안녕하세요 2025년 ICCV에 accept된 Scene Text Recognition (STR) 논문 중 한 편인 SVTRv2을 가져왔습니다. 기존에 많이 사용됐던 CTC 기반의 방법론에 모듈을 추가해 트랜스포머 기반의 text recognizer를 능가하는 성능을 기록하는 모델을 제안한 연구입니다. 그래서 기존에 CTC 모델이 갖던 빠른 추론 속도, 간단한 구조의 장점은 그대로 가져가면서도 기존 CTC 기반 방법론들이 해결하기 못하던 걸 해결한 연구입니다. 아래에 바로 리뷰하겠습니다.
1. Introduction
스캔된 문서에 있는 텍스트를 읽는 것 보다 natural scene에서 텍스트를 인식하는 것이 더 어렵다. 배경이 복잡해 텍스트와 배경간의 분간이 어렵다거나 텍스트의 형태가 다양하다거나 글꼴도 하나로 정해진 게 없다는 이유가 있다. 이런 문제를 집중적으로 다룬 연구가 많았고 크게 제안됐던 text recognizer를 둘로 나눠보자면 CTC 기반의 방법론과 encoder-decoder (EDTRs) 기반의 방법론이 있다.
CTC 모델의 구조는 이렇다. 하나의 visual model이 있어 text image로 부터 feature 추출을 하고 CTC linear classifier 를 사용해 recognition 결과를 낸다. 직관적인 구조로 추론속도가 빠르다는 장점을 가진다. 이런 이유로 주로 상용화를 위한 OCR 모델로는 이 타입의 모델을 사용한다. 하지만 텍스트의 다양성에 대해서는 잘 다루지 못한다는 단점이 있습니다.
그래서 CTC가 갖는 이런 문제를 해결하기 위해 나온 것이 EDTRs 모델들이지요. 굽어 있거나, 방향이 여러 각도로 회전돼 있거나, 글꼴이 복잡하거나, occlusion이 있는 경우에도 그리고 다른 언어의 텍스트에도 보다 강건하게 인식할 수 있는 기술을 갖는다.
앞서 얘기한 CTC모델이 가지는 단점 즉 정확도가 EDTRs 보다 더 떨어지는 데에는 두가지 이유가 있다. 첫째, 비정형 텍스트에 대한 인식 정확도가 떨어진다. 보통 CTC는 왼쪽에서 오른쪽으로 수평방향과 거의 일치하게 정형의 텍스트에 대해서는 인식이 잘 되지만 그렇지 않은 경우에는 어려움이 있다. 둘째, EDTRs 과 다르게 텍스트가 갖는 의미 정보를 활용하지 않는다. CTC 자체로도 이런 문제를 해결하기 위해 비정형성을 완화할 수 있는 rectification을 추가하거나 2D CTC을 사용하거나, masked image modeling을 사용했다. 그럼에도 CTC와 EDTRs 간의 차이는 여전히 좁혀지지 않았다.
