ICCV 2025 억셉 리스트가 공개되었고, 제목에 이끌려 읽게된 논문에 대해 리뷰해보겠습니다.
오늘 알아볼 논문은, 멀티모달 러닝 태스크입니다. 다양한 모달리티를 어떻게 학습하면 좋을까? 에 대한 연구는 지금도 무궁무진하게 수행되고 있습니다. 해당 연구는 어떤 모달리티는 상관없이 “비디오”로 바꿔서 동일한 공간에서 학습하고 처리하면 되지 않을까? 에서 시작된 연구입니다. 아이디어는 엄청 심플합니다. 리뷰 시작하겠습니다.

- Conference: ICCV 2025
- Authors: G. Thomas Hudson, Dean Slack, Thomas Winterbottom, Jamie Sterling, Chenghao Xiao, Junjie Shentu, Noura Al Moubayed
- Affiliation: Durham University
- Title: Everything is a Video: Unifying Modalities through Next-Frame Prediction
1. Introduction
이제는 다들 아시겠지만… 텍스트, 이미지, 오디오, 비디오 등 다양한 모달리티를 동시에 처리하는 멀티모달 학습 기법은 VQA, 캡셔닝, Cross-modal Retrieval과 같은 태스크에 이제는 필수적이죠. 그러나 지금까지의 멀티모달 모델은 보통 각 모달리티에 별도의 인코더를 설계하여 정보를 개별적으로 처리한 뒤, 이후에 이를 결합(concat or attention 방식)하여 통합된 표현을 만들어내는 구조였습니다. 그러나 이 방식은 모달리티 마다 설계를 별도로 해야하므로 확장성과 유연성이 떨어지고, 새로운 태스크나 조합이 등장할 경우 재 설계가 필요하다는 한계가 있습니다.
이러한 한계를 극복하기 위해, 본 논문에서는 태스크 재정의(task reformulation)라는 아이디어를 기반으로 하는 새로운 접근 방식을 제안하였습니다. 이 개념은 원래 NLP에서 시작된 것이라고 하는데요, 다양한 태스크를 하나의 통일된 형식으로 바꿔 LLM이 다양한 작업을 수행할 수 있게 만들어주는 방식이라고 합니다.

상단 그림처럼… 예전에는 번역이면 번역, 요약이면 요약만 별개의 모델이 학습을 수행했습니다. 데이터셋 역시 태스크에 맞춘 입출력이 각각 존재하였죠. (CV에서도 이건 마찬가지죠? Detection, Depth 등등 구분되있던 것처럼요) 그런데 Prompt 기반의 학습이 등장하며, 학습의 판도가 완전히 변경되었습니다.

상단 그림이 바로 Prompt 기반의 학습 예시입니다. 번역, 요약, 질의응답 등 서로 다른 태스크를 “질문-응답” 형식으로 재구성함으로써 하나의 LLM이 모든 태스크를 처리할 수 있도록 하는 것이죠. 예를 들어, “이 영화 리뷰의 감정이 긍정적인가요, 부정적인가요?”와 같은 Instruction도 모델에 주고 감정인식이라는 Task를 수행하게 되었습니다.
저자들은 이러한 태스크 재정의 방식을 멀티모달 학습 영역까지 확장하였습니다. 구체적으로는 텍스트, 이미지, 오디오, 비디오 등 모든 입력과 출력을 “다음 프레임 예측(next-frame prediction)” 문제로 바꾸는 통합 프레임워크를 제안한 것이죠! 즉, 모든 모달리티를 순차적인 비디오 프레임의 형태로 표현함으로써, 하나의 트랜스포머 모델이 다양한 입력을 동일한 방식으로 처리할 수 있게 되는 구조라고 합니다.
이러한 접근 방식은 설계의 단순화뿐만 아니라, 새로운 모달리티의 통합도 쉽게 만들 수 있다는 장점이 존재합니다. 최근에는 NLP에서 LLM이 foundation model로 작동하듯, 본 논문은 이 unified next-frame prediction 방식을 멀티모달 영역의 범용 기반 모델로 발전시키고자 한 것이죠! 이제 본격적인 리뷰 시작하겠습니다.
2. Related work
이번에도 제가 자주 다룬 분야가 아닌만큼 간단하게 관련 연구들을 다뤄보겠습니다.
2.1 Multimodal Learning
트랜스포머 기반의 모델과 LLM, 그리고 대규모 사전학습이 가능해지면서 다양한 모달리티를 하나의 모델로 통합하려는 시도가 활발하게 이루어지고 있었다고 합니다. 초기 멀티모달 모델들은 우리가 흔히 아는 것처럼 주로 텍스트와 이미지를 별도의 인코더로 처리한 뒤, 뒷단에서 이를 결합하는 방식이 많았습니다. 하지만 이처럼 모달리티마다 전처리 과정을 다르게 설정해야 한다는 한계가 있었죠.
