포함하기 때문에 다양한 도메인의 video-text pair 수집이 도움이 될 수 있다고 분석합니다.
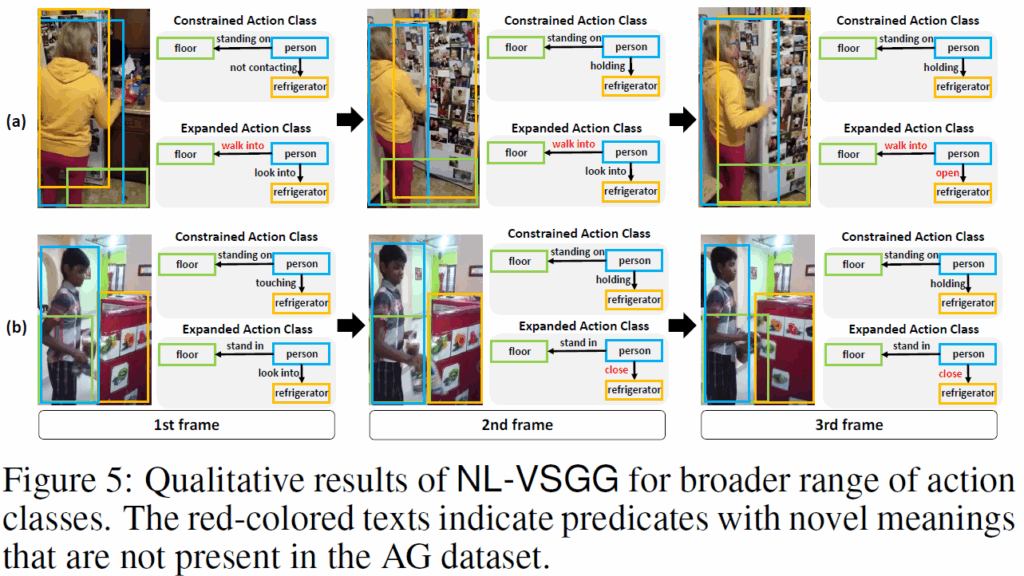
마지막으로, Figure 5에서는 학습 데이터(Action Genome)에 포함되지 않은 action class도 예측 가능함을 보여줍니다. 빨간색 텍스트는 AG데이터셋에 포함되지 않은 novel class predicate인데, video caption만을 사용하여 학습을 했기 때문에 어찌 생각하면 당연하게도 novel class에 대한 예측을 수행할 수 있습니다.
VidSGG에 최초로 Weakly Supervised를 적용한 논문을 살펴봤습니다. Image 도메인의 WS기법들을(LLM4SGG, GPT4SGG) video로 확장할 때 고려할 지점들에 대한 고민을 많이 한 듯한 논문이네요. 뭔가 detector나 시간 정렬 등의 부분에서 개선할 수 있는 지점들이 있을 것 같기도 합니다. 또 하나 느낀 게, 이제 LLM을 어디에 활용하면 효과가 있을지 고민해보는것도 중요하다는 생각이 많이 들었습니다. 모두 비전쪽만 보지 말고, LLM을 각자의 연구에 어떻게 접목할 수 있을지 생각해보면 좋을 것 같습니다.
감사합니다.