그리하여 이 논문의 저자는 비정형 텍스트도 잘 인식하고 텍스트의 의미 정보를 활용하도록 해 더 강력한 CTC 모델을 설계한 것이다. 1) 첫번째로 비정형 문제를 다루고자 visual feature 를 추출하고 나서 각 character에 대한 특징이 잘 정렬되도록 하는데 집중했다. 우선, 1-1) 기존에 존재하던 대부분의 text recognition 모델은 모든 이미지를 원래 크기가 다양한 것을 고려하지 않고 하나의 고정된 크기로 맞추는데 논문의 저자는 이런 기존의 방법의 유효성에 대한 의문을 제기하였다. 저자는 오히려 기존 이미지 크기와 모양을 고려하지 않고 단일 크기로 크기를 지정하는 것은 추가적으로 text에 distortion을 주는 일이라고 지적한다. 그래서 저자는 Multi-size resizing (MSR)을 도입해 종횡비에 따라 다른 크기로 reshaping하도록 해 resizing로 인한 텍스트 이미지 내 왝곡을 줄이고 각 문자가 확실히 구분되며 인식될 수 있도록 했다. 1-2) 그리고 이미지 내에서 다양하 형태로 배열돼 있는 텍스트에 대해 기존의 horizontal text에 대한 텍스트 인식에 적합한 CTC 방법을 조정해 비정형 텍스트에도 적절하게 정렬될 수 있도록 하는 feature rearrangement module (FRM)을 제안하였다. recognition 을 수행하기에 앞서 visual model로 부터 추출된 2D feature를 각 character에 대해 적절히 나눠서 하나의 시퀀스로 변환해야 한다. 이로써 CTC 모델이 rectification module을 추가로 두거나 attetion 기반의 디코더 없이도 비정형의 텍스트를 정확하게 인식할 수 있게 되었다. 2) 두번 째 문제인 문자의 의미 정보를 다루고 있지 않다는 점을 보완하기 위해서는 CTC는 visual feature로 부터 바로 text recognition을 수행하기 때문에 visual model 내에서 의미 정보를 이해할 수 있게 하는 것이 필요한데 저자는 segmantic guidance module로 이를 구현하고자 했다. 간단하게 그 방법은 각 글자마다 주변 글자를 이용하는 것이었다.
text irregularity 문제에 대해서 1) MSR 2) FRM 을 linguistic context를 활용하지 않는다는 점에 대해서는 3) SGM을 제안하며 SVTRv2 모델을 제안함으로써 CTC 기반의 모델이 갖는 구조의 간단함과 빠른 속도를 유지하면서 성능 향상을 보였다.
이후 regular text와 irregular text에 대한 실험을 기존 모델과 비교하며 SVTRv2의 성능을 검증하였는데 해당 결과와 분석 내용은 방법론에 대한 설명 이후에 다시 자세하게 하겠다.
2. Methods
overall pipeline
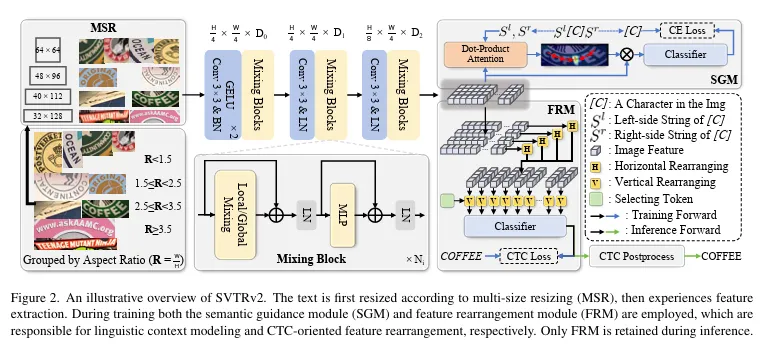
위는 SVTRv2의 전체 모델 구조를 나타낸 것이다. MSR을 통해 우선 입력된 이미지는 이미지의 종횡비에 맞게 크기가 조정된다. 3차례의 특징 추출 단계를 통과하며 visual feature 를 추출한다. 학습 때는 추출된 feature를 SGM, FRM에 둘 다 입력한다. SGM은 해당 모델로 부터 텍스트가 가지는 의미를 파악하고 활용할 수 있게 하고 FRM은 추출된 visual feature map은 2D인데 이를 순서를 갖는 시퀀스로 변환하는 역할을 한다. inference 시에는 SGM은 사용되지 않는다.