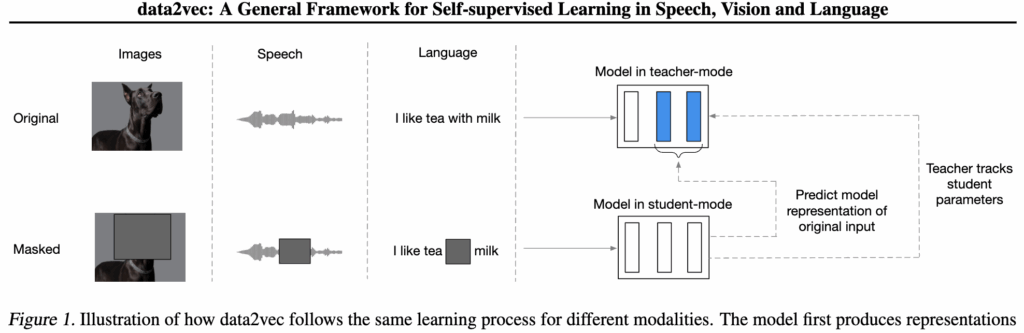
이를 극복하기 위해 모든 모달리티를 하나의 시각 표현(visual input)으로 통합하는 시도가 있었다고 합니다. 대표적인 예시가 data2vec이라는 논문인데, 텍스트, 이미지, 오디오를 각각 전용 인코더로 처리하면서도 동일한 방식의 학습 목표를 사용해 모달리티 간 표현 학습 방식을 동일하게 개선하려고 하였습니다. 이 방식은 학습 프로세스를 통일하려는 중요한 전환점이었지만, 여전히 입력 전처리와 인코딩 구조는 모달리티마다 달랐습니다.
본 논문은 이를 한 걸음 더 나아가, 텍스트, 이미지, 오디오를 ‘영상처럼 보이도록 시각화하여’ 하나의 입력 공간에 투입하는 방식을 제안하였습니다. 쉽게 말해, 텍스트든 오디오든 다 이미지 프레임처럼 바꿔서 모델에 넣는다는 겁니다. 그러면 자연스럽게 하나의 인코더로 모든 입력을 처리할 수 있게 되고, 모달리티에 따라 구조를 다르게 설계할 필요가 없어지는 것이죠.
저자들은 이러한 방식이 기존의 FLAVA나 GPT-4 Vision과 달리, 완전히 통합된 입력 구조를 가질 수 있다는 점에서 의미 있다고 주장하였습니다.
2.2 Next-frame Prediction
Next-frame prediction은 원래 비디오 생성 분야에서 활발히 연구되어 왔던 주제라고 합니다. 예측된 다음 프레임이 얼마나 실제와 유사한지를 평가하면서, 자연스러운 시퀀스 흐름을 모델이 학습할 수 있도록 하는 것이 핵심이죠. 최근에는 Transformer 기반 구조나 Diffusion 방식까지 확장되어 고품질의 장면 예측이 가능해졌습니다.
예를 들어 VideoGPT는 트랜스포머 구조를 활용하여 Long / Short frame 예측에서 좋은 성능을 보였고, 최근에는 photorealistic한 비디오까지 생성 가능한 수준에 도달하였다고 하네요. 하지만 본 논문은 새로운 예측 모델을 제안하는 것은 아니고, 이미 성능이 입증된 구조들을 가져와서, 다양한 멀티모달 태스크를 동일한 ‘다음 프레임 예측 문제’로 재정의했을 때 얼마나 잘 작동하는지를 실험적으로 검증하는 것이 주된 목적이라고 합니다.
3. Method
해당 논문에서는 통합된 멀티모달 학습을 위해, 태스크를 재정의한 것이 가장 큰 핵심 아이디어 였습니다. 그런만큼 논문에서 제안하는 프레임워크는 크게 두 가지 요소로 이루어져 있습니다. 첫 번째는 다양한 입력과 출력을 다음 프레임 예측(next-frame prediction) 문제로 바꾸는 태스크 재정의 방식이고, 두 번째는 이를 처리하는 Transformer 기반 모델 구조입니다.
3.1 Reformulation
우선 태스크를 재정의하는 방식부터 설명드리겠습니다. 사실 아이디어는 단순합니다. 모든 태스크를 64×64 RGB 비디오 시퀀스로 바꿔버리는 것입니다. 그러면 입력과 출력 모두를 “프레임”의 시퀀스로 통일할 수 있게 되고, 모델 입장에서는 그저 간단하게 “다음 프레임을 예측”하는 문제로 바뀌게 되겠죠?
그리고 각 태스크에서는 입력 프레임과 출력 프레임 사이에 구분자 역할을 하는 특수 토큰(|)을 넣어서, 어디까지가 입력이고 어디서부터 예측을 시작해야 하는지 모델이 명확히 알 수 있도록 하였습니다.
특히 텍스트 처리 방식이 재미있는데, 일반적인 텍스트 인코딩 방식(Vocab → Token ID → Embedding)이 아닌, 텍스트를 이미지로 렌더링해서 한 글자씩 프레임으로 변환해버립니다. 예를 들어 “very good”이라는 문장이 있다면, 각 단어를 고정된 폰트로 시각화하여 64×64 이미지 프레임으로 만들고, 이를 시퀀스로 모델에 입력합니다. 그러면 모델은 이 프레임들을 마치 이미지처럼 다룰 수 있게 되죠.