각 모듈에 대해서 추가적으로 설명하겠다
1. Multi-Size Resizing (MSR)
기존에는 텍스트 이미지를 32×128과 같이 하나의 고정된 해상도로 이미지를 resizing 했었다. 하지만 일부 이미지에서는 오히려 원치 않은 왜곡을 주며 character 간의 구별을 더 어렵게 한다. 따라서 논문의 저자는 원본 이미지가 갖는 종횡비를 고려하고 다르게 크기를 조정할 것을 제안하였다. 이미지가 워낙 긴 경우에도 유연하게 대처가 되도록 하기 위해 R4의 경우 이미지 크기가 종횡비에 따라 유동적인 것도 특징이다. (R = W/H)
R1: R < 1.5 ⇒ [64, 64]
R2: 1.5 ≤ R < 2.5 ⇒ [48, 69]
R3: 2.5 ≤ R < 3.5 ⇒ [40, 112]
R4: R ≥ 3.5 ⇒ [32, R x 32]
2. Visual Feature Extraction
총 3단계를 거쳐 visual feature이 추출되는데 각 단계 마다 여러 번의 mixing block이 있다. mixing block도 local과 global 두가지로 나뉜다. local mixing layer에서는 grouped convolution이 수행되며 엣지, 텍스처 정보 같은 local한 character 특징을 추출하는데 쓰인다. global mixing layer는 multi-head self attention이 수행되며 텍스트를 구성하는 character 들 간의 관계에 대한 이해를 키운다.
3. Feature Rearanging Module (FRM)
여러 방향으로 회전돼 있는 irregular 한 텍스트에 대한 missalignment 문제를 다루는 게 FRM 모듈인데 visual feature F를 CTC가 요구하는 정렬에 맞게 \tilde{F} 의 시퀀스로 변환한다. 재정렬의 과정을 확률에 기반한 soft mapping이라고 논문에서는 정의하고 매핑 행렬 M을 구하도록 모델을 설계하였다. Visual feature Extraction 모듈을 통과하고 나온 feature map에서의 F_{i, j} feature를 시퀀스의 m 번째 위치로 매핑하는 것이다. 수평 방향과 수직 방향 모두에 대해서 매핑을 각각 수행한다. 수직 방향에 대한 매핑을 수행할 때는 수직 방향에서와는 다르게 selecting token이란 게 사용된다. 이후 CTC clasifier를 통해 최종 예측을 낸다.
4. Semantic Guidance Module (SGM)
CTC 기반의 인식 모델은 인코딩된 visual feature로 부터 CTC classifier를 통해 텍스트 시퀀스에 대한 예측을 했었다. 여기에 lingustic information을 활용하기 위해선 visual feature에서 의미 정보를 함께 포함시켜야 했다. 그래서 제안한 게 SGM이란 모듈인데 텍스트에 대한 character 단위의 라벨이 다음과 같을 때 각 character를 주변 character들로 나타낼 수 있다. 하나의 character를 기준으로 왼쪽에 있는 character들을 S_{i}^{l}, 오른쪽에 있는 character들이 이루는 문자열 S_{i}^{r}으로 나타낼 수 있다. SGM의 역할은 이 둘로 부터 얻은 의미 정보를 visual feature에 통합하는 것이다. 즉 양 옆의 문자 정보를 이용해서 예측하고자하는 문자를 더 확실시 하는 것이다. 왼쪽 String을 가지고 그 과정을 설명하겠다. S_{i}^{l}의 character들은 string embedding 으로 매핑되고 어떤 representation Q_{i}^{l}으로 인코딩된다. Q_{i}^{l}과 visual feature F간의 dot product로 attention map A_{i}^{l}이 만들어진다. 수식은 이렇다.
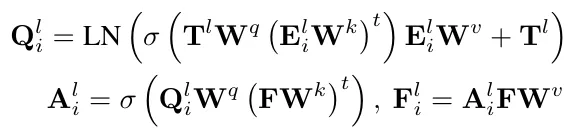
이렇게 만들어진 attetntion weight은 feature F를 가중하는 데 사용되며 현재 예측하고자 하는 문자가 이미지 상에 어디에 위치하는 지를 집중하게 하는 것이다. Q_{i}^{l}대로 F에 attention된 F_{i}^{l}을 기반으로 해당 문자를 예측하고 GT와의 cross entropy loss를 계산한다. 그리고 이 방법을 문자 우측에 위치한 문자열에 대해서도 동일하게 진행하는 것이다. SGM은 모듈은 추론 시에만 사용되는데 학습 때 해당 모듈을 통해 visual feature 자체가 context information을 가지도록 한다.