이 방식은 전통적인 텍스트 토크나이징 없이도, 모델이 텍스트를 읽고 쓸 수 있도록 만들어준다고 합니다. 게다가 텍스트도 이미지처럼 시각화되었기 때문에, 이미지/텍스트/오디오 같은 서로 다른 모달리티가 같은 입력 형식으로 자연스럽게 통합될 수 있습니다.
아래는 조금 더 구체적으로 다양한 태스크를 비디오 프레임 형태로 재구성한 방식에 대해 설명하겠습니다. 각 태스크는 입력 모달리티 → 출력 모달리티 구조에 따라 다음과 같이 구성됩니다:
(1) Text-to-Text: SST2 감성 분류

SST2(Stanford Sentiment Treebank 2) 감정 분류 태스크에서는 각 텍스트 토큰을 고정된 폰트로 렌더링한 후, 이를 하나의 64×64 비디오 프레임으로 변환합니다. 입력 텍스트가 여러 프레임으로 표현되며, 마지막에는 레이블 텍스트(positive/negative)가 프레임으로 들어갑니다. 텍스트 토큰화를 시각적 시퀀스로 변환함으로써, 별도의 텍스트 전용 인코더 없이 학습이 가능해졌다고 하네요.
(예시) [“unflinchingly”, “bleak”, “and”, “desperate”] → [|] → [“negative”]
(2) Image-to-Text (CIFAR-10)

CIFAR-10 이미지 분류는 단일 이미지를 64×64로 리사이즈하고, 그 뒤에 구분자 프레임, 그리고 클래스 라벨(예: “dog”)을 텍스트 이미지로 추가하여 비디오 프레임을 구성하였습니다. 결과적으로 상단 그림처럼, [이미지] → [|] → [dog] 같은 형태의 시퀀스가 만들어집니다.
(3) Video-to-Text (TinyVIRAT)

TinyVIRAT 동작 인식은 여러 프레임의 영상을 입력으로 사용하고, 이 뒤에 구분자 프레임과 여러 개의 동작 라벨(예: “walking”, “carrying”)을 텍스트 프레임으로 이어 붙였습니다. 멀티라벨 구성의 동작 인식을 단일 비디오 시퀀스로 표현한다고 하네요.
(4) Video+Text-to-Text (CLEVRER VQA)

CLEVRER 데이터셋은 질문-응답 비디오 기반 VQA 태스크입니다. 4장의 영상 프레임(입력) + 질문 텍스트 프레임 + 구분자 프레임 + 정답 텍스트 프레임으로 구성된다고 합니다. (예시) [video₁, video₂, video₃, video₄, “What”, “shape”, “leaves”… , “?”] → [|] → [“sphere”].
(5) Video-to-Video (TinyVIRAT / LaSOT)

Colorization: 흑백 영상 프레임을 입력으로 넣고, RGB 영상 프레임을 출력으로 구성.

Object Tracking (LaSOT): 첫 프레임에 bbox가 덧입혀진 이미지 → 영상 시퀀스 → 구분자 → GT bbox가 포함된 영상 프레임들로 구성
(6) Audio-to-Text (AudioMNIST)

오디오 데이터를 스펙트로그램으로 변환한 후, 이를 첫 번째 프레임으로 사용하였습니다. 이후 구분자 프레임과 숫자 레이블 텍스트가 비디오 프레임 형태로 구성됩니다. (예시) [스펙트로그램 이미지] → [|] → [“3”]
3.2 Video Prediction Model
저자들은 모든 태스크를 순수 트랜스포머 기반의 비디오 예측 모델로 통합하여 수행하였습니다. 이는 기존의 ViT와 TimeSformer (비디오)를 기반으로, 시공간 정보의 통합적 인코딩과 프레임 단위의 auto-regressive 예측이 가능한 구조로 확장한 것이라고 합니다. 특히 기존처럼 사전학습된 인코더-디코더 구조를 활용하지 않고, 학습의 효율성과 단순성을 위해 end-to-end로 학습 가능한 구조를 설계하였다는 점이 핵심입니다.
Patch-based Encoding with Hierarchical Merging
입력 비디오 시퀀스는 각 프레임을 일정 크기의 patch로 나눈 뒤, spatial-temporal self-attention을 적용하여 인코딩됩니다. 여기서, 인코더는 마치 U-Net처럼 계층적으로 설계되어 있어, 해상도를 줄여가며 patch를 병합하고, 이를 통해 연산량을 줄이면서도 다양한 스케일의 공간 정보를 포착할 수 있었다고 합니다. 또한 각 인코딩 블록 사이에는 patch merge 연산이 수행되고, 마지막에는 global attention 블록이 전체 시퀀스 수준의 표현이 통합되었다고 하네요.
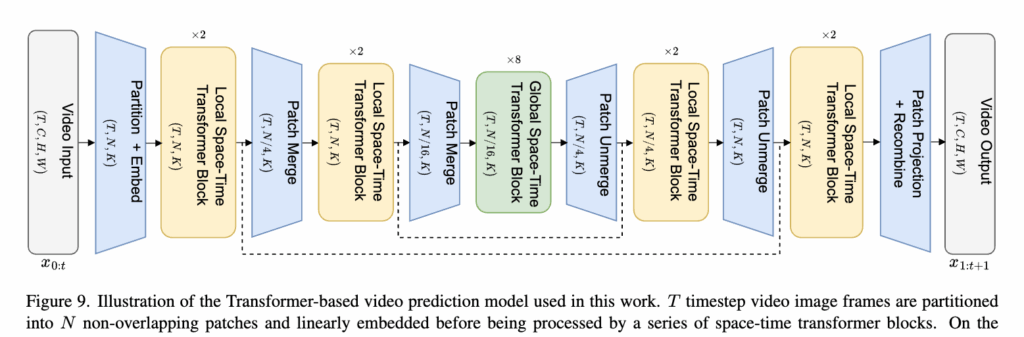
조금 더 구체적으로 설명드리면… 입력 시퀀스는 {x_1, x_2, ..., x_T} 형태의 비디오 프레임 시퀀스로 표현되며, 각 프레임 x_t는 크기 C×H×W의 이미지입니다. 각 프레임은 다시 N개의 patch로 분할되고, 각 patch는 1D 토큰으로 임베딩됩니다 (임베딩 차원 K=512).
이후 patch 임베딩은 학습 가능한 spatial/temporal positional encoding과 결합되어 transformer의 입력으로 들어갑니다. 주의할 점은 attention 메커니즘이 intra-frame과 inter-frame으로 구분되어 동작한다는 것입니다:
- Spatial attention: 한 프레임 내 patch 간 관계 학습
- Temporal attention: 동일 위치의 patch가 시계열적으로 어떻게 변화하는지 학습
Auto-regressive Decoding
디코딩 과정에서는 각 입력 프레임에 대해 다음 프레임을 예측하는 auto-regressive 방식이 적용되었습니다. 즉, 예측된 프레임은 시퀀스에 concat되어 다음 단계의 입력으로 사용됩니다. 이를 통해 모델은 시퀀스의 causal 관계를 학습하며, 다중 modality가 혼합된 입력 시퀀스에서도 점진적으로 출력을 생성할 수 있었다고 하네요.
다시 말해, 학습 시에는 미래의 프레임 정보를 마스킹하여 temporal causality를 유지하고, inference 시에는 autoregressive 방식으로 순차적으로 다음 프레임을 예측하였다고 합니다.
3.3 Training Details
가장 중요한 점! 모델은 사전학습 없이, 각 데이터셋에 대해 독립적으로 학습됩니다. 즉, 텍스트 언어모델이나 이미지 모델에서 사전학습된 파라미터를 전혀 활용하지 않고, 제안한 task reformulation 전략의 순수한 효과를 평가하는 것이 목적이죠!
학습은 end-to-end 방식으로 진행되며, Loss 함수로는 MS-SSIM(Multi-Scale Structural Similarity Index)을 사용하였습니다. 이는 생성된 프레임과 정답 프레임 간의 구조적 유사도를 측정하는 Loss함수로, 픽셀 단위의 L1/L2보다 더 정밀한 비주얼 퀄리티적인 판단이 가능하다고 합니다
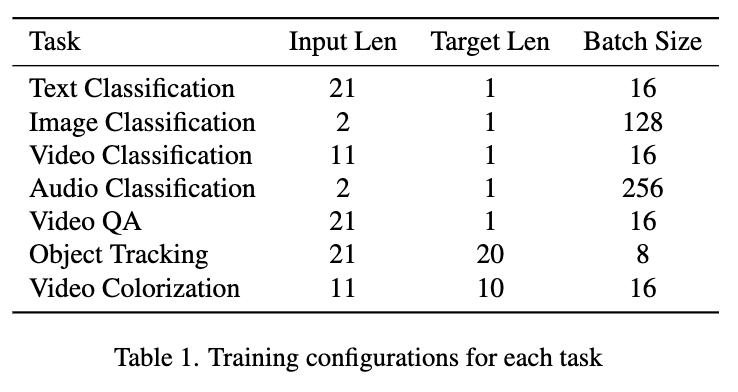
모든 실험은 NVIDIA A100 단일 GPU에서 최대 7일간 학습되었으며, 태스크별 입력/출력 길이와 배치 크기는 상단 Table 1에 정리해두었습니다.
4. Experiment
본 논문에서는 모든 태스크를 단일 태스크(single-task) 설정으로 독립적으로 학습하였다고 합니다. (동시에 여러 태스크를 수행하는 멀티태스크 joint 학습은 본 논문의 범위를 넘어선 future work라고 명시해두었죠.)