물론 SGM이 어텐션 기반의 방법론을 사용하지만 추론 시에는 사용하지 않기 때문에 CTC 기반의 방법론이라고 하는데 문제가 없고 추론 과정에도 어텐션 기반의 디코딩 과정을 통해 의미 정보를 취득하는 모델들과는 차이가 있다고 강조한다.
최적화할 목적함수는 다음과 같이 나타내진다.
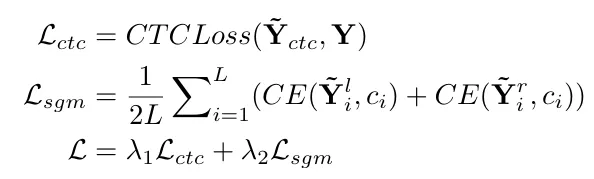
3. Experiments
3.1. ablation study
아래는 여러 ablation study에 대한 결과다
Effectiveness of MSR
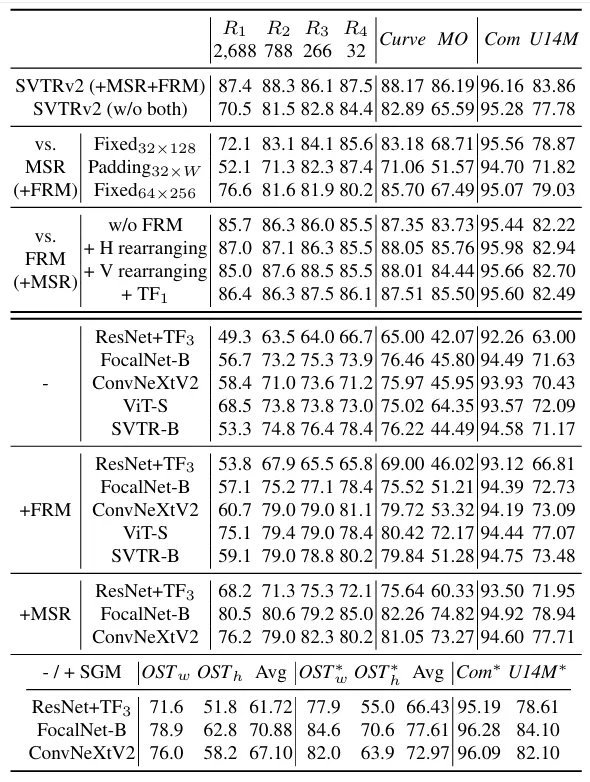
데이터의 대부분은 R1, R2에 해당하는 종횡비를 갖는다. 고정된 크기로 resizing한 것과 비교하면 R1 은 15.3 정도의 개선 R2는 5.2 정도의 성능 개선을 갖는다고 할 수 있다. resizing 하는 크기 자체를 키웠을 때 기존 보다는 성능이 향상됐지만 그럼에도 MSR을 사용해 각 데이터에 맞는 크기로 reshaping이 하는 것이 효과적임을 알 수 있다.
Effectiveness of FRM
FRM은 방향에 따라 수직, 수평 방향의 정렬 모듈로 나눠볼 수 있는데 특히 비정형 텍스트로 구성된 Curve, MO 데이터셋 결과를 같이 보면 FRM을 전혀 사용하지 않은 것과 비교해서 각각의 모듈을 추가함으로써 각각에서의 성능 향상을 보이는 것을 확인할 수 있다. 그리고 대신 Transformer block을 사용했을 때는 향상 폭이 저조했다. text irregulary에 대해서 강인함을 알 수 있다.