모델의 출력은 항상 다음 프레임(next frame)의 예측이므로, 태스크에 따라 다음과 같은 방식으로 출력 결과를 평가하였습니다.
텍스트 생성(Text output)
출력 프레임에 대해 Tesseract OCR 엔진을 사용하여 텍스트를 추출. 분류와 같은 고정된 단어 집합이 있는 태스크의 경우, OCR 결과를 가장 유사한 단어로 정렬하여 OCR 오류를 최소화. 이때 정확도(Accuracy)와 F1-score로 성능 평가.
Object Tracking
출력된 프레임에서 바운딩 박스를 추출한 뒤, GT와 IoU를 비교하여 정확도 측정.
Video Colorization
흑백 비디오를 컬러로 예측하는 태스크에서는 두 가지 측면을 평가
- 컬러 복원 성능: PSNR과 컬러풀니스 지표(Colorfulness)를 사용
- 시간적 일관성: 프레임 간 색의 일관성을 평가하기 위해 CDC(Color Distribution Consistency)사용. 이는 프레임 간 RGB 채널별 컬러 분포의 Jensen-Shannon Divergence를 계산한 값으로 정의되며, 시간 간격(t=1,2,4)에 따라 평균:
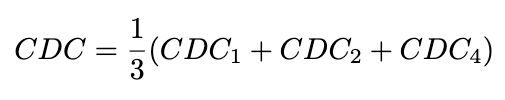
이러한 설정은 영상 기반 출력이 다양한 태스크에서 어떻게 공통적으로 평가될 수 있는지를 나타내고, Unified Next-Frame Prediction 접근의 범용성을 정량적으로 평가하기 위함이라고 하네요.
5. Result
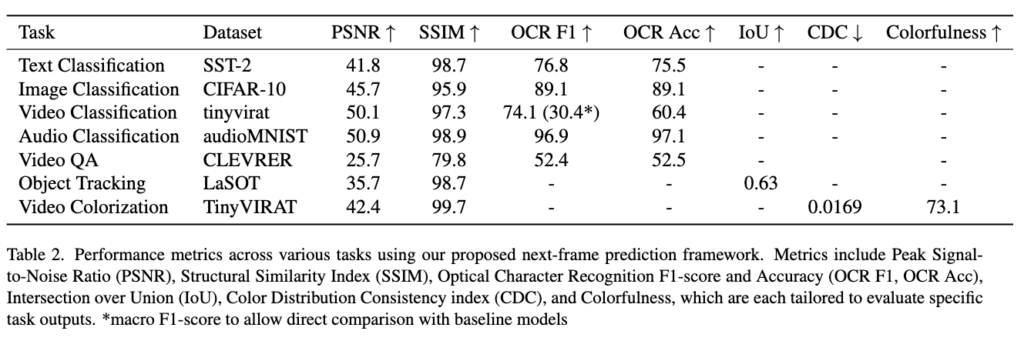
다양한 modality의 태스크들을 video prediction 형태로 변환한 뒤, 별도의 사전학습 없이 학습을 수행하고 그 성능을 평가한 결과는 아래 테이블 1과 같습니다.
Text Classification (SST-2)
F1-score 76.8으로, 기존 SoTA (91.3)에는 미치지 못하지만, 사전학습 없이 직접 학습했다는 점을 감안하면 의미 있는 성능이라고 합니다. 입력 토큰 수를 20 이하로 제한할 경우 F1-score는 80.0까지 상승하였습니다.
Image Classification (CIFAR-10)
Accuracy는 89.1로, ViT+pretraining(99.5)보다는 낮지만, PCANet (77.14) 등의 단순한 모델보다는 훨씬 우수하였다고 합ㄴ다. 사전학습 없이도 합리적인 분류 성능을 달성한 결과라고 하네요
Multi-label Classification (TinyVIRAT)
ResNet50 (29.1)보다 우수, WideResNet (32.6)에는 다소 못 미치는 결과이긴 합니다. 그러나 비디오 표현만으로도 여러 개의 객체 레이블링이 가능함을 보였습니다.
Audio Classification (AudioMNIST)
Accuracy는 97.1로, AlexNet baseline (95.82)보다 높았습니다. 그러나 주로 숫자 “four”와 “five” 사이에서 혼동 발생하였다고 하네요
Visual QA (CLEVRER)
Accuracy는 52.5 (on descriptive QA)로 LSTM (34.7), LSTM+CNN (51.8) 대비 우수한 결과였습니다, 또한 VQA도 별도의 인코더-디코더 없이 처리 가능함을 보여준 결과였습니다..만! 하드웨어 제약으로 해상도와 프레임 수가 다소 작게 처리되어 있었죠 (64×64, 4 frames… 허허)
Object Tracking (LASOT)
IoU는 0.63로, Autoregressive 예측을 통해 객체 위치를 일관되게 추적하지만, 긴 시퀀스에서 정확도가 약간 감소하였습니다.
Video Colorization
Color Diversity는 73.1 (vs. GT 70.6)로 더 풍부한 색상 분포를 가지지만.. CDC (Temporal Color Consistency)는 0.0169 (vs. GT 0.00522)로 시간 일관성은 다소 떨어지는 결과를 보입니다. 저자가 말하길 색상 다양성 vs. 시간적 일관성 간의 trade-off 존재한다고 하네요.
5.1 Attention Map
이제 모델이 각 태스크에서 어떤 정보를 주목하는지, 시각적으로 확인하고자 저자는 patch-wise attention을 시공간적으로 분석하였습니다. 그 결과는 아래 이미지와 같습니다.
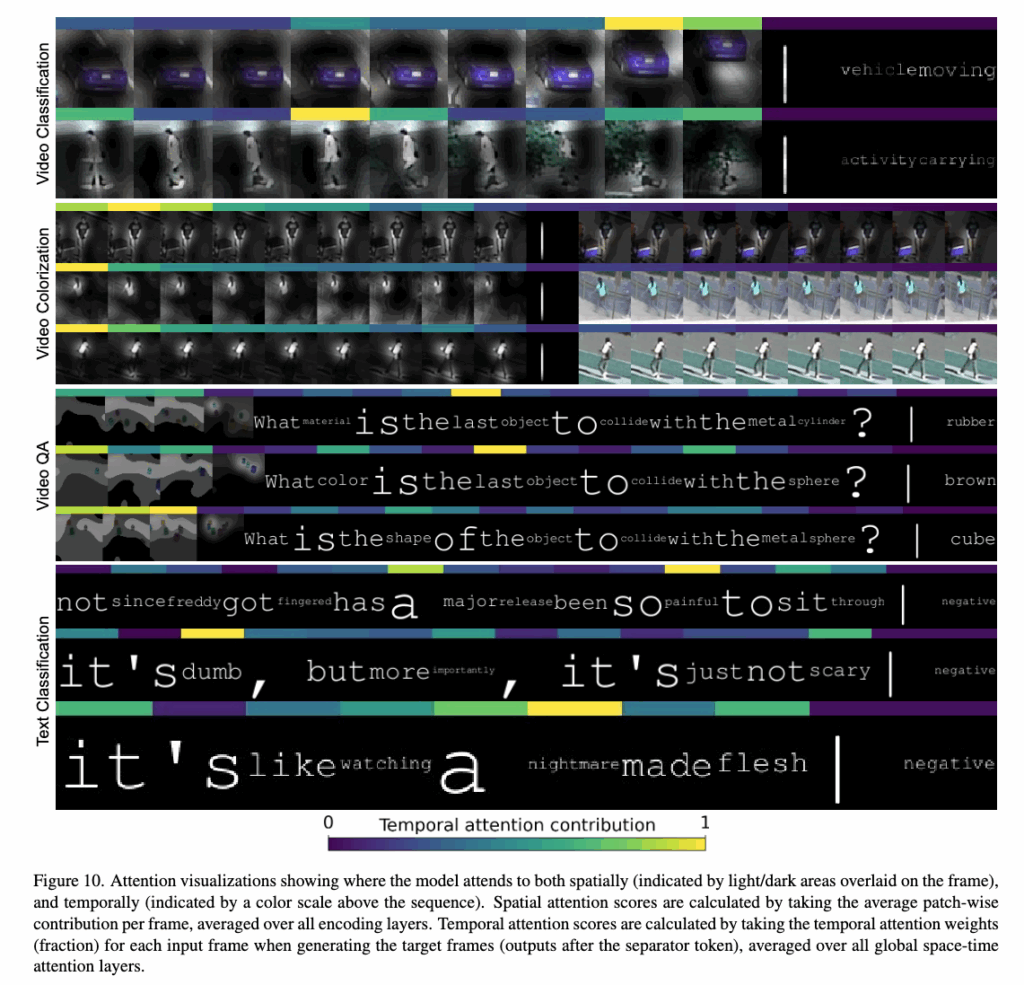
TinyVIRAT (Video Classification)
Spatial attention은 자동차의 가장자리처럼 움직임을 암시하는 패치에 집중하는 경향을 보였습니다. 또한 Temporal attention은 자동차가 움직이는 마지막 두 프레임에 높게 분포하였고, ‘vehicle moving’ 클래스 예측에 중요했다고 하네요
Colorization
첫 입력 프레임에 집중된 attention은 시퀀스 전반에 걸쳐 색상 일관성 유지에 기여한 결과를 보였습니다. 출력 시퀀스의 첫 프레임에도 attention을 주어 일관된 색 재현을 유도했고, Spatial하게는 움직이는 객체 및 뚜렷한 색상의 영역에 주목하는 경향을 보였습니다.
CLEVRER (VQA)
질문 문장에서 ‘color’, ‘metal’과 같은 핵심 단어에 집중하는 결과를 보였습니다. 영상에서는 객체와 궤적에 대해 spatial attention이 분포하였는데, ‘metal cylinder’, ‘sphere’ 등 객체를 올바르게 인식하는 결과를 보였다고 하네요.