Effectiveness of SGM
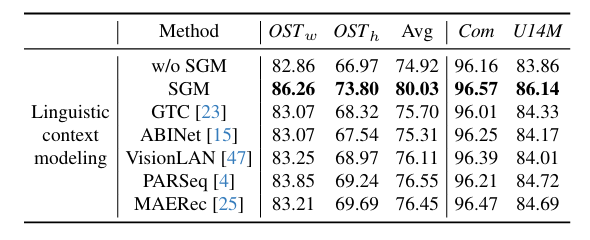
위는 SGM 모듈에 대한 ablation 결과로 occlusion 이 있는 OST 데이터셋에서의 향상 폭이 큰 게 특징인데 character 일부가 보이지 않는 상황에서 주변의 문자로 단어의 의미를 유추하고 이를 활용하는 것의 인식 정확도에 미치는 영향을 확인할 수 있는 결과였다.
3.2. Comparison with State-of-the-arts
다음은 24개의 기존 STR 모델들과 성능을 비교한 결과다. SVTRv2-B가 15개의 데이터셋 중 9개에 대해서 제일 좋은 성능을 보였다. 다른 모델과 비교했을 때 훨씬 더 빠른 추론 속도를 갖는다. 예를 들어 CPPD 모델도 빠른 속도로도 충분히 높은 정확도를 내기로 유명한 모델인데 저자가 제안한 SVTRv2은 이 만큼 빠르며 더 좋은 성능을 보이는 것이 확인된다. 더 작은 SVTRc2-T, S 모델들도 대체적으로 경쟁력이 있는 정확도를 가진다.
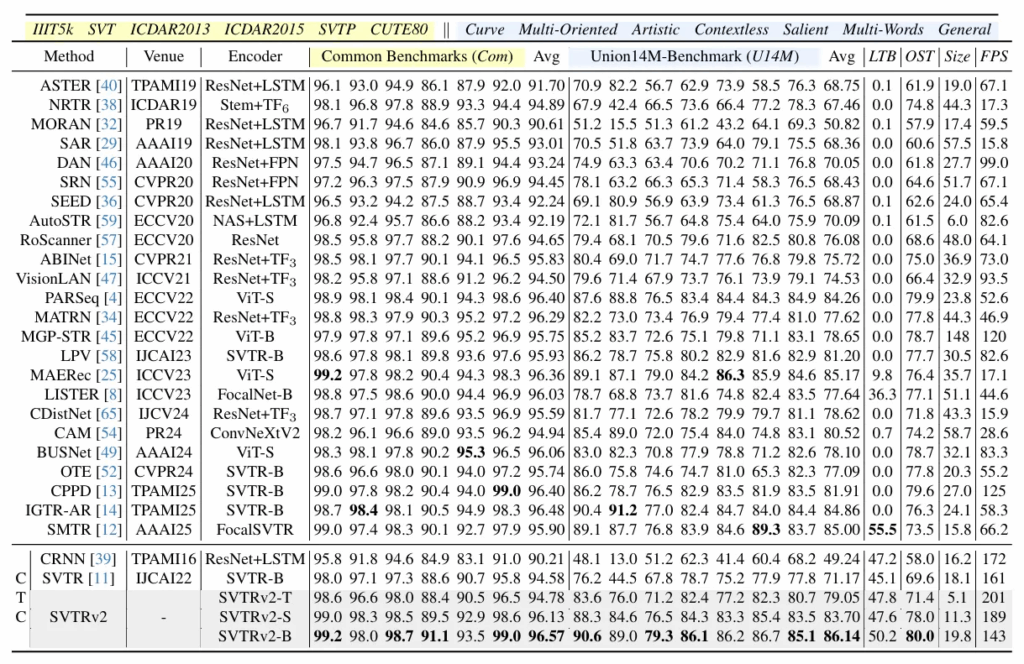
그리고 다음은 Curve, Multi-Oriented(MO)라는 데이터셋에 대한 더 자세한 분석 결과인데. 우선 위 table 3. 에서 확인할 수 있는데 두 데이터셋에 대해 다른 CTC 모델보다 높은 정확도를 갖는다. 그리고 아래표로는 rectification module이나 attention-based Decoder를 사용했을 때 보다도 더 성능이 좋음을 확인할 수 있어 SVTRv2 가 비정형 텍스트에 대한 인식 정확도가 높다는 것을 알 수 있다.