SST-2 (Text Classification)
LLM에서처럼 감정이 강한 단어들(예: ‘nightmare’, ‘painful’, ‘dumb’)에 높은 attention 부여하였습니다. 이는 문장의 전체 감성 판단에 중요한 힌트로 작용한 결과라고 하네요.
6. Summary
해당 논문에서는 다양한 멀티모달 태스크를 비디오 예측 문제로 재구성함하여, 하나의 통합된 입력/출력 포맷 내에서 다양한 입력 modality를 수용하는 새로운 프레임워크를 제안하였습니다. 이를 위해 모든 입력을 비디오 형태로 변환한 후 autoregressive하게 다음 비디오를 예측하는 방식을 통해, 다양한 멀티모달 입력들을 단일한 형태로 처리할 수 있었죠.
제안된 방식은 pretraining 없이 학습되었고, 다양한 태스크(텍스트 분류, 이미지 분류, VQA, 오디오 인식, 객체 추적, 컬러라이제이션 등)에 대해 어느정도 성능을 보였습니다. 특히 CLEVRER, LASOT, TinyVIRAT와 같은 멀티모달 태스크에서도 별도의 modality-specific decoder 없이 attention 기반 구조만으로 의미 있는 결과를 보인 것이 아닌가 싶습니다.
결국 “모든 입력을 비디오처럼 처리할 수 있다면, 하나의 학습 파이프라인으로 다양한 태스크를 아우를 수 있다”는 아이디어를 실험적으로 설계한 뒤, 그 가능성을 작게나마 보여준 논문이 아닌가 싶습니다.
처음에 논문을 읽기 시작했을 때부터.. 와이게 학습이 되나? 성능이 나려나? 라는 의구심과 함께 다소 실험적인 연구이지 않나 싶었는데.. 역시 데이터셋이 아주 작고 성능 역시 제가 기대한 것과는 달리 드라마틱한 결과는 아니었습니다. 그러나 지금도 새로운 패러다임을 만들고자 계속해서 새로운 멀티모달 연구가 수행되고 있다는 것을 새삼스레 깨닫게 해준 연구가 아닌가 싶네요.
안녕하세요 주영님 독특한 아이디어를 가진 논문 재밌게 읽었습니다.
주영님이 얘기해주셨듯이 이게 드라마틱한 성능을 보여주는 것은 아니더라도 여러 task를 다음 프레임을 예측하는 단일 모델로 해결할 수 있는 것을 보여주는 것 같습니다. 뭔가 대기업에서 해당 아이디어로 큰 모델을 만들어주기를 바란 논문인건지 싶네요.. 그리고 여러 task 들을 비디오처럼 보이게 하기 위한 전처리가 다 달라서 은근 단점이라고 생각할 수도 있을 것 같습니다. 이게 이후에 실제 대기업에서 가져갈 만큼의 이론적 컨셉, 강점이 확실하다고 생각하시는지 궁금합니다. 강점이 확실하다면 추가적으로 해결되어야할 문제점은 뭐가 있을지 혹시 생각해보신게 있나요? 감사합니다.
말씀하신대로, 이 논문은 성능보다는 구조적 가능성과 단순화 가능성에 집중한 연구로 볼 수 있을 것 같습니다. 산업적으로도 이 개념은 굉장히 매력적으로 느낄 수는 있겠지만, 아래 두 조건이 충족되어야 현실 적용이 가능할 것으로 같다 생가합니다.
1) 더 일반화된 사전학습 체계 (modality 간 transferable한 representation 확보)
2) 전처리/후처리 비용 없이 직접 task를 해결하는 end-to-end 구조
다시 말해, “비디오 예측 하나로 모든 태스크를 해결할 수 있다”는 개념 자체는 분명 매우 강력하겠지만, 이를 task-agnostic하게, 효율적으로, 정확하게 만드는 작업은 아직 남아 있는 셈 아닐까요
안녕하세요 정말 좋은 논문을 소개해주셔서 감사합니다.
해당 논문이 다양한 모달리티를 2D 데이터 도메인(영상 도메인)으로 바꾸어 멀티모달 학습을 통합한 것이 맞을까요?
맞다면 오디오 도메인을 영상 도메인으로 바꾸어 학습에 사용했던 방법과 차이점이 무엇일까요?
물론 이러한 입력의 형태 변환 자체 노벨티 보다, 해당 변환을 통해 트렌스포머가 전문가의 사전정의없이 통합적으로 문제를 해결할 수 있음을 보였다는 관점에서 매우 유의미한 연구로 보입니다.
그렇다면 새로운 입력 형태를 제안한것보다 트렌스포머의 잠재력을 보이는 논문으로 이해하면 될까요?
감사합니다.
Q1. 다양한 모달리티를 2D 영상으로 바꾼 것이 맞는가?
-> 네, 다양한 모달리티를 2D 이미지/비디오 도메인으로 변환하여 학습한 것이 맞습니다.