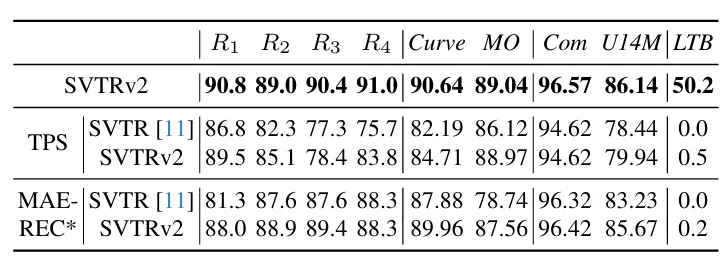
또한 긴 텍스트가 있는 데이터셋 LTB에 대한 정량적 결과와 정성적 결과를 함께 살펴보면 rectification 모듈을 사용한 것과 attention decode를 사용한 것의 결과가 현저히 낮은 한 편 SVTRv2의 정확도는 비교적 꽤 큰 차이로 높다는 것을 확인할 수 있다. 이로써 SVTRv2이 비정형 텍스트에 대해 충분히 강인하게 인식 정확도를 갖는다고 할 수 있지 않을까 싶다.

4. Conclusion
논문에서 제안한 방법론에 대해 정리하고 마무리 짓겠습니다. 기존의 CTC 기반의 STR 모델이 갖는 효율성을 그대로 가져가면서도 정확도를 높인 방법을 제안하였는데요. 기존에는 CTC 기반의 모델은 1) 비정형의 텍스트를 다루는데 정확도가 낮았고 2) 텍스트의 의미 정보를 활용하지 못했었습니다. 이를 보완하기 나온 것이 트랜스포머 기반의 STR 들이었지만 이들은 추론속도가 느리고 무겁다는 단점이 있었습니다. 그래서 논문의 저자가 제안한 것은 CTC 기반의 모듈이 앞서 설명한 문제를 해결하도록 적절히 모델을 재설계하는 것이었습니다. 우선 1번 문제를 해결하기 위해 MSR, FRM을 도입해 이미지의 왜곡을 최소한으로 하고 비정형 텍스트일지라고 character 각각에 대한 feature가 정확하게 분리되고 이용되도록 수직, 수평 방향으로 재정렬하는 과정이 추가로 설계되었었습니다. 그리고 문자가 단어에서 가지는 문맥 정보를 얻기 위해서는 각 문자를 기준으로 왼쪽, 오른쪽 문자열을 사용하도록 하는 SGM 모듈을 제안하였습니다. 그리고 실험 결과를 통해 일반적인 텍스트와 그렇지 않은 텍스트에 대해서도 전반적으로 높은 성능을 보이는 것 또한 확인할 수 있었습니다.
안녕하세요. 좋은 리뷰 감사합니다.
본 논문이 CTC 기반으로 기존 transformer 기반의 모델보다 좋은 성능을 낸 논문이라고 이해했습니다.
1. 궁금한 점이, CTC 모델 구조를 설명해주시는 부분에서 그냥 feature에 CTC linear classifier를 사용하면 결과가 나온다고 하셨는데, CTC linear 가 어떻게 동작하는 건가요?
2. 또, FRM 부분이 중요한 부분이라고 생각이 드는데요, 확률 기반으로 soft aranging한다는건 알겠는데 어떻게 한다는 건지는 설명이 안되어 있는 것 같아 보충 설명 부탁드립니다. 추가적으로 수직 방향에 대한 매핑에서는 왜 selecting token이 사용되는거고 어떻게 사용된다는 건지 궁금합니다.
감사합니다.
1.