– 텍스트 → 폰트로 렌더링된 텍스트 이미지 시퀀스
– 오디오 → Mel-spectrogram 이미지 시퀀스 (즉, 시간-주파수 2D 이미지)
– 이미지 → 단일 프레임 혹은 시퀀스로 구성
– 비디오 → 원래 비디오 그대로 사용
즉, 모든 입력을 2D 이미지들의 연속인 비디오처럼 보이도록 만들어 Autoregressive Video Prediction 문제로 바꿉니다. 이 때, 오디오는 기존 영상 도메인으로 바꿔서 학습하는 방법과는 큰 차이가 없습니다.
2. 새로운 입력 형태 제안한 것이 아닌 트랜스포머의 잠재력을 보인 논문인가?
-> 네, “새로운 입력 표현 제안”보다는, 기존의 Transformer 아키텍처가 하나의 프레임워크 안에서 다중 모달리티를 통합적으로 처리할 수 있음을 보여주는 연구가 아닐까 싶습니다
안녕하세요 주영님 좋은 논문 소개해주셔서 감사합니다 재밌게 잘 읽었습니다!
Auto-regressive Decoding을 설명해주실 때 ‘학습 시에는 미래의 프레임 정보를 마스킹하여 temporal causality를 유지한다’고 하셨는데, 이 문장이 정확히 어떤 의미인지 잘 이해가 되지 않아 설명해주시면 감사하겠습니다
먼저, 잘 아시겠지만 Auto-regressive 모델은 출력 시퀀스를 한 단계씩 순차적으로 예측하는 방식입니다.
즉, 이전에 생성한 출력을 바탕으로 다음 출력을 예측하는 방식입니다.
예를 들면 “맑음”을 예측한다 가정했을 때 아래 과정을 거칩니다
– 입력: “오늘 날씨는”
– 출력: “맑”
– 그 다음: “맑”을 입력으로 넣고 → “음”
– 그 다음: “맑음”을 넣고 → “입”
– … 반복…
그런데 학습할 땐, 전체 GT가 존재합니다. 전체 시퀀스를 한번에 예측하면 미래 정보를 미리 본 채로 예측할 수 있는 상황에 처해집니다. 그러나 inference 시에는 입력이 순차적으로 들어오기 때문에, 미래 정보를 모르는 상황이죠. 그래서 Temporal Causality 를 유지해야 합니다, Temporal Causality란, 시간 순서를 지켜서 과거 정보만 보고 미래를 예측하도록 학습하는 것이라고 하는데요. 미래 정보는 마스킹해서 모델이 학습할 때 과거 정보만으로 미래 정보를 예측하도록 하는 것이죠
홍주영 연구원님. 좋은 리뷰 감사합니다. 내용이 신박해서 재밌게 읽었습니다.
task refomulation은 ImageBind처럼 하나의 모달리티를 기준으로 여러 모달리티를 통합한 것과, 기존의 텍스트 분야에서 잘 되던 next sentence(token) prediction을 비디오 시퀀스로 확장시킨 아이디어를 적절하게 섞은 것으로 보이네요. 여기까지는 ‘와 다른 분야의 아이디어를 비디오에 잘 접목했다’정도의 생각이 들었는데 텍스트를 그대로 이미지로 넣어버리는 부분에서부터는 계속 주영님처럼 이게 된다고? 라는 생각이 들었습니다. (해당 프레임워크를 처음 제안한 것임을 감안해야겠지만)프레임워크가 굉장히 나이브하긴 하네요. 동작하는게 신기합니다..
읽다 보니 궁금한 점이 있어 질문 2개 남기겠습니다.
1. transformer 입력 시퀀스에 순서 정보를 주기 위해 일반적으로 positional encoding/embedding을 같이 넣어주는데, 해당 프레임워크에서 사용하는 learnable spatial/temporal positional encoding은 어떻게 구성되나요?
2. attention 부분에서 sptial attention 수행 후 temporal attention을 수행하는데, 그럼 각 입력 프레임들을 모두 별도로 spatial attention을 수행한 다음 이렇게 attention을 수행한 frame vector들을 모아서 이들끼리 다시 temporal attention을 수행하는 건가요? temporal attention이 구체적으로 어떻게 수행되는지 잘 이해 되지 않습니다.
감사합니다!
1. 해당 논문에서는 입력 비디오 시퀀스에 대해 학습 가능한 spatial/temporal positional embedding을 각각 사용합니다. Spatial embedding은 프레임 내 각 패치의 위치(row, column)를 나타내고, temporal embedding은 해당 프레임이 시퀀스에서 몇 번째인지(t=0, 1, …)를 나타냅니다. 두 임베딩은 patch embedding에 더해져 모델 입력이 됩니다.
2. Attention은 두 단계로 나뉘는데, 먼저 각 프레임 내에서 패치들 간 관계를 보는 spatial attention을 수행하고, 이후 각 프레임의 요약 표현을 기반으로 temporal attention을 적용하여 시간 간 관계를 학습합니다. 즉, 프레임별로 공간 정보를 처리한 후, 시퀀스 수준에서 시간적 연관성을 학습하는 구조입니다.