CTC 기반의 텍스트 인식 모델의 학습 과정에 대해 설명을 드리면 대답이 될 것 같네요! 입력된 텍스트 이미지[H x W x C]에 대해서 인코딩된 피처를 받아와 시퀀스 벡터[T x D | T: timesteps, D: feature dimension]를 만듭니다. 이후 시퀀스 모델을 통과해서 앞뒤 문자와의 맥락이 고려된 시퀀스 벡터가 만들어지고요 이 벡터를 가지고 linear classifier에 전달해 각 타임스탭(T)마다 각 문자에 대한 확률을 예측합니다. 그리고 입력 시퀀스 길이와 실제 텍스트의 길이와 같지 않아 완전히 일대일로 정렬 되지 않기 때문에 정답라벨을 빈칸이나 문자를 중복해서 입력 시퀀스 길이와 맞추는 조합을 여러개 만든 뒤 모델의 출력과 실제 정답 간의 (타임스탭마다) loss를 계산해서 학습합니다.
2.
FRM은 수평, 수직 방향의 재배열의 과정을 담당합니다.
먼저 수평 방향의 재배열 과정을 설명 드리면, 이미지 피처 (F)의 행( F_i) 마다 multi-head self attention을 수행해 각 행의 피처들이 서로 가지는 관계를 나타내는 Attention Weight (M_i)^ h을 학습합니다.
이후 이를 각 행에 가중해 재배열합니다.
수직 방향의 재배열은 조금 차이가 있는데요 이미지 피처의 각 열 마다 모든 피처에 대해 selecting token과 cross attention을 수행해 Attention weight을 구하게 됩니다.
이때 이 선택 토큰이란 것은 학습이 가능한 것이고 각 세로줄에서 글자가 어디에 있을지를 선택하고자 집중하는 단계라고 보시면 됩니다. 이후 attention weight을 열 마다 모든 피처에 대해 가중하고 재배열 합니다. 재배열된 피처를 가지고 각 피처마다 하나의 피처만을 갖게 하는데 그 과정에 대해서는 하나만 선택하는 것인지 평균을 하는 것인지에 대한 자세한 설명은 논문에 나와있지는 않아 확실히 얘기 드리기가 어렵네요! 무튼! 재배열을 통해 정렬된 피처 시퀀스를 만들 수 있게 되는 것입니다.
두 방향에서의 재배열 과정의 차이를 정리하면 다음과 같습니다.
수평 방향의 재배열: 각 행 내 피처간의 관계를 학습한다. 문자간의 순서를 재정렬한다.
수직 방향의 재배열: 열 내 실제 글자가 있는 위치를 선택하는데. 이를 위해 선택 토큰이 추가적으로 도입된다.
안녕하세요 지연님 좋은 리뷰 감사합니다.
SGM 설명해주시는 부분에서 저는 문맥상 SGM이 학습시에만 사용되서 visual feature가 context정보를 학습하도록 돕는다고 이해했는데 “SGM은 모듈은 추론 시에만 사용되는데”라는 부분이 있어서 헷갈려서 댓글드립니다.
그리고 원래 하고 싶었던 질문은 단순히 SGM 파트만 읽었을 때에는 character들의 좌우 모음 대칭적으로 처리한 것 같은데 언어에 따라 좌측 context와 우측 context의 정보량이 다를 수 있을 것 같다고 생각이드는데 이에 대해서 논문에서 다루고 있는 부분이 있을까요?
감사합니다.
안녕하세요 지연님 리뷰 감사합니다.
세미나 때 질문을 하려다 못 했는데, 간단한 질문만 남기도록 하겠습니다. 기존의 CTC 방법들이 transformer 모델보다 성능이 좋지 않음에도 불구하고 (물론 해당 연구를 통해 성능도 좋아졌지만) CTC 방법들을 사용했다고 하셨는데, FPS로 봤을때는 80정도 되는 트랜스포머 기반 방법들도 못 쓸 정도로 느린건 아니지 않나..? 라는 생각이 들었습니다. 혹시 이런 Scene Text Recognition 모델들이 실제로 어떤 용도로 활용되나